Hallo zusammen
Ich versuch, eine eigentlich einfache Aufgabe mittels eines FPGAs zu
lösen.
Leider aber wird mein VHDL-Code in eine riesige Struktur synthetisiert.
Ich habe bereits eine Verdacht warum, aber ich wärse sehr froh um eure
Hilfe bei der Optimierung.
Ausgangslage:
Chip: Lattice MachXO3-4300C Speedgrade 5
Beim FPGA kommen externe RGB Daten an (insgesamt drei std_logic_vector
(7 downto 0))
Diese Vektoren verden verrechnet und es steht ein Ergebnis in einem
signal namens RESULT.
Nun gut. Dieses Resultat wird nun in einem zweidimensionalen Array
bestehend aus Integer gespeichert. Nennen wird deses Array
RGB_RES_ARRAY()().
Das Array ist wie folgt definiert:
Nach der Synthese bzw. dem Mapping sieht der Report wie folgt aus:
1
Design Summary
2
Number of registers: 14792 out of 4941 (299%)
3
PFU registers: 14792 out of 4320 (342%)
4
PIO registers: 0 out of 621 (0%)
5
Number of SLICEs: 9208 out of 2160 (426%)
6
SLICEs as Logic/ROM: 9208 out of 2160 (426%)
7
SLICEs as RAM: 0 out of 1620 (0%)
8
SLICEs as Carry: 78 out of 2160 (4%)
9
Number of LUT4s: 8789 out of 4320 (203%)
10
Number used as logic LUTs: 8633
11
Number used as distributed RAM: 0
12
Number used as ripple logic: 156
13
Number used as shift registers: 0
Wenn ich hingegen diese eine Zeile:
1
RGB_RES_ARRAY(row)(col)<=RESULT;
Dahingehend ändere (in eine fixe Zuweisung):
1
RGB_RES_ARRAY(row)(col)<=123;
So ergibt der Report folgendes:
1
Design Summary
2
Number of registers: 75 out of 4941 (2%)
3
PFU registers: 75 out of 4320 (2%)
4
PIO registers: 0 out of 621 (0%)
5
Number of SLICEs: 241 out of 2160 (11%)
6
SLICEs as Logic/ROM: 241 out of 2160 (11%)
7
SLICEs as RAM: 0 out of 1620 (0%)
8
SLICEs as Carry: 16 out of 2160 (1%)
9
Number of LUT4s: 481 out of 4320 (11%)
10
Number used as logic LUTs: 449
11
Number used as distributed RAM: 0
12
Number used as ripple logic: 32
13
Number used as shift registers: 0
Die Frage die sich mir nun stellen sind:
- Ist die Konvertierung von Integer zu std_logic_vector evtl. Ressourcen
intensiv?
- Ist es ein Problem, dass ich mehrere solcher Arrays verwende?
- Die VHDL-Bedingungen scheinen sehr viele Multiplexer zu erzeugen. Gibt
es für das von mir benötigte Mapping evtl. elegantere Umwege?
- Hat evtl. jemand allgemein eine Idee für mein Problem?
Danke!
Holger K. schrieb:> - Ist die Konvertierung von Integer zu std_logic_vector evtl. Ressourcen> intensiv?
Nein. Synthetisier doch einfach mal ein Minimalbeispiel in dem nichts
anderes drin ist als eine Konvertierung von int zu std_logic. Dann
kannst im RTL Viewer ja sehen was passiert.
Hej,
type t_RESMemory_row is array (0 to 17) of integer range 0 to 65535;
ist schon verdächtig groß. Aus den deinem Reports fehlen leider auch die
Angaben, ob du embedded Memory Blöcke überhaupt verwendest. Je nach
Anwendung, könnten diese die restliche Logik erheblich entlasten.
z.B. (ohne deine Schaltung genau zu kennen, aber aus meiner vergangenen
Lösungen), einen BMRAM als Pipeline verwenden, zyklisch hineinschreiben
und einen konstanten Abstand zwischen Schreib- und Lese-Pointer
verwenden.
Viel Erfolg.
Ich hab's jetzt nur schnell diagonal gelesen, aber der hier:
Holger K. schrieb:> RGB_RES_ARRAY(row)(col) <= RESULT;
sorgt sehrwahrscheinlich dafuer, dass der Mapper nicht mehr einen EBR
fuer dein RAM inferiert (und alles in die LUTs packen muss). Bei einem
konstanten Wert schon. Guck doch auch mal nach den EBR in den
Mapper-Stats.
Also: no such fun. Wenn du so in das RAM schreiben willst, musst du eine
I/O-Logik dazu basteln.
Danke für eure Antworten.
Charles G. schrieb:> ist schon verdächtig groß.
Ja. Ist wirklich nicht klein!
Charles G. schrieb:> Aus den deinem Reports fehlen leider auch die> Angaben, ob du embedded Memory Blöcke überhaupt verwendest.
Nein, aktuell verwende ich kein Memory dafür.
Charles G. schrieb:> zyklisch hineinschreiben> und einen konstanten Abstand zwischen Schreib- und Lese-Pointer> verwenden.
Wie meinst du zyklisch hineinschreiben?
Ich muss für meine Anwendung immer ein wenig am RAM ergänzen bzw. ändern
und dann wieder das gesamte Memory auslesen. Dann wieder ein Paar werte
anpassen und wieder Auslesen.
Daher kann der Abstand zwischen schreib und lese-pointer nie konstant
sein. Müsste ich dafür evtl. ein Dualport BMRAM verwenden?
Holger K. schrieb:> Leider aber wird mein VHDL-Code in eine riesige Struktur synthetisiert.
Dann packe dein komplettes Projekt in eine Zip-Datei und lade sie hier
hoch.
Strubi schrieb:> Guck doch auch mal nach den EBR in den> Mapper-Stats.
Danke für die Antwort. Hier der komplette Log:
1
Design Summary
2
Number of registers: 14792 out of 4941 (299%)
3
PFU registers: 14792 out of 4320 (342%)
4
PIO registers: 0 out of 621 (0%)
5
Number of SLICEs: 9208 out of 2160 (426%)
6
SLICEs as Logic/ROM: 9208 out of 2160 (426%)
7
SLICEs as RAM: 0 out of 1620 (0%)
8
SLICEs as Carry: 78 out of 2160 (4%)
9
Number of LUT4s: 8789 out of 4320 (203%)
10
Number used as logic LUTs: 8633
11
Number used as distributed RAM: 0
12
Number used as ripple logic: 156
13
Number used as shift registers: 0
14
Number of PIO sites used: 79 + 4(JTAG) out of 207 (40%)
15
Number of PIO sites used for single ended IOs: 63
16
Number of PIO sites used for differential IOs: 20 (represented by 10 PIO
17
comps in NCD)
18
Number of IDDR/ODDR/TDDR cells used: 9 out of 621 (1%)
19
Number of IDDR cells: 0
20
Number of ODDR cells: 9
21
Number of TDDR cells: 0
22
Number of PIO using at least one IDDR/ODDR/TDDR: 9 (9 differential)
23
Number of PIO using IDDR only: 0 (0 differential)
24
Number of PIO using ODDR only: 9 (9 differential)
25
Number of PIO using TDDR only: 0 (0 differential)
26
Number of PIO using IDDR/ODDR: 0 (0 differential)
27
Number of PIO using IDDR/TDDR: 0 (0 differential)
28
Number of PIO using ODDR/TDDR: 0 (0 differential)
29
Number of PIO using IDDR/ODDR/TDDR: 0 (0 differential)
30
Number of block RAMs: 0 out of 10 (0%)
31
Number of GSRs: 1 out of 1 (100%)
32
EFB used : No
33
JTAG used : No
34
Readback used : No
35
Oscillator used : Yes
36
Startup used : No
37
POR : On
38
Bandgap : On
39
Number of Power Controller: 0 out of 1 (0%)
40
41
Number of Dynamic Bank Controller (BCINRD): 0 out of 6 (0%)
42
Number of Dynamic Bank Controller (BCLVDSO): 0 out of 1 (0%)
43
Number of DCCA: 0 out of 8 (0%)
44
Number of DCMA: 0 out of 2 (0%)
45
Number of PLLs: 1 out of 2 (50%)
46
Number of DQSDLLs: 0 out of 2 (0%)
47
Number of CLKDIVC: 1 out of 4 (25%)
48
Number of ECLKSYNCA: 1 out of 4 (25%)
49
Number of ECLKBRIDGECS: 0 out of 2 (0%)
50
Notes:-
51
1. Total number of LUT4s = (Number of logic LUT4s) + 2*(Number of
52
distributed RAMs) + 2*(Number of ripple logic)
53
2. Number of logic LUT4s does not include count of distributed RAM and
54
ripple logic.
Scheint kein EBR verwendet worden zu sein.
Strubi schrieb:> musst du eine> I/O-Logik dazu basteln.
Wie stellst du dir diese vor? bzw. was soll diese genau umsetzen?
Laserfreak schrieb:> Holger K. schrieb:>>> Leider aber wird mein VHDL-Code in eine riesige Struktur synthetisiert.>> Dann packe dein komplettes Projekt in eine Zip-Datei und lade sie hier> hoch.
Werde ich sogleich tun.
Holger K. schrieb:> Strubi schrieb:>> Guck doch auch mal nach den EBR in den>> Mapper-Stats.>> Danke für die Antwort. Hier der komplette Log:
Jetzt noch das Projekt und wir können es durchsehen
Meine Glaskugel sagt: du versuchst die Berechnung für das gesamte Array
auf einmal durchzuführen. Sinnvoller wäre, das nacheinander für jedes
Element des Array durchzuführen.
Um beides unterscheiden zu können wäre hilfreich, was in diesem Prozess
von dir
process (CLK)
if(rising_edge(CLK)) then
..
if(RESULT > RGB_RES_ARRAY(row)(col)) then
RGB_RES_ARRAY(row)(col) <= RESULT;
end if;
...
end if;
mit row und column während eines Taktzyklus passiert. Sind das Signale,
die taktsynchron durchzählen (also pro Takt nur eine Element des Arrays
ansprechen)? Oder sind das Variablen, die du innerhalb des gezeigten
Prozesses in Schleifen durchzählst (also pro Takt alle Elemente des
Arrays ansprechen)?
Laserfreak schrieb:> Jetzt noch das Projekt und wir können es durchsehen
Damit ließe sich meine Glaskugel dann wieder rekalibrieren ;-)
Sicherlich gibt es (wie bei den üblichen Verdächtigen) auch bei Lattice
ein Kapitel "recommended design practice" (oder so ähnlich), das dir
Infos darüber liefert, wie Du die Synthese dazu bringst, ROM-Strukturen
im Memory anzulegen?
Markus F. schrieb:> Sicherlich gibt es (wie bei den üblichen Verdächtigen) auch bei> Lattice> ein Kapitel "recommended design practice" (oder so ähnlich), das dir> Infos darüber liefert, wie Du die Synthese dazu bringst, ROM-Strukturen> im Memory anzulegen?
Gute Idee. Das sollte ich mir anschauen.
Hier noch das Projekt zum download:
https://omega.databyte.ch/index.php/s/nD8DL9f4Xm9KJew/download
Holger K. schrieb:> Hat sich das Projekt schon jemand angeschaut?
Nicht das ganze Projekt. Aber immerhin mal so viel, um ein Beispiel daür
zu finden, wodurch du sehr große Logikblöcke erzeugst.
Dieser Code in rgbanalyzer.vhd steht innerhalb eines getakteten
Prozesses:
Du beschreibst hiermit, dass gleichzeitig (innerhalb eines Taktzyklus)
led_count_x Berechnungen auf einmal durchgeführt werden. Damit kann z.B.
boundaries_x nicht in einem Blockram gespeichert werden, weil alle
Elemente davon gleichzeit benötigt werden. Und du hast einen
entsprechend große Logik, um all diese Berechnungen innerhalb eines
Taktzyklus durchführen zu können.
Sehr viel kompakter würde das, wenn du pro Taktzyklus nur einen Wert von
I betrachten würdest. Und dann mit dem Takt I von 0 bis led_count_x
(-1?) hochzählen würdest. Dann würde das ganze halt nicht einen Takt
dauern sondern led_count_x Takte.
led_count_x ist nur 18, deshalb kann es ggf. sein, dass du wirklich die
gleichzeitige, parallele Berechnung auf alle 18 Elemente anwenden
willst. Aber schau deinen Code mal kritisch nach weiteren for-Schleifen
innerhalb von Prozessen durch. Wenn die Schleife über viele Elemente
läuft (z.B. bei geschachtelten Schleifen), dann wird die erzeugte Logik
automatisch riesig.
Holger K. schrieb:> Hast du dieses gemeint?
Wahrscheinlich habe ich das gemeint (Lattice kenn' ich nicht).
Aber die müssten ja auch was aus der VHDL-Abteilung haben, oder nicht?
Holger K. schrieb:> Scheint kein EBR verwendet worden zu sein.>
Das war zu erwarten. Jetzt nochmal mit dem Fall der statischen
Konstanten, da solltest du eine EBR-Instanzierung sehen.
> Strubi schrieb:>> musst du eine>> I/O-Logik dazu basteln.>> Wie stellst du dir diese vor? bzw. was soll diese genau umsetzen?
Du musst da dem 'Standard' fuer inferierbare Memories folgen, oben hast
du ja schon die Verilog-Version zitiert.
Such dir sonst hier eins aus:
https://github.com/hackfin/MaSoCist/tree/opensource/hdl/ram
Holger K. schrieb:> Bezüglich dem RAM habe ich dieses Dokument gefunden.
Sieh dir mal die Technical Note TN1290 (bzw. den Memory Usage Guide for
MachXO3 Devices) näher an.
Achim S. schrieb:> Dieser Code in rgbanalyzer.vhd steht innerhalb eines getakteten> Prozesses:for I in 0 to led_count_x loop> if I < led_count_x then> if X_POS+1 > boundaries_x(I) and X_POS+1 < boundaries_x(I+1)> then> col <= I+1;> end if;> else> if X_POS+1 > boundaries_x(I) and X_POS+1 <> boundaries_x(led_count_x) then> col <= I+1;> end if;> end if;>> if X_POS+1 > 0 and X_POS+1 < boundaries_x(0) then> col <= 0;> end if;> end loop;>> Du beschreibst hiermit, dass gleichzeitig (innerhalb eines Taktzyklus)> led_count_x Berechnungen auf einmal durchgeführt werden. Damit kann z.B.> boundaries_x nicht in einem Blockram gespeichert werden, weil alle> Elemente davon gleichzeit benötigt werden. Und du hast einen> entsprechend große Logik, um all diese Berechnungen innerhalb eines> Taktzyklus durchführen zu können.>> Sehr viel kompakter würde das, wenn du pro Taktzyklus nur einen Wert von> I betrachten würdest. Und dann mit dem Takt I von 0 bis led_count_x> (-1?) hochzählen würdest. Dann würde das ganze halt nicht einen Takt> dauern sondern led_count_x Takte.>> led_count_x ist nur 18, deshalb kann es ggf. sein, dass du wirklich die> gleichzeitige, parallele Berechnung auf alle 18 Elemente anwenden> willst. Aber schau deinen Code mal kritisch nach weiteren for-Schleifen> innerhalb von Prozessen durch. Wenn die Schleife über viele Elemente> läuft (z.B. bei geschachtelten Schleifen), dann wird die erzeugte Logik> automatisch riesig.
Danke für deine Antwort.
Bei diesem Codeabschnitt geht es darum zu prüfen, in welchem Abschnitt
sich die aktuelle X bzw. Y-Position befindet.
Die Grenzen wurden zuvor mittels:
Denkt ihr, das dieser Code schneller ist als jener mit for?
Eigentlich erwarte ich, dass das synthese tool selbst ein ensprechendes
Konstrukt generiert.
Holger K. schrieb:> Die Grenzen wurden zuvor mittels:> ......> Definiert.> Obiger Code sollte eigentlich Konstanten generieren.
Ok. Mit "zuvor ermittelt" meinst du "zuvor während der Synthese", d.h.
die Konstanten werden bereits auf deinem PC berechnet und dann als
konstanter Wert in die Konfiguration des FPGA übernommen? Dann vergiss
meinen früheren Beitrag.
Oder meinst du mit "zuvor" etwas, was während der "Laufzeit" bestimmt
werden muss (also nicht vom PC, sondern vom FPGA)? In dem Fall bleibt es
bei meiner früheren Aussage: du generierst damit eine riesige Logik.
Holger K. schrieb:> Denkt ihr, das dieser Code schneller ist als jener mit for?
Wieso jetzt "schneller"? Ich dachte dein Problem sei, dass dein FPGA
überläuft. Geschwindigkeit und Ressourcenverbrauch sind oft
gegensätzliche Anforderungen: du kannst Ressourcen im FPGA sparen (ein
"kleineres" Design machen) wenn du bereit bist, Berechnungen nicht
parallel durchzuführen sondern - von einem Takt gesteuert -
nacheinander.
Achim S. schrieb:> Ok. Mit "zuvor ermittelt" meinst du "zuvor während der Synthese", d.h.> die Konstanten werden bereits auf deinem PC berechnet und dann als> konstanter Wert in die Konfiguration des FPGA übernommen?
Das war das Ziel bei diesem Code:
Achim S. schrieb:> Wieso jetzt "schneller"? Ich dachte dein Problem sei, dass dein FPGA> überläuft. Geschwindigkeit und Ressourcenverbrauch sind oft> gegensätzliche Anforderungen: du kannst Ressourcen im FPGA sparen (ein> "kleineres" Design machen) wenn du bereit bist, Berechnungen nicht> parallel durchzuführen sondern - von einem Takt gesteuert -> nacheinander.
Ja du hast natürlich recht. Ich meine nicht schneller. Sondern
platzsparender.
>> Denkt ihr, das dieser Code schneller ist als jener mit for?> Eigentlich erwarte ich, dass das synthese tool selbst ein ensprechendes> Konstrukt generiert.
Wenn dein Synthesetool nicht schlau genug ist herauszufinden, dass hier
nur ein Fall zutreffend sein kann, wird es möglicherweise daraus einen
Priority-Encoder bauen (ich bin gerade nicht motiviert genug, das selbst
rauszufinden).
Jedenfalls fährst Du m.E. hier mit separaten if's u.U. besser.
Danke für deine Antwort.
Habe herausgefunden, dass das Problem gar nicht in diesem Code-Abschnitt
liegt.
Das FPGA überfüllt bei der Ausgabefunktion an den SPI, da hier ebenfalls
ein 288 x 16Bit grosses register liegt.
Wenn ich nur schon diese Register hochzähle (ohne irgendwelche Pixel
analyse) eskaliert mir die Netzlistengrösse...
Mal eine Grundsätzliche Frage:
Ist ein FPGA mit diesen Eckdaten:
1
Design Summary
2
Number of registers: 14792 out of 4941 (299%)
3
PFU registers: 14792 out of 4320 (342%)
4
PIO registers: 0 out of 621 (0%)
5
Number of SLICEs: 9208 out of 2160 (426%)
6
SLICEs as Logic/ROM: 9208 out of 2160 (426%)
7
SLICEs as RAM: 0 out of 1620 (0%)
8
SLICEs as Carry: 78 out of 2160 (4%)
9
Number of LUT4s: 8789 out of 4320 (203%)
10
Number used as logic LUTs: 8633
11
Number used as distributed RAM: 0
12
Number used as ripple logic: 156
13
Number used as shift registers: 0
Aus eurer Erfahrung heraus überhaupt geeignet eine Aufgabe wie die hier
geplante umzusetzen?
Ziel ist es: Bildinhalt Pixelweise zu analysieren und dabei die
Helligkeit pro Segment zu bestimmen. Diese Information (288 x 16Bit
Wert) soll dann mittels SPI ausgegeben werden.
An sich eine banale Aufgabe aber scheinbar mit meiner jetzigen
Implementierung nicht optimal gelöst. An der Implementierung des RAMs
arbeite ich noch.
Aber denkt ihr, sowas sollte mit den obigen Ressourcen machbar sein?
Oder schiesst das total über die Ressourcen hinaus?
Holger K. schrieb:> Aber denkt ihr, sowas sollte mit den obigen Ressourcen machbar sein?
wenn das Bild selbst ins blockram passt, dann sollte der Rest deines
Designs lockerst ins FPGA passen. Mehr als ein paar Zähler, Addierer,
kleine Schieberegister, einen FIFO für's SPI und ein bisschen FSM
sollten nicht dabei herauskommen
noch eine kleine Ergänzung zu:
Achim S. schrieb:> einen FIFO für's SPI
Wenn die Reihenfolge des Datenzugriffs über SPI wahlfrei sein soll, dann
natürlich kein FIFO sondern ein Blockram. Aber es sollten eben nicht
288*16=4608 Register dafür verschwendet werden, wenn die Daten
genausogut in einem Blockram gehalten werden können.
Achim S. schrieb:> 288*16=4608 Register dafür verschwendet werden, wenn die Daten
Danke für deine Antwort.
Das macht absolut Sinn!
Achim S. schrieb:> wenn das Bild selbst ins blockram passt, dann sollte der Rest deines> Designs lockerst ins FPGA passen.
Nun, das Bild selbst möchte ich ja garnicht zwischenspeichern.
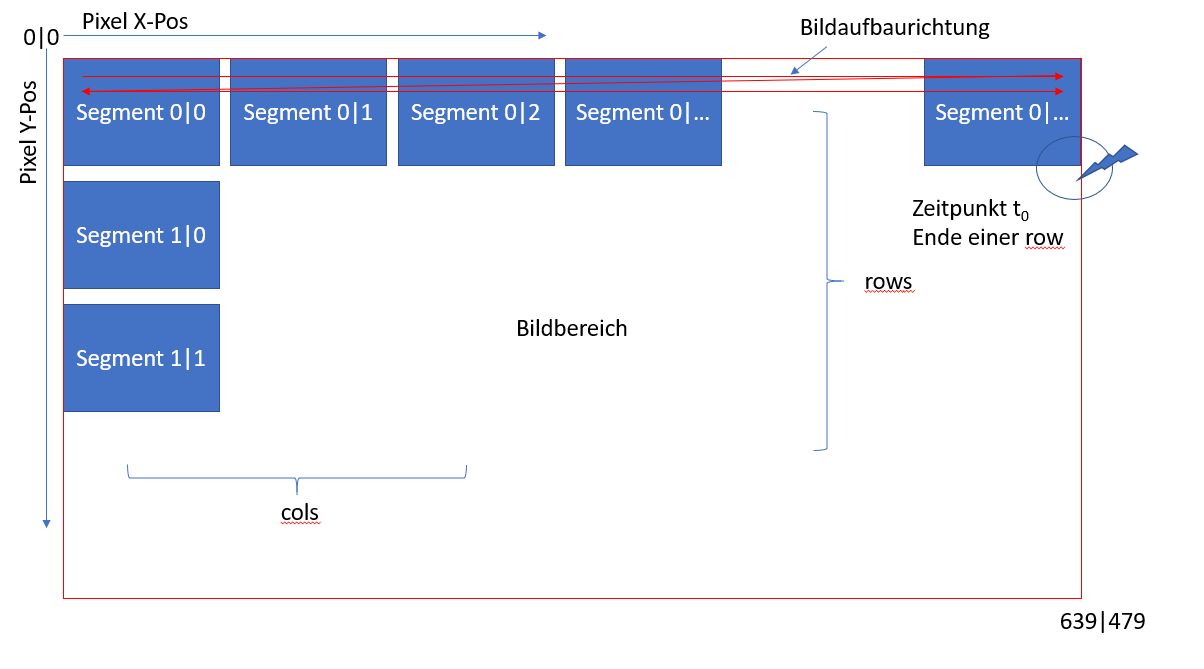
Mein Ziel ist folgendes: (siehe Bild im Anhang)
Ich Habe Zugang zum Bilddatenstrom innerhalb des FPGAs. Nun erhalte ich
synchron zum Pixelclock die Farbinformationen des aktuellen Pixels. Also
R G sowie B mit jeweils 8 bit. Nun Muss ich prüfen, in welchem Segment
sich das aktuelle Pixel gerade befindet. Aufgrund von
Kenne ich die X und Y Grenzen aller Segmente.
Mittels der bereits mehrfach beschriebenen for-loop, versuche ich zu
prüfen in welchem Segment sich das aktuelle Pixel gerade befindet.
Is nun row und col bekannt (und damit das aktuell gültige Segment) so
habe ich bisher versucht, den zuvor in diesem Segment abgespeicherte
16-Bit Wert auszulesen und mit einem, aufgrund von R G und B neu
berechnetem Wert zu vergleichen. Ist der neue Wert höher, so speichere
ich diesen ab (im Array welches aktuell eben (row x col) Werte fasst.
Dies entspricht 288 x 16-Bit Werten.
Dies mache ich solange, bis Zeitpunkt t0 eingetreten ist. Ist eine Row
zu Ende, so wird der Wert aller Rows ausgegeben!
Dies wiederholt sich nun ständig.
Mein Ansatz ist nun folgender:
Ich halte mir aktuell nur noch eine einzelne Row als Register (18 x
16-Bit Wert). Am Ende einer Row speichere ich dieses in ein DP-RAM.
Nun setz eich ein Flag welches dazu führt, dass eine andere Logik das
DP-RAM asliest und per SPI weiterleitet.
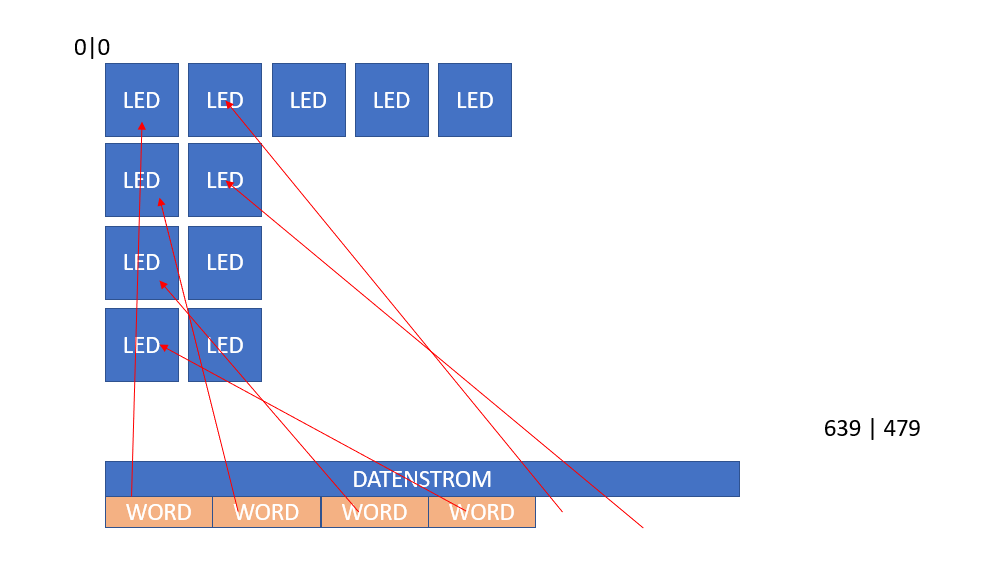
Das RAM muss demnach auch 288x16Bit Werte halten können.
Damit die Zuordnung stimmt, muss beim Auslesen aus dem RAM ein
Adressdekoder/Multiplexer aufgebaut werden.
Das RAM hätte ich als 288x16Bit organisation realisiert.
Nun muss aber jedes Word (2-Byte) in einer bestimmten Reihenfolge per
SPI gesendet werden.
Daher müsste ich eine Zuordnung ähnlich dieser Umsetzen:
Counter | RAM-Adresse
0 -> 42
1 -> 99
2 -> 128
3 -> 14
...
Könnte dies wieder zu einem enormen Ressourcenverbrauch führen?
Vielen Dank!
Holger K. schrieb:> Könnte dies wieder zu einem enormen Ressourcenverbrauch führen?
Wenn Du es so machst, wie in deinem ursprünglichen Ansatz durchaus.
Da hast Du auf alle Elemente deines "RAM-Arrays" in einem Takt
gleichzeitig zugegriffen. Und ein RAM, dass das kann, gibt's natürlich
nicht.
Holger K. schrieb:> Aufgrund von> genboundsX :> for I in 0 to led_count_x generate> boundaries_x(I) <= ((display_width) / (led_count_x + 1)) * (I+1);> end generate;>> genboundsY :> for I in 0 to led_count_y generate> boundaries_y(I) <= ((display_heigth) / (led_count_y + 1)) * (I+1);> end generate;>> Kenne ich die X und Y Grenzen aller Segmente.>> Mittels der bereits mehrfach beschriebenen for-loop, versuche ich zu> prüfen in welchem Segment sich das aktuelle Pixel gerade befindet.
Ich bin immer noch ein wenig irritert davon, dass du hier Konstanten
anlegen willst und dafür ein Generate verwendest (damit instanziere ich
üblicherweise Logikblöcke). Wenn Boundaries(i) tastächlich Konstanten
sind würde ich sie normalerweise auch als constant deklarieren und in
einem Package ablegen. Dann wüsste ich, dass dafür keine Logik erzeugt
wird.
Holger K. schrieb:> Das RAM muss demnach auch 288x16Bit Werte halten können.> Damit die Zuordnung stimmt, muss beim Auslesen aus dem RAM ein> Adressdekoder/Multiplexer aufgebaut werden.
Jedes Blockram hat schon einen Adressdekoder. Achte einfach darauf, dass
du keine künstlich verkomplizierte Abbildung zwischen RAM-Adresse und
Segmentadresse hast. Einfach wäre z.B.: wenn du 12 Columns von Segmenten
hast, dann nutze einfach den Column-Index als untere 4 Adressbits des
RAMs. Wenn du 24 Rows von Segmenten hast, dann nutze den Row-Index als
nächst höherwertie 5 Adressbits des RAMs. Damit kannst du ohne große
Rechnerei und zusätzliche Adressdekodierung von Row und Column auf
RAM-Adresse umrechnen (und umgekehrt). Wenn die Größe eines Segments in
x- und y-Richtugn beliebig variieren kann, dann wird es natürlich etwas
komplizierter.
Holger K. schrieb:> Ich Habe Zugang zum Bilddatenstrom innerhalb des FPGAs. Nun erhalte ich> synchron zum Pixelclock die Farbinformationen des aktuellen Pixels.
Sind alle deine Segmente gleich groß? Dann wäre mein Ansatz
- beim Start eines neuen Bilds im Bilddatenstrom setzt du rowcount,
colcount, linecount und Pixelcount auf 0
- bei jedem neuen Pixel setzt du Pixelcount ein hoch
- wenn Pixelcount dabei über die Breite eines Segments wächst, dann
setzt du Pixelcount wieder auf 0 und inkrementierst Colcount um 1
- wenn Colcount dabei über die Grenze des Bildschirms wächst, dann setzt
du colcount auf 0 und erhöhst linecount um 1
- wenn linecount dabei über die y-Grenze eines Segmenst wächst dann
setzt du linecount auf 0 und erhöhst rowcount um 1.
In rowcount und colcount steht dann jeweils, in welchem Segment du dich
befindest. Und wenn du Rowcount und Colcount concatenierst, kannst du
eine einfache RAM-Adresse daraus bauen.
Markus F. schrieb:> Holger K. schrieb:>> Könnte dies wieder zu einem enormen Ressourcenverbrauch führen?>> Wenn Du es so machst, wie in deinem ursprünglichen Ansatz durchaus.>> Da hast Du auf alle Elemente deines "RAM-Arrays" in einem Takt> gleichzeitig zugegriffen. Und ein RAM, dass das kann, gibt's natürlich> nicht.
Nein, in diesem Beispiel geht es lediglich darum, die Adressen des RAMs
mit einer Lookuptable zu generieren.
Achim S. schrieb:> Sind alle deine Segmente gleich groß? Dann wäre mein Ansatz> - beim Start eines neuen Bilds im Bilddatenstrom setzt du rowcount,> colcount, linecount und Pixelcount auf 0
Vielen Dank für deine Antwort.
Das finde ich einen sehr guten Ansatz!
Ja, die Segmente sind identisch.
Leider löst es das Problem der Ram-Zuordnung nicht direkt.
Da, die Zuordnung im SPI-Datenstrom nicht analog zur Segment zuordnung
ist.
Daher komme ich nicht um ein Mapping mittels LUT herum. Zumindest nicht
aus meiner Sicht.
Daher, eine LUT mit 288 Einträgen.
Du kannst für den Synthese mal den XO3-9400 einstellen und schauen, ob
es dort passen würde.
Ansonsten hätte ich eine Bingröße von 8 oder 16, o.ä. gewählt. Da kann
man direkt die MSBs von rowcount für die Andressierung verwenden.
Duke
Holger K. schrieb:> Leider löst es das Problem der Ram-Zuordnung nicht direkt.> Da, die Zuordnung im SPI-Datenstrom nicht analog zur Segment zuordnung> ist.
Ich verstehe nicht, wieso. An welcher konkreten Adresse im RAM die Info
steht kann dir doch eigentlich egal sein. Warum brauchst du unbedingt
eine komplizierte Zuordnung von Segment zu RAM-Adresse, wenn eine
einfache, eindeutige Zuordnung auch möglich ist (also z.B. das
concatenieren von rowcount und colcount zu Ramadress).
Besteht dein Controller am anderen Ende des SPI auf einer bestimmten
Adressübersetzung? Dann soll er doch die Umrechnung machen...
Holger K. schrieb:> Daher, eine LUT mit 288 Einträgen.
Wenn du wirklich denkst, dass das unbedingt sein muss (ich glaub ja
immer noch nicht dran), dann pack es halt auch in einen RAM-Block rein.
Wie Markus schon geschrieben hat: achte darauf, dass du nicht
versehentlich alle Einträge der LUT gleichzeitig schreiben oder abfragen
willst sondern immer nur einen pro Taktzyklus.
Achim S. schrieb:> Ich verstehe nicht, wieso. An welcher konkreten Adresse im RAM die Info> steht kann dir doch eigentlich egal sein. Warum brauchst du unbedingt> eine komplizierte Zuordnung von Segment zu RAM-Adresse, wenn eine> einfache, eindeutige Zuordnung auch möglich ist (also z.B. das> concatenieren von rowcount und colcount zu Ramadress).
Der Grund ist, dass am SPI sechs mal folgender Baustein hängt:
http://www.ti.com/lit/ds/symlink/tlc5955.pdf
Dieser hat die LEDs nicht so vedrahtet wie die Segmente angeordnet sind.
(natürlich befinden sich die LEDs physikalisch in der gleichen Anordnung
auf dem Board aber eben nicht in der gleichen Reihenfolge verdrahtet...)
Die Chips sind in einer DaisyChain. Damit am Ende jedes Physische
Segment (LED) den richtigen Wert aus dem RAM des FPGAs erhält. muss ich
diese in der richtigen Reihenfolge am SPI ausgeben.
Daher die unschöne LUT für die Adressen des RAMs.
Ich möchte beim Ausgeben der 6 x 96 Bytes per SPI ja einen Counter
hochzählen.
Quasi:
while(i != 96)...
Wenn i nun 0 ist, dann muss ich aus dem RAM den richtigen Wert für die
entsprechende Position innerhalb des SPI-Streams auslesen.
Holger K. schrieb:>>>> Der Grund ist, dass am SPI sechs mal folgender Baustein hängt:
OK, das lass ich als Grund gelten. dann halt tatsächlich noch ein
Blockram in dem gespeichert ist, in welcher Reihenfolge die
Helligkeitswerte aus dem Haupt-RAM abgeholt werden und zum SPI Modul
geliefert werden