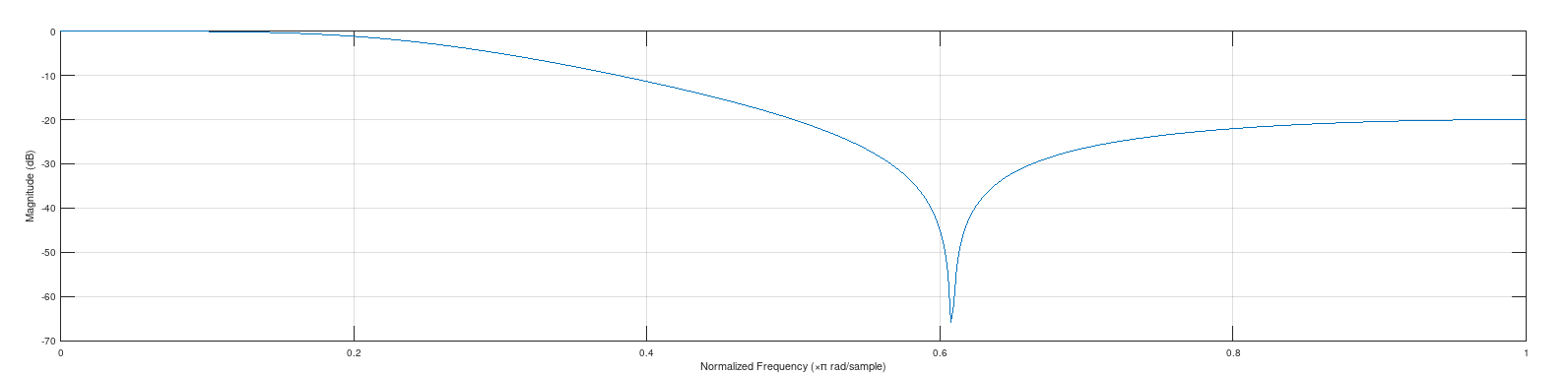
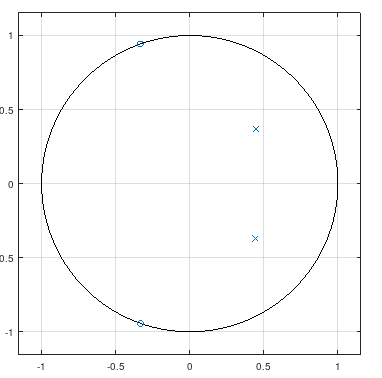
Guten Tag, ich spiele gerade etwas mit der CMSIS DSP Library des Cortex-M4 herum. Ich habe ein Biquadfilter mit folgenden Koeffizienten: Zählerpolynom: b0 = 0.16667 b1 = 0.11111 b2 = 0.16667 Nennerpolynom: a0 = 1 a1 = -0.88889 a2 = 0.33333 Laut Octave sind die Nullstellen dafür: -0.33333 + 0.94281i -0.33333 - 0.94281i und die Polstellen: 0.44444 - 0.36851i 0.44444 + 0.36851i Die Polstellen liegen also schön weit im Einheitskreis der z-Ebene. Den Frequenzgang und den Pol-Nullstellenplot habe ich angehängt. Ich habe nun die Filterkoeffizienten, wie oben angegeben in meinen Mikrocontroller gehackt und das Ganze laufen lassen. NAch einigen Tausend Samples, läuft allerdings das Filter komplett weg und schlägt an die +/- inf Grenze der 32bit floating point Zahlen. Der Eingangswert ist eine Floating Point Zahl die aktuell relativ konstant ist. Wert: 3050 (+- Rauschen von 10). Das Filter selbst ist mir nicht so wichtig. Das war nur zum Testen. Allerdings verstehe ich nicht, warum das Filter sich sofort ins Nirvana schwingt. Die Polstellen sollten soweit vom Einheitskreis entfernt liegen, dass selbst die Floating-Point Quantisierung das hier nicht nennenswert beeinflusst, oder? Es wäre nett, wenn mir jemand sagen kann, warum das Ganze nicht stabil ist. Ich habe mit der praktischen Auslegung von Filtern keine/kaum praktische Erfahrungen. Habt ihr noch praktische Tipps, wie ich beispielsweise mit Octave ein stabiles IIR Filter erzeugen kann? Mein Ansatz ist da: 1) Mit entsprechenden Funktionen, bspw: butter(...) ein Filter zu erstellen 2) mit zf2sos das Ganze in eine Kaskade aus Biquad-Filtern umbauen. Allerdings habe ich damit bisher wenig Erfolg :)
Angehängte Dateien:
-

freqz.png
7 KB -

zplane.png
2,7 KB
Das Problem liegt bestimmt nicht an den Filterkoeffizienten. Vielleicht hast du einen Fehler bei der Umsetzung der Filterkoeffizienten in die Software gemacht oder du schickst ab und zu falsche Zahlen in das Filter.
Hallo, vielen Dank für deine Antwort. Ich nutze den "fertigen Code" von ARM, den sie in einer Library zur Verfügung stellen. https://www.keil.com/pack/doc/CMSIS/DSP/html/group__BiquadCascadeDF1.html#ga812eb9769adde4fed6d5ff4968a011d3 Ich habe mich noch nicht daran gemacht, das selbst zu coden, da ich dachte, die Library wird das schon optimierter machen, als ich. Werde es aber morgen gleich versuchen. Ich habe hier noch folgendes gelesen: Dergute W. schrieb: > Allgemein wird's unangenehmer (=muss genauer gerechnet werden), wenn > Pole oder Nullstellen des Filters in der Naehe des Einheitskreises sind. Mein Stand war bisher, dass die Nullstellen für die Stabilität unkritisch sind. Meine liegen direkt auf dem Einheitskreis. Kann das ein Problem sein? Vielen Dank Edit: ich habe zum Test das Filter durch ein Moving average filter mit b0 = 0.1 b1 = b2 = 0 a0 = 1 a1 = 0.9 a2 = 0 ausgetauscht. Das läuft wie erwartet und mittelt munter den Eingangswert. Die Funktion scheint also zu funktionieren. Werde es trotzdem mal händisch nachcoden.
In dem Link steht
Some design tools use the difference equation
y[n] = b0 * x[n] + b1 * x[n-1] + b2 * x[n-2] - a1 * y[n-1] - a2 *
y[n-2]
Probier es mal mit umgekehrtem Vorzeichen für a1 und a2.
Moin, M. H. schrieb: > Mein Stand war bisher, dass die Nullstellen für die Stabilität > unkritisch sind. Meine liegen direkt auf dem Einheitskreis. Wuerde mich auch wundern, wenn die Nullstellen fuer die Stabilitaet ein Problem waeren. Was problematisch werden koennte, waere die Sperrdaempfung in der Umgebung der Nullstellen, wenn die eben durch irgendwelche Rundungs/Rechenfehler nicht genau auf'm Einheitskreis liegen, sondern etwas daneben. Dann ist da halt die Daempfung nur noch "hoch", nicht mehr unendlich. Gruss WK
Helmut S. schrieb: > In dem Link steht > > Some design tools use the difference equation > y[n] = b0 * x[n] + b1 * x[n-1] + b2 * x[n-2] - a1 * y[n-1] - a2 * > y[n-2] > > Probier es mal mit umgekehrtem Vorzeichen für a1 und a2. Glaube ich auch. Die lib wird von umgedrehten Vorzeichen der a's ausgehen. Komisch ist allerdings, dass das Ding nach einigen Tausend samples explodiert. Das sollte eigentlich schneller gehen. Cheers Detlef
Detlef _. schrieb: > Helmut S. schrieb: >> In dem Link steht >> >> Some design tools use the difference equation >> y[n] = b0 * x[n] + b1 * x[n-1] + b2 * x[n-2] - a1 * y[n-1] - a2 * >> y[n-2] >> >> Probier es mal mit umgekehrtem Vorzeichen für a1 und a2. > > Glaube ich auch. Die lib wird von umgedrehten Vorzeichen der a's > ausgehen. Komisch ist allerdings, dass das Ding nach einigen Tausend > samples explodiert. Das sollte eigentlich schneller gehen. > > Cheers > Detlef Mit fällt da noch etwas anderes ein. Falls du C++ verwendest: Legst du eventuell das Biquad-Objekt vor jedem Aufruf neu an und dir geht am Ende der Speicher aus?
Detlef _. schrieb: > Glaube ich auch. Die lib wird von umgedrehten Vorzeichen der a's > ausgehen. Tut sie nicht. Der Hinweis gilt dafür, dass manche Design-Tools das invertiert ausgeben. Mein Moving average Filter M. H. schrieb: > ich habe zum Test das Filter durch ein Moving average filter mit > b0 = 0.1 > b1 = b2 = 0 > > a0 = 1 > a1 = 0.9 > a2 = 0 > > ausgetauscht. hätte sonst auch nicht getan. Helmut S. schrieb: > Falls du C++ verwendest Reines C. Mit aktivierter FPU
Habs gerade mal mit single float Koeffizienten in ML durchgerechnet, RMSE < 2 Promille bei nem Eingangssignal von 3050+randn(10000,1). Also wie erwartet liegt es nicht an der Quantisierung. Zeig mal bitte den Code, bisher hat die CMSIS Implementierung keine Probleme gemacht. Welche Version ist das? Da es der M4 ist, gibt's da noch irgendwelche Probleme mit der FPU oder so? Ggf. mal hardfloat ausschalten.
habe den Code gestern rausgemüllt. Müsste es nochmal nachcoden. Auf jeden Fall gut, dass du es mal nachprobiert hast. Ich schreibe gerade ien kleines C-Programm auf dem PC, was das auch mal testen soll. Mit der CMSIS Lib habe ich auch das Problem gehabt, dass ich eigentlich ein Festkomma Filter wollte, die Funktionen aber immer gehardfaultet sind. Kann schon sein, dass mein Kompilat da sehr verbuggt ist. habe die .a-Datei aus einem relativ alten projekt und schleife sie seitdem herum. Ich mache mich daran, dass Problem minimal auf dem STM nachzustellen.
Also: Ich habe das Ganze nun auf dem PC implementiert. Ergebnis: Es läuft, genau wie auf dem uC, nach einigen 100 Takten weg. Habe das Programm angehängt. Wäre nett, wenn mir jemand sagen kann, wo ich den Fehler eingebaut habe. Die ersten paar Ausgangswerte:
1 | 0,508.252289 |
2 | 1,395.463257 |
3 | 2,1173.332886 |
4 | 3,444.518494 |
5 | 4,1351.419434 |
6 | 5,302.570648 |
7 | 6,1536.957031 |
8 | 7,90.332680 |
9 | 8,1787.458496 |
10 | 9,-203.080811 |
11 | 10,2131.770508 |
12 | 11,-606.939880 |
13 | 12,2605.526367 |
14 | 13,-1162.675049 |
15 | 14,3257.430664 |
Nach 522 Samples oszilliert der Ausgang nur noch zwischen -inf und +inf. Edit: Habe das Ganze nochmal mit double als Zahlenformat implementiert. Da läuft das Filter auch weg.
Also. Habe das Ganze nun gelöst. Das Problem ist meine Dummheit. Ich habe das Ganze jetzt nochmals auf Papier ausgekaspert. Natürlich muss bei einer Funktion
die Differenzengleichung
lauten. Also war es doch das mit dem Vorzeichen der Filterkoeffizienten. Habe mich von der beschreibung in der CMSIS Library komplett verwirren lassen. Damit ist die Sache dann wohl gelöst. Vielen Dank an euch.
Angehängte Dateien:
-

floatVsDouble.png
5 KB
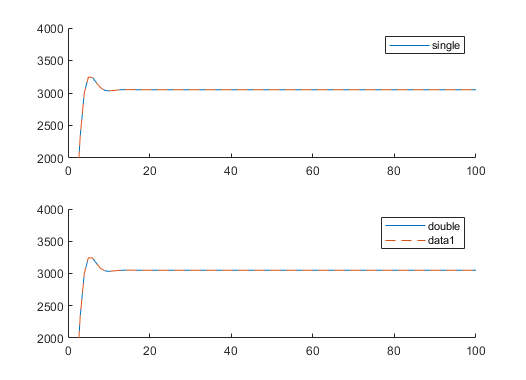
Hab deinen Code in ML getestet. Deine Vorzeichen sind falsch, siehe https://en.wikipedia.org/wiki/Digital_biquad_filter. Anbei ein Plot, oben single vs Referenz, unten double. Geht beides :) Code (sorry, quick + dirty)
1 | clear mex, mex CFilter.c -R2018a, |
2 | b = [.16667 .11111 .16667]; a = [1 -.88889 .33333]; |
3 | % f = dfilt.df1(b,a) % für fvtool, braucht signal processing tb |
4 | ff = filter(b,a,3050.453*ones(1000,1)); |
5 | [cf1, cf2] = CFilter; |
6 | |
7 | figure, subplot(211), hold all, |
8 | plot(cf1), plot(ff,'--'), |
9 | ylim([2000 4000]), |
10 | legend('single')
|
11 | |
12 | subplot(212),hold all, |
13 | plot(cf2), |
14 | plot(ff,'--'), |
15 | legend('double'),
|
16 | ylim([2000 4000]) |
edit: Kacke, zu lahm :D
>>>>>>>>>>>> > Probier es mal mit umgekehrtem Vorzeichen für a1 und a2. Glaube ich auch. Die lib wird von umgedrehten Vorzeichen der a's ausgehen. <<<<<<<<<<<<<< Yo. :))))))))) Cheers Detlef
Und was soll Floatingpoint dabei ? Welches Verhaeltnis von der groessten und kleinsten Zahl benoetigst du ? Welches ist der dynamische Bereich ? Der Witz daran : Float32 hat 6 signifikante dezimalstellen bedeutet : 20'000'000 - 1 = 20'000'000 waehrend Int32 9 signifikannt stellen hat : 2'000'000'000 - 1 = 1'999'999'999 Einfach float zu nehmen ist unguenstig.
>>>> Einfach float zu nehmen ist unguenstig. Kann man so nicht sagen. Das hängt wie immer davon ab. Wenn ich mich um den Wertebereich in dem mein Ergebnis liegt nicht kümmern will/kann nehme ich float. Es wird schon irgendwie in -/+ 10^38 liegen. Wenn es rauschmässig auf die Rundungsfehler ankommt muss ich integer nehmen und sicher sein, dass kein Overflow auftritt. Die Genauigkeit ist dann besser. Früher war Signalverarbeitung mit floats nogo, inzwischen kann der STM32 das schneller als integer. Cheers Detlef
Detlef _. schrieb: > Früher war Signalverarbeitung mit floats nogo, inzwischen kann der STM32 > das schneller als integer. Warum sollte das so gewesen sein? Wenn man die Randbedingungen zu Rundung und Auflösung beachtet (was man in beiden Fällen muss!) ist das nie ein Problem. Man muss nur binomische Formeln kennen um die Rechnungen aufzu spalten und das machen LIBs.
>Detlef _. schrieb: >> Früher war Signalverarbeitung mit floats nogo, inzwischen kann der STM32 >> das schneller als integer. Das glaube ich nicht. Wie viele Taktzyklen braucht eine Integer-Additon im Vergleich zur Float-Addition inclusive laden der Register auf dem STM?
Christoph M. schrieb: > Das glaube ich nicht. Wie viele Taktzyklen braucht eine Integer-Additon > im Vergleich zur Float-Addition inclusive laden der Register auf dem > STM? Die Registerbank der FPU ist single cycle angebunden. Allerdings können diese Register nicht direkt mit RAM Werten geladen werden. Sprich, man benötigt einen mov mehr, um die Daten in FPU Register zu bekommen. Für eine Addition (2 Werte aus RAM laden + 1 Wert in RAM abspeichern), werden also 3 zusätzliche Zyklen benötigt. Bei größeren hyperskalaren Cores, wird das untergehen. Die Addition benötigt in beiden Fällen einen Zyklus, siehe Instruction set summary der FPU Instruktionen [1]. Das Ganze ist allerdings eine Milchmädchenrechnung, da dort durch Compileroptimierung bzw. auch selektiv selbst geschriebene Assemblerroutinen massiv optimiert werden kann. Meine Erfahrung ist allerdings, dass sich GCC manchmal nicht besonders intelligent anstellt und teilweise Werte von A nach B nach C und wieder nach A schiebt und so Performance verbrennt. Wem es richtig auf Performance ankommt, kann sich seine Biquadstrukturen effizient in Assemblerroutinen gießen. Der Cortex M4 besitzt zumindest das Instruktion-Set, um solche Dinge auch effizient abzuarbeiten. Die CMSIS DSP-Lib lässt dort leider auch teilweise zu wünschen übrig. [1] https://developer.arm.com/documentation/100166/0001/Floating-Point-Unit/FPU-functional-description/FPU-instruction-set-table?lang=en
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.