Guten Abend,
ich habe hier ein seltsames Problem mit meinem Ringbuffer, nämlich
"verschieben" sich bei mir die beiden Statusvariablen m_freeSpace und
m_UnreadChars, die aber immer im Wechsel erhöht, bzw. verringert werden,
d.h. die Summe der beiden sollte immer gleich der Puffergröße sein, was
aber nicht der Fall ist.
Natürlich tritt der Fehler nicht bei jedem Aufruf auf, sondern in
unregelmäßigen Abständen, aus denen ich bisher kein Muster erkennen
konnte.
Im folgenden meine Lese- und Schreibroutinen (der komplette Code des
Buffers befindet sich im Anhang):
dienen nur zu Debugzwecken und sorgen dafür, dass der Buffer wenigstens
so halbwegs funktioniert. So bleiben soll das natürlich nicht.
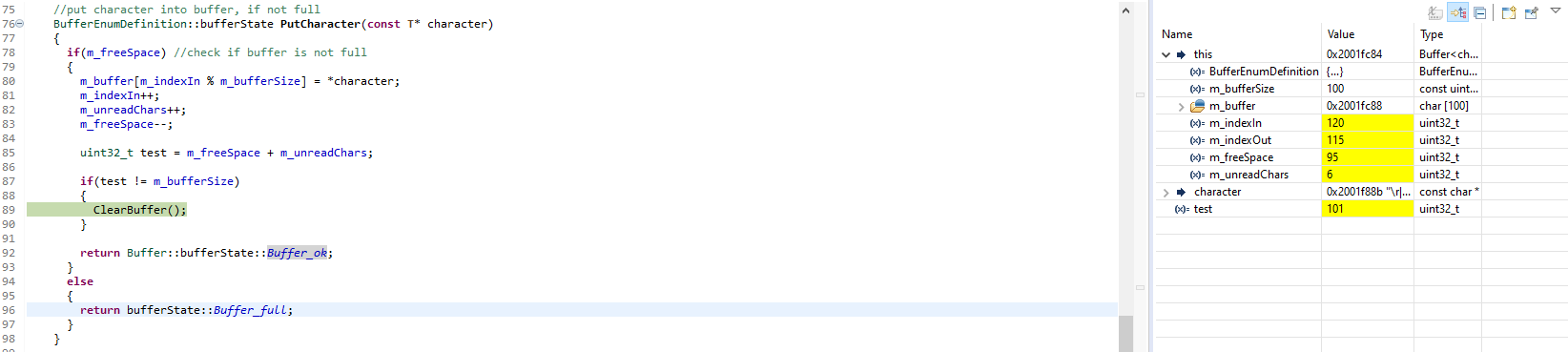
Im angehängten Screenshot sieht man, was im Problemfall vorliegt,
nämlich ist hier die Summe größer als die Puffergröße von 100 geworden.
Ein (natürlich auch nur manchmal) auftretender Effekt ist auch, dass die
Variable "test" aus der PutCharacter-Methode manchmal den Wert 101 hat,
aber dafür bei m_freeSpace und m_unreadChars in der Debugansicht aber
trotzdem die Summe stimmt.
Die Bufferfunktionen werden innerhalb meiner Uart-Klasse verwendet und
dann in den Sende- und Empfangsinterrupts verwendet.
Meine Vermutung ist, dass irgendwelche Interrupts dazwischenhauen und
dadurch Inkremente/Dekremente verloren gehen. Das kann ich mir aber so
nicht vorstellen, denn eigentlich sollte der Compiler vor dem Sprung in
eine (andere!) ISR verhindern, dass derartige Daten verloren gehen?
Ich programmiere übrigens mit der STM32CubeIDE auf einem STM32F446.
Vielen Dank schonmal
Karsten
PS: Natürlich hätte man die eine oder andere Statusvariable einsparen
können und es gibt bestimmt noch andere Baustellen in meinem Code (ich
mache noch nicht lange C++), es geht mir aber hier auch sehr darum, zu
verstehen was da schief läuft, damit ich an anderer Stelle nicht wieder
Probleme bekomme.
Ich nehme mal an, eine der beiden Routinen wird aus dem ISR-Kontext
aufgerufen, die andere vom Applikationsteil.
Was Du hier hast, ist eine race condition. Wenn der Applikationsteil
hier das macht:
1
m_unreadChars--;
2
m_freeSpace++;
und wenn nun ein Interrupt passiert (also nach dem Lesen der Variable,
aber bevor sie wieder zurückgeschrieben wird), dann wird parallel das
hier gemacht:
[quote]m_unreadChars++;
m_freeSpace--;[/quote]
Und das führt zu Inkonsistenzen.
Lösung: lösche diese beiden überflüssigen Variablen. Ein Ringbuffer
braucht nur den Lese- und Schreibindex. Dann wird eine der Variablen nur
in der Get-Routine aus dem Applikationskontext her verändert, die andere
nur in der Put-Routine aus dem Interruptkontext.
Sobald Du Variablen hast, die in beiden Teilen geändert werden können,
mußt Du ein Lock einführen. Hieße konkret, in der Get-Routine den
RX-Interrupt temporär sperren. Das ist aber häßlich und unnötig, und
könnte zu verpaßten Zeichen führen.
Karsten D. schrieb:> es geht mir aber hier auch sehr darum, zu> verstehen was da schief läuft, damit ich an anderer Stelle nicht wieder> Probleme bekomme.
Nochwas. Ich weiß nicht, wie weit Du mit C/C++ bist, aber wichtig zum
Verständnis ist Folgendes. So eine Quelltextzeile...
1
a++;
... wird auf Maschinenebene zu drei Befehlen umgesetzt:
1) lade a aus dem RAM in Register Rx
2) incrementiere Register Rx
3) schreibe Rx ins RAM an die Stelle a zurück
Ein Interrupt kann zwischen 1) und 2) oder zwischen 2) und 3) passieren.
Was dann passiert ist etwa so:
1) Applikation lädt a aus dem RAM in Register Rx
2) Applikation inkrementiert Register Rx
3) Interrupt passiert, Register werden automatisch gesichert
4) Interrupt lädt a aus dem RAM in Register Rx
5) Interrupt dekrementiert Rx
6) Interrupt schreibt Rx ins RAM an Stelle a zurück
7) Interrupt endet, Register werden wieder zurückkopiert
8) Applikation schreibt Rx an Stelle a zurück - und das ist der Wert von
bevor der Interrupt kam!
In Summe hat die Applikation den Wert um eins erhöht und der Interrupt
um eins vermindert, also erwartest Du, daß sich das ausgleicht. Tut es
aber nicht, wegen Schritt 8), sondern der Wert am Ende des Ablaufs ist
um eins höher!
Das passiert natürlich nicht immer, sondern nur, wenn der Interrupt so
ungünstig im Zeitablauf passiert. Deswegen tritt der Effekt bei Dir nur
manchmal auf.
Ergänzend zu den guten Antworten oben hier ein paar Begriffe zum
Googeln, scheint ja als wolltest du was lernen :)
Das Ganze heißt read-modify-Write und tritt bei ARM Chips (und bei
anderen ggf auch) immer auf, wenn sie eine sogenannte load-Store
Architektur haben, d.h. die Chips müssen ein Datum erst in ein Register
laden, es dann modifizieren und dann zurück schreiben. Z.b., wenn eben
counter inkrementiert werden. Oder aber auch bei sonstigen
arithmetischen Operationen.
Wie das bei anderen Architekturen ist kann ich dir allerdings nicht
sagen, ggf. existiert ein Befehl, das Inkrement ununterbrechbar zu
machen oder so. Denke aber grundsätzlich besteht das Problem da auch.
Auch wenn in deinem Fall es ausreicht, zu überlegen, wer lesen und er
schreiben darf und die Counter wegzumachen, gibt es Situationen wo das
nicht geht. Dann musst du entweder interrupts sperren (aka eine
„critical section“ erstellen), oder spezielle Befehle benutzen. Bei
vielen ARM gibt es Befehle, die zumindest sicherstellen, dass eine
Variable zwischen dem load und dem Store nicht durch einen anderen
Kontext geändert worden ist. D.h., der genannte read-modify-Write Ablauf
besteht nach wie vor, man weiß aber, ob etwas dazwischen gefunkt hat und
kann dann ggf die Operation wiederholen. Wieder was zum googeln, der
Befehl heißt ldrex.
Schöne Grüße
Jan
Jan schrieb:> Wie das bei anderen Architekturen ist kann ich dir allerdings nicht> sagen, ggf. existiert ein Befehl, das Inkrement ununterbrechbar zu> machen oder so. Denke aber grundsätzlich besteht das Problem da auch.
Nicht überall. Bei den kleinen PIC's z.B. nicht, denn die können mit
einem einzigen Maschinenbefehl direkt Daten im RAM in- und
dekrementieren. Ohne da irgendwas laden und speichern zu müssen.
Obendrein können die, falls das gebraucht wird, auch noch dabei einen
Test auf 0 machen.
Aber all das ist bei einem gewöhnlichen Ringpuffer überhaupt nicht
erforderlich. Da braucht es tatsächlich nur zwei Indizes in den Puffer -
und jede der zwei über den Puffer kommuniziernden Instanzen verwaltet
nur einen davon. D.H. nur sie darf ihren index schreiben. Lesen dürfen
beide.
z.B. Test auf leer:
if (inzgr==outzgr)
{Ringpuffer ist leer}
else
{Ringpuffer ist nicht leer}
Der Test ob voll ist etwas umfänglicher.
int i;
i = inzgr+1;
if (i>=puffergröße) i -= puffergröße;
if (i==outzgr) { Ringpuffer ist voll}
W.S.
Ergänzend zu den Interrupt-Hinweisen: das Konstrukt "buffer[index %
size]" bereitet beim Überlauf von index Schwierigkeiten, wenn size
keine 2er-Potenz ist.
foobar schrieb:> Ergänzend zu den Interrupt-Hinweisen: das Konstrukt "buffer[index> %> size]" bereitet beim Überlauf von index Schwierigkeiten, wenn size> keine 2er-Potenz ist
... die da waeren?
Ich denke, du verwechselst das jetzt mit '& (size-1)'.
leo
> ... die da waeren?
Beim Overflow macht der Zähler einen Sprung und überspringt Elemente.
Z.B. index 8-bit, size=10: 250%10 = 0, ..., 255%10 = 5, 0%10 = 0 upps.
Guten Morgen,
Erstmal vielen Dank für eure Hilfe!
Ich habe meine Implementierung jetzt entsprechend euren Vorschlägen
angepasst und - Überasschung! - wenn man es richtig macht, funktioniert
es auch :)
Die Problematik mit den atomaren Zugriffen usw. kannte ich, aber ich
habe vor lauter Bäumen den Wald nicht gesehen, dass put von der
Applikation aufgerufen wird, während die ISR mittels get schon fleißig
Daten rausschaufelt.
Wieder was gelernt, mal sehen, ob ich mich daran erinnere, wenn ich das
nächste Mal in so etwas hineinlaufe...
Ich habe mir übrigens das Disasembly mal angesehen, der Compiler macht
aus m_indexIn++ sogar 5 Instruktionen!
1
77 m_indexIn++;
2
0800530e: ldr r3, [r7, #4]
3
08005310: ldr r3, [r3, #104] ; 0x68
4
08005312: adds r2, r3, #1
5
08005314: ldr r3, [r7, #4]
6
08005316: str r2, [r3, #104] ; 0x68
(Oder ich bin zu doof das zu lesen, ARM-Assembler kann ich nicht)
Dafür komme ich ursprünglich vom PIC16/PIC18, der DECFSNZ-Befehl ist
wirklich praktisch, um Schleifen zu bauen (Decrement, skip if not zero).
foobar schrieb:> Beim Overflow macht der Zähler einen Sprung und überspringt Elemente.>> Z.B. index 8-bit, size=10: 250%10 = 0, ..., 255%10 = 5, 0%10 = 0 upps.
Aber wie geht man denn jetzt damit um?
Ich habe es jetzt erstmal mit einem if gelöst, um dann die Zähler
explizit zu nullen, geht das auch schöner (wenn man keine 2er-Potenzen
als Puffergröße verwendet)?
Viele Grüße
Karsten
Karsten D. schrieb:> Ich habe mir übrigens das Disasembly mal angesehen, der Compiler macht> aus m_indexIn++ sogar 5 Instruktionen! 77 m_indexIn++;> (Oder ich bin zu doof das zu lesen, ARM-Assembler kann ich nicht)
Nö, das passt schon, ist halt ARM! (ARM = Advanced RISC Machine).
> 0800530e: ldr r3, [r7, #4]
Pointer Register r3 laden
> 08005310: ldr r3, [r3, #104] ; 0x68
Wert über Pointerregister und Offset #104 laden
> 08005312: adds r2, r3, #1
Wert incrementieren
> 08005314: ldr r3, [r7, #4]
Nochmal Pointer laden (warum, der ist doch schon geladen?)
> 08005316: str r2, [r3, #104] ; 0x68
Wert über Pointer und Offset speichern.
Naja, zumindest der vorletzte Befehlt ist überflüssig. Hast du die
Optimierung im Compiler eingeschaltet?
Man sollte auch nicht ALLES in der FIFO-Stuktur als volatile deklarieren
und auch nur die minimal notwenigen Zugriffe atomar durchführen.
Das Ganze ist ja ein Template und die Fifo Elemente können auch größer
werden. Wenn dann doch mit Locking gearbeitet werden muss, ist es
günstiger erst die Zeiger zu setzen (unter lock), und dann den
Datenpuffer zu bearbeiten (ohne lock). Das spart Blockierungszeit.
leo schrieb:> ... die da waeren?
Ein schlichtes Maskieren mit UND ist einfach, ein Einschränken mit
MODULO bedarf einer Division und Verwenden des Restes. Ist eben
aufwendiger.
W.S.
foobar schrieb:> Beim Overflow macht der Zähler einen Sprung und überspringt Elemente.
Das kommt davon, wenn man sich beim Programmieren auf so etwas wie das
Verhalten bei einem Overflow verlässt (Pfusch) und hat nichts mit Modulo
zu tun.
MfG Klaus
W.S. schrieb:> Ein schlichtes Maskieren mit UND ist einfach,
Machst du das in Python oder bei Excel Macros auch so? Und wenn die
Sprache intern nur Floating Point verwendet?
MfG Klaus
Klaus schrieb:> Machst du das..
Ich verwende weder Python noch Excel.
Und hier geht es um eine Low-Level-Treiber-Angelegenheit in einem µC und
nicht um die Jahresbilanz der Firma.
Ich habe es schon SO OFT gesagt, daß es falsch ist, immerzu nur all die
Verhältnisse, die man am PC hat, einfach so 1:1 auf die Welt der
Mikrocontroller zu übertagen.
Demnächst fragt dann jemand wie du, wo denn malloc auf dem PIC16F711 ist
oder wie man die bash auf einem Padauk-µC aufruft.
W.S.
foobar schrieb:> Beim Overflow macht der Zähler einen Sprung und überspringt Elemente.>> Z.B. index 8-bit, size=10: 250%10 = 0, ..., 255%10 = 5, 0%10 = 0 upps.
Ach so, du darfst natuerlich nicht einfach weiterzaehlen und in den
Overflow kommen.
W.S. schrieb:> Und hier geht es um eine Low-Level-Treiber-Angelegenheit in> einem µC und nicht um die Jahresbilanz der Firma.
Auf einem µC, der mehr Bums unter der Haube hat, als die ersten PCs oder
CPM-Rechner, auf denen kleine Firmen schon mal eine Monatsabrechnung
gemacht haben.
Aber die wirklich Harten fällen auch heute noch Bäume mit der Handaxt.
MfG Klaus
leo schrieb:> Ach so, du darfst natuerlich nicht einfach weiterzaehlen und in den> Overflow kommen.> index = ++index % size;
Bei Controllern ohne DIV-Instruction wäre besonders in Interrupts oft
ein
1
Index++;
2
if(Index>=size)Index=0;
besser.
Klaus schrieb:> Das kommt davon, wenn man sich beim Programmieren auf so etwas wie das> Verhalten bei einem Overflow verlässt (Pfusch)...
Wenn das Überlaufverhalten vom Datentyp definiert ist, dann ist das kein
Pfusch.
W.S. schrieb:> Ein schlichtes Maskieren mit UND ist einfach, ein Einschränken mit> MODULO bedarf einer Division und Verwenden des Restes. Ist eben> aufwendiger.
Mal wieder keine Ahnung?
Ab M3 gibts Division in Hardware und damit auch Modulo.
W.S. schrieb:> Ich habe es schon SO OFT gesagt, daß es falsch ist, immerzu nur all die> Verhältnisse, die man am PC hat, einfach so 1:1 auf die Welt der> Mikrocontroller zu übertagen.
Jaja wir wissen, dass du selbst die libc mit memcopy verteufelst.
-> du hast von wirklich nix nen Plan!
Franz schrieb:> Wenn das Überlaufverhalten vom Datentyp definiert ist, dann ist das> kein Pfusch.
Ok, objektiv richtig. Aber in der Mathematik laufen Ganzzahlen nie über.
Und bei heutigen Prozessoren gern erst bei 64 Bit. Wenn ich zum
Verständnis eines so simplen mathematischen Ausdrucks erst noch eine
Prozessorspec oder eine Sprachdefinition zu Rate ziehen muß, dann ist
das schon dicht an Pfusch. Insbesondere, wenn es auch leicht anders geht
und das dann auch für andere Sprachen und sogar mit dem Taschenrechner
funktioniert.
MfG Klaus
Mw E. schrieb:> Ab M3 gibts Division in Hardware und damit auch Modulo.
Erstens kostet eine Division auf M3 2-12 Takte, zweitens gibt es kein
Modulo und keinen Rest. Das wird dann mit einem weiteren MLS-Befehl
(multiply-subtract) gemacht, der nochmal zwei Takte kostet. Ein
einfaches AND hingegen ist in einem Takt erledigt.
Da hast du völlig recht.
Der Vorteil ist eben, dass man dann nicht 2^n Buffergrößen braucht.
Also erst 8k und wenns nicht reicht dann gleich 16k.
Es ist jedenfalls nicht so viel langsamer wie W.S. behauptet wenn man es
nutzt.
Die 12 Takte Variante ist jetzt der Extremfall, ich muss nochmal suchen
woe das ST angeeben hat, abers waren keine 12 CLKs.
W.S. spricht eben immer im absoluten und lässt keine anderen Gedanken
zu.
Die Verteufeufelung von Debuggern, DMA und inzwischen auch memcopy is
einfach hanebüchen.
Siehe:
W.S. schrieb:
> Und hier geht es um eine Low-Level-Treiber-Angelegenheit in> einem µC und nicht um die Jahresbilanz der Firma.
Mw E. schrieb:> Der Vorteil ist eben, dass man dann nicht 2^n Buffergrößen braucht.> Also erst 8k und wenns nicht reicht dann gleich 16k.
Klar, aber ein serieller Buffer wird eh nicht so groß sein.
> Die 12 Takte Variante ist jetzt der Extremfall, ich muss nochmal suchen> woe das ST angeeben hat, abers waren keine 12 CLKs.ARM gibt das an, nicht ST, und es sind bis zu 12 Takte:
http://infocenter.arm.com/help/index.jsp?topic=/com.arm.doc.100165_0201_02_en/ric1414056333562.html
Wobei es natürlich schon richtig ist, daß auch bis zu 13 unnötige Takte
im Interrupt jetzt keinen Schönheitspreis gewinnen, aber zumindest für
einen seriellen Treiber auf einem doch recht schnellen Cortex-M3 eher
nicht kritisch sein dürften.
Übrigens sollte ein anständiger C-Compiler heute ohnehin von selber in
der Lage sein, ein Modulo durch eine Zweierpotenz mit einem AND zu
ersetzen, wenn das zur Compile-Zeit feststeht.
Nop schrieb:> Übrigens sollte ein anständiger C-Compiler heute ohnehin..
Ja, hast ja Recht damit.
Aber derartige Tests seitens des Compilers ändern nichts an der
Tatsache, daß ein UND per se eben weniger Aufwand macht als eine
Division, die für ein Modulo halt unerläßlich ist, um den Rest zu
bestimmen.
Und wenn man Strukturen zu bearbeiten hat, deren Größe man nicht selber
bestimmen kann, dann ist Modulo unerläßlich - aber für einen popligen
Ringpuffer gilt das nicht.
W.S.
Hallo,
Johannes S. schrieb:> Das Ganze ist ja ein Template und die Fifo Elemente können auch größer> werden. Wenn dann doch mit Locking gearbeitet werden muss, ist es> günstiger erst die Zeiger zu setzen (unter lock), und dann den> Datenpuffer zu bearbeiten (ohne lock). Das spart Blockierungszeit.
Ringbuffer sind dazu gedacht, ohne Locking Daten zwischen zwei asynchron
laufenden Prozessen (bspw. ISR und main Loop) auszutauschen. Wenn der
Ringbuffer korrekt implementiert ist, muss nicht gelockt werden. Das
gilt auch für Ringbuffer-Template-Implementierungen, die beliebige
I/O-Datenstrukturen verarbeiten können.
Heinz schrieb:> Wenn der> Ringbuffer korrekt implementiert ist, muss nicht gelockt werden.
Falsch! Denn wenigstens der Update der Lese- und Schreibzeiger bzw.
Indizes muss atomar erfolgen. Wenn das die Hardware ohne Interruptsperre
kann, z.B. weil es eine 32 Bit Maschine ist, dann geht das. Allgemein
stimmt das aber nicht!
das war jetzt aus meiner Erfahrung mit x86 Embedded Systemen, habe das
auf den Cortex-M noch nicht so genau angesehen. Aber die werden ja auch
immer komplexer und so selten auftrende Fehler sind sehr schäbig, da
wäre ich einfach vorsichtig.
Falk B. schrieb:> Falsch! Denn wenigstens der Update der Lese- und Schreibzeiger bzw.> Indizes muss atomar erfolgen.
Wieviele Beispiele kennst du, wo tatsächlich mehr als 255 Elemente im
Ringpuffer gehalten werden müssen?
W.S.
Ein Ringbuffer ist kein Hexenwerk. Wer dort ein Locking macht, der hat
es oft nicht verstanden. Der bastelt so eher Deadlocks andere Timing
Probleme. Falks Einwand ist zwar richtig, es ist aber 'nur' eine
wichtige Feinheit am Rande. Ein einfaches "Falsch!" finde ich unpassend.
W.S. schrieb:> Wieviele Beispiele kennst du, wo tatsächlich mehr als 255 Elemente im> Ringpuffer gehalten werden müssen?
Bis du behämmert? Ach ne, W.S., der Kleingeistige. Dann bist du
entschuldigt.
Schon mal drüber nachgedacht, daß jeder normale PC bzw. alles was
irgendwie mit Internet und Streaming zu tun hat, einen Puffer braucht?
Und daß der im Allgemeinen DEUTLICH größer als deine pupertären 255 Byte
ist?
Es gibt µC die atomar nur 8 Bit lesen (das hier Entscheidende!) können
-> Ja.
Außerdem gibt es Fälle in denen man mehr als 8 Bit benötigen würden ->
Ja.
Wie oft hat man Fälle in denen beidens gleichzeitig zutrifft?
Falk B. schrieb:> Falsch! Denn wenigstens der Update der Lese- und Schreibzeiger bzw.> Indizes muss atomar erfolgen.
Wie ich schon schrieb - "wenn der Ringbuffer korrekt implementiert ist".
Das "korrekt" schließt natürlich mit ein, dass die Zugriffsvariablen
atomar bearbeitbar sein müssen. Aber gut, dass nochmal auf diese
Feinheit hingewiesen wurde.
Falk B. schrieb:> Schon mal drüber nachgedacht, daß jeder normale PC bzw. alles was> irgendwie mit Internet und Streaming zu tun hat, einen Puffer braucht?> Und daß der im Allgemeinen DEUTLICH größer als deine pupertären 255 Byte> ist?
Nunja, solche Maschinen können allerdings typisch auch mehr als 8 Bit
atomar lesen und schreiben...
Dein Einwand trifft also nur für den eher seltenen Fall eines 8 Bit µC
zu, bei dem für irgendeine Anwendung mehr als 256(!) Einträge(!) im
Ringpuffer benötigt werden. Kompetente Programmierer können diesen Fall
regelmäßig problemlos vermeiden...
Falk B. schrieb:> Bis du behämmert? Ach ne, W.S., der Kleingeistige. Dann bist du> entschuldigt.>> Schon mal drüber nachgedacht,
Schon mal drüber nachgedacht, sich hier wie ein gesitteter Mensch zu
benehmen? Oder gar mal sachlich zu antworten?
W.S.
c-hater schrieb:> bei dem für irgendeine Anwendung mehr als 256(!) Einträge(!)
Ja.
Ich habe jedoch Zweifel, daß deine Hervorhebungen beim Falk angekommen
sind. Der hat's nämlich von anfang an nicht kapiert, daß es nicht 256
Bytes, sondern 256 Einträge sind:
Falk B. schrieb:> Und daß der im Allgemeinen DEUTLICH größer als deine pupertären 255 Byte> ist?
Eben. Falk kann nicht unterscheiden zwischen Byte und Eintrag.
W.S.
W.S. schrieb:> Schon mal drüber nachgedacht, sich hier wie ein gesitteter Mensch zu> benehmen? Oder gar mal sachlich zu antworten?
Musst du schonwieder Selbstgespräche führen?
Wie es in den Wald hinein ruft, so schallt es heraus.
Sachlich mit dir über was zur schreiben ist einfach nicht möglich.
Zudem: wer geht denn hier andauernd User an?
Tipp: du bists!
Dein Geblubber nervt hier einfach nurnoch im Forum, du hast von absolut
garnichts auch nur die geringste Ahnung, aber versuchst jeden mit deinen
"Weiseheiten" zu nerven.
Hau einfach ab!
Johannes S. schrieb:> warum muss ich gerade fürchterlich lachen?
Ich lache mit dir mit ;)
Mw E. schrieb:> Ich lache mit dir mit ;)
Tja, Lernbehinderte, weitgehend in ihrer eigenen Filterblase gefangen...
Da wird wohl kein Fortschritt mehr zu verzeichnen sein...
c-hater schrieb:> Tja, Lernbehinderte, weitgehend in ihrer eigenen Filterblase gefangen...>> Da wird wohl kein Fortschritt mehr zu verzeichnen sein...
Japp, alles auf W.S. zutreffend.
Er kommt immer mit den selben Flausen an, die jetzt schon x Fach von
vielen Usern hier im Forum widerlegt wurden.
Da ist kein Fortschritt erkennbar.
Mw E. schrieb:> Er kommt immer mit den selben Flausen an, die jetzt schon x Fach von> vielen Usern hier im Forum widerlegt wurden.
Du machst dich lächerlich.
Es ist sicherlich nicht so, dass ich W.S. in jeder seiner Äußerungen
zustimmen würde (er meinen sehr wahrscheinlich ebenfalls nicht). Der
Punkt ist: im konkreten Fall hat er nach Lage der Fakten einfach mal
Recht und nicht Falk B.
Beweisbare Fakten sollten die Diskussion entscheiden und nicht
irgendeine Sympathie oder Aversion gegenüber Diskussionspartnern.
Und: wenn einer Bullshit vertellt, dann MUSS es erlaubt sein, den
Bullshit auch öffentlich als eben solchen zu brandmarken! Ohne jede
Rücksicht auf die persönlichen Befindlichkeiten des Posters. Rein nach
dem Konzept: Gemeinwohl ist wichtiger als das Wohl Einzelner.