Hallo liebe Community,
also meine Frage ist, wie man eine.csv Datei möglichst effizient
auswerten kann.
Die Ausgangslage:
Ich lese mit Hilfe eines RPi Sensordaten aus und speichere diese auf
einem USB Stick als .csv Datei ab.
Eine Datei besitzt dabei 500000 Zeilen mit je 13 Spalten (timestamp + 12
Messwerte).
Die Messung läuft etwa 10 Stunden, das heißt ich bekomme ca 20 solcher
csv Dateien.
Jetzt meine Frage:
Was ist der beste Weg diese Messwertdaten zuerst umzurechnen (von den
0-10V die abgespeichert werden zu zum Beispiel der Auszugslänge eines
Seilzugsensors) und danach grafisch darzustellen.
Ein Beispiel, wie so eine Datei aussieht befindet sich im Anhang.
Mein erster Gedanke war Excel, jedoch weiß ich nicht, wie ich die
Datenumrechnung dort umsetzen kann. Ebenso denke ich, dass bei so vielen
Messwerten das Programm an seine Grenzen stoßen wird.
Eine andere Variante wäre auch die Daten nicht als .csv sondern als
MySQL Datenbank abzuspeichern, jedoch müsste ich mich da vorher erstmal
einlesen.
Zu erwähnen ist, dass ich noch relativ neu in der ganzen Sache hier bin,
also habt bitte ein wenig Nachsicht, falls ich etwas nicht auf Anhieb
verstehe.
Ich hoffe es kann mir jemand bei meinem Problem helfen.
Vielen Dank bereits im Voraus
Mit freundlichen Grüßen
Matthias
Bei 10 Mio Zeilen will man SCHNELL sein. Daher kein Excel. Sondern ein
Programm. Es muss offenbar nur zeilenweise durch die Dateien.
Dbei sollte es die umgerechneten und in der Menge reduzierten Daten
rausschreiben, je nach gewünschtem Aussehen der Graphik kann das GnuPlot
sein oder was anderes. Das Programm kan man in Python oder awk oder C
schreiben oder was auch immer man gut kann.
Hauptsache man lasst das Plot-Programm nicht 120 Mio Datenwerte lesen um
eine Graphik von 640 Pixeln Breite zu erzeugen, dafür reichen offenbar
320 Stützstellen.
Insgesamt sieht es nach grossem Unsinn aus, soviele Daten zu erfassen.
Temperatur und Luftdruck kann es jedenfalls nicht sein.
MaWin schrieb:> Insgesamt sieht es nach grossem Unsinn aus, soviele Daten zu erfassen.
Datenerfassung ist pauschal Unsinn, ja ja. Was für ein MaWin ist das
schon wieder?
Andere Leute leben davon sehr viele Daten zu erfassen.
Also danke erstmal für die Antworten.
Habe ich das richtig verstanden, dass ich mit GNUPlot dann ein Programm
schreiben kann, dass die Daten umrechnet und Darstellt?
Zu der Menge an Daten. Es geht um eine Kraftmessung. 6 Der 12 Sensoren
sind DMS, die die auftretenden Kräfte aufzeichnen. Die anderen sind ein
Seilzugsensor und Beschleunigungssensor. Es werden so viele Daten
benötigt, damit man genau sehen kann, wo Spannungsspitzen auftreten und
wie hoch diese sind.
Nur eine Frage noch. Die Daten in der .csv Datei sehen ja so aus:
Timestamp, SpannungSensor1,SpannungSensor2, ...
Gibt es einen Weg (zum Beispiel in C#, bevorzugt aber im LabVIEW) diese
Daten aus den Zeilen einzeln auszulesen. Also immer bis zum nächsten
","?
Ganz ehrlich: So eine Datenmenge würde ich in eine
Datenbank schreiben. Siehe dir mal https://sqlite.org an,
dann geht das auch in einem File ohne Server zu
installieren.
merciless
SQL hat allerdings viel Verwaltung im Verhältnis zu den Daten. Wenn es
um zeitbasierte Daten geht, dann gibt es für diesen Zweck optimierte
Datenspeicherung, die TDBMS. Bekannter Vertreter hierfür ist InfluxDB,
die gibts auch als OpenSource Variante, sofern man nicht gleich riesige
Cluster braucht.
Große Datenmengen und schnelle Zugriffe kann InfluxDB, es gibt auch
viele Codebeispiele für Zugriffe aus verschiedenen Sprachen. Bei hohem
Datenvolumen muss man aber die Daten sammeln und in Pakten übertragen,
Standardprotokoll ist HTTP.
Auf InfluxDB setzt z.B. Grafana als grafische Oberfläche auf. InfluxDB
unterstützt auch die Datenkomprimierung bei der Abfrage oder um alte
Daten zu packen.
CSV kann man natürlich auch einfach in C# verarbeiten, Zeile lesen und
mit split String Funktion in Teile zerlegen lassen. Nach Beispielen
googlen dürfte reichlich Ergebnisse liefern.
Auch LabView kann CSV mit Sicherheit einlesen, habe nur schon lange nix
mit LabView gemacht. Schleifen lassen sich mit LabView ja auch
programmieren, sollte also auch gehen, die Frage ist nur wie schnell das
dann läuft.
Schau Dir mal orange an, ist Freeware und kann mit python gescripted
werden. Die Umrechnung Spg. zu Weg ist ja vermtl. nur 3Satz?
Ansonsten python + pandas + matplotlib
//hufnala
In Ordnung.
Werde mir das mit SQLite einmal ansehen und schauen ob dies mit meinem
Python Programm von der Geschwindigkeit her kompatibel ist.
Ansonsten werde ich mir noch die anderen vorgeschlagenen Anwendungen
durchsehen und hoffe, dass eine geeignete dabei ist.
Dass die Messdaten in der angehängten Datei noch linear sind, hängt
daran, dass ich die Sensoren noch nicht einlesen lasse. Wird sich noch
ändern
Danke für die schnellen Hilfestellungen
Ich würde dafür awk empfehlen, das wurde für genau solche Aufgaben
erfunden. Unter Windows bekommst du es zum Beispiel als Bestandteil von
CygWin.
Eine Einführung in awk findest du im Buch
http://stefanfrings.de/smstools/SMS_Anwendungen.pdf Kapitel 4.10
Das CSV Modul von Python implementiert IMHO einen Streamreader, d.h. das
File wird nicht komplett im RAM gebuffert und zeilenweise gelesen. 10^6
Zeilen sollten da kein nennenswertes Problem darstellen, sofern der USB
Stick schnell genug liefert. Eine Datenbank ist Overkill, soweit keine
komplexeren Abfragen gewünscht sind. Die Frage ist eher, was ist in
diesem Anwendungsfall "schnell genug"? Danach richtet sich dann die
mögliche Lösung.
Matthias P. schrieb:> also meine Frage ist, wie man eine.csv Datei möglichst effizient> auswerten kann.
Ein Dateizugriff wird wesentlich effizienter, wenn die Daten in
Binärform als Records fester Länge abgespeichert werden. CSV ist da eine
Sackgasse.
"Ein Dateizugriff wird wesentlich effizienter, wenn die Daten in
Binärform als Records fester Länge abgespeichert werden."
Und dann mmap(). Aber vielleicht ist das für ein paar popelige Dateien
schon zu viel Aufwand. Deswegen meine Frage nach dem "schnell genug"...
ich würde auch Gnuplot nehmen, geht schnell und ist einfach, leider hast
Du in allen Zeilen gleiche Werte in Deiner Datei, sonst hätte ich mit
einem Vierzeiler zumindest den 1. Wert grafisch dargestellt (so gibt das
nur eine waagerechte Linie).
ergo70 schrieb:> "Ein Dateizugriff ...
Versuch's mal mit markieren und dem Button "Markierten Text zitieren"
;-)
ergo70 schrieb:> Und dann mmap().
Früher (tm) hätte man die Datei einfach als Binärdatei geöffnet und
dabei die Recordlänge/-typ übergeben.
InfluxDB kann man auch direkt auf dem Raspi installieren, dann entfällt
das Turnschuhnetzwerk (wenn man den RPi ans Netz hängen kann).
Eine der vielen Anleitungen:
https://simonhearne.com/2020/pi-influx-grafana/
Also unter "schnell genug" verstehen ich, dass die Auswertung pro Datei
(500000) nicht länger als 2-3min dauern sollte.
Dass in der Datei nur Lineare Werte zu finden sind, dafür möchte ich
mich entschuldigen, habe jedoch gerade die Sensoren nicht zur Hand, um
echte Werte aufnehmen zu können.
Was noch nicht wirklich behandelt wurde ist, dass die Daten vor der
Darstellung noch umgerechnet werden müssen/sollten.
Zum Beispiel von der Brückenspannung der DMS auf die wirkende Kraft.
Umrechnung ist in dem Fall z.B.:
mech. Spannung(soll Dargestellt werden) = (Uab 4 E-Modul)/(U0 * K)
in diesem Fall handelt es sich um eine Vollbrücke (deswegen *4)
E-Modul=72
K(Brückenfaktor) = 2.11
U0= 3
Uab = Wert in der dazugehörigen Spalte
Dies soll nur ein Beispiel für die Umrechnung sein und vor der
Darstellung geschehen.
Die Umrechnung und Darstellung würde ich aber vorzugsweise nicht auf dem
Raspi machen, sondern auf einem anderen Rechner(Windows)
Also ich mache genau das was du das treibst regelmaessig mit einem
kleinen C-Programm. Das geht auf einem aktuellen Rechner in Sekunden.
Ausserdem kannst du dann auch einfach Werte zusammenfassen/mitteln weil
du fuer die Anzeige sicher sehr viel weniger Werte brauchst. Also
Zeilenuebergreifend arbeiten.
Ich hab sogar noch einen Filter in meinem Programm mit dem ich manchmal
die Daten Tiefpassfilter. Alles kein grosses Problem.
Und man kann auch gleich noch etwas Sonderbehandlung einbauen. Zum
Beispiel die ersten 3Zeilen weglassen falls ein Header drin steht oder
sowas.
Setzt natuerlich voraus das du C kannst. Falls nicht dann nimmst du halt
irgendeine andere Sprache die du kannst. Das was du da machen willst ist
ja eigentlich ein triviales Problem.
Olaf
Matthias P. schrieb:> Also unter "schnell genug" verstehen ich, dass die Auswertung pro Datei> (500000) nicht länger als 2-3min dauern sollte.
Dann vergleiche das mal mit der Anzahl der Rechenoperationen, die in
einem aktuellen Spiel für die flüssige Darstellung einer halbwegs
realisischen Umgebung anfallen.
den aber mit aufsteigenden Zeitstempeln 120tausend-mal hintereinander.
"gnuplot" macht zwar trotzdem innerhalb einer Sekunde einen Graphen
draus, aber viele waagrechte, parallele Linien sind nicht so
interessant.
Dirk K. schrieb:> Ganz ehrlich: So eine Datenmenge würde ich in eine> Datenbank schreiben.
Wozu, damit es grottenlangsam wird ?
Es muss nicht sortieren, indizieren, umsortieren.
Er muss nichts machen, bei dem eine Datenbank helfen würde.
Sie bremst nur.
Matthias P. schrieb:> Gibt es einen Weg (zum Beispiel in C#, bevorzugt aber im LabVIEW) diese> Daten aus den Zeilen einzeln auszulesen. Also immer bis zum nächsten> ","?
Du hast noch nier programmiert ?
Es kann jede Sprache.
Echtes CSV ist aber komplexer, kann , in Zellen enthalten per
Gänsefüsschen.
CSV Parser wurden wohl auch schon in jeder Sprache geschrieben.
Die schlechteren hängen dann an \n vs \r\n vs. \r zwischen Mac, Linux
und Windows.
Dein Vorteil: Dein Einlesen muss nur deine Dateien können. Sogar deine
Zeilenlänge ist bekannt. Es ist also sehr einfach.
Wolfgang schrieb:> Dann vergleiche das mal mit der Anzahl der Rechenoperationen, die in> einem aktuellen Spiel für die flüssige Darstellung einer halbwegs> realisischen Umgebung anfallen.
Als Programmieranfänger ?
Ein klassisches Textpipingprogramm wie wc (word count) welches ungefähr
dieselbe Komplexität hat (und als langsam bekannt ist) zieht ungefähr
500MB in den 20 Sekunden durch. Geht also, ist aber nicht viel Luft. Ob
Cä genau so schnell ist ? Da dauert schon der Programmstart 20s :-( Ok,
ich mag C# nicht, aus politsichen Gründen (Antwort von MS gegen Java)
und wegen der unsäglichen Manifest (nachträglich von MS an die eigentich
saubere Entwicklung von Cool drangeflanscht).
Εrnst B. schrieb:> Die Datei enthält exakt einen> Datensatz:0.000102141631942,-6.98468502378e-05,-0.000108901003841,6.0083
3118369e-06,-4.53128304798e-05,0.0188736710697,
> den aber mit aufsteigenden Zeitstempeln 120tausend-mal hintereinander.
... und dazu noch mit einer völlig irrsinnigen Anzahl von Stellen.
Welcher Sensor liefert bitte Daten mit einer Genauigkeit, die diese
Anzahl von Stellen für die Messwerte rechtfertigt?
Google mal nach SQLiteStudio . Das ist eine Software mit der man
SQL-Lite Datenbanken erstellen und befüllen kann. Die hat auch
CSV-Import.
Und dort kannst du auch SQL-Befehle direkt eingeben. Mit den Import und
den richtigen Befehl solltest du schnell zu einen Ergebnis finden.
Prg. ist kostenlos.
Was bedeutet du musst nur ein paar Befehle lernen :)
Matthias P. schrieb:> Eine andere Variante wäre auch die Daten nicht als .csv sondern als> MySQL Datenbank abzuspeichern, jedoch müsste ich mich da vorher erstmal> einlesen.
Was willst Du genau mit den Daten machen? Eine Datenbank macht nur Sinn,
wenn Du sehr oft nach unterschiedlichen Daten suchen willst. Sollen aber
nur einmalig die einzelnen Zeilen gelesen, umgerechnet und geplottet
werden, reicht die CSV vollkommen. Alles andere ist unnötiger Overhead.
Von Excel zur Datenauswertung rate ich bei dieser Datenmenge auf jeden
Fall.
Schlaumaier schrieb:> SQL-Lite Datenbanken
Bringt so direkt nix, wird furchtbar langsam, wenn du einen großen
Zeitraum auswerten willst.
"select tag,avg(messwert) from tabelle group by tag" über 365 Tage mit
einem Messwert alle drei Millisekunden?
Da hilft nur, die Daten schon beim Einlesen passend vorzubereiten.
Sollte eigentlich seit über 20 Jahren IT-Allgemeinwissen sein, so lange
gibt's "rrdtool" schon.
Kennst ja das Sprichwort: "Wer als Werkzeug nur einen Hammer hat, sieht
in jedem Problem einen Nagel."
Also: Schau dir auch mal andere Werkzeuge an, manchmal kommt man mit dem
Winkelschleifer schneller zum Fahrrad.
MaWin schrieb:> Dirk K. schrieb:>> Ganz ehrlich: So eine Datenmenge würde ich in eine>> Datenbank schreiben.>> Wozu, damit es grottenlangsam wird ?> Es muss nicht sortieren, indizieren, umsortieren.> Er muss nichts machen, bei dem eine Datenbank helfen würde.
Ach heute ist ja Freitag.
SQLite ist optimiert, von Hand eine .csv-Datei
einlesen dürfte nur unwesentlich schneller gehen.
Außerdem hat sich der TO darüber ausgeschwiegen,
wie die Daten genau ausgewertet werden sollen,
er sprach nur von Grafischer Darstellung. Meine
Erfahrung ist jedoch, das man ganz schnell in
Situationen kommt, wo man sich Details genauer
ansehen will. Er misst 10 Stunden lang, interessiert
sich jedoch für die Zeit von 11:45 bis 11:53, weil
da in der Grafik ein komischer Peak zu sehen ist.
Mit einer DB eine Kleinigkeit.
merciless
hufnala schrieb:> Ansonsten python + pandas + matplotlib
Das wäre auch mein Vorschlag gewesen, wobei selbst pandas schon overkill
ist, wenn es nur um Zahlen geht. Da reicht imho numpy völlig aus.
Wenn man sowieso schon in Python auf dem Raspberry Pi unterwegs ist,
dann drängt sich einem diese Lösung geradezu auf. Am besten man
integriert numpy direkt in seinen logging-Algorithmus und schreibt die
Daten als HDF5 weg, siehe z.B. https://www.h5py.org/
Was hier eine relationale Datenbank bringen soll erschließt sich mir
irgendwie überhaupt nicht.
Dirk K. schrieb:> Er misst 10 Stunden lang, interessiert> sich jedoch für die Zeit von 11:45 bis 11:53, weil> da in der Grafik ein komischer Peak zu sehen ist.> Mit einer DB eine Kleinigkeit.
Das ist selbst mit numpy eine Kleinigkeit und im Zweifelsfall nimmt man
dann doch pandas als in-memory-db
Wenn man so was macht mit so vielen Werten dann bedeutet grafische
Auswertung i.d.R. ne Menge Mittelwerte über ein Zeitraum X. Wobei X dann
noch unterteilt wird in 10-20 kleiner Zeiträume. Innerhalb dieser
Zeiträume noch mal den Mittelwert bilden.
Diese Punkte an Excel übergeben und ihn malen lassen.
Fertig.
Das sind wenn man es kann ca. 25 Sql-Befehle und das wars.
Mit Visual-Basic schaffe ich das in 1 Tag zu coden. Und Excel schmeißt
automatisch (ohne das man es selbst starten muss) die fertige Tabelle
raus inkl. Diagramm.
Schlaumaier schrieb:> Mit Visual-Basic schaffe ich das in 1 Tag zu coden.
Schaffst du das auch so, dass es am Schluß schneller läuft als die
datenbank-freie CSV->gnuplot Lösung, die ich vorhin auf 5 Minuten
zusammengestöpselt hatte?
Also:
gnuplot : 5 Minuten programmieren, Laufzeit 1 Sekunde bei 120k
Datensätzen.
sqlite+Vb+Excel: 1 Tag programmieren, Laufzeit: ??? Minuten.
Zeig was du kannst!
Wolfgang schrieb:> Ein Dateizugriff wird wesentlich effizienter, wenn die Daten in> Binärform als Records fester Länge abgespeichert werden.
Ja
> CSV ist da eine Sackgasse.
Ich würde eher sagen, dass es ein bequemes Format für Schnittstellen
ist, da es für Maschine und Mensch lesbar und schreibbar ist.
Wo ich arbeite, spielt sich alles mit XML (SOAP) oder JSON ab. Dagegen
ist CSV ultra-schlank.
Binärdateien kann hingegen nur die Maschine verarbeiten. Da ist es viel
schwieriger, etwas manuell zu kontrollieren oder zu ändern.
Stefan ⛄ F. schrieb:> Binärdateien kann hingegen nur die Maschine verarbeiten. Da ist es viel> schwieriger, etwas manuell zu kontrollieren oder zu ändern.
Bei einer halben Million Datensätzen willst du das auch nicht wirklich.
Dirk K. schrieb:> Er misst 10 Stunden lang, interessiert> sich jedoch für die Zeit von 11:45 bis 11:53, weil> da in der Grafik ein komischer Peak zu sehen ist.> Mit einer DB eine Kleinigkeit.
Mit der richtigen DB, ja.
Für sowas gibt's Time-Series DBs, die exakt auf diese Anwendungen
hintentwickelt und optimiert wurden.
Mit einer relationalen DB kommt man eine Weile hin, aber irgendwann
stößt man an die Grenzen, versucht zu Optimieren, bastelt
Cleanup-Scripte die alte Daten aggregieren um die Tabelle und die
Indices wieder klein zu bekommen, und hat am Ende eine Time Series
Database auf SQL-Basis in Schlecht nachimplementiert.
Da kann man auch gleich zum richtig passenden Werkzeug greifen, auch
wenn das bedeutet dass man sein armes Hirn mal kurz mit neuen Konzepten
und Ideen stressen muss.
InfluxDB + Grafana wäre z.B. was aktuelles.
Anschauen-->
https://play.grafana.org/
Da kannst du einfach interaktiv rein- und rauszoomen, um deinen
"Komischen Peak" aus der Nähe zu betrachten.
Heutzutage dank Docker auf wenige Minuten installiert und sofort
einsatzbereit.
Εrnst B. schrieb:> sqlite+Vb+Excel: 1 Tag programmieren, Laufzeit: ??? Minuten.
Keine Ahnung muss man ausprobieren. Ich habe noch nie mit mathematischen
Funktionen innerhalb SQL gearbeitet. Ergo kenne ich deren
Verarbeitungszeit nicht.
Was ich aber weiß ist das eine LIKE Abfrage von 4.7 Mio Datensätze aud
ein nicht indiziertes Feld ca. 90 Sekunden dauert. Bei seiner DB würde
ich aber alle Felder die ich Abfrage indizierten.
Aber der größte Zeitfaktor denke ich ist eh das umwandeln der CSV in
SQL.
Wobei man den Import bedeutend beschleunigen kann, wenn man ganze als
"Transaction" macht. Das aber nur nebenbei.
Der einzige Grund wieso die das als CSV aufzeichnen, wird eh sein das
ein Arduino kein SQL kann. ;) Für das Erstellen / Erweitern einer
Text-Datei gibt es ja Scripte. :)
Schlaumaier schrieb:> Aber der größte Zeitfaktor denke ich ist eh das umwandeln der CSV in> SQL.
Nö. Das macht sqllite (mit der Ursprungstabelle getestet, alles im RAM)
in so 350msec.
Bis dahin ist's also noch schneller als gnuplot
Εrnst B. schrieb:> Nö. Das macht sqllite (mit der Ursprungstabelle getestet, alles im RAM)> in so 350msec.
OK. dann ist der Zeitunterschied ja nicht wirklich gravierend für die
Verarbeitung.
Dann die Mittelwerte bilden, sollte auch kein Zeitfaktor darstellen. Und
diese Daten in Excel übergeben. Fertig.
Alles in allen 1-2 Minuten Unterschied schätze ich, das sollte nicht
wirklich was zu melden haben. Muss der TO halt sehr was er macht. Die
Verarbeitung von SQLite-Dateien in VB ist jedenfalls kein Hexenwert.
Stefan ⛄ F. schrieb:> Wo ich arbeite, spielt sich alles mit XML (SOAP) oder JSON ab. Dagegen> ist CSV ultra-schlank.
Naja, gar so groß ist der Vorteil nicht, speziell bei JSON. Die
Hauptarbeit beim Einlesen ist ja nicht die Zerlegung in die Token,
sondern das wandeln der Token in's Maschinenformat.
Aber genau das ist gleichzeitig auch der Hauptvorteil: da erst auf der
Zielmaschine gewandelt wird, passt das Maschinenformat dann wenigstens
garantiert dazu...
> Binärdateien kann hingegen nur die Maschine verarbeiten. Da ist es viel> schwieriger, etwas manuell zu kontrollieren oder zu ändern.
15 Millionen Zeilen CSV kontrollierst und bearbeitest du auch nicht mehr
manuell...
Johannes S. schrieb:> SQL hat allerdings viel Verwaltung im Verhältnis zu den Daten. Wenn es> um zeitbasierte Daten geht, dann gibt es für diesen Zweck optimierte> Datenspeicherung, die TDBMS.
Oder das gute alte "schreib einfach die floats mit 4 Bytes je Float in
eine Datei". Man braucht nicht immer eine SQL-Datenbank. ;)
Sven B. schrieb:> Oder das gute alte "schreib einfach die floats mit 4 Bytes je Float in> eine Datei". Man braucht nicht immer eine SQL-Datenbank. ;)
Nur dann, wenn man mit den Daten dann auch noch irgendwas sinnvolles
anfangen möchte...
Für einen reinen Dump (write once, read never) ist natürlich das binäre
Speicherformat unerreicht schnell. Da geht absolut nix drüber...
Man kann es auch sehr schnell wieder einlesen, allerdings nur auf
derselben Architektur...
Sinnvolles Auswerten ist allerdings dann schon ein wenig schwieriger,
vor allem, wenn die Daten in ihrer Gesamtheit nicht in's verfügbare RAM
passen mögen...
c-hater schrieb:> Man kann es auch sehr schnell wieder einlesen, allerdings nur auf> derselben Architektur...
Welche Architektur, auf der du als Durchschnittsanwender wie hier 100 MB
Daten einliest, hat denn ein von irgendeiner anderen der in Frage
kommenden Architekturen abweichendes Binärformat für floats? Ernsthafte
Frage.
> Sinnvolles Auswerten ist allerdings dann schon ein wenig schwieriger,> vor allem, wenn die Daten in ihrer Gesamtheit nicht in's verfügbare RAM> passen mögen...
Hä, ich kann die doch genauso Wert für Wert oder in Chunks einlesen wie
in jedem anderen Format? Bei sqlite ist eher die Frage, wie realistisch
du deine 5 GB Floats da performat wieder rausbekommst, vor allem wenn du
irgendetwas damit machen möchtest, was nicht einfach von oben nach unten
durchlesen ist ... in meiner Erfahrung "eher gar nicht".
c-hater schrieb:> Man kann es auch sehr schnell wieder einlesen, allerdings nur auf> derselben Architektur...
Sinnvollerweise wird man nicht irgendein architekturspezifisches Format
verwenden. Was meinst du wohl, warum im IEEE Standard 754 Binärformate
für den Datenaustausch definiert sind.
Bei Sensoren mit begrenzter Dynamik und endlicher Auflösung ist float
allerdings sowieso nur bedingt angebracht. Was soll ein Sensor mit
irgendwelchen 10..14 Bit mit dem Dynamikbereich von Float Zahlen.
Hallo Matthias P.,
leider schreibst Du nicht, ob eine Datei mit 500000x13 Werten isoliert
dargestellt wird, oder ob noch datensatzübergreifend etwas gemacht
werden muss.
Für den ersteren Fall kannst Du Excel verwenden.
Folgendes fiel mir beim Blick auf Deine CSV-Datei auf:
Du verwendest Kommas als Trennzeichen. Das ist ungünstig, weil Komma und
Dezimalpunkt ländereinstellungsabhängig interpretiert werden. Bei den
aktuellen Excelvarianten (ich verwende daheim noch Office 2000) kannst
Du die Übernahme der Ländereinstellungen in Excel korrigieren.
Ich kann's gerade nicht testen, aber ein Semikolon ist als Trennzeichen
günstiger, ich glaube Excel macht die csv-Datei dann sofort auf und die
Ländereinstellungen interferieren dann nicht mehr mit der Feldtrennung.
Das Zeilenende einer CSV-Datei ist normalerweise CR, LF oder die
Kombination davon. Dein Schlusskomma suggeriert, dass es hinter noch
einen Datensatz gibt - das sehe ich so zu ersten Mal. :)
Bei Verwendung des richtigen CSV-Format machst Du einen Doppelklick auf
die csv-Datei, fügst in Spalte 14 oben Deine Formel ein, kopierst die
herunter und baust Dir dann ein Diagramm und speicherst das Ergebnis als
xlsx-Datei.
Wenn Du das sehr oft hintereinander machen musst, kannst Du den Vorgang
unter Verwendung von VBA-Code in einer zweiten Excel-Datei wunderbar
automatisieren.
Wichtig: Bei den Datenmengen nicht in der Firma Citrix benutzen, Dein
Excel sollte auf einem Fat Client laufen!
Als meine Datensätzen nicht mehr in die 65535 Zeilen meines Office 2000
passten, habe ich zuerst LibreOffice verwendet, aber das stürzte sehr
schnell ab. Office 2007 oder höher war da stabiler.
Mittlerweile lese ich meine Hobbydatensätze in der Sprache R ein, rechne
ein bisschen herum und erzeuge in R ein schönes Diagramm, was ich meist
in einem Bitmap-Format wie png speichere.
Die Datenbankvorschläge der anderen Foristen haben alle eine
Berechtigung für bestimmte Anwendungsfälle, aber dazu müsstest Du schon
mehr Details herausrücken.
Viel Erfolg!
Peter M. schrieb:> Ich kann's gerade nicht testen, aber ein Semikolon ist als Trennzeichen> günstiger, ich glaube Excel macht die csv-Datei dann sofort auf und die> Ländereinstellungen interferieren dann nicht mehr mit der Feldtrennung.
Trotzdem macht es immer noch einen ziemlicher Unterschied, ob Excel das
Trennzeichen als Dezimal- oder als Tausendertrennzeichen verwurschtelt.
Wolfgang schrieb:> Peter M. schrieb:>> Ich kann's gerade nicht testen, aber ein Semikolon ist als Trennzeichen>> günstiger, ich glaube Excel macht die csv-Datei dann sofort auf und die>> Ländereinstellungen interferieren dann nicht mehr mit der Feldtrennung.>> Trotzdem macht es immer noch einen ziemlicher Unterschied, ob Excel das> Trennzeichen als Dezimal- oder als Tausendertrennzeichen verwurschtelt.
Ich versteh' den Erkenntniswert Deines Beitrags nicht.
Genau wegen der länderspezifischen Behandlung habe ich ja auf das
Problem hingewiesen.
Faule Leute wie ich exportieren mundgerecht bzw im Hinblick auf die
verbreiteten Ländereinstellungen.
Peter M. schrieb:> Ich versteh' den Erkenntniswert Deines Beitrags nicht.
Ich wollte damit sagen, dass mit der Wahl eines Semikolons (oder eines
Tabs) als Feldtrennzeichen nicht alle Interpretationsprobleme beim
Einlesen einer CSV-Datei behoben sind. Allerdings sagt die Bezeichnung
"CSV" bereits, dass es sich im "Comma Separated Values" handelt, aber es
steht natürlich jedem frei, dies zu ignorieren.
Peter M. schrieb:> Bei den> aktuellen Excelvarianten (ich verwende daheim noch Office 2000) kannst> Du die Übernahme der Ländereinstellungen in Excel korrigieren.
Man kann aber auch ohne sich die Locales systemübergreifend zu
verpfuschen einfach mal was anderes tun als einen stumpfsinnigen
Doppelklick auf eine Datei. Nämlich: Anwendung öffnen un deren
Importfunktion verwenden. Bei Excel ist das irgendwie
Daten->importieren->und dann Text-Typ wählen.
Das war schon im allerersten Excel so und funktioniert auch bei einem
aktuellen noch ganz genauso. Und man kann dort viel mehr tun, als nur
"localefremde" CSVs ordentlich einzulesen...
Hallo c-hater,
c-hater schrieb:> Peter M. schrieb:>>> Bei den>> aktuellen Excelvarianten (ich verwende daheim noch Office 2000) kannst>> Du die Übernahme der Ländereinstellungen in Excel korrigieren.>> Man kann aber auch ohne sich die Locales systemübergreifend zu> verpfuschen einfach mal was anderes tun als einen stumpfsinnigen> Doppelklick auf eine Datei. Nämlich: Anwendung öffnen un deren> Importfunktion verwenden. Bei Excel ist das irgendwie> Daten->importieren->und dann Text-Typ wählen.>> Das war schon im allerersten Excel so und funktioniert auch bei einem> aktuellen noch ganz genauso. Und man kann dort viel mehr tun, als nur> "localefremde" CSVs ordentlich einzulesen...
Das ist genau die umständliche Variante, die ich vermeiden will.
Der stumpfsinnige Klick auf eine Datei ist das Ziel.
Deswegen auch meine Frage an die weitere Verarbeitung: Wenn der Vorgang
sich zig mal wiederholt, automatisiere ich das ganze mit Hilfe von VBA
in einer zweiten Exceldatei, die dann die CSV-Datei bearbeitet.
Zur Not wird noch eine byteweise Importroutine geschrieben (schon längst
gemacht).
Ich kann natürlich die fleißigen unter den µc-Lesern von der Arbeit
nicht abhalten. Ich mach's mir gerne einfach!
Peter M. schrieb:> Das ist genau die umständliche Variante, die ich vermeiden will.> Der stumpfsinnige Klick auf eine Datei ist das Ziel.>> Deswegen auch meine Frage an die weitere Verarbeitung: Wenn der Vorgang> sich zig mal wiederholt, automatisiere ich das ganze mit Hilfe von VBA> in einer zweiten Exceldatei, die dann die CSV-Datei bearbeitet.> Zur Not wird noch eine byteweise Importroutine geschrieben (schon längst> gemacht).>> Ich kann natürlich die fleißigen unter den µc-Lesern von der Arbeit> nicht abhalten. Ich mach's mir gerne einfach!
Nicht wirklich. Wer VBA und Excel wirklich beherrscht, der kann
natürlich auch problemlos dafür sorgen, dass für das Öffnen von
CSV-Dateien die einmal bei einem Import gewählten Einstellungen immer
zur Anwendung kommen, wenn irgendein Volltrottel stumpfsinnig eine
CSV-Datei doppelklickt, ganz unabhängig von den aktuellen
Locale-Einstellungen...
Ist wie immer: man muss einfach nur das System verstehen und seine
Möglichkeiten kennen und beherrschen...
Du hast wohl viel zu früh aufgehört bei der Erforschung der
Möglichkeiten des Systems. No mercy...
Hallo c-hater,
c-hater schrieb:> Du hast wohl viel zu früh aufgehört bei der Erforschung der> Möglichkeiten des Systems. No mercy...
für Deine wertvollen Beiträge zum Thema Excel-Automatisierung verleihe
ich Dir den großen Schwanzus-Longus-Preis am Bande.
Ein Assemblerprogramm wäre jetzt sicherlich der Gipfel der Gefühle. :)
Devise:
https://www.youtube.com/watch?v=1Dh5-jTpi6k
Ernsthaft, nimm Python !
Das was du machen möchtest ist quasi der Anfang von allem, was mit
DataSience zu tun hat.
Es gibt für alles und jeden Tutorials und Beispiele.
Bei den Fragen, die du hier stellst musst du dir vor allem einen Weg
suchen, den du auch gehen kannst.
Alles andere ist erstmal zweitrangig, was bringt dir die gesparte
Sekunde in der Auswertung, wenn du bis dahin Stunden gebraucht hast, um
die erste Auswertung zu machen.
Eigentlich müsste ich dir sogar zu Excel raten, aber das ist hässlich.
Wolfgang schrieb:> Matthias P. schrieb:>> Also unter "schnell genug" verstehen ich, dass die Auswertung pro Datei>> (500000) nicht länger als 2-3min dauern sollte.>> Dann vergleiche das mal mit der Anzahl der Rechenoperationen, die in> einem aktuellen Spiel für die flüssige Darstellung einer halbwegs> realisischen Umgebung anfallen.
Ich hoffe du meintest Sekunden.
Relevante Zeit dauert das einlesen der CSV und das erstellen der Grafik.
Das Rechnen ist fast egal.
Excel ist doch hier das mit Abstand einfachste Tool.
Alles andere ist für einen Programmieranfänger doch nur Qual.
Draufklicken, Spalten Auswählen, und Diagram erstellen.
Einfacher gehts nicht.
Solange da keine superkomplizierten Berechnungen gemacht werden,
ist das in Excel komfortabel möglich.
Auch Statistik (Pivot-Tabellen) sind in Excel mit ein paar Klicks
erledigt.
Der TE müsste halt noch das "," am Ende der Zeile wegtun, sonst
erkennt Excel die CVS nicht automatisch.
Ich verstehe echt nicht, was die ganzen Performance Überlegungen
da sollen, das Öffnen der Datei braucht grad mal eine Sekunde,
im Taskmanager bei der Speicherauslastung sieht man grad mal eine
Mini-Delle.
Peter M. schrieb:> Folgendes fiel mir beim Blick auf Deine CSV-Datei auf:> Du verwendest Kommas als Trennzeichen.
Das ist eigentlich schon richtig, denn CSV heißt ja bekanntermaßen
"Comma-separated values". Insofern ist die Verwendung von Kommata schon
korrekt. Probleme gibt es halt nur in Sprachräumen in den das Komma als
Dezimalseparator benutzt wird. Aus diesem Grund ist es auch
empfehlenswert die Werte in Anführungszeichen zu setzen, womit
verhindert wird das ein Dezimalkomma als Feldtrenner interpretiert wird.
Ich habe es mir angewöhnt in CSV-Dateien die Werte generell in
Anführungszeichen zu setzen, so umgeht man von vorherein Probleme, wenn
in den Werten selbst die Feldtrenner enthalten sind. Bei Dateien die ich
mit eigener Software verarbeite benutze ich als Dezimalmaltrenner auch
generell den Punkt, da eigentlich alle Programmiersprachen intern den
Punkt als Dezimaltrenner benutzen, wodurch die Umwandlung des Strings in
einen Zahlenwert unproblematischer ist. In der GUI wird's dann aber
schon gemäß den lokalen Einstellungen angezeigt.
Peter M. schrieb:> Ich kann's gerade nicht testen, aber ein Semikolon ist als Trennzeichen> günstiger, ich glaube Excel macht die csv-Datei dann sofort auf
Excel ist bezüglich CSV etwas zickig. Man muß da wirklich über Import
gehen, damit der Import auch wirklich so läuft wie man sich das wünscht.
Openoffice kekommt es richtig hin zeigt, sobald es eine csv-ähnliche
Dateistruktur erkennt, automatisch die Maske an wo man den Feldtrenner
einstellen kann. In unserer Gerätesoftware wird als Feltrenner per
default der Tabulator benutzt. Da gibt es generell keine Kollisionen mit
Dezimal-, Tausendetrennzeichen etc., aber die Datei ist schlechter
lesbar.
Udo K. schrieb:> Ich verstehe echt nicht, was die ganzen Performance Überlegungen> da sollen, das Öffnen der Datei braucht grad mal eine Sekunde,> im Taskmanager bei der Speicherauslastung sieht man grad mal eine> Mini-Delle.
Und die ganzen mikrosekunden sind auf einmal verschwunden...
Aber mit VBA dauert das einlesen der angehängten Datei knapp 1sec
und parsen noch nicht einmal 0.5sec.
Das schreiben der Daten (natürlich schön formatiert und mit us)
dauert ca. 30sec. (sind ja knapp 120000 Zeilen).
Matthias P. schrieb:> Eine Datei besitzt dabei 500000 Zeilen mit je 13 Spalten (timestamp + 12> Messwerte).
Warum so viele Zeilen pro Datei - das ist .csv und keine Database?
> Die Messung läuft etwa 10 Stunden, das heißt ich bekomme ca 20 solcher> csv Dateien.
Und jede Datei ist etwa 68MB - warum?
Warum nicht 100 Dateien mit jeweils 100000 Zeilen und etwa 12MB?
VBA kann diese 100 Dateien in weniger als 2 Minuten einlesen, braucht
vilelleicht noch weitere 60 Sekunden um die Daten zu bearbeiten und
entsprechend vorzubereiten...
Matthias P. schrieb:> Seilzugsensor und Beschleunigungssensor. Es werden so viele Daten> benötigt, damit man genau sehen kann, wo Spannungsspitzen auftreten und> wie hoch diese sind.
Dann kann man auch noch auswählen, ob alle Werte ins Excel geschrieben
werden oder nur Werte die sich um mehr als xx Einheiten pro gewählte
Zeiteinheit unterscheiden, oder die höher sind als Grenzwerte, oder...
Und auf einmal werden aus langweiligen meterlangen geraden Linien
nutzbare und übersichtliche Excel-Graph...
Andreas M. schrieb:> Soviele Beiträge schon und keiner weist darauf hin, dass das in "PC> Hard- und Software" richtig platziert wäre.
Da braucht es keinen Hinweis. Das Verschieben machen die Moderatoren
angeblich automatisch - habe ich gehört.
Wie wäre es mit QlikView? Kann CSV importieren, mit großen Datenmengen
umgehen und ist auch für nicht programmierende Office User geeignet.
Kostet halt etwas für den nicht privaten Gebrauch. Aber man kann ja mal
die Testversion versuchen und dann abwägen ob es das Geld wert ist oder
nicht.
Wolfgang schrieb:> Allerdings sagt die Bezeichnung> "CSV" bereits, dass es sich im "Comma Separated Values" handelt, aber es> steht natürlich jedem frei, dies zu ignorieren.
Microsoft hat sich traditionell schon immer recht wenig um Standards
geschert. In letzter Zeit merken sie, dass diese Strategie nicht mehr
lange funktionieren wird.
c-hater schrieb:> Nicht wirklich. Wer VBA und Excel wirklich beherrscht, der kann> natürlich auch problemlos dafür sorgen, dass für das Öffnen von> CSV-Dateien die einmal bei einem Import gewählten Einstellungen immer> zur Anwendung kommen, wenn irgendein Volltrottel stumpfsinnig eine> CSV-Datei doppelklickt, ganz unabhängig von den aktuellen> Locale-Einstellungen...
Dafür müsste man Markos in die Standard-Vorlagen packen. War das nicht
genau der Weg, mit dem die Makro-Viren Plage begann?
Mein Chef würde nicht erlauben.
Kleiner Tipp. Benenne die CSV Datei in eine TXT-Datei um. Wenn du diese
mit Excel öffnest über Datei -> öffnen, geht automatisch ein
Import-Fenster auf, da kannst du alles einstellen.
Stefan ⛄ F. schrieb:> Dafür müsste man Markos in die Standard-Vorlagen packen.
Ganz genau so ist das.
> War das nicht> genau der Weg, mit dem die Makro-Viren Plage begann?
Ja. So what? Die Existenz von Viren begann mit der Existenz
programmierbarer Maschinen. Sollte man deshalb auf programmierbare
Maschinen verzichten?
Das Problem ist nicht die Programmierbarkeit, das Problem ist einzig,
die Authentizität des Codes zu prüfen. Und das kann Excel. Sprich: du
signierst deinen Code anständig, teilst Excel mit, dass dieser
speziellen Signatur vertrauen darf und alles ist schick.
Da konntest du nicht alleine drauf kommen?
c-hater schrieb:> Das Problem ist nicht die Programmierbarkeit, das Problem ist einzig,> die Authentizität des Codes zu prüfen.
Das Problem ist, das man einer lausigen Script-Sprache Systemrechte
einräumt, anstatt Rechte vernünftig zu verwalten. Menn MS so einer
Sprache nur Zugriff auf gewisse Verzeichnisse genehmigen würde, und
einige Rechte aberkennt, wäre das VBA sicher.
Aber die haben seit I-LOVE-YOU nix dazu gelernt.
Und was ich von Zertifikaten halten muss, haben mir die Lehmann Brüder
sehr gut bei gebracht. ;)
c-hater schrieb:> Da konntest du nicht alleine drauf kommen?
Doch schon, aber dieses Thema "Makro-Viren" lässt bei vielen die rote
Lampe angehen. Damit wollen sie ein für alle Male nichts mehr zu tun
haben.
Für Leute, die da technisch nicht durch steigen, ist es am Einfachsten,
diese Sachen komplett zu meiden. Die meisten Leute brauchen ja auch
keine Makros.
Ich kenne sogar Leute, die sicherheitshalber auf die Nutzung von Emails
verzichten, soweit es geht.
Das ist alles Teufelszeug :-)
Schlaumaier schrieb:> Das Problem ist, das man einer lausigen Script-Sprache Systemrechte> einräumt
Das ist doch völliger Unsinn. Der Macrocode in irgendwelchen
Office-Dokumenten hat natürlich keine Systemrechte, sondern allenfalls
die Rechte des aktuellen Benutzers. Das bedeutet aber selbst für
Benutzer, die lokale Admins sind, noch nicht, das sie automatisch
Systemrechte oder auch nur die Rechte lokaler Admins hätten, da ist seit
über einem Jahrzehnt noch die UAC davor. Wenn sie nicht irgendein
Vollidiot abgeschaltet hat...
c-hater schrieb:> Das bedeutet aber selbst für> Benutzer, die lokale Admins sind, noch nicht, das sie automatisch> Systemrechte oder auch nur die Rechte lokaler Admins hätten,
Hm, ich bin lokaler Administrator aber habe gleichzeitig nicht die
Rechte eines lokalen Admininstrators?
Das ist schwerer Stoff für mich.
Klar bekommst du als Benutzer nicht wirklich Admin-Rechte mit so einen
Script.
Aber wieso kann es dann Viren geben, wenn die das System dicht gemacht
haben. ???
Und genau davon rede ich. Entweder die UAC und der Rest machen das VBA
Sicher, dann brauch man keine Warnungen und Sperren, oder es ist halt
NICHT sicher.
So einfach und logisch ist es.
Nehme ich gewisse Befehle von vorne rein weg, dann ist die Sicherheit zu
99% gegeben.
PS: Die UAC wird meiner Erfahrung nach nur unter VISTA abgeschaltet. ;)
Da geht die ein nämlich auf den Sa**. ;)
c-hater schrieb:> Das ist doch völliger Unsinn. Der Macrocode in irgendwelchen> Office-Dokumenten hat natürlich keine Systemrechte, sondern allenfalls> die Rechte des aktuellen Benutzers.
Vorsicht. Es ist noch nicht lange her, da hatte jeder normale Nutzer
uneingeschränkte Zugriffsrechte auf so ziemlich alles. Aus dieser Zeit
stammt der Makro-Viren Wahnsinn.
Heute haben wir mit Viren ja kaum noch was zu tun. Damals war machte es
50% meines Jobs aus, mich um Viren und Schutzmaßnahmen zu kümmern. Da
waren mehr Computer wegen Viren kaputt, als wegen Fehlkonfiguration oder
Hardare-Defekt.
Ganz unabhängig von speziellen Rechten hat ein Makro Voll-Zugriff auf
alle meine persönlichen Dateien. Reicht das nicht, sich zumindest ein
kleines bisschen zu fürchten? Wenn ein Makro mal einfach in sämtlichen
Dateien die geraden Bytes mit den ungeraden vertauscht (das gab es
tatsächlich), dann sind aus Anwendersicht alle wichtigen Dateien
kaputt und dem Virenscanner kommt das nicht einmal verdächtig vor.
Schlaumaier schrieb:> Nehme ich gewisse Befehle von vorne rein weg, dann ist die Sicherheit zu> 99% gegeben.
Dann musst du nur noch genügend blöde Verfasser von Viren finden, die es
genau mit diesen 99% versuchen.
Jeder mit ein bisschen Verstand wird natürlich versuchen, das restlichen
eine Prozent zu 100 Prozent zu nutzen.
Peter M. schrieb:> Hm, ich bin lokaler Administrator aber habe gleichzeitig nicht die> Rechte eines lokalen Admininstrators?>> Das ist schwerer Stoff für mich.
Ja, das geht vielen so. Das Grundkonzept ist einfach: ein lokaler
Administrator kann sich zwar prinzipiell alle Rechte beschaffen, hat sie
aber nicht automatisch. Er muß sie sich erst beschaffen, wenn er sie
wahrnehmen will. Das tut normalerweise der Code. Der kann das aber nicht
tun, ohne dass sich eine Rückfrage beim Benutzer ergibt. Genau das ist
der Job der UAC.
Bei Linux gibt es ein (in der Wirkung) recht ähnliches Konzept, genannt
sudo. Es funktioniert allerdings im Detail betrachtet doch ganz anders.
Die Grundkonzepte von Linux sind halt uralt, es gibt dort nichts
vergleichbares zu dem Konzept der "Privilegien", auf die WindowsNT
zurückgreifen kann, um dies zu realisieren.
Wie auch immer: Nur Vollidioten, die entweder die UAC komplett
abschalten oder UAC-Dialoge ohne Nachdenken bestätigen, laufen also
Gefahr, unabsichtlich das System zu gefährden. Also schätzungsweise nur
99% der Anwender...
Diese Sache gilt ganz allgemein, nicht nur für Office-Macros.
Für diese gibt es aber darüber hinaus weitere Sicherungschichten.
Konkret erlaubt man nur die Ausführung signierter Macros. Für fremde
Macros ist das also ziemlich exakt dasselbe, als wären sie garnicht
erlaubt. Für eigene Macros hingegen kann man Excel beibringen, dem
signierten Code zu vertrauen. Man muss halt nur verstehen, wie das mit
der Kryptographie funktioniert und die richtigen Zertifikate an den
richtigen Stellen im System platzieren...
c-hater schrieb:> Wie auch immer: Nur Vollidioten laufen also Gefahr, unabsichtlich> das System zu gefährden. Also schätzungsweise nur 99% der Anwender...
Klingt lustig, aber leider ist es tatsächlich so.
Warum nur tun viele Leute mit ihren wichtigsten Dateien so, als gäbe es
weder zerstörerische Viren, noch Hardwaredefekte noch direkt selbst
verschuldete Desaster?
Kein Backup -> kein Mitleid.
Ich empfehle, viele Backups für lange Zeit zu sammeln, denn es kommt ab
und zu auch mal vor, dass man eine kaputte Datei erst nach Monaten
bemerkt. Es wäre zu blöd, wenn das Backup nur eine weitere kaputte Kopie
der Datei enthält. Mobile Speichermedien sind so schnell und billig
geworden, dass man sich den Aufwand durchaus leisten kann. Im
einfachsten Fall simple Kopien der persönlichen Ordner anlegen - dazu
braucht man nicht einmal spezielle Software.
Stefan ⛄ F. schrieb:> Vorsicht. Es ist noch nicht lange her, da hatte jeder normale Nutzer> uneingeschränkte Zugriffsrechte auf so ziemlich alles.
Unsinn. Bei NT war das noch niemals so. Nur bei den
DOS-Windows-Geschichten (weil die garkein ernsthaftes Benutzerkonzept
kannten), also zuletzt bei WindowsME. Wann ist der Support dafür
ausgelaufen? Dürfte gut und gerne 15 Jahre her sein. Minimum.
Aber bei NT gab es von Anfang an eine starke Benutzerverwaltung. Also
auch bei z.B. XP (AKA WindowsNT 5.1).
Sie wurde nur dadurch praktisch ausser Kraft gesetzt, dass
DAU-Dummdödel, der das System aufgesetzt (oder komplettiert) hat,
erstmal Admin war. Wer Ahnung hat, konnte aber auch schon damals selber
das Risiko verringern, indem er nach der Grundkonfiguration einfach
einen neuen reinen Benutzeraccount für sich selber angelegt hat und im
täglichen Betrieb einfach nur noch diesen benutzt hat.
Tja, das System bot schon damals(tm) diese Möglichkeit, nur die Benutzer
waren halt zu blöd dazu, sie zu benutzen. Sind sie heute immer noch...
Microsoft hat reagiert und mit der UAC etwas geschaffen, was den Spagat
versucht zwischen der Freiheit des Benutzers zu Konfiguration seines
Systems und seiner Sicherheit. Man muss diesen Versuch wohl als
weitgehend gescheitert bezeichnen. Er tut zwar, was er soll, aber die
Malware hat sich angepasst. Sie ist einfach oft mit den Rechten des User
vollkommen zufrieden. Die genügen ihr, um sich zu verbreiten und um
Schaden anzurichten. Der Versuch zur Rechte-Eskalation macht sie nur
leichter erkennbar. Sie will aber nicht erkannt werden oder zumindest
erst so spät wie möglich...
c-hater schrieb:>> Vorsicht. Es ist noch nicht lange her, da hatte jeder normale Nutzer>> uneingeschränkte Zugriffsrechte auf so ziemlich alles.> Unsinn. Bei NT war das noch niemals so
Habe ich NT geschrieben?
Du dichtest gerne Unsinn in die Aussagen anderer um sie dann als Unsinn
zu beschimpfen. Ich weiß nicht wie andere das sehen, aber ich finde das
anstrengend.
Besser wäre eine Gegenfrage gewesen, was denn für mich "nicht lange her"
bedeutet.
Das Virenproblem ist im konkreten Fall gar keines, weil der TE beim
Versuch, seine 12 Messreihen à 500000 Werte mit Excel zu plotten, schon
lange vor dem Eintippen der ersten VBA-Codezeile entnervt aufgeben wird
;-)
Ich hab's gerade mal mit Excel 2010 ausprobiert. Ja, es geht prinzipiell
sogar ohne Crash, was mich schon etwas erstaunt hat. Da Zeichnen des
Diagramms dauert 2 Minuten, was nicht gerade schnell ist, aber immerhin
noch innerhalb der Anforderungen des TE liegt.
Aber:
Als superinteractive und megaresponsive Tool meint Excel, das Diagramm
wegen jedem Mäusefurz neu zeichnen zu müssen. Wenn man bspw die
Linienstärke einer der 12 Kurven vom Default (2,25pt) auf 0,75pt ändern
möchte, hat man dafür in dem dafür vorgesehenen Dialog prinzipiell zwei
Möglichkeiten:
1. Man benutzt die Inkrement-/Dekrementpfeile. Nach 6 Klicks ist man am
Ziel, aber nach jedem Klick muss man die o.g. 2 Minuten warten. In
Summe sind das 12 Minuten.
2. Man editiert den Wert per Tastatur. Dabei wird nach jedem Löschen
oder Einfügen eines Zeichens das Diagramm neu gezeichnet. Wenn man es
geschickt anstellt (die zu ändernden Ziffern nicht einzeln löscht,
sondern als Gruppe markiert und dann alle miteinander löscht), hat
man nach 5 Warteperioden (also nach 10 Minuten) die Linienstärke
geändert.
Damit hat man die Änderung für die erste Kurve durchgeführt, 11 weitere
folgen noch. Erst nach über 2 Stunden hat man alle durch. Dann möchte
man vielleicht noch die Farben ändern, da die Defaultfarben nur schwer
voneinander unterscheidbar sind ...
Interessanterweise ist sich Excel sogar des Problems bewusst, denn es
zeigt die ersten paar Male eine Warnung an, dass die Aktion länger
dauern könnte. Auf die Idee, den Benutzer erst einmal den Wert
vollständig eingeben und bestätigen zulassen, bevor mit dem Zeichnen
begonnen wird, kommt es aber leider nicht.
Die vielen auf diese Weise sinnlos verplemperten Stunden könnte man
bspw. auch dazu nutzen, für den RPi einen XY-Schreiber zu basteln. Das
braucht zwar auch seine Zeit, aber man hat wesentlich mehr Spaß dabei.
Was lernen wir daraus (wieder einmal)?
Excel ist für BWLer, die hin und wieder mal ein Säulendiagramm mit
maximal 20 Werten generieren müssen und sonst den ganzen Tag nichts zu
tun haben. Für alles, was darüber hinausgeht, gibt es um Welten bessere
Tools. Selbst mit Gnuplot und Matplotlib, die auch nicht gerade für "Big
Data" optimiert sind, kommt man in einem Bruchteil der Zeit ans Ziel.
Wenn man sich auf das beschränkt, was Excel wirklich kann, muss man sich
auch nicht mit VBA herumschlagen. Alles, was man meint, mit VBA besser
hinzubekommen, erreicht man i.Allg. noch besser und vor allem in viel
küzerer Zeit mit einem Python-, Perl- oder Ruby-Progrämmchen.
Das DBMS "MariaDB" (Fork bzw. Nachfolger von MySQL) kann für jede
Tabelle eine eigene Storage Engine definieren. Es gibt auch eine, die
CSV importieren und für SQL-Kommandos zur Verfügung stellen kann.
Freilich nur lesend ...
MaWin schrieb:> Insgesamt sieht es nach grossem Unsinn aus, soviele Daten zu erfassen.> Temperatur und Luftdruck kann es jedenfalls nicht sein.
Jetzt stell dir einfach mal einen mit Helium gekühlten
Kugelhaufenreaktor vor.
Die Reaktionszeit um bei einem Ausfall der Gaskühlung die Kernschmelze
zu verhindern, betragen nur ein paar Sekunden*. Deswegen sind kurze
Intervallmessungen notwendig.
OT:
Die kurze Reaktionszeit war übrigens der Hauptgrund, warum man diesen
Reaktortyp nicht weiterverfolgt hat.
Ein Gas ist da einfach nicht so gut, wenn es zum Kühlen großer
Energiemengen geht, wie Wasser oder noch besser, flüssiges Metall.
Yalu X. schrieb:> Das Virenproblem ist im konkreten Fall gar keines, weil der TE beim> Versuch, seine 12 Messreihen à 500000 Werte mit Excel zu plotten, schon> lange vor dem Eintippen der ersten VBA-Codezeile entnervt aufgeben wird
Tja, das ist, was manche Leute unter Programmieren verstehen...
Wenn man zuerst Code eintippt (nämlich zur "Verdichtung" umfangreicher
Messreihen) und dann erst anfängt mit Diagrammen zu hantieren, dann
klappt das mit Excel wunderbar und ist ideal für interaktive
Auswertungen.
Was man von dem ganzen OSS-Geraffel, weiß Gott, nicht behaupten kann...
Übrigens: den nötigen VBA-Code habe ich schneller eingetippt und
signiert als ich Zeit brauche, um auch nur eine Übersicht über die
Kommandozeilenoptionen von gnuplot zu gewinnen...
Um das ganz klar zu sagen: gnuplot ist sehr gut. Aber eben nicht dafür
ausgelegt, dass man interaktiv damit arbeitet. Das Benutzerinterface ist
dafür einfach mal völlig unzumutbar. Das ist sowas von letztes
Jahrtausend...
Das wurde auch erkannt und es gibt diverse GUIs, die gnuplot als Backend
benutzen. Aber wirklich überzeugend ist das Ergebnis auch damit nicht...
Yalu X. schrieb:> Auf die Idee, den Benutzer erst einmal den Wert> vollständig eingeben und bestätigen zulassen, bevor mit dem Zeichnen> begonnen wird, kommt es aber leider nicht.
Doch. ;) Aber nur mit etwas Hilfe. Dafür ist die F9 Taste dann
zuständig.
Wenn man bei Excel größere Sache machen will, muss man in den Optionen
die Funktion "Neuberechnen" ABSCHALTEN. Dann berechnet Excel nur nach
drücken der F9-Taste. Sonst ist bei den lahmen Teil bei größeren
Datenmengen und Kreuzbezügen kein anständiges Arbeiten mehr möglich.
c-hater schrieb:> Übrigens: den nötigen VBA-Code habe ich schneller eingetippt und> signiert als ich Zeit brauche, um auch nur eine Übersicht über die> Kommandozeilenoptionen von gnuplot zu gewinnen...
Manche Leute sehen das umgekehrt: bis ich mich in VB eingelesen habe,
ist der Gnuplot-Code schon 1000x durchgelaufen und Gnuplot ist wirklich
sauschnell, viel schneller als Excel, LibreCalc etc.
c-hater schrieb:> Wenn man zuerst Code eintippt (nämlich zur "Verdichtung" umfangreicher> Messreihen) und dann erst anfängt mit Diagrammen zu hantieren, dann> klappt das mit Excel wunderbar und ist ideal für interaktive> Auswertungen.
Man muss sich also erst in die VB-Programmierung und zusätzlich in das
Excel-API einarbeiten, um danach in den Genuss der Interaktivität zu
kommen? Toll, das wird jeden typischen Windows- und Excel-Benutzer
sofort überzeugen ;-)
Und wie interaktiv ist das Ganze danach? Kann man bspw. mit der Maus den
Diagramminhalt verschieben und zoomen? Oder muss man dafür weiteren
VBA-Code schreiben?
Da kann man sich doch genauso gut in Python (wie VBA, nur einfacher) und
Matplotlib (wie Excel-API, nur einfacher) einarbeiten und hat dann mit
weniger Programmieraufwand wesentlich mehr Möglichkeiten, sowohl was die
Diagrammtypen und -attribute als auch die Interaktivität betrifft.
Matplotlib ist übrigens auch schnell genug, um die Datensatzgröße von
(1+12)·500000 auch ohne Ausdünnen in akzeptabler Zeit verarbeiten zu
können. Das Laden der Daten dauert 6s, das Neuzeichnen des kompletten
Diagramms 0,5s, und bei entsprechend großem Zoomfaktor ist praktisch
keine Verzögerung erkennbar.
> Übrigens: den nötigen VBA-Code habe ich schneller eingetippt und> signiert als ich Zeit brauche, um auch nur eine Übersicht über die> Kommandozeilenoptionen von gnuplot zu gewinnen...
Das hängt halt vom Vorwissen ab. Bei mir ist es genau umgekehrt.
Schlaumaier schrieb:> Wenn man bei Excel größere Sache machen will, muss man in den Optionen> die Funktion "Neuberechnen" ABSCHALTEN. Dann berechnet Excel nur nach> drücken der F9-Taste.
Danke für den Tipp, da habe ich wieder etwas dazugelernt.
Leider wirkt sich diese Option nur auf die Neuberechnung von Zellen aus.
Das Zeichnen des Diagramms zählt wohl nicht als Neuberechnung, weswegen
das oben beschrieben Problem mit dem Ändern der Linienattribute immer
noch besteht.
Hallo zusammen,
Stephan S. schrieb:> Manche Leute sehen das umgekehrt: bis ich mich in VB eingelesen habe,
VB ist ungleich VBA. VBA ist der Teil von VBA, der in Microsoft Office
genutzt wird.
Yalu X. schrieb:> Man muss sich also erst in die VB-Programmierung und zusätzlich in das> Excel-API einarbeiten, um danach in den Genuss der Interaktivität zu> kommen? Toll, das wird jeden typischen Windows- und Excel-Benutzer> sofort überzeugen ;-)
nein, das VB-basierte oder VB-ähnliche VBA ist die Programmiersprache
von Microsoft Office und damit auch von Excel.
Yalu X. schrieb:> Und wie interaktiv ist das Ganze danach? Kann man bspw. mit der Maus den> Diagramminhalt verschieben und zoomen?
Nein. Vielleicht mit externen kostenpflichtigen Erweiterungen,
sogenannten Office-Add-Ins.
> Oder muss man dafür weiteren> VBA-Code schreiben?
Ja!
Yalu X. schrieb:> Leider wirkt sich diese Option nur auf die Neuberechnung von Zellen aus.> Das Zeichnen des Diagramms zählt wohl nicht als Neuberechnung, weswegen> das oben beschrieben Problem mit dem Ändern der Linienattribute immer> noch besteht.
Das war meine Befürchtung, als ich den Faden las. Damit ist das von mir
gerne genutzte Excel für diese Aufgabe nur bedingt geeignet.
Yalu X. schrieb:> Das hängt halt vom Vorwissen ab. Bei mir ist es genau umgekehrt.
Jemand, der ganz viele Sprachen kennt, kann bestimmt sagen, welches das
beste Werkzeug für dieses Problem ist.
Aber selbst wenn man das dann mit Namen kennt, ist es oftmals einfacher,
das Problem in einer Sprache zu lösen, mit der man vertraut ist.
Es ist wie immer bei solchen Fragestellungen:
Viele, die nur wenige Werkzeuge kennen, verteidigen die mit Zähnen und
Klauen, weil nicht sein darf, dass andere bessere Werkzeuge nutzen. :)
Peter M. schrieb:> Jemand, der ganz viele Sprachen kennt, kann bestimmt sagen, welches das> beste Werkzeug für dieses Problem ist.
Kann ich die sagen: Es ist die, die du am besten beherrschst.
Yalu X. schrieb:> Leider wirkt sich diese Option nur auf die Neuberechnung von Zellen aus.> Das Zeichnen des Diagramms zählt wohl nicht als Neuberechnung, weswegen> das oben beschrieben Problem mit dem Ändern der Linienattribute immer> noch besteht.
Sorry ich schalte Neuberechnen nur bei Verweise auf Externe Tabellen ab.
Besonders bei Analyse-Tabellen mit Sverweis. Sonst muss ich beim
editieren jeder Zelle ca 2-3 Minuten warten. (Ca. 15.000 Zeilen mit
Sverweis auf ca. 12.000 Zeilen dauern halt fg)
Peter M. schrieb:> Yalu X. schrieb:>> Man muss sich also erst in die VB-Programmierung und zusätzlich in das>> Excel-API einarbeiten, um danach in den Genuss der Interaktivität zu>> kommen? Toll, das wird jeden typischen Windows- und Excel-Benutzer>> sofort überzeugen ;-)>> nein, das VB-basierte oder VB-ähnliche VBA ist die Programmiersprache> von Microsoft Office und damit auch Excel.
Ja, klar. Aber für das im vorliegenden Fall unumgängliche Ausdünnen der
Daten auf ein für Excel erträgliches Maß muss nach Aussage des c-haters
erst einmal die VBA-Hürde überwunden werden. D.h. vor der interaktiven
Nutzung des Programms muss hier erst einmal programmiert werden.
Dinge wie die Visualisierung von Messdaten liegen einfach nicht im Fokus
von Microsoft, sonst hätten sie das Softwarepaket sicher nicht "Office",
sondern "Lab" genannt :)
Yalu X. schrieb:> Ja, klar. Aber für das im vorliegenden Fall unumgängliche Ausdünnen der> Daten auf ein für Excel erträgliches Maß muss nach Aussage des c-haters> erst einmal die VBA-Hürde überwunden werden. D.h. vor der interaktiven> Nutzung des Programms muss hier erst einmal programmiert werden.
Das ist so. Aber man benötigt nur eine sehr kleine Submenge des
VBA-Sprachumfangs (dazu kommt: VBA ist eine sehr einfach zu erlernende
Sprache) und einen sehr kleinen Subset des Excel-Objektmodells, um das
zu tun.
> Dinge wie die Visualisierung von Messdaten liegen einfach nicht im Fokus> von Microsoft
Das allerdings ist eine unbestreitbare Wahrheit. Wäre es anders, wäre
der VBA-Exkurs nicht nötig, dann hätte Winzigweich das gleich selber
eingebaut.
Verzeihung, dass ich solange keine Rückmeldung gegeben habe.
Danke erstmal für die ganzen Hilfestellungen
Soweit ich das jetzt verstanden habe sind die sinnvollsten Lösungen
Gnuplot und Excel.
Wobei man bei Gnuplot ein eigenes Script schreiben muss und im Excel ein
VBA.
Hier stellt sich für mich die Frage, ob es im Excel noch das Zeilenlimit
mit
~65000 Zeilen gibt, oder ob meine Dateien mit 500000 Zeilen auch schon
problemlos verarbeitet werden können.
Ebenso habe ich noch nichts mit diesen "VBA" gemacht und wollte wissen
wie komplex es ist, diese zu schreiben.
Die Funktion sollte sein, dass wenn ich auf die CSV-Datei Doppelklicke
die Werte im ersten Zug umgerechnet werden sollen und dann grafisch
dargestellt.
Des weiteren sollen die Daten minimalisiert werden, also dass zum
Beispiel nur die Werte über einer bestimmten Schwelle dargestellt
werden.
Könnte man das dann auch irgendwie machen, dass wenn man die meas0.csv
Datei öffnet, alle anderen automatisch Verarbeitet werden?
Im Anhang habe ich noch eine neue .csv-Datei angehängt, bei in der jetzt
richtige Messwerte gespeichert sind.
Matthias P. schrieb:> Hier stellt sich für mich die Frage, ob es im Excel noch das Zeilenlimit> mit ~65000 Zeilen gibt, oder ob meine Dateien mit 500000 Zeilen auch> schon problemlos verarbeitet werden können.
Ab Excel 2016 beträgt die maximale Zeilenanzahl 1.048.576 und
die maximale Spaltenanzahl liegt bei 16.384.
Bei einer größeren Zeilenanzahl könnte man die Datei splitten oder zwei
oder mehrere benachbarte Zeilen vor dem Import ins Excel zusammen
fassen. (MITTELWERT)
TIP für den Import :
1.) ',' vor dem Zeilenumbruch weglassen
2.) ',' durch ';' ersetzen
Ok danke.
Das mit dem "," vor dem Zeilenumbruch kriege ich leider nicht so einfach
weg, da ich in meinem Programm eine "For-Schleife" laufen lasse, die
nach jedem Wert ein, schreibt und am Zeilenende halt ein "\n".
Das mit dem ";" habe ich jedoch bereits umgeschrieben.
Matthias P. schrieb:> Wobei man bei Gnuplot ein eigenes Script schreiben muss
naja, "Script" ist etwas hochgegriffen.
Es ist einfach eine Config-Datei, in der du reinschreibst, wie du deine
Spalten-Werte gerne umgerechnet hättest, und wie/worauf/wiegroß/mit
welchen Achsen/welches Dateiformat geplottet werden soll.
Viele Defaultwerte "funktionieren" erstmal, d.H. du kannst mein
"test.gnuplot" von oben nehmen, und deine Tabelle reinschmeißen.
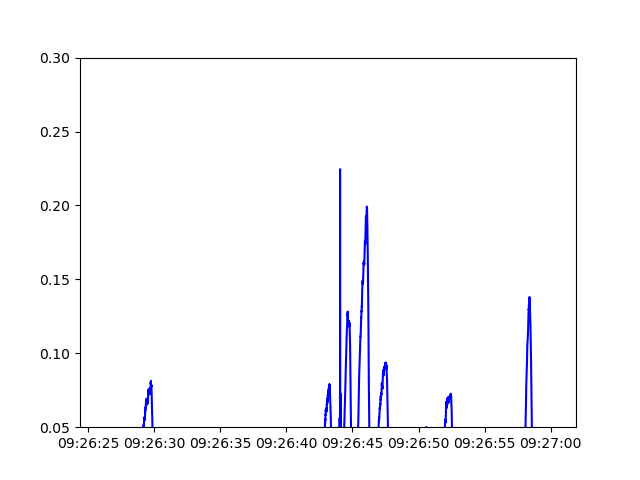
Schaut dann wie im Anhang aus.
Davon ausgehend kannst du es schrittweise "verschönern", andere
Linien-Stile, ein Grid im Hintergrund, Mittelwert-Linien, ... alles kein
Problem, man muss nur etwas in der Doku blättern oder sich Beispiele
anschauen.
Bitte um etwas Nachsicht:
Wo genau kann man den Dateipfad auswählen, die dargestellt werden soll.
Und noch zu Gnuplot:
Wie gut kann man die Daten dann filtern bzw. auswerten (Extremwert,
Mittelwert, ...)?
Matthias P. schrieb:> Das mit dem "," vor dem Zeilenumbruch kriege ich leider nicht so einfach> weg, da ich in meinem Programm eine "For-Schleife" laufen lasse, die> nach jedem Wert ein, schreibt und am Zeilenende halt ein "\n"
Am besten den "," vor und nicht nach dem Wert schreiben.
Mit np.loadtxt wird die Datei "meas0.csv" eingelesen, wobei eine Spalte
mit Datum/Uhrzeit ("M8[us]") und 3 Spalten mit Double-Werten ("3f8")
erwartet werden. Die gelesenen Daten werden in t (Datum/Uhrzeit) und ys
(alles andere) geschrieben. Mit plt.plot und plt.show wird das Diagramm
erstellt und ausgegeben.
Im Diagrammfenster gibt es Buttons, mit denen der Diagramminhalt
verschoben, gezoomt und als Grafikdatei (PNG, SVG, PDF, PS usw.)
gespeichert werden kann. Vor dem Plotten können nach Belieben
Berechnungen, Filterungen u.ä. auf den Daten durchgeführt werden.
Da das Ganze auf Python basiert, kannst du alles, was die Sprache und
die Bibliotheken bieten (und das ist sehr viel), für deine Zwecke
nutzen.
Gerald K. schrieb:> Am besten den "," vor und nicht nach dem Wert schreiben.
Dann habe ich das Problem, dass vor dem ersten Wert auch ein ",". Ich
denke, dass das dann erst recht probleme verursacht.
Mein Problem mit Matplitlib ist, dass ich die Datenverarbeitung auf
einem externen Rechner machen möchte, da der RPi fix am Messaufbau
befestigt ist und deshalb nicht verwendet werden kann.
Matthias P. schrieb:> Mein Problem mit Matplitlib ist, dass ich die Datenverarbeitung auf> einem externen Rechner machen möchte, da der RPi fix am Messaufbau> befestigt ist und deshalb nicht verwendet werden kann.
Was spricht dagegen, es auf dem externen Rechner zu installieren?
Matthias P. schrieb:> Dann habe ich das Problem, dass vor dem ersten Wert auch ein ",". Ich> denke, dass das dann erst recht probleme verursacht.
Dann muss man beim Zeitstempel eine Ausnahme machen und kein
Trennzeichen setzen.
Dagegen spricht, dass man ein anderes Betriebssystem bräuchte (Linux)
oder aber ein Virtual Environment aufsetzen müsste, was für unsere
Anwendung schon wieder zu aufwändig wäre.
Das mit dem Trennzeichen werde ich noch versuchen zu ändern.
Matthias P. schrieb:> Dagegen spricht, dass man ein anderes Betriebssystem bräuchte (Linux)
... oder Windows oder Mac OS ...
Hab's gerade mal unter Windows 7 erfolgreich ausprobiert.
Habe nicht gewusst, dass man Python so einfach mit Windows ausführen
kann. Danke für den Hinweis.
Werde mir die Variante mit Matplotlib noch genauer anschauen und
austesten.
Aber kann man die Daten damit auch noch weiterverarbeiten/analysieren
(gesamtes Maximum, lokale Extremstellen, ...)?
Matthias P. schrieb:> Habe nicht gewusst, dass man Python so einfach mit Windows ausführen> kann.
Hier gibt es den Installer für Windows:
https://www.python.org/downloads/windows/
Bei der Installation kannst du irgendwo ankreuzen, dass Python in die
PATH-Variable eingetragen werden soll. Tu das, denn das erleichtert
anschließend die Verwendung.
Nachdem du Python installiert hast, musst du in einer Kommandozeile noch
Matplotlib mitsamt ein paar Abhängigkeiten installieren:
1
pip install matplotlib
Danach kannst du mit
1
python plot.py
das Programm starten. Die Datei meas0.py liegt dabei im aktuellen
Verzeichnis, und plot.py enthält die weiter oben von mir geposteten
Code-Zeilen.
> Aber kann man die Daten damit auch noch weiterverarbeiten/analysieren> (gesamtes Maximum, lokale Extremstellen, ...)?
(Fast) alles, was du lustig bist. Matplotlib baut u.a. auf der
NumPy-Bibliothek auf, die jede Menge numerischer Algorithmen enthält.
Reicht das nicht, kannst du noch SciPy hinzuinstallieren. Hier ist ein
kleiner Auszug, was dich alles erwartet:
https://docs.scipy.org/doc/scipy/reference/signal.htmlhttps://numpy.org/doc/stable/reference/routines.fft.html
Die von dir gesuchten Funktionen heißen max, min (globale Extrema, in
NumPy), argrelmin und argrelmax (lokale Extrema, in SciPy.signal).
Daneben bringt die Standardinstallation von Python jede Menge nützlicher
Bibliotheken mit. Falls du also auf die Idee kommen solltest, die
Messdaten automatisch per FTP oder HTTP vom RPi herunterzuladen und die
daraus erzeugten Diagramme gleich per E-Mail weiterverschicken zu
wollen, alles kein Problem :)
Matthias P. schrieb:> Gibt es auch die Möglichkeit die Daten zu beschränken (erst ab> Schwellwert darzustellen)?
Selbstverständlich.
Möglichkeit 1: Man setzt die untere Grenze der y-Achse auf den
Schwellwert. Damit liegen alle unerwünschten Werte außerhalb des
Diagramms, wo man sie nicht sehen kann. Beispiel: ylim.py
Möglichkeit 2: Man ersetzt die unerwünschten Werte durch NaNs (not a
number). NaNs werden nicht geplottet, sondern erzeugen Lücken im Plot.
Beispiel: nan.py
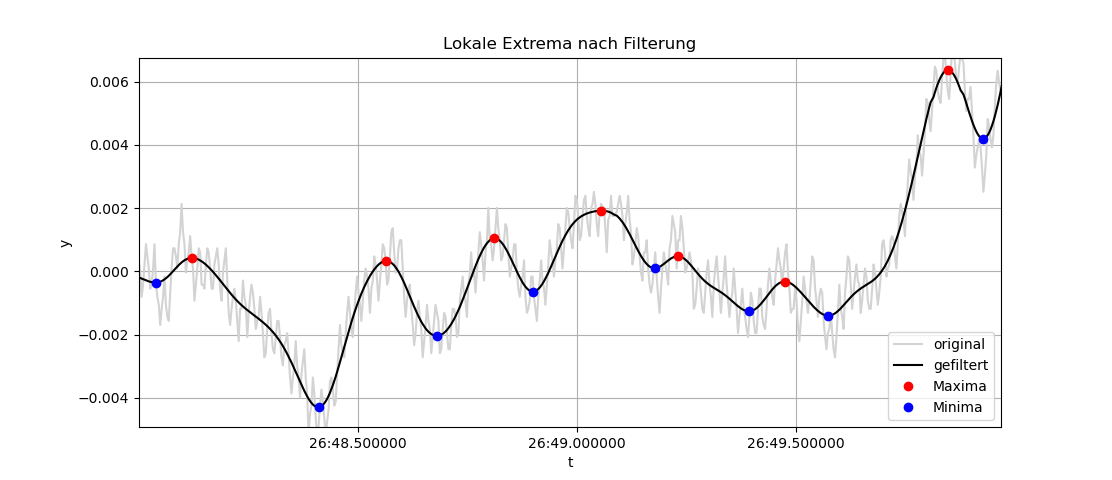
Hier ist noch ein etwas komplizierteres Beispiel, in dem die Daten erst
tiefpassgefiltert und dann die lokalen Extrema bestimmt werden. Des
Weiteren wird das Diagramm beschriftet, Gitterlinien gezeichnet und eine
Legende erstellt: filtext.py
Die Beispiele hier zeigen, was man sonst noch so alles mit Matplotlib
anstellen kann:
https://matplotlib.org/gallery/index.html
Habe die drei probiert und funktionieren einwandfrei.
Gabe aber noch ein paar Fragen:
.)Habe zwar schon über Filter gelernt und weiß, was diese machen, jedoch
wäre es nett, wenn du mir noch erklären könntest, was die beiden
Parameter a und b genau machen.
.)Kann man die Extremstellen dann auch als Koordinaten ausgeben lassen?
.)Wo kann man sagen welche Zeile der CSV Datei dargestellt wird? Bzw.
Könnte man alle 6/12 Werte untereinander abbilden lassen?
.)Wo bzw. wie kann ich die Umrechnung der Werte umsetzne?
.)Könnte ich mein 20 csv Dateien zusammenfassen und auf einmal
darstellen oder würde das das Programm überfordern (10mio Zeilen mit je
13 Werten)?
Vielen Dank bereits jetzt für die ganze Hilfe
Matthias P. schrieb:> Ok danke.> Das mit dem "," vor dem Zeilenumbruch kriege ich leider nicht so einfach> weg, da ich in meinem Programm eine "For-Schleife" laufen lasse, die> nach jedem Wert ein, schreibt und am Zeilenende halt ein "\n".
Falls du C++ verwendest kannst du ab C++11 folgendes verwenden:
1
string str; // dein String
2
....
3
str.pop_back(); // entfernt das letzte ,
4
str +="\n"; // schließt den String mit endl ab.
Für C und sonstige Sprachen musst du den Code entsprechend anpassen,
kannst aber ähnlich vorgehen.
Nano schrieb:> Matthias P. schrieb:>> Ok danke.>> Das mit dem "," vor dem Zeilenumbruch kriege ich leider nicht so einfach>> weg, da ich in meinem Programm eine "For-Schleife" laufen lasse, die>> nach jedem Wert ein, schreibt und am Zeilenende halt ein "\n".>> Falls du C++ verwendest kannst du ab C++11 folgendes verwenden: string> str; // dein String> ....> str.pop_back(); // entfernt das letzte ,> str +="\n"; // schließt den String mit endl ab.>> Für C und sonstige Sprachen musst du den Code entsprechend anpassen,> kannst aber ähnlich vorgehen.
Bei ... steht dann deine For schleife.
Obiges kommt also nach der Schleife.
Wenn die Ausführungsgeschwindigkeit keine Rolle spielt, kannst du
alternativ auch das setzen des ',' Zeichens auf via IF Bedingung lösen.
Dazu einfach prüfen ob es der letzte Schleifendurchlauf ist und dann das
',' nicht setzen.
Noch besser ist es, du setzt das ',' vor dem Messwert in der Schleife.
Dann musst du allerdings den allerersten Messwert vor der Schleife schon
einfügen.
Nano schrieb:> Noch besser ist es, du setzt das ',' vor dem Messwert in der Schleife.> Dann musst du allerdings den allerersten Messwert vor der Schleife schon> einfügen
Das ist sicher die beste Lösung, da der erste Wert kein Messwert ist,
sondern der Zeitstempel.
Den Zeitstempel vor der Schleife ausgeben und anschließend in der
Schleife alle Messwerte.
Wobei sich weder der NumPy-"loadtext"-Import noch Gnuplot an dem
Extra-Komma am Zeilenende stören.
Warum auch, ist ja komplett korrektes und gültiges CSV, nur eben mit
einer leeren Spalte zum Schluss.
Solang der Speicherplatz auf der SD-Karte nicht knapp wird, kann man das
also auch einfach ignorieren und weiterlaufen lassen wie bisher.
Habe das mit der letzten Spalte jetzt geändert. Den Zeitstempel habe ich
einfach separat einschreiben lassen und dann vor die Messwerte das ";"
gehängt.
Danke
Matthias P. schrieb:> .)Habe zwar schon über Filter gelernt und weiß, was diese machen, jedoch> wäre es nett, wenn du mir noch erklären könntest, was die beiden> Parameter a und b genau machen.
Das sind die Filterkoeffizienten, s. hier:
https://docs.scipy.org/doc/scipy/reference/generated/scipy.signal.butter.htmlhttps://de.wikipedia.org/wiki/Filter_mit_unendlicher_Impulsantwort#Rekursive_oder_rationale_Systeme> .)Kann man die Extremstellen dann auch als Koordinaten ausgeben lassen?
Ja, einfach mit print() als Konsolenausgabe oder np.savetxt() in eine
Datei.
> .)Wo kann man sagen welche Zeile der CSV Datei dargestellt wird? Bzw.> Könnte man alle 6/12 Werte untereinander abbilden lassen?
Meinst du Zeilen oder Spalten?
In meinen Beispielen stehen nach dem Einlesen der Daten in t die Zeiten
(eindimensionales Array) und in ys die Messwerte (zweidimensionales
Array). Letzteres kann man entweder als Ganzes an plt.plot() übergeben,
so wie
Yalu X. schrieb:> Hier
oder man extrahiert daraus einzelne Spalten, die dann jeweils getrennt
behandelt werden können, s. dazu diese
Yalu X. schrieb:> Beispiele> .)Wo bzw. wie kann ich die Umrechnung der Werte umsetzne?
Da, wo im obigen nan.py die Zeile
1
y[y < 0.05] = np.nan
steht. Um die Werte zu skalieren und einen Offset zu subtrahieren,
kannst du schreiben:
1
scale_factor = 3.7
2
offset = 1.2
3
y = scale_factor * y - offset
Solche Rechenoperationen werden immer auf das gesamte Array (hier y)
angewandt.
> .)Könnte ich mein 20 csv Dateien zusammenfassen und auf einmal> darstellen oder würde das das Programm überfordern (10mio Zeilen mit je> 13 Werten)?
Prinzipiell ja. Allerdings dauert dann das Laden und Plotten der Daten
sehr lange, und du solltest um die 16 GiB RAM haben, da der Rechner
sonst fast nur noch mit Swappen beschäftigt ist.
Alle 13 × 10 Mio Werte in einem Rutsch zu plotten macht ohnehin wenig
Sinn, da die wenigsten Bildschirme eine horizontale Auflösung von 10 Mio
Pixel haben. Die Daten mit einem bestimmten Faktor auszudünnen ist kein
Problem, aber idealerweise sollte der Ausdünnfaktor dynamisch an den
jeweils eingestellten Zoomfaktor angepasst werden, so dass bei hohem
Zoomfaktor weniger stark ausgedünnt wird und dadurch mehr Details
sichtbar werden. Das macht Matplotlib nicht automatisch, man kann es
aber wahrscheinlich über Event-Handling realisieren.
Das Problem mit den langen Ladezeiten und dem hohen RAM-Verbrauch kann
man evtl. durch Memory-Mapping in den Griff bekommen. Ich habe
diesbezüglich aber keine Erfahrungen.
Was willst du denn mit diesen riesigen Datenmengen konkret machen? Nur
als Plot anschauen? Wenn du soweit hineinzoomst, dass die einzelnen
Messpunkte voneinander unterscheidbar sind, und du dann vom Anfang bis
zum Ende durchscrollst, bist du ja viele Stunden beschäftigt.
Hier noch ein Tip: es gibt für Python einene Zusatz, der Gnuplot
aufruft. D.h. Du kannst Deine Daten mit Python vorverarbeiten und dann
mit Gnuplot grafisch aufarbeiten. Wenn Du Dich mit Python auskennst, ist
das dann ein Klacks, ansonsten: Python ist sehr leicht zu lernen und
läuft auch auf dem Raspi.
https://pypi.org/project/PyGnuplot/
Stefan ⛄ F. schrieb:> Ich empfehle, viele Backups für lange Zeit zu sammeln, denn es kommt ab> und zu auch mal vor, dass man eine kaputte Datei erst nach Monaten> bemerkt. Es wäre zu blöd, wenn das Backup nur eine weitere kaputte Kopie> der Datei enthält.
Dafür habe ich Prüfsummen, die ich für noch funktionierende Dateien
verwende.
Wenn die Prüfsumme dann nicht mehr stimmt, bemerke ich, dass sie kaputt
ist.
In ZFS sind die Prüfsummen auch gleich eingebaut.
Ansonsten ja, man sollte von seinem Backup wenn möglich mehrere
Iterationen haben.
Ganz wichtige Daten gehören zusätzlich noch auf optische Datenträger, da
die keine anfällige Elektronik haben.
Stichwort: Gammablitz und vergleichbares.
Yalu X. schrieb:> Meinst du Zeilen oder Spalten?>> In meinen Beispielen stehen nach dem Einlesen der Daten in t die Zeiten> (eindimensionales Array) und in ys die Messwerte (zweidimensionales> Array). Letzteres kann man entweder als Ganzes an plt.plot() übergeben,> so wie
Ich meine die verschiedenen Spalten untereinander Darstellen lassen.
Sodass die verschiedenen Messwerte mit der selben Zeitskalierung
dargestellt werden.
Bzw. wird bei deinem Beispiel ja nur die 1 Spalte im Diagramm angezeigt.
Wie kann ich dann die 3 und 4 auch noch abbilden?
Ich kann kein Zweidimensionales Array verwenden, da nicht jeder
Kanal/Spalte mit dem gleichen Skalierungsfaktor multipliziert wird,
sonder dieser unterschiedlich ist.
Das mit dem Zusammenfassen der Dateien werde ich dann aber besser sein
lassen, wollte nur für besseren Überblick sorgen.
Wenn das aber so viel RAM benötigt und auch nicht gut dargestellt werden
kann dann lasse ich es bei den 500000 Zeilen pro Datei.
Das mit dem ausgeben lassen über print() habe ich schon verstanden, aber
in welcher Variable werden diese Extremwerte gespeichert.
Die Datenmenge soll nach der Messung analysiert werden. Das heißt die
Punkte bei denen Kräfte-/Spannungsspitzen auftreten müssen genauer
betrachtet werden.
Nano schrieb:> Dafür habe ich Prüfsummen, die ich für noch funktionierende Dateien> verwende. Wenn die Prüfsumme dann nicht mehr stimmt, bemerke ich,> dass sie kaputt ist.
Das schützt nur gegen schlechte Kopien.
Ich meine den Fall, dass die Quelldatei schon kaputt ist. Durch
Fehlfunktionen (Bugs) kommt das ab und zu vor.
Mir ist es mit LibreOffice mehrmals passiert. Da änderst du einen 300
Seiten Text (Buch), speicherst ab, exportierst es als PDF und vergisst
es danach für eine Weile. Bei der nächsten Änderung (vielleicht Wochen
später) fällt dir erst auf, dass du die Datei nicht mehr öffnen kannst.
Es gab auch schon öfters Viren, die Dateien unbrauchbar machen. Wenn du
von so einer kaputten Datei ein exaktes Backup hat, nützt das nichts.
Dann braucht man ein älteres Backup aus einem Zeitraum, wo die Datei
noch nicht kaputt war.
Matthias P. schrieb:> Bzw. wird bei deinem Beispiel ja nur die 1 Spalte im Diagramm angezeigt.> Wie kann ich dann die 3 und 4 auch noch abbilden?
Schau in seinen Code, er hat die Stelle sogar kommentiert:
1
y = ys.T[0] # erste Messreihe
Du musst einfach die anderen Messreihen auch aus den CSV-Daten nehmen,
entsprechend Vorverabeiten wie nötig, und dann auch an den plot-Aufruf
übergeben (der schluckt mehrere Datenreihen auf einmal).
Oder, geht genauso, einfach mehrfach ".plot" ausführen:
1
spannung = ys.T[1]
2
strom=ys.T[2]
3
plt.plot(t, spannung, color=red)
4
plt.plot(t, strom, color=blue)
5
plt.show()
Evtl. ausprobieren:
"ys.T" ruft implizit ein array transpose auf, was bei großen Arrays
speicherintensiv sein könnte.
je nachdem wie gut der python Optimizer arbeitet könnte es besser sein,
"ys.T" nur einmal zu berechnen und zwischenzuspeichern. --> benchmark.
Matthias P. schrieb:> Wenn das aber so viel RAM benötigt und auch nicht gut dargestellt werden> kann dann lasse ich es bei den 500000 Zeilen pro Datei.
Du kannst den Speicherverbrauch auch zeitlich staffeln, die "meas*.csv"
nacheinander laden, jeweils einzeln die Werte reduzieren
(z.B. jeweils X werte durch ihren Durchschnitt ersetzen geht mit
array.reshape, danach numpy.mean darauf, oder mit was passendem aus
scipy)
und nur die reduzierten Werte im Speicher halten um sie anschließend zu
plotten.
Matthias P. schrieb:> Das mit dem ausgeben lassen über print() habe ich schon verstanden, aber> in welcher Variable werden diese Extremwerte gespeichert.
die Zeitstempel der Extremwerte in maxima und minima.
die Datenwerte zu den jeweiligen Zeitstempeln in deinem Datenarray.
du könntest dir z.B. um eine oder jede der lokalen Extremstellen einen
Zeitbereich aussuchen, und nur den plotten.
Die Zeile mit ys.T[] habe ich wohl übersehen. Habe schon nach so einer
Zeile gesucht aber wohl einfachh überflogen.
Was gemeint ist mit zeitlich staffeln habe ich nicht ganz verstanden.
Meinst du, dass ich die Dateien in einem Programm nacheinander laden
soll?
Das mit den Extremwerten ausgeben funktioniert jetzt auch. Danke.
Noch zwei Fragen zu matplotlib:
.)Kann man beim Diagramm eine Art Checkbox machen die man ankreuzen
kann, um auszuwählen welche Linien man abgebildet haben will?
.)Gibt es eine Möglichkeit auf die erstellte Linie zu klicken und dann
den Punkt auf den man geklickt hat auszugeben? Mein Problem ist nämlich,
dass meine Zeitangabe auf Millisekunden genau ist und dann anscheinend
nicht abgebildet werden kann.
Εrnst B. schrieb:> "ys.T" ruft implizit ein array transpose auf, was bei großen Arrays> speicherintensiv sein könnte.
Das ist kein Problem, da NumPy bei solchen Operationen die Rohdaten
nicht kopiert.
> spannung = ys.T[1]> strom=ys.T[2]
Auch spannung und strom greifen auf die Originaldaten von ys zu.
Man kann die drei Spalten von ys auch in einem Rutsch extrahieren:
1
kraft, spannung, strom = ys.T
Dabei muss die Anzahl der Variablen auf der linken Seite exakt mit der
Anzahl der Spalten von ys übereinstimmen. Möchte man einzelne Spalten
nicht weiter verarbeiten, kann man dafür eine Dummy-Variable verwenden:
1
kraft, _, strom = ys.T
Matthias P. schrieb:> .)Kann man beim Diagramm eine Art Checkbox machen die man ankreuzen> kann, um auszuwählen welche Linien man abgebildet haben will?
Ja, hier gibt es ein Beispiel dazu:
https://matplotlib.org/gallery/widgets/check_buttons.html> .)Gibt es eine Möglichkeit auf die erstellte Linie zu klicken und dann> den Punkt auf den man geklickt hat auszugeben? Mein Problem ist nämlich,> dass meine Zeitangabe auf Millisekunden genau ist und dann anscheinend> nicht abgebildet werden kann.
Ja, auch dafür findet sich ein Beispiel:
https://stackoverflow.com/questions/22052532/matplotlib-python-clickable-points
Nachdem du gesehen hast, dass Python, NumPy und Matplotlib deine
Anforderungen ganz gut erfüllen, wäre es IMHO an der Zeit, etwas tiefer
in die Materie einzusteigen. Hier findest du gute Tutorials dazu:
https://docs.python.org/3/tutorial/index.htmlhttps://numpy.org/doc/stable/https://matplotlib.org/tutorials/index.html
Du musst dabei nicht sofort alle Tutorials bis zum Ende durchexerzieren,
sondern immer nur soweit, dass du beim nächsten nicht mehr nur Bahnhof
verstehst. Dann kommst du recht schnell zu ersten Erfolgserlebnissen.
Für konkrete Fragen kannst du auch Google bemühen. Da Matplotlib
ziemlich verbreitet ist, stehen die Chancen gut, dass irgendjemand
dieselbe Frage schon einmal auf stackoverflow.com gestellt und eine
Antwort darauf erhalten hat. Vieles wird auch in der umfangreichen
Beispielsammlung geklärt:
https://matplotlib.org/gallery/index.html
Schön, dass du dich für Python entschieden hast.
Und noch schöner, dass Yalu dir so detailiert helfen kann,
seine Antworten übersteigen mein Wissen bei weitem...
Einen habe ich aber noch:
Matthias P. schrieb:> Ich meine die verschiedenen Spalten untereinander Darstellen lassen.> Sodass die verschiedenen Messwerte mit der selben Zeitskalierung> dargestellt werden.https://matplotlib.org/3.1.0/gallery/subplots_axes_and_figures/shared_axis_demo.html
c-hater schrieb:> Wenn man zuerst Code eintippt (nämlich zur "Verdichtung" umfangreicher> Messreihen) und dann erst anfängt mit Diagrammen zu hantieren, dann> klappt das mit Excel wunderbar und ist ideal für interaktive> Auswertungen.>> Was man von dem ganzen OSS-Geraffel, weiß Gott, nicht behaupten kann...
LOL!
> Übrigens: den nötigen VBA-Code habe ich schneller eingetippt und> signiert als ich Zeit brauche, um auch nur eine Übersicht über die> Kommandozeilenoptionen von gnuplot zu gewinnen...
Ja, weil Du ein Ritter der Excel-Runde bist und drölfundneunzig
Millionen Jahre an Erfahrung damit hast. Ich hingegen analysiere
Massendaten schon ähnlich lange, und halte es für unfaßbar dämlitsch,
eingelesene Rohdaten erstmal in große, grafische Objekte wie
Tabellenzellen umzuwandeln.
Diese OSS-Spinner haben für die Analyse und Visualisierung von
Massendaten in CSVs schon einen Haufen fertiger Werkzeuge, die Deine
Excel-und-VBA-Spielzeuge in jeder Hinsicht locker in den Schatten
stellen. Da wäre zum Beispiel -- auf einem extrem einfachen Niveau --
das csvkit [1], das die Daten schon gelesen, verarbeitet und aggregiert
hat, bevor Dein Excel überhaupt gestartet ist.
Statt dieser einfachen Lösung sind heute in den meisten professionellen
Bereichen entweder kommerzielle Lösungen wie SAS [2] oder Qlik [3] in
Verwendung, meistens jedoch Software wie Orange[4], Tableau [5], SpagoBI
[6], RapidMiner [7], KNIME [9], JasperReports [9], Helical Insight [10]
oder natürlich das gute alte BIRT [11]. In letzter Zeit sehr ich auch
immer häufiger einen echten Allrounder, den ELK-Stack [12] aus
Elasticsearch, Logstash und Kibana. Ab Orange übrigens alles OSS, einige
verkaufen zudem kommerzielle Erweiterungen ihrer Software.
Wer noch ein bisschen mehr Flexibilität oder Leistung will als mit den
vorgenannten Fertig-Werkzeugen, kommt heute wahrscheinlich nicht mehr um
Python herum. Dort gibt es für die interaktive Datenanalyse das
Pandas-Framework [13], das -- wer wirklich Dampf braucht -- auch gerne
mit verteilten High-Performance-Frameworks wie Apache Hadoop, Apache
Spark, Apache Arrow, Redis etc. zusammenarbeitet, zur interaktiven
Visualisierung das altbekannte matplotlib [15], das moderne Bokeh [15]
und weitere nutzen kann, und mit Jupyter und iPython über ausgesprochen
moderne, leistungsfähige interaktive Frontends genutzt werden kann.
Mit Ausnahme von SAS und Qlik ist übrigens alles, was ich hier genannt
habe, ganz oder allergrößtenteils OpenSource-Software. Und ich wette:
alles, was Du mit Excel kannst, mache ich mit Python und Pandas in einem
Zehntel der Zeit -- einhändig.
Ach ja, und mit richtigen Datensätzen hast Du mit Deinem Excel ohnehin
keinerlei Chance. Das kann ja gerade mal eine popelige Million
Datensätze mit maximal 16k Spalten -- und höchstens 255 Zeichen pro
Feld. ;-)
[1] https://csvkit.readthedocs.io/en/latest/
[2] https://www.sas.com/de_de/software/stat.html
[3] https://www.qlik.com/us/
[4] https://orange.biolab.si/
[5] https://public.tableau.com/s/
[6] https://www.spagobi.org/
[7] https://rapidminer.com/
[8] https://www.knime.com/
[9] https://community.jaspersoft.com/project/jasperreports-server
[10] https://www.helicalinsight.com/
[11] https://www.eclipse.org/birt/
[12] https://www.elastic.co/de/what-is/elk-stack
[13] https://pandas.pydata.org/
[14] https://matplotlib.org/
[15] https://docs.bokeh.org/en/latest/
Stefan ⛄ F. schrieb:> Peter M. schrieb:>> Jemand, der ganz viele Sprachen kennt, kann bestimmt sagen, welches das>> beste Werkzeug für dieses Problem ist.>> Kann ich die sagen: Es ist die, die du am besten beherrschst.
Das stimmt!!1!
Aber wenn man keines beherrscht, was nimmt man dann? Heutzutage geht die
Wahl immer häufiger zu dem, was die Profis in Wissenschaft und
Wirtschaft nutzen: Python, mit seinem exzellenten Ökosystem, seiner
hohen Performance und seinen fast unbegrenzten Möglichkeiten. Warum auch
nicht? ;-)
Yalu X. schrieb:> Dinge wie die Visualisierung von Messdaten liegen einfach nicht im Fokus> von Microsoft,
Äh, schon, es gibt da eine Software namens "Microsoft Power BI". Aber
ich habe bei Profis noch nie gesehen oder gehört, daß die einer
benutzt... "\(".)/"
Matthias P. schrieb:> Verzeihung, dass ich solange keine Rückmeldung gegeben habe.> Danke erstmal für die ganzen Hilfestellungen>> Soweit ich das jetzt verstanden habe sind die sinnvollsten Lösungen> Gnuplot und Excel.
Ach, diesbezüglich kann man unterschiedliche Ansichten vertreten.
Gnuplot ist eine tolle und sehr leistungsfähige Software, die ich lange
und oft für verschiedenste Visualisierungen benutzt habe... aber es ist
ein wenig in die Jahre gekommen, und heutzutage gibt es deutlich
leistungsfähigere Möglichkeiten.
Dreisterweise habe ich mir mal den Spaß gegönnt, ein kleines Programm zu
schreiben, das Deine Daten einliest und die Daten als Lineplot
visualisiert. Das Programm ist geradezu riesig, unfaßbar:
1
#!/usr/bin/env python
2
fromargparseimportArgumentParser
3
4
importpandasaspd
5
importmatplotlib.pyplotasplt
6
7
8
if__name__=='__main__':
9
parser=ArgumentParser(description='plot a nice diagram from CSV data')
Wenn dieses Programm läuft, stellt es Deine Datei (bei mir) in unter
zwei Sekunden dar, wie in der angehängten Datei "gestartet.png" gezeigt.
Es ist eine interaktive Darstellung, die -- zum Beispiel -- maximiert
werden kann (siehe "maximiert.png"), oder in der natürlich auch
bestimmte Bereiche ausgewählt und genauer betrachtet werden können,
gezeigt in "zoom.png".
Das Progrämmchen hat gerade mal sechs spannende Zeilen: die Imports von
pandas und matplotlib, das Lesen und Konfigurieren der CSV-Datei und
ihrer Daten, das Erzeugen eines Lineplot und dessen Darstellung.
Das Ganze kostet auf meinem > zehn Jahre alten Q9650 gute eineinhalb
Sekunden, in der Zeit ist Excel auf einer aktuellen Büchse nichtmal
gestartet... ;-)
> Die Funktion sollte sein, dass wenn ich auf die CSV-Datei Doppelklicke> die Werte im ersten Zug umgerechnet werden sollen und dann grafisch> dargestellt.
Ich... weiß nicht genau, was Dein Betriebssystem bzw. Desktop da
anbietet. Unter Windows ist es üblicherweise so, daß das System anhand
der Dateinamenerweiterung (hier: 'csv') "erkennt", was für eine Datei
das ist und mit welchem Programm die Datei geöffnet werden soll. Soweit
ich weiß (ich kenne mich mit Windows überhaupt nicht aus, das können
hier andere besser beantworten) ist die Zuordnung wohl auch eindeutig --
womöglich müßtest Du Dir eine eigene Dateinamenerweiterung für Deine
CSV-Dateien ausdenken und die dann mit dem betreffenden Programm
verknüpfen.
> Des weiteren sollen die Daten minimalisiert werden, also dass zum> Beispiel nur die Werte über einer bestimmten Schwelle dargestellt> werden.
Klar, das geht alles. Für genau solche Dinge ist Pandas gemacht worden.
> Könnte man das dann auch irgendwie machen, dass wenn man die meas0.csv> Datei öffnet, alle anderen automatisch Verarbeitet werden?
Ja, mit Python wäre das natürlich ganz einfach: Du würdest statt des
Dateinamens (parser.add_argument('filename') im Programm oben einfach
ein Verzeichnis angeben. Das Programm würde dann alle Dateien aus diesem
Verzeichnis einlesen -- oder Dir einen Dialog zur Auswahl der Dateien
aus diesem Verzeichnis anbieten, oder...
> Im Anhang habe ich noch eine neue .csv-Datei angehängt, bei in der jetzt> richtige Messwerte gespeichert sind.
;-)
Aber bleiben wir realistisch: nur um mal schnell ein paar Daten zu
plotten, dürfte es sich nicht lohnen, eine neue Programmiersprache zu
lernen -- und schon gar nicht fette Profisoftware wie Pandas und die
darunterliegenden Bibliotheken numpy und scipy. Sowas lohnt sich nur
dann, wenn Du mittelfristig sehen kannst, daß Du noch andere Ideen hast.
Aber wenn Du noch andere Ideen hast, dann ist Python sicherlich eine
hervorragende Wahl mit unendlichen Möglichkeiten. YMMV.
Matthias P. schrieb:> Dagegen spricht, dass man ein anderes Betriebssystem bräuchte (Linux)> oder aber ein Virtual Environment aufsetzen müsste, was für unsere> Anwendung schon wieder zu aufwändig wäre.
Das halte ich für ein Gerücht. Python läuft ganz wunderbar unter Windows
und MacOS, inklusive numpy, scipy, Pandas und matplotlib...
Nebenbei: was ist eigentlich so ein Docker-Image? ;-)
Yalu X. schrieb:> Matthias P. schrieb:>> Habe nicht gewusst, dass man Python so einfach mit Windows ausführen>> kann.>> Hier gibt es den Installer für Windows:>> https://www.python.org/downloads/windows/
Wer Spaß mit Python und Daten unter Windows haben möchte, nimmt meist
Anaconda [1] und dessen Paketmanager conda. Mir sind sogar eine ganze
Reihe Linux-User bekannt,
die das benutzen... ;-)
[1] https://www.anaconda.com/> Nachdem du Python installiert hast, musst du in einer Kommandozeile noch> Matplotlib mitsamt ein paar Abhängigkeiten installieren:>>>
1
> pip install matplotlib
2
>
>> Danach kannst du mit>>
1
> python plot.py
2
>
>> das Programm starten. Die Datei meas0.py liegt dabei im aktuellen> Verzeichnis, und plot.py enthält die weiter oben von mir geposteten> Code-Zeilen.
Warum eigentlich nicht Jupyter oder wenigstens iPython? ;-)
> Die von dir gesuchten Funktionen heißen max, min (globale Extrema, in> NumPy), argrelmin und argrelmax (lokale Extrema, in SciPy.signal).>> Daneben bringt die Standardinstallation von Python jede Menge nützlicher> Bibliotheken mit.
Ja, min() und max() sind -- wie viele andere -- sogar Builtins! ;-)
> Falls du also auf die Idee kommen solltest, die> Messdaten automatisch per FTP oder HTTP vom RPi herunterzuladen und die> daraus erzeugten Diagramme gleich per E-Mail weiterverschicken zu> wollen, alles kein Problem :)
Ansible! ;-)
Yalu X. schrieb:>> .)Könnte ich mein 20 csv Dateien zusammenfassen und auf einmal>> darstellen oder würde das das Programm überfordern (10mio Zeilen mit je>> 13 Werten)?>> Prinzipiell ja. Allerdings dauert dann das Laden und Plotten der Daten> sehr lange, und du solltest um die 16 GiB RAM haben, da der Rechner> sonst fast nur noch mit Swappen beschäftigt ist.
Das Schöne an modernen Bibliotheken wie numpy, scipy und Pandas ist, daß
die Daten direkt in ein Binärformat gelesen werden können. "0.3412565"
ist dann intern nicht mehr ein String, sondern ein float64... ;-)