Hallo Leute, es geht um eine Linearisierung einer Kennlinie. Die Kennlinie hat ein lineares Verhalten jedoch aufgrund von Störeinflüssen ist sie nichtlinear. Die nichtlineare Kennlinie hat 20 Stützstellen. Die Frage ist, wie kann ich möglichst einfach diese Kennlinie linearisieren sodass der Linearitätsfehler unter einem Prozent bleibt. Ich hab alles möglich schon gelesen und es scheint einfach zu sein, nur komm ich irgendwie nicht rein. Die erste Idee war lineare Regression, jedoch war das noch zu ungenau. Oft lese ich, das man die Umkehrfunktion anwenden muss, wie genau muss ich die Umkehrfunktion anwenden, ich verstehe hier den Zusammenhang zur Linearisierung nicht? Weiterhin sind mir Interpolations-Methoden wie Lagrange und Newton begegnet die eingesetzt werden könnten, das scheint jedoch aufgrund hohem Rechenaufwand nicht Sinnvoll zu sein. Und letztendlich bin ich zu der stückweisen linearen Spline Interpolation gekommen. Ich steh momentan auf dem Schlauch und weiß nicht wie ich hier am besten anfangen soll. Hoffe ihr könnt ein wenig Licht in Dunkel bringen. VG
Wer 20 Stützstellen hat, hat 19 gerade Strecken. Die Geradengleichung kannst du hoffentlich rechnen und hast dann zu jedem Messwert direkt seinen korrigierten Wert. Es macht keinen Sinn, andere Annahmen über den Verlauf zu treffen, wie Splines oder Gerade der linearen Regression. Es sei denn, deine Stützstellen umgibt man mit Fehlerbereichen und man weiss, dass die physikalische Realität hinter der Messung lineare Zusammenhänge ergeben muss.
Walter A. schrieb: > Ich steh momentan auf dem Schlauch und weiß nicht wie ich hier am besten > anfangen soll. Was ist denn die Zielsetzung, und zwar ganz konkret? Walter A. schrieb: > Die Kennlinie hat ein > lineares Verhalten jedoch aufgrund von Störeinflüssen ist sie > nichtlinear. Im Klartext: Die Messwerte stellen einen nichtlinearen Zusammenhang dar. Du suchst kein Interpolationsverfahren, du suchst ein Verfahren, um den Störeinfluss zu kompensieren oder zu filtern, und danach wird wahrscheinlich ein ziemlich simples Verfahren für lineare Regression.
Heiner schrieb: > Was ist denn die Zielsetzung, und zwar ganz konkret? Es soll eine Sensorkennlinie linearisiert werden. Ich soll dazu ein Algorithmus schreiben der die Kennlinie mithilfe von 20 Stützstellen linearisiert und ggfls. optimiert da ein absoluter Linearitätsfehler über die gesamte Kennlinie unter 1% erreicht werden soll. Der Ansatz von MaWin mit den 19 Geradengleichungen habe ich so auch schon empfohlen bekommen, jedoch war da noch was mit der Umkehrfunktion, wo mir der Zusammenhang fehlt. Wenn zwischen den Stützstellen einfach linear interpoliert wird, dann muss die gesamt Kennlinie nicht zwangsläufig linear sein, jedoch ist das die Anforderung (Linearitätsfehler).
M. K. schrieb: > wie kann ich möglichst einfach diese Kennlinie linearisieren sodass > der Linearitätsfehler unter einem Prozent bleibt. Das ist einfach. Dazu brauchst Du nur 0,8% Linearisierungssalz.
M. K. schrieb: > Die Kennlinie hat ein > lineares Verhalten jedoch aufgrund von Störeinflüssen ist sie > nichtlinear Was für Störeinflüsse sind das denn? Und warum sind sie reproduzierbar? Wenn sie reproduzierbar und bekannt sind, dann reicht vielleicht auch nur eine oder 2 Stützstellen und ein wenig mehr rechnen.
M. K. schrieb: > Die nichtlineare Kennlinie hat 20 Stützstellen Wichtige Frage: ist die Kennlinie immer die gleiche oder ist die bei jedem Gerät verschieden? Georg
georg schrieb: > M. K. schrieb: >> Die nichtlineare Kennlinie hat 20 Stützstellen > > Wichtige Frage: ist die Kennlinie immer die gleiche oder ist die bei > jedem Gerät verschieden? > > Georg So, mein Ahnungsloser! Annahme die Kurve sei Sinusförmig. Wo würdest Du die Stützstellen implementieren?
OldHenry schrieb: >> Wichtige Frage: ist die Kennlinie immer die gleiche oder ist die bei >> jedem Gerät verschieden? >> >> Georg > > So, mein Ahnungsloser! Was für eine hochqualifizierte Pöbelei. Eine sachliche Begründung für meine Frage wäre völlig unangebracht, weil du die sowieso nicht verstehen könntest. Georg
OldHenry schrieb: > So, mein Ahnungsloser! Gegenannahme: Du bist nicht nur ein Troll sondern hast etwas Ahnung. Warum hilfst du dann nicht sondern provozierst nur?
Um zu sehen, was für dich genügt, reicht es vielleicht schon, die Wertepaare in Excel einzutragen und zu markieren, eine grafische Darstellung mit Einfügen, Diagramme Punkt zu erhalte. Dort kannst du das verschiedene Ausgleichsfunktionen ausprobieren und schauen, ob es dir gefällt. Man kann die Funktion sich im Diagramm einblenden lassen, aber alternativ die RGP Funktion von Excel verwenden. Man kann ja bei Regressionsrechnungen nicht nur linear, sondern mit Polynomen höherer Ordnung rechnen. Die Mathematik ist halt bisschen aufwendiger.
Tut mir leid wenn ich mich zu unpräzise Ausdrücke. Ich muss dazu sagen das ich das auch nur theoretisch mache. Ich habe keine Messreihe aus der Praxis. Es sind verschiedene Kennlinien die optimiert (linearisiert) werden müssen. Hier zum Beispiel eine mögliche Messreihe die ich einfach linearisieren möchte so das ich eine bestimmte Linearität erreiche. Die Messpaare sind dabei meine Stützstellen. Das ganze soll mithilfe von Stützstellen passieren. Es soll ein möglichst einfacher Rechenprozess für den µC werden. Polynome höheren Grades wären, so wie ich das verstanden habe, aufgrund der vielen Koeffizienten zu aufwändig.
Was ist jetzt an linearer Regression nicht passend? Wenn die Kennlinie linear ist, wird es nicht genauer und wenn die Stützstellen halbwegs äquidistant sind, ist auch die Konditionszahl kein großes Problem, so dass Gleitkommazahlen einfacher Genauigkeit ausreichen. Bei äquidistanten Stützstellen kann man sogar etliche Werte vorberechnen, dass statt dem GEV nur noch eine einfache Matrix-Vektor-Multiplikation nötig ist (wobei die Matrix nur Konstanten enthält). Bei pathologischen Ausreißern kann man noch ein wenig herausholen, wenn man zwei Durchgänge macht. Aber im Großen und Ganzen ist lineare Regression für eine polynomiale Kennlinie optimal.
@TO: ist deine Frage ich wünsch mir was? Oder hat dich jemand dazu beauftragt? Ist das eine Hausaufgabe? Also jetzt mal Butter bei die Fische! Drück dich klar aus das jeder hier deine Fragen versteht.
Walter T. schrieb: > Was ist jetzt an linearer Regression nicht passend? Damit könnte der TO eine Gerade an seine Messpunkte anpassen. Aber das will er nicht, obwohl sich große Teile seiner Beiträge tatsächlich so lesen. Sondern er will eine mathematische Beschreibung seiner tatsächlich nichtlinearen Kennlinie bestimmen. Und die soll so ausreichend einfach sein, damit er seine später aufgenommenen Messwerte ohne viel Rechenaufwand auf eine lineare Skala zurückrechnen kann. (Daher seine Fragen zum Einsatz der "Umkehrfunktion"). Walter T. schrieb: > Wenn die Kennlinie > linear ist, wird es nicht genauer Ist sie leider nicht. Die Aussage im Eröffnungsthread M. K. schrieb: > Die Kennlinie hat ein > lineares Verhalten jedoch aufgrund von Störeinflüssen ist sie > nichtlinear. war etwas irreführend.
Deine Messpunkte haben doch schon einige Ausreißer. Wenn du eine mathematische Beschreibung suchst um über eine Funktion die Daten umzurechnen wird das jedenfalls nicht so ohne weiteres gehen wenn der Fehler klein sein soll. Allerdings ist es etwas verwirrend was du jetzt genau willst. Soll X in Y oder Y in X umgerechnet werden? Grundsätzlich wenn du eine mathematische Funktion brauchst sollte es ein Polynom 3. oder 4. grades tun, alternative über Sinussummen. Jenachdem kann man die Messwerte noch skalieren um die Koeffizienten "schöner" zu bekommen. Wenn es bei einem float bleibt sollte ein moderner µC mit FPU damit wenig Probleme haben.
Finde die Angabe des OPs recht klar. Er hat ne nichtlineare Kennlinie und will diese linearisieren. Wer damit nix anfangen kann ist hier falsch, denn das ist ne Standard Aufgabe. Voraussetzung: die Nichtlinearität ist reproduzierbar! Umkehrfunktion ist auch korrekt. Du bildest die aktuelle Kennlinie y der Funktion f(x) ab. x ist deine unabhängige Variable, deine "wahren Werte", f eine beliebige Funktion zur Approximierung und y eben deine Messwerte. Wenn du y=f(x) hast, suchst du aber ja das umgekehrte. Du hast den Messwert und suchst aber den tatsächlichen Wert. Also brauchst du eine Umkehrfunktion x=g(y). Damit schließt du vom gemessenen Wert auf den wahren. Die Funktion zu bestimmen ist nicht immer möglich und nicht unbedingt einfach, gerade bei periodischen funktioniert das z.B. nicht. Aber das ist das Konzept. Wenn du Fragen hast, frag ;)
Achim S. schrieb: > Sondern er will eine mathematische Beschreibung seiner tatsächlich > nichtlinearen Kennlinie bestimmen. Und die soll so ausreichend einfach > sein, damit er seine später aufgenommenen Messwerte ohne viel > Rechenaufwand auf eine lineare Skala zurückrechnen kann. (Daher seine > Fragen zum Einsatz der "Umkehrfunktion"). Das ergibt aber auch wenig Sinn. Wenn ich die Abbildung Meßwerte (m) -> Echtwerte (e) benötige, stelle ich doch auch die richtige Funktion e(m) (auf welchem Weg auch immer) auf, anstelle erst m(e) zu approximieren und dann die Umkehrfunktion zu bilden. Ich kenne keinen einzigen Ansatz (egal ob polynomial, stückweise, sinus ...) bei dem die Umkehrfunktion annähernd so einfach wie die Approximationsfunktion ist. (Stückweise lineare Lagrange-Polynome mal aussen vor ... und selbst da nur in bestimmten Fällen). Und was daran "linearisieren" ist, verstehe ich auch immer noch nicht. (Vielleicht wird das klarer, wenn man die Werte sieht. Ich habe hier kein Office.) Wird die erste Ableitung benötigt?
Walter T. schrieb: > (auf welchem Weg auch immer) Genau das ist das Problem des TO: er fragt nach dem Weg, um auf die "richtige" Funktion e(m) zu kommen. Er hat nur seine Messwertpaare, die sich nicht unbedingt einfach durch eine simple Funktion beschreiben lassen. Jan schrieb: > Die Funktion zu bestimmen ist nicht immer möglich und nicht unbedingt > einfach, gerade bei periodischen funktioniert das z.B. nicht. Aber das > ist das Konzept. > > Wenn du Fragen hast, frag ;) Na, dann stelle ich für den TO die Frage: wie findet er die geeignete Funktion für sein Zahlenbeispiel von 20 Messwerten?
Achim S. schrieb: > Na, dann stelle ich für den TO die Frage: wie findet er die geeignete > Funktion für sein Zahlenbeispiel von 20 Messwerten? Schritt 1: Punktewolke als X-Y-Plot darstellen und angucken.
-> geeignete Stützstellensuche (!) durchführen, um die Linearisierung möglichst gut/wenig Fehlerabweichung der ursprünglichen Kurve anzupassen -> Lookuptable für die Stützstellen aufstellen (Wertepaare) -> dann lineare Approximation zwischen zwei Stützstellen durchführen .... Voila !
Beitrag #6455591 wurde von einem Moderator gelöscht.
Beitrag #6455592 wurde von einem Moderator gelöscht.
Beitrag #6455616 wurde von einem Moderator gelöscht.
Achim S. schrieb: > Walter T. schrieb: >> (auf welchem Weg auch immer) > > Genau das ist das Problem des TO: er fragt nach dem Weg, > um auf die "richtige" Funktion e(m) zu kommen. Er hat > nur seine Messwertpaare, die sich nicht unbedingt einfach > durch eine simple Funktion beschreiben lassen. Naja, ich denke, Du kennst -- im Gegensatz zum TO -- die Antwort schon: Im allgemeinen Falle lautet sie nämlich "Gar nicht!". Was die "richtige" mathematische Beschreibung (eine Funktion ist ja eine solche) für einen realen Sachverhalt ist, das ist keine mathematische oder numerische Frage. Die Numerik liefert nur die Antwort, wie gut ein abstraktes Modell auf einen konkreten, durch Zahlen beschriebenen Sachverhalt passt -- aber das abstrakte Modell muss man sich halt vorneweg schon ausgedacht haben. > Na, dann stelle ich für den TO die Frage: wie findet > er die geeignete Funktion für sein Zahlenbeispiel von > 20 Messwerten? Naja, vielleicht ist er schon zufrieden, wenn er die Rollen von Argument und Funktionswert vertauscht und dann einen Spline (im einfachsten Falle einen Polygonzug) interpoliert. Wer weiss schon, was für ihn "geeignet" ist?
MaWin schrieb: > Es macht keinen Sinn, andere Annahmen über den > Verlauf zu treffen, wie Splines oder Gerade der > linearen Regression. Naja, eine stetige erste Ableitung kann manchmal schon angenehm sein; da ist der Spline höherer Ordnung dem einfachen Polygonzug überlegen. Der Wunsch wäre schon plausibel, auch wenn man die Physik hinter den gegebenen Stützstellen nicht kennt.
Angehängte Dateien:
-

Punktwolke.png
15 KB
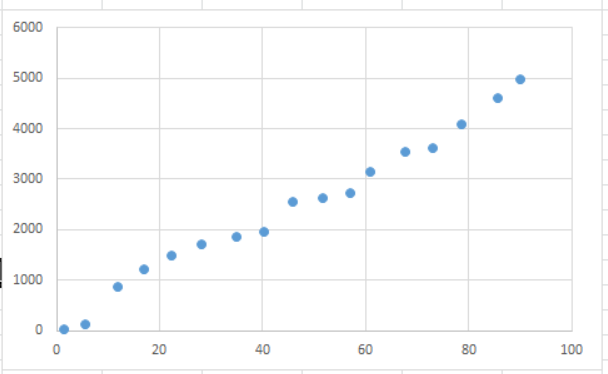
Egon D. schrieb: > Naja, ich denke, Du kennst -- im Gegensatz zum TO -- die > Antwort schon: Im allgemeinen Falle lautet sie nämlich > "Gar nicht!". so ist es. Im Anhang mal die Punktewolke des TO (für diejenigen, die das xlsx-File öffnen können oder wollen). Wenn man nicht weiß, wodurch sich z.B. der "Sprung" der Stützwerte bei x=40 ergibt, dann kann man nur raten wie der echte Verlauf der Kurve zwischen x=40 und x=45 aussieht. Mit wolchen Ratereien erreicht man nicht den vom TO gewünschten Linearitätsfehler von <1%. Wenn man weiß, wodurch sich der Sprung ergibt (z.B. durch eine Messbereichsumschaltung bei x=42), dann kann man diese Wissen in die Modellierung der Kennlinie einfließen lassen und die "echte" Formel der Kennlinie an die Messwerte anpassen.
Achim S. schrieb: > (für diejenigen, die das > xlsx-File öffnen können oder wollen). sollte natürlich heißen: die das xlsx-File nicht öffnen können oder wollen
Eine Frage der hoeheren Koeffizienten. Es gibt verschiedene Moeglichkeiten. Approximierend oder Interpolierend. Beim Zweiten geht die Funktion durch die Punkte. Beim ersten in der Naehe durch. Erst mal muss so eine Funktion konvergieren. Meiner Erfahrung nach sollte man nicht zu hoch mit dem Grad des Polynoms gehen. Vielleicht 6 ter Ordnung. Am Schnellsten wird so ein Polynom als Integer gerechnet. Alternativ kann man auch ueberlappende Splines legen. Allenfalls gehen auch lineare interpolationen. Etwas Mathe ist notwendig fuer eine gute Loesung. Irritierend fand ich die Nichtlinearitaet aufgrund von Stoereinfluessen. Sind die Konstant ? Falls nicht, kannst das Ganze in die Tonne werfen.
Geht es darum, eine geschlossene Funktion zu finden, oder nur eine
schöne Kurve zeichnen zu können?
>stückweise lineare Spline Interpolation
liefert nur schöne glatte Kurven aber keine Funktion.
Soll die Funktion exakt durch alle Kurvenpunkte laufen oder darf sie
auch nahe daran vorbeigehen?
Pandur S. schrieb: > Falls nicht, kannst das Ganze in die Tonne werfen Ja, aber das wird dann mangels sonstiger Information recht einfach: linear in dem Intervall interpolieren in dem der aktuelle Messwert liegt. Wie linear das global ist ist eine sinnlose Frage wenn man zufällig gestreute Stützpunkte hat. Die Daten des TO entsprechen sicher keiner realen Messeinrichtung, sondern sind reine Phantasie. Womit wir beim Trollen wären. Die Frage ob die Nichtlinearität immer die gleiche ist, habe ich vor langem auch schon gestellt, aber der TO versteht schon die Frage nicht. Übrigens ist nicht von Interesse, ob die Ergebnisfunktion linear ist, sondern wie weit sie vom realen Werteverlauf abweicht. Die ist z.B. bei einem Pt100 bekannt und aus den Tabellen kann man jederzeit geeignete Stützpunkte auslesen, da ist eine Aproximation mit einem Polynom 3.Grades kein Problem, bzw. man kann sich zu jeder gewünschten maximalen Abweichung in jedem gewünschten Intervall eine geeignetes Polynom schnitzen. Und das konnte bei mir auch schon ein alter Z80 locker berechnen. Georg
Hallo,sin um ein Urteil abzugeben muss man wissen, woher Störung kommt. Ist eine Störfrequenz vorhanden so könnte man mit mit sin(x)/x arbeiten. Ist aber die Störung ein Ausreißer, z.B. Zündung an einem Verbrennungsmotor, würde ich einen schleifenden Medianwert hernehmen. Also: Woher kommt das Störsignal? Sonst ist das alles ein Stochern im Nebel. Ich halte es auch für unbedingt notwendig, dass wir das Signal auch sehen dürfen.
Hallo, um ein Urteil abzugeben muss man wissen, woher Störung kommt. Ist eine Störfrequenz vorhanden so könnte man mit mit sin(x)/x arbeiten. Ist aber die Störung ein Ausreißer, z.B. Zündung an einem Verbrennungsmotor, würde ich einen schleifenden Medianwert hernehmen. Also: Woher kommt das Störsignal? Sonst ist das alles ein Stochern im Nebel. Ich halte es auch für unbedingt notwendig, dass wir das Signal auch sehen dürfen.
Walter T. schrieb: > Achim S. schrieb: >> Sondern er will eine mathematische Beschreibung seiner tatsächlich >> nichtlinearen Kennlinie bestimmen. Und die soll so ausreichend einfach >> sein, damit er seine später aufgenommenen Messwerte ohne viel >> Rechenaufwand auf eine lineare Skala zurückrechnen kann. (Daher seine >> Fragen zum Einsatz der "Umkehrfunktion"). > > Das ergibt aber auch wenig Sinn. Wenn ich die Abbildung Meßwerte (m) -> > Echtwerte (e) benötige, stelle ich doch auch die richtige Funktion e(m) > (auf welchem Weg auch immer) auf, anstelle erst m(e) zu approximieren > und dann die Umkehrfunktion zu bilden. Ich kenne keinen einzigen Ansatz > (egal ob polynomial, stückweise, sinus ...) bei dem die Umkehrfunktion > annähernd so einfach wie die Approximationsfunktion ist. (Stückweise > lineare Lagrange-Polynome mal aussen vor ... und selbst da nur in > bestimmten Fällen). Das stimmt. Wenn es datenbasiert ist, tauscht man abhängige und unabhängige Variable einfach. Wenn das Modell aber z.B. physikalisch motiviert ist, wird das schwieriger bzw. einfach weniger sinnvoll. > > Und was daran "linearisieren" ist, verstehe ich auch immer noch nicht. > (Vielleicht wird das klarer, wenn man die Werte sieht. Ich habe hier > kein Office.) Wird die erste Ableitung benötigt? Linearisieren heißt im Sensor Kontext erstmal nur, dass die Ausgangskennlinie "geradegezogen" werden soll. Wenn du dir dann nämlich den Idealfall einer korrigierte Ausgangskennlinie anguckst, hast du zu jedem wahren Wert auf der x-Achse denselben Messwert auf der y-Achse und somit eine Ausgangskennlinie in Form einer linearen Funktion mit Steigung 1 und Offset 0. Im allgemeinen eliminiert man eben die Nichtlinearitäten, wodurch die Ausgangskennlinie linear wird (dann halt vielleicht mit anderer Steigung und Offset)
Jan K. schrieb: > Linearisieren heißt im Sensor Kontext erstmal nur, dass die > Ausgangskennlinie "geradegezogen" werden soll. Danke für die Klarstellung. Mir ist der Begriff in diesem Zusammenhang noch nicht begegnet, aber ich fange üblicherweise auch erst weit hinter dem Sensor an. Jan K. schrieb: > Das stimmt. Wenn es datenbasiert ist, tauscht man abhängige und > unabhängige Variable einfach. Wenn das Modell aber z.B. physikalisch > motiviert ist, wird das schwieriger bzw. einfach weniger sinnvoll. Aber auch da: Erst (in diesem Fall die physikalisch motivierte) Abbildungsfunktion aufstellen (oder eine Näherung davon), dann fitten. Nicht andersherum. Ansonsten sehe ich die Gefahr, dass das Hauptgewicht des Fittings weit weg vom realen Arbeitspunkt ist.
Beitrag #6456468 wurde von einem Moderator gelöscht.
M. K. schrieb: > es geht um eine Linearisierung einer Kennlinie. Die Kennlinie hat ein > lineares Verhalten jedoch aufgrund von Störeinflüssen ist sie > nichtlinear. Die nichtlineare Kennlinie hat 20 Stützstellen. Die Frage > ist, wie kann ich möglichst einfach diese Kennlinie linearisieren sodass > der Linearitätsfehler unter einem Prozent bleibt. Ich hab alles möglich > schon gelesen und es scheint einfach zu sein, nur komm ich irgendwie > nicht rein. Du willst also die Daten durch eine Funktion f(x) = a + b*x beschreiben, so dass das Maximum der Beträge |f(x_i)-s(x_i)|*100%/f(x_18) möglichst klein ist (s(x): Sample-Wert an der Stelle x_i, i=1..18). Gewünscht ist von dir 1% maximale Abweichung. Kleine Bemerkung zu deinen Daten, siehe Skizze: Deine Daten lassen ganz sicher kein 1%-Fitting zu. Die rote Linie zeigt etwa den 1%-Korridor, die grüne annährend das Bestmögliche. Du kannst rein graphisch den roten Korridor legen wie du willst, du kriegst niemals alle Punkte in einen dieser 1%-Korridore. Im Allgemeinen kannst du ja nicht beides wünschen, zum einen eine maximale prozentuale Abweichung und zum anderen beliebige Daten, das beisst sich immer. Falls a=0 gesetzt wird, dann erhälst du ein relativ einfaches Fittingverfahren: 1. Bestimme aus den Daten grosszügig die minimale und maximale Steigung b_min, b_max aus f(x). 2. zu jedem b kannst du die maximale Abweichung zwischen f(x) und s(x) inkl. Vorzeichen berechnen (linearer Aufwand). Man erhält so die Differenz diff(b). 3. diff(b) ist monoton steigend (oder fallend, je nachdem, ob f(x)-s(x) oder s(x)-f(x) betrachtet wird), kann man sich relativ einfach klarmachen. 4. somit kann man mittels Intervallhalbierung in O(n*log(n)) Schritten das Optimum finden. (wahrscheinlich lässt sich das Verfahren auf ein Sortierverfahren reduzieren, d.h. es wird wahrscheinlich das bestmögliche bzgl. Komplexität sein) Mit etwa dem Ansatz (habe zur Vereinfachung auf die Intervallhalbierung verzichtet und stattdessen das Intervall hoch aufgelöst) komme ich auf eine Abweichung von etwa 6.66% für die beste Approximation mit a=0 und b=53.91. Andere Fittingverfahren, wie z.B. das hier schon erwähnte lin. Regressionsverfahren berechnen bzgl. deiner Zielsetzung etwas vollkommen anderes, wenn es auch in etwa wie die Lösung aus meinem Ansatz aussieht. Das lin. Regressionsverfahren minimiert ja die mittlere quadratische Abweichung, die willst du ja aber nicht.
Sigi schrieb: > Du willst also die Daten durch eine Funktion > > f(x) = a + b*x Will er meiner Meinung nach nicht, siehe meine Ausführungen darüber. Er will, dass die Sensor Ausgangskennlinie nach der Linearisierung einer linearen Funktion entspricht. Er will imo nicht eine Gerade in die Daten fitten.
Angehängte Dateien:
-

Kennlinie.png
5,1 KB
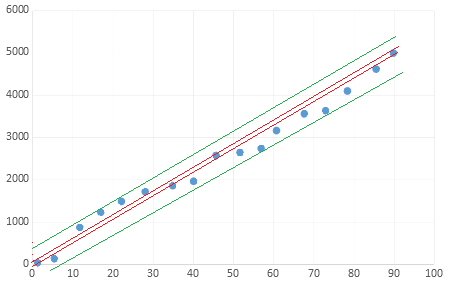
Jan K. schrieb: > Er will, dass die Sensor Ausgangskennlinie nach der Linearisierung > einer linearen Funktion entspricht. > > Er will imo nicht eine Gerade in die Daten fitten. Ups, habe das Hochladen meiner Graphik vergessen, hoffentlich klappt's jetzt. Bei Linearisierung verstehe ich das, was z.B. auf folgenden Seiten inkl. einiger Kennzahlen zu finden ist: http://techniker.pi-pro.de/fs/messtechnik/pdf/messfehler.pdf https://www.hawe.com/de-de/content-pages/linearitaetsfehler-bei-messgeraeten Die Formeln zum Fitten im PDF-Dokument finde ich aber komplett blödsinnig, siehe meine Bemerkung Oben. Ob du jetzt eine lineare Funktion (warum soll sich diese von meiner unterscheiden?) per Gradeziehen oder einem beliebigen anderen Verfahren erhälst ist eiglich komplett egal, solange die Zielvorgabe von 1% nicht verletzt wird. Das ist aber bei dem Datensatz nicht möglich, siehe Skizze. Btw. man kann auch den Parameter a ungleich 0 setzen, dann kommt man auf etwa 6% Abweichung mit a=80.82 und b=51.65.
Schöne Grafik :) Da sehe ich aber auch nur eine Ausgleichsgerade. Und du hast Recht, damit bestimmt man den Linearisierungs-*Fehler*. Auch genannt Nichtlinearität in vielen Datenblättern. Häufig steht auch "non-linearity best fitted straight line" das ist aber was anderes als Linearisierung. Was der TO aber möchte, ist seine Kennlinie so durch ein Verfahren zu optimieren, dass eben der Fehler, den du berechnet hast < 1% wird.
Beitrag #6456882 wurde von einem Moderator gelöscht.
Jan K. schrieb: > Was der TO aber möchte, ist seine Kennlinie so durch ein Verfahren zu > optimieren, dass eben der Fehler, den du berechnet hast < 1% wird. So verstehe ich das auch. Das ist aber keine Frage des Regressionsverfahrens (die Daten sind nicht so linear, wie man es gerne hätte), sondern erfordert eine Aufbereitung der Messwerte. Im einfachsten Fall schmeißt man so lange den Messwert mit der größten Abweichung von der Regressionsgeraden weg, bis der gewünschte Fehler erreicht ist. Sofern man ein Modell über die Herkunft der Abweichungen aufstellen kann, könnte man vielleicht auch so die Werte bereinigen. Oder es ist halt doch etwas ganz anderes gewünscht. Abschnittsweise Interpolationen wurden hier schon vorgeschlagen. Außerdem steht ja am Ende doch eine Anwendung dahinter, denn ... M. K. schrieb: > Es soll ein > möglichst einfacher Rechenprozess für den µC werden. Polynome höheren > Grades wären, so wie ich das verstanden habe, aufgrund der vielen > Koeffizienten zu aufwändig. ... es gibt genügend µC, die das für die paar Dutzend Messwerte mal ganz locker nebenher erledigen. Ok, ein AVR8 rechnet dann vielleicht mal ein paar Sekunden, wenn man etwas ganz abgefahrenes macht, aber wenn das ein Problem ist, scheinen ja konkrete Zeitanforderungen bekannt zu sein.
Ich glaube, es gibt hier Missverständnisse zum Begriff "Linearisierung". Fakt ist: Es wird keine einzelne Gerade gesucht, sondern eher mehrere. Erklärung: https://de.wikipedia.org/wiki/Linearisierung Wenn ich das richtig verstehe, soll die Anwendung von Geraden nur in "lokalen Stücken" geschehen, nämlich derart, dass keine Gerade eine größere Abweichung als 1% von der tatsächlichen Kurve erzeugt. Anschaulich kann man sich das so vorstellen: Man hat eine gegebene Messreihe auf einem Blatt Papier im X-Y-Diagramm. Nun legt man mehrere Streichhölzer so auf das Papier, dass eine Abweichung der (lokalen) Geraden - repräsentiert durch die Streichhölzer - kleiner als 1% wird. Man hat also N Geradengleichungen, welche jeweils für ein lokales Gebiet gelten. Habe ich das so korrekt verstanden?
Frank M. schrieb: > Habe ich das so korrekt verstanden? Nicht so ganz. Wenn du zwischen 2 Stützpunkten mit einem Streichholz, äh einer Geraden interpolierst, ist die Frage nach 1% sinnlos - an den Enden (Stützstellen) ist es genau, und dazwischen ist der wahre Wert ja nicht bekannt, also wovon 1% Abweichung? Georg
georg schrieb: > also wovon 1% Abweichung? Abweichung von einer interpolierten Kurve? Diese muss (wegen Messfehlern) nicht unbedingt durch die Messpunkte (Stützstellen) gehen. Und damit kann die Abweichung auch an den Stützstellen größer als 0% sein. Die Geraden durch jeweils benachbarte Messpunkte zu ziehen ist wohl zu trivial - auch wenn das MaWin direkt in der ersten Antwort dieses Threads als Verfahren vorstellte.
Frank M. schrieb: > Und damit kann die Abweichung auch an den Stützstellen größer als 0% > sein. Die Abweichung zwischen den beiden bekannten Stützstellen kann auch alles Mögliche sein, auch größer 100% Wenn Platz im µC ist kann auch jedem ADC Wert ein y-Wert in einer Tabelle zugewiesen werden. ADC habe ich mal geraten!
Frank M. schrieb: > Ich glaube, es gibt hier Missverständnisse zum Begriff "Linearisierung". > Fakt ist: Es wird keine einzelne Gerade gesucht, sondern eher mehrere. Ich glaube eher, mit "Linearisierung" ist hier die Korrektur der Nichtlinearität eines Sensors oder eines Messgeräts durch Anwendung einer geeigneten mathematischen Funktion auf die Messewerte gemeint. Und genau nach dieser Funktion sucht der TE. Diese Funktion ist die Umkehrfunktion der durch die Kennlinie gegebene Funktion (deswegen fiel im Eröffnungsbeitrag auch dieser Begriff). Da die Kennlinie aber nur durch relativ wenige Punkte gegeben ist, ist die zugehörige Funktion nur sehr unvollständig definiert. Entsprechend kann auch die daraus gewonnene Umkehrfunktion keine optimale Korrektur liefern und ihr maximaler oder RMS-Fehler kann nur grob geschätzt werden. Je verschnörkelter die Nichtlinearitäten sind, umso komplizierter wird die Korrektorfunktion. Gleichzeitig soll diese Funktion nach Aussage des TE aber sehr einfach zu berechnen sein. Deswegen muss ein sinnvoller Kompromiss gefunden werden. Da sich der TE nicht mehr meldet, gehe ich davon aus, dass er das Problem entweder gelöst hat oder sich nicht mehr weiter damit beschäftigt.
Frank M. schrieb: > Wenn ich das richtig verstehe, soll die Anwendung von Geraden nur in > "lokalen Stücken" geschehen, nämlich derart, dass keine Gerade eine > größere Abweichung als 1% von der tatsächlichen Kurve erzeugt. Ich versuche das mal, als Hausaufgabentext zu formulieren: "Gegeben seien n Tupel x_i, y_i, die durch eine stückweise lineare Funktion f(x) mit m Abschnitten derart approximiert werden soll, dass der Approximationsfehler an jedem Tupel kleiner oder gleich 1% ausfällt." Das ließe die Fragen offen: a) muss die Approximationsfunktion stetig sein? b) muss m < n-1 sein? c) muss m minimal sein? d) dürfen die Stützstellen beliebig nach dem Fehlerkriterium gewählt werden, oder muss ihr x-Wert mit einem gegebenen Tupel zusammenfallen?
Angehängte Dateien:
-

measurement_degree4.png
90 KB -

example_degree3.png
89 KB -

blockschaltbild.jpg
240 KB
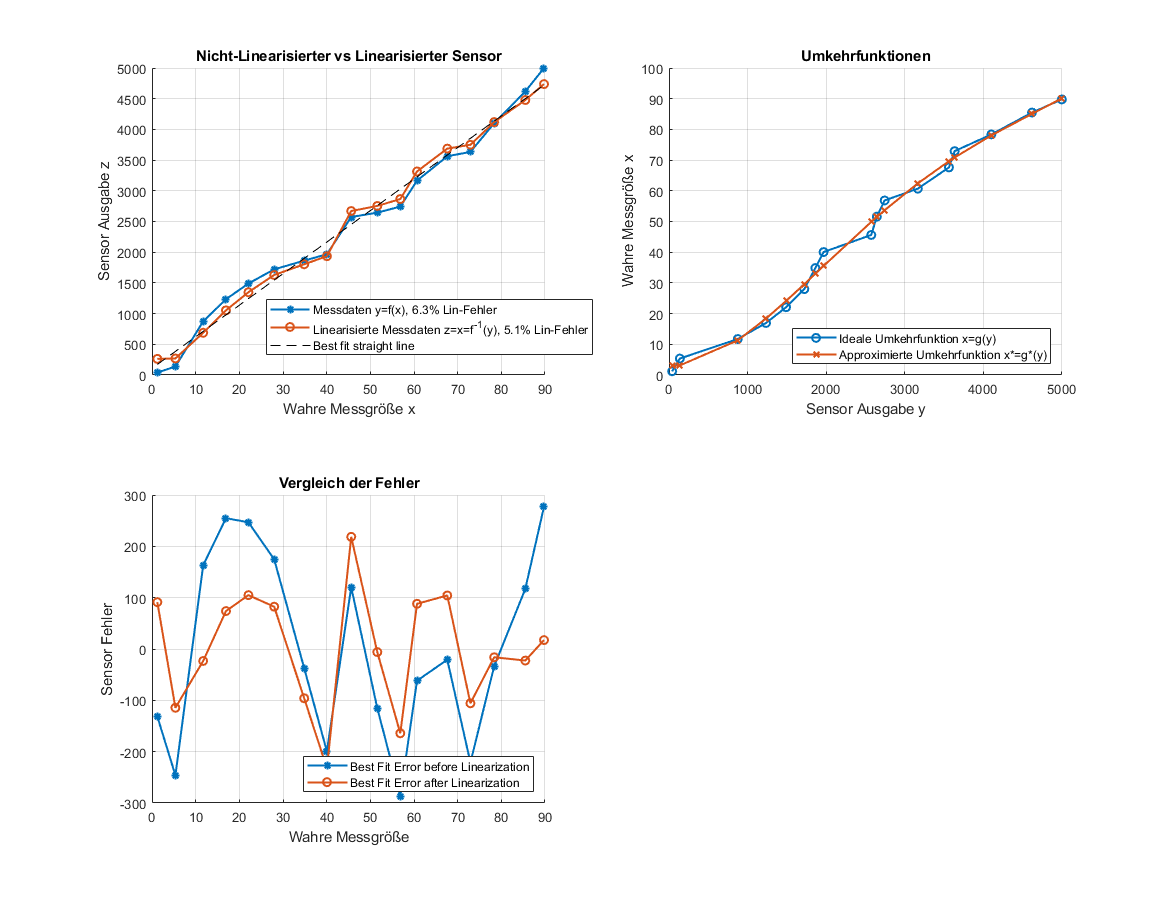
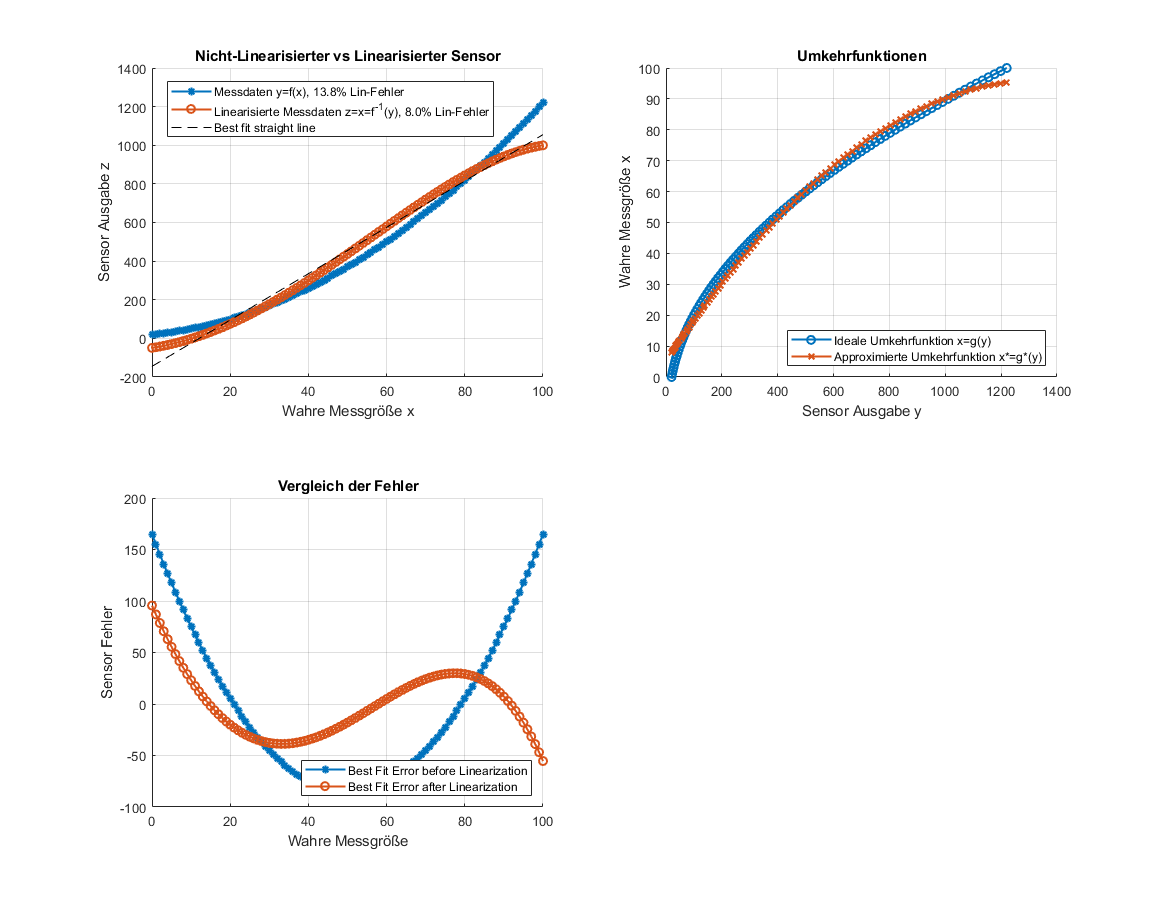
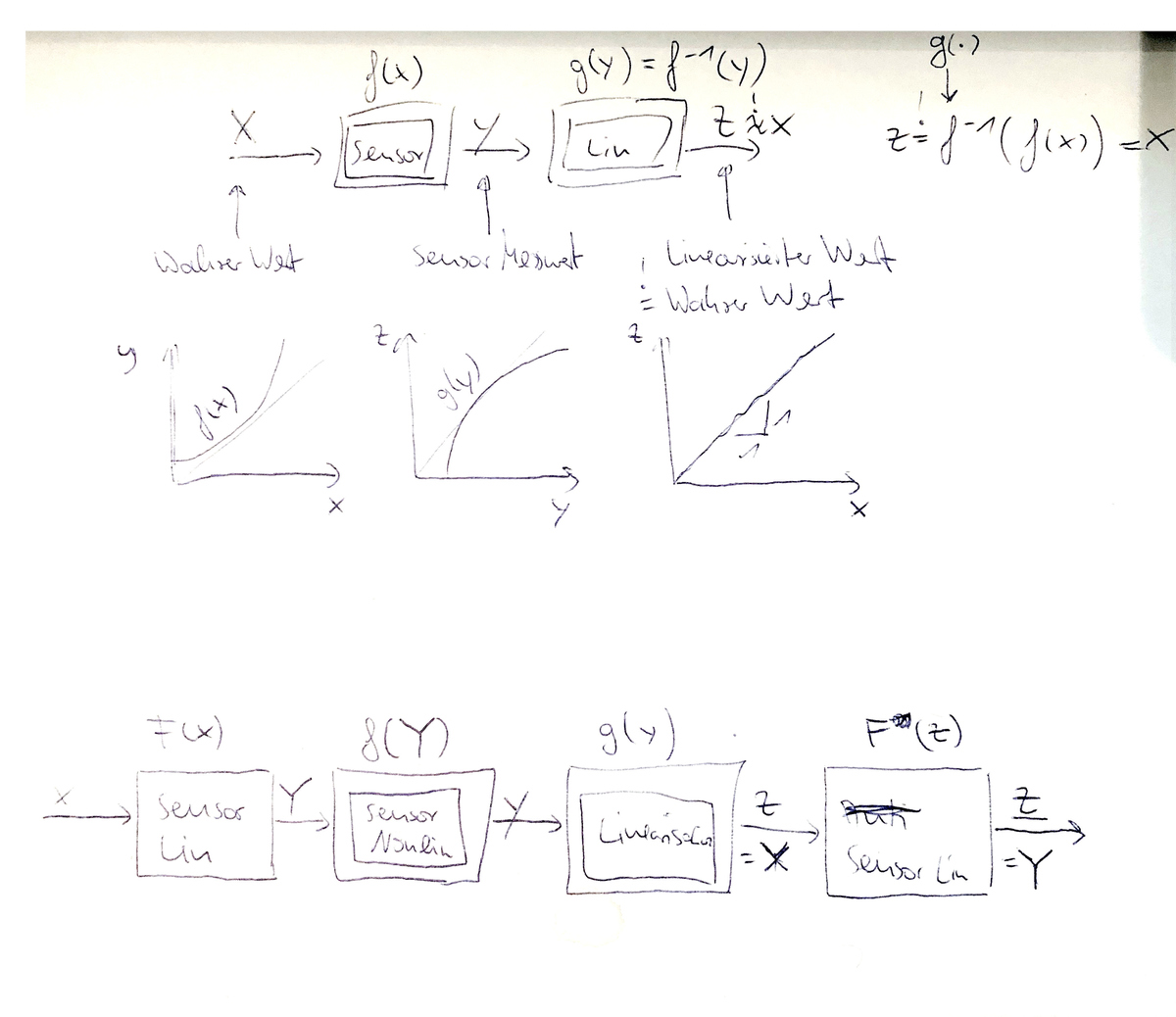
Yalu X. schrieb: > Ich glaube eher, mit "Linearisierung" ist hier die Korrektur der > Nichtlinearität eines Sensors oder eines Messgeräts durch Anwendung > einer geeigneten mathematischen Funktion auf die Messewerte gemeint. Und > genau nach dieser Funktion sucht der TE. Ganz genau so ist es. Und so hab' ich es oben auch schon ein paar Mal geschrieben. Es wird die Umkehrabbildung gesucht! Hier mal zwei Paper dazu: http://physics.gu.se/~larsbn/Publikationer/pub6_2012.pdf https://www.atpjournal.sk/buxus/docs/casopisy/atp_plus/plus_2006_2/plus13_17.pdf Und weil mir aus unerklärlichen Gründen zu langweilig war (nicht wirklich... :D), hab' ich das Ganze mal in Matlab aufgeschrieben. Mit einem einfacheren Beispiel sowie mit den Daten vom TO. Ich habe versucht, so viel zu kommentieren wie nur möglich. Lässt sich hoffentlich auch in Octave ohne toolboxen ausführen. Es basiert auf dem Fit der inversen Funktion. Oben kann man mit dem Grad des Polynoms spielen und einstellen, ob die TO Daten oder ein Beispiel gezeigt werden soll:
1 | %% Parameter zum rumspielen |
2 | |
3 | fitOrder = 2; % Polynom Ordnung der gefitteten Inversen Funktion |
4 | dataSource = 'example'; % 'example' or 'measurement' |
Im Anhang seht ihr ein paar Ergebnisse mit verschiedenen Einstellungen. Wie man hoffentlich sehen kann, bekommt man den (Nicht-)Linearitätsfehler nicht unter 5.1 % mit dem angewendeten Verfahren (globales Polynom der Inversen). D.h. man müsste jetzt gucken, ob lokale Modelle besser funktionieren. Oder man nimmt ne Lookup Table, oder oder oder. Fakt ist aber, dass die Nichtlinearitäten seltsam aussehen und auch Messfehler sein könnten. Daher noch ein Beispiel von mir, wo man eine "echte" nichtlinearität (x^2) über die gesamte Kennlinie sehen kann.
Walter T. schrieb: > "Gegeben seien n Tupel x_i, y_i, die durch eine stückweise lineare > Funktion f(x) mit m Abschnitten derart approximiert werden soll, dass > der Approximationsfehler an jedem Tupel kleiner oder gleich 1% > ausfällt." Es muss aber die Inverse approximiert werden!
Jan K. schrieb: > Es muss aber die Inverse approximiert werden! Die Umkehr"funktion" einer stückweise linearen Funktion ist auch stückweise linear. Nur nicht mehr zwangsläufig eine Funktion.
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.