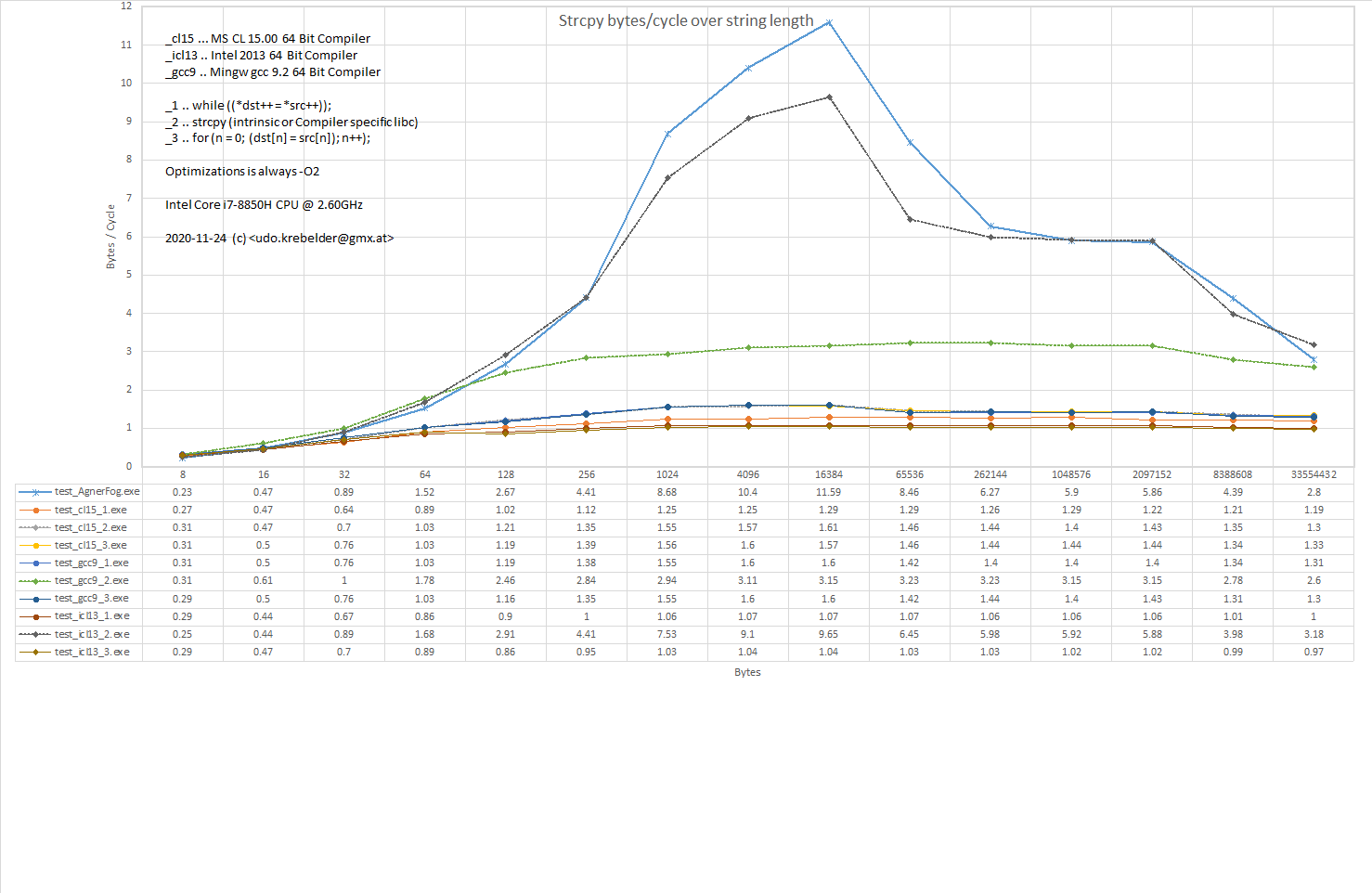
Hallo, Hier die Ergebnisse der Performance Tests für die strcpy Funktion, in der Hoffnung, dass sie jemanden nützen besseren Code zu schreiben. - Bei kurzen String < 30 Zeichen ist der Unterschied nicht allzu gross. - Bei langen Strings ist die AgnerFog Asmlib und die Intel Lib weit vorne. Wenn Interesse besteht, das ganze auf dem eigenen Rechner auszuprobier, dann kann ich den Source und die Exe hier reinstellen. Gruss, Udo
Angehängte Dateien:
-

Log.png
29 KB
Ich hab jetzt ehrlich gesagt noch nie von einem Programm gehört, das zu langsam gelaufen wäre, weil ein strcpy() zu viel Rechenzeit verbraucht hätte. 🤔
Mark B. schrieb: > Ich hab jetzt ehrlich gesagt noch nie von einem Programm gehört, > das zu > langsam gelaufen wäre, weil ein strcpy() zu viel Rechenzeit verbraucht > hätte. 🤔 Weißt du denn von jedem trägen Programm den Grund, warum es träge ist?
Le X. schrieb: > Weißt du denn von jedem trägen Programm den Grund, warum es träge ist? Wenn ich das richtig überblicke, dann hat der Themenersteller nie gesagt, dass irgendein Teil einer Software zu träge wäre.
Weißt du, warum die eine Variante schneller ist? Der Maschinencode wäre interessant. Ich könnte mir vorstellen, dass irgendwo die Vektorverarbeitung in der CPU verwendet wird.
Der Asm Code wird bei den Testfiles mit ausgegeben. Hier ein Beispiel für die den Microsoft Compiler mit -O2, für eine memcpy() Funktion. (Parameterübergabe findet immer in den Registern rcx, rdx und r8 statt).
1 | for (n = 0; n < len; n++) |
2 | dest[n] = source[n]; |
MS CL.EXE 15.00 macht eine übersichtliche Schleife mit 6 Befehlen:
1 | test_memcpy PROC ; COMDAT |
2 | |
3 | ; 19 : size_t n; |
4 | ; 20 : BYTE *p = dst; |
5 | ; 21 : const BYTE *r = src; |
6 | ; 22 : |
7 | ; 23 : for (n = 0; n < len; n++) |
8 | |
9 | test r8, r8 |
10 | je SHORT $LN8@test_memcp |
11 | mov r9, rcx |
12 | sub rdx, rcx |
13 | npad 5 |
14 | $LL3@test_memcp: |
15 | |
16 | ; 24 : p[n] = r[n]; |
17 | |
18 | movzx eax, BYTE PTR [rdx+r9] |
19 | inc r9 |
20 | sub r8, 1 |
21 | mov BYTE PTR [r9-1], al |
22 | jne SHORT $LL3@test_memcp |
23 | $LN8@test_memcp: |
24 | |
25 | ; 25 : |
26 | ; 26 : return dst; |
27 | |
28 | mov rax, rcx |
29 | |
30 | ; 27 : } |
31 | |
32 | ret 0 |
33 | test_memcpy ENDP |
64 Bit Register r8 ist die Länge (len), und wird in jedem Schleifendurchlauf bis auf 0 runtergezählt (sub r8,1). 64 Bit Register r9 ist der Index n, der in jedem Durchlauf raufgezählt wird (inc r9). Die Daten werden ins Register 32 Bit Register eax geladen, und dann gleich als Byte (al = Register eax Low Byte) abgespeichert Intel ICL.EXE macht bei -O1 -Oi- daraus 5 Befehle:
1 | ;;; for (n = 0; n < len; n++) |
2 | |
3 | xor r10d, r10d ;23.10 |
4 | test r8, r8 ;23.21 |
5 | jbe .B1.5 ; Prob 10% ;23.21 |
6 | ; LOE rdx rcx rbx rbp rsi rdi r8 r10 r12 r13 r14 r15 xmm6 xmm7 xmm8 xmm9 xmm10 xmm11 xmm12 xmm13 xmm14 xmm15 |
7 | .B1.3:: ; Preds .B1.1 .B1.3 |
8 | |
9 | ;;; p[n] = r[n]; |
10 | |
11 | mov r9b, BYTE PTR [r10+rdx] ;24.16 |
12 | mov BYTE PTR [r10+rcx], r9b ;24.9 |
13 | inc r10 ;23.26 |
14 | cmp r10, r8 ;23.21 |
15 | jb .B1.3 ; Prob 82% ;23.21 |
16 | ; LOE rdx rcx rbx rbp rsi rdi r8 r10 r12 r13 r14 r15 xmm6 xmm7 xmm8 xmm9 xmm10 xmm11 xmm12 xmm13 xmm14 xmm15 |
17 | .B1.5:: ; Preds .B1.3 .B1.1 |
18 | |
19 | ;;;
|
20 | ;;; return dst; |
21 | |
22 | mov rax, rcx ;26.12 |
23 | ; LOE |
24 | .B1.8:: ; Preds .B1.5 |
25 | ret ;26.12 |
Eine 1:1 Umsetzung der for Schleife, mit 64 Bit Register r10 als Index n. Register r8 ist der Länge len. Geladen werden die Bytes ins 64 Bit Register r9, und als Byte (r9b) abgespeichert. Wenn man aber -QxHost -O2 angibt, wird daraus ein Aufruf der intel_memcpy(), zumindest für wenn der Block grösser als 96 Bytes ist:
1 | test_memcpy PROC |
2 | ; parameter 1: rcx |
3 | ; parameter 2: rdx |
4 | ; parameter 3: r8 |
5 | .B1.1:: ; Preds .B1.0 |
6 | |
7 | ;;; { |
8 | |
9 | push rdi ;18.1 |
10 | sub rsp, 32 ;18.1 |
11 | mov rdi, rcx ;18.1 |
12 | |
13 | ;;; size_t n; |
14 | ;;; BYTE *p = dst; |
15 | ;;; const BYTE *r = src; |
16 | ;;;
|
17 | ;;; for (n = 0; n < len; n++) |
18 | |
19 | test r8, r8 ;23.21 |
20 | jbe .B1.5 ; Prob 50% ;23.21 |
21 | ; LOE rdx rbx rbp rsi rdi r8 r12 r13 r14 r15 xmm6 xmm7 xmm8 xmm9 xmm10 xmm11 xmm12 xmm13 xmm14 xmm15 |
22 | .B1.2:: ; Preds .B1.1 |
23 | cmp r8, 96 ;23.5 |
24 | jbe .B1.6 ; Prob 10% ;23.5 |
25 | ; LOE rdx rbx rbp rsi rdi r8 r12 r13 r14 r15 xmm6 xmm7 xmm8 xmm9 xmm10 xmm11 xmm12 xmm13 xmm14 xmm15 |
26 | .B1.3:: ; Preds .B1.2 |
27 | mov rax, rdi ;23.5 |
28 | mov ecx, 1 ;23.5 |
29 | sub rax, rdx ;23.5 |
30 | xor r10d, r10d ;23.5 |
31 | cmp rax, r8 ;23.5 |
32 | cmovg r10d, ecx ;23.5 |
33 | xor r9d, r9d ;23.5 |
34 | neg rax ;23.5 |
35 | cmp rax, r8 ;23.5 |
36 | cmovg r9d, ecx ;23.5 |
37 | or r10d, r9d ;23.5 |
38 | je .B1.6 ; Prob 10% ;23.5 |
39 | ; LOE rdx rbx rbp rsi rdi r8 r12 r13 r14 r15 xmm6 xmm7 xmm8 xmm9 xmm10 xmm11 xmm12 xmm13 xmm14 xmm15 |
40 | .B1.4:: ; Preds .B1.3 |
41 | |
42 | ;;; p[n] = r[n]; |
43 | |
44 | mov rcx, rdi ;24.9 |
45 | call _intel_fast_memcpy ;24.9 |
46 | ; LOE rbx rbp rsi rdi r12 r13 r14 r15 xmm6 xmm7 xmm8 xmm9 xmm10 xmm11 xmm12 xmm13 xmm14 xmm15 |
47 | .B1.5:: ; Preds .B1.1 .B1.10 .B1.4 .B1.11 |
48 | |
49 | ;;;
|
50 | ;;; return dst; |
51 | |
52 | mov rax, rdi ;26.12 |
53 | add rsp, 32 ;26.12 |
54 | pop rdi ;26.12 |
55 | ret ;26.12 |
56 | ; LOE |
57 | .B1.6:: ; Preds .B1.2 .B1.3 |
58 | mov rax, r8 ;23.5 |
59 | mov r9d, 1 ;23.5 |
60 | shr rax, 1 ;23.5 |
61 | xor ecx, ecx ;23.5 |
62 | test rax, rax ;23.5 |
63 | jbe .B1.10 ; Prob 10% ;23.5 |
64 | ; LOE rax rdx rcx rbx rbp rsi rdi r8 r9 r12 r13 r14 r15 xmm6 xmm7 xmm8 xmm9 xmm10 xmm11 xmm12 xmm13 xmm14 xmm15 |
65 | .B1.8:: ; Preds .B1.6 .B1.8 |
66 | mov r9b, BYTE PTR [rdx+rcx*2] ;24.16 |
67 | mov BYTE PTR [rdi+rcx*2], r9b ;24.9 |
68 | mov r10b, BYTE PTR [1+rdx+rcx*2] ;24.16 |
69 | mov BYTE PTR [1+rdi+rcx*2], r10b ;24.9 |
70 | inc rcx ;23.5 |
71 | cmp rcx, rax ;23.5 |
72 | jb .B1.8 ; Prob 64% ;23.5 |
73 | ; LOE rax rdx rcx rbx rbp rsi rdi r8 r12 r13 r14 r15 xmm6 xmm7 xmm8 xmm9 xmm10 xmm11 xmm12 xmm13 xmm14 xmm15 |
74 | .B1.9:: ; Preds .B1.8 |
75 | lea r9, QWORD PTR [1+rcx*2] ;23.5 |
76 | ; LOE rdx rbx rbp rsi rdi r8 r9 r12 r13 r14 r15 xmm6 xmm7 xmm8 xmm9 xmm10 xmm11 xmm12 xmm13 xmm14 xmm15 |
77 | .B1.10:: ; Preds .B1.9 .B1.6 |
78 | dec r9 ;23.5 |
79 | cmp r9, r8 ;23.5 |
80 | jae .B1.5 ; Prob 10% ;23.5 |
81 | ; LOE rdx rbx rbp rsi rdi r9 r12 r13 r14 r15 xmm6 xmm7 xmm8 xmm9 xmm10 xmm11 xmm12 xmm13 xmm14 xmm15 |
82 | .B1.11:: ; Preds .B1.10 |
83 | mov al, BYTE PTR [rdx+r9] ;24.16 |
84 | mov BYTE PTR [r9+rdi], al ;24.9 |
85 | jmp .B1.5 ; Prob 100% ;24.9 |
86 | ALIGN 16 |
87 | ; LOE rbx rbp rsi rdi r12 r13 r14 r15 xmm6 xmm7 xmm8 xmm9 xmm10 xmm11 xmm12 xmm13 xmm14 xmm15 |
88 | .B1.12:: |
89 | ; mark_end; |
90 | test_memcpy ENDP |
"-O2" sollte man wegen dem Code-Bloat nur machen, wenn es notwendig ist. Wobei im Zeitalter, wo ein "Hello World" schon mal 100 MByte hat, ist das auch schon Wurscht. Der gcc 9.2 mit -O2 macht daraus auch 5 Befehle:
1 | test_memcpy:
|
2 | .seh_endprologue |
3 | mov rax, rcx |
4 | test r8, r8 |
5 | je .L2 |
6 | xor r9d, r9d |
7 | .p2align 4,,10 |
8 | .p2align 3 |
9 | .L3: |
10 | movzx r10d, BYTE PTR [rdx+r9] |
11 | mov BYTE PTR [rax+r9], r10b |
12 | add r9, 1 |
13 | cmp r8, r9 |
14 | jne .L3 |
15 | .L2: |
16 | ret
|
mit "-O3 -march=native" werden daraus AVX Befehle, die 32 Bytes in
einem Rutsch kopieren (Label L4), zumindest wenn der Block > 64 Bytes
ist,
und aligned ist, sonst wird ganz konventionell über Register r9 kopiert
(Label L3):
[/c]
test_memcpy:
.seh_endprologue
mov rax, rcx
test r8, r8
je .L22
lea rcx, 31[rcx]
sub rcx, rdx
cmp rcx, 62
jbe .L8
lea rcx, -1[r8]
cmp rcx, 30
jbe .L8
mov rcx, r8
and rcx, -32
xor r9d, r9d
.p2align 4,,10
.p2align 3
.L4:
vmovdqu ymm0, YMMWORD PTR [rdx+r9]
vmovdqu YMMWORD PTR [rax+r9], ymm0
add r9, 32
cmp r9, rcx
jne .L4
mov r9, r8
and r9, -32
test r8b, 31
je .L21
.p2align 4,,10
.p2align 3
.L6:
movzx ecx, BYTE PTR [rdx+r9]
mov BYTE PTR [rax+r9], cl
inc r9
cmp r8, r9
ja .L6
vzeroupper
.L22:
ret
.p2align 4,,10
.p2align 3
.L8:
xor ecx, ecx
.p2align 4,,10
.p2align 3
.L3:
movzx r9d, BYTE PTR [rdx+rcx]
mov BYTE PTR [rax+rcx], r9b
inc rcx
cmp r8, rcx
jne .L3
ret
.L21:
vzeroupper
ret
[/c]
Ich fände einen Vergleich mit strlen interessanter. Weil da mehr Spielraum für Optimierung des Algorithmus besteht. Bei strcpy muss jedes Zeichen kopiert werden. Untere Schranke für die Komplexität ist also O(n). D.h. die Optimierung beschränkt sich allein auf die Details der Rechnerarchitektur. Bei strlen aber nicht.
Cyblord -. schrieb: > Ich fände einen Vergleich mit strlen interessanter. Weil da mehr > Spielraum für Optimierung des Algorithmus besteht. Bei strcpy muss jedes > Zeichen kopiert werden. Untere Schranke für die Komplexität ist also > O(n). D.h. die Optimierung beschränkt sich allein auf die Details der > Rechnerarchitektur. > Bei strlen aber nicht. Was willst du denn bei strlen anders machen? Bei strlen muss man jedes Byte angucken, bis man ne 0 gefunden hat und darf nicht dahinter weitergucken. Was soll man da anderes machen als ne lineare Suche Byte für Byte?
Ist das so? Der Compiler kann ja nicht irgendwo nach im Speicher nach '\0' rumsuchen, Die Komplexität muss also auch bei strlen() O(n) sein. Aber wenn dir ein ganz bestimmter Test vorschwebt, kann ich den gerne einbauen. Die Benschmarks drehen sich aber um die Details der Rechnerarchitektur, und inwieweit der Compiler da optimieren kann. Hier wird ja immer wieder behauptet, dass Optimierungen auf dieser Ebene keine Rolle spielen, aber wenn man z.B. grosse Daten kopiert, dann machen solche "Mikrooptimierungen" schon mal einen sehr spürbaren Faktor aus. Hast du einen Ryzen? Mich würde wirlich interessieren, wie die da abschneiden.
udok schrieb: > Ist das so? > Der Compiler kann ja nicht irgendwo nach im Speicher nach '\0' > rumsuchen, > Die Komplexität muss also auch bei strlen() O(n) sein. Wäre in der Tat möglich. Mein erster Gedanke war da könnte Algorithmisch was gehen, aber vielleicht auch nicht.
udok schrieb: > dann machen solche "Mikrooptimierungen" schon mal einen sehr spürbaren > Faktor aus Nur sind die hochgradig vom konkreten System abhängig. Bei Systemwechseln ungünstig.
Cyblord -. schrieb: > Ich fände einen Vergleich mit strlen interessanter. Weil da mehr > Spielraum für Optimierung des Algorithmus besteht. Da ist was dran. Bei strlen() gäbe es für sehr lange Ketten jede Menge Optimierungspotenzial über die Ausnutzung des Wissens über das Layout des virtuellen Adressraums und des Heaps. Andererseits stellt sich natürlich auch die Frage, wo so große Zeichenketten überhaupt ohne Längeninformation überhaupt vorkommen, dass das eine Rolle spielt.
Walter T. schrieb: > Bei strlen() gäbe es für sehr lange Ketten jede Menge > Optimierungspotenzial über die Ausnutzung des Wissens über das Layout > des virtuellen Adressraums und des Heaps. Nö. Die Anforderung: "Darf kein Byte nach \0 lesen" macht dir so ziemlich alle Optimierungsmöglichkeiten zunichte. Der Prozessor wird zwar trotzdem viele Bytes nach dem "\0" lesen und auswerten (Speculative execution), aber wieder "ROLLBACKen". Was uns die schöne Klasse der Spectre-CPU-Bugs eingehandelt hat.
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.