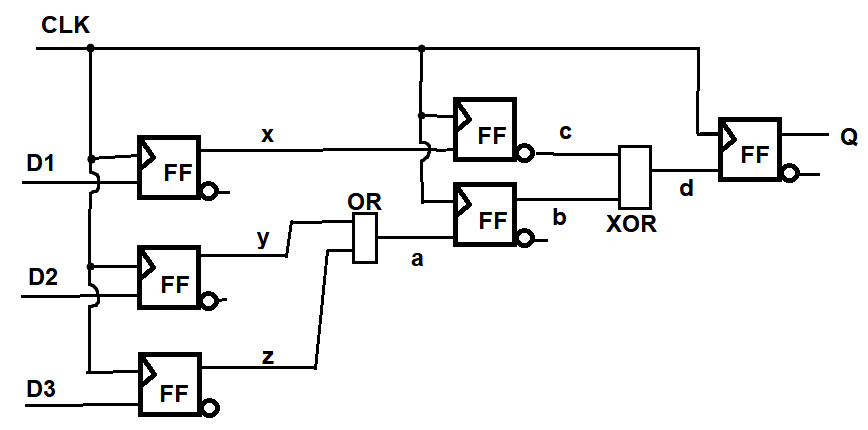
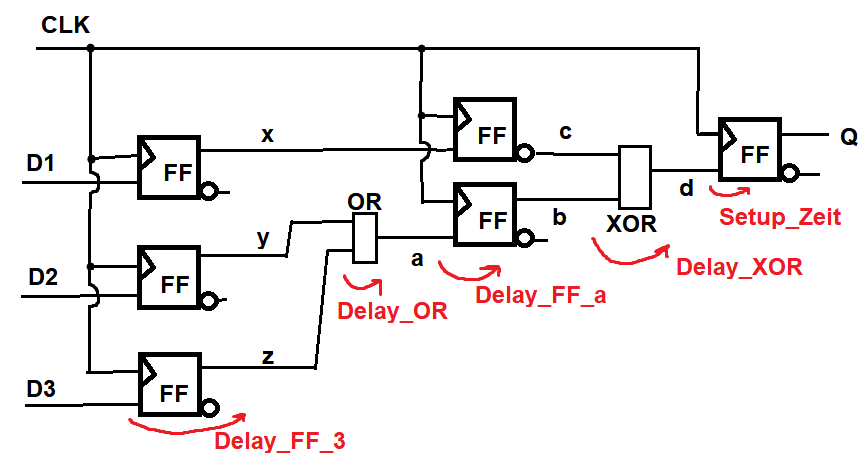
Hallo, ich habe eine Frage zur Berechnung der minimalen Taktzykluszeit eines Flipflops. Hier gibt es den besonderen Fall, dass es sich hier um eine Pipeline handelt. Ich habe gelernt, dass die minimale Taktzykluszeit aus der Addition verschiedener "Timings" berechnet wird u.a. Dealy Zeit am Eingang des FF, Delay der Kombinatorischen Schaltung etc. Bild siehe "FF_Pipeline.png" Für die Berechnung würde ich mir jetzt den kritischen Pfad heraussuchen, dieser wäre meiner Meinung nach: z, a, b, d. Für die Berechnung bedeutet dies: Delay_FF_3 + Delay_OR + Delay_FF_a + Delay_XOR + Setup_Zeit_Ausgabe_Q, ich habe das mal im Bild entsprechend markiert :) Die Hold time kann hier vernachlässigt werden! Bild siehe "FF_Pipeline_Timings.png" Jetzt habe ich in meinen Aufzeichnungen nachgesehen und hier ist mir aufgefallen, dass der Teil "d" (Verbindung zwischen FF_a und dem letzten FF) nicht mit einbezogen worden ist. Warum ist das so? Ist meine Berechnung falsch? Danke für kommende Hilfen :)
Angehängte Dateien:
-

FF_Pipeline.png
5,7 KB -

FF_Pipeline_Timings.png
8,9 KB
Danke für deine Antwort! Ich habe zwei Rückfragen. Erstens: warum wird bei dem ersten FF die Set Time nicht berücksichtigt, einfach weil es das erste FF ist? Zweitens: Wenn ich die Setup Zeit des zweiten FF noch mit in meine Gesamtrechnung aufnehme, in der Form von: time_CLK,MIN = Delay_FF_3 + Delay_OR + Delay_FF_a_set + Delay_FF_a + Delay_XOR + Setup_Zeit_Ausgabe_Q Wäre dies jetzt die minimale Taktzykluszeit?
Handelt es um "Einflankengesteuertes Flip-Flops" oder "Zweiflankengesteuertes Flip-Flops"? https://www.elektronik-kompendium.de/sites/dig/0209301.htm
Danke für deine Antwort @geku, es handelt sich nur um asynchrone flankengesteuerte (edge triggered) FF. Weitere Infos sind mir da leider nicht gegeben. Aber hilft die Information weiter?
Peter M. schrieb: > Jetzt habe ich in meinen Aufzeichnungen nachgesehen und hier ist mir > aufgefallen, dass der Teil "d" (Verbindung zwischen FF_a und dem letzten > FF) nicht mit einbezogen worden ist. Warum ist das so? Ist meine > Berechnung falsch? Meines Wissens beginnt die Berechnung nach jedem Q-Ausgang erneut. Es muss nur delay_FF3 + Delay_OR zur Setupzeit des FF_a passen. Nach jedem FF beginnt eine neuer Pfad, denn FF_a ist ja wieder synchron nach dem Takt; sein Ausgangssignal b wechselt zeitgleich mit z - nur eben einen Takt später. Also: a hat das Delay von den beiden FFs zu y und z plus das OR-Delay und dann noch die Setupzeit von FF_a. Das ist ein kritischer Pfad. Der zweite ist c und b über XOR zu d und der Setupzeit des rechten FFs. Um den schlimmsten Pfad zu erkennen, muss man wissen, ob OR oder XOR länger brauchen. Aus dem Grund macht man ja Pipelining. Man könnte hier auch die beiden mittleren FFs weglassen, dann ist tatsächlich der Pfad FF3-OR-XOR vorhanden.
Peter M. schrieb: > Hier gibt es den besonderen Fall, dass es sich hier um eine > Pipeline handelt. Und deshalb funktioniert die Schaltung so überhaupt nicht: alle FFs haben einen gemeinsamen Takt und schalten daher gleichzeitig. Die Information vorheriger Stufen kann also die Setup-Zeiten der nächsten niemals einhalten, mit etwas Glück wird der Ausgang z.B. der ersten Stufe erst beim nächsten Takt in der zweiten Stufe verarbeitet, es könnte aber auch ziemlich undefiniert sein. Georg
@HildeK, das ist sehr sehr hilfreich für mich! Danke! Um die Zeit also zu berechnen, reicht es wenn ich mir die Verbindungen zwischen zwei FFs ansehe, richtig? So bist du ja auch auf die zwei kritischen Pfade 1. y,z,a 2. b,c,d gekommen? > Meines Wissens beginnt die Berechnung nach jedem Q-Ausgang erneut. Woher genau weißt du das? > Aus dem Grund macht man ja Pipelining. Man könnte hier auch die beiden > mittleren FFs weglassen, dann ist tatsächlich der Pfad FF3-OR-XOR > vorhanden. Das ist gut beobachtet! Ich habe genau so eine Schaltung als (erstes) Beispiel gehabt um zu sehen, dass die Zeit (ohne Pipeline) deutlich höher ist. Mich hat gewundert (in diesem Beispiel), dass ich trotz Pipeline dennoch auf eine höhere Zeit komme, siehe meine Berechnung oben...
Remus schrieb: > Aber hilft die Information weiter? Ja. Zweiflankengesteuertes Flip-Flop : Ein zweiflankengesteuertes Flip-Flop nimmt den Eingangszustand während einer Taktflanke (steigende Takflanke) auf und gibt diese erst bei der folgenden Flanke (fallende Taktflanke) aus. Damit kann die zweite Flip-Flop Reihe die neuen Daten erst mit der nächsten Flanke übernehmen. Das bedeutet, dass Signallaufzeiten größer/gleich der halben Taktrate sein müssen, damit sie zu Fehlern führen. Achtung auch unterschiedliche Taktlaufzeiten können zu Probleme führen.
Peter M. schrieb: > So bist du ja auch auf die zwei kritischen Pfade 1. > y,z,a 2. b,c,d gekommen? Genau! Georg schrieb: > Die > Information vorheriger Stufen kann also die Setup-Zeiten der nächsten > niemals einhalten, mit etwas Glück wird der Ausgang z.B. der ersten > Stufe erst beim nächsten Takt in der zweiten Stufe verarbeitet, es > könnte aber auch ziemlich undefiniert sein. Denke darüber nochmals nach. Das FF hat ein Delay von Clk nach Q, die Zeit reicht, um den alten Zustand ins nächste FF zu übernehmen. Als Setupzeit kann das nächste FF dann die restliche Periodendauer des Clks nutzen. Die Holdzeit an einem D-Eingang ist meist nahe Null, e.g. beim HC74 sogar typisch -2ns, also negativ. Alles ist darauf ausgelegt, den alten Zustand des vorangegangenen FFs zu übernehmen, mit möglichst viel Luft dazwischen, so dass man logische Verknüpfungen machen kann, wie oben gezeichnet! Ohne das würde kein Schieberegister funktionieren.
Peter M. schrieb: > @HildeK, das ist sehr sehr hilfreich für mich! Danke! Um die Zeit also > ... > oben... Wenn man aber nur diese einzel Pfade nimmt, wie du das vorschlägst, dann ist die Zeit genau wie in meiner Lösung. Das heißt dann, dass es reicht sich nur die "größte" bzw. "längste" Verbindung zwischen zwei FFs anzusehen?!
Georg schrieb: > ziemlich undefiniert sein genaus so ist es! Einflankengesteuertes Flip-Flops : Daher kann man bei jeder FF-Reihe mit einem anderen Takt oder Flanke arbeiten. Z.B. erste Reihe steigende Flanke, zweite FF-Reihe fallende Flanke
Peter M. schrieb: > Woher genau weißt du das? Wer mir das beigebracht hat (vor zig Jahren) weiß ich nicht mehr 😀. Naja, hab anfangs meiner Berufslaufbahn viel mit PLDs gemacht. Dort ist ein Gattergrab und ein FF eine Zelle und da ist man halt immer mal wieder auf den Geschwindigkeitsanschlag gekommen, wenn die Verknüpfung zu aufwändig war. Das ist genau so bei FPGAs oder CPLDs. Wobei bei FPGAs noch relevante Routing-Delays dazukommen (soweit ich weiß). Aber eigentlich ist es doch logisch, sonst ist der ganze Aufwand mit x Pipelinestufen überflüssig.
Peter M. schrieb: > Das heißt dann, dass es reicht > sich nur die "größte" bzw. "längste" Verbindung zwischen zwei FFs > anzusehen?! Ja.
Gerald K. schrieb: > Georg schrieb: >> ziemlich undefiniert sein > > genaus so ist es! Ihr seid beide auf dem Holzweg. Das geht selbstverständlich mit ganz normalen D-FFs. Das zitierte HC74 hat CP→Q typ. 17ns; heißt, 17ns nach der Taktflanke ist an Q die D-Information angekommen. Das nächste FF hat nun 1 Taktperiode Zeit (Setupzeit), minus die 17ns und -2ns Holdtime, also t_per-15ns. Bei 10MHz Takt kannst du also mit Gatterverknüpfungen noch 85ns verbraten. Ich habe jetzt der Einfachheit halber die typischen Zahlen bei 4.5V hergenommen, weil die Holdzeit für 5V nicht genannt ist.
Wenn ich die Rückfrage nochmal stellen darf. Und nochmal vielen Dank für die super guten Antworten! Wie genau wird der Geschwindigkeitsvorteil bei der Piepline erreicht? Wenn ich das richtig verstanden habe, dann habe ich pro Taktzyklus logische Verarbeitungen in den zwischengeschalteten Gattern. Diese Info wird ans nächste FF weitergegeben, die Ausgabe steht dann am Ende der Pipeline. Wenn ich jetzt mal auf die Pipeline oben verzichte, dann habe ich ein OR und ein XOR als logische Verarbeitung (Zwischen FF De und dem letzten FF mit Ausgang Q). Ich brauche dann zwei Zyklen, bis das Ergebnis bei Q steht. Durch die Pipeline brauche ich aber drei Taktzyklen und habe eine kleinschrittige logische Verarbeitung (OR und XOR sind ja wie im Bild nun aufgeteilt). Warum ist das jetzt schneller?
Peter M. schrieb: > Warum ist das jetzt schneller? Das Ergebnis steht insgesamt später zur Verfügung, das ist richtig. Aber der Takt kann schneller sein. Meist ist ja nicht nur so ein einzelner Pfad vorhanden, sondern noch viele andere, in denen auch vieles gemacht wird und die z.B. schnell zählen sollen oder was weiß ich ... 😀 Stell dir eine größere Zahl von Verknüpfungen vor, die einerseits parallel erstellt werden und andererseits aber unterschiedliches Delay haben und das auch u.U. deutlich temperaturabhängig. Deren Ergebnis soll aber gleichzeitig vorliegen. Dann bist du mit dem höchsten Takt auf diesen langsamsten Pfad gebunden. Diese Pipelining wird häufigst in FPGAs angewendet. Dort sind eine Unmenge FFs mit unterschiedlichsten Aufgaben am werkeln und trotzdem wird eine hohe Taktgeschwindigkeit gefordert. Mir fehlen ein wenig die anschaulichen Beispiele; hier im Forum gibt es aber einige FPGA-Spezialisten, die das hoffentlich sehen und hier bessere Beispiele liefern können.
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.