Hallo, immer wenn ich etwas über uart lese, werden immer nur strings bzw. chars übermittelt. Warum ist das so? Warum wird es nie als werte (z.B. in HEX) dargestellt? Das char nur eine andere Darstellung von werten ist, ist mir bewusst. Aber bei anderen Schnittstellen (z.B. CAN) sieht man nur, dass Werte (meistens in HEX dargestellt) übertragen werden.
Historische Gründe. Da ging Klartext drüber und dann ist es sinnvoll, den auch als Klartext darzustellen.
Liegt an der Art der Anwendung. Uarts wurden viel für z.B. Terminals und Datenaustausch (Texte) genutzt. CAN etc. sind für Werte und dort werden selten Texte gesendet.
Franz schrieb: > Warum wird es nie als werte (z.B. in HEX) dargestellt? Das stimmt ja überhaupt nicht, es gibt zahllose Protokolle, bei denen z.B. die Anzahl der Bytes als Wert übertragen wird - sofern man sich überhaupt damit abgeben will zwischen Char und Byte zu unterscheiden. Auch Prüfsummen sind keine Char. Georg
>anderen Schnittstellen (z.B. CAN) sieht man nur, dass Werte >(meistens in HEX dargestellt) Nein! eigentlich alles als Bit-Brei, je nach ID ist dann von Bit x bis Bit y steht der Wert z
Franz schrieb: > immer wenn ich etwas über uart lese, werden immer nur strings bzw. chars > übermittelt. und das ist auch gut so. Wenn am anderen ein Mensch sitzt, sowieso. Zwischen zwei Maschinen könnte man, aber oft will auch da ein Mensch zuschauen und dann ist Klartext soviel angenehmer. Wenn es um Zahlen mit mehr als 8 Bit geht, hat Klartext den Vorteil, dass sich auch Maschinen mit unterschiedlichen internen Datenformaten verstehen. > Aber bei anderen Schnittstellen (z.B. CAN) sieht man nur, dass Werte > (meistens in HEX dargestellt) übertragen werden. Wobei CAN der Extremfall ist, weil nur maximal 64 Bit im Stück übertragen werden. Würde man einzelne Bytes übertragen, wäre der Overhead immens. Deshalb verzichtet man gerne auf strings. Bei den meisten anderen Schnittstellen ist es Geschmackssache bzw. eine Forderung von "weiter oben", vom Protokoll.
Franz schrieb: > immer wenn ich etwas über uart lese, werden immer nur strings bzw. chars > übermittelt. > > Warum ist das so? Warum wird es nie als werte (z.B. in HEX) dargestellt? Das ist vielleicht üblich, aber keine Regel ohne Ausnahmen! Serial.print(4711,HEX); So sendet Arduino die 4711 hexadezimal codiert Wert über die Uart.
Franz schrieb: > immer wenn ich etwas über uart lese, werden immer nur strings bzw. chars > übermittelt. Nein, es werden Bytes übermittelt. Was sich der Nutzer der Übertragungsstrecke dabei denkt, ist dem UART völlig egal.
Wolfgang schrieb: > Nein, es werden Bytes übermittelt. Was sich der Nutzer der > Übertragungsstrecke dabei denkt, ist dem UART völlig egal. Jepp! Ob Dezimal, Hexadezimal oder Binär sind nur Interpretationen eines Bitstreams für Menschen.
Wolfgang schrieb: > Nein, es werden Bytes übermittelt. Was sich der Nutzer der > Übertragungsstrecke dabei denkt, ist dem UART völlig egal. Und char ist in C ein Datentyp für Byte.
Bei vielen ordentlichen Terminals kann man sowieso einstellen wie es dargestellt werden soll. Hterm zb.
STK500-Besitzer schrieb: > Ob Dezimal, Hexadezimal oder Binär Oder Steuerzeichen.... Wie will man einzelne Zeichen senden und empfangen, wenn man sie nicht von den Steuerzeichen unterscheiden kann?! Entweder führt man ein Protokoll ein, das auch mehrere Zeichen am Stück übertragen kann, oder man vereinbart gar keine uncodierten Daten zu übertragen....
> Und char ist in C ein Datentyp für Byte
Eben. Bis vor kurzem war es so dass "char" der einzige 8bit-Datentyp in
C war.
Seit UTF-16 kann man sich nicht mehr darauf verlassen dass "char" 8 Bit
breit ist. Und heutzutage gibt es in C auch "uint8_t" der garantiert 8
Bit breit ist, also nimmt man besser den. Aber "char" zu nehmen wenn man
ein Byte speichern will ist trotzdem noch weit verbreitet.
Teo schrieb: > Oder Steuerzeichen.... > Wie will man einzelne Zeichen senden und empfangen, wenn man sie nicht > von den Steuerzeichen unterscheiden kann?! Entweder führt man ein > Protokoll ein, das auch mehrere Zeichen am Stück übertragen kann, oder > man vereinbart gar keine uncodierten Daten zu übertragen.... Hä? Die Frage gibt doch wohl eher in Richtung der Darstellung. Ein UART-Datenwort hat i.d.R. eine Länge von acht Datenbits + Steuerbits zwecks Synchronisierung ("lowlevel Protokoll"). Wenn man die mit LEDs darstellt, sieht man nur die binäre Darstellung. Benutzt man eine Tabelle und ein alphanumerisches Display, kann man jedem der 256 Tabelleneinträge eine anderes Zeichen (bzw. eine andere Zeichenfolge) zuweisen. Das wurde mit dem ASCII für 7-Bit (quasi willkürlich) getan. Als dann auch Kleinschreibung umgesetzt wurde, brauchte man ein Bit mehr. Statt Steuerzeichen ("Soft Handshake") kann man auch die Steuerleitungen einer RS232 verwenden. Der Mensch braucht halt irgendwas bekanntes. Hexadezimal passt ja auch schon nicht in die standardmäßig gelernte Dezimalschreibweise.
STK500-Besitzer schrieb: > Hä? > Die Frage gibt doch wohl eher in Richtung der Darstellung. > Ein UART-Datenwort hat i.d.R. eine Länge von acht Datenbits + > Steuerbits zwecks Synchronisierung ("lowlevel Protokoll"). Das is ne Ebene zu tief! Steuer Zeichen nicht Bits! Setzen wir hier mal an: STK500-Besitzer schrieb: > Statt Steuerzeichen ("Soft Handshake") https://de.wikipedia.org/wiki/Datenflusssteuerung#Software-Flusssteuerung,_Software-Handshake,_Software-Protokoll_oder_X-ON/X-OFF Wie willst du davon deine binären Daten unterscheiden?
asd schrieb: > Bis vor kurzem war es so dass "char" der einzige 8bit-Datentyp in C war. > Seit UTF-16 kann man sich nicht mehr darauf verlassen dass "char" 8 Bit > breit ist. Bullshit. Char ist lt. Definition immer der kleinste Datentyp (sizeof(char) == 1), aber nicht zwingend 8 Bit, auf manchen DSPs gibts schlicht keinen 8 Bit Typ.
VN nn schrieb: > Bullshit. Sag nicht Bullshit, das ist zu extrem. Dein Beispiel ist eine exotische Ausnahme. Du hast Recht, dass in C niemand den char auf 8 Bit festgelegt hat. Aber bei ausnahmslos allen mir bekannten Mikrocontrollern und Mikroprozessoren ist das so. Und um diese Geräte dreht sich offenbar die Frage des TO. Weiter oben war schon die richtige Antwort: char war in C auf den allermeisten Plattformen lange Zeit der einzige 8 Bit Datentyp. Man hatte gar keine andere Wahl, außer vielleicht noch void*.
Teo schrieb: > Wie willst du davon deine binären Daten unterscheiden? Gar nicht. Das war auch nicht das Problem der Eingangsfrage.
Ob HEX der ASCII ist eine Frage der Darstellung. Die Übertragung ist **immer binär**.
Wolfgang schrieb: > Franz schrieb: >> immer wenn ich etwas über uart lese, werden immer nur strings bzw. chars >> übermittelt. > > Nein, es werden Bytes übermittelt. Was sich der Nutzer der > Übertragungsstrecke dabei denkt, ist dem UART völlig egal. Streng genommen werden nur bits übermittelt, denn die Interpretation von Bytes ist bereits eine Abstraktion.
Stefan ⛄ F. schrieb: > Sag nicht Bullshit, das ist zu extrem Sein Bullshit bezog sich darauf, dass UTF16 oder sonstwas einen Einfluss auf char hat. > Weiter oben war schon die richtige Antwort: char war in C auf den > allermeisten Plattformen lange Zeit der einzige 8 Bit Datentyp. Und es ist auch heute auf allen Plattformen 8 Bit, die einen 8-bit-Typen haben. Einfach weil sizeof(char)==1 ist (per Definition).
Stefan ⛄ F. schrieb: > Weiter oben war schon die richtige Antwort: char war in C auf den > allermeisten Plattformen lange Zeit der einzige 8 Bit Datentyp. Man > hatte gar keine andere Wahl, außer vielleicht noch void*. Das ist aber keine Frage zu Bitbreite von UARTs, sondern ein Problem der Programmiersprache C. Gelle? Apropos 'char': Unsere Schreibweise, Wörter aus Buchstaben zusammenzusetzen, ist aus mathematischer Sicht das Optimum. Und im Englischen insbesondere, wo man eigentlich keine Sonderzeichen hat und auch die Groß/Kleinschreibung nicht so vordergründig ist. Mit dieser Art, Wörter aus Buchstaben zu bilden, reichten anfangs 7 Bit, später 8 Bit (ANSI) völlig aus, weswegen 8 Bit für ein Textzeichen in westlichen Gefilden die angemessene Daenbreite ist. Lediglich in Gegenden mit eigentlich veralteten Schriftsystemen kommt man damit nicht mehr zurecht, daher als Notlösung die Erweiterungen der Codierung auf 16 Bit. Man erinnere sich einmal an die Bestrebungen zu Mao's Zeiten, auf ein Buchstabensystem zu wechseln. Schade, daß daraus nichts geworden ist. Die Türken hingegen haben es geschafft. W.S.
W.S. schrieb: > Unsere Schreibweise, Wörter aus Buchstaben zusammenzusetzen, > ist aus mathematischer Sicht das Optimum. Nein. > Mit dieser Art, Wörter aus Buchstaben zu > bilden, reichten anfangs 7 Bit, später 8 Bit (ANSI) völlig aus Das ist gut das Doppelte dessen, was bei (mathematisch optimaler) Codierung nötig wäre. Die Buchstaben in natürlicher Spache haben sehr unterschiedliche Häufigkeiten. Wenn man die nach einem Huffmann-Schema codiert, kommt man auf im Mittel 4 Bit pro Zeichen. Und das ist noch nicht das Ende der Fahnenstange. Auf ein "q" folgt fast mit Sicherheit ein "u". Modellierung mit Markov-Ketten bringt nochmal einiges. Ach, es ging dir gar nicht um "mathematisches Optimum"?
W.S. schrieb: > Unsere Schreibweise, Wörter aus Buchstaben zusammenzusetzen, ist aus > mathematischer Sicht das Optimum. Damit wurde viel Papier vergeudet.
W.S. schrieb: > Man erinnere sich einmal an die Bestrebungen zu > Mao's Zeiten, auf ein Buchstabensystem zu wechseln Das hält China zusammen - die Bedeutung eines Zeichens etwa für Haus ist unabhängig von der Sprache, davon gibt es in China einige verschiedene. Das ist etwa so wie wenn man in Europa so ein Zeichen für "Haus" hätte, das in allen europäischen Ländern/Sprachen verstanden wird. Hätte Vor- und Nachteile, aber das unterwickelte deutsch Bildungssystem würde von der Menge der zu lernenden Zeichen in den Abgrund gestossen. So "moderne" Ansätze wie Schreiben nach Gehör wären garnicht möglich. W.S. schrieb: > als Notlösung die Erweiterungen der > Codierung auf 16 Bit Das reicht nicht für den Anspruch alle Schriften der Welt darzustellen, auch 32 bit reicht nicht, derzeit benutzt Unicode 48 bit. STK500-Besitzer schrieb: > Als dann auch Kleinschreibung umgesetzt wurde, brauchte man ein Bit > mehr. Das stimmt natürlich nicht, ASCII7 umfasst auch die Kleinbuchstaben, und das von Anfang an. Auch wenn Teletype und Fernschreiber das nicht konnten. Mein erster Nadeldrucker übrigens auch nicht. Georg
Georg schrieb: > Fernschreiber Das sind "5 Bit pro Byte" Maschinen Die weit verbreitete AVR UART kann 9 Bit pro Byte versenden. usw. Die weiter oben zu findende Aussage: > uint8_t hat immer 8 Bit Beruht auf einer Realitätsverzerrung. Richtig ist: uin8_t existiert nur auf Maschinen, welche nativ 8 Bit Werte verarbeiten können. char dagegen auf allen Kesselchen, auch wenn die Anzahl Bits pro Byte konfigurierbar ist.
Arduino Fanboy D. schrieb: > char dagegen auf allen Kesselchen, auch wenn die Anzahl Bits pro Byte > konfigurierbar ist. Das war durchaus eine vernünftige Design-Entscheidung. Problematisch wurde es erst, als man begann, auf einer Anlage mehrere Zeichensätze gemischt zu verwenden.
Franz schrieb: > Warum ist das so? Warum wird es nie als werte (z.B. in HEX) dargestellt? > Das char nur eine andere Darstellung von werten ist, ist mir bewusst. > Aber bei anderen Schnittstellen (z.B. CAN) sieht man nur, dass Werte > (meistens in HEX dargestellt) übertragen werden. Wie Du die übertragenen Daten darstellst, ist Deine Sache. Du kannst die 8 übertragenen Bits als Char, Hex- oder Binärzahl darstellen, wie Du willst. Gerne auch als Zahl zur Basis 5.
Christian H. schrieb: > Wie Du die übertragenen Daten darstellst, ist Deine Sache. Du kannst die > 8 übertragenen Bits als Char, Hex- oder Binärzahl darstellen, wie Du > willst. Gerne auch als Zahl zur Basis 5. Oder als bunte Lichtpunkte (WS2812).
Stefan ⛄ F. schrieb: > Problematisch > wurde es erst, als man begann, auf einer Anlage mehrere Zeichensätze > gemischt zu verwenden. Nochmal: Die Anzahl der Bits pro Byte hat nichts mit Zeichen und Zeichensätzen zu tun: ein char ist immer ein Byte ist immer von der Größe 1. sizeof(char) = 1.
A. S. schrieb: > ein char ist immer ein Byte ist immer von der Größe 1. Im Gegensatz zu **wchar** welches 16bit groß ist. https://docs.microsoft.com/en-us/cpp/cpp/char-wchar-t-char16-t-char32-t?view=msvc-160
Dirk B. schrieb: > Und char ist in C ein Datentyp für Byte. Das hat auch nichts damit zu tun, was das UART macht. Wie dieser Datentyp im Sourcecode der von dir verwendeten Programmiersprache genannt wird, ist dem UART ebenfalls egal. Namen sind Schall und Rauch. Genauso gut könntest du den Datentyp uint8_t, int8_t oder blabla nennen. Entscheidend ist einzig, dass zum Senden ein Byte im entsprechenden Register des UART landet - woher auch immer das kommt.
Wolfgang schrieb: > Genauso gut könntest du den Datentyp uint8_t, int8_t > oder blabla nennen. Was dann (in C) auch nur typedefs von einem char-Typ sind.
W.S. schrieb: > Und im Englischen insbesondere, wo man > eigentlich keine Sonderzeichen hat und auch die Groß/Kleinschreibung > nicht so vordergründig ist. Mit dieser Art, Wörter aus Buchstaben zu > bilden, reichten anfangs 7 Bit, später 8 Bit (ANSI) völlig aus, weswegen > 8 Bit für ein Textzeichen in westlichen Gefilden die angemessene > Daenbreite ist. Das Ganze geht eigentlich sogar noch weiter, denn ursprünglich war mal angedacht, im ASCII gar keine gesonderte Kodierung für Groß- und Kleinschreibung zu verwenden, sondern die Darstellung für den Menschen rein durch Steuercodes zu realisieren. Sprich: CC-UPPERCASE -> Alles was danach kommt wird groß dargestellt CC-LOWERCASE -> Alles was danach kommt wird klein dargestellt 'A' und 'a' sind prinzipiell keine unterschiedlichen Zeichen, sondern nur zwei Schreibweisen für ein und dasselbe Zeichen. Von daher hätte es intern richtigerweise nur einen Kode für alle 'A' gegeben und nicht die zwei, die wir heute kennen (-> 0x41 und 0x61). Das hätte u.a. den großen Vorteil gehabt, dass uns solche Kuriositäten wie Case-Sensitivity erspart geblieben wären, denn sowohl für uns Menschen als auch für den Computer wäre ein 'A' immer ein 'A', egal ob es groß (A) oder klein (a) dargestellt/geschrieben wird. Case-Sensitive-Dateisysteme sind nach dieser Logik dementsprechend eine Absurdität. Auch die Implementierung von Funktionen wie "strcmp" zum Vergleichen zweier Zeichenfolgen, bei der es auf die Schreibweise nicht ankommt, wäre wesentlich einfacher gewesen und würde weniger Rechenzeit erfordern. Der Hauptgrund, warum man es am Ende nicht gemacht hat, waren u.a. die instablien Übertragungswege der damaligen Zeit. Denn wenn ein UPPER- oder LOWERCASE-Steuerzeichen mal verloren geht (oder vergessen wird), ist die Darstellung für den Menschen natürlich hinterher im Eimer. Aber das alles geht über die Fragestellung hinaus, letztlich kann man doch nur feststellen, dass der UART ein binäres Protokoll ist, über das in der Regel (vor allem historisch bedingt) ASCII-kodierte Zeichen übertragen werden. Das muss aber nicht so sein. Ich habe schon kleine Protokolle zwischen MCU entwickelt, die lediglich aus Command/Event und Werten bestanden, ähnlich einem Assembler-Maschinencode. Dort, wo kein Mensch mit der Ein-/Ausgabe konfrontiert wird, macht ein menschenlesbares Protokoll auch keinen Sinn.
Axel S. schrieb: > Das ist gut das Doppelte dessen, was bei (mathematisch optimaler) > Codierung nötig wäre. Du ziehst hier die binäre Codierung separat heraus und vernachlässigst alle anderen Aspekte. Deshalb ist dein 'nein' falsch. W.S.
Wolfgang schrieb: > Genauso gut könntest du den Datentyp uint8_t, int8_t > oder blabla nennen. Nur mal so am Rande: es soll angeblich auch noch andere Programmiersprachen als C geben. Was Kernighan und Ritchie vor Äonen festgelegt haben ist nicht wirklich ein Naturgesetz und "beweist" nicht dass ein Char 8 bit hat - was sowieso nur manchmal zutrifft, viele Übertragungen mit einem UART arbeiten mit 7 bit (und manchmal auch mit 5). Georg
Wolfgang schrieb: > Entscheidend ist einzig, dass zum Senden ein Byte im entsprechenden > Register des UART landet - woher auch immer das kommt. Entscheidend war und ist, daß für das Serialisieren und Einrahmen einer Anzahl von Bits die Menge 8 viel besser paßt als alle anderen aus der Reihe 1,2,4,8,16,32... Es sind soviel Bits wie geht bevor die Synchronisation zwischen zwei verschiedenen Geräten zu sehr auseinander läuft und zugleich ist es eine Menge, die nahtlos in fast allen Systemen gespeichert und verarbeitet werden kann. OK, als ich it dem Programmieren anfing, da war das auf einer Maschine, die Daten nur in 16 Bit Stücken speichern konnte. Aber das hatte sich später in anderen Architekturen erledigt. W.S.
Florian S. schrieb: > war mal angedacht, im ASCII gar keine gesonderte Kodierung für Groß- und > Kleinschreibung zu verwenden, Bist Du sicher? Klar andere Systeme kamen mit 5 Bit aus, Fernschreiber z.B., mit der von dir beschriebenen Umschaltung zwischen Buchstaben und Zahlen. Aber im ASCII?
Franz schrieb: > Hallo, > > immer wenn ich etwas über uart lese, werden immer nur strings bzw. chars > übermittelt. Hallo, die Frage lässt sich ganz leicht beantworten. Das USART Modul kann immer nur ein Byte übertragen und dann das nächste Byte usw. Jede Ziffer und jeder Buchstabe wird dabei als ASCII übertragen. Darum ist char in der Regel ausreichend, weil im Wertebereich von char alle Zeichen standardisiert sind. Die höheren ASCII Codes sind speziell. Wenn du meinetwegen den Wert 255 überträgst, dann wird das aufgesplittet in 2, 5 und 5. Damit werden 3 Bytes übertragen und die Ziffern im ASCII Code. Nämlich 50, 53 und 53. Das passt alles in ein Byte bzw. Char. Genauso mit Text wenn du dir eine ASCII Tabelle anschaust. Die Sende- und Empfangsroutinen zerlegen das alles und setzen es wieder zusammmen. Die andere Frage mit HEX hat damit nichts zu tun. Das bleibt eine reine Darstellungsoption wie man das lesen möchte. Sprich ein 0xFF wird auch als 2, 5 und 5 im ASCII Code übertragen. Das ist nichts anderes.
Veit D. schrieb: > Jede Ziffer und > jeder Buchstabe wird dabei als ASCII übertragen. Das ist Bullshit. Du kannst einen Code deiner Wahl verwenden. Sinnvoll ist, wenn Sender und Empfänger denselben Code verwenden. ASCII hat sich durchgesetzt, ist aber nicht zwingend.
Hallo, du schreibst doch selbst das sich ASCII durchgesetzt hat. Damit ist ASCII Standard und nur mit dem Standard kann man so eine Frage grundlegend beantworten und erklären. Alles andere sind Spezialitäten die hier nicht hingehören.
Veit D. schrieb: > du schreibst doch selbst das sich ASCII durchgesetzt hat. Damit ist > ASCII Standard und nur mit dem Standard kann man so eine Frage > grundlegend beantworten und erklären. Alles andere sind Spezialitäten > die hier nicht hingehören. HALLO, Du liegst da falsch. Nehmen wir mal einen ATTiny4313 als Beispiel an. Du legst u.a. mit UCSZ0, UCSZ1, und UCSZ2 fest, ob Du 5,6,7,8 oder gar 9 Bit übertragen möchtest. Mit dem 8 Bit breitem UDR-Register sendest und empfängst Du die Daten. Bei einer 9- Bit Datenlänge ist es etwas aufwendiger. Das UDR ist ein Schieberegister, dem es völlig egal ist, welche Daten er schieben soll. Für die Übertragung zu meinem Laserplotter nutze ich sowohl ASCII als auch ganze Bilddateien auch gemischt, wobei der gesamte Zahlenbereich von 0 bis 255 übertragen wird. Es kommt doch darauf an, was Du übertagen möchtest und nicht was sich durchgesetzt hat. Gruß Carsten
Wie werden dann deine Bilddateien übertragen? Man sagt doch der USART nicht das sie in ASCII die Bytes übertragen soll. Das macht die von ganz alleine so. Wie sagst du der USART das sie deine Bilddateien nicht Byte für Byte als ASCII übertragen soll sondern irgendwie anders?
Veit D. schrieb: > Wie werden dann deine Bilddateien übertragen? > Man sagt doch der USART nicht das sie in ASCII die Bytes übertragen > soll. Das macht die von ganz alleine so. Wie sagst du der USART das sie > deine Bilddateien nicht Byte für Byte als ASCII übertragen soll sondern > irgendwie anders? Den USART interessiert es überhaupt nicht, ob das Bilddaten sind. Für den sind das alles nur Bits und Bytes ... Wenn Deine Entwicklungsumgebung meint, Bild oder Text über den UART verschicken zu müssen, dann ist das ein Problem deiner Entwicklungsumgebung, und nicht des UARTs ,,,
Florian S. schrieb: > Das Ganze geht eigentlich sogar noch weiter, denn ursprünglich war mal > angedacht, im ASCII gar keine gesonderte Kodierung für Groß- und > Kleinschreibung zu verwenden, sondern die Darstellung für den Menschen > rein durch Steuercodes zu realisieren. Sprich: > > CC-UPPERCASE -> Alles was danach kommt wird groß dargestellt > CC-LOWERCASE -> Alles was danach kommt wird klein dargestellt Soetwas hat man nicht nur angedacht, sondern Jahrzehnte lang auch praktiziert. Allerdings ging es dabei nicht um Groß- und Kleinbuchstaben, sondern um die Umschaltung zwischen Buchstaben und Zahlen/Sonderzeichen. Als Überrest in der heutigen Technik begegnet einem das noch bei UARTS, die 5 Datenbits unterstützen.
Jens G. schrieb: > Veit D. schrieb: >> Wie werden dann deine Bilddateien übertragen? >> Man sagt doch der USART nicht das sie in ASCII die Bytes übertragen >> soll. Das macht die von ganz alleine so. Wie sagst du der USART das sie >> deine Bilddateien nicht Byte für Byte als ASCII übertragen soll sondern >> irgendwie anders? > > Den USART interessiert es überhaupt nicht, ob das Bilddaten sind. Für > den sind das alles nur Bits und Bytes ... > Wenn Deine Entwicklungsumgebung meint, Bild oder Text über den UART > verschicken zu müssen, dann ist das ein Problem deiner > Entwicklungsumgebung, und nicht des UARTs ,,, Habe ich irgendwas etwas anderes behauptet? Nun lies oder lest doch nochmal in Ruhe bevor sich alle auf meine Aussage stürzen. Das kann doch bald nicht mehr wahr sein.
Georg schrieb: > Das reicht nicht für den Anspruch alle Schriften der Welt darzustellen, > auch 32 bit reicht nicht, derzeit benutzt Unicode 48 bit. Ähm, nein.
"char" ist eine (in der Regel) 8-Bit-Kombination (Byte) zur
Repräsentation
von (meist) lesbaren Zeichen (characters).
Als "char", oder Byte kann ich aber auch alles Mögliche übertragen, nur
eben in 8-Bit-Abschnitte zergliedert.
Ansonsten schauen wir mal auf die USART weit verbreiteter µCs:
The USART accepts all 30 combinations of the following as valid
frame formats:
• 1 start bit
• 5, 6, 7, 8, or 9 data bits
• no, even or odd parity bit
• 1 or 2 stop bits
Wo ist da eine Beschränkung auf "char" zu sehen?
Knut schrieb: > Wo ist da eine Beschränkung auf "char" zu sehen? Du musst da wohl ein paar Ebenen höher schauen. Auf die Funktionen, die die Zeichen/Bytes senden/empfangen. Die haben als Datentyp meist char oder char*
Dirk B. schrieb: > Die haben als Datentyp meist char oder char* Aber nur, weil das die in heutigen datenverarbeitenden Geräten übliche kleinste Datenmenge ist und weil die Erfinder von C das Byte eben Char genannt haben und es gleichermaßen für das Rechnen un zur Textdarstellung benutzen. Ist eigentlich eine Schlamperei in C. Im Gegensatz dazu gibt es in Pascal eine grundsätzliche Trennung zwischen Textzeichen und numerischen Dingen - jedoch in Assembler ist das alles einerlei. W.S.
Georg schrieb: > Das reicht nicht für den Anspruch alle Schriften der Welt darzustellen, > auch 32 bit reicht nicht, derzeit benutzt Unicode 48 bit. Wie kommst du drauf? Für 1.114.112 Codepunkte braucht niemand 48 bit. https://de.wikipedia.org/wiki/Unicode#Codepunkte_und_Zeichen
Wolfgang schrieb: > Georg schrieb: >> Das reicht nicht für den Anspruch alle Schriften der Welt darzustellen, >> auch 32 bit reicht nicht, derzeit benutzt Unicode 48 bit. > > Wie kommst du drauf? > Für 1.114.112 Codepunkte braucht niemand 48 bit. > https://de.wikipedia.org/wiki/Unicode#Codepunkte_und_Zeichen UTF-8, nicht Unicode. 4 Byte reichen dabei nicht.
Wolfgang schrieb: > Wie kommst du drauf? > Für 1.114.112 Codepunkte braucht niemand 48 bit. Stimmt, es sind nur 3 Byte, Sorry, ich hatte die Hexzeichen gezählt. Allerdings gibt es üblicherweise keinen Datentyp mit 3 Byte, wäre auch unpraktisch, daher wird man oft 4 Byte (long integer) für ein universelles Unicode-Zeichen verwenden. Prinzipiell sind die 3 Byte schon überaus grosszügig, selbst für zukünftige Erweiterungen ist nur ein kleiner Teil vorgesehen und auch der aktuelle Bereich bis 10FFFF ist (bisher) spärlich belegt. Georg
Angehängte Dateien:
-

HTerm_senden.png
76 KB
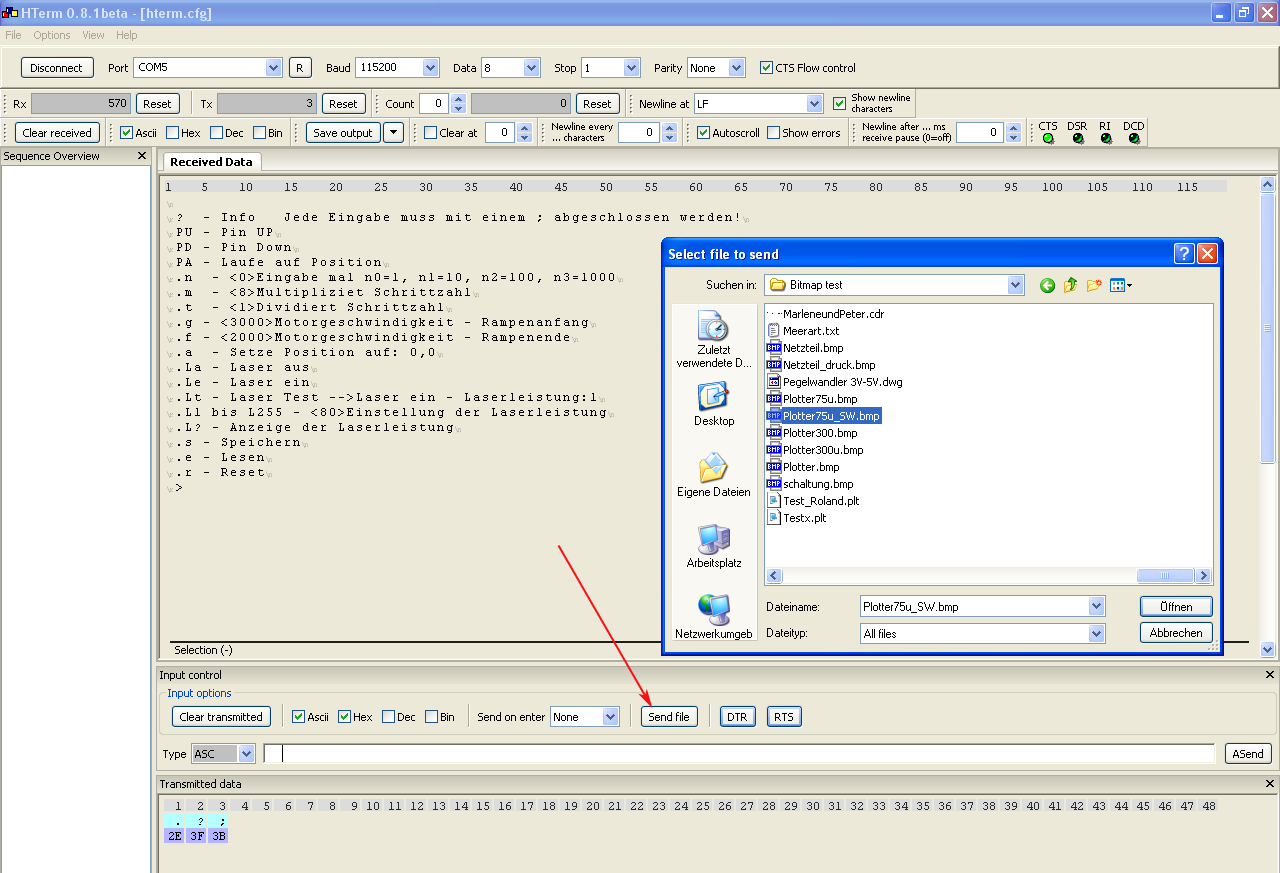
Veit D. schrieb: > Wie werden dann deine Bilddateien übertragen? Ich mache das mit HTerm. Einfach mit Send file die Datei auswählen und öffnen. > Man sagt doch der USART nicht das sie in ASCII die Bytes übertragen > soll. Das macht die von ganz alleine so. Wie sagst du der USART das sie > deine Bilddateien nicht Byte für Byte als ASCII übertragen soll sondern > irgendwie anders? Jedes ASCII Zeichen passt in ein Byte, aber nicht jedes Byte ist auch ein ASCII Zeichen. Stell Dir vor, Du möchtest zwei Messwerte mit jeweils einem Byte übertragen. Dann kann das so aussehen: USART_Transmit: ; Wait for empty transmit buffer lds AH, UCSR0A sbrs AH, UDRE1 rjmp USART_Transmit sts UDR0, AL ;out Das Gleiche fürs 2. Byte – C++ macht das auch so. Stell Dir nun vor, das erste Byte hat den Wert 220 und der 2. Wert ist 5. Wenn Du das als Hexwert senden möchtest, lädst Du das Register R16 also AL mit dem Wert 250 = 0xDC und danach mit 5 = 0x05. Das sind 2 gesendete Byte, die am anderen Ende ankommen. Nun das ganze mit reinem ASCII: Du sendest die Ziffern 2205. Das ist schon mal die doppelte Länge und der Empfänger weiß nicht, ob das nun 2, 205 oder 22,05 oder 220,5 sein soll. Also brauchst Du noch Trennzeichen, um die beiden Zahlen zuzuordnen und Rechenaufwand, für die Wandlung auf beiden Seiten. Gruß Carsten
Hallo, ich verstehe überhaupt nicht warum man aneinander vorbei redet. Du redest vom Protokoll was jeder Programmierer für sich selbst festlegt. Das hat aber nichts mit der eigentlichen USART sprich ASCII Übertragung zu tun. "Dein" Protokoll liegt ein zwei Ebenen darüber. Meine Nachfrage an Dirk sollte ihm zum nachdenken seiner unsinnigen Aussage mir gegenüber bewegen. Er hat es wahrscheinlich schon eingesehen. Zudem deine Erklärung auch falsch ist. Ich hatte das schon vorher beschrieben. Dein Byte Wert 250 wird in 3 ASCII Zeichen zerlegt. In 2, 5 und 0, sprich 50, 53 und 48. Das ist der gemeinsame Nenner für alles weitere. Diese ASCII Werte landen beim empfangen nacheinander in der üblichen char Variablen und sicherlich bei jedem in einem Buffer. Für das zusammensetzen zu 250 auf Empfangsseite musst du selbst sorgen. Genau das macht dann dein Protokoll, weil nur du weißt was du in welcher Reihenfolge sendest und empfängst.
Bauform B. schrieb: > UTF-8, nicht Unicode. 4 Byte reichen dabei nicht. 4 Byte reichen um mit UTF-8 jedes Unicode-Zeichen abzubilden, deswegen verbietet RFC3629 längere Sequenzen auch einfach.
Hallo Veit, Veit D. schrieb: > Das hat aber nichts mit der eigentlichen USART sprich ASCII Übertragung > zu tun. Veit D. schrieb: > Meine Nachfrage > an Dirk sollte ihm zum nachdenken seiner unsinnigen Aussage mir > gegenüber bewegen. Er hat es wahrscheinlich schon eingesehen. Veit D. schrieb: > Zudem deine Erklärung auch falsch ist. Ich hatte das schon vorher > beschrieben. Dein Byte Wert 250 wird in 3 ASCII Zeichen zerlegt. In 2, 5 > und 0, sprich 50, 53 und 48. Das ist der gemeinsame Nenner für alles > weitere. Das stimmt für die UARTs/USARTs die ich kenne nicht. Wenn ich ein Byte mit dem Wert 250 an meine USART zum Senden übergebe, dann sended meine USART (bei 8N1) genau dieses eine Byte, davor ein Startbit, danach ein Stopbit. Welche Protokollebene meinst du denn, die bei dir Bytes in ASCII-Zeichen zerlegt? Ich glaube, du verwechselst Serial.write() mit Serial.print() ... LG, Sebastian
Veit D. schrieb: > Meine Nachfrage > an Dirk sollte ihm zum nachdenken seiner unsinnigen Aussage mir > gegenüber bewegen. Er hat es wahrscheinlich schon eingesehen. Nein, hat er nicht. Weil ASCII da gar keine Rolle spielt. Denn es kann auch der Wert 65 gemeint sein und nicht 'A' Oder gar 164, den es bei ASCII gar nicht gibt.
Dirk B. schrieb: > Veit D. schrieb: >> Meine Nachfrage >> an Dirk sollte ihm zum nachdenken seiner unsinnigen Aussage mir >> gegenüber bewegen. Er hat es wahrscheinlich schon eingesehen. > > Nein, hat er nicht. > Weil ASCII da gar keine Rolle spielt. > Denn es kann auch der Wert 65 gemeint sein und nicht 'A' > Oder gar 164, den es bei ASCII gar nicht gibt. Veit hat schon recht, nur er kommt damit nich weit. Weder in seinen Projekten, noch im Rest der Welt.
Hallo, @ Sebastian: Schau dir bitte mit einem Datalogger oder Oszi mit Dekoderfunktion die eigentliche Übertragung an. Nimm die ASCII Tabelle zur Hand und vergleiche.. @ Dirk: Dein Antworten beweisen das du dich mit dem Thema überhaupt nicht befasst hast. Ein ASCII Code 65 kann niemals ein Wert 65 sein. Das geht überhaupt nicht. Ein ASCII Code stellt immer! nur ein einziges Zeichen dar. Also entweder die 6 oder 5. Was im ASCII Code 54 und 53 entspricht. Nimm einen Datalogger und schau es dir selbst an. @ Teo: Warum ich damit nicht weit kommen soll weiß ich nicht. Ich habe das im Griff.
Veit D. schrieb: > @ Sebastian: > Schau dir bitte mit einem Datalogger oder Oszi mit Dekoderfunktion die > eigentliche Übertragung an. Nimm die ASCII Tabelle zur Hand und > vergleiche.. Du meinst, welche Pegel/Bits genau auf der Leitung zu messen sind, wenn zum Beispiel auf einem Arduino Serial.write(250) aufgerufen wird? Und deiner Meinung nach wäre dann bei einer 8N1-Konfiguration UART auf der Leitung S01001100P S10101100P S00001100P zu erwarten? LG, Sebastian
Veit D. schrieb: > Dein Antworten beweisen das du dich mit dem Thema überhaupt nicht > befasst hast. Ein ASCII Code 65 kann niemals ein Wert 65 sein. Das geht > überhaupt nicht. Ein ASCII Code stellt immer! nur ein einziges Zeichen > dar. Also entweder die 6 oder 5. Was im ASCII Code 54 und 53 entspricht. > Nimm einen Datalogger und schau es dir selbst an. Wie wird dann der Wert 54 oder 53 übertragen? Als "5453"? Ich zitiere nochmal die komischen Stellen > Ein ASCII Code 65 > Was im ASCII Code 54 und 53 Und wie gesagt, ASCII ist ein 7-Bit Code. Wie überträgst du da 8 Bit?
Angehängte Dateien:
-

print_250.png
4,9 KB -

print_2501.png
5,5 KB -

Text.png
12 KB -

write_250.png
8,1 KB -

write_2501.png
8,1 KB



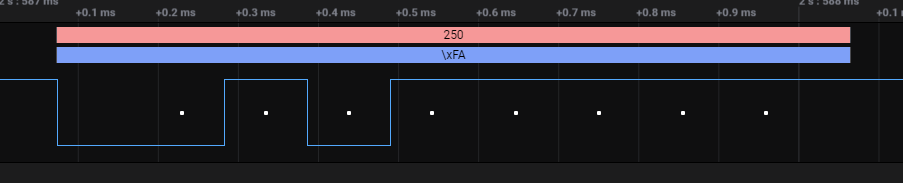

Hallo, @ Sebastian: Du bist auf dem richtigen Weg. Du hast das genau richtig erkannt. Damit war das schon einmal nicht umsonst. Damit du das auch siehst habe ich das aufgezeichnet. rot ist dezimaler ASCII Code und blau druckbare Zeichen laut ASCII Tabelle. Allerdings, dass zur Korrektur, Zeichenketten gibt man mit print raus. write schickt direkt ein Steuerzeichen raus. Kann man Zweck entfremden für reine Byte Übertragungen. Dazu das Bsp. mit dem Dezimalwert 2501. Mit write klassischer Bereichsüberlauf. Mit print wie man das erwartet. write nutzt man zum Bsp. um gezielte Steuerzeichen zu senden. Bsp. auf einem Display wenn im Zeichensatz Symbole außerhalb des ASCII Standards darstellbar sein sollen. Bsp. kannst du statt print(0) auch write(48) senden. Einmal dezimal und das andere ASCII Code. In beiden Fällen gibts die Ziffer 0. Probiere es aus. Das alles bekommst du rein im Terminal nicht so mit, weil die Ziffern wie rausgeschickt optisch aneinandergereiht wieder dargestellt werden. Jedoch ist der Bytewert 250 im Terminal schon kein Bytewert mehr sondern 3 einzelne Ziffern. Das merkst du spätestens dann auf der Empfangsseite wenn du alle Zeichen in einen Buffer einliest und dann erstmal nach Integer wandeln musst. Ansonsten kannst du den Buffer zwar rein optisch richtig ausgeben, aber rechnen kannst du damit nicht. Hast ja eine Zeichenkette mit 3 einzelne Ziffern im Buffer stehen und keinen Integer 250. @ Dirk: Du solltest dich schämen und mir Anfangs nicht blöd kommen. Wie wird denn nun wohl 54 oder 53 oder 1258495050 oder was auch immer übertragen? Wie wird denn ein Text "Ich weiß es." übertragen? Ich kann mich nur wiederholen. Jedes einzelne Zeichen wird für sich übertragen. 5 gefolgt von 4. 5 gefolgt von 3 1 gefolgt 2, dann 5, dann 8, 4, 9, 5, 0, 5 und 0 Dezimal geschrieben. Wichtig zu wissen ist das alles in Einzelne! Zeichen zerlegt wird, damit ist das alles mittels ASCII Code darstellbar und übertragbar. Ansonsten könnte man nie Werte größer Byte versenden und empfangen. Muss nur zerlegt und wieder zusammengesetzt werden. Das muss jeder programmieren oder er nutzt fertige Bibliotheken dafür. Jetzt sind wir wieder bei der Eingangsfrage char. Weil in ein char alle standardisierten Zeichen der ASCII Tabelle reinpassen und man in der Regel damit auskommt. Alles was darüber hinausgeht muss man ausprobieren. Heißt zwei verschiedene Displays werden sicherlich mit write(211) verschiedene Sonderzeichen darstellen. Je nach eingebauten Zeichensatz. Ich denke damit sollte das erschöpfend erklärt sein.
> Jedoch ist der Bytewert 250 im Terminal schon kein Bytewert > mehr sondern 3 einzelne Ziffern. Das ist doch Quatsch. Es kommt darauf an, wie man die Übertragung definiert (Protokoll). Man kann den Wert 250 übertragen wie man will. als write(250), print(250), print(250,16), print(250,2) oder sonstwie. Nur: Sender und Empfänger müssen die gleiche Sprache sprechen, d.h. die Bits gleich interpretieren. Dabei ist man überhaupt nicht auf 5-9 bits pro "Char" beschränkt, nur weil die meisten UARTS das können. Man kann mit Soft-UART problemlos 16 oder mehr Bits pro "Durchgang" senden. Der Empfänger muss es nur wissen und ensprechend decodieren (können). 8N1 ist halt der am meisten verbreitete Modus. > Das merkst du spätestens dann auf der Empfangsseite wenn du alle > Zeichen in einen Buffer einliest und dann erstmal nach Integer > wandeln musst. Nur weil Du es so machst, heißt noch lange nicht, dass das die einzige Möglichkeit ist.
War ja fast schon klar das jetzt der Nächste um die Ecke mit irgendeinem Bsp. abseits vom Standard kommt. Ist Foren typisch. Jetzt muss schon eine verbogene 16 bittige Software Serial herhalten um widersprechen zu können. Ich fass es nicht. Bei soviel Ignoranz bin ich raus.
Tippgeber schrieb: > Man kann mit Soft-UART problemlos 16 oder mehr Bits pro "Durchgang" > senden. Mit "problemlos" ist es in dem Moment vorbei, wo die Taktfrequenzen auf Sender- und Empfängerseite nicht ausreichend genau überein stimmen.
250 ist nicht "250" Das erste passt in ein byte, das Zweite sind drei Zeichen oder drei Bytes. Da Terminalprogramme zur Darstellung von Text gedacht sind, benutzen alle Programme, die zur Nutzung mit Terminalprogrammen gedacht sind, die Textuelle Darstellung "250". Manchmal werden auch andere Zahlensysteme benutzt, zum Beispiel hexadezimal. Ein Beispiel: http://stefanfrings.de/serial_io/index.html Tippgeber schrieb: > Man kann den Wert 250 übertragen wie man will. > als write(250), print(250), print(250,16), print(250,2) oder sonstwie. Veit D. schrieb: > War ja fast schon klar das jetzt der Nächste um die Ecke mit irgendeinem > Bsp. abseits vom Standard kommt. Ist Foren typisch. Jetzt muss schon > eine verbogene 16 bittige Software Serial herhalten um widersprechen zu > können. Ich fass es nicht. Bei soviel Ignoranz bin ich raus. Falls du dich dabei auf "print(250,16)" beziehst: Hier wird die Zahl hexadezimal ausgegeben. Das hat nichts mit 16 Bit zu tun.
Veit D. schrieb: > Ich fass es nicht. Ja, das bemerke ich. > Bei soviel Ignoranz bin ich raus. Bleib ruhig, vielleicht lernst du es dann doch noch. Aber bleiben wir mal bei deinem ASCII. Wenn ich in eine Tabelle schaue, steht da bei 'A', dass es den Wert 65 (dezimal) hat oder 0x41 (hexadezimal) oder 0b01000001 (dual) Es ist immer derselbe Wert, nur die Darstellung ist anders - bzw. die Interpretation bei ASCII mit dem 'A' Diese 65 könne aber auch ein Fehlercode sein oder eine Koordinate. Und das spielt bei der Übertragung gar keine Rolle, welche Bedeutung der Wert hat. Und beachte bitte, das 'A' ein Zeichen ist, wie z.B. '6' Und '6' hat bei ASCII nicht den Wert 6 sondern 54 Und die Darstellung vom Wert 54 besteht aus den Zeichen '5' und '4'
Veit D. schrieb: > @ Sebastian: > Allerdings, dass zur Korrektur, Zeichenketten gibt man mit print raus. > write schickt direkt ein Steuerzeichen raus. Kann man Zweck entfremden > für reine Byte Übertragungen. Dazu das Bsp. mit dem Dezimalwert 2501. > Mit write klassischer Bereichsüberlauf. Mit print wie man das erwartet. Man benutzt die serielle Schnittstelle für vieles. Die Übertragung lesbarer Texte, die du als einzig richtige ansiehst, ist dabei nur eine Möglichkeit. Ich lese mit der UART die Statusdaten meines Viessmann-Ölbrenners über eine serielle Infrarot-Schnittstelle genannt Optolink (4800 Baud 8E2) aus, und dort werden alle Werte als reine Bytes (little-endian, und im Zweierkomplement wo negative Werte vorkommen) übertragen und eben nicht als ASCII-Zeichen. Dein Beispiel des Werts 2501 wird der Ölkessel also nicht als 50 (0x32), 53 (0x35), 48 (0x30) und 49 (0x31) senden, sondern als 197 (0xC5) und 9. Das ist auch keine Zweckentfremdung, sondern eine sehr übliche Verwendung. LG, Sebastian
Angehängte Dateien:
-

vor_senden.png
33 KB -

nach_senden.png
41 KB
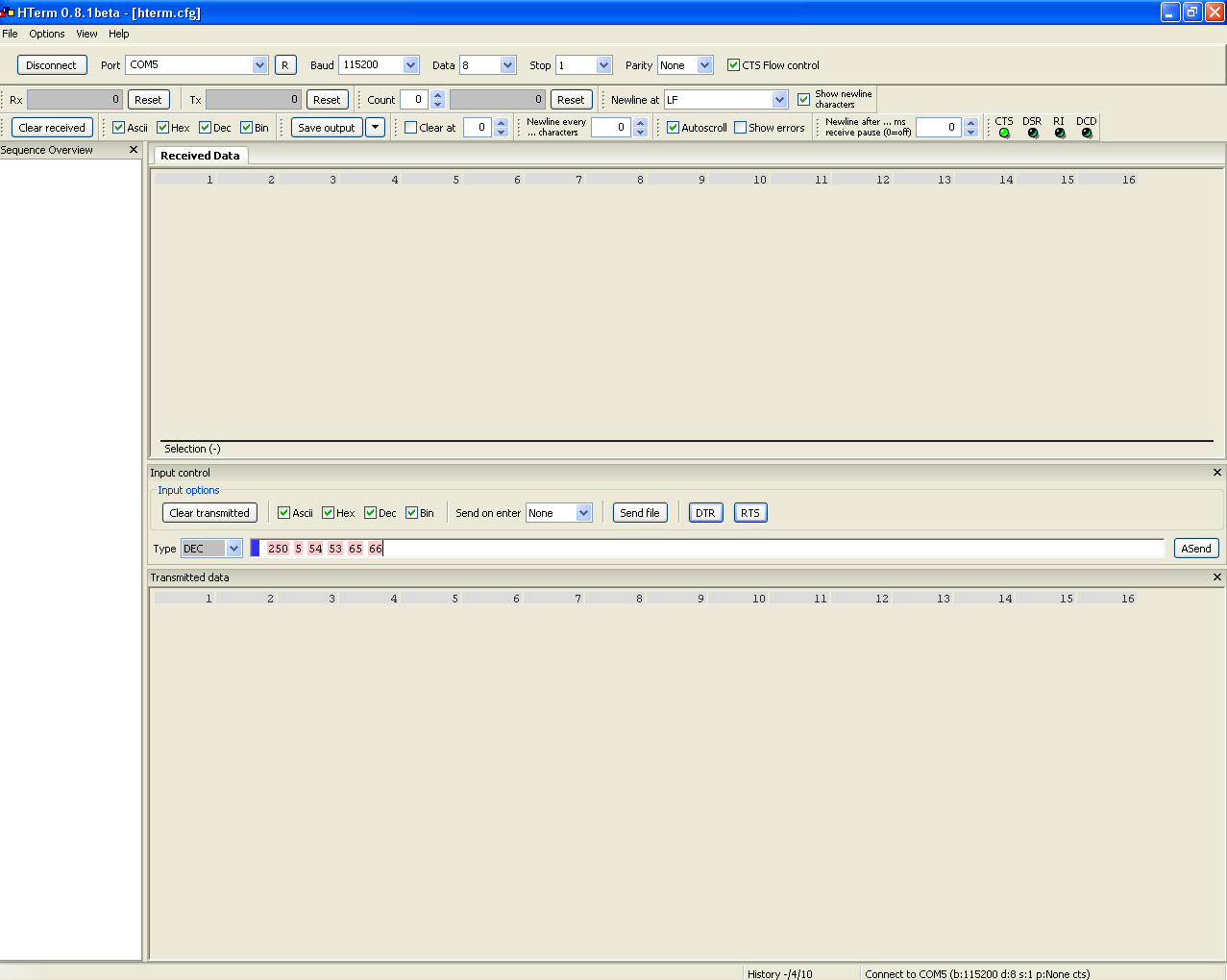
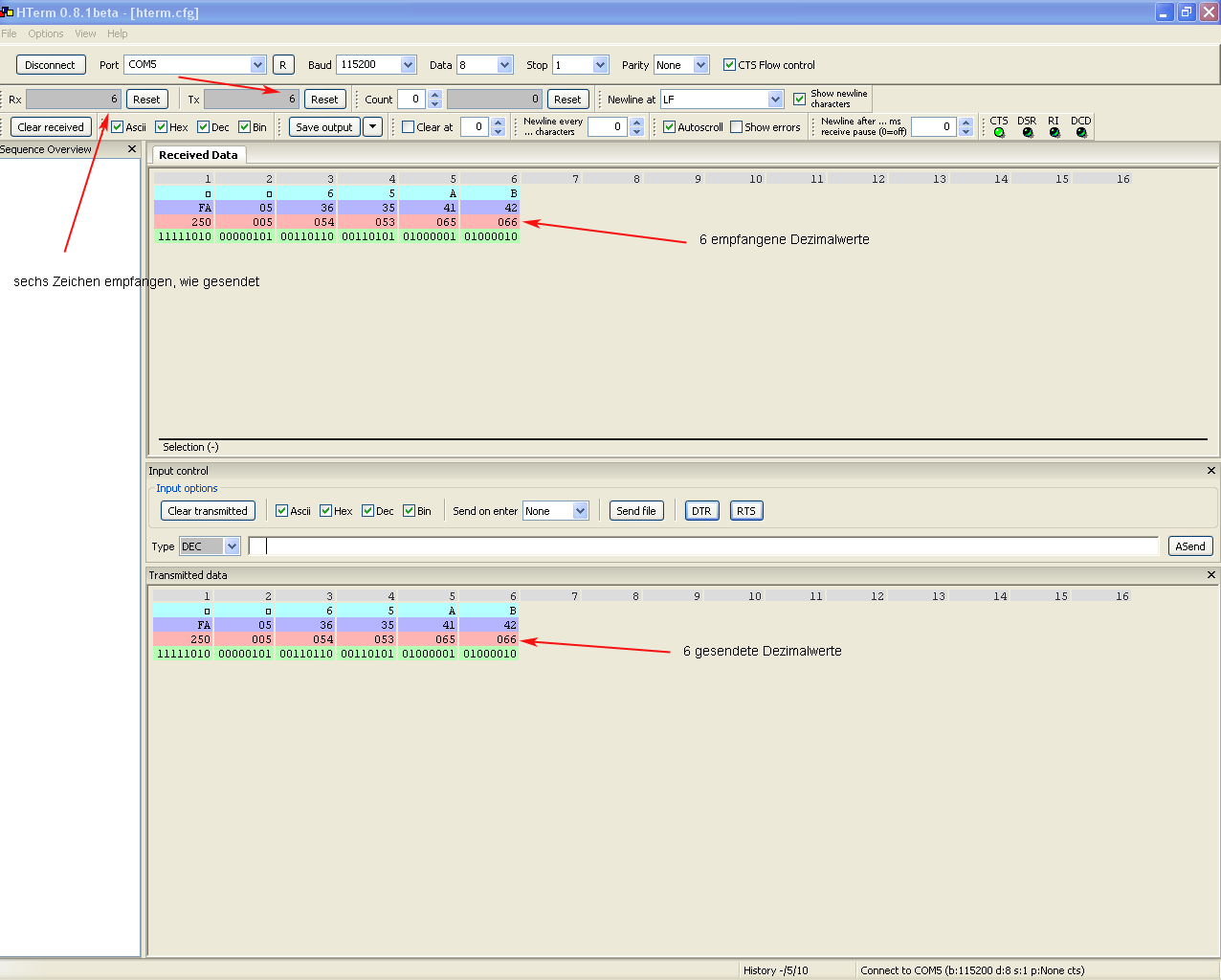
Veit D. schrieb: > Wichtig zu wissen ist das alles in Einzelne! Zeichen zerlegt wird, damit > ist das alles mittels ASCII Code darstellbar und übertragbar. Ansonsten > könnte man nie Werte größer Byte versenden und empfangen. Muss nur > zerlegt und wieder zusammengesetzt werden. Das muss jeder programmieren > oder er nutzt fertige Bibliotheken dafür. Hallo, ich habe, um das mal anschaulich zu machen, die sechs Dezimalzahlen 250, 5, 54, 53,65 und 66 mit HTerm über eine Serielle Schnittstelle geschickt und über eine Brücke TX-RX wieder empfangen. Jeder möge jetzt selbst seine Schlüsse daraus ziehen. Zum Thema „Standard“: Sieht man sich die bekannten seriellen Schnittstellen wie Druckerport, Scanner usw. an, sollte spätestens da klar sein, das da kein ASCII Übertragen wird. Gruß Carsten
Carsten-Peter C. schrieb: > Zum Thema „Standard“: Veit wird das nie begreifen: für ihn ist Standard wie er es mit seiner beschränkten Qualifikation immer macht und alles andere ist falsch. Ein richtiger Ichling und vollkommen resistent gegenüber Fakten. Georg
Georg schrieb: > Ein > richtiger Ichling und vollkommen resistent gegenüber Fakten. Nein, dem muss ich widersprechen! Habe ihn mehrfach einsichtig erlebt. Ist manchmal etwas zäh, ihn von einer vorgefassten Projektion/Sichtweise runter zu bekommen. Aber dann gehts...
Die Initiative von Veit, die Bilder von den realen Übertragungen zur Diskussion zu stellen, finde ich hilfreich und anerkennenswert. Auf der Basis von solchen Fakten lassen sich dann Missverständnisse (im Sinne von der eine versteht nicht was der andere sagen will, und umgekehrt) klären. Danach muss man ja nicht einer Meinung sein. LG, Sebastian
Carsten und Dirk: Sendet in HTerm Ganzzahlen größer Byte Wertebereich und guckt euch das an. Sebastian: Das sendet dein Kessel so ganz sicher nicht. Ansonsten erkläre bitte wie du aus 197 und 9 zurück auf die Ganzzahl 2501 kommst.
Veit D. schrieb: > erkläre bitte wie du aus 197 und 9 zurück auf die Ganzzahl 2501 kommst. ein Tipp: wieviel ist 9 * 256?
Veit D. schrieb: > Sendet in HTerm Ganzzahlen größer Byte Wertebereich und guckt euch das > an. Es ist doch egal wie HTerm das macht. Bei mehreren Bytes werden die Bytes hintereinander gesendet - das geht auch, ohne auf die Codierung zu achten. Ein Protokoll wäre nett, damit man das Ende erkennen kann.
Veit D. schrieb: > Sebastian: Das sendet dein Kessel so ganz sicher nicht. Ansonsten > erkläre bitte wie du aus 197 und 9 zurück auf die Ganzzahl 2501 kommst. Hab ich doch geschrieben: Reine bytes, little-endian, negative Zahlen im Zweierkomplement. Siehe z.B. https://de.wikipedia.org/wiki/Byte-Reihenfolge. Gib mir eine Stunde, ich fabriziere mal einen Mitschnitt an den seriellen Ports. LG, Sebastian
Ach jetzt plötzlich braucht es ein Protokoll damit am Ende wieder alles stimmt wie gesendet? Du/Ihr hattet die ganze Zeit erzählt das wäre das Protokoll. Nun lest nochmal in Ruhe was ich die ganze Zeit geschrieben habe. In der Ursprungsfrage ging es übrigens um char und ihr schweift immer ab. Genauso ist die Interpretation von 9*256 + 197 nur eine Frage des darüberliegendes Protokolls was der Programmierer festgelegt ist. Es muss schon vorm senden so zerlegt werden um überhaupt von der 9 zu wissen. Denn die 256 taucht nirgends in der Übertragung auf. An Hand der reinen Werte von 197 und 9 kommt man nie zurück auf 2501.
Veit D. schrieb: > War ja fast schon klar das jetzt der Nächste um die Ecke mit irgendeinem > Bsp. abseits vom Standard kommt. Hmm, Standard. Also welchen denn? Kannst du mal einen nennen? Ich meine so einen echten Standard. Von einer Standardisierungsorganisation. Mit Nummer und so. Am besten einen der lange und weit bekannt ist. Während du noch nachdenkst suche ich mal einen raus. Welchen nehmen wir denn? Ah, ich ziehe mal V.24 aus dem Sumpf. V.24, die Älteren unter uns erinnern sich, beschreibt die serielle Schnittstelle, die auch als RS-232 bekannt ist. Das Ding was man mit einem UART + Pegelwandler bedient. V.24 ist die Version der Telefon-Leute, also derjenigen, die das Zeug erfunden haben. Erstmalig unter der Bezeichnung V.24 im Jahre 1964 veröffentlicht. Also, was steht da in Kapitel 1, Unterkapitel 1.1 der V24 (2/2000)? >> 1 Scope >> >> 1.1 Range of application >> >> This Recommendation applies to the interconnecting circuits being >> called interchange circuits at the interface between DTE and DCE for >> the transfer of binary data, control and timing signals as >> appropriate. >> ... "binary data". Scheiße, die haben es doch echt gewagt nur von "binary data" zu reden. Kein Wort über ASCII oder IA5. Nix, im ganzen Standard nicht. > Ich fass es nicht. Bei soviel Ignoranz bin ich raus. Also keinen Standard von dir? Ja, dann lauf mal ganz schnell.
Veit D. schrieb: > Man sagt doch der USART nicht das sie in ASCII die Bytes übertragen > soll. Das macht die von ganz alleine so Ein USART ist ein Schieberegister, das parallel ins Senderegister geladene Daten seriell, Bit für Bit, rausschiebt. Die Behauptung ein USART würde das Byte mit dem Wert 250 automatisch in 3 ASCII-Zeichen 2,5 und 0 aufteilen und nacheinander senden ist völlig absurd und spricht für ein vollkommenes technisches Unverständnis. Hoffnungsloser Fall. Georg
Veit D. schrieb: > Du/Ihr hattet die ganze Zeit erzählt das wäre das > Protokoll. Es gibt das serielle Protokoll (wo fängt ein Byte an, wo hört es auf) und ein Protokoll, das die Daten interpretiert (welche Bedeutung haben diese Bytes) > Nun lest nochmal in Ruhe was ich die ganze Zeit geschrieben habe. Du hast geschrieben, es gibt nur ASCII und der Wert 65 wird als zwei Zeichen '6' und '5' übertragen - und das ist Bullshit. > In der > Ursprungsfrage ging es übrigens um char und ihr schweift immer ab. Die ist schon lange geklärt.
Veit D. schrieb: > Ach jetzt plötzlich braucht es ein Protokoll damit am Ende wieder alles > stimmt wie gesendet? Kein Protokoll, eine Darstellung. Wenn du einen Wert wie die Zahl 2501, oder die Zahl -17.3, oder sogar die Zeichenkette "Hallo", physisch repräsentieren willst dann brauchst du natürlich eine verabredete Darstellung solcher Werte. ASCII ist dabei eine Möglichkeit unter vielen. Veit D. schrieb: > Wenn du meinetwegen den Wert 255 überträgst, dann wird das aufgesplittet > in 2, 5 und 5. Damit werden 3 Bytes übertragen und die Ziffern im ASCII > Code. Nämlich 50, 53 und 53. [...] > Die Sende- und Empfangsroutinen zerlegen das alles und setzen es wieder > zusammmen. Werte können als ASCII dargestellt übertragen werden. Das ist aber kein Zwang, andere Darstellungen sind auch möglich und werden auch oft benutzt. Die eigentliche UART Sende- und Empfangshardware zerlegt nichts und setzt auch nichts wieder zusammen. Veit D. schrieb: > Man sagt doch der USART nicht das sie in ASCII die Bytes übertragen > soll. Das macht die von ganz alleine so. Nein, macht sie nicht. Das macht bei Arduino der folgende Code in Print.cpp der Klasse Print, von der HardwareSerial (über Stream) erbt:
1 | size_t Print::printNumber(unsigned long n, uint8_t base) |
2 | {
|
3 | char buf[8 * sizeof(long) + 1]; // Assumes 8-bit chars plus zero byte. |
4 | char *str = &buf[sizeof(buf) - 1]; |
5 | |
6 | *str = '\0'; |
7 | |
8 | // prevent crash if called with base == 1 |
9 | if (base < 2) base = 10; |
10 | |
11 | do {
|
12 | char c = n % base; |
13 | n /= base; |
14 | |
15 | *--str = c < 10 ? c + '0' : c + 'A' - 10; |
16 | } while(n); |
17 | |
18 | return write(str); |
19 | } |
20 | |
21 | size_t Print::print(long n, int base) |
22 | {
|
23 | if (base == 0) {
|
24 | return write(n); |
25 | } else if (base == 10) {
|
26 | if (n < 0) {
|
27 | int t = print('-');
|
28 | n = -n; |
29 | return printNumber(n, 10) + t; |
30 | } |
31 | return printNumber(n, 10); |
32 | } else {
|
33 | return printNumber(n, base); |
34 | } |
35 | } |
LG, Sebastian
Hallo Sebastian, ich danke dir für deine Geduld und den letzten Wink mit dem Zaunpfahl. Stimmt, die print Klasse zerlegt "nur" alle Zeichenketten. Der Rest ist Darstellung wie man es gerade einstellt. Die könnte das auch komplett anders zerlegen. Wegen der Byte weisen Übertragung und dem char dachte ich wirklich es gibt nur den einen ASCII Standard für alles auf unterster Ebene. Fehler eingesehen Irrtum beseitigt. Manchmal dauert es länger. Jetzt ist mir das irgendwie peinlich. Danke nochmal.
Es ist vielleicht besser, die Besonderheiten von Arduino nicht automatisch als einzige Möglichkeit oder Standard aufzufassen.
Veit D. schrieb: > Carsten und Dirk: > Sendet in HTerm Ganzzahlen größer Byte Wertebereich und guckt euch das > an. Hallo Veit, um es vorweg zu nehmen, ich sende einfach die nötigen Bytes. Um ein Beispiel zu geben, möchte ich noch mal auf die Bilddateien zurückkommen. Mein Laserplotter kann entweder HPGL oder eben Bilddateien verarbeiten. HPGL ist Klartext in ASCII. Bilder müssen in SW und im .bmp - Format vorhanden sein. Alles andere macht für meine Anwendung keinen Sinn. Die ersten 2 Zeichen sind BM (424D in Hexadezimal) gibt an, dass es sich um eine Windows-Bitmap handelt. Danach kommen Bytes, die ich überspringe. Irgendwann kommen: Bildbreite (auf 4 Bytes): Anzahl der horizontal angeordneten Pixel (width). Und Bildhöhe (auf 4 Bytes): Anzahl der vertikal angeordneten Pixel (height). Danach weiß ich, wo mein eigentliches Bild anfängt und wo es aufhört. Ganz ohne Protokoll. Und dann irgendwann die Bildinformation z.B. 0xE1,…… usw. 0xE1 = 11100001 wobei die 1 für einen schwarzen Punkt steht und die 0 für einen weißen. Ganz ohne ASCII. Ich habe mein Programm selbst in Assembler geschrieben und es läuft. Das habe ich hier vor einiger Zeit in: Zeigt her, Eure Kunstwerke veröffentlicht. Gruß Carsten
Ist alles richtig Carsten. Ich war zu sehr auf die ASCII Darstellung fixiert und die Interpretation der Zeichen. Dabei habe ich mir auch schon ein Protokoll geschrieben wo ich im Datenstrom Escape Zeichen interpretieren/filtern muss. Ich bin heftig durcheinander gekommen. Sagen wir mal so. :-)
Angehängte Dateien:
-

optolink.png
50 KB
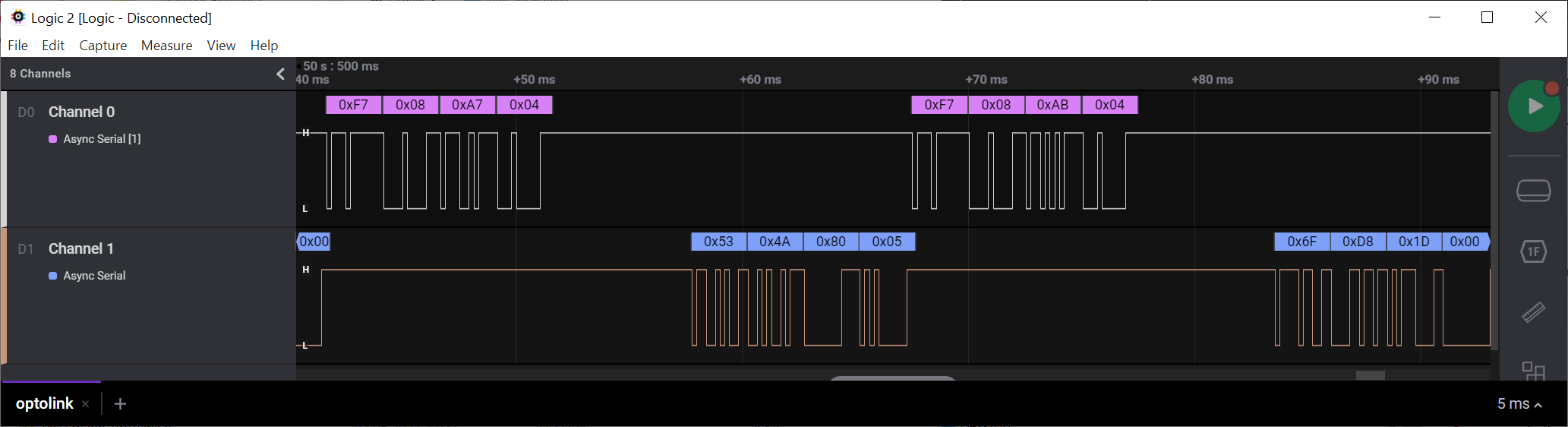
Veit D. schrieb: > Der Rest ist Darstellung wie man es gerade einstellt. Anbei noch wie angekündigt ein Ausschnitt aus einer seriellen Optolink-Kommunikation. Der Mikrocontroller sendet auf Channel 0, der Ölbrenner auf Channel 1. Es werden zwei 32-Bit-Werte jeweils als 4 Bytes abgerufen, und zwar die Betriebssekunden in Stufe 1 und die in Stufe 2. Die Rückgabewerte des Heizkessels lauten 0x53 0x4A 0x80 0X05 (also 0x5804A53 = 92293715 Sekunden) und 0x6F 0xD8 0x1D 0x00 (also 0x1DD86F = 1955951 Sekunden). LG, Sebastian
Arduino Fanboy D. schrieb: > Georg schrieb: >> Ein >> richtiger Ichling und vollkommen resistent gegenüber Fakten. > > Nein, dem muss ich widersprechen! > > Habe ihn mehrfach einsichtig erlebt. > Ist manchmal etwas zäh, ihn von einer vorgefassten Projektion/Sichtweise > runter zu bekommen. Aber dann gehts... Veit D. schrieb: > ich danke dir für deine Geduld und den letzten Wink mit dem Zaunpfahl. Veit D. schrieb: > Ist alles richtig Carsten. Ich war zu sehr auf die ASCII Darstellung > fixiert und die Interpretation der Zeichen. Damit lagst du (Arduino Fanboy D.) ja richtig, auch wenn es lange gedauert hat. Also, Veit D.: du bist doch kein hoffnungsloser Fall :-) Ende gut, alles gut!
Hallo, Arduino Fanboy kennt mich schon fast zu gut. ;-) Ich habe nun meinen älteren Code rausgeholt und nachgeschaut. Hätte ich eher machen sollen. Ich mach das genauso wie Sebastians Heizkessel. Der Bufferinhalt wird mittels write gesendet, sprich 9 Raw-Bytes oder wie man dazu sagt und paar Steuercodes.
1 | union Nachricht |
2 | {
|
3 | struct
|
4 | {
|
5 | uint8_t toAddr; |
6 | uint8_t fromAddr; |
7 | uint8_t cmd; |
8 | int32_t data; |
9 | uint16_t crc; |
10 | };
|
11 | const static uint8_t length = sizeof(toAddr) + sizeof(fromAddr) + sizeof(cmd) + sizeof(data) + sizeof(crc); |
12 | uint8_t asArray[length]; // für Zugriff über Index |
13 | } empfDaten, sendDaten; // zwei gleiche Buffer anlegen |
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.