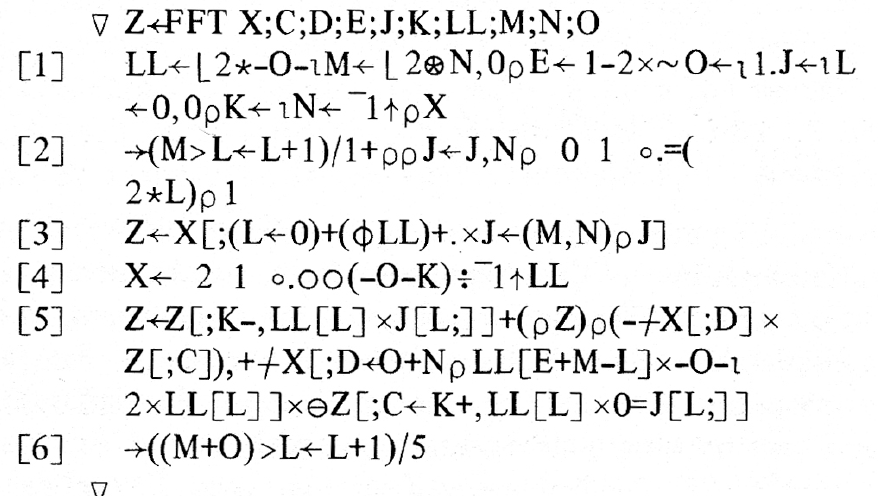Du übersiehst den Drang mancher Leute, sich mit Tausend #define
irgendwas zurechtzubasteln, was erstmal geht aber nur Verwirrung
stiftet.
Sonst hast du recht - es ist ganz schlicht in C, und auch nicht schwer
zu verstehen.
Logische Ausdrücke liefern (als int betrachtet) immer 0 oder 1.
Bei der Verwendung von Zahlen oder Zeigern wird 0 als false betrachtet,
alles andere als true.
Mehr muß man nicht wissen.
Egon D. schrieb:> Was also übersehe ich?
Nichts, du hast damit meine Aussage wiederholt und begründet:
Stefan ⛄ F. schrieb:> Das ist doch ganz einfach:> - True hat den Wert 1, false hat den Wert 0> - Alle Werte ungleich 0 sind wahr
Egon D. schrieb:> Das bedeutet für meinen schwachen Verstand: Wenn kein> Operator in der Liste oben fehlt, dann liefern alle> Vergleichs- und sonstigen booleschen Operatoren nur> entweder 0 oder 1 als Ergebnis, und nix anderes.
Genau so ist es.
> Fazit: Mir will scheinen, dass es bei der Auswertung> boolescher Ausdrücke überhaupt kein Problem gibt.
Sagen wir mal so: Die Probleme, die einige hier sehen, sind rein
akademischer Art. Ich hatte diese Probleme noch nie, obwohl ich, bevor
ich C lernte, hauptsächlich Pascal gemacht habe, das im Gegensatz zu C
klar zwischen Boolean und Integer unterscheidet.
Egon D. schrieb:> Was also übersehe ich?
Nichts. Es hat doch auch niemand etwas anderes behauptet. Es gab nur ein
paar, die zur reinen optischen Leseerfahrung Ausdrücke z.B. im if in 0/1
wandeln möchten um dann auch auf == true abfragen zu dürfen.
Wer das will, kann das machen, C kam viele Jahre ohne bool aus und die
Regelung mit 0 (nicht erfüllt) und 1 (erfüllt) als Ergebnis boolscher
Ausdrücke deckt sich mit 0 (nicht erfüllt) und !=0 (erfüllt) bei
Abfragen.
Eine Sonderstellung nehmen hier Bitfelder ein, die bei "int" oder Bool
keinen Wert von 1 annehmen können. Das spielt in der Praxis keine Rolle,
Warnungen sind dementsprechend angepasst oder anpassbar. Ein Vergleich
auf "true" schlägt dann aber immer fehl.
Klaus W. schrieb:> Sonst hast du recht - es ist ganz schlicht in C,
Ja, offensichtlich.
> und auch nicht schwer zu verstehen.
Das sehe ich etwas anders: Ob etwas schwer zu verstehen
ist, hängt nicht nur von der Kompliziertheit des
Sachverhaltens ab, sondern auch von der Güte der Erklärung :)
Mir steht nur die (zweite) deutsche Ausgabe des K&R zur
Verfügung; das Buch ist zwar als historisches Dokument
interessant, aber das VERSTEHEN kommt in der Regel erst
bei den Diskussionen hier auf µC.net :)
Stefan ⛄ F. schrieb:> Nichts, du hast damit meine Aussage wiederholt> und begründet:>> Stefan ⛄ F. schrieb:>> Das ist doch ganz einfach:>> - True hat den Wert 1, false hat den Wert 0>> - Alle Werte ungleich 0 sind wahr
Das ist sachlich zwar richtig, unterschlägt aber den
Punkt, auf den es mir entscheidend ankam: Für das
BERECHNEN von Wahrheitswerten gelten andere Regeln
als für das AUSWERTEN von Bedingungen durch Steuer-
anweisungen.
Ein boolescher Ausdruck kann nie das Ergebnis "3"
liefern -- aber ein "if" akzeptiert eine "3" problemlos
als Argument.
Egon D. schrieb:> Mir steht nur die (zweite) deutsche Ausgabe des K&R zur> Verfügung; das Buch ist zwar als historisches Dokument> interessant, aber das VERSTEHEN kommt in der Regel erst> bei den Diskussionen hier auf µC.net :)
Früher(tm), als das Usenet noch von Bedeutung war, war ich oft in der
newsgroup comp.lang.c. Da waren dort auch richtige C-Profis wie Dan Pop,
Steve Summit oder Richard Heathfield unterwegs. Dort hab ich wahnsinnig
viel über C gelernt.
Yalu X. schrieb:>> Fazit: Mir will scheinen, dass es bei der Auswertung>> boolescher Ausdrücke überhaupt kein Problem gibt.>> Sagen wir mal so: Die Probleme, die einige hier sehen,> sind rein akademischer Art.
Das sehe ich nicht so.
Ich verstehe den Sinn von vielem, was ich im K&R lese,
tatsächlich erst dadurch, dass es hier diskutiert wird.
> Ich hatte diese Probleme noch nie,
Lass' es mich so ausdrücken: Ich halte Dich, was logisch-
mathematische Fragen angeht, nicht für eine allgemein
anwendbare Referenz :)
> obwohl ich, bevor ich C lernte, hauptsächlich Pascal> gemacht habe, das im Gegensatz zu C klar zwischen> Boolean und Integer unterscheidet.
Schätzungsweise nicht "obwohl", sondern "weil". Wer
weiss, wie es richtig geht, kann in der Praxis auch
schlampen, ohne gleich Fehler zu machen -- wer es
aber von vornherein schlampig gelernt hat, kommt nie
auf einen grünen Zweig.
Egon D. schrieb:> Das ist sachlich zwar richtig, unterschlägt aber den> Punkt, auf den es mir entscheidend ankam: Für das> BERECHNEN von Wahrheitswerten gelten andere Regeln> als für das AUSWERTEN von Bedingungen durch Steuer-> anweisungen.> Ein boolescher Ausdruck kann nie das Ergebnis "3"> liefern -- aber ein "if" akzeptiert eine "3" problemlos> als Argument.
Nein, da wird gar nichts unterschlagen.
Vergleichsoperatoren liefern true(1) oder false(0). Das habe ich nicht
ausdrücklich geschrieben, da es selbstverständlich ist und auch überall
so dokumentiert ist.
Dein zweiter Punkt, dass if eine 3 akzeptiert ergibt sich aus meiner
Aussage, dass alle Werte ungleich 0 wahr sind.
Vermutlich ist das zu simpel, um von einigen hier akzeptiert zu werden.
Wasser ist nass, aber nicht alles nasse ist Wasser. Das kann man auch
einfach mal hinnehmen, oder verrückt zu werden.
Teo D. schrieb im Beitrag #6720075:
> Oder wo in den> Tiefen von C, verbirgt sich da der Pferdefuß?
Seit über(?) 50 Jahren ist klar, das ein if(irgendwas) völlig ausreicht
und ein if(irgendwas == true) ganz schnell ins verderben führt.
Das gilt für altes C, frisches C, und auch für C++.
Dabei ist völlig egal, obs einen Boolean Datentype kennt, oder auch
nicht.
Mehr Problem ist da nicht.
Außer, dass es noch nicht in jedem seine Hirnwindungen angekommen ist.
Egon D. schrieb:> Ich verstehe den Sinn von vielem, was ich im K&R lese,> tatsächlich erst dadurch, dass es hier diskutiert wird.
Vielleicht solltest Du bei allem, was Du da liest, Dich fragen, wie man
es einfacher machen könnte, dass es weniger Seiten im Standard oder
einer Beschreibung braucht. Und nicht immer in UB oder ID ausartet.
Beispiel: Natürlich kann man NIL für einen uninitialisierten Ptr
einführen. Doch dann muss ich zusätzlich dieses NIL erklären UND
beschreiben, wie ich es z.B. von einem gültigen 16-bit-Ptr
unterscheiden kann.
So blöd es klingt, ziel war auch damals schon die minimale Überraschung
gewesen.
Die in C fehlende Trennung von Integers und Boolean wirkt sich dort aus,
wo man Booleans in Vergleichen verwendet, ohne darauf zu achten, ob die
andere Seite auch ein Boolean ist. Sprachen mit Trennung zeigen einem
dann den Vogel, weil die Datentypen nicht zueinander passen. C nicht.
Wer also partout auf solche Vergleiche besteht, sollte "true" nur in
Zuweisungen verwenden, nie in Vergleichen. Wer es nicht lassen kann,
fährt mit if(x != false) besser als mit if(x == true). Ist aber eher was
für Leute, die damit dokumentieren wollen, dass sie C nicht mögen, weil
sich dem kundigen Leser die Zehennägel kräuseln.
A. S. schrieb:> Egon D. schrieb:>> Was also übersehe ich?>> Nichts. Es hat doch auch niemand etwas anderes> behauptet.
Oh doch.
Bereits in der ursprünglichen Fragestellung taucht die
Behauptung auf, man könne ja gar keinen festen Wert
für "true" angeben, weil int schließlich mehr als 0
und 1 darstellen kann.
> Es gab nur ein paar, die zur reinen optischen> Leseerfahrung Ausdrücke z.B. im if in 0/1 wandeln> möchten um dann auch auf == true abfragen zu> dürfen.
Mag wohl sein -- der Knackpunkt ist: WAS FÜR
Ausdrücke?
Einen booleschen Ausdruck erstmal in 0/1 zu wandeln,
um dann auf == true abzufragen, hat m.E. überhaupt
keinen Sinn.
Und wenn es um ganzzahlige Ausdrücke geht -- nun ja,
man könnte sich ja vielleicht so als Zugeständnis
an's dritte Jahrtausend doch mal dazu entschließen,
einen booleschen Ausdruck ins Argument von "if" zu
schreiben, und keinen ganzzahligen.
Was ist an "if (errno>0)" so viel entsetzlicher als
an "if (errno)" -- außer dass es allgemeinverständlich
ist?
> Wer das will, kann das machen, C kam viele Jahre ohne> bool aus und die Regelung mit 0 (nicht erfüllt) und 1> (erfüllt) als Ergebnis boolscher Ausdrücke deckt sich> mit 0 (nicht erfüllt) und !=0 (erfüllt) bei Abfragen.
Ja -- aber das ist nicht der Punkt.
Es wird allerorten -- z.B. im K&R -- so penetrant
betont, dass man ganzzahlige Ausdrücke als Argumente
für Bedingungen verwenden kann , dass völlig
untergeht, dass man das nicht tun muss !
Der (m.E. schlechte und schlampige) Stil wird so
penetrant angepriesen, dass man völlig überliest,
dass man den Käse nicht mitmachen muss!
Egon D. schrieb:> dass völlig untergeht, dass man das nicht tun muss !
Man muss C nicht verwenden...
> Was ist an "if (errno>0)" so viel entsetzlicher als> an "if (errno)" -- außer dass es allgemeinverständlich> ist?
...aber man es dennoch tut, dann sollte man sich dran gewöhnen, dass es
C ist.
Wer if(errno) nicht als allgemeinverständlich betrachtet, der hat m.E.
ein Problem mit dieser Sprache.
Konsequenter wäre es hier, nicht if(errno>0) zu schreiben, sondern
abstrahiert von konkreten Werten sowas wie if(success(errno)), und
success() an zentraler Stelle als Layer zwischen Sprachebenen
definieren.
Egon D. schrieb:> Es wird allerorten -- z.B. im K&R -- so penetrant> betont, dass man ganzzahlige Ausdrücke als Argumente> für Bedingungen verwenden kann , dass völlig> untergeht, dass man das nicht tun muss !> Der (m.E. schlechte und schlampige) Stil wird so> penetrant angepriesen, dass man völlig überliest,> dass man den Käse nicht mitmachen muss!
Nochmal:
In C ist ein logischer Ausdruck ein ganzzahliger Ausdruck, und zwar mit
dem Wert 0 oder 1.
(a<b) ist eine ganze Zahl, (&i==0) ebenso, (3.1415926535>2.718281828)
auch.
Nur daß diese Ausdrücke halt nicht irgendeine Zahl liefern, sondern
entweder 0 oder 1.
Sobald du also if( a>b )... schreibst, verwendest du einen ganzzahligen
Ausdruck als Bedingung.
(prx) A. K. schrieb:> Egon D. schrieb:>> dass völlig untergeht, dass man das nicht tun>> muss !>> Man muss C nicht verwenden...
Warum redest Du hier wider besseren Wissens?
Für Mikrocontroller gibt es keine praktikable
Alternative; das ist hier schon oft genug
durchgekaut worden.
>> Was ist an "if (errno>0)" so viel entsetzlicher>> als an "if (errno)" -- außer dass es>> allgemeinverständlich ist?>> ...aber man es dennoch tut, dann sollte man sich> dran gewöhnen, dass es C ist.
Bei allem Respekt: Was ich sollte , das mache ich
davon abhängig, wie gut die Begründung ist.
Kleiner Tipp: "Das haben wir schon immer so gemacht!
Das haben wir noch nie so gemacht! Da könnte ja jeder
kommen!" sind keine guten Begründungen.
> Wer if(errno) nicht als allgemeinverständlich> betrachtet, der hat m.E. ein Problem mit dieser> Sprache.
Und wer das -- unter der Voraussetzung, dass errno
ein Integer ist -- als vernünftig und sinnvoll
ansieht, hat m.E. ein Problem mit mathematischer
Logik.
Arduino Fanboy D. schrieb:> Teo D. schrieb im Beitrag #6720075:>> Oder wo in den>> Tiefen von C, verbirgt sich da der Pferdefuß?>> Seit über(?) 50 Jahren ist klar, das ein if(irgendwas) völlig ausreicht> und ein if(irgendwas == true) ganz schnell ins verderben führt.> Das gilt für altes C, frisches C, und auch für C++.> Dabei ist völlig egal, obs einen Boolean Datentype kennt, oder auch> nicht.
Das war nicht meine Frage. Die war einfach nur dämlich und wurde deshalb
gelöscht. :D
Egon D. schrieb:> Was ist an "if (errno>0)" so viel entsetzlicher als> an "if (errno)" -- außer dass es allgemeinverständlich> ist?
Der Schrecken kommt mit "errno = -4".
Stefan ⛄ F. schrieb:> Egon D. schrieb:>> hat m.E. ein Problem mit mathematischer Logik.>> C ist nun einmal nicht Mathe, sonder C.
Wer kennt ne Sprache wo das anders is?
Ich mein ja BASIC ZX81, aber das is nu wirklich zu lange her.
Klaus W. schrieb:> Egon D. schrieb:>> Es wird allerorten -- z.B. im K&R -- so penetrant>> betont, dass man ganzzahlige Ausdrücke als Argumente>> für Bedingungen verwenden kann , dass völlig>> untergeht, dass man das nicht tun muss !>> Der (m.E. schlechte und schlampige) Stil wird so>> penetrant angepriesen, dass man völlig überliest,>> dass man den Käse nicht mitmachen muss!>> Nochmal:> In C ist ein logischer Ausdruck ein ganzzahliger> Ausdruck, und zwar mit dem Wert 0 oder 1.
Korrekt. Logische Ausdrücke sind SPEZIELLE ganzzahlige
Ausdrücke (nämlich solche, die nur 0 oder 1 liefern).
Mit "ganzzahliger Ausdruck" war im oben zitierten
Text ein ALLGEMEINER ganzzahliger Ausdruck gemeint,
also einer, der auch Werte größer 1 liefern kann.
Ich dachte, das sei klar.
Egon D. schrieb:> Korrekt. Logische Ausdrücke sind SPEZIELLE ganzzahlige> Ausdrücke (nämlich solche, die nur 0 oder 1 liefern).
Nö, das sind und bleiben Boolsche Ausdrücke und haben mit Zahlen nix am
Hut. Nur Wahr oder Falsch, lässt sich halt nur recht schlecht ins RAM
tackern!
Der Rest ist einfach nur Bequemlichkeit.
Egon D. schrieb:> hat m.E. ein Problem mit mathematischer Logik.
Da ich in APL programmieren lernte, war die Versuchung gering, C als
Verwirklichung mathematischen Denkens zu verstehen. ;-)
Jeder Sprache ihre Sphäre. C ist nicht von Mathematik abgeleitet,
sondern von Praktikabilität zur Entstehungszeit. Nicht Abstraktion,
sondern relativ dicht am Konkreten. Das ist ihr Konzept - bis heute.
Daher auch mein Vorschlag vorhin bei errno: Wenn Abstraktion, dann auch
von konkreten Werten. Das reduziert die Abhängigkeit von "magic numbers"
auf eine zentrale Stelle.
Stefan ⛄ F. schrieb:> Egon D. schrieb:>> hat m.E. ein Problem mit mathematischer Logik.>> C ist nun einmal nicht Mathe, sonder C.
Das Problem ist nicht C -- die Sprache lässt ja eine
andere Ausdrucksweise zu, wie wir jetzt wissen.
Das Problem sind die C-Programmierer, wie diese
Diskussion lehrt.
Wer gegen ihre Initiationsriten aufmuckt, wird
weggebissen.
Teo D. schrieb:> Egon D. schrieb:>> Was ist an "if (errno>0)" so viel entsetzlicher als>> an "if (errno)" -- außer dass es allgemeinverständlich>> ist?>> Der Schrecken kommt mit "errno = -4".
Ja... okay. Stattgegeben. Dann halt "(errno!=0)".
Egon D. schrieb:> as Problem ist nicht C> Das Problem sind die C-Programmierer
Ich würde sagen beides ist das Problem.
Ewiggestrige Programmierer, die Verlustängste haben und an ihrer
ewiggestrigen Sprache krampfhaft festhalten.
Teo D. schrieb:> Egon D. schrieb:>> Korrekt. Logische Ausdrücke sind SPEZIELLE ganzzahlige>> Ausdrücke (nämlich solche, die nur 0 oder 1 liefern).>> Nö, das sind und bleiben Boolsche Ausdrücke
Jein -- unsere (Klaus' und meine) Ausdrucksweise ist
schlampig: Die Ausdrücke sind im Prinzip tatsächlich
boolesche Ausdrücke, denn sie verwenden ja boolesche
Operatoren. Deren Ergebnis ist aber (leider) ganz-
zahlig.
> und haben mit Zahlen nix am Hut.
Das wäre schön und logisch -- ist aber in C nicht so.
Teo D. schrieb:>> C ist nun einmal nicht Mathe, sonder C.> Wer kennt ne Sprache wo das anders is?
Darauf wollte ich hinaus. Programmiersprachen definieren ihr eigenes
Regelwerk. Die Tatsache, dass es da viele Gemeinsamkeiten mit anderen
bekannten Regelwerken gibt, wollte keinen Entwickler dazu verleiten, die
Regeln der Sprache zu missachten.
Die meisten Softwareentwickler benutzen regelmäßig viele
unterschiedliche Programmiersprachen mit unterschiedlichen Regeln. Wer
das nicht auseinander halten kann der ist kein Softwareentwickler.
Sorry, ist so.
Egon D. schrieb:> Was ist an "if (errno>0)" so viel entsetzlicher als> an "if (errno)" -- außer dass es allgemeinverständlich> ist?
Es bietet keinen Mehrwert beim Lesen. Deutlich wird es bei
if(keyPressed) oder if(KeyPressed())
Deutlich wird es auch bei "if(3>4)" da schreibt auch niemand
"if((3>4)!=0)".
Warum sollte keyPressed anders behandelt werden wie 3>4 ?
"Wenn 3 > 4 ist" ist besser als "Wenn (3>4) wahr ist"
Genauso ist "wenn taste gedrückt ist" besser als "wenn Taste gedrückt
wahr ist". Im echten Leben redet doch auch niemand so.
(prx) A. K. schrieb:> Egon D. schrieb:>> hat m.E. ein Problem mit mathematischer Logik.>> Da ich in APL programmieren lernte, war die Versuchung> gering, C als Verwirklichung mathematischen Denkens> zu verstehen. ;-)
Okay... Du erwähntest dies früher schon, glaube ich. :)
> Jeder Sprache ihre Sphäre. C ist nicht von Mathematik> abgeleitet, sondern von Praktikabilität zur> Entstehungszeit. Nicht Abstraktion, sondern relativ> dicht am Konkreten. Das ist ihr Konzept - bis heute.
Damit habe ich auch kein Problem.
> Daher auch mein Vorschlag vorhin bei errno: Wenn> Abstraktion, dann auch von konkreten Werten.
Meinetwegen.
Ändert aber nix daran, dass ich es für schlechten Stil
halte, mit einer binären Fallunterscheidung auf Ausdrücke
loszugehen, die mehr als zwei zulässige Belegungen haben.
> Das reduziert die Abhängigkeit von "magic numbers"> auf eine zentrale Stelle.
Okay, meinetwegen: "if (errno==fehlerfrei) { ..."
mit passender Definition von fehlerfrei.
Klaus W. schrieb:> Logische Ausdrücke liefern (als int betrachtet) immer...
Das war von Anfang an unbestritten, aber schön daß auch du es nochmal
formuliert hast.
Der Knackpunkt in C besteht darin, daß man dort die Freiheit hat,
überhaupt Integerarithmetik damit zu betreiben. Das ist genau so wie die
numerische Benutzung von Textzeichen aka 'char'. Es geht ja, aber es ist
jemandem, der ordentliche logische Verhältnisse gewohnt ist, zu Recht
suspekt.
W.S.
A. S. schrieb:> Egon D. schrieb:>> Was ist an "if (errno>0)" so viel entsetzlicher als>> an "if (errno)" -- außer dass es allgemeinverständlich>> ist?>> Es bietet keinen Mehrwert beim Lesen.
Doch, mir schon.
Ich finde umgekehrt "if (errno)" in sich widersprüchlich.
"if" stellt eine binäre Fallunterscheidung dar; das ist
eine aussagenlogische Geschichte. Entweder die Bedingung
tritt zu oder eben nicht. Da gibt es "wahr" und "falsch",
was -- der Bedeutung nach -- abstrakte Belegungen und
keine Zahlen sind.
Ein aussagenlogischer Ausdruck kann aber nicht sinnvoll
eine beliebige ganze Zahl als Argument haben.
Der Vergleich "(errno!=0)" löst das Problem, denn es
werden zwei Zahlen verglichen, und das Resultat ist ein
binäres Ergebnis; hier ist die Welt wieder in Ordnung.
Ich erwarte von niemandem, dass er meiner Sichtweise
folgt -- es wäre nur recht schön, wenn nicht dauernd
diese ganzen verzichtbaren Schlampigkeiten als DAS
grandiose Alleinstellungsmerkmal von C angepriesen
würden.
> Deutlich wird es auch bei "if(3>4)" da schreibt> auch niemand "if((3>4)!=0)".
???
Muss ja auch nicht: "3" ist eine Zahl, "4" ist eine
Zahl, ">" ist ein Vergleichsoperator, der ein binäres
Ergebnis liefert. Alles paletti.
Egon D. schrieb:> Ich finde umgekehrt "if (errno)" in sich widersprüchlich.
Ich lese das als: "wenn ein Fehlercode geliefert wurde, dann ...".
Deswegen benutzt man auch oft die 0 für den Erfolg.
A. S. schrieb:> Deutlich wird es auch bei "if(3>4)" da schreibt auch niemand> "if((3>4)!=0)".
if((((((((((((((((((((((3>4)!=0)!=0)!=0)!=0)!=0)!=0)!=0)!=0)!=0)!=0)!=0)
!=0)!=0)!=0)!=0)!=0)!=0)!=0)!=0)!=0)!=0))
Egon D. schrieb:> Ein aussagenlogischer Ausdruck kann aber nicht sinnvoll> eine beliebige ganze Zahl als Argument haben.
Wenn du unbedingt Mathematik bemühen willst, dann betrachte es unter dem
Aspekt der Boolschen Algebra mit Bezug auf die Mengenlehre. Dann geht
das. ;-)
Stefan ⛄ F. schrieb:> Ich lese das als: "wenn ein Fehlercode geliefert wurde, dann ...".
Benennung von Variablen ist viel wichtiger, als die Bullenexkremente,
die hier diskutiert werden.
if (error) { handle_error(); }
Stefan ⛄ F. schrieb:> Darauf wollte ich hinaus. Programmiersprachen definieren> ihr eigenes Regelwerk. Die Tatsache, dass es da viele> Gemeinsamkeiten mit anderen bekannten Regelwerken gibt,> wollte keinen Entwickler dazu verleiten, die Regeln der> Sprache zu missachten.
Seit wann ist es ein Missachten von Regeln, wenn ich
eine inhaltlich widersprüchliche Ausdrucksweise wie
"if(ganzzahl)" ablehne und durch eine konsistente
wie "if(ganzzahl==referenz)" ersetze, die genauso
regelgerecht ist?
> Die meisten Softwareentwickler benutzen regelmäßig> viele unterschiedliche Programmiersprachen mit> unterschiedlichen Regeln.
Es geht nicht um unterschiedliche Regeln -- es geht
um in sich widersprüchliche Konstrukte, für die es
widerspruchsfreie Alternativen in der Sprache gibt!
Stefan ⛄ F. schrieb:> Teo D. schrieb:>>> C ist nun einmal nicht Mathe, sonder C.>> Wer kennt ne Sprache wo das anders is?>> Darauf wollte ich hinaus. Programmiersprachen definieren ihr eigenes> Regelwerk.
Aber ich bekomme doch keinen Konten im Hirn, wegen "if(x)".
> Die Tatsache, dass es da viele Gemeinsamkeiten mit anderen> bekannten Regelwerken gibt, wollte keinen Entwickler dazu verleiten, die> Regeln der Sprache zu missachten.
Naja, das "missachten" funktioniert so oder so nich.
Stefan ⛄ F. schrieb:> ist kein Softwareentwickler.
Hab ich auch nie behautet.
Mach ich seit >30J nich mehr und wirkliche Erfahrung hatte ich nur in
einer Sprache, mit einem sehr speziellem Dialekt. :)
Also Asche auf mein Haupt, wegen obiger Frage, wo das anders wäre.
(Interessieren würds mich aber trotzdem)
Egon D. schrieb:>> und haben mit Zahlen nix am Hut.>> Das wäre schön und logisch -- ist aber in C nicht so.
Hab ich doch auch nie behautet.....
Eine Meinung, zwei Stuhle... Lassen wirs lieber!
Ich wollts doch nur einfacher... Das ging dann wohl nach Hinten los. :´D
Egon D. schrieb:> wenn ich> eine inhaltlich widersprüchliche Ausdrucksweise wie> "if(ganzzahl)" ablehne und durch eine konsistente> wie "if(ganzzahl==referenz)" ersetze
Ich werfe if (0 == variable) in den Ring.
Stefan ⛄ F. schrieb:>>> ">" ist ein Vergleichsoperator, der ein binäres>>> Ergebnis liefert.>> MaWin schrieb:>> nein>> Jetzt bin ich aber mal auf die Erklärung gespannt.
Ein Boolsches, dargestellt als 0/1.
Taugt Euch das?
>> ">" ist ein Vergleichsoperator, der ein binäres>> Ergebnis liefert.
MaWin schrieb:
> nein>> Jetzt bin ich aber mal auf die Erklärung gespannt.
MaWin schrieb:
> Lies den Thread. Es liefert ein komplettes int zurück.
"The result of a relational expression is 1 if the tested relationship
is true and 0 if it is false. The type of the result is int."
https://docs.microsoft.com/en-us/cpp/c-language/c-relational-and-equality-operators?view=msvc-160
"Ein Binärcode ist ein Code, in dem Informationen durch Sequenzen von
zwei verschiedenen Symbolen (zum Beispiel 1/0 oder wahr/falsch)
dargestellt werden."
https://de.wikipedia.org/wiki/Bin%C3%A4rcode
Da das Ergebnis nur 0 oder 1 sein kann, also zwei mögliche Werte, ist
es binär.
Stefan ⛄ F. schrieb:> Da das Ergebnis nur 0 oder 1 sein kann, also zwei mögliche Werte, ist> es binär.
Ja gut. Du hast die Sprachdefinition gefunden, die dir recht gibt. Du
hast gewonnen. Bravo.
MaWin schrieb:> Ja gut. Du hast die Sprachdefinition gefunden, die dir recht gibt. Du> hast gewonnen. Bravo.
Es wäre auch binär, wenn das Ergebnis nur die Werte 7 und 8 haben kann.
Oder "HIGH" und "LOW" oder 0V und 5V, um mal bei etwas Bekanntem zu
bleiben.
Ich erinnere mich ganz vage an die Fortran-Grundkurse, wo man einige
Jobs fürs Rechenzentrum "gewann", wenn die Abschlußklausur mindestens 2+
war. Und ich erinnere mich an den "wahnsinnigen Geheimtip", einem
Ausdruck, der einen Wahrheitswert verarbeiten will, ein numerisches
Rechenergebnis "unterzujubeln", weil eben False = 0 und True != False...
Kam mir rein vom Gefühl immer unsauber vor. Aber später, bei den ersten
Controllern war das fast schon üblich und hat auch keinen wirklich
gekratzt, solange es funzte... Trotzdem, für mich "unsauber" (was aber
nicht heißt, dass ich es nicht auch mal mache :-)
Gruß Rainer
Stefan ⛄ F. schrieb:> Es wäre auch binär, wenn das Ergebnis nur die Werte 7 und 8 haben kann.> Oder "HIGH" und "LOW" oder 0V und 5V, um mal bei etwas Bekanntem zu> bleiben.
Also war deine Aussage eine Nullaussage, weil alles auf Computern binär
ist?
Stefan ⛄ F. schrieb:> Egon D. schrieb:>> Ich finde umgekehrt "if (errno)" in sich widersprüchlich.>> Ich lese das als: "wenn ein Fehlercode geliefert wurde, dann ...".> Deswegen benutzt man auch oft die 0 für den Erfolg.
errno ist generell ein schlechtes Beispiel, weil das nicht benutzt
werden kann, um zu erkennen, ob ein Fehler aufgetreten ist. Die
Funktionen geben normalerweise über den Returnwert oder so zu erkennen,
ob ein Fehler aufgetreten ist, und nur wenn es einen gab, dann kann man
per errno abfragen, welcher Fehler das war.
Es ist nicht mal definiert, ob es überhaupt geschrieben wird, wenn kein
Fehler aufgetreten ist. Der Standard sagt sogar ausdrücklich, dass errno
von Standard-Funktionen niemals auf 0 gesetzt wird.
Die Sprache C zwingt niemanden dazu eine Zahl mit true oder false zu
vergleichen, wie
1
interrno=3;
2
if(errno==true)...
Niemand wird gezwungen, nicht boolesche Ausdrücke in if() zu benutzen,
wie in
1
interrno=3;
2
if(errno)...
Manche Programmiersprachen verbieten beides sogar. C erlaubt es halt.
Genieße die Freiheit ohne sie zu missbrauchen.
Wenn man das aber nun trotzdem macht und dabei einen Knoten im Kopf
bekommt, dann hat man sich selbst verascht. Wer dem Design der
Programmiersprache anlastet, soll erstmal selbst eine bessere
Programmiersprache auf den Markt bringen, um wenigstens ungefähr auf
Sichtweite (Augenhöhe verlange ich nicht) zu kommen.
C ist keine Sprache für Leute, die Pampers und Hosenträger brauchen. Für
diese Leute gibt es andere Programmiersprachen und Berufe/Hobbies, wo
man gar nicht programmieren muss.
>> Es wäre auch binär, wenn das Ergebnis nur die Werte 7 und 8 haben kann.>> Oder "HIGH" und "LOW" oder 0V und 5V, um mal bei etwas Bekanntem zu>> bleiben.MaWin schrieb:> Also war deine Aussage eine Nullaussage, weil alles auf Computern binär> ist?
Nein. Eine Funktion, die viele (mehr als 2) unterschiedliche
Status-Codes zurückliefert, liefert kein binäres Ergebnis zurück. Alles
was mehr als zwei Werte haben kann, ist nicht binär. Ein Byte zum
Beispiel.
Aber wenn ich einen int oder String zurückliefere und dessen gültige
Werte auf genau zwei beschränke, dann ist das binär.
Teo D. schrieb:> Nö, das sind und bleiben Boolsche Ausdrücke und haben mit Zahlen nix am> Hut. Nur Wahr oder Falsch, lässt sich halt nur recht schlecht ins RAM> tackern!
Ich wiederhole es gerne noch öfter:
In C liefern logische Ausdrücke eine ganze Zahl, nämlich 0 oder 1.
Da kann man nicht behaupten, daß sie nichts mit Zahlen zu tun hätten.
Steht so im K&R, siehe die Bilder oben.
Klaus W. schrieb:> Da kann man nicht behaupten, daß sie nichts mit Zahlen zu tun hätten.
Hat das wer gesagt? Es wurde nur gesagt, dass diese Integer-zahl binär
sei, weil sie nur zwei Werte haben kann/darf.
Stefan ⛄ F. schrieb:> C ist keine Sprache für Leute, die Pampers und Hosenträger brauchen.
Das "Argument" kommt immer wieder gerne, wenn C kritisiert wird.
Spoiler: Es ist kein Argument.
errno ist eine wohldefinierte und reservierte Variable des
C-Runtime-Systems. Diese selbst zu definieren führt zu Konflikten.
Rolf M. schrieb:> errno ist generell ein schlechtes Beispiel, weil das nicht benutzt> werden kann, um zu erkennen, ob ein Fehler aufgetreten ist.
Korrekt. errno sollte man nur abfragen, wenn man zuvor den Return-Wert
einer libc-Funktion als Fehler detektiert - vorher nicht. Denn errno
wird nie zurückgesetzt, kann also noch einen uralten Fehler beinhalten,
der längst nicht mehr aktuell ist.
Beispiel:
1
#include<errno.h>
2
...
3
FILE*fp=fopen("/tmp/a.txt","r");
4
5
if(!fp)
6
{
7
fprintf(stderr,"cannot open /tmp/a.txt, errno = %d\n",errno);
8
}
Besser:
1
#include<errno.h>
2
...
3
FILE*fp=fopen("/tmp/a.txt","r");
4
5
if(!fp)
6
{
7
perror("/tmp/a.txt");
8
}
perror wertet die Variable errno aus und schreibt dann den Grund des
Fehlers auf stderr, z.B.
MaWin schrieb:>> C ist keine Sprache für Leute, die Pampers und Hosenträger brauchen.> Das "Argument" kommt immer wieder gerne, wenn C kritisiert wird.> Spoiler: Es ist kein Argument.
Was ist es denn, ein Fakt?
Klar darfst du die Sprache ätzend finden, tue ich auch. Dennoch arbeite
ich damit.
Frank M. schrieb:> errno ist eine wohldefinierte und reservierte Variable des> C-Runtime-Systems. Diese selbst zu definieren führt zu Konflikten.
Ich wollte nur unmissverständlich klar stellen, dass es ein Integer ist,
kein boolean.
Stefan ⛄ F. schrieb:> Alles> was mehr als zwei Werte haben kann, ist nicht binär. Ein Byte zum> Beispiel.
Also gibt es gar keine binären Werte auf gängigen CPUs.
Stefan ⛄ F. schrieb:> Klaus W. schrieb:>> Da kann man nicht behaupten, daß sie nichts mit Zahlen zu tun hätten.>> Hat das wer gesagt? Es wurde nur gesagt, dass diese Integer-zahl binär> sei, weil sie nur zwei Werte haben kann/darf.
Er war's (sie war's, sie war's...):
Teo D. schrieb:> Nö, das sind und bleiben Boolsche Ausdrücke und haben mit Zahlen nix am> Hut.
MaWin schrieb:> Also gibt es gar keine binären Werte auf gängigen CPUs.
Statusbits in der CPU.
(Gleich kommt c-hater unter dne Steinen vor: ich hab's schon immer
gewusst...)
Stefan ⛄ F. schrieb:> Was ist es denn, ein Fakt?
Um das zu verstehen, muss man verstehen, dass es gar keine guten
C-Programmierer gibt.
Oder woher kommen ständig diese Sicherheitslücken, die auf trivialen
C-Eigenschaften beruhen? Alles Trottel? Außer ich? Ich bin der
Super-C-Programmierer, und alle anderen sind dumm? Wohl kaum.
MaWin schrieb:> Oder woher kommen ständig diese Sicherheitslücken, die auf trivialen> C-Eigenschaften beruhen?
Ja, vor 20 Jahren las man desöfteren davon. Buffer-Overflows waren die
bekanntesten.
Aber:
So wie ich die Meldungen von Sicherheitslücken der letzten 10 Jahre
wahrgenommen habe, beruhen mittlerweile die wenigsten Sicherheitslücken
"auf trivialen C-Eigenschaften". Da hat sich die "Qualität" mittlerweile
verschoben.
Frank M. schrieb:> von Sicherheitslücken der letzten 10 Jahre> wahrgenommen habe, beruhen mittlerweile die wenigsten Sicherheitslücken> "auf trivialen C-Eigenschaften"
Da gibt natürlich jetzt mehrere Antworten drauf:
- Ist das denn so, oder ist es nur eine falsche Wahrnehmung?
- Wenn es so ist, ist es, weil C-Programme endlich gut sind, oder weil
niemand mehr neue securitykritische SW in C schreibt (lies: Weniger
securitykritische SW in C geschrieben wird).
Ich tippe auf: beides.
MaWin schrieb:> Also gibt es gar keine binären Werte auf gängigen CPUs.
Doch, zum Beispiel die Status Flags (Zero Flag).
Und außerdem alle Bit-Kombinationen, die per Definition nur zwei gültige
Zustände haben, wie eben das besagte 0/1 Pärchen.
MaWin schrieb:>> Doch, zum Beispiel die Status Flags (Zero Flag).> Die von C aus nicht verwendbar sind.
Gut, ich gebe dir noch ein Beispiel. Letzendlich eine Wiederholng der
vorherigen nur in anderer Version.
Sagen wir mal, die Funktion tuWas() liefert 9 im Erfolgsfall und 22 im
Fehlerfall zurück. Andere Rückgabewerte sind per Spezifikation
unzulässig. Dan liefert die Funktion ein binäres Ergebnis.
Binär heißt: Es gibt nur zwei erlaubte Zustände. Ganz egal, wie viele
Zustände tatsächlich physikalisch möglich sind.
Ein digitaler Arduino Eingang ist binär, denn er kennt nur HIGH und LOW.
Du kannst reich technisch unendlich viele unterschiedliche Spannungen
anlegen. Aber es gibt nur zwei gültige Bereiche, deswegen ist das binär.
"tot" oder "lebendig" ist auch binär. Es gibt keine weiteren Werte
("untot", "bewusstlos" und "scheintot" gilt hier nicht).
Stefan ⛄ F. schrieb:> Gut, ich gebe dir noch ein Beispiel.
Was genau willst du mir eigentlich erklären?
Es gibt in C ein int. Alles wird darauf promoviert, es sei den es ist
bereits größer.
Warum spielt dein theoretisches Gedankenspiel mit 9 und 22 als binäre
Werte irgendeine Rolle in diesem Thread?
MaWin schrieb:> Was genau willst du mir eigentlich erklären?
Das es binäre (Rückgabe-)werte vom Typ int gibt, so wie es die Doku von
Microsoft auch klar aussagt.
Stefan ⛄ F. schrieb:> Das es binäre (Rückgabe-)werte vom Typ int gibt, so wie es die Doku von> Microsoft auch klar aussagt.
Ah ja. Und das hat jetzt welche Relevant genau?
Was ändert das an
"frage zu defines TRUE/FALSE"
?
MaWin schrieb:> Ah ja. Und das hat jetzt welche Relevant genau?
Die Diskussion hat dazu geführt, das ist die Relevanz. Du kannst ja
nochmal den ganzen Thread von Anfang an durchlesen um nachzuvollziehen,
wie deine eigenen Beiträge zu diesem Punkt hier geführt haben.
Stefan ⛄ F. schrieb:> Ich gebe auf.
Ich verstehe durchaus, was du meinst.
Aber es ist trotzdem Unsinn im C-Kontext.
Ein int ist ein int ist ein int.
Die Interpretation eines int interessiert es grundsätzlich nicht, ob der
Wert ursprünglich aus einem Vergleich stammt.
Das kommt höchstens bei der Optimierung und der as-if-Regel zum Tragen.
Aber im grundsätzlichen Sprachumfang kommt das nicht vor.
Egon D. schrieb:> Was ist an "if (errno>0)" so viel entsetzlicher als> an "if (errno)" -- außer dass es allgemeinverständlich> ist?
Für mich ist "if (errno>0)" nicht verständlicher. Für mich sind da zwei
zusätzliche Zeichen Quellcode ohne Nutzen, und jedes unnütze Zeichen
Quellcode ist für mich eines zu viel. Source is evil.
Aber ich habe schon viele Programmierer erlebt die da anderer Meinung
sind und für die, wie für Egon und Schlaumaier, "if (errno)" kryptisch
ist.
LG, Sebastian
Sebastian W. schrieb:> Für mich ist "if (errno>0)" nicht verständlicher. Für mich sind da zwei> zusätzliche Zeichen Quellcode ohne Nutzen, und jedes unnütze Zeichen> Quellcode ist für mich eines zu viel.
Mir kommt da spontan die Frage ind en Sinn, ob negative Fehlercode
absichtlich ignoriert werden und ob negative Werte überhaupt vorkommen.
Stefan ⛄ F. schrieb:> Mir kommt da spontan die Frage ind en Sinn, ob negative Fehlercode> absichtlich ignoriert werden und ob negative Werte überhaupt vorkommen.
Nicht fragen, sondern einfach errno.h bzw. dessen Sub-Includes
anschauen, unter Linux meist /usr/include/newlib/sys/errno.h
Ergebnis: errno ist 0 oder positiv.
Wie aber einige oben schon mehrfach(!) geschrieben haben, ist die
Prüfung mittels if(errno) Unsinn. Von daher ist es als Anwender von
errno.h auch völlig irrelevant, welche konkreten numerischen Werte errno
ungleich 0 annehmen kann. Du kannst natürlich errno auf konkrete Werte
wie ENOENT abchecken - oder aber einfach perror() aufrufen, um Dir die
konkretete Fehlermeldung ausgeben zu lassen.
errno ungleich 0 ist kein Kriterium, dass der letzte
libc-Funktionsaufruf in die Binsen ging!
Siehe auch: https://man7.org/linux/man-pages/man3/errno.3.html
Titel: errno - number of last error
Betonung liegt hier auf "last".
Auszug:
"The value of errno is never set to zero by any system call or library
function."
Frank M. schrieb:> Stefan ⛄ F. schrieb:>> Mir kommt da spontan die Frage ind en Sinn, ob negative Fehlercode>> absichtlich ignoriert werden und ob negative Werte überhaupt vorkommen.>> Nicht fragen, sondern einfach errno.h bzw. dessen Sub-Includes> anschauen, unter Linux meist /usr/include/newlib/sys/errno.h>> Ergebnis: errno ist 0 oder positiv.
Außer innen im Linux Kernel, da gibt eine Funktion ggf. -ENOENT zurück.
> errno ungleich 0 ist kein Kriterium, dass der letzte> libc-Funktionsaufruf in die Binsen ging!
Wenn man errno nicht selber auf 0 setzt, ist es meistens != 0. Zum
Beispiel sucht eine Funktion nach einer config-Datei und findet sie
nicht gleich im ersten Verzeichnis. Am Ende war alles erfolgreich, aber
errno == ENOENT.
Stefan ⛄ F. schrieb:> Vermutlich ist das zu simpel, um von einigen hier akzeptiert zu werden.
Du vergißt immer wieder das Eine: Daß es in C keinen Datentyp "boolean"
gibt und daß daraus folgt, daß es dafür einen Ersatz geben muß, denn
ohne Ergebnisse wie true oder false kommt keine Programmiersprache aus -
auch wenn sich das 'nur' in den Ergebnissen von Vergleichsoperationen
widerspiegelt.
W.S.
He Leute, mal ehrlich, wie lange wollen wir hier noch weitermachen?? Ich
bin mir sicher, dass das hier Geschriebene und Gelesene bei "0 Null Nill
Nada ect." irgend etwas an seinen Programmiergewohnheiten ändern wird!
Was zählt ist doch letztlich nur das (positive) Ergebnis. Oder hat sich
einer schon mal die fiktive Situation vorgestellt, wo "Ardunio-Fanboy"
und "C-hater" beim Chef sitzen und dem erzählen, dass,
wenn,"Ardunio-Fanboy" nicht sofort aufhört, die Integerzahl 42 als
boolsche Variable "True" zu benutzen, er, C-hater, für das Gelingen, vor
allem für das rechtzeitige Gelingen der Projektentwicklung nicht
garantieren könne. Nun kennt jeder doch diese Cartoons, wo irgendwer in
die Luft springt, explodiert...was auch immer.... Genau das wird auch im
fiktiven Chefzimmer passieren. Ein atomexplosionsähnliches Raus! ist das
Resultat. Und zu Recht!
Am Rande, und nur für mich... habe wenige Male an einer Software
"rummachen" müssen/sollen, die ich nicht selbst verbrochen hatte und ich
habe ausnahmslos die verlangte Funktionalität studiert und dann das
Kunstwerk neu geschrieben. Kann man eigentlich fast immer
durchsetzen...es sei denn "hardcoregeschütze" wie Kündigung nehmen Raum
:-)
Gruß Rainer
Stefan ⛄ F. schrieb:> Darauf wollte ich hinaus. Programmiersprachen definieren ihr eigenes> Regelwerk. Die Tatsache, dass es da viele Gemeinsamkeiten mit anderen> bekannten Regelwerken gibt, wollte keinen Entwickler dazu verleiten, die> Regeln der Sprache zu missachten.
So herum will das aber kein Mensch mit wenigstens einem Rest an
Selbstgefühl akzeptieren.
Sieh das mal anders herum:
Der Daseinszweck von Programmiersprachen besteht darin, den Willen des
Menschen in so einer Form darzustellen, daß daraus eine
Maschinenbefehlsfolge für ein entsprechendes elektronisches Ding
entstehen kann, so daß dieses Ding so funktioniert, wie es sich der
Mensch gedacht hat.
Also die Maschine soll dem Menschen dienen und nicht umgekehrt.
Die Programiersprache soll dabei nicht 'ihre' Regeln aufstellen, sondern
so gut es geht, den Regeln des Menschen entsprechen, was je nach
Programmiersparte unterschiedlich eng aufgefaßt wird. Für Leute ohne
naturwissnschaftlichen Hintergrund (wie z.B. BWLler) hat das
erwiesenermaßen in so etwas wie COBOL gemündet, alle anderen haben dafür
zu viel mathematischen Hintergrund, weswegen denen so etwas wie if(A==B)
unsinnig ist, genau so, als wenn eine Programmiersprache als 'ihre'
Regel definieren würde, daß bei ihr 1+1 = 3 und 1+1+1 = 7 wäre. Man kann
selbsternannte Regeln zwar formulieren, aber je weiter man sich damit
von der Mathematik entfernt, desto problematischer wird das.
Nochwas:
MaWin polterte ein wenig über die alten Säcke in
C-Programmierer-Kreisen. Nun, wenn gerade für Mikrocontroller
ausreichend an Alternativen zur Verfügung ständen, dann wäre dies nebst
der hier geführten Diskussion gegenstandslos.
Ja, C ist schludrig konzipiert, C ist recht alt und Programmierer ohne
Bodenkontakt zur Elektronik neigen dazu, sich in immer abenteuerlichere
Konstrukte auch beim Erfinden neuer Programmiersprachen zu versteigen.
Schließlich ist es denen gar zu oft ein inneres Bedürfnis, in 'ihrer'
Programmiersprache eine Art eigenes Reich zu haben, zu dem Außenstehende
möglichst keinen Zugang haben sollen.
Man kann in C auch lesbar und ohne Quellcode-Akrobatik, also quasi
'bieder' schreiben und das Ergebnis wird den C-Akrobaten nicht
nachstehen.
Soviel zu der Ansicht, daß sich der Verstand des Menschen (ungeprüft) an
die Regeln einer Programmiersprache zu halten habe.
W.S.
Rainer V. schrieb:> Oder hat sich> einer schon mal die fiktive Situation vorgestellt, wo "Ardunio-Fanboy"> und "C-hater" beim Chef sitzen und dem erzählen, dass,> wenn,"Ardunio-Fanboy" nicht sofort aufhört, die Integerzahl 42 als> boolsche Variable "True" zu benutzen, er, C-hater, für das Gelingen, vor> allem für das rechtzeitige Gelingen der Projektentwicklung nicht> garantieren könne.
Die Situation wird nie so geschehen!
Gar nicht so sehr, weil ich und C-hater niemals vor einem gemeinsamen
Chef auftauchen könnten.
Sondern:
Das einhalten einer Firmenphilosophie, ist mehr oder weniger einer der
Bedingungen, zugehörig zum Arbeitsvertrag. Wenn ich damit nicht
einverstanden bin, mich nicht anpassen kann, dann darf ich da nicht
arbeiten.
Was der C-hater dann tut, ist sein Problem.
Es wird also keine Welle geben.
Hallo,
W.S. schrieb:> Ja, C ist schludrig konzipiert...
Kann man so sehen.
Ich würde eher sagen das C pragmatisch konzipiert wurde, nämlich in
Hinblick auf das Programmieren von Hardware-Systemen, für die es zur
dieser Zeit scheinbar keine andere geeignete Programmiersprache gab.
Interessanterweise scheinen die nicht schludrig konzipierten Sprachen
keine Alternative gewesen zu sein.
Übrigens: gibt es überhaupt nicht schludrig konzipierte Sprachen, die
eine nennenswerte Verbreitung erlangt haben?
> Nun, wenn gerade für Mikrocontroller ausreichend an Alternativen zur> Verfügung ständen...
Da stellt sich doch direkt die Frage, warum nicht ausreichend
Alternativen
zur Verfügung stehen.
Offensichtlich muss C doch über Eigenschaften verfügen, die es trotz
aller Unzulänglichkeiten so attraktiv macht, das die Sprache auch nach
50 Jahren immer noch so weit verbreitet ist.
rhf
Roland F. schrieb:> Interessanterweise scheinen die nicht schludrig konzipierten Sprachen> keine Alternative gewesen zu sein.
Unix war für kleinere Rechner konzipiert als Multics. Nicht nur das
Betriebssystem musste dementsprechend kleiner sein, sondern auch der
genutzte Compiler.
Roland F. schrieb:> Übrigens: gibt es überhaupt nicht schludrig konzipierte> Sprachen, die eine nennenswerte Verbreitung erlangt> haben?
"Hatten": Algol? Pascal?
"Haben": C++?
> Da stellt sich doch direkt die Frage, warum nicht> ausreichend Alternativen zur Verfügung stehen.
Pfadabhängigkeit.
Eine bessere Lösung muss nicht nur in der Zukunft einen
Gewinn gegenüber der bisherigen versprechen -- sie muss
auch den Umstellungsaufwand wieder wettmachen, und der
wächst, je länger man wartet.
> Offensichtlich muss C doch über Eigenschaften verfügen,> die es trotz aller Unzulänglichkeiten so attraktiv> macht, das die Sprache auch nach 50 Jahren immer noch> so weit verbreitet ist.
Deine Lieblingsthese.
Ich halte sie für falsch.
Es ist mittlerweile sogar in der Wirtschaftswissenschaft
angekommen, dass das gebetsmühlenartig wiederholte Mantra
"Das Bessere setzt sich durch" falsch ist.
Wenn das "gerade ausreichend Gute" früh genug eine
hinreichende Verbreitung hat, setzen Mitkopplungseffekte
ein, die die Lage stabilisieren. Alternativen -- selbst
wenn sie tatsächlich besser sind -- haben es im Laufe der
Zeit schwerer und schwerer.
Arduino Fanboy D. schrieb:> Die Situation wird nie so geschehen!
Ja ja, du hast die fiktive Situation aber nicht verstanden. Jetzt bin
ich mal Chef (Werner is König und auf nach Flachköpper) und sage
schlicht: Ihr Vögel könnt von mir aus machen was ihr wollt, aber macht
es!!!
Capito?!
Gruß Rainer
Roland F. schrieb:> Übrigens: gibt es überhaupt nicht schludrig konzipierte Sprachen, die> eine nennenswerte Verbreitung erlangt haben?
Anders herum: PHP ist extrem schluderig gestaltet und dennoch eine der
erfolgreichsten Programmiersprachen geworden.
Egon D. schrieb:> "Haben": C++?
Ich mag C++, aber sauber gestaltet ist anders. Die Mehrdeutigkeit von
"static" und dass man den Shift-Operator "<<" zur Textausgabe und sogar
zu dessen Formatierung missbraucht hat ist schon sehr schluderig.
Stefan ⛄ F. schrieb:> Anders herum: PHP ist extrem schluderig gestaltet und dennoch eine der> erfolgreichsten Programmiersprachen geworden.
Wobei die Tage von PHP eindeutig gezählt sind.
Niemand setzt mehr neue Projekte mit PHP auf. Das sind alles Altlasten,
die es zu beseitigen gilt.
>> gibt es überhaupt nicht schludrig konzipierte Sprachen, die>> eine nennenswerte Verbreitung erlangt haben?Egon D. schrieb:> "Haben": C++?
Ich mag C++. Aber wenn ich an die Mehrdeutigkeit von "static" denke und
an den Missbrauch des Shift Operators nicht nur zur Textausgabe sondern
auch zu dessen Formatierung, fällt mir alles andere ein, als Lobeshymnen
auf die Klarheit/Sauberkeit der Sprache. Auch die Unterstützung von
Unicode wirkt eher wie ein nachträglich angeklebter Pickel.
Roland F. schrieb:> Übrigens: gibt es überhaupt nicht schludrig konzipierte Sprachen, die> eine nennenswerte Verbreitung erlangt haben?
Python, Rust, Go, Lua.
Ja, jede Sprache hat Ecken und Kanten.
Aber C besteht aus Ecken und Kanten, die mit Duct-Tape zusammengeklebt
wurden.
MaWin schrieb:> Roland F. schrieb:>> Übrigens: gibt es überhaupt nicht schludrig konzipierte Sprachen, die>> eine nennenswerte Verbreitung erlangt haben?>> Python, Rust, Go, Lua.
Python? Ernsthaft? Die Sprache hat allerhand halbgaren BS, auch
abgesehen von der Abstandssache. Dinge, worüber ich immer mal wieder
stolpere:
Kein block scope, keine expliziten Variablendeklarationen:
1
#!python3
2
defsomething_list_pets(self,name):
3
pets=user_pet_list[name]
4
print("You have the following pets: ")
5
forname,speciesinpets:
6
print(f" - Your beloved {species}{name}")
7
print(f"Have a nice day, {name}")
Das Letzte print gibt nicht etwa den Benutzernamen aus, sondern wurde in
der Schleife überschrieben...
Und dann gibt es dinge wie z.B. die set syntax, die sich mit der dict
syntax überschneidet: {1,2,3} ist ein set. {1} auch. {} ist aber ein
dict...
Bei async generators gibt es auch gewisse quirks. Ich sag nur aclose. Um
den quark muss man sich bei JS nicht kümmern.
Dann die Sache mit den tuple, wo man keine klammern braucht. "x=y"
"x=y," und "x,=y" sind gültig, aber anders als ersteres erstellen /
entpacken die Dinger tuple. Geht auch innerhalb von for in schleifen und
anderem zeug. Klar, bei mehreren Werten oft schön anzusehen, aber
trotzdem irgendwie Murks. Viel zu einfach, mal ein Komma zu vergessen,
oder zu übersehen.
Und das ist nur die Spitze des Eisbergs. Da gibt es noch einiges mehr an
Fallstricken.
PS: Gibt es hier im Forum eigentlich eine Möglichkeit im code tag direkt
anzugeben, das etwas z.B. python code ist? Also etwas, was nicht wie #!
mit dem code mit angezeigt wird?
Daniel A. schrieb:> Python? Ernsthaft?
Ja. Ernsthaft.
Die von dir geschilderten "Probleme" sind alle in der Praxis nicht
besonders relevant.
Bei C ist das anders. Mit UB kämpft man ständig, um mal nur ein Beispiel
zu nennen.
MaWin schrieb:> Die von dir geschilderten "Probleme"
Um das nochmal deutlicher zu sagen: Ich bin der Meinung, dass die
meisten deiner Beispiele gar keine Probleme sind.
Nicht alles, was von deiner C-Gewohnheit abweicht, ist ein Problem.
MaWin schrieb:> Daniel A. schrieb:>> Python? Ernsthaft?>> Ja. Ernsthaft.> Die von dir geschilderten "Probleme" sind alle in der Praxis nicht> besonders relevant.
Doch, die haben mir, ganz in der Praxis, schon ein paar mal den Tag
versaut. Da vergisst man dann mal ein Komma, und schon hat man den
Datensalat...
> Bei C ist das anders. Mit UB kämpft man ständig, um mal nur ein Beispiel> zu nennen.
Na du vielleicht. Passiert mir mittlerweile eigentlich nicht mehr, das
ich da rein laufen würde.
Hallo,
Egon D. schrieb:> "Hatten": Algol? Pascal?> "Haben": C++?
Algol:
Hauptverbreitungszeit zwischen (grob) 1960-1970, danach ausgestorben.
Gab es überhaupt Softwareprojekte außerhalb der universitären Blase, die
damit entwickelt wurden?
Pascal:
Wurde zeitgleich zeitgleich mit C entwickelt und hat sich trotz
ähnlicher Kompaktheit, ähnlich geringer Komplexität und deutlich
besserer theroretischer Basis nicht behaupten können. Erst als mit Turbo
Pascal eine pragmatische Version zur Verfügung stand, erweiterte sich
das Verbreitungsgebiet für circa 20. Heute gehört Pascal zu den
bedrohten Arten.
C++:
Mag sein, aber dem steht eine überbordende Vielfalt an sprachlichen
Ausdrucksmitteln gegenüber. Ob die dann (und in ihrem Zusammenwirken
untereinander) wirklich alle "nicht schludrig" entworfen wurden kann ich
zwar nicht beurteilen, habe aber bei der Komplexität von C++ gewisse
Zweifel.
> Eine bessere Lösung muss nicht nur in der Zukunft einen> Gewinn gegenüber der bisherigen versprechen -- sie muss> auch den Umstellungsaufwand wieder wettmachen, und der> wächst, je länger man wartet.
Ich wiederhole mich: C und Pascal wurden zur gleichen Zeit entwickelt,
da gab es noch keinen Umstellungsaufwand. Beide Sprachen verursachten in
etwa die gleichen "Hardwarekosten".
Warum hat sich C gegenüber Pascal durch gesetzt, obwohl doch Pascal die
bessere Basis darstellte?
> Wenn das "gerade ausreichend Gute" früh genug eine> hinreichende Verbreitung hat,...
Trifft aber bei C und Pascal, wie oben beschrieben, nicht zu.
rhf
Daniel A. schrieb:> Da vergisst man dann mal ein Komma, und schon hat man den> Datensalat
In welcher Sprache bekommt man keinen Datensalat, wenn man irgendwelche
Zeichen "vergisst"?
10, 100, 1000 alles gleich. Die Sprache muss raten, was ich will. Sind
ja nur Nullen!
Roland F. schrieb:> Warum hat sich C gegenüber Pascal durch gesetzt, obwohl doch Pascal die> bessere Basis darstellte?
Unix.
Die Qualität der Sprache war es nicht so sehr. Sondern die
Verfügbarkeit.
Ungefähr dem Zeitpunkt, als zunehmend Maschinen für selbstgehostete
Compiler wirklich geeignet und erforderlich waren, gab es auch bald C
Compiler dafür. Dafür war nicht zuletzt Johnsons Portable C Compiler
verantwortlich, ein konzeptioneller Vorläufer des GCC, der mit
überschaubarem Aufwand auf viele Zielarchitekturen umgestellt werden
konnte.
Egon D. schrieb:>> Offensichtlich muss C doch über Eigenschaften verfügen,>> die es trotz aller Unzulänglichkeiten so attraktiv>> macht, das die Sprache auch nach 50 Jahren immer noch>> so weit verbreitet ist.>> Deine Lieblingsthese.> Ich halte sie für falsch.>> Es ist mittlerweile sogar in der Wirtschaftswissenschaft> angekommen, dass das gebetsmühlenartig wiederholte Mantra> "Das Bessere setzt sich durch" falsch ist.
Die These "Das Bessere setzt sich durch" ist IMHO schon richtig, aber
mit einigen Einschränkungen:
- Die Verbesserung muss von der Mehrheit als solche wahrgenommen werden,
da spielen aber oft subjektive Aspekte eine Rolle.
- Die Verbesserung darf nicht mit deutlicher wahrgenommenen
Verschlechterungen an anderer Stelle einhergehen.
- Das Delta der wahrgenommenen Verbesserung muss einen gewissen
Schwellwert überschreiten, sonst siegt die Gewohnheit.
Des Weiteren muss berücksichtigt werden, dass je nach Produkttyp
verschiedene Formen der Verbesserung unterschiedlich bewertet werden. So
spielen bspw. bei Klamotten und teilweise auch bei Autos Verbesserungen
im Aussehen eine große Rolle, während bei Werkzeugen (zu denen auch
Programmiersprachen gehören) der praktische Nutzen höher bewertet wird.
Konkret auf Programmiersprachen bezogen bedeutet das: Der Programmierer
muss das Gefühl haben, dass er
- mit der neuen Sprache Zeit einspart (auch unter Berücksichtigung des
durch die Umstellung entstehenden Overheads) oder
- damit Dinge realisieren kann, die mit der bisherigen Sprache nicht
(oder nur mit ganz krummen Tricks) möglich sind.
Ob die Sprache schludrig konzipiert ist oder nicht, spielt dabei eine
untergeordnete Rolle, zumal dies ohnehin z.T. im Auge des Betrachters
liegt.
Es gibt ja durchaus Fälle, wo etablierte Programmiersprachen durch
neuere weitgehend verdrängt wurden. Typische Fortran-Anwendungen
(lineare Algebra, Numerik u.ä.) werden heute vermehrt in C oder C++
realisiert. Im Finanzwesen, wo früher Cobol vorherrschte, sind heute
m.W. Python und Java angesagt. Wobei man sich jetzt natürlich darüber
streiten kann, ob C++ wirklich besser als Fortran und Python wirklich
besser als Cobol ist.
Yalu X. schrieb:> Die These "Das Bessere setzt sich durch" ist IMHO schon richtig, aber> mit einigen Einschränkungen:
Es gibt eine Zeit, in der Varianten angenommen werden. Hat sich etwas
auf breiter Front durchgesetzt, gewinnt die Masse. Wirklich Neues hat es
danach schwer, auch wenn eindeutig besser - unmöglich ist es aber nicht.
Es ist aber kein Zufall, dass mit der Zeit recht viele Sprachen
entstanden sind, die mindestens einen Teil des C Sektors übernehmen
wollen oder es bereits teilweise haben. Nur hat das den
Mikrocontroller-Sektor nicht erreicht.
(prx) A. K. schrieb:> Roland F. schrieb:>> Warum hat sich C gegenüber Pascal durch gesetzt, obwohl doch Pascal die>> bessere Basis darstellte?>> Unix.>> Die Qualität der Sprache war es nicht so sehr. Sondern die> Verfügbarkeit.
Ein anderer wesentlicher Grund war, dass Pascal von einem Lehrer als
reine Lehrsprache, C aber von Praktikern für die Praxis entwickelt
wurde. Pascal war einzig und allein dafür gemacht, den Studenten
Algorithmen zu lehren, und darin (und nur darin) war es sehr gut.
So kennt Ur-Pascal bspw. nicht einmal so etwas wie Dateinamen, was dazu
führte, dass ein Programm, das einfach nur den Inhalt einer vom Benutzer
vorgegebenen Datei auflistet, in Pascal schlicht unmöglich war.
Des Weiteren konnte man in Ur-Pascal ein Programm nicht in einzelne
Übersetzungseinheiten zerlegen, was bei größeren Softwareprojekten ein
Hindernis war.
Beide (und noch weitere) Mankos wurden bald von den Compilerherstellern
durch entsprechende Spracherweiterungen beseitigt. Allerdings kochte
dabei jeder sein eigenes Süppchen, und es entstand eine Vielzahl von
Pascal-Dialekten, ähnlich wie es auch bei Basic der Fall war. Portable
Programmierung war damit erst einmal gestorben.
Weshalb Wirth bald Modula-2 nachlegte, später Oberon. Wirths erklärtes
Prinzip, Programmiersprachen genau auf ein Anwendungsszenario
zuzuschneidern und deshalb beliebig nach Bedarf zu neu definieren, half
bei der Verbreitung nicht wirklich.
Roland F. schrieb:> Pascal:> Wurde zeitgleich zeitgleich mit C entwickelt und hat> sich trotz ähnlicher Kompaktheit, ähnlich geringer> Komplexität und deutlich besserer theroretischer> Basis nicht behaupten können.
Moment -- Du hattest von "nennenswerter Verbreitung"
gesprochen, und die war m.E. durchaus gegeben. Wer war
das -- Apple? -- die irgendwelche Systemkomponenten
in Pascal programmiert haben? Auf HP-Kisten gab es --
zu meiner Überraschung -- wohl angeblich auch einen
Pascal-Compiler.
> Erst als mit Turbo Pascal eine _pragmatische_> Version zur Verfügung stand, erweiterte sich das> Verbreitungsgebiet für circa 20 [Jahre].
Naja, zu den Hochzeiten von DOS würde ich schon von
einem erdrutschartigen Sieg sprechen...
Mit dem Niedergang von Borland-Pascal und Delphi
war dann aber auch damit Schluss...
> C++:> Mag sein, aber dem steht eine überbordende Vielfalt> an sprachlichen Ausdrucksmitteln gegenüber.
Danach war ja nicht gefragt... :)
>> Eine bessere Lösung muss nicht nur in der Zukunft>> einen Gewinn gegenüber der bisherigen versprechen>> -- sie muss auch den Umstellungsaufwand wieder>> wettmachen, und der wächst, je länger man wartet.>> Ich wiederhole mich: C und Pascal wurden zur> gleichen Zeit entwickelt, da gab es noch keinen> Umstellungsaufwand.
Stop. Pascal bringst Du jetzt ins Spiel. Ich war von
der Vorstellung ausgegangen, dass jetzt jemand die
neue Wundersprache entwickelt, die C ablösen kann und
soll.
> Beide Sprachen verursachten in etwa die gleichen> "Hardwarekosten". Warum hat sich C gegenüber Pascal> durch gesetzt, obwohl doch Pascal die bessere Basis> darstellte?
Das ist m.E. einfach:
1. Wirth hatte ganz offensichtlich kein Interesse daran,
die Standardisierung von Pascal voranzutreiben und
den Standard weiterzuentwickeln. Statt dessen hat er
sich neuen Sprachen zugewandt (Modula-2, Oberon).
Das hat zu dem bekannten Pascal-Wildwuchs geführt,
aber anders als bei C fehlte der ANSI-Gärtner, der
da mal mit der Heckenschere durchgegangen wäre.
2. Pascal ist m.E. keine wirklich bessere Sprache als C,
denn das, was Pascal (ich meine das Wirthsche Standard-
pascal) bietet, ist brauchbar -- aber es bietet,
verglichen mit C, einfach zu wenig: Zeiger existieren
nur rudimentär, Zeigerarithmetik gar nicht -- das ist
besonders fatal, weil bei Arrays auch zahlreiche
Einschränkungen existieren: Die Länge des Arrays ist
fester Bestandteil des Typs, daher gibt es keine zur
Laufzeit längenvariablen Felder, und man kann ohne
Trickserei keine Unterprogramme schreiben, die Felder
beliebiger Länge als Argument akzeptieren.
Darüberhinaus sind die I/O-Funktionen fester Bestandteil
der Sprache -- man kann Pascal also nicht "freestanding"
verwenden, wie das bei C geht. Hinderlich bei System-
programmierung.
Inwieweit es möglich ist, Pascal-Module irgenwo anders
hinzuzulinken, weiss ich nicht.
Dass es trotz starker Typisierung besser geht, zeigt
FreePascal. Da gibt es nicht nur Zeigerarithmetik wie
in C -- man darf Dank der starken Typisierung auch
Prozeduren überladen. Sehr nett.
>> Wenn das "gerade ausreichend Gute" früh genug eine>> hinreichende Verbreitung hat,...>> Trifft aber bei C und Pascal, wie oben beschrieben,> nicht zu.
Ich hatte, wie schon geschrieben, auch nicht an Pascal
gedacht.
Im übrigen teile ich die These, C sei schlampig
entworfen, gar nicht. C ist im Gegenteil ein kleines
Wunder -- auch Dank der Nachbesserungen durch die
verschiedenen Standards.
Man muss m.E. nur verstehen, dass der Fokus zur Zeit
seiner Entstehung auf komplett anderen Eigenschaften
lag, als das heute der Fall ist.
Die Sprache ist weniger das Problem -- eher die Lehr-
tradition. Es heißt ja auch nicht "Stop using C",
es heißt "Stop teaching C" :)
Roland F. schrieb:> Warum hat sich C gegenüber Pascal durch gesetzt, obwohl doch Pascal die> bessere Basis darstellte?>
Ich kann dir einen sehr handfesten Grund sagen: Pascal konnte auch ein
Cheffe lesen und so lala verstehen - C hingegen nicht, das war für ihn
wie Hieroglyphen. Sowas ändert die Ansichten im Falle einer anstehenden
Personal-Reduktion beim Cheffe. Das ist kein Argument technischer Natur,
sondern kommt aus der Personal-Politik, wiegt aber deutlich schwerer als
programmtechnische Belange.
Yalu X. schrieb:> Konkret auf Programmiersprachen bezogen bedeutet das: Der Programmierer> muss das Gefühl haben, dass er>> - mit der neuen Sprache Zeit einspart (auch unter Berücksichtigung des> durch die Umstellung entstehenden Overheads) oder>> - damit Dinge realisieren kann, die mit der bisherigen Sprache nicht> (oder nur mit ganz krummen Tricks) möglich sind.>
Nö, die schwerer wiegenden Gründe hab ich bereits weiter oben genannt.
Und nenne mir einmal ein Beipiel, wo man in C ein Ding realisieren kann,
was in heutigem Pascal nicht geht. Es ist eher umgekehrt - und zwar in
allen Belangen. Dennoch mögen gar manche Programmierer C mehr als
Pascal, die Gründe sind eigentlich immer rein geschmacklicher Natur. Ein
ehemaliger Kollege von mir meinte dazu, daß Pascal ihm zu wort- und
buchstabenreich sei, insbesondere durch 'begin' und 'end' und daß Pascal
ihm zu wenig stylisch sei im Aussehen des Quellcodes.
Tja, da kann man nix machen, gegen Geschmäcker helfen keinerlei
Argumente.
W.S.
W.S. schrieb:> Und nenne mir einmal ein Beipiel, wo man in C ein> Ding realisieren kann, was in heutigem Pascal nicht> geht.
"Programmiere eine Bibliotheksfunktion für die
Wochentagsberechnung, die sich ohne Veränderung für
MSP430, ATMega, 8052 und i386 übersetzen lässt."
Wohlgemerkt: Gemeint ist nicht "... übersetzen ließe ,
wenn ein Compiler existierte ...", sondern gemeint
ist: "... tatsächlich übersetzen lässt".
W.S. schrieb:> Ich kann dir einen sehr handfesten Grund sagen: Pascal konnte auch ein> Cheffe lesen und so lala verstehen - C hingegen nicht, das war für ihn> wie Hieroglyphen.
Musst du deinen Code tatsächlich immer deinem Chef zur Absegnung
vorlegen? ;-)
Aber mal ganz abgesehen davon: Welcher Chef, der nur wenig Ahnung von
Programmierung hat, versteht folgenden Pascal-Code, der ein Element in
eine doppelt verkettete Liste einfügt?
1
procedure realistic_insert_link( a, c: link_ptr );
2
begin
3
if a^.next <> nil then a^.next^.prev := c;
4
c^.next := a^.next;
5
a^.next := c;
6
c^.prev := a;
7
end;
Quelle:
https://rosettacode.org/wiki/Doubly-linked_list/Element_insertion#Pascal
In C würde man halt <> durch !=, ^. durch -> und := durch = ersetzen. Wo
ist da der große Unterschied bzgl. der Hieroglyphen.
Das Argument mit der Lesbarkeit durch Unerfahrene lasse ich allenfalls
für Cobol gelten. Oder doch nicht, denn auch ein nicht ganz triviales
Cobol-Programm lässt einen typischen Chef nur Bahnhof verstehen.
Nachtrag:
Dein Argument mit der Lesbarkeit von Pascal durch Chefs hinkt sowieso:
Denn dann würde ja in jeder Firma, wo der Chef auch nur ein Bisschen was
zu sagen hat, nur noch in Pascal programmiert.
Apropos Chefs und Hieroglyphen. Ein früherer Chef hatte was für APL
übrig und sich eigens IBMs APL mitsamt Umbausatz für die Tastenkappen
besorgt. Anbei eine FFT in APL.
Also unterschätzt die Chefs nicht!
Egon D. schrieb:> Es ist mittlerweile sogar in der Wirtschaftswissenschaft> angekommen, dass das gebetsmühlenartig wiederholte Mantra> "Das Bessere setzt sich durch" falsch ist.
In vielen Fällen sind die Kriterien für "das Bessere" einfach subjektiv.
Natürlich "war Apple besser", aber auch teurer, langsamer, unflexibler,
...
Natürlich "ist Pascal besser", aber auch geschwätziger, komplexer bzw.
unflexibler, ...
Daniel A. schrieb:> Das Letzte print gibt nicht etwa den Benutzernamen aus, sondern wurde in> der Schleife überschrieben...
Immerhin gewöhnt Python einem ganz schnell das Copy-Paste programmieren
ab. Man merkt schnell, dass man sich nach dem Kopieren jede einzelne
besser dreimal angucken sollte.
Roland F. schrieb:> Warum hat sich C gegenüber Pascal durch gesetzt, obwohl doch Pascal die> bessere Basis darstellte?
Ich hatte zuerst Pascal gelernt und zwei kommerzielle Projekte damit
entwickelt. Eins für DOS und eins für Windows. Die Windows Anwendung
sollte einige Windows-Spezifische Funktionen überstützen, wie
Statusmeldungen in der Taskleiste, Drag&Drop, sowie kommunikation mit
MS-Office.
Dabei war es für mich immer hinderlich, dass die Doku von Microsoft von
C ausging. Ich musste immer dolmetschen. Da ging mir irgendwann zu sehr
auf die Nerven, so kam ich freiwillig zu C und kurz danach zu C++.
Zu der Zeit programmierte ich Mikrocontroller in Assembler, später dann
logischerweise auch in C.
A. S. schrieb:> Egon D. schrieb:>> Es ist mittlerweile sogar in der Wirtschaftswissenschaft>> angekommen, dass das gebetsmühlenartig wiederholte Mantra>> "Das Bessere setzt sich durch" falsch ist.>> In vielen Fällen sind die Kriterien für "das Bessere"> einfach subjektiv.
Die Kriterien für "sich durchsetzen" aber auch. :)
Faktisch läuft auf (fast) allem außer Desktops ein
Linux-Derivat. Trotzdem spricht niemand davon, "Linux
habe sich durchgesetzt".
Und Bill Gates ist der Milliardär, nicht Linux Torvalds.
> Natürlich "ist Pascal besser",
Das bestreite ich :)
Hallo,
Yalu X. schrieb:> Ein anderer wesentlicher Grund war, dass Pascal von einem Lehrer als> reine Lehrsprache, C aber von Praktikern für die Praxis entwickelt> wurde. Pascal war einzig und allein dafür gemacht, den Studenten> Algorithmen zu lehren, und darin (und nur darin) war es sehr gut.
Genau das ist der Punkt.
Man könnte auch sagen das Pascal für Probleme entworfen wurde, die die
Mehrheit der Programmierer damals nicht hatte, während genau die
Probleme löst, die damals anstanden, nämlich die Systemprogrammierung
der neuartigen Minicomputer.
rhf
Roland F. schrieb:> Man könnte auch sagen das Pascal für Probleme entworfen> wurde, die die Mehrheit der Programmierer damals nicht> hatte, während genau die Probleme löst, die damals> anstanden, nämlich die Systemprogrammierung der> neuartigen Minicomputer.
Das greift deutlich zu kurz. Auch die Regeln des
Straßenverkehrs sind nicht ausschließlich bzw. primär
dazu entworfen, die Probleme der Autofahrer zu lösen,
sondern den Radfahrern und Fußgängern eine
Überlebenschance zu lassen.
In den 60ern und 70ern gab es den Begriff der "Software-
krise", und diese wurde u.a. darauf zurückgeführt, dass
die Softwerkerei nicht als solide ingeneurtechnischen
Disziplin mit erprobten und gesicherten Methoden
praktiziert wurde, sondern dass da im Wesentlichen ein
Haufen genialer (oder sich für genial haltender) Chaoten
am Werk war, die in brainfuck-ähnlichen Sprachen
Programme zusammengefrickelt haben, die für niemanden
außer ihnen selbst verständlich und wartbar waren.
Soll heißen: Qualitätssicherung und eine über den
Horizont des Einzelprojektes hinausgehende Arbeits-
teilung waren Fremdworte.
Dass heute nicht in fast jeder Familie ein Therac-25-
Opfer zu beklagen ist, haben wir also auch und gerade
Leuten wie Wirth zu verdanken, die versucht haben,
schon in der Lehre, in der Ausbildung künftiger
Programmierer anzusetzen.
Hallo,
Egon D. schrieb:> Moment -- Du hattest von "nennenswerter Verbreitung"> gesprochen, und die war m.E. durchaus gegeben.
Ja, das stimmt.
> Naja, zu den Hochzeiten von DOS würde ich schon von> einem erdrutschartigen Sieg sprechen...
Wovon heute nichts mehr zu sehen ist, weil...
> Mit dem Niedergang von Borland-Pascal und Delphi> war dann aber auch damit Schluss...
Merkwürdigerweise haben aber selbst freie Nachfolger/Clone wie Free
Pascal haben daran nicht mehr ändern können.
> Stop. Pascal bringst Du jetzt ins Spiel. Ich war von> der Vorstellung ausgegangen, dass jetzt jemand die> neue Wundersprache entwickelt, die C ablösen kann und> soll.
Da haben wir wohl aneinander vorbeigeredet. Mir ging es um die Frage
warum sich die Sprache mit der schlechteren Basis durchgesetzt hat.
> 1. Wirth hatte ganz offensichtlich kein Interesse daran,> die Standardisierung von Pascal voranzutreiben und> den Standard weiterzuentwickeln.
Das stimmt so nicht. Vor mir liegt das Buch "pascal, USER MANUAL AND
REPORT, THIRD EDITION ISO Pascal Standard" von Kathleen Jensen und
Niklaus Wirth, von November 1974.
> Im übrigen teile ich die These, C sei schlampig> entworfen, gar nicht. C ist im Gegenteil ein kleines> Wunder -- auch Dank der Nachbesserungen durch die> verschiedenen Standards.
Da stimme ich absolut zu.
> Man muss m.E. nur verstehen, dass der Fokus zur Zeit> seiner Entstehung auf komplett anderen Eigenschaften> lag, als das heute der Fall ist.
Das stimmt und es stimmt auch wieder nicht. Wenn man die damaligen
Minicomputer mit ihren heutigen Nachfahren vergleicht, ist das
sicherlich richtig. Aber bei der Systemprogrammierung von z.B. kleineren
Mikrocontrollern ist der Unterschied zu den alten Rechner nicht
besonders groß.
rhf
Egon D. schrieb:> .> Und Bill Gates ist der Milliardär, nicht Linux Torvalds.
Weil Bill Gates etwas geschaffen hat und nicht sein Stallbursche.
Egon D. schrieb:> Software-> krise", und diese wurde u.a. darauf zurückgeführt, dass> die Softwerkerei nicht als solide ingeneurtechnischen> Disziplin mit erprobten und gesicherten Methoden> praktiziert wurde, sondern dass da im Wesentlichen ein> Haufen genialer (oder sich für genial haltender) Chaoten> am Werk war,
Das mag man damals als Grund gesehen haben. Der Begriff bezeichnet aber
eher die Erkenntnis, dass SW teurer (und viel komplexer) ist, als HW.
Etwas völlig neues. Und daran hat sich nichts geändert. Du kannst sicher
sein, dass auch im den 50ern und 60ern programmierteams von 100 oder
1000 Leuten nicht aus Einzelkämpfern bestanden. Vielleicht im Gegenteil,
heute kann jemand alleine ein facemesh bauen und Milliardär werden.
Roland F. schrieb:>> Mit dem Niedergang von Borland-Pascal und Delphi>> war dann aber auch damit Schluss...>> Merkwürdigerweise haben aber selbst freie> Nachfolger/Clone wie Free Pascal haben daran nicht> mehr ändern können.
Naja, die Gesamtsituation ist heute anders als vor
30 Jahren. Die Rechner sind viel leistungsstärker
und es gibt viel mehr Konkurrenz durch Scriptsprachen.
Wer ein kleines Progrämmchen incl. GUI zusammennageln
will, nimmt Java oder Python/Tkinter; das ist dann,
wenn's gut läuft, auch plattformunabhängig.
> Mir ging es um die Frage warum sich die Sprache mit> der schlechteren Basis durchgesetzt hat.
Naja, woran macht Du die "schlechtere Basis" fest?
Alles, was man in (Standard-)Pascal ausdrücken kann,
kann man auch in C machen.
Darüberhinaus gehen in C aber auch noch Sachen, die
in (Standard-)Pascal nicht vernünftig machbar sind,
die der systemnahe Programmierer aber dringend
braucht.
Genannt wurden:
- I/O gehört bei Pascal zum Sprachkern; bei C steckt
das in der Standardbibliothek.
- C erlaubt "freistehenen" Betrieb (also Compilat
läuft ohne OS); das geht bei Pascal m.W. nicht.
- C kennt Pointer und Pointerarithmetik; Pascal kennt
Pointer nur rudimentär, Pointerarithmetik gar nicht
und nur Arrays mit zur Laufzeit fester Länge.
- C kann einzelne Einheiten separat übersetzen und
nachträglich zusammenlinken; das geht bei Standard-
Pascal m.W. auch nicht.
Die Grundsituation ist also fast immer: "In C geht
es mit standardkonformen Mitteln, ist aber Gewürge
und Gefrickel. In Pascal geht es mit standard-
konformen Mitteln gar nicht."
Wofür wird sich ein Programmierer, der gegen Geld
arbeitet, wohl entscheiden?
>> 1. Wirth hatte ganz offensichtlich kein Interesse>> daran, die Standardisierung von Pascal>> voranzutreiben und den Standard weiterzuentwickeln.>> Das stimmt so nicht.
Doch.
> Vor mir liegt das Buch "pascal, USER MANUAL AND> REPORT, THIRD EDITION ISO Pascal Standard" von> Kathleen Jensen und Niklaus Wirth, von November 1974.
Schön.
Und wo sind "Pascal-89", "Pascal-99", "Pascal-11"
und "Pascal++"?
Das hatte ich gemeint.
>> Man muss m.E. nur verstehen, dass der Fokus zur Zeit>> seiner Entstehung auf komplett anderen Eigenschaften>> lag, als das heute der Fall ist.>> Das stimmt und es stimmt auch wieder nicht. Wenn man> die damaligen Minicomputer mit ihren heutigen Nachfahren> vergleicht, ist das sicherlich richtig. Aber bei der> Systemprogrammierung von z.B. kleineren Mikrocontrollern> ist der Unterschied zu den alten Rechner nicht besonders> groß.
Doch!
Damals musste der C-Compiler auf einer Maschine mit 8k
Worten zu je 14 Bit laufen.
Heute wird crosscompiliert -- d.h. der Compiler läuft
auf einer Kiste mit 16GByte RAM und 3GHz Takt; nur das
Compilat -- also das übersetzte Programm! -- muss auf
dem Mikrocontroller mit 8k Flash und 1k RAM laufen.
Komplett andere Ausgangslage.
Yalu X. schrieb:> Musst du deinen Code tatsächlich immer deinem Chef zur Absegnung> vorlegen?
Nö.
Aber ich hätte da auch keine Befürchtungen.
Und: es geht hier weder um mich privat noch um dich privat. Also bleib
auch du lieber sachlich.
Zur Sache, also zum Abhaken der Diskussion zwischen C un Pascal: Pascal
war und ist nur für relativ wenige Plattformen zu bekommen. Insbesondere
nicht für alles, was man unter 'Mikrocontroller' zusamenfassen kann -
wenn man mal Mikroe beiseite läßt. Es hatte auch nie in der Zeit vor
Freepascal einen freien Compiler gegeben - und der Laufzeit-Interpreter
für Wirth's Zwischencode-Compilat war nicht gerade prickelnd. Insofern
hatte Pascal nur durch Borland (und deren Nachfahren) eine Basis - und
das war deutlich weniger als bei C. Na, vielleicht ringt sich irgendwer
mal durch, einen tatsächlich für ARM und MIPS geeigneten Compiler daraus
zu bauen. Und in der Zwischenzeit kann man auch seine Firmware in C
formulieren und dabei dennoch mit den Füßen auf dem Boden bleiben.
W.S.
A. S. schrieb:>> Und Bill Gates ist der Milliardär, nicht Linux Torvalds.>> Weil Bill Gates etwas geschaffen hat und nicht sein Stallbursche.
Direkt arm ist Torvalds aber auch nicht. Er wird auf 50 Mio taxiert.
Egon D. schrieb:> Und wo sind "Pascal-89", "Pascal-99", "Pascal-11" und "Pascal++"?
Es gibt immerhin ISO 7185:1983, ISO 7185:1990 (Standard-Pascal) und
ISO/IEC 10206:1991 (Extended Pascal), die man auch als Pascal 83, Pascal
90 und Pascal 91 bezeichnen könnte. Nach 1991 gab es allerdings keine
weiteren Normierungsbestrebungen mehr, da sich kaum noch jemand dafür
interessierte und mittlerweile mit Turbo-Pascal ein konkurrierender
De-Facto-Standard geschaffen wurde, gegen den es sich nicht anzukämpfen
lohnte.
Delphi und Free Pascal wären in dieser Nomenklatur dann Pascal++.
Yalu X. schrieb:> Egon D. schrieb:>> Und wo sind "Pascal-89", "Pascal-99", "Pascal-11" und>> "Pascal++"?>> Es gibt immerhin ISO 7185:1983, ISO 7185:1990> (Standard-Pascal) und ISO/IEC 10206:1991 (Extended Pascal),> die man auch als Pascal 83, Pascal 90 und Pascal 91> bezeichnen könnte.
Richtig.
Dem entsprechen ungefähr ANSI-C/C90.
> Nach 1991 gab es allerdings keine weiteren> Normierungsbestrebungen mehr, da sich kaum noch> jemand dafür interessierte
Eben. Das war mein Punkt.
1991 liegt dreißig (!!) Jahre zurück.
> und mittlerweile mit Turbo-Pascal ein konkurrierender> De-Facto-Standard geschaffen wurde, gegen den es sich> nicht anzukämpfen lohnte.
Ja -- "... SCHEINBAR nicht anzukämpfen lohnte".
Denn so schnell, wie DOS verschwunden war, war auch
Turbo-/Borland-Pascal wieder weg vom Fenster. Geblieben
ist die Normungslücke.
> Delphi und Free Pascal wären in dieser Nomenklatur> dann Pascal++.
... nur ohne den Hauptvorteil von C++: Den Standard.
(prx) A. K. schrieb:> A. S. schrieb:>>> Und Bill Gates ist der Milliardär, nicht Linux>>> Torvalds.>>>> Weil Bill Gates etwas geschaffen hat und nicht>> sein Stallbursche.>> Direkt arm ist Torvalds aber auch nicht. Er wird> auf 50 Mio taxiert.
Eben.
Jetzt geh' auf die Straße und frage 100 Leute, wer
sich "in der IT durchgesetzt hat". Wenn auch nur
10 Leute "Linus Torvalds" sagen, geben ich ein
Volksfest...
Egon D. schrieb:> Jetzt geh' auf die Straße und frage 100 Leute, wer> sich "in der IT durchgesetzt hat". Wenn auch nur> 10 Leute "Linus Torvalds" sagen, geben ich ein> Volksfest...
Hat Torvalds auch TRUE und FALSE definiert?
MaWin schrieb:> Egon D. schrieb:>> Jetzt geh' auf die Straße und frage 100 Leute, wer>> sich "in der IT durchgesetzt hat". Wenn auch nur>> 10 Leute "Linus Torvalds" sagen, geben ich ein>> Volksfest...>> Hat Torvalds auch TRUE und FALSE definiert?
Hat Bill Gates das getan?
Klaus W. schrieb:> In den Windows-Headerdateien wird tatsächlicxh mit TRUE und FALSE> gespielt; irgendwo dadrin ist das definiert...
Dann ist Gates wohl doch besser als Torvalds.
Daniel A. schrieb:> Kein block scope, keine expliziten Variablendeklarationen:#!python3> def something_list_pets(self, name):> pets = user_pet_list[name]> print("You have the following pets: ")> for name, species in pets:> print(f" - Your beloved {species} {name}")> print(f"Have a nice day, {name}")> Das Letzte print gibt nicht etwa den Benutzernamen aus, sondern wurde in> der Schleife überschrieben...
Was soll man dazu jetzt zu diesem Beispiel sagen? "name" nimmt in der
Schleife alle Werte in pets an und hat nach Beendigung der Schleife
natürlich den letzten Listenwert drin. Und den druckst du dann in der
letzten Anweisung aus. Und?? Ich hoffe mal, dass du wenigstens kein
C-hater bist :-)
Gruß Rainer
Felix schrieb:> Wie kommt es, dass man doch meistens die erstere variante sieht?
Ich versteh echt net, warum man da so lange rumredet...
Das ist Compiler abhängig.
" Die Größe einer _Bool-Variablen ist plattformabhängig und kann 8 Bit
übersteigen."
https://de.wikipedia.org/wiki/Datentypen_in_C#bool
Es ist bekannt, das in ASM eine Abfrage auf 0 implementiert ist,
alles andere benötigt mehr Befehle.
Wenn FALSE = 0 ist,
dann ist das TRUE != 0
Alles andere ist egal.
Somit ist es auch schneller wenn man auf 0 prüft anstatt auf >= 500ms
z.B. bei einem Timeout zu prüfen.
Ob der Complier nun wirklich im BitBang Bereich das bool anlegt oder
eine
Systemspezifische größe nimmt (für bool) z.B. uint8_t...
0 ist nun mal 0.
Rainer V. schrieb:> Was soll man dazu jetzt zu diesem Beispiel sagen? "name" nimmt in der> Schleife alle Werte in pets an und hat nach Beendigung der Schleife> natürlich den letzten Listenwert drin.
Ist mir schon klar. Der springende Punkt ist, das der Fehler einfach zu
machen, aber nur selten gewollt ist. Insbesondere, wenn man sich
Sprachen gewohnt ist, wo man variablen deklarieren kann, und es einen
ordentlichen Block Scope gibt. Bei vielen Sprachen (JS, C, C++, Rust,
Java, etc.) kann ich das, dann gewöhnt man sich an, die Loop variablen
nur im Loop zu definieren, und dann bekommt man solche Probleme im
vornherein nicht. Ich habe die Einführung von let und const in JS
erlebt. Ich garantiere dir, das vereinfacht alles extrem, was das
Ausmacht, das sind Welten!
Egon D. schrieb:> Denn so schnell, wie DOS verschwunden war, war auch> Turbo-/Borland-Pascal wieder weg vom Fenster.
Nein, es wurde erweitert (u.a. um objektorientierte Elemente) und in
Delphi umbenannt.
>> Delphi und Free Pascal wären in dieser Nomenklatur>> dann Pascal++.>> ... nur ohne den Hauptvorteil von C++: Den Standard.
Wenn es für eine Sprache nur einen relevanten Compiler gibt und einen
zweiten, der diesen einen möglichst gut nachzuahmen versucht, braucht es
keinen ISO-Standard. Der Referenzcompiler sagt einfach, wo es lang geht.
Das ist bei Python, Ruby, Tcl, Perl, Scheme, Visual Basic und vielen
weiteren Sprachen auch nicht anders.
Bei C/C++ geht so etwas natürlich nicht, weil dort ein Streit unter den
zig Compiler-Herstellern darüber losbrechen würde, welcher Compiler denn
nun von allen anderen als Referenz akzeptiert werden soll.
Egon D. schrieb:> Schön.> Und wo sind "Pascal-89", "Pascal-99", "Pascal-11"> und "Pascal++"?>> Das hatte ich gemeint.
Du ziehst Vergleiche zu Wirth's Ur-Pascal. Kann man machen, stellt aber
nur den damaligen Zustand dar und sollte dann auch mit dem
ursprünglichen K&R C verglichen werden. Vergleiche mal heutiges Pascal
mit heutigem C oder C++. Das wäre weitaus interessanter.
Abgesehen davon sind deine Schlüsse gelinde gesagt ein wenig schräg.
W.S.
Yalu X. schrieb:> Egon D. schrieb:>> Denn so schnell, wie DOS verschwunden war, war>> auch Turbo-/Borland-Pascal wieder weg vom Fenster.>> Nein, es wurde erweitert (u.a. um objektorientierte> Elemente)
Stimmt so nicht. Bereits Turbo-/Borland-Pascal brachte
OOP mit. TurboPascal mit TurboVision lief unter DOS;
Borland-Pascal gabs m.E. (auch) für Windows.
> und in Delphi umbenannt.
Sicher -- aber das war meiner Erinnerung nach ein
permanenter Kampf gegen den drohenden Untergang.
Die Idee war super, aber die Features kamen zu
spät, waren zu unausgereift und zu fehlerhaft.
>>> Delphi und Free Pascal wären in dieser Nomenklatur>>> dann Pascal++.>>>> ... nur ohne den Hauptvorteil von C++: Den Standard.>> Wenn es für eine Sprache nur einen relevanten Compiler> gibt und einen zweiten, der diesen einen möglichst gut> nachzuahmen versucht, braucht es keinen ISO-Standard.
Na, dann schau Dir mal an, wieviele Dialekte FreePascal
unterstützt (meiner Erinnerung nach sind es fünf). Das
Chaos bei den Stringtypen hat m.E. epische Ausmaße
erreicht.
Egon D. schrieb:> Bereits Turbo-/Borland-Pascal brachte> OOP mit. TurboPascal mit TurboVision lief unter DOS;> Borland-Pascal gabs m.E. (auch) für Windows.
Ja. Borland Pascal hatte bis Windows 95 Anpassungen erhalten, danach
wurde es in Delphi umbenannt.
Daniel A. schrieb:> Ist mir schon klar. Der springende Punkt ist, das der Fehler einfach zu> machen, aber nur selten gewollt ist.
Es lohnt hier nicht, das weiter zu diskutieren...ich weiß, was du sagen
willst und so einen Fehler macht als Anfänger sicher jeder mal! Viel
schlimmer finde ich an Python (das ich mir als 2te Hochsprache neben
VisualBasic unter Windoof uralt geönnt habe) dass es immer ein
Kuddelmuddel der Typen gibt. Wenn ich mit np.arrays arbeite und
Operationen ausführe, kommen manchmal als Ergebnis np.arrays raus,
manchmal aber auch effe Listen! Nun fragt sich sicher mancher, wie blöd
ich denn sein muß...ja, dann bin ich blöd und es hat mich (nicht nur in
der Lernphase) stunden gekostet, da Fehler zu finden. Denn
Fehlermeldungen vom System erzeugt das nicht! Und so geht es seinen
Gang...
Gruß Rainer
Rainer V. schrieb:> Wenn ich mit np.arrays arbeite und
Was soll das sein?
np.ndarray?
> Operationen ausführe, kommen manchmal als Ergebnis np.arrays raus,> manchmal aber auch effe Listen
Was ist eine "effe Listen"?
Kannst du bitte mal ein Beispiel geben?
Aus ndarray-Operationen kommen eigentlich ausschließlich ndarrays raus.
MaWin schrieb:> Aus ndarray-Operationen kommen eigentlich ausschließlich ndarrays raus.
Nein...aber das gehört hier jetzt nicht hin! Wenn du das noch nicht
erlebt hast, dann sei froh...und wie gesagt, vermutlich bin ich der
Depp...
Gruß Rainer
Yalu X. schrieb:> Musst du deinen Code tatsächlich immer deinem Chef zur Absegnung> vorlegen? ;-)
haben das die VW Ingenieure etwa nicht gemacht?
Irgendwie hiess es doch immer wir wussten von NICHTS.
In der Prüfgeräte Entwicklung glaubte mir mein Chef nicht mal das das
alte Programm das ich anpassen sollte für neue Baugruppen nur
Luftmessungen machte! Egal ob mit Prüfling oder Ohne es kam immer GUT
raus.
Sein Kommentar, da liefen 100k Baugrupen drüber!
W.S. schrieb:> Egon D. schrieb:>> Schön.>> Und wo sind "Pascal-89", "Pascal-99", "Pascal-11">> und "Pascal++"?>>>> Das hatte ich gemeint.>> Du ziehst Vergleiche zu Wirth's Ur-Pascal.
Naja, der "zweite revidierte Bericht" darf es schon
sein. Aber abgesehen davon -- ja, ich versuche,
Vergleichbares zu vergleichen.
> Kann man machen, stellt aber nur den damaligen> Zustand dar und sollte dann auch mit dem> ursprünglichen K&R C verglichen werden.
Naja, ich finde es sinnvoller, Standard-Pascal mit
ANSI-C zu vergleichen; das haut auch zeitlich ungefähr
hin. Die allerersten Entwürfe herzunehmen finde ich dann
doch nicht fair. Jeder hat das Recht auf Fehlgriffe...
> Vergleiche mal heutiges Pascal mit heutigem C> oder C++. Das wäre weitaus interessanter.
Finde ich nicht. Der Vergleich ist schnell zu
Ende.
Heutiges C(++): Genormt, mehrere Compiler von
mehreren Anbietern. Relativ weite Verbreitung auf
vielen Plattformen.
Heutiges Pascal: Nicht genormt, FreePascal. Ach
so: Mikroe (oder wie die heißen). Keine kommerzielle
Bedeutung.
> Abgesehen davon sind deine Schlüsse gelinde gesagt> ein wenig schräg.
Ich bin, so unglaublich es auch klingen mag, für
Veränderungen offen -- sofern gute Gründe genannt
werden. :)