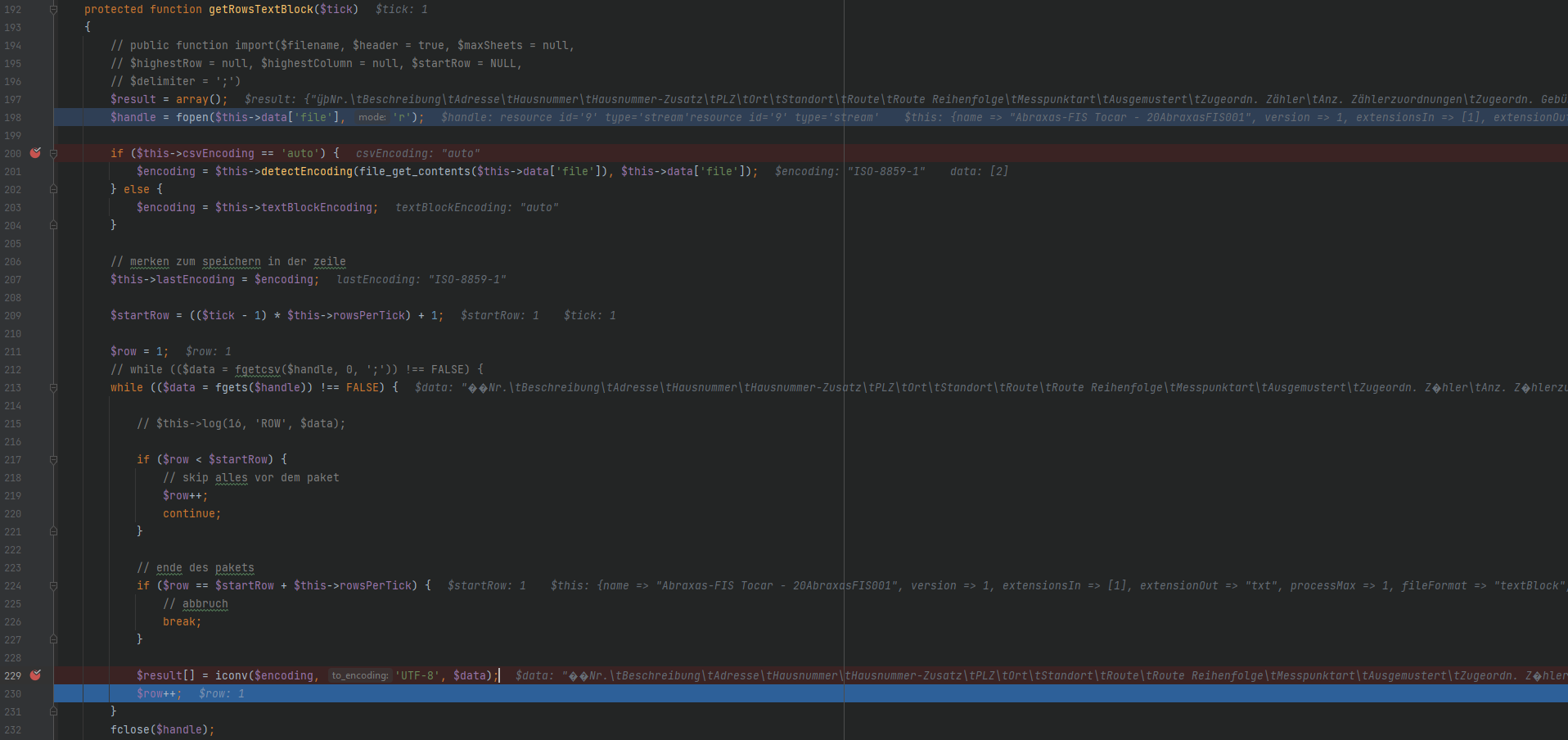
Ich schlage mich gerade ohne grosse PHP Kenntnisse mit PHP herum und habe Probleme mit der encodierung. Das PHP Script öffnet eine txt Datei (gespeichert mit UTF-16 LE codierung, Kundenimport und kann nicht anders gespeichert werden), die im angehängten Screenshot auf Zeile 229 mit UTF-8 encodiert werden sollte. Dies funktioniert aber nicht korrekt. Mit dem Debugger ist ersichtlich, dass die Umlaute nicht korrekt angezeigt werden. Kann mir jemand weiterhelfen? Könnte da ein Fehler sein oder suche ich vielleicht am komplett falschen Ort? Vielen Dank, Isabelle
Angehängte Dateien:
-

Unbenannt.PNG
160 KB
Überprüf vielleicht erstmal unabhänging vom PHP das Input-File, ob da die Umlaute passen. Eine UTF8->UTF16 - Konvertierung beim Kunden repariert die nicht, wenn das Ursprungs-File z.B. vorher eigentlich WIN1252 war.
Angehängte Dateien:
-

Unbenannt1.PNG
21 KB -

Unbenannt2.PNG
18 KB -

Unbenannt3.PNG
1,6 KB


Vielen Dank für die Antworten. Das Input File habe ich überprüft und da stimmen die Umlaute. Mit detectEncoding wird ISO-8859-1 als encoding gefunden (Unbennant1). Wenn ich aber dann mit diesem encoding nach einem Wort in $medium suche, wird nichts gefunden, obwohl ich sehe, dass das Wort vor kommt (Unbennant2). Ich habe mb_strpos auch mit UTF-16 probiert, aber da kam das gleiche Ergebnis (false) raus. Wenn ich im Debugger auf "set value" bei $medium klicke, wird mir folgendes angezeigt (Unbennant3): "\\u0000w\\u0000a\\u0000s\\u0000s\\u0000e\\u0000r\\u0000 \\u0000&\\u0000 \\u0000a\\u0000b\\u0000w\\u0000a\\u0000s\\u0000s\\u0000e\\u0000r\\u0000" Ich nehme an, dies gibt auch nochmal einen Hinweis auf das Encoding oder? Wie muss mein Code lauten, damit ich true zurückbekomme (Unbennant2)?
Isabelle schrieb: > Wenn ich im Debugger auf "set value" bei $medium klicke, wird mir > folgendes angezeigt (Unbennant3): > "\\u0000w\\u0000a\\u0000s\\u0000s\\u0000e\\u0000r\\u0000 \\u0000&\\u0000 > \\u0000a\\u0000b\\u0000w\\u0000a\\u0000s\\u0000s\\u0000e\\u0000r\\u0000" Das ist UTF-16. Öffne das File in einem Editor und probiere dort mit verschiedenen Encodings, dann siehste schneller ob das Encoding passt. Wenn du es dort ermittelt hast stellt du das in deinem Code ein. Wenn du Pech hast, ist das File ein Mischmasch aus verschiedenen Encodings weil mal einer mit falschen Encodingeinstellung das File geändert hat.
Angehängte Dateien:
-

Unbenannt4.PNG
57 KB
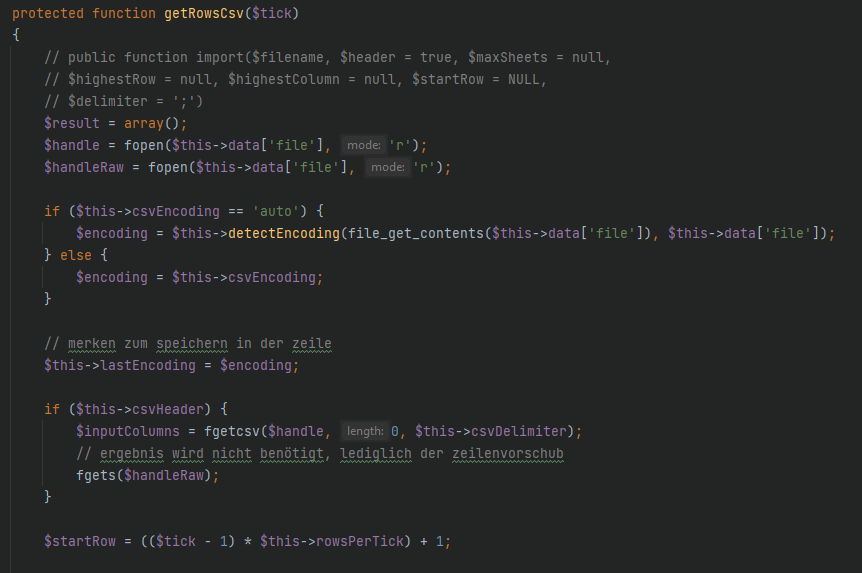
bashooka schrieb: > Öffne das File in einem Editor und probiere dort mit verschiedenen > Encodings, dann siehste schneller ob das Encoding passt. Wenn du es dort > ermittelt hast stellt du das in deinem Code ein. Ich hab das File geöffnet und mal in UTF-8 abgespeichert. Wenn ich es dann teste, läuft alles korrekt durch ohne dass ich ich im Code etwas verändern musste. Heisst bei mb_strpos ist immer noch ISO-8859-1 als Encoding drin, aber mit UTF-8 wird das trotzdem richtig erkannt? Kann ich allenfalls das File in UTF-16 lassen und dafür beim Öffnen des Files (Unbennant4) alles auf UTF-8 codieren? iconv habe ich probiert, aber das hat nicht geklappt.
Angehängte Dateien:
-

Unbenannt5.PNG
95 KB
{kind=link}
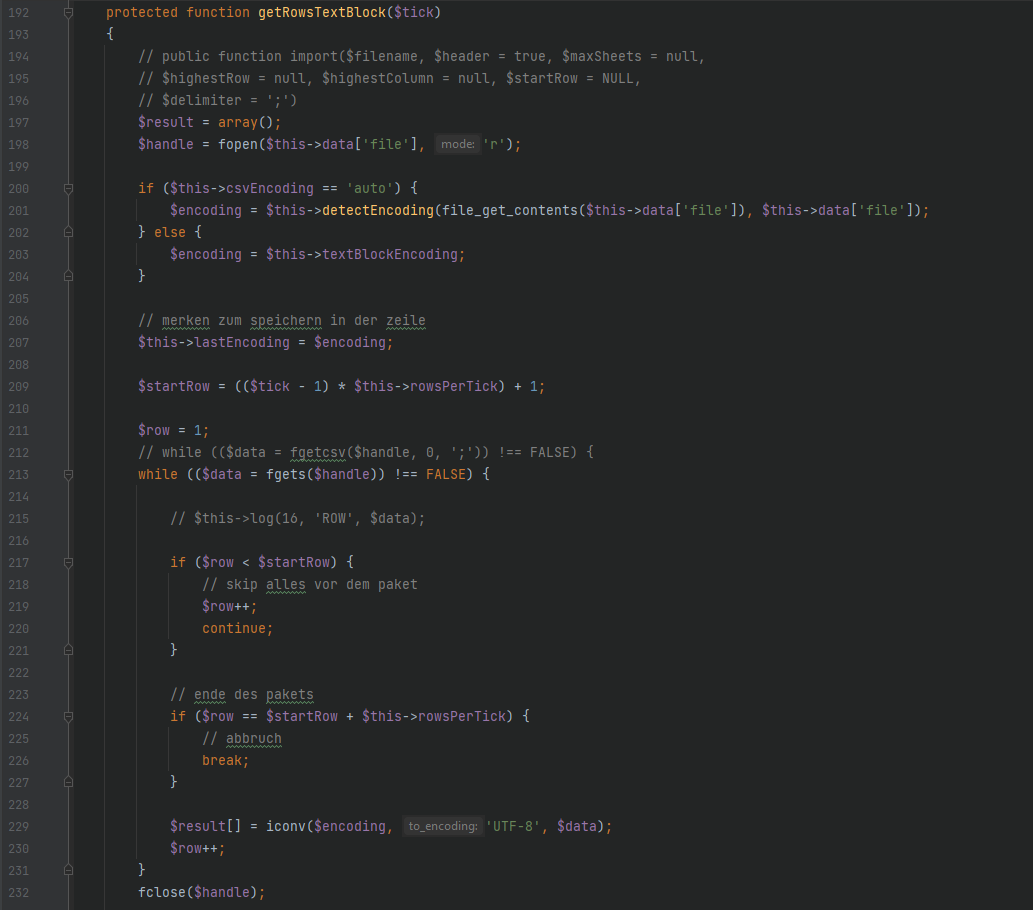
Isabelle schrieb: > Kann ich allenfalls das File in UTF-16 lassen und dafür beim Öffnen des > Files (Unbennant4) alles auf UTF-8 codieren? iconv habe ich probiert, > aber das hat nicht geklappt. Ich hab den falschen Screenshot angehängt, sorry. Das hier ist der Part, wo das File geöffnet wird.
Isabelle schrieb: > immer noch ISO-8859-1 als > Encoding drin, aber mit UTF-8 wird das trotzdem richtig erkannt? Schau mal hier nach: https://www.php.net/manual/de/function.utf8-encode.php Mit dieser Funktion kannst du von ISO-8859-1 nach UTF-8 kodieren.
1. detectEncoding würde ich rauswerfen, das funktioniert nicht zuverlässig, siehe auch Doku dazu. 2. In deinen iconv-Aufrufen steht nie das Quellformat drinn. Probier mal bei iconv als Quelle "UTF16LE" iconv gibts auch als gleichnamiges Kommandozeilenprogramm: iconv -l: Listet die Encodings, hier die UTFs: ... UTF-7, UTF-8, UTF-16, UTF-16BE, UTF-16LE, UTF-32, UTF-32BE, UTF-32LE, UTF7, UTF8, UTF16, UTF16BE, UTF16LE, UTF32, UTF32BE, UTF32LE, ... Ansonsten muss du da evt. ein bischen rumprobieren denn der mb-string support in PHP war schon immer mehr oder weniger kaputt und sowas wie UTF-16 funktioniert meist noch schlechter als UTF-8, nicht nur in PHP. Die mb_string-Funktionen tun deshalb meist nicht das was sie sollten. Wenn mb_string immer noch Ärger macht, dann vielleicht UTF-16 in einen einbytiges characterset (ISO-8859-*) wandeln, dann mit den normalen strpos-Funktionen arbeiten und das Resultat wieder nach UTF-8 oder was auch immer wandeln.
hört sich vermutlich blöd an, aber mit iconv hatt ich auch schon Freude, dass hinterher nichts passte, versuch mal mb_convert_encoding nach dem Lesen Deiner Datei.
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.