Xilinx vertreibt einen Display-Port-Core für die /er Baureihe, der sogar frei zu sein scheint, allerdings gibt es den nur für die Kintex, Virtex und Ultrascale. Der Artix ist nicht gelistet. Ich frage mich warum? Der Artix hat laut Spezifikation Transceiver, die bis 6GBPS gehen. Das müsste eigentlich reichen, oder?
M. W. schrieb: > Ich frage mich warum? Der Artix hat laut Spezifikation Transceiver, die > bis 6GBPS gehen. Das müsste eigentlich reichen, oder? Also ich finde auf die schnelle für die langsamste spec für display-port 8,64 Gbps...
Blame4Lame schrieb: > M. W. schrieb: > >> Ich frage mich warum? Der Artix hat laut Spezifikation Transceiver, die >> bis 6GBPS gehen. Das müsste eigentlich reichen, oder? > > Also ich finde auf die schnelle für die langsamste spec für display-port > 8,64 Gbps... die kommt woher? Der Displayport treibt wie HDMI 3 differentielle Paare + Takt, bzw kann sogar 4 ohne Takt. Bei HDMI 2.0 reichen 6BBPS für 8 bit RBG in Vollauflösung. 150 MHz x 3 x 8 Bit x b10b8 = 4,5GBPS.
>Ich frage mich warum? Der Artix hat laut Spezifikation Transceiver, die >bis 6GBPS gehen. Das müsste eigentlich reichen, oder Ich würde auch vermuten, dass das unnötig ist, Makketinng Linzenskosten und Herstellerbindung würden mir da einfallen.
Die Aussagen von Xilinx und Digilent sind zu diesem Thema etwas widersprüchlich. In dem "Nexys Video FPGA Board Reference Manual" von Digilent wird ausdrücklich die DisplayPort-Schnittstelle erwähnt, ebenso auch gesagt: "Xilinx provides a fully documented Vivado IP core that implements a DisplayPort controller. Using this core will greatly decrease the development required to get DisplayPort working on the Nexys Video. This core requires a paid license, but a 120 day evaluation license can be obtained for free from the Xilinx website." In dem ebenfalls erwähnten Xilinx UG482 ist wiederum nichts speziell zu DisplayPort zu finden. Laut PG168 werden jedoch nur die Transceivertypen GTH und GTX in Kintex und Virtex unterstützt. https://digilent.com/reference/_media/reference/programmable-logic/nexys-video/nexysvideo_rm.pdf Es gab laut Trenz offenbar mal eine freie Implementierung von DisplayPort auf Artix-7, aber die verlinkte Webseite existiert offenbar nicht mehr: https://shop.trenz-electronic.de/de/26722-Nexys-Video-Artix-7-FPGA-Trainer-Board-for-Multimedia-Applications?number=26722 Stattdessen findet man den Core nun auf Github: https://github.com/hamsternz/FPGA_DisplayPort
Die Erklaerung findet sich wohl hier: https://support.xilinx.com/s/article/68639 Der Support fuer GTP Transceiver und damit Artix-7 wurde eingestellt. Der Product Guide zu einer alten Version (ich weiss leider nicht ob es die letzte war) findet sich hier: https://www.xilinx.com/support/documentation/ip_documentation/displayport/v7_0/pg064-displayport.pdf Darin steht, dass mit Vivado 2017.2 der Support aufhoert. Also am besten mal Vivado 2017.1 aufspielen und schauen ob der Core da noch mit dabei ist.
Tobias B. schrieb: > Der Support fuer GTP Transceiver und damit Artix-7 wurde eingestellt. In irgendeinem Pamphlet von Xilinx hatte ich auch einen möglicherweise damit zusammenhängenden Hinweis gelesen, der sinngemäß lautete: "Auf Grund von 'silicon errata workarounds' dauert die Implementation deutlich länger als erwartet, wenn man auf einem Artix-7 die Transceiver nutzt". Ich frage mich, worin diese Workarounds bestehen und warum sie bei der Generierung deutlich Rechenleistung bzw. Zeit benötigen. Sind eventuell irgendwelche Timinganforderungen wesentlich strenger als normal? Oder müssen womöglich irgendwelche Verzögerungsleitungen mit engen Toleranzen rund um den halben Chip geroutet werden? Ggf. müsste man sich - hinreichendes Interesse vorausgesetzt - mal das fertige Routing anschauen, um hoffentlich zu erkennen, an welchen Stellen Xilinx da nachhelfen musste.
Andreas S. schrieb: > In irgendeinem Pamphlet von Xilinx hatte ich auch einen möglicherweise > damit zusammenhängenden Hinweis gelesen, der sinngemäß lautete: "Auf > Grund von 'silicon errata workarounds' dauert die Implementation > deutlich länger als erwartet, wenn man auf einem Artix-7 die Transceiver > nutzt". Bezieht sich das auf den DisplayPort Core oder generell? In meinem obigen Post war das etwas undeutlich von mir, da war der GTP Support wirklich nur auf den DisplayPort Core bezogen. Ich denke fuer die Xilinx Power Users sollte das klar sein, wollte das aber fuer die Newbies hier mal noch richtig stellen. :-)
Andreas S. schrieb: > In irgendeinem Pamphlet von Xilinx hatte ich auch einen möglicherweise > damit zusammenhängenden Hinweis gelesen, der sinngemäß lautete: "Auf > Grund von 'silicon errata workarounds' dauert die Implementation > deutlich länger als erwartet, wenn man auf einem Artix-7 die Transceiver > nutzt". Gut möglich. Die GTP am Artix haben doch von Anfang an diesen komischen Reset Silicon Bug, der dann mit einer riesigen State Machine am DRP behoben wird. Ganz am Anfang musste man die selbst dran fummeln, inzwischen wird die beim Core mit generiert. Das kann gut sein dass das dann zuviel wird, wenn man DP damit machen will, der Klumpen der da als Würgaroud dran hängt ist schon nicht ohne. Wir nutzen die GTP, das klappt soweit problemlos. https://support.xilinx.com/s/article/53561?language=en_US
Das ist allerdings echt be**** ... scheiden, dass ausgerechnet bezüglich DP die Transceiver nicht funktionieren sollen. Andreas S. schrieb: > https://github.com/hamsternz/FPGA_DisplayPort Ja, den Hamsterworks, den kenne ich. Scheint aber nur 800x600 zu schaffen und erstaunlich gleich 3840. Woran es jetzt im Detail hängt, durchschaue ich auch nicht. Wenn er 3840 mit 2 lanes schafft, wie er schreibt, müsste er mit einer lane die Hälfte schaffen, denke ich mir. Ungeachtet dessen, frage ich micht, warum man einen bug im Silicon nicht einfach beheben kann. Produzieren die keine neuen ARTIX-Bausteine mehr? Was wäre denn der kleinste Kintex, der das kann? Und welcher von denen ist mit der Webedition noch machbar?
M. W. schrieb: > Das ist allerdings echt be**** ... scheiden, dass ausgerechnet bezüglich > DP die Transceiver nicht funktionieren sollen. Heisst doch nicht, dass das nicht funktioniert. Der Support wurde halt eingestellt, lohnt sich nicht. Offensichtlich ist da der Markt nicht gross genug, dass sich das lohnt zu pflegen. Nimm den alten Core aus dem alten Vivado und schau ob das fuer deine Anwendung funktioniert.
M. W. schrieb: > Ungeachtet dessen, frage ich micht, warum man einen bug im Silicon nicht > einfach beheben kann. Produzieren die keine neuen ARTIX-Bausteine mehr? Frage ich mich auch schon länger. Die Dinger werden doch massenhaft produziert und verbaut. Aber ein BWLer hat sicher errechnet dass es günstiger ist, dauerhaft die große State Machine einzubauen als das hardware design zu ändern. Es funktioniert ja auch mit dem workaround...
M. W. schrieb: > Ungeachtet dessen, frage ich micht, warum man einen bug im Silicon nicht > einfach beheben kann. Produzieren die keine neuen ARTIX-Bausteine mehr? Xilinx wird ganz sicher keine Bugfix-Version des Artix rausbringen, das wäre dann eine RevB und der Anwender müsste immer schauen, dass er den richtigen verwendet. Bei Massenprodukten ist das ein NoGo, das Eingeständnis eines Fehlers. In folgenden Artix-Varianten kommen neue Features hinzu und nebenbei werden heimlich still und leise auch die Bugs der alten Varianten behoben. Intel hat es nach dem P5-Bug genauso gemacht. Was den DP-Core betrifft... die Artix-Serie ist kaum für Videoanwendungen gedacht. Selbst wenn der Core selbst funktioneren würde, wäre zu wenig Platz übrig um etwas Sinnvolles damit anzufangen, außer ein paar einfachen Filtern oder einem OSD. Und dafür spendiert keiner ein FPGA, außer bei kleinen Privatprojekten.
Fällt mir gerade noch ein zum Thema, ich glaube es gab vor Jahren bei den Virtex-II mal einen haarstäubenden Bug in den Tranceivern, der die Teile für bestimmte Anwendungen unbrauchbar machte. Das wurde nie gefixt, sondern es gab ein Addendum zum Datenblatt, in dem die Transceiver abgelastet wurden. Stattdessen hat man dann den Virtex-4 gearbeitet. War im Grunde auch sinnvoller als einen ganzen Maskensatz für ein Silicon-Fix zu erstellen. Die Masken sind nämlich verflixt teuer, selbst für Xilinx.
Vancouver schrieb: > Fällt mir gerade noch ein zum Thema, ich glaube es gab vor Jahren bei > den Virtex-II mal einen haarstäubenden Bug in den Tranceivern, der die > Teile für bestimmte Anwendungen unbrauchbar machte. Das wurde nie > gefixt, sondern es gab ein Addendum zum Datenblatt, in dem die > Transceiver abgelastet wurden. Ja, das zeigt schon mal in die Richtung des tatsächliche Problems, das auch heute noch besteht: der Yield und die Exemplastreuung bei analogen/Mixed signal Baugruppen wie die Multi Gigabit Transceiver. Meines Wissens hat Xilinx damals nicht einfach weiterentwickelt oder Masken gefixed, sondern die bisherige Baugruppe 'Rocket-IO' samt den (externen?) Entwicklern rausgeschmissen und diese Silizium-Ecke komplett neu designed. Und das in enger Zusammenarbeit mit der tatsächlichen Chip-fab, was eigentlich gegen das Geshäftsprinzip von Xilinx als fabless IP-Firma steht, die es gewöhnt ist, das deren Chip-Layouts 1:1 mit den erwarteten Eigenschaften gefertigt werden können.
Tobias B. schrieb: > Die Erklaerung findet sich wohl hier: > > https://support.xilinx.com/s/article/68639 > Da steht: "It has been determined that the DisplayPort RX/TX Subsystems and Video PHY product cannot meet Xilinx production *level* criteria " also IMHO geht es hier um 3 Punkte: (1) wie entstehen die Werte in den Datenblättern ? (2) wie betsimmt der yield (Ausbeute an 100% funktionierenden IC's aus einem Wafer) den Stück-Preis. (3) was bedeudet es, wenn die Einhaltung eines kompletten Standards garantiert wird (1) Es gibt bei den Datenblättern im wesentlichen zwei Lebensphasen, "preliminary" and "production" data. Zuerst gibt es preliminary data, also bspw Laufzeiten wie sie aus Simulationen oder Prototypen ermittelt wurden. Das sind noch viel "Wünsch dir was" Zahlen dabei und bei den Prototypen akzeptiert man auch ganz schlechte Ausbeute, Hauptsache man hat einen 'proof of concept' Jahre später, wenn Hunderttausende von den IC gefertigt wurden, hat man dann dank Statistik 'production data' -> also die Werte die ein IC aus der auf Kosten optimierten serienfertigung mit hoher statistischer Wahrscheinlichkeit erreicht. Dann, bei der Massenfertigung, stellt sich manchmal heraus das die preliminary data zu optimistisch waren und nur 'unter Laborbediungungen erreichbar sind, insbesonders bei den Low Cost Produkten. (2) Hohes yield bedeudet geringer Stückspreis, geringes yield hoher Preis, weil die Kosten für die Fertigung eines Pizzagrossen Wafers eben gleich sind, unabhängig in wieviel funktionierende Einzel-Chips er zerlegt werden kann. Nun kann man aber als Xilinx nixht viel am yield verändern und hat dann die Arschkarte gezogen, wenn der Hersteller eben Chips mit 100% analog-parametern nur aus dem Wafer-zentrum schneiden kann (bspw wegen zum Rand zunehnden Parallaxenfehler bei der Belichtung) und die am Rand eben mehr Toleranzen im Analogteil haben. Will man Chips mit garantierten Top-leistungen liefern, kann man nur das Filetstück verwenden. Aber das war ja für die schnelleren und hochpreisigern IC-Familien vorgesehen. Also kündigt man das Feature für die LowCost-Reihe ab, um nicht bei der Herstellung wegen dem schlechten yield draufzuzahlen. (3) Das hat man auch bei intel und DDR-Interface schon erlebt, da werden Controller für einen Standard für manche Baureihen abgekündigt, weil man eben nicht garantieren kann, das alle Geschwindigkeitsklassen unter allen Bedingungen erfüllt werden kann. Ja, man könnte für langsame 'Ecken' des Standards volle Funktion garantieren, aber eben nicht für alle möglichen Anwendungen innerhalb dieses Standards. Und vielleicht spielt es bei displays eine Rolle, das dort hohe isochrone Datenraten über Stunden/Tage Laufzeit vorausgesetzt werden, während es bei (Paketorientierten) Datenverbindungen auch akzeptabel ist, das die Transceiver bei zu hoher Bitfehlerrate mal eine 'Trainingspause' einschieben, um die für die aktuelle Temperatur optimolen werte für Preemphasis und anderen Analogkram zu ermitteln und zwischen Rx und Tx auszuhandeln. Nicht umsonst braucht xilinx 400 seiten um allein für die Transceiver alle Einstellmöglichkeiten zu nennen.
Noch ein weiterer Punkt: Wenn gravierende Änderungen an solch einem Peripherieblock durchgeführt werden, ist er womöglich nicht mehr voll abwärtskompatibel zu vorherigen Maskenversionen. Bei einem Microcontroller bekommt man das noch irgendwie auf die Reihe, aber bei einem FPGA stimmen dann die ganzen Timingberechnungen älterer Designs nicht mehr. Das kann also gravierende Seiteneffekte besitzen. Und funktionieren dann überhaupt noch Designs, die den alten Workaround einsetzen und sich daher ggf. auf die Fehlfunktion verlassen. National Semiconductor meinte ja damals(tm), mit der Überarbeitung des 8250 etwas Gutes zu tun, indem sie einen der bekannten Bugs behoben. Leider verließen sich doch etliche Treiber darauf. Folglich wurde dann der 8250B nachgeschoben, der diese Bug (nun jedoch als Feature) wieder beinhaltete.
Angehängte Dateien:
-

artix7_family.png
55 KB
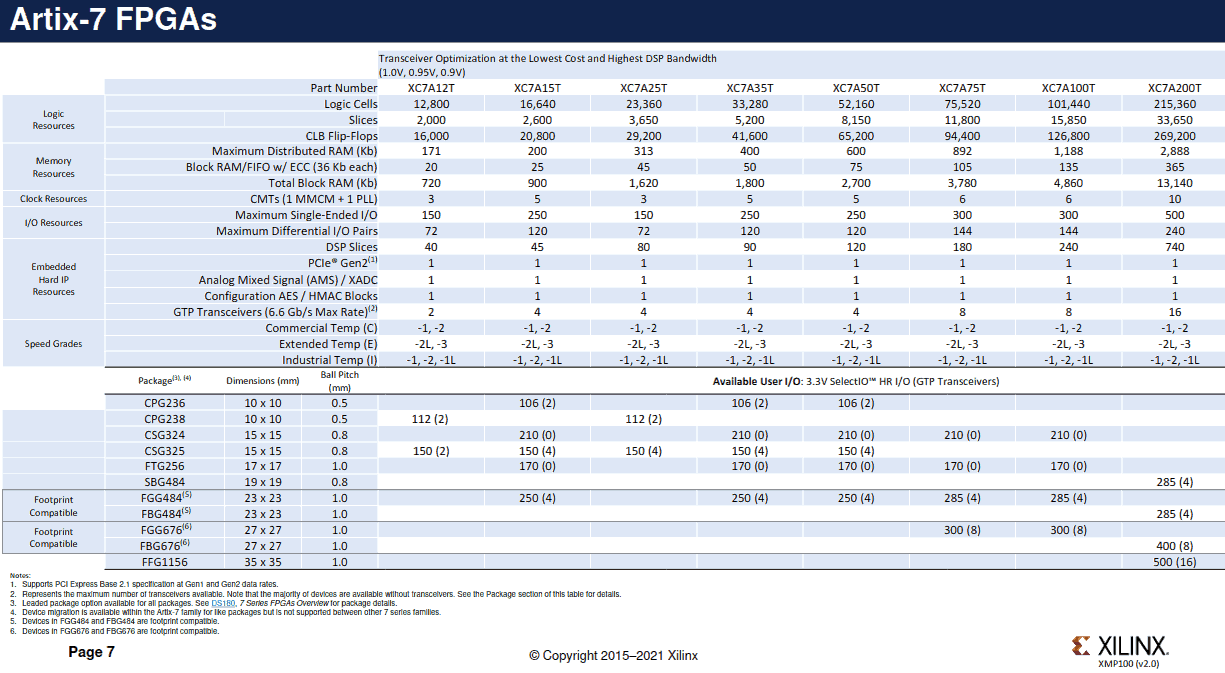
Bzgl. Yield kenne ich mich nicht so aus, aber ich kann mir nicht wirklich vorstellen, das Xilinx für jeden Artix-7 in jedem Footprint einen neuen Maskensatz hat. Weiß da jemand mehr? Reicht es, für die unterschiedlichen BGA-Varianten nur die äußeren Metal-Layer anzupassen? Vielleicht läßt sich ja die Ausbeute auch erhöhen, wenn man die Chips, wo die GTPs nicht die volle Performance bringen, als Spartan-7 verkauft... Duke
Duke Scarring schrieb: > Bzgl. Yield kenne ich mich nicht so aus, aber ich kann mir nicht > wirklich vorstellen, das Xilinx für jeden Artix-7 in jedem Footprint > einen neuen Maskensatz hat. Weiß da jemand mehr? Bei FPGAs hast du typischerweise pro "Grösse" ein Die/Maskensatz (In deiner Tabelle als Part Number). Die verschiedenen Gehäusevarianten werden mit dem selben Die hergestellt. Wen ein Gehäuse weniger Pins hat, als das Die I/Os, dann werden die einfach nicht angeschlossen -> Das lässt auch schon etwas Erhöhung des Yield zu. Bei Lattice gibt es in den Reports dazu so Zeilen, die das suggerieren. Bei Microchip Libero gibt man im TCL das Die an anstatt die Part Number und das Gehäuse ist ein separater Parameter :-)
Christoph Z. schrieb: > Die verschiedenen Gehäusevarianten > werden mit dem selben Die hergestellt. Wen ein Gehäuse weniger Pins hat, > als das Die I/Os, dann werden die einfach nicht angeschlossen -> Das > lässt auch schon etwas Erhöhung des Yield zu. Auch bei Microcontrollern und -prozessoren ist so etwas üblich. Und wenn man Pech hat, dann hat der Hersteller dabei geschlampt, wie z.B. Atmel bei AT91RM9200. Dort waren in der QFP-Variante nämlich Pins offen, die eigentlich auf definierte Signalpegel hätten gezogen werden müssen. Leider gab es auch keine Möglichkeit, interne Pull-Up- oder Pull-Down-Widerstände zu aktivieren, so dass man einfach mit sporadischen Interrupts leben musste. Betroffen war z.B. einer der USB-Host-Ports, bei denen die obligatorischen 15k-Pull-Down-Widerstände fehlten. Und dann gibt es auch noch Bausteine, bei denen wohl vorrangig rechtliche Gründe zu unterschiedlichen Typen führen, z.B. LPC2294 mit CAN und LPC2214 ohne CAN. Bei beiden Typen sind die CAN-Leitungen herausgeführt, und auch alle Register sind vorhanden. Jedoch muss(te) NXP wohl ordentlich Lizenzgebühren an Bosch abführen, so dass sie sich für die "halblegale" Version ohne formal vorhandenes CAN entschieden. Als Kunde darf man sich natürlich nicht darauf verlassen, dass der CAN-Block tatsächlich einwandfrei funktioniert.
Duke Scarring schrieb: > Vielleicht läßt sich ja die Ausbeute auch erhöhen, wenn man die Chips, > wo die GTPs nicht die volle Performance bringen, als Spartan-7 > verkauft... Die Frage ist, was 'GTP außerhalb Produktionstoleranzen' für den Anwender bedeudet; das mit 'nicht volle Performance' gleichzusetzen kann schon Wunschdenken sein. Wenns mal längeren Streit um die Zulieferqualität gab, dann war es meist, das die Leistungsaufnahme der IC's höher war als man aus dem Datenblatt 'gedeutet' hat. Auch aus der Speicherfertigung bei Quimonda ist mir bekannt, das es bei quality immer um 'zuviel Stromaufnahme' ging, das waren aber dann lediglich ein paar Picoamperes zuviel, was aber die Halbleiter-Ingenieure dort schon beunruhigte und die hektisch mit den Rasterkraftmikroskopen o.ä. nach den Stromlecks suchten. https://en.wikipedia.org/wiki/Conductive_atomic_force_microscopy Könnte auch sein, das zuviel Strom -> Engstelle im Si oder Metallisierung -> lokaler HotSpot -> erwartbarer früher Ausfall bedeutet; weil ein paar nanoAmperes,mikro oder gar miliAmperess mehr oder weniger sollten den FPGA-Anwender nicht beunruhigen. Bei dem GTP's kommt wohl noch fehlende strukturelle Redundanz hinzu. Bei den LUT's baut man gerne ein paar mehr als 'sewing gates' drauf, um nach der Produktion/Test per Laserabgleich defekte Regionen abzuschalten. Weil aber der GTP als analoger Leistungstreiber viel Die-fläche belegt, kann man es sich wohl nicht leisten zwei, drei extra als benötigt aufzubauen.
Andreas S. schrieb: > Als Kunde darf man sich natürlich nicht darauf verlassen, dass der > CAN-Block tatsächlich einwandfrei funktioniert. Wie darf man das denn interpretieren? Wenn der CAN als Komponente drin ist, ist er drin - sofern er verwendbar ist. (?) Fpgakuechle K. schrieb: >> Vielleicht läßt sich ja die Ausbeute auch erhöhen, wenn man die Chips, >> wo die GTPs nicht die volle Performance bringen, als Spartan-7 >> verkauft... Also Artixe haben einiges mehr an Ruhestrombedarf als Spartan, wie ein Kunde von mir schon lernen musste und einen solchen als Spartan zu labeln, wird deshalb wohl eher nicht hinhauen. Eher schon ließe sich so etwas aufziehen, wie es Altera mal Mitte der 2000er gemacht hat: Da gab es 3 Cylones desselben Types: A) den Schnellen, B) den Stromsparer und C) den Billigen. Die Gruppe C setzte sich dann aus den Kameraden der Gruppen A und B zusammen, die die SPEC nicht gepackt haben. Man hatte mit einem Billigen also entweder einen Stromfresser, der trotzdem nicht so schnell ist, wie er müsste, aber immer noch schnell - oder eine Schnecke, die trotz Design auf Sparen, nicht viel spart.
Vancouver schrieb: > Was den DP-Core betrifft... die Artix-Serie ist kaum für > Videoanwendungen gedacht. Selbst wenn der Core selbst funktioneren > würde, wäre zu wenig Platz übrig um etwas Sinnvolles damit anzufangen, > außer ein paar einfachen Filtern oder einem OSD. Und dafür spendiert > keiner ein FPGA, außer bei kleinen Privatprojekten. Interessant! Ich habe in den vergangenen Jahren einige Videoanwendungen mit Artix gemacht und die enthielten auch Signalverarbeitung, sassen in einem Fall in dem kleinen 15er drin. Allerdings wurde entweder HDMI per TMDS über Buffer oder einen Triber-Chip verwendet. M. W. schrieb: > Und welcher von denen ist mit der Webedition noch machbar? Der kleinste ist meines Wissens der 75er. Allerdings sind die Kintex im Schnitt 30%-40% teuer, Pro Leistung in MHz x Resourcenanzahl. Konkret kostet der kleine Kintex erheblich mehr, als der mittlere Artix, hat aber deutlich weniger Resourcen - packt nur eben intern 400 MHz statt 300, die man fürs Video nicht unbedingt braucht, es sei denn man möchte 4X-AXI@100MHz. Ein Artix schafft ohne weiteres die 297 fürs Video und die 594, die wir ja gerne hätten packt noch keiner. Auch kein Versal. Andreas S. schrieb: > Es gab laut Trenz offenbar mal eine freie Implementierung von > DisplayPort auf Artix-7, aber die verlinkte Webseite existiert offenbar > nicht mehr: Das Trainerboard gibt es nicht mehr, aber das ist ja nur eine preiswert verkaufte Version des eigentlichen Boards. Das gibt es auch noch zu kaufen und steht auch bei mir auf'm Tüsch! Hat mini-DP-Port mit 3.75Gbps. Darüber geht als DP+ (HDMI-Emulation) 1080i60 oder 1080p30. Was der gute Mike vom Hamster macht, ist kein Vollformat sondern 4:2:2. Das bedeutet reduzierte Farben. Außerdem scheint er in zumindest einem Design die GTPs zu übertakten. Und das ist halt nicht stabil.
Jürgen S. schrieb: > Andreas S. schrieb: >> Als Kunde darf man sich natürlich nicht darauf verlassen, dass der >> CAN-Block tatsächlich einwandfrei funktioniert. > Wie darf man das denn interpretieren? Wenn der CAN als Komponente drin > ist, ist er drin - sofern er verwendbar ist. (?) Beim LPC2214 ist der CAN-Block laut Datenblatt nicht angegeben. Trotzdem sind erfahrungsgemäß die Register usw. vorhanden und funktionsfähig. NXP dürfte aber bei gelieferten LPC2214 auch entweder den Block komplett weglassen, ihn in der Fertigung deaktivieren oder auch einen defekten CAN-Block liefern. Es wurde niemals zugesichert, den LPC2214 mit funktionsfähigem CAN zu liefern.
Jürgen S. schrieb: > Außerdem > scheint er in zumindest einem Design die GTPs zu übertakten. Und das ist > halt nicht stabil. Das verstehe ich nicht. Gerade vorgestern gab es von PLC2 ein Seminar zur Portierung von Spartan 6 auf Artix, Spartan 7 und Virtex/Kintex und den Kriterien, wann man welchen Ersatz nimmt. Dazu gab es genau diesen Fall, dass der Spartan 6 Transceiver hat, die der S7 offenbar nicht zu haben scheint. Der Artix hat die aber und der steht auf 6.xxx Gbps, während der S6 nur 3.xxx hatte. Mehr als &G braucht es aber laut SPEC nicht, um DP zu machen. Warum also sollte es nicht gehen? Taugen die PLLs qualitativ nicht?
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.