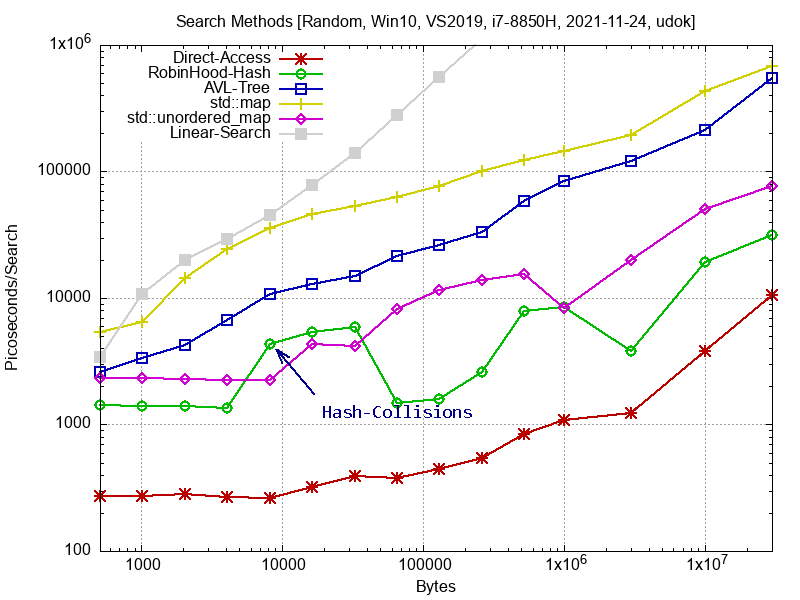
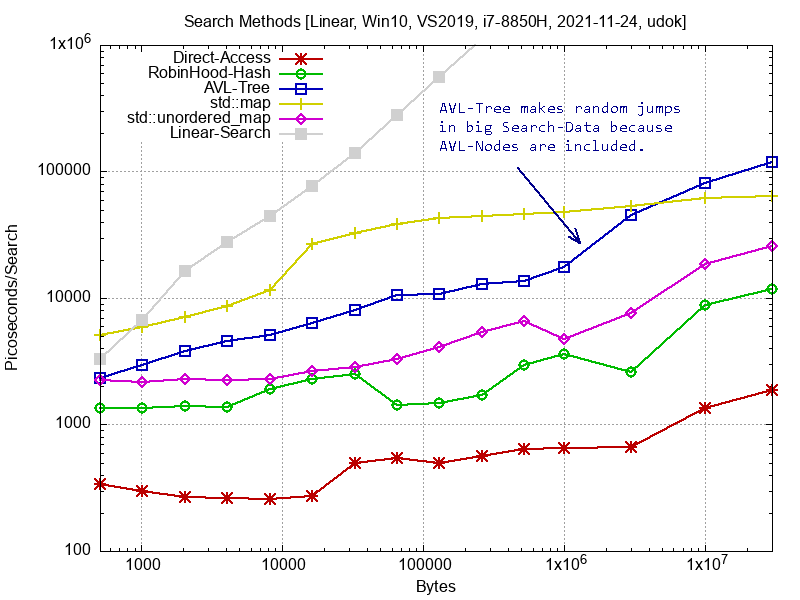
Um mal wieder etwas handfeste Info zum Programmieren zu bringen: In den angehängten Bildern findet ihr Benchmarks für verschiedene gängige C/C++ Suchmethoden. Im Prinzip nichts Neues, aber es sind aktuelle gemessene Daten, die euch als Entscheidungsgrundlage für eure Programme dienen können. OS ist Win10, Compiler ist VS2019, System ist ein i7-8850H Laptop (L1 Cache 32kByte, L2=256k, L3=1.5MByte). Gesucht werden 32 Byte Strukturen in einem Feld. Als Suchindex dient ein Integer, damit die Vergleichsfunktion so wenig Einfluss wie möglich hat. Das Feld mit den N Strukturen ist immer aufsteigend sortiert. Die Suchwerte kommen aus einem zweiten Feld mit Integer Werten. Dieses zweite Feld ist entweder mit Zufallszahlen initialisiert, oder linear aufsteigend von 1 - N sortiert. Das erste Bild zeigt die Ergebnisse, wenn das zu suchende Element zufällig ist, das zweite Bild zeigt die Ergebnisse, wenn die zu suchenden Elemente der Reihe nach gesucht werden. Suchmethoden: Direct-Access: Hier wird direkt auf table[map[index]] zugegriffen. Wir liegen hier bei teilweise 250 Pikosekunden :-) Robin-Hood Hash Map: Eine selbstgestrickte Hash-Map, die das Robin-Hood Verfahren verwendet. Als Hash-Funktion kommt CRC32 zum Einsatz. Da gibt es teilweise noch Probleme (bei ca. 20000 Bytes) mit Kollisionen, das muss ich mir noch anschauen. Eine gute Referenz ist https://codecapsule.com/2013/11/11/robin-hood-hashing/ AVL-Tree: Adelson Velskii Landis (AVL) Balanced Binary Tree. Standardmethode seit 1962 aus Russland. Erstaunlich viele und komplizierte Spezialfälle, ich möchte es nicht noch mal ausprogrammieren. Einstieg: https://de.wikipedia.org/wiki/AVL-Baum std::map: Verwendent angeblich einen Red-Black Balanced Binary Tree. Wenn da jemand mehr Info hat, dann her damit. std::unordered_map: C++ Hash Tabelle. Leider ist mir da auch nichts genaueres bekannt. Linear-Search: Ist eine einfach for() Schleife. Laut https://dirtyhandscoding.github.io/posts/performance-comparison-linear-search-vs-binary-search.html soll ja lineare Suche bei weniger als ca. 256 Einträgen schneller sein. Das habe ich mit dem Code von jender Seite auch nachvollziehen können. Bei diesen etwas komplexeren Daten hier aber nicht, da muss ich aber noch mehr testen. Bei Fragen kann man das gerne diskutieren und auch ausbauen! Besten Gruss, Udo
Angehängte Dateien:
-

run4_edited.png
15 KB -

run4_lin_edited.png
14 KB
Also ist Direct Access immer schneller lt. deinen Diagrammen.
Ja, da wird ja ohne Suche auf das Element zugegriffen.
Ist auf der x-Achse die "Anzahl" der gesuchten oder durchsuchten Elemente dargestellt? Wie sieht es mit binärer Suche aus?
mh schrieb: > Ist auf der x-Achse die "Anzahl" der gesuchten oder durchsuchten > Elemente dargestellt? > > Wie sieht es mit binärer Suche aus? Die X-Achse ist die Grösse der durchsuchten Elemente in Bytes (Anzahl * Grösse). Da sieht man schön die Cache Effekte. Binäre Suche kommt hoffentlich noch.
Eigentlich sind die Wuerfel schon laengst gefallen. Falls man sich's leisten kann nimmt man Binaersuche. Das Problem ist eher wie kommen die Daten sortiert dort hin wo sie sind.
Pandur S. schrieb: > Eigentlich sind die Wuerfel schon laengst gefallen. Falls man sich's > leisten kann nimmt man Binaersuche. Kannst du das etwas genauer erklären?
Angehängte Dateien:
-

run4.png
20 KB
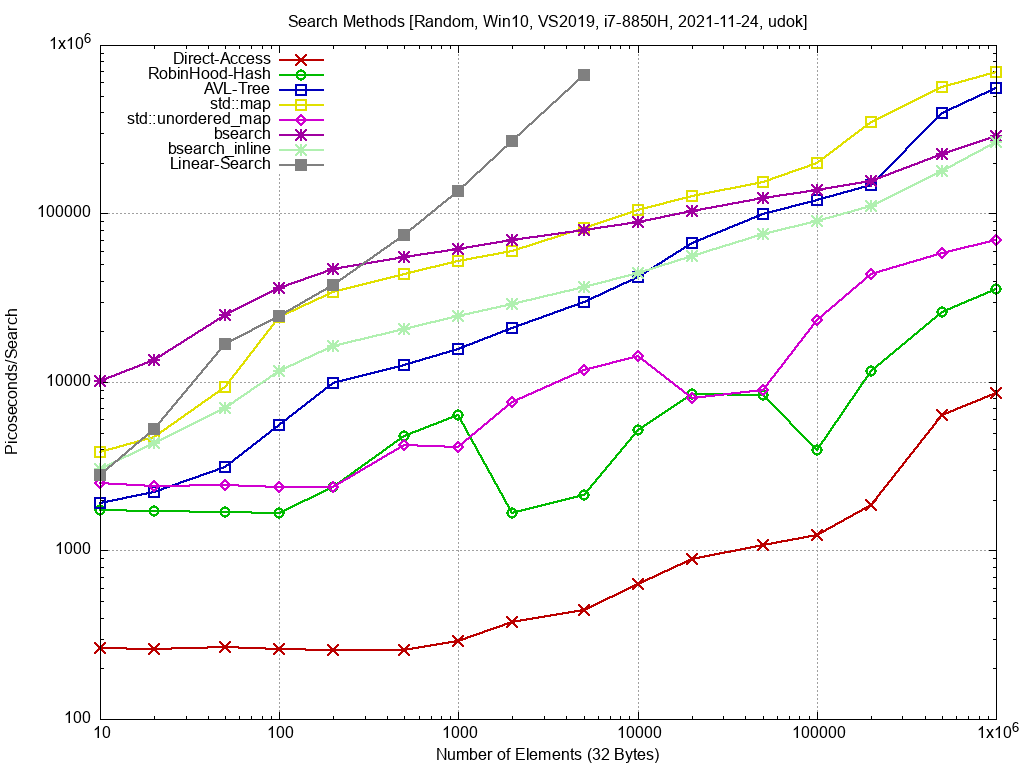
mh schrieb: >> Eigentlich sind die Wuerfel schon laengst gefallen. Falls man sich's >> leisten kann nimmt man Binaersuche. Im Anhang ein Update mit Binärsuche. Die X Achse ist jetzt mit der Anzahl der Elemente skaliert (32 Bytes/Element). Einmal mit der libc bsearch Funktion, und dann noch mit einer inline Version, die aus den Sourcen von BSD 4.3 abgekupfert ist. Gerade bei der hier sehr einfachen Compare Funktion kann die libc bsearch nicht mithalten. Wie macht man in C++ eine binäre Suche, wo man nicht nur gefunden oder nicht gefunden zurückbekommt, sondern den Index des gefundenen Elements (bzw. wer hat sich die kranke std::binary_search einfallen lassen...)? Grüsse, Udo
udok schrieb: > Wie macht man in C++ eine binäre Suche, wo man nicht nur gefunden oder > nicht gefunden zurückbekommt, sondern den Index des gefundenen Elements > (bzw. wer hat sich die kranke std::binary_search einfallen lassen...)? std::lower_bound bzw upper_bound.
Falls du lower/upper_bound testest, kannst du dann zufällig auch teste, ob sich std::find von deiner linearen Suche unterscheidet? (std::find hat das gleiche Interface).
Angehängte Dateien:
-

run4.png
21 KB
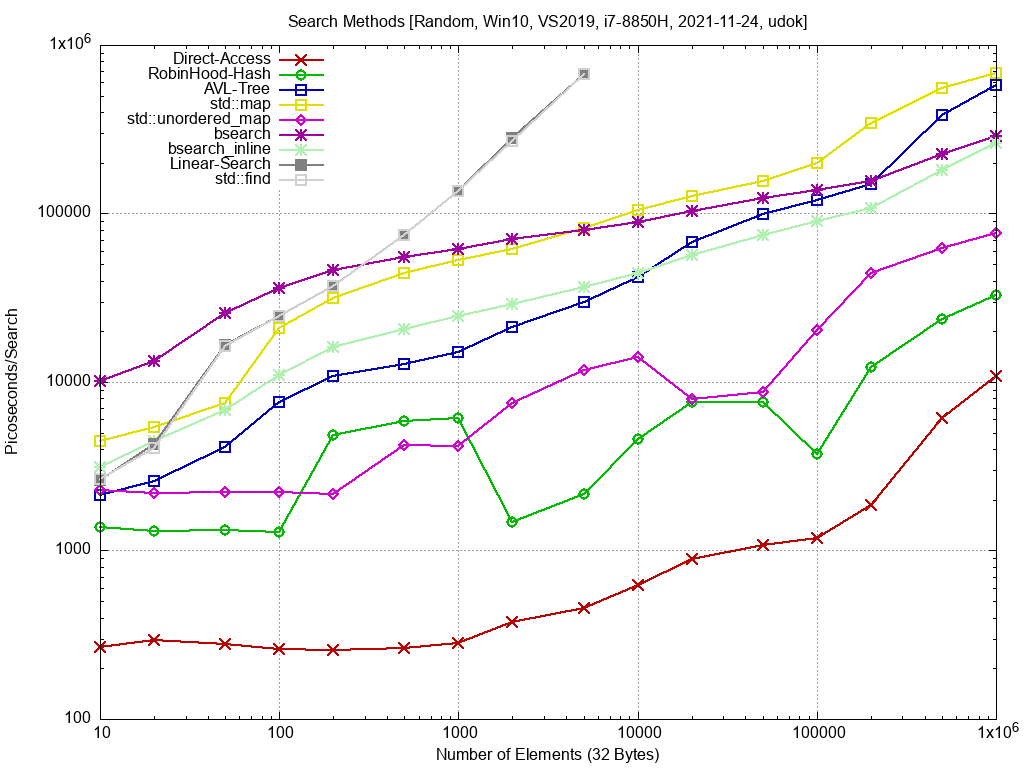
mh schrieb: > Falls du lower/upper_bound testest, kannst du dann zufällig auch teste, > ob sich std::find von deiner linearen Suche unterscheidet? (std::find > hat das gleiche Interface) Ist identisch zur linearen Suche (überdeckt sich mit der for() Schleife). Bild ist im Anhang.
Angehängte Dateien:
-

run4.png
22 KB
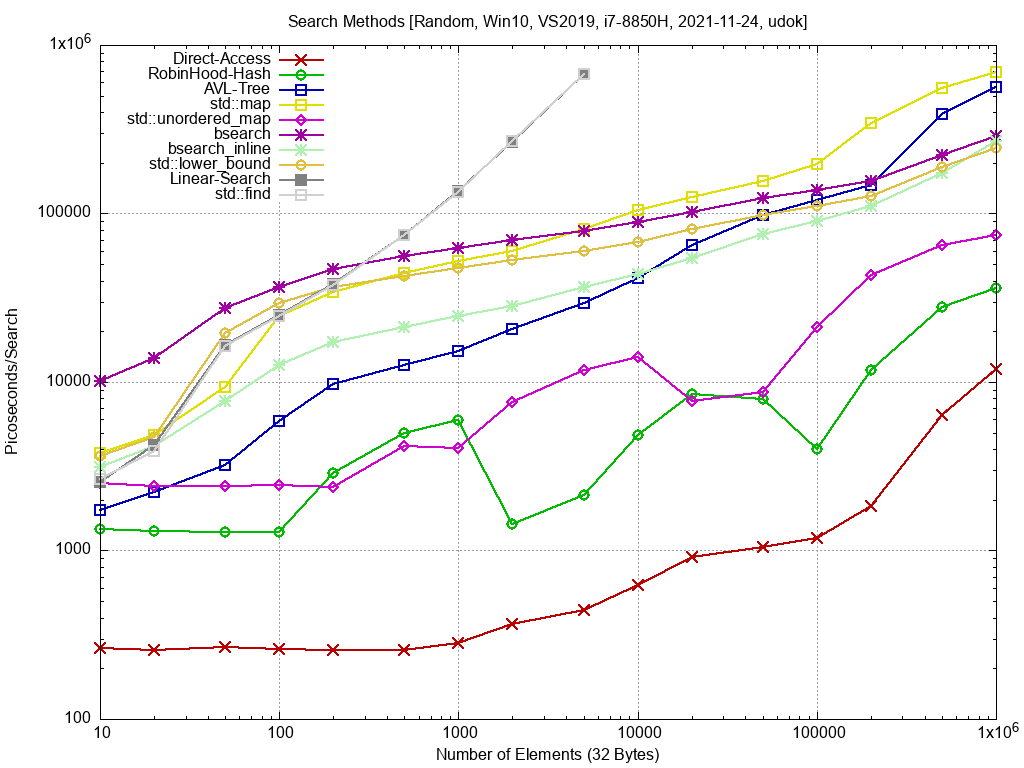
udok schrieb: >> Falls du lower/upper_bound testest Habe ich eingebaut. lower_bound() verhält sich ca. wie bsearch. Bei kleinen Datensätzen ist lower_bound klar im Vorteil.
Angehängte Dateien:
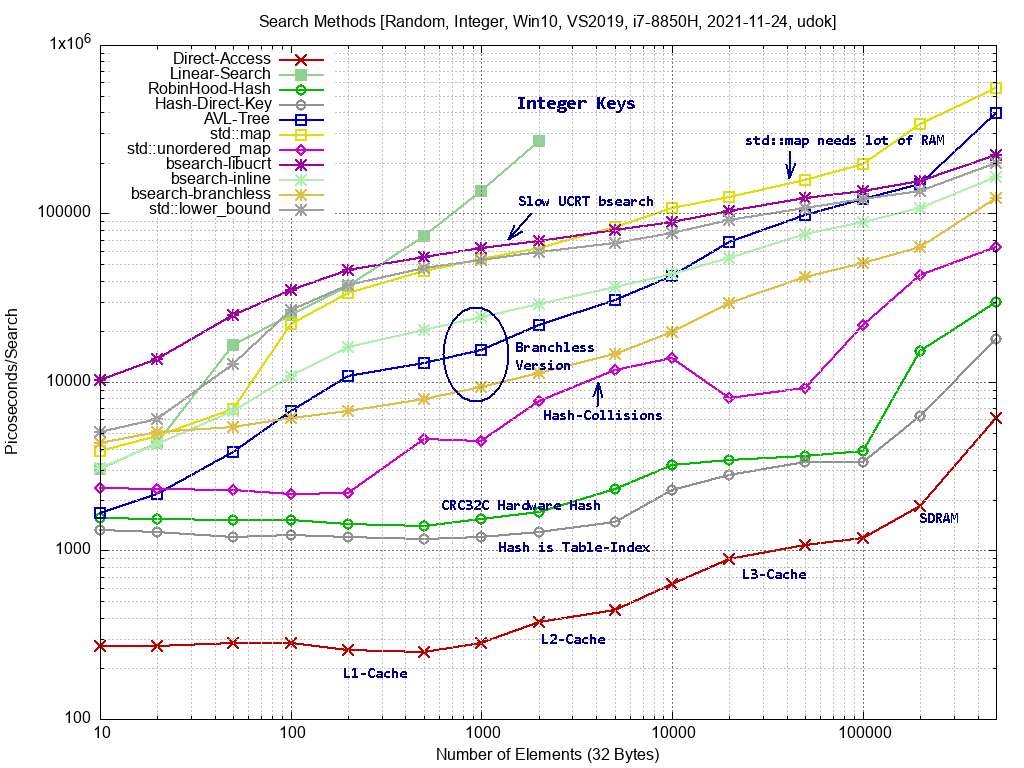
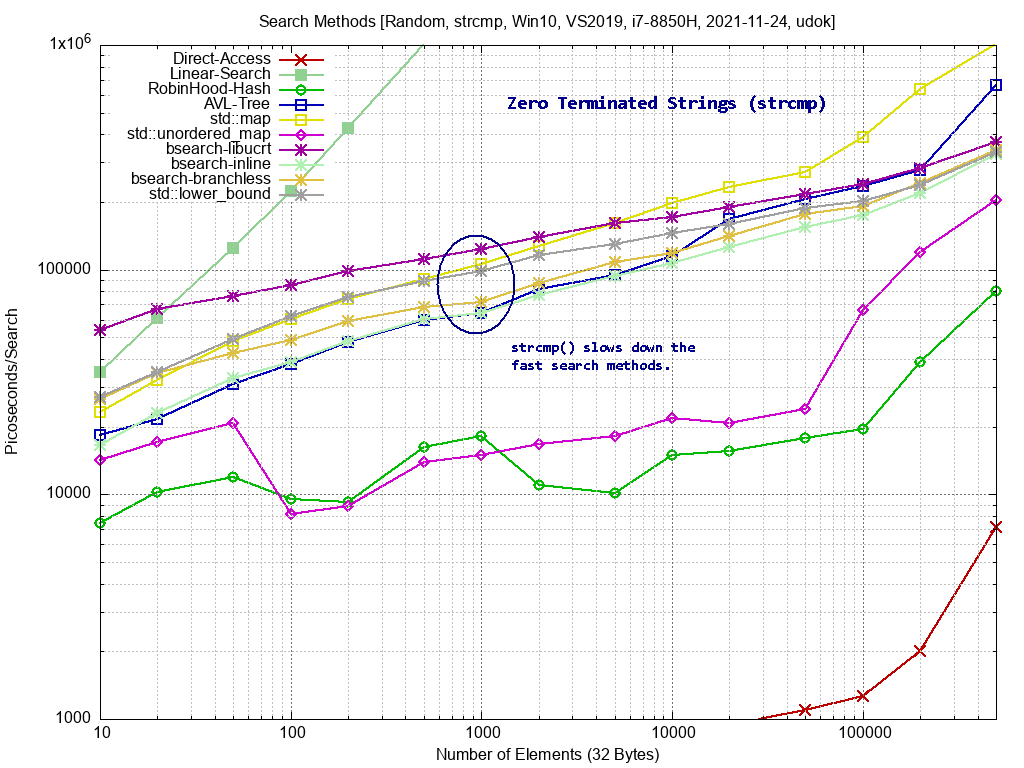
Ich habe noch ein Update des Benchmarks gemacht. Bilder sind wieder im Anhang. Das erste Bild zeigt die Suche nach zufälligen Integer Keys. Hier habe ich einige "branchless" Versionen ausprobiert. Bei den Branchless Versionen wird ein "if-else" durch ein "Conditional-move" ersetzt. Teilweise branchless sind AVL-Baum und bsearch-inline. bsearch-branchless ist komplett branchless, da wird die Suche immer erst nach log2(N) Vergleichen terminiert. Speziell bei den binären Suchmethoden sind die Sprünge recht zufällig und der CPU-Branchprediktor funktioniert damit nicht. Die Conditional-Move Befehle haben das Problem nicht, weil immer derselbe Codepfad ausgeführt wird, und damit die CPU-Pipeline voll bleibt. Das bringt einen beachtlichen Geschwindigkeitsvorteil, sofern die Daten in den L2 Cache passen. Passen die Daten da nicht mehr rein, kann das ein Nachteil werden, weil "spekulative RAM-Read" der CPU auch nicht mehr funktioniert. Das habe ich hier aber nicht gesehen. Das zweite Bild zeigt die Suche nach zufälligen Strings. Da sieht man sehr schön, das in der Praxis die Unterschiede zwischen den Suchverfahren sehr viel kleiner ausfallen, weil die relativ langsame strcmp() Funktion die Zeit dominiert. Einzig die Hash Suchverfahren heben sich positiv heraus, weil die strcmp() Funktion da nur ein einziges Mal ausgeführt wird.
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.