
Um Teilchen mit finiten Elementen zu simulieren (siehe Anhang Grafik) suche ich eine Hardware, die die einfachen Rechnungen Addieren und Division durch 4 für alle Pixel einer Rastergrafik mehrmals nacheinander ausführt und damit einen kurzen Film erzeugt. Für jedes Pixel sind mehrere Zahlen hinterlegt. Bisher kenne ich verschiedene Möglichkeiten: - Auf dem PC mit mehreren Threads (deshalb, um alle Kerne einer CPU zu verwenden) - Mit der AMD Grafik-Karte (dort GPU-Shader, 10x schneller als CPU Kerne) - 64 Bit Zahl in 8 Zahlen mit 15 Bit aufteilen und auf einmal addieren - Möglichkeiten der Einplatinen PCs (Raspi und Odroid), kenne ich noch nicht - Smartphone Technik, kenne ich auch noch nicht, weil es Geld kostet - GPU mieten - Bitcoin HW, kenne ich auch nicht, HW kann teuer werden Bitte, liebes Forum, gib mir Hinweise wie ich für minimierte Kosten diese relativ kleine parallele Rechenaufgabe mit Hardware bearbeiten kann!
Angehängte Dateien:
-

ZuseSpaceSimulation.gif
1,2 MB
Wieso eine besondere Hardware? Das macht man nur wenn ein normaler PC zu langsam wäre. Also, wie lange darf die Berechnung dauern? Hast du es sehr eilig? Welche Auflösung und wie viele Iterationen sind gewünscht? Mach doch mal eine Schätzung wie lange dafür ein normaler Rechner braucht. Ist auch die Frage ob das etwas einmaliges ist oder du da die nächsten Jahre jeden Tag mehrere Videos rechnen möchtest. Für einmalige Dinge lohnt sich das Mieten von Rechenleistung, z.B. bei Amazon.
Notfallseelsorge schrieb: > Wieso eine besondere Hardware? Das macht man nur wenn ein normaler PC zu > langsam wäre. > Also, wie lange darf die Berechnung dauern? Hast du es sehr eilig? > Welche Auflösung und wie viele Iterationen sind gewünscht? Kann ich mich anschliesen. Wievile Mio. Berechnungen pro sekunde benötigst du, dass dir aktuelle CPU mit z.b. 64 Cores dafür nicht ausreichen? Ansonsten kannst du dir überlegen das ganze mit einem /mehreren FPGA/ASIC zu realisieren: - https://de.wikipedia.org/wiki/Field_Programmable_Gate_Array
Irgend W. schrieb: > Ansonsten kannst du dir überlegen das ganze mit einem /mehreren > FPGA/ASIC zu realisieren: Lohnt sich nur wenn man das häufiger machen muss oder selbst die einmalige Aktion irre lange dauert auf normaler Hardware. Kostet auch echt viel Geld.
Claus W. schrieb: > - Mit der AMD Grafik-Karte (dort GPU-Shader, 10x schneller als CPU > Kerne) Es gäbe noch OpenCL. (Aber nur 10x schneller?!? Hast du da noch vsync aktiviert, oder schaufelst du immer alle Daten noch mal hin und her statt transform feedback zu verwenden, oder rechnest du mit hunderten Integern statt floats, oder wie schaffst du das?!?).
Division durch 4 ist Schieben um 2 Bits bei einer geeigneten Zahlendarstellung. Das ist wohl die Domaine von FPGAs. Willst Du keine Hardware anschaffen, könnte eine Amazon F1 Instanz die Lösung sein. Kostet natürlich auch Geld.
Wir wissen doch noch gar nicht welche Rechenlast da anfällt. Vielleicht kann das ein normaler Rechner mit einem eigigermaßen optimiertem Programm in wenigen Minuten bis vielleicht einem Tag rechnen. Und selbst wenn ein PC mal eine Woche rechnen würde, wenn das eine einmalige Angelegenheit ist dann ist das weit billiger als das auf eine Spezialhardware zu portieren. Claus W. schrieb: > 64 Bit Zahl in 8 Zahlen mit 15 Bit aufteilen und auf einmal addieren Klingt fast nach SIMD. Aber egal, wenn das kein Geheimprojekt ist, dann zeig doch mal den Code und beschreibe was du konkret rechnen willst. Damit am abschätzen kann was eine sinnvolle Lösung wäre. Bitoperationen sind in C sehr schnell. In Python hingegen leider nicht. Die Wahl der Sprache kann sehr viel ausmachen.
Angehängte Dateien:
-

000000.png
260 KB
{kind=link}
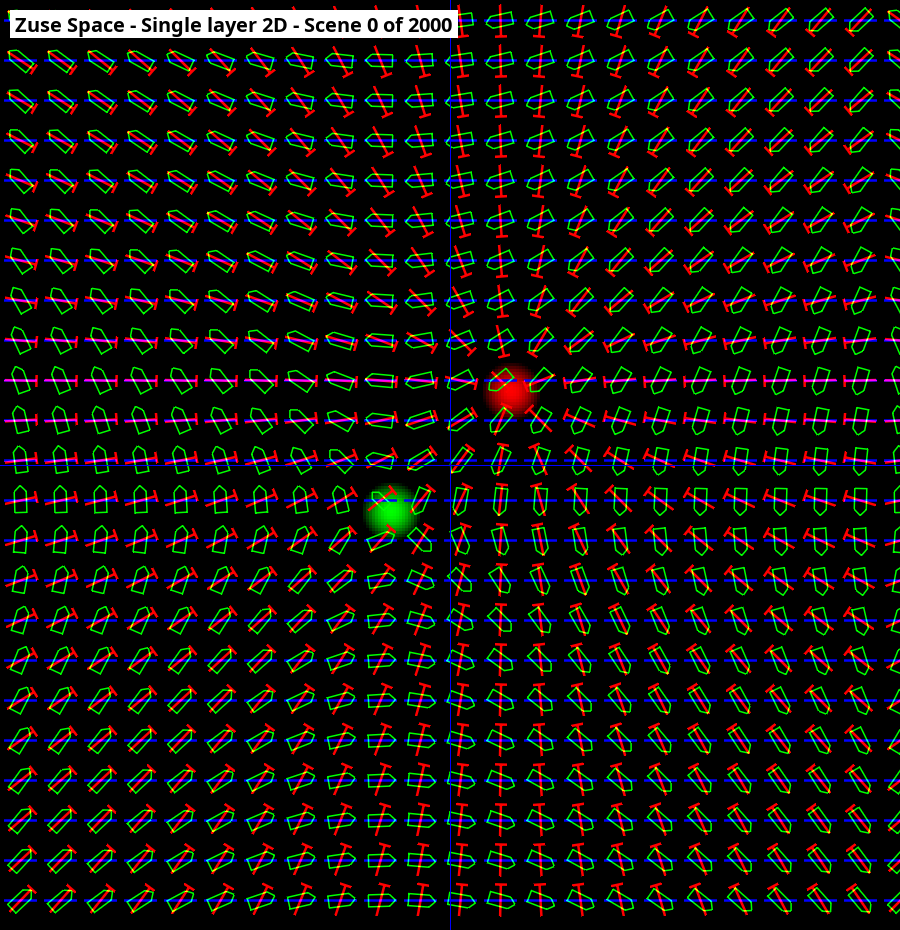
Die Massenrechnung berechnet eine quadratische Fläche von Pixeln mit der Kantenlänge 300px bis 1000px wobei jedes Pixel sechs bis zwölf float32-Variablen enthält. Ich habe es bereits mehrfach rechnen lassen und es braucht z.B. mit der CPU 10 Minuten und mit der GPU 1 Minute. Im Anhang die GPU Kerne für ein Zwischenergebnis. Bislang interessierte sich niemand für den fachlichen Inhalt. Das Python-Skript führt die Init-Kerne einmal aus und danach immer reihum die Iterationskerne. Regelmäßig fragt es den Inhalt der Pixel ab und macht eine Grafikdatei daraus. Mit bisherigen Mitteln kann es passieren, dass ich in etwa 3 Wochen das Ergebnis errate. Es besteht aus einer bestimmten geometrischen Konstruktion der Zeiger (im Bild sichtbar) und deren rechnerischen Wechselbeziehungen. Dann wäre das Rätsel fertig und ich kann damit beginnen, einen erklärenden Text dazu zu schreiben. Es genügte, erst dann Hardware auszusuchen und das Beispiel übersichtlich zu ordnen. Was fehlt an der Sache: - Nicht einfach als Beispielcode zu verteilen, weil woanders nicht die gleiche Grafikkarte vorliegt. Oft Änderungen in den Betriebssystemen um OpenCL anzusteuern. Oder wenn mit CPU: Langsamer als eine standardisierte GPU Lösung sein könnte. - Neue Hardware (z.B. Einplatinen Computer) kamen auf. Nicht sicher, ob derartige Hardware den Büro-PC vielleicht schon überrundet hat. - Warum sind Shader-Prozessoren nur in PC-Grafikkarten verbaut? Warum verkauft niemand ein GPU-Modul, das man über Ethernet ansteuert? Es gibt Artikel über eGPU, aber das sieht aus wie ein PC ohne Monitor. Gibt es Module die auf Parallel-Rechnen spezialisiert sind (ohne Gaming, also leichtgewichtiger)?
Es werden für High Performance Computing (HPC) unterschiedliche Beschleunigerkarten von NVidia, ATI, Intel, ARM hergestellt Teilweise sind sie auf bestimmte Probleme wie Neuronale Netze z.B. optimiert. Du findest diese Karten, wenn Du nach dem Aufbau von aktuellen Supercomputern suchst. Z.B. sowas https://en.m.wikipedia.org/wiki/Nvidia_DGX Das Problem ist, dass solche Karten keine Massenware sind, und deshalb für den Normalanwender unbezahlbar. Dann kamen clevere Leute auf die Idee, dass man ja auch günstige Spielegrafikkarten für sowas verwenden könnte.
Claus W. schrieb: > Bitte, liebes Forum, gib mir Hinweise wie ich für minimierte Kosten > diese relativ kleine parallele Rechenaufgabe mit Hardware bearbeiten > kann! Xilinx Versal FPGAs mit AL cores. Haben wir im Einsatz.
Es gibt auch noch ASICs oder auch noch AVX/SSE - Spielereien oder man kann auch noch mit logischen Operationen addieren, bzw. dividieren und gehen wir man in Richtung Software, da sind pyCuda recht beliebt oder der Haskell-Ghc ganz gut parallel-optimiert. Und: die Literaturliste aus dem Buch von der dritten Auflage" Matrix Computations" von Holub und Loan teils mit Referenzen aus den 50er und 60er Jahren, die ist mit Sicherheit nicht so schlecht zu dieser Thematik.
> Welche Hardware ... für paralleles Rechnen? Variable Lösung, es werden nur kreative Mitarbeiter samt Stühlen gebraucht. (Keine Altersbeschränkung, kein Stromverbrauch.) => http://www.reichstiftung.org/wp-content/uploads/2019/05/Lernferien-Climb-5.jpg Oder, muss noch auf Mehrplatzsystem aufgerüstet werden: https://bilder.2-cpu.de/funny/Ulli%20Stein/ABAKUS.GIF
{kind=link}
{kind=link}
Ne Lupe ginge eigentlich auch- muss man nur bei Sonnenschein in entsprechender Höhe über den Tisch halten, um Antwort A zu provozieren. Allerdings rechnet man da nix, sondern erhöht die Wahrscheinlichkeit für Antwort A, die dann aber analog abgelesen wird. Da ist nichts mehr mit Rechnen oder Digital ;) "Quantencomputing" ist also erstmal ein ziemlich irreführender Begriff.
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.