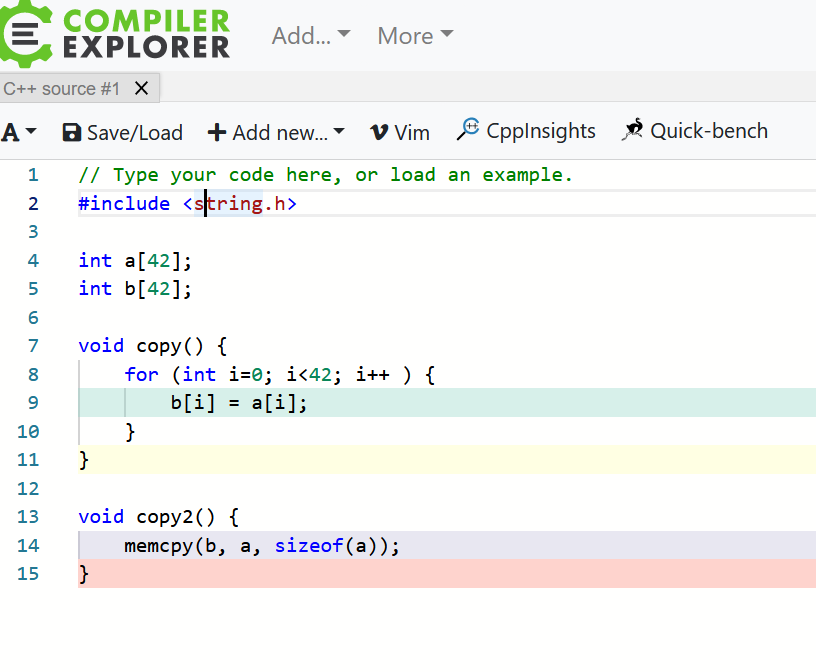
Das ist nicht zwingend schlecht oder ineffizient.
Es besteht eine hohe Wahrscheinlichkeit, dass der Compiler das durch
eine effiziente memcpy-Variante übersetzt.
Die Schleife erspart das möglicherweise falsche Umrechnen der
Array-Größe.
So wie es oben geschrieben ist, "i < a", ist aber nicht gut.
Hier reicht auch nur sizeof(a), weil es wohl Byte-Elemente sind.
Das geht nur, wenn a als Array sichtbar ist und nicht als Pointer
übergeben wurde.
Ist aber alles Egal, memcpy ist der richtige weg und i.d.R. schneller.
Wer sich mal anschauen will, was verschiedene Compiler aus
Codeschnipseln machen, dem empfehle ich mit dem Compiler Explorer ein
bischen rumzuspielen:
https://godbolt.org/
Tilo R. schrieb:> Es besteht eine hohe Wahrscheinlichkeit, dass der Compiler das durch> eine effiziente memcpy-Variante übersetzt.
Nein, diese "Wahrscheinlichkeit" besteht nicht...ich habe es getestet.
Adam P. schrieb:> Tilo R. schrieb:>> Es besteht eine hohe Wahrscheinlichkeit, dass der Compiler das durch>> eine effiziente memcpy-Variante übersetzt.>> Nein, diese "Wahrscheinlichkeit" besteht nicht...ich habe es getestet.
Dann hast du schlecht getestet. Bei mir ersetzen gcc und clang eine
einfach Kopierschleife mit memcpy, wenn die Randbedingugen es zulassen
und es einen Vorteil bringt.
Tilo R. schrieb:> vereinigt imho das schlechte beider Lösungen
?
Es ist die einzige Lösung bisher. Ob nun als #define oder direkt oder
ohne die Division durch die Elementgröße.
Oder was meinst Du? Das nur "a" ein Fehler ist, wurde sofort im
Debugger sichtbar:
Debugger schrieb:> Thomas R. schrieb:>> i < a>> liegt a an Adresse 42?
Mombert H. schrieb:> eine einfach Kopierschleife mit memcpy
Und jetzt teste das nur mal so aus Neugier, gegen einen direkten
einzelnen memcpy Aufruf...
vereint in meinen Augen das Schlechte beider Lösungen:
memcpy hat den Nachteil, dass man sich mit physikalischen Speichergrößen
beschäftigen muss. Wobei das notwendige sizeof(a) aber ziemlich
offensichtlich ist.
Die Schleifen-Variante hat den Nachteil länger zu sein, dafür aber den
Vorteil, sprechend zu sagen wie viele Elemente kopiert werden. "i < 42"
Wenn man jetzt
for(int i = 0; i < sizeof(a)/sizeof(a[0]); i++) schreibt hat man:
* die manuelle Speichergrößenberechnung, aber zusätzlich nachteilig noch
in einem komplizierteren Ausdruck als beim memcpy
* die längere Schleifenvariante, aber zusätzlich sieht man nicht mehr
auf einen Blick wie viele Elemente kopiert werden.
Tilo R. schrieb:> Wenn man jetzt> for(int i = 0; i < sizeof(a)/sizeof(a[0]); i++) schreibt hat man:> * die manuelle Speichergrößenberechnung, aber zusätzlich nachteilig noch> in einem komplizierteren Ausdruck als beim memcpy> * die längere Schleifenvariante, aber zusätzlich sieht man nicht mehr> auf einen Blick wie viele Elemente kopiert werden.
Ja, komplex geht immer.
Aufm 32Bit System könnte man es sogar noch irgendwie dem Compiler
schmackhaft machen erst alle 32Bit durch den Bus zu jagen und dann den
Rest mit Modulo und Einzelbytes.
Evtl. würde das was bringen?
Es kommt drauf an.
Tilo R. schrieb:> Die Schleifen-Variante hat den Nachteil länger zu sein, dafür aber den> Vorteil, sprechend zu sagen wie viele Elemente kopiert werden. "i < 42"
In beiden Fällen muß ich die Länge kennen. Ob ich die jetzt wie bei
memcpy als Parameter übergeben muß oder bei der Schleife mit der
Schleifenvariable vergleiche, ist ziemlich wurscht.
OK...
andere Lösung.
Listen?
Diese als struct aufgebaut.
Man biegt den einen Zeiger auf die andere Adresse und den anderen setzt
man NULL. Fertig.
Das wären 2 Adresszugriffe?
Und durch den Typ des Datenformates, könnte man sogar auf die einzelnen
"Offset" Elemente wieder zugreifen. Wie bei den Linux-Devices.
Sorry, nur ne wirsche Idee, aber könnte man versuchen.
edit:
es geht ja nur um RAM-Adresszuweisungen.
Sebastian schrieb:> Leute!>> sizeof(a)/sizeof(a[0]) kann man verkürzen zu sizeof(a)/sizeof(*a)>> Spart wertvolle Bildschirmtinte!>> LG, Sebastian
Es geht mir nicht um Bildschirmtinte oder Codelänge.
Es geht darum, die Intention des Programmierers dem Leser am klarsten zu
zeigen.
Die kognitive Leistungsfähigkeit von Menschen (Code-Lesern) wird gerne
überschätzt. Jedes Quäntchen zusätzliche Aufmerksamkeit, die in das
Code-Parsen und verstehen, z.B. des Divisions-Ausdrucks, geht, fehlt,
wenn man irgendwann diesen kniffligen Fehler, der sich irgendwo im
Quelltext versteckt, suchen muss.
Ich geb gern zu, dass ich da etwas pedantisch bin und das vielleicht
auch manchmal übertreibe.
Aber genau so Vorschläge wie das hier
Adam P. schrieb:> Aufm 32Bit System könnte man es sogar noch irgendwie dem Compiler> schmackhaft machen erst alle 32Bit durch den Bus zu jagen und dann den> Rest mit Modulo und Einzelbytes.> Evtl. würde das was bringen?
erschweren die Lesbarkeit maximal und bringen - wenn überhaupt - einen
minimalen Performance-Vorteil.
Idiomatisches Programmieren: Man sollte so programmieren, "wie man das
in der entsprechenden Sprache macht".
Man schreibt nicht "for (int i=1; i<=10; i++)" um irgendwas 10 mal
wiederholen. Auch nicht "(int i=0; i<=9; i++)". Und erst recht vermeidet
man Tricks mit Pre- und Post-Inkrement.
Man schreibt "for (int i=0; i<10; i++)".
Letzteres ist (in C) idiomatisch und wird vom geübten Leser verstanden
ohne dass er jeden einzelnen Buchstaben lesen muss.
Tilo R. schrieb:> Idiomatisches Programmieren: Man sollte so programmieren, "wie man das> in der entsprechenden Sprache macht".
Ja ich gebe dir da 100% recht, DANKE.
Jedoch verlangte der TO anscheinend nach einer Formel die weder
"memcpy" noch "for" erwartet.
Ich habe um die Ecke gedacht und JA:
Tilo R. schrieb:> erschweren die Lesbarkeit maximal und bringen - wenn überhaupt - einen> minimalen Performance-Vorteil.
Da gebe ich dir Recht! Aber kann auf einem embedded system
funktionieren...wollte nur eine Idee präsentieren, habe die Laufzeit
nicht gemessen ;)
edit:
Aber danke den Troll @WauWau!
Wir kommen echt auf Ideen wie man es besser machen könnte :-D
Kaum zu glauben, dass das mal passiert.
Also ganz ehrlich,
ich mag jüngere Menschen die sich für Technik interessieren!
Und ich bin der letzt, der ihnen nicht helfen würde...sogar sehr
gerne...
Aber das artet hier so langsam aus.
Ich habe hier durch das Forum schon vielen geholfen, aber das ist doch
nur noch ein Kindergarten hier...
Sorry für diese Worte, aber das ist grad ein perfektes Bsp.
edit:
Klar ..."WIR" diskutieren wild usw. und suchen die beste Lösung,
(SUPER) wir bleiben im Training, aber das ist doch kacke!
Es gibt Schüler oder andere die es wirklich lernen möchten.
Was ist wenn diese als Trolls angesehen werden, das ist auch Müll.
Doch da muss man eine Lösung finden. SORRY.
edit die #2:
Kann gelöscht werden, wenn nötig, doch es geht ums Prinzip. Wenn man um
Hilfe bittet, sollte es echt sein und dann wird auch geholfen!
Adam P. schrieb:> Tilo R. schrieb:>> Es besteht eine hohe Wahrscheinlichkeit, dass der Compiler das durch>> eine effiziente memcpy-Variante übersetzt.>> Nein, diese "Wahrscheinlichkeit" besteht nicht...ich habe es getestet.
"eine effiziente memcpy-Variante" heißt nicht unbedingt, dass da nachher
ein "call memcpy" im Assembler steht.
Tilo R. schrieb:> Wenn man jetzt> for(int i = 0; i < sizeof(a)/sizeof(a[0]); i++) schreibt hat man:> * die manuelle Speichergrößenberechnung, aber zusätzlich nachteilig noch> in einem komplizierteren Ausdruck als beim memcpy> * die längere Schleifenvariante, aber zusätzlich sieht man nicht mehr> auf einen Blick wie viele Elemente kopiert werden.
Man sieht auf einen Blick, dass alle Elemente kopiert werden. Diese
Information bringt mir meistens mehr als das Wissen, dass das jetzt
gerade 42 Stück sind.
Zugegebenermaßen ist die Schreibweise nicht sonderlich schön, aber wer
schon ein paar Tage mit C programmiert hat, erkennt diesen Konstrukt
schnell wieder.
Adam P. schrieb:> Aufm 32Bit System könnte man es sogar noch irgendwie dem Compiler> schmackhaft machen erst alle 32Bit durch den Bus zu jagen und dann den> Rest mit Modulo und Einzelbytes.> Evtl. würde das was bringen?>> Es kommt drauf an.
Das sind genau die Dinge, um die sich dann er Optimizer kümmert. gcc hat
da recht ausgeklügelte Mechanismen, um ein memcpy möglichst effizient zu
gestalten. Gerade weil es drauf ankommt, will ich das nicht explizit in
meinen Code schreiben.
Sebastian schrieb:> Leute!>> sizeof(a)/sizeof(a[0]) kann man verkürzen zu sizeof(a)/sizeof(*a)>> Spart wertvolle Bildschirmtinte!
Man kann es sogar verkürzen zu sizeof a/sizeof*a
Tilo R. schrieb:> ch weiß dass man manchmal tricksen muss und Code nicht immer schön sein> kann.
Thilo, es ist nicht klar, ob Du Anfänger bist oder ob Dein erster Post
ein Versehen war.
Es gibt 3 Möglichkeiten, hier eine arraygröße anzugeben:
* als Magic number (42)
* als Define (sprechender Name)
* als countof bzw. sizeof (memcpy)
Magie number funktioniert zwar, ist aber nicht wartbar. D.h. wenn ich
die arraygröße ändere, muss ich alle verwndungen finden und ändern.
Beim define muss ich darauf achten, das richtige zu nehmen. Für einen
Anfänger ist das egal, der sagt: ich muss sowieso immer aufpassen. Wenn
ich einen Fehler mache, ...
Es ist gut, bedeutet aber 2 Namen zusammen zu halten wo einer
ausreicht.(o.t.: ja, gängige Metrik sagen, dass der ein guter felderherr
sei, der zwei Token braucht, wo bisher einer war)
Was halt gar nicht geht ist die von Dir zitierte Form i<a.
Dass Magic numbers hässlich sind ist klar (das war nur als Beispiel
hingeschrieben).
Ich bin kein Anfänger mehr, ich war >10 Jahre Softwareentwickler
(diverse Sprachen, auch C, C++), dann noch etliche Jahre
Pentester/Security-Berater, wo ich gelegentlich auch Code-Audits gemacht
habe.
So eine Magic-Number wäre ein Finding gewesen.
Adam P. schrieb:> Mombert H. schrieb:>> eine einfach Kopierschleife mit memcpy> Und jetzt teste das nur mal so aus Neugier, gegen einen direkten> einzelnen memcpy Aufruf...
Ja ... und was willst du sagen?
Für Array-Größen habe ich mir angewöhnt, eigentlich immer irgendwo ein
Makro zu definieren, das wie hier beschrieben mit der Division der
beiden sizeofs (Gesamtarray durch Arraygröße) berechnet. Als Makro mit
sizeof-Operatoren braucht es keinerlei zusätzliche Laufzeit, da der
Compiler den Wert schon berechnen und einsetzen kann, wodurch sich das
Kompilat nicht von einer magic number, egal ob direkt geschrieben oder
per #define irgendwo festgelegt, unterscheidet.
Und ein
1
for(inti=0;i<ARRAY_SIZE(my_array);i++)
ist meines Erachtens selbst ohne nachzuschauen, wie genau ARRAY_SIZE
definiert ist, intuitiv erfassbar. Ich iteriere über alle Elemente des
Arrays.
Klar, wenn ich irgendwo das Array nur als Pointer übergebe, klappt das
nicht mehr - aber da gibt es keine Alternative zur expliziten
zusätzlichen Längenangabe (die dann aber auch das ARRAY_SIZE-Makro
verwenden kann). ;-)
Mombert H. schrieb:> Adam P. schrieb:>> Mombert H. schrieb:>>> eine einfach Kopierschleife mit memcpy>> Und jetzt teste das nur mal so aus Neugier, gegen einen direkten>> einzelnen memcpy Aufruf...> Ja ... und was willst du sagen?
Das selbe, was ich oben geschrieben habe:
Rolf M. schrieb:> "eine effiziente memcpy-Variante" heißt nicht unbedingt, dass da nachher> ein "call memcpy" im Assembler steht.
und
> gcc hat da recht ausgeklügelte Mechanismen, um ein memcpy möglichst> effizient zu gestalten.
Sprich: memcpy führt zumindest im Falle von gcc nicht einfach zu einem
Funktionsaufruf, sondern ist im Compiler selbst umgesetzt, so dass er es
möglichst gut auf den jeweiligen Fall optimieren kann. Das heißt, dass
du im generierten Assembler-Code nicht mehr so leicht erkennen kannst,
dass das jetzt ein memcpy ist. Wenn du nun den Code, der aus dieser
Schleife generiert wird mit dem aus einem memcpy vergleichst, stehen die
Chancen gut, dass der Code identisch ist. Das wurde oben aber auch schon
erwähnt:
Tilo R. schrieb:> Der AVR GCC und viele andere Compiler auch werfen exakt den selben> Binärcode aus.
Rolf M. schrieb:> Mombert H. schrieb:>> Adam P. schrieb:>>> Mombert H. schrieb:>>>> eine einfach Kopierschleife mit memcpy>>> Und jetzt teste das nur mal so aus Neugier, gegen einen direkten>>> einzelnen memcpy Aufruf...>> Ja ... und was willst du sagen?>> Das selbe, was ich oben geschrieben habe:> [...]
Das ist das, wass passiert. Aber ist das das, was er sagen wollte? Ich
habe ihn anders verstanden. Deswegen hatte ich nochmal nachgefragt.
Tilo R. schrieb:> Der AVR GCC und viele andere Compiler auch werfen exakt den selben> Binärcode aus.Mombert H. schrieb:> Dann hast du schlecht getestet. Bei mir ersetzen gcc und clang eine> einfach Kopierschleife mit memcpy, wenn die Randbedingugen es zulassen> und es einen Vorteil bringt.
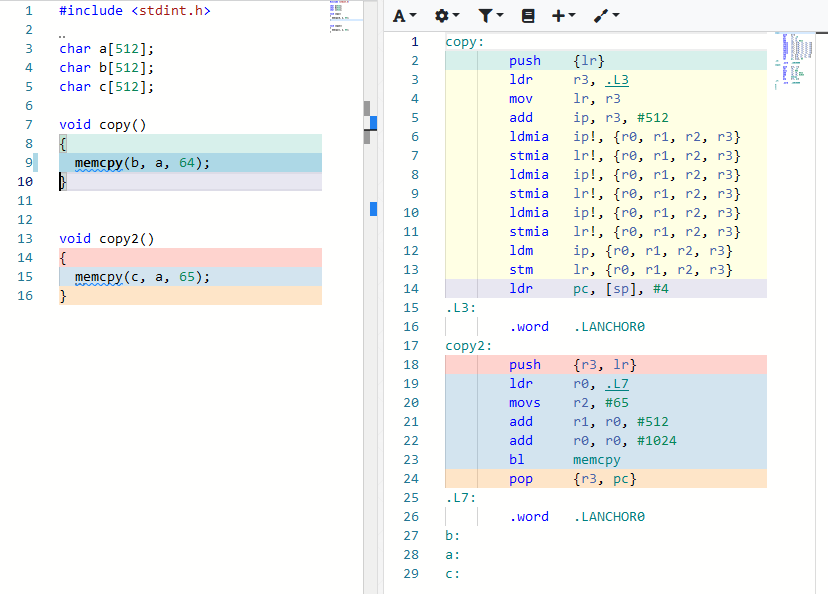
geht auch umgekehrt. Bei wenigen (<=64) Bytes die zu kopieren sind wird
selbst memcpy durch direktes Kopieren ersetzt.
temp schrieb:> geht auch umgekehrt. Bei wenigen (<=64) Bytes die zu kopieren sind wird> selbst memcpy durch direktes Kopieren ersetzt.
Was hier durch was ersetzt wird, ist Ansichtssache. Jedenfalls ist der
von dir gezeigte Assembler-Code keine Schleife mit 64 Durchläufen, die
die Daten byteweise kopiert.
Was man allgemein sagen kann: Er erkennt in so einem Fall die
for-Schleife als etwas, das einen Speicherblock kopieren soll und setzt
dann den Code ein, den er an der Stelle zum Kopieren eines Block dieser
Größer für am besten erachtet. Das gleiche passiert auch, wenn man ein
memcpy hinschreibt.
Apollo M. schrieb:> struct {byte a[42];} a;
Für mich macht bei Array nur noch ein struct Sinn, weil
Typ unabhängig und der Compiler alles weitere optimal erledigt.
Das kann keine Variante die hier diskutiert wurde leisten und noch
besser als b=a gehts hins. Lesbarkeit auch nicht!
Aus b=a macht gcc v11, wäre das size/time optimal?
ldi r24,lo8(42)
movw r30,r28
adiw r30,43movw r26,r28
adiw r26,1
0:
ld r0,Z+
st X+,r0
dec r24
brne 0b
Apollo M. schrieb:> Für mich macht bei Array nur noch ein struct Sinn, weil> Typ unabhängig und der Compiler alles weitere optimal erledigt.
Ja, das Kopieren ganzer Strukturen ist toll. Ich würde mir dafür aber
nicht den Code verbauen. Zumal ich komplette Arrays ganz selten kopiere.
Sobald eine Funktion Array und Größe bekommt, nützt Dir die Struktur
nichts (zumindest in C. In C++ schon eher).
Rolf M. schrieb:> Was hier durch was ersetzt wird, ist Ansichtssache. Jedenfalls ist der> von dir gezeigte Assembler-Code keine Schleife mit 64 Durchläufen, die> die Daten byteweise kopiert.
das hat niemnd behauptet.
> Was man allgemein sagen kann: Er erkennt in so einem Fall die> for-Schleife als etwas, das einen Speicherblock kopieren soll und setzt> dann den Code ein, den er an der Stelle zum Kopieren eines Block dieser> Größer für am besten erachtet. Das gleiche passiert auch, wenn man ein> memcpy hinschreibt.
welche for Schleife? Ich habe da 2 x memcpy im Code. Dein Text past
vielleicht zu anderen Posts aber nicht zu meinem.
Adam P. schrieb:> Tilo R. schrieb:>> Wenn man jetzt>> for(int i = 0; i < sizeof(a)/sizeof(a[0]); i++) schreibt hat man:>> * die manuelle Speichergrößenberechnung, aber zusätzlich nachteilig noch>> in einem komplizierteren Ausdruck als beim memcpy>> * die längere Schleifenvariante, aber zusätzlich sieht man nicht mehr>> auf einen Blick wie viele Elemente kopiert werden.>> Ja, komplex geht immer.>> Aufm 32Bit System könnte man es sogar noch irgendwie dem Compiler> schmackhaft machen erst alle 32Bit durch den Bus zu jagen und dann den> Rest mit Modulo und Einzelbytes.> Evtl. würde das was bringen?>> Es kommt drauf an.
Nach Art von Duff's Device:
1
size_t count = sizeof(a) / sizeof(a[0]);
2
size_t n = count / 4;
3
switch(count % 4)
4
{
5
case 0:
6
do
7
{
8
count--;
9
b[count] = a[count];
10
case 3:
11
count--;
12
b[count] = a[count];
13
case 2:
14
count--;
15
b[count] = a[count];
16
case 1:
17
count--;
18
b[count] = a[count];
19
}
20
while(n-->0);
21
}
Duff nutze dies für ein ähnliches Problem: musste 1983 in memory-mapped
I/O kopieren, die Schleife war in seinem Programm performanzkritisch,
und wurde von dem verwendeten Compiler nicht automatisch abgerollt. Er
kopierte damals acht Elemente pro Schleifendurchlauf.
A. S. schrieb:> Ich würde mir dafür aber> nicht den Code verbauen.
Wie das den?
A. S. schrieb:> Zumal ich komplette Arrays ganz selten kopiere.
Hast du auch an löschen oder alle Werte auf default setzen gedacht?
Gefühlt macht hier jeder zweit eine for Schleife, um seinen Buffer zu
löschen oder zu initialisieren, was suboptimal ist!
Es geht besser mit struct z.B. ... zeigt mal echte Alternativen dazu!
#define DEFAULT_VAL (10,11,12,13,14,15,16,17,18,19) //or enum
struct {unit8_t val[10];}
para= {DEFAULT_VAL}, //initial parameter setting
para_default= {DEFAULT_VAL}, //to set back on default
para_zero= {0}, //to zero all parameter
para_new= {0,1,2,3,4,5,6,7,8,9};
para= para_new; //new parameters
para= para_default; //re-init on default values
para= para_zero; //delete anything
A. S. schrieb:> Ich würde mir dafür aber> nicht den Code verbauen.
Wohl eher eine schwache Behauptung, ich muss lediglich noch minimal zwei
Zeichen mehr im Bezeichner aufwenden.
statt buf[13], dann halt x.buf[13] oder buf.x[13] oder wo soll hier das
Hindernis sein?!
Apollo M. schrieb:> Hast du auch an löschen oder alle Werte auf default setzen gedacht?
Das sind bei mir eher Dinge, für die ich eine Struktur nutze, kein
Array. Die verwende ich eher für Speicher, Konstanten (CRC, Character
Bitmaps, ...), Berechnungen, Listen (die aber dann verschieden lang
sind), ...
Für Parameter (was Dein Name suggeriert) verwende ich eher konkrete
Namen (in Strukturen), keine Arrays mit Enum. Oder wieder verschieden
lange Listen. Und ja, das sieht mit Structs dann genauso aus wie bei Dir
mit Array.
A. S. schrieb:> eher konkrete> Namen (in Strukturen), keine Arrays
So ist auch mein Ansatz, sinnige Bezeichner sind immer besser als
informationlose Kommentare, die leider allzu oft vorliegen und array war
hier nur der Einstieg.
Alle verwendeten Parameter in einen Container/Array reinlegen, war nur
ein Beispiel und macht für mich auch wenig Sinn.
Apollo M. schrieb:> Hast du auch an löschen oder alle Werte auf default setzen gedacht?>> Gefühlt macht hier jeder zweit eine for Schleife, um seinen Buffer zu> löschen oder zu initialisieren, was suboptimal ist!
Nein. Es ist ok eine Schleife hinzuschreiben. Mit allergrößter
Wahrscheinlichkeit wird das vom Compiler in effizienten Code
umgewandelt.
C ist kein Makro Assembler. Auch wenn es sich so anfühlt, man
programmiert nicht wie der Computer irgendwas erledigen soll, sondern
was das Ziel ist. Generationen von Compiler-Bauern haben Mühe
investiert, das Ziel möglichst gut zu erkennen und den effizientesten
Binärcode dorthin auszugeben.
Ich verweise dazu auf folgendes Video:
What Everyone Should Know About How Amazing Compilers Are - Matt Godbolt
[C++ on Sea 2019]
https://www.youtube.com/watch?v=w0sz5WbS5AM
Man kann nicht wissen, welche Variante schneller ist (Array vs. struct,
for vs. memcpy). Im Einzelfall, auf vorgegebener Architektur und
vorgegebenem Compiler kann man es ausprobieren und weiß das dann. Für
diesen Spezialfall.
Schon mit der nächsten Compilerversion, oder anderen Flags, kann es
anders aussehen. Im dümmsten Fall verkehrt sich die händische
Optimierung ins Gegenteil.
Wenn man wirklich die drei Zeilen Code identifiziert hat, die absolut
zeitkritisch sind, und wo es scheinbar auf jeden CPU-Cycle ankommt,
dann:
* hat man in der Regel vorher was falsch gemacht (z.B. ineffizienter
Algorithmus, Premature Optimization, zu kleine CPU...)
* schafft man mit "händisch optimiertem C-Code" leicht eine schwer
wartbare, fragile technische Schuld
* sollte man über eine Inline-Assembler-Lösung nachdenken. Das ist zwar
auch nicht schön, aber weniger fragil als die C-Lösung.
Man sollte immer im Hinterkopf haben, dass es in C über 100 "undefined
behaviours" gibt. Das ist Code, bei dem die C-Spezifikation nicht
vorgibt, was rauskommt. Paradebeispiel ist hier der signed overflow.
I.d. Regel funktioniert das wie erwartet. Das kann man auch testen.
Manche Optimierung nutzt genau sowas aus.
Beispiel:
1
inti=10;// signed!
2
do{
3
...
4
i++;
5
while(i>0)// Intention ist hier der Schleifenabbruch wenn i überläuft. Ich behaupte nicht dass das besonders performant oder clever ist, der Code soll nur als Beispiel dienen.
Der Compiler darf davon ausgehen, dass kein undefined behaviour genutzt
wird. Er könnte beliebigen Code ausgeben. I.d. Regel wird das aber der
normale increment-Befehl sein, der in der CPU genau so überläuft wie wir
das erwarten und der Code funktioniert.
Dem Compilerbauer steht es frei, unter der Annahme, dass kein undefined
behaviour genutzt wird, Optimierungen zu machen. Im obigen Beispiel
könnte der Compiler erkennen, dass i >0 initialisiert und nur
inkrementiert wird. Demzufolge kann die Prüfung am Schleifenende
entfallen. Und wenn i nie ausgewertet wird kann man die Variable
vielleicht sogar ganz entfernen.
Das Problem ist, dass diese (validen) Optimierungen in späteren
Compilerversionen dazu kommen können. Getesteter, jahrelang
funktionierender Code hat dann schwer zu findende Fehler, weil damals
ein Entwickler clever sein wollte.
Etwas Lesestoff zu Undefined Behaviour:
https://raphlinus.github.io/programming/rust/2018/08/17/undefined-behavior.html
(Bei allen anderen Überlegungen, sinnigen Bezeichnern in structs etc.,
bin ich natürlich voll eurer Meinung)
Tilo R. schrieb:> Wenn man wirklich die drei Zeilen Code identifiziert hat, die absolut> zeitkritisch sind, und wo es scheinbar auf jeden CPU-Cycle ankommt,> dann:> […]> * schafft man mit "händisch optimiertem C-Code" leicht eine schwer> wartbare, fragile technische Schuld> * sollte man über eine Inline-Assembler-Lösung nachdenken. Das ist zwar> auch nicht schön, aber weniger fragil als die C-Lösung.
Hier bin ich gegenteiliger Ansicht. Der händisch optimierte C-Code, so
Standard-C-Code ist, ist meiner Meinung nach dem Assemblercode
vorzuziehen:
Der C-Code ist immerhin portabel, so dass er auch auf zukünftigen
Systemen mit anderer Architektur einsetzbar ist. Das gilt für den
Assemblercode nicht. Möglicherweise erfüllt die händische Optimierung
ihren Zweck dort nicht, aber wenn das neue System schneller ist, kann es
die Aufgabe dennoch erledigen.
Das Wartbarkeitsproblem gibt es zwar, aber es ist deutlich kleiner als
es bei Assemblercode wäre.
So ein Duff's Device-artiger Code, wie ich ihn oben postete, ist sicher
nicht die verständlichste Art ein Array zu kopieren. Aber dennoch für
C-Programmierer deutlcih besser verständlich (auch wenn ich hoffe, dass
jeder, der solchen C-Code schreibt, ihn gut kommentiert), als der
äquivalente Assemblercode für eine potentiell unbekannte Architektur.
Tilo R. schrieb:> C ist kein Makro Assembler. Auch wenn es sich so anfühlt, man> programmiert nicht wie der Computer irgendwas erledigen soll, sondern> was das Ziel ist. Generationen von Compiler-Bauern haben Mühe> investiert, das Ziel möglichst gut zu erkennen und den effizientesten> Binärcode dorthin auszugeben.
Was haben deine langen Ausführungen mit dem Thema noch gemeinsam?
Ich sehe hier eher ein Problem hins. Gewohnheiten und unvollständigen
Kennnissen bzgl. dem aktuellen Sprachumfang in C.
Was z.B. auch hins. anonymous struct, compound literals oder statement
expressions gilt, da diese hier quasi keiner verwendet, selten versteht
und praktisch die Vorteile unbekannt sind.
Lit. dazu wäre das Buch "21st Century C" von Ben Klemens, liegt als pdf
hier libgen.rs rum.
Ein array in struct ist immer noch ein array und die geliebte for
Schleife kann auch weiterhin angewendet werden. Nur gibt es kürzere und
sinnvolle Wege nach Rom und die Möglichkeiten mit struct gehören dazu.
Zu beachten wäre auch, der Pre-Compiler ist fester Bestandteil der
Sprachdefinition von C und nicht irgendein Anhängsel.
udok schrieb:> Ich packs nicht mehr. Knapp 50 Posts für so einen Firlefanz!
Geht mir genauso. (Endlich spricht es mal jemand aus ;-) )
Die Frage wurde spätestens im 4. Beitrag von Teo D. beantwortet. Da der
TO sich nicht mehr gemeldet hat, war das wohl auch für ihn hinreichend
geklärt.
Andreas B. schrieb:> Die Frage wurde spätestens im 4. Beitrag von Teo D. beantwortet
Leider nein. Hast Du den Link gelesen? Da wurde ein String (!) als
Beispiel für memcpy genommen, mit strlen statt sizeof oder n.
Dann Lösungen mit a statt sizeof a oder structs um die Arrays herum.
Wer ein Array kopiert und dazu fragt, ist vermutlich ein Anfänger. Warum
sollte er sich wieder melden, wenn die ersten Lösungen zum Absturz oder
am Thema vorbei führen?
Andreas B. schrieb:> Die Frage wurde spätestens im 4. Beitrag von Teo D. beantwortet.
Ahoi, dann hast du ja wieder richtig viel nicht verstanden und kannst
jetzt ungestört weiter machen mit Basic in Kombination/Verwendung mit C
Syntax.
A. S. schrieb:> Hast Du den Link gelesen?
Zugegebenermaßen nicht.
A. S. schrieb:> Warum> sollte er sich wieder melden, wenn die ersten Lösungen zum Absturz oder> am Thema vorbei führen?
Gerade dann würde er sich wieder melden. Die Länge hatte er ja schon
direkt angegeben. Das einzige Problem wäre, ob er das element[0]
mitgezählt hat.