Ich bin gerade dabei eine 40Msps single point DFT zu implementieren und würde gerne nach eurer Einschätzung fragen ob es sinnvoll ist die Multiplikation in einer Pipeline zu machen. Die DFT soll gepipelined sein mit 3 Stufen: Lookup table für sinus/cosinus, Multiplikation und Addition. Im Moment benutze ich die enclustra fixed point library.
Schau doch nach ob du den Takt schaffst. Pipeline kostet Ressourcen, Takt Leistungsaufnahme. Je nachdem auf was du optimieren willst solltest du entscheiden.
Frederic W. schrieb: > ob es sinnvoll ist die > Multiplikation in einer Pipeline zu machen. Da wird wohl kein Weg dran vorbei führen, weil es keine 32x32 Multiplier gibt, sondern die binomisch kaskadiert werden (müssen). D.h. das tool wird das von sich aus tun und dir dann erklären, ob das das mit 40MHz noch packt. Beim Spartan 3 kann das noch gehen. Es gibt aber noch mehr zu betrachten: Mal angenommen, deine DFT arbeitet mit einem Kanal, wird es dann wohl ein 40MHz Datentakt sein. Wenn sonst nichts dagegen spricht, sollte man auch den Systemtakt mit 40MHz fahren. Ob das mit den kaskadierten MULs klappt, hängt vom FPGA ab. Wie gesagt sind 40MHz beim Spartan 3/e§ kaum ein Problem, allerdings müssten da ohnehin FFs hinter den MUL. Ein Artix z.B. kriegt das mit einem Zusatztakt hin. Zusammen mit ein- und ausschreiben also maximal 2 Takte extra. Hingegen mit einem hohen Systemtakt von z.B. 160 MHz (für 4 DFT-Kanäle im Multiplex) wird das nicht mehr gehen. Da braucht jeder MUL einen Takt vorne und 2 dahinter, je nach Folgestufe. Macht dann nach Adam Ries 6+2=8. Wäre dann aber durchaus noch schneller, als die 40er-Lösung. Die letzliche Lösung und der MUL-Verbrauch hängt auch ein wenig vom Tool und den constraints ab: Wenn der Takt niedrig genug ist, dann spart er bei den AREA-orientierten Implementierungen auch durchaus einen MUL weg und baut Logik drum herum um. Das macht so bis etwa 80MHz-100MHz noch Sinn, wenn (a + x) * b gerechnet wird und x<<25. Allerdings haben moderne FPGAs so arg viele MULs dass das kaum noch was bringt.
Was prinzipiell passiert ist die ADC Daten erst zu fenstern und dann a = a + x*b zu berechnen wobei b aus einer lookup table kommt. Die Frage ist nur wie man die Multiplikation aufteilen kann.
Angehängte Dateien:
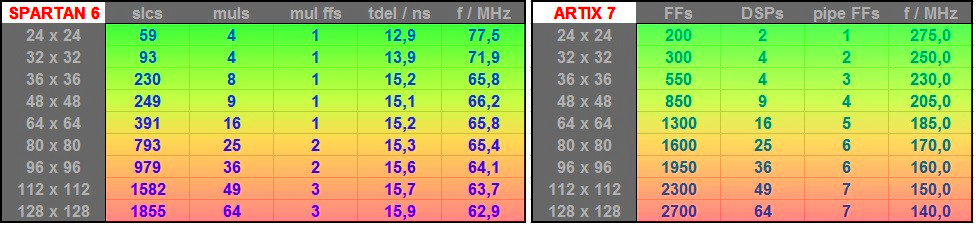
Mir ist noch nicht klar, wieso die Multiplikation "aufgeteilt" werden soll. Bei der Verarbeitungsgeschwindigkeit sollte das kein Problem sein, das mittels einer pipeline mit 2-3 Takten Latenz zu erledigen. Du formulierst einfach den Multiplier und baust FFs dahinter. Hier mal eine alte Tabelle, was man da erwarten kann. Die Schaltung hatte einen unterschiedliche breit eingestellten Multiplier mit a*b (wobei b immer so groß war wie a, aber einen anderen Wert hatte) und einen Akkumulator zum Aufsummieren. Es ist zu berücksichtigen, das für die Eingänge und Ausgänge der Vektoren weitere FFs hinzu kommen, die das timing ermöglichen, daher sind das nur Richtwerte.
Laut Tabelle scheint das sehr unkritisch für mich zu sein. Was bringt es mir ffs hinter den multiplizier zu schalten. Der muss ja trotzdem in einem Takt fertig werden oder bewirkt das schwarze Magie im synthesizer?
Frederic W. schrieb: > Was bringt es mir ffs hinter den multiplizier zu schalten. > Der muss ja trotzdem in einem Takt fertig werden Dadurch, dass du FFs dahinter schaltest, kann er leichter in einem Takt fertig werden, genauer: Die Multiplizier sitzen an einer bestimmten Stelle und dorthin müssen die Signale, also die "Leitungen" genutzt werden. FFs auf dem Weg dahin ermöglichen es, das zu verkürzen und bewirken indirekt, dass die Lauf- und Schaltzeit der Kombinatorik noch in eine dedizierte Taktperiode passt. Daher werden solche schnell schaltenden Elemente (auch BRAMS) gerne gepipelined. XI empfiehlt generell MULs 2x zu pipelinen. Die Alternative wäre die Eingänge zu multiplexen und zwei solcher MUL-Stufen zu parallelisieren, d.h. jeder einzelne hat zwei Takte Zeit zum Fertigwerden. So haben wir das früher gebaut, um mit eben solchen langsamen Chips wie dem S3 die Aufgaben zu packen, ohne den Takt zu verändern. Braucht dann ein Multicycle-constraint auf dem MUL. > oder bewirkt das schwarze Magie im synthesizer? Ja und Nein. Man muss in deinem Fall noch die Funktion "Multiplikation" von dem Chipelement "Multiplizier" trennen, weil es keinen 32x32 gibt. Der muss zusammengebaut werden, d.h. es kommt zu einer binomischen Aufspaltung. Wenn ein aktueller Xilinx z.B. einen 18x25 MUL hat, muss er (ohne Verrenkungen) eben 4 Teilterme realisieren und dann addieren. D.h. es läuft ohnehin auf etwas Zweistufiges hinaus. FFs davor und dahinter helfen dann beim Plazieren, weil sie Freiheitsgrade eröffnen. Ich würde sagen "graue Magie".
Frederic W. schrieb: > Der muss ja trotzdem in > einem Takt fertig werden oder bewirkt das schwarze Magie im synthesizer? Man muss auch unterscheiden ob er wirklich in einem Takt fertig werden muss oder ob er ein Ergebnis pro Takt liefern muss, das ist ein wichtiger Unterschied. Erster Fall z.B. wenn das Ergebnis in einer Rückkoppelung gebraucht wird, dann ist die zusätzliche Latenz durch FF hinderlich. Bei einer DFT geht es aber darum viele Multiplikationen abzuarbeiten, da bringt Pipelining viel da durch die zusätzlichen FF nach und im Multiplizierer der kritische Pfad kürzer wird und daher das Ganze sich schneller Takten läßt. Der Multiplizierer liefert weiterhin ein Ergebnis pro Taktzyklus aber durch den höheren Takt ist die gesamte DFT in kürzerer Zeit fertig.
Gerade im alten Synthesizer-Design von 2005 machgesehen: Der Spartan 3E möchte mindestens ein zusätzliches FF haben, wenn er ein 24 Bit-Audio-Sample mit einem 16-Bit-Koeffizient bei 48MHz abarbeiten will. In der Regel braucht man 2, insbesondere wenn das FPGA ziemlich voll ist.
Jürgen S. schrieb: > Gerade im alten Synthesizer-Design von 2005 machgesehen: > Der Spartan 3E möchte mindestens ein zusätzliches FF haben, wenn er ein > 24 Bit-Audio-Sample mit einem 16-Bit-Koeffizient bei 48MHz abarbeiten > will. In der Regel braucht man 2, insbesondere wenn das FPGA ziemlich > voll ist. Wo möchte er den FF? Vor oder nach dem multiplier?
Frederic W. schrieb: > Wo möchte er den FF? Vor oder nach dem multiplier? Na, danach natürlich, wobei es bei entsprechenden Einstellungen der Synthese auch reicht, wenn beide Faktoren registriert sind und die dann nach hinten balanciert werden.
Als Beispiel die Syntheseergebnisse bei einem Wurzelalgorithmus:
1 | -- |
2 | -- Synthesis Results Artix 7-2L |
3 | -- |
4 | -- 32 Bit -> 16 Bit without Rest |
5 | -- |
6 | -- with ARESET : |
7 | -- |
8 | -- 3.000 ns 333 MHz +0.30 ns (Default) |
9 | -- |
10 | -- 2.800 ns 357 MHz +0,07 ns (PerfOpti, Retiming) |
11 | -- |
12 | -- LUT 457 |
13 | -- LUTRAM 20 |
14 | -- FF 370 |
15 | -- |
16 | -- |
17 | -- 2.600 ns 384 MHz -0.30 ns (PerfOpti, Retiming) |
18 | -- |
19 | -- |
20 | -- with SRESET |
21 | -- |
22 | -- 2.800 ns 357 MHz +0,01 ns (PerfOpti, Retiming) |
23 | -- |
24 | -- LUT 459 |
25 | -- LUTRAM 20 |
26 | -- FF 384 |
27 | -- |
28 | -- |
29 | -- |
30 | -- with SRESET + FF |
31 | -- |
32 | -- 2.800 ns 357 MHz +0,01 ns (PerfOpti, Retiming) |
33 | -- |
34 | -- LUT 460 |
35 | -- LUTRAM 20 |
36 | -- FF 388 |
37 | -- |
38 | -- |
39 | -- 2.700 ns 370 MHz -0,21 ns (PerfOpti, Retiming) |
40 | -- |
41 | -- |
42 | -- |
43 | -- with SRESET + FF + WRAP + IO-FF |
44 | -- |
45 | -- 2.800 ns 357 MHz +0,01 ns (PerfOpti, Retiming) |
46 | -- |
47 | -- |
48 | -- |
49 | -- 64 Bit -> 32 Bit without Rest |
50 | -- |
51 | -- with SRESET + FF + WRAP + IO-FF |
52 | -- |
53 | -- 3.500 ns 285 MHz +0.06 ns (PerfOpti, Retiming) |
54 | -- |
55 | -- LUT 1714 |
56 | -- LUTRAM 52 |
57 | -- FF 1622 |
58 | -- |
59 | -- |
60 | -- 32 Bit + 0 -> 16.16 Bit without Rest |
61 | -- |
62 | -- with SRESET + FF + WRAP + IO-FF |
63 | -- |
64 | -- 3.400 ns 294 MHz +0.08 ns (PerfOpti, Retiming) |
65 | -- |
66 | -- LUT 1604 |
67 | -- LUTRAM 20 |
68 | -- FF 1437 |
69 | -- |
70 | -- |
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.