Hallo, Ich musste leider feststellen, dass das 1kByte EEPROM des AtMega32U4 (Arduino Leonardo) nicht besonders verlässlich ist. Ich speichere dort drinnen Daten und musste nun bei einem meiner Kunden feststellen, dass es einen Bitwechsel in den Daten gab. Das ist das erste mal in ca. 1,5 Jahren gewesen und das EEPROM wurde in dieser Zeit nicht beschrieben sondern immer nur gelesen. Mein kurzfristiger erster Lösungsansatz war eine eigene Implementierung eines Hamming Codes mit der ich mit einer Redundanz von 11 Byte Einzelbitfehler detektieren und korrigieren kann und Doppelbitfehler wenigstens erkenne. Das funktioniert soweit ganz gut. Trotzdem bin ich noch immer nicht 100%ig von der Lösung überzeugt und ich würde gerne die Ursache des Bitkippers genauer verstehen. Wann kann es zu einem Bitkipper kommen? Nur beim Schreiben? (ausgeschlossen) Nur beim Lesen? Oder auch wenn der Chip nicht gepowert ist? Ist Drittes der Fall dann würde das bedeuten, dass das Gerät durch einfaches einlagern, ohne Stromversorgung ebenfalls altern würde und früher oder später die Bitfehler auftreten würden. Da das gerät aber nicht aktiv wäre würden die Einzelbitfehler nicht korrigiert werden und früher oder später würde es zu Mehrfachfehlern kommen. Das wäre sehr blöd. Was meinen die Experten? Zusatzfrage: Wie sieht es mit der Verlässlichkeit des integrierten Flashs aus? Wenn ich es SW technisch lösen könnte die Daten im Flash zu speichern, wäre die Gefahr damit gebannt sporadische Bitkipper zu erhalten? Danke und liebe Grüße
Das EEprom reagiert empfindlich auf Einbrüche der Spannungsversorgung, sowohl bei Schreibzugriffen als auch auch bei Lesezugriffen. Dagegen hilft in gewissem Rahmen der Brown-Out Detektor. Der Programmspeicher ist nach meinem Kenntnisstand weniger betroffen, hält aber auch nicht ewig. Ich habe da etwas von 10 Jahren im Gedächtnis, ab dann sind Ausfälle zu erwarten. Wie oft hast du die Zellen denn beschrieben? Die sind ja nur für 10.000 Schreib-Zyklen spezifiziert.
Fpdragon F. schrieb: > Das ist das erste mal in ca. 1,5 > Jahren gewesen und das EEPROM wurde in dieser Zeit nicht beschrieben > sondern immer nur gelesen. Von wie vielen Geräten im Feld sprechen wir? Millionen? Oder Einzelstücke? Welche Temperatur herrscht? Wie viele Schreibzyklen hat der Chip bzw. die Zelle schon durch? Warum kannst du einen Fehler in deiner Software ausschließen? Bitfehler in EEPROM können auftreten, das kann verschiedene Ursachen haben bis hin zu Fertigungsfehlern, Softwareproblemen, Problemen mit der Spannungsversorgung. Wie Störanfällig ist die Anlage? Gibts dort Motoren, Blitze, hohe Ströme in der Gegend oder steht das Ding irgendwo im Keller und läuft mit Batterie? Fpdragon F. schrieb: > Oder auch wenn der Chip nicht gepowert ist? Natürlich altert das. Du hast da Ladung auf einem Floating Gate. Diese haut dir nach langer Zeit irgendwann mal ab. > Ist Drittes der Fall dann würde das bedeuten, dass das Gerät durch > einfaches einlagern, ohne Stromversorgung ebenfalls altern würde und > früher oder später die Bitfehler auftreten würden. Schau ins Datenblatt. Da steht drin wie lange die Bits halten sollen. Stefan ⛄ F. schrieb: > Ich habe da etwas von 10 Jahren im > Gedächtnis, ab dann sind Ausfälle zu erwarten. > > Wie oft hast du die Zellen denn beschrieben? Die sind ja nur für 10.000 > Schreib-Zyklen spezifiziert. Das ist normalerweise "entweder-oder". Entweder du willst 10 Jahre Haltbarkeit oder 10k Zyklen. Jedes Schreiben beeinträchtigt die Zelle bzw. deren Oxidschicht.
Ich bin zum ersten mal drauf gestoßen, als ich die Stromaufnahme einer Ethernet Schnittstelle unterschätzte, sowie die Kontaktwiderstände meines Steckbretts.
Angehängte Dateien:
-

preventing_corruption.png
120 KB -

eepromcycles.png
66 KB -

dataretention.png
33 KB



Fpdragon F. schrieb: > Wann kann es zu einem Bitkipper kommen? (1) Das Datenblatt gibt dazu ja eindeutige Empfehlungen (Screenshot, p25), die auf die vom Vorredner zitierten Maßnahmen (BOD) hinauslaufen. Da geht es um undefiniertes Verhalten der CPU bei Unterspannung, die dann das Daten-EEPROM korrumpiert. Das betrifft imho aber eher komplette Bytefehler als einzelen Bitfehler. (2) Die Anzahl der zulässigen Schreibzyklen wird dort nicht als 10000 sondern als als 100000 beziffert (Screenshot, p20). Abnutzung durch zu häufige Schreibvorgänge wäre natürlich auch ein Grund. Kannst Du abschätzen, wie oft Du schreibst? (3) Über die Datenerhaltung während des Ausgeschaltetseins gibt das Datenblatt auf Seite 8 Auskunft (dreitter Screenshot). Bei 1Kbyte Daten und Normaltemperaturen ist ein Bitkipper da zwar unwahrscheinlich - aber eben auch nicht ausgeschlossen. HTH, (re)
Hey super, vielen Dank für die zahlreichen hilfreichen Antworten. direkt zur Sache: 1.) Brown-Out Detektor hört sich sehr vielversprechend an. Ich werde schauen wie ich diesen in Betrieb nehmen kann. Das Gerät wird per 5V USB Versorgt und deshalb kann ich mir durchaus vorstellen, dass eine instabile Versorgung möglich ist bei den diversen USB Hub- Konstrukten und zu langen USB Kabeln. 2.) Ich gehe auch von 100k Schreibzyklen aus und die habe ich bei weiten sicher nicht erreicht. Wenn's hoch kommt sind es vl ein paar hundert gewesen. 3.) Einen SW Fehler würde ich ausschließen. Das Gerät wird typischerweise einmalig konfiguriert und dann liegen die Daten permanent im EEPROM. Der Fehler trat in einem ASCII Text Datenbereich auf und deshalb war es relativ einfach zu erkennen, dass sich ein Character verändert hat. 4.) Bzgl. Temperatur glaube ich nicht, dass das die Ursache sein konnte. Die Geräte werden bei Zimmertemperatur eingesetzt und selbst mit direkter Sonneneinstrahlung sollte das Gehäuse ausreichend schützen. Die vielversprechendste Ursache scheint mir wirklich eine instabile Stromversorgung gewesen zu sein. Ich werde mir jedenfalls diesen BOD zu Gemüte führen. Die Frage die ich mir jetzt aber stelle ist, ob meine Hamming Fehlerkorrektur nun unnötig war bzw vl sogar kontraproduktive Effekte entwickeln könnte?
Keine Lösung Fpdragon F. schrieb: > 100%ig Gute Forderung, ist leider nicht zu erreichen. Auch nicht in der Medizin oder Avionik. > Das ist das erste mal in ca. 1,5 Jahren gewesen Immerhin. > und das EEPROM wurde in dieser Zeit nicht beschrieben > sondern immer nur gelesen. Bin kein "AtMega32U4-Chipfehler-Experte", aber: "100%ig" fordern und gleichzeitig im Zeitrahmen von 1,5 Jahren "AtMega32U4 beim Kunden", also ausserhalb jedweder Kontrolle aller Eventualitäten eine Vermutung Doppelpunktistgleich := schlechter Lösungsansatz zur Ursachenforschung. Normalerweise werden solche Fälle "einfach eingepreist" (Garantie ohne Folgekostenerstattung oder +/- Versicherung). Selbst wenn vereinzelt Menschen wegen irgendwelchem Versagen sterben; auch dies wird "einfach eingepreist". Sorry für die direktheit meines Beitrages, ich bin immer noch angefressen wegen fahrlässig verursachten unnötigen Verkehrstoten (völlig anderer Faden). Lösungsansatz, näher an 99,99999% Fpdragon F. schrieb: > Mein kurzfristiger erster Lösungsansatz war eine eigene Implementierung > eines Hamming Codes mit der ich mit einer Redundanz von 11 Byte > Einzelbitfehler detektieren und korrigieren kann und Doppelbitfehler > wenigstens erkenne. Das funktioniert soweit ganz gut. Klingt gut! 100% werden es trotzdem nicht.
Fpdragon F. schrieb: > Brown-Out Detektor hört sich sehr vielversprechend an. Ich werde schauen > wie ich diesen in Betrieb nehmen kann Wenn Du den bisher deaktiviert hattest, gehe ich stark davon aus, dass das Problem danach weg sein wird. Generell lohnt sich ein Blick auf die Stromversorgung. Fpdragon F. schrieb: > Die Frage die ich mir jetzt aber stelle ist, ob meine Hamming > Fehlerkorrektur nun unnötig war bzw vl sogar kontraproduktive Effekte > entwickeln könnte? Stören wird sie nicht, aber ich würde es auf eine Prüfsumme beschränken, um im (hoffentlich nie auftretenden) Fehlerfall nicht mit falschen Daten zu arbeiten.
Fpdragon F. schrieb: > 1.) Brown-Out Detektor hört sich sehr vielversprechend an. Ja, ohne BOD sind Verluste sowohl im EEPROM als auch im Flash (wenn auch mit geringerer Wahrscheinlichkeit) quasi vorprogrammiert. Nur mittels einer sehr genau auf die konkrete Anwendung abgestimmten Versorgung kann man eigentlich die Notwendigkeit für die Aktivierung des BOD umgehen. Das läuft aber effektiv letztlich darauf hinaus, den eingebauten BOD durch einen externen zu ersetzen. Das lohnt (wenn überhaupt) nur für extrem energiesparende Designs, sprich Batteriebetrieb. Und es ist schon recht schwierig, es besser (also insbesondere energesparender) hinzubekommen als der interne BOD es tut. Also, für deinen Fall (Versorgung via USB): eingebauten BOD korrekt konfigurieren und aktivieren und alles ist chic (zumindest, wenn die Software fehlerfrei ist).
2aggressive schrieb: > fahrlässig verursachten unnötigen Verkehrstoten Wenn solche, wie 2aggressive an das Steuer und Gaspedal gelassen werden, ist das wirklich fahrlässig. Vor Fahrtantritt müsste auf !aggressive getestet werden. Dann wird erst das Fahrzeug zur Bedienung freigegeben.
Angehängte Dateien:
-

Fusebits-BOD.png
77 KB
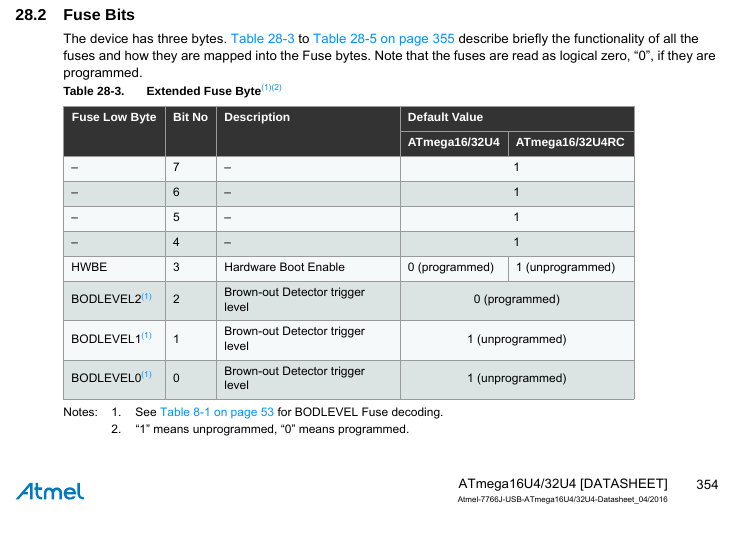
Fpdragon F. schrieb: > Ich werde mir jedenfalls diesen BOD zu Gemüte führen. Das halte ich auch für eine Pflichtübung. Ist recht einfach mit den Fuses die Schwelle einstellen und dann macht die CPU einen Reset statt undefiniertem Zeug. Das wegzulassen macht höchstens dann Sinn, wenn bei verreckender Batterie noch ein teilweise aussetzender "Notbetrieb" stattfinden soll. Nicht bei USB. > Das Gerät wird per 5V USB > Versorgt und deshalb kann ich mir durchaus vorstellen, dass eine > instabile Versorgung möglich ist bei den diversen USB Hub- Konstrukten > und zu langen USB Kabeln. Wenn es tatsächlich liegt, dann wird die BOD "überraschende" (aber heilsame) Effekte bringen. "Eigentlich" ist bei gut designten Versorgungen die BOD nur für die paar Millisekunden des Ein- und Ausschaltens wichtig. Bei schlecht designten Versorgungen verhindert sie eben das schlimmste, aber natürlich nicht das Aussetzen der Versorgung. Fpdragon F. schrieb: > ob meine Hamming Fehlerkorrektur nun unnötig war bzw vl sogar > kontraproduktive Im Gegenteil, sowas ist oft sinnvoll. Eine vom Hersteller quanitfizierte Fehlerrate von 1ppm über 100 Jahre bei 25°C bedeutet schließlich nicht, dass die akkumulierte Fehlerrate in 1.5 Jahren auf exakt "0" liegt, sondern dass die Chance, Pech zu haben, nur eben ziemlich klein ist. Mit ECC-Verfahren bemerkst Du diesen sehr seltenen Fall aber immerhin bei moderatem Ressourceneinsatz automatisch. Hängt eben davon ab, wie wichtig Dir diese Daten in der Anwendung sind. (re)
Parallelschreiberia Fpdragon F. schrieb: > Die Frage die ich mir jetzt aber stelle ist, ob meine Hamming > Fehlerkorrektur nun unnötig war Gefährdungsbeurteilung deines Apparellos. Was wird beim schlimmsten anzunehmenden Versagen an negativen Folgen passieren? Solange "der Gerät" gefahrlos ausfallen kann (zB Zahnbürsten- oder Effektbeleuchtungssteuerung) sicherlich nicht wirklich nötig, weil keine Folgekosten und keine teuren Klagen zu erwarten sind. Bei der Steuerung eines Schiffsruders kann das anders aussehen. Das andere Extrem: > bzw vl sogar kontraproduktive Effekte entwickeln könnte? Spätestens wenn "der Gerät" lebensnotwendig in Echtzeit arbeiten muss (Herz-Lungen-Maschine, oder Höhenruder an einem Flugzeug) eher nicht. Dann lieber suboptimale/falsche Parameter, als gar keine Funktion. Da brauchts noch mehr!
Fpdragon F. schrieb: > Ich werde mir jedenfalls diesen BOD zu > Gemüte führen. > > Die Frage die ich mir jetzt aber stelle ist, ob meine Hamming > Fehlerkorrektur nun unnötig war Sorry, ich war etwas voreilig: Die beiden Maßnahmen adressieren unterschiedliche Ursachen der Bitkipperei, die nix miteinander zu tun haben. (a) korrumpiertes CPU-Verhalten --> BOD, (b) alternde Ladungshaltung der Speicherzelle --> ECC+refresh. Die "eine" Maßnahme hilft imho nicht effektiv gegen die "andere" Ursache. Wenn auch die Fehlerkorrektur immerhin in begrenzem Maß korrigieren kann, wenn (a) nicht zu häufig passiert ist (was hier ja wohl nicht der Fall war). (re)
Dieter schrieb: > 2aggressive schrieb: >> fahrlässig verursachten unnötigen Verkehrstoten > > Wenn solche, wie 2aggressive an das Steuer und Gaspedal gelassen werden, > ist das wirklich fahrlässig. Keine Angst: Steuerrad und Hebel sind unter Kontrolle des Schweins. Meine Aufgabe: finger weg von den Hebeln, nur das Schwein füttern! Damit klappts auch seit vielen Jahrzehnten unfallfrei, ich liebe mein inneres Schwein :D > Vor Fahrtantritt müsste auf !aggressive getestet werden. Dann wird erst > das Fahrzeug zur Bedienung freigegeben. -2aggressive != !aggressive -Bedienung != Beherrschung -niemanden sehen != niemand teilnehmend Allerdings :D = Dieter :D
re schrieb: > Die beiden Maßnahmen adressieren unterschiedliche Ursachen der > Bitkipperei, die nix miteinander zu tun haben. (a) korrumpiertes > CPU-Verhalten --> BOD, (b) alternde Ladungshaltung der Speicherzelle --> > ECC+refresh. So ist es. > Wenn auch die Fehlerkorrektur immerhin in begrenzem Maß korrigieren > kann, wenn (a) nicht zu häufig passiert ist (was hier ja wohl nicht der > Fall war). Einzel-Bitfehler (was der Normalfall bei alterungsbedingten Fehlern ist), kann man mit sehr guter Sicherheit korrigieren. Allerdings habe ich noch NIEMALS solche altersbedingte Ausfälle der NV-Speicher eines AVR8 selber gesehen. Und das, obwohl die garantierte data retention time in Tausenden von noch im Einsatz befindlichen Exemplaren (vorwiegend ATmega16/32) weitaus überschritten ist. Sprich: Atmel hat hier in den Datenblättern auf Sicherheit gesetzt. Die Dinger halten typisch weitaus länger, als es offiziell garantiert war. Allerdings gilt das natürlich nur für die entsprechend ollen Designs mit den ollen AVR8. Könnte gut sein, dass die späteren AVR8 (mit geshrinkten Strukturen) nicht mehr so extrem gutmütig sind.
c-hater schrieb: > Einzel-Bitfehler (was der Normalfall bei alterungsbedingten Fehlern > ist), kann man mit sehr guter Sicherheit korrigieren. Da stimme ich zu, deswegen halte ich das auch für sinnvoll. Nur wenn wegen wegen fehlendem BOD irgenwann ganze Blöcke durch undefiniertes CPU-Verhalten wegerodiert sind, ist es irgendwann vorbei mit der Korrigiererei. c-hater schrieb: > Allerdings habe ich noch NIEMALS solche altersbedingte Ausfälle der > NV-Speicher eines AVR8 selber gesehen. [...] > Atmel hat hier in den Datenblättern auf Sicherheit gesetzt. Ich auch nicht. Immerhin sind solche Datenverluste im Sinne der Retention Time in sinnvoll ausgelegten Anwendungen ja auch ziemlich seltene Ereignisse und nach der nächsten Auffrischung auch wieder rückstandsfrei verschwunden. Ich stelle es mir für den TO dementsprechend auch etwas aufwändig vor, zu überprüfen, ob die entsprechende Maßnahme tatsächlich etwas "gebracht" hat, also der Bitfehler in den nächsten 1.5 Jahren nicht mehr auftritt. ;-) Da kann es wohl nur um "defensives Programmieren" gehen. Wenn die Hersteller von "projizierten" Fehlerraten sprechen, dann ermitteln die das ja auch nicht an wenigen Dutzend Expemplaren bei Normaltemperatur, auch wenn die Experimente keine 20 oder 100 Jahre laufen. (re)
Ok, werden wir konkreter weil die Frage schon mehrmals da war: Die Anwendung selbst ist nicht "sicherheitskritisch" aber unter den EEPROM Daten befindet sich z.B. ein Passwort. Sollte sich dieses unmotiviert verändern kann sich der Kunde über's externe Tooling nicht mehr einloggen und das Gerät hat keine Funktion mehr. Das sollte auch das Verständnis geben warum nur eine Fehlerkorrektur Sinn macht und bei einer reinen Fehlererkennung wäre trotzdem schon alles vorbei. Ich habe nun kontrolliert: Die interne BOD war schon aktiviert aber auf einem Schwellwert von 2,6V. Ich habe sie jetzt testweise auf den höchsten Schwellwert von 4,3V verstellt und es scheint noch immer alles zu funktionieren. Ich denke diese Einstellung macht in Zukunft mehr Sinn. Ein USB Anschluss mit weniger als 4,3V scheint mir nicht vertrauensvoll zu sein. In ein paar Meldungen habe ich nun wieder rausgelesen, dass Einzelbitfehler wahrscheinlicher durch andere Einflüsse als der Versorgungsspannung entstehen könnten. Daher denke ich macht die SW-Seitige Fehlerkorrektur weiterhin Sinn. Also künftig mit BOD auf 4,3V und Hamming Code Modul. Bzgl. der Belehrungen mit "100%ig verlässlich" und "Kundeneinsatz"... Wenn ich auf dieses Problem sensibilisiert gewesen wäre, dann hätte ich mich selbstverständlich schon früher damit befasst. Weiter möchte ich auf diese Aussagen aber nicht eingehen weil mich das nicht weiter bingt. Danke für die Hilfe und wenn es noch weitere Anregungen gibt bin ich dankbar.
re schrieb: > Ich stelle es mir für den TO dementsprechend auch etwas aufwändig vor, > zu überprüfen, ob die entsprechende Maßnahme tatsächlich etwas > "gebracht" hat, also der Bitfehler in den nächsten 1.5 Jahren nicht mehr > auftritt. ;-) > > Da kann es wohl nur um "defensives Programmieren" gehen. Mit dem Hamming Code kann man ohne Probleme Einzel und Doppelbitfehler erkennen. Ich habe natürlich auch einen Error Counter und einen Repair Counter eingebaut um künftig genau sehen zu können wie viel das nun wirklich gebracht hat bzw. wie gut oder schlecht das EEPROM funktioniert. Warum das nicht funktionieren soll ist mir nicht klar. Wie schon erwähnt, einen Fehler in der Software würde ich ausschließen aufgrund des Aufbaus der Software und detailierter Inspections und Analysen.
Fpdragon F. schrieb: > Ist Drittes der Fall dann würde das bedeuten, dass das Gerät durch > einfaches einlagern, ohne Stromversorgung ebenfalls altern würde und > früher oder später die Bitfehler auftreten würden. Was meinst du mit "altern". Ein einzelnes, mit der EEPROM-Zelle wechselwirkendes Neutrino dürfte reichen, um das Bit zu kippen.
Wolfgang schrieb: > Was meinst du mit "altern". Ein einzelnes, mit der EEPROM-Zelle > wechselwirkendes Neutrino dürfte reichen, um das Bit zu kippen. Neutrinos sind eher kein Problem, denn deren wesentliche Eigenschaft ist, dass sie kaum mit baryonischer Materie interagieren. Deswegen ist es auch so aufwendig, sie zu beobachten... Was aber tatsächlich relevant sein kann, ist der ganz normale "radioaktive" Hintergrund. Darüber hinaus aber auch tatsächliche Alterungseffekte, insbesondere die verfickte Geschichte mit dem Tunnelling von Ladungsträgern. Das ist eine kaum logisch erklärbare Sache aus der Quantentheorie. Es muss aber was dran sein, sonst würden diese Speicher nämlich garnicht funktionieren können, denn das tuen sie nur deshalb, weil es das Tunneling gibt... However: als unschöner Nebeneffekt ergibt sich halt zwingend aus der Theorie (die inzwischen überaus gut durch die Praxis belegt ist), dass da auch mal ein Bit zurück kippen kann, mehr noch: sogar irgendwann zwingend kippen wird. Der Rest ist ist eigentlich nur eins: die entsprechenden Wahrscheinlichkeiten mit hinreichender Treffsicherheit angeben zu können...
Fpdragon F. schrieb: > Ein USB Anschluss mit > weniger als 4,3V scheint mir nicht vertrauensvoll zu sein. Kann aber mit ein paar hundert mA Last schnell passieren, vor allem wenn das Kabel lang und dünn ist.
c-hater schrieb: > Neutrinos sind eher kein Problem, denn deren wesentliche Eigenschaft > ist, dass sie kaum mit baryonischer Materie interagieren. Deswegen ist > es auch so aufwendig, sie zu beobachten... "kaum" ersetzt du besser mit "selten". Auch seltene Ereignisse können eintreten.
c-hater schrieb: > Allerdings habe ich noch NIEMALS solche altersbedingte Ausfälle der > NV-Speicher eines AVR8 selber gesehen. Und das, obwohl die garantierte > data retention time in Tausenden von noch im Einsatz befindlichen > Exemplaren (vorwiegend ATmega16/32) weitaus überschritten ist. > > Sprich: Atmel hat hier in den Datenblättern auf Sicherheit gesetzt. Die > Dinger halten typisch weitaus länger, als es offiziell garantiert war. Also in meinem Datenblatt von 2006 steht beim Atmega16 einfach nichts zur Datensicherheit des Flashs. Nur zum Eeprom. In der aktuellen Version steht 20 Jahre bei 85°C. 100 Jahre bei 25°C. Und dann noch der Hinweis: Reliability Qualification results show that the projected data retention failure rate is much less than 1 PPM over 20 years at 85°C or 100 years at 25°C. Dürfte schwierig sein das außer im industriellem Umfeld überschritten zu haben. 20 Jahre sind die doch noch nicht am Markt. Hab 2004 einen At90S8535 durch einen ATmega16 ersetzt.
Wolfgang schrieb: > "kaum" ersetzt du besser mit "selten". Wennschon, dann mit "überaus selten, so selten, dass praktisch vollkommen irrelevant". Genau das bescheibt die Sache bezüglich der Neutrinos im Zshg. mit EEPROM/Flash wohl sehr gut. > Auch seltene Ereignisse können > eintreten. Na klar. Nur eben praktisch sicher niemals innerhalb der üblichen retention times für solche Datenträger. Mein Gott, schau dir die schieren Ausmaße der Einrichtungen an, die für den Nachweis von Neutrinos errichtet wurden. Das machen die nicht deshalb so groß, weil sie Steuermittel verprassen wollen. Nein, das machen die, weil es eben so extrem unwahrscheinlich ist, dass ein Neutrino interagiert.
c-hater schrieb: > Na klar. Nur eben praktisch sicher niemals innerhalb der üblichen > retention times für solche Datenträger. So etwas wie "praktisch sicher" kennt Statistik nicht. Es bleibt immer eine Wahrscheinlichkeit > 0. Das Ereignis kann also eintreten - und wenn man großes Pech hat, auch innerhalb von 1.5 Jahren Nutzungsdauer. Bei einem einzigen beobachteten Ereignis fehlt die statische Grundlage, um beurteilen zu können, wie oft so etwas eintritt.
Angehängte Dateien:
-

dataretention.png
33 KB

Fpdragon F. schrieb: > Warum das nicht funktionieren soll ist mir nicht klar. Dochdoch, da habe ich mich vielleicht suboptimal ausgedrückt. In der von Dir zitierten Passage ging es um den Vorher-Nachher-Vergleich, mit dem dann am Objekt tatsächlich nachgewiesen wird, dass die Maßnahme das Problem tatsächlich behebt und ohne die Maßnahme das Problem weiterbesteht, sich aber in Deinem Fall erst nach einigen Jahren zeigt. Da dauert der Nachweis, wennn er signifikant seion soll. Den grundsätzlichen Einsatz einer ECC mittels Hamming-Codierung, so wie Du es beschrieben hast, hab eich nicht in Zweifel gezogen hund halte ihn - wie ja schon vorher geschrieben - für sehr sinnvoll. Nicht nur, um defensiv zu projektieren, sondern auch als Diagnosewerkzeug. Fpdragon F. schrieb: > BOD war schon aktiviert aber auf einem Schwellwert von 2,6V. Das könnte formal gesehen etwas knapp gewesen sein, weil das Datenblatt korrekte Funktion je nach Taktfrequenz erst ab 2.7V - 4.5V garantiert. In der Praxis mag das an den meisten Exemplaren trotzdem funktionieren. Malte _. schrieb: > In der aktuellen Version steht 20 Jahre bei 85°C. 100 Jahre bei 25°C. > 20 Jahre sind die doch noch nicht am Markt. Hmm... Da steht, dass innerhalb eines Zeitraums von 20 Jahren bei 85°C eine Fehlerrate der Datenhaltung **von weniger 1ppm** erwartet wird. Aber nicht, dass bei weniger als 20 Jahren die Fehlerrate 0.0 sein soll. Das dafür verantwortliche Wegtunneln der Ladungsträger durch die Oxidschicht lässt sich nur statistisch beschreiben, aber nicht deterministisch. Aus der Herstellerprojektion könnte man dann unter Zugrundelegung eines Prozessmodells seiner Wahl eine Datensicherheit für den Zeitraum von z.B. 2 Jahren abschätzen. Die Fehlerrate wird dann vermutlich praktisch vernachlässigbar klein sein. Aber nicht null. Wie ja vom TE auch beobachtet. (re)
re schrieb: > In der von Dir zitierten Passage ging es um den > Vorher-Nachher-Vergleich, mit dem dann am Objekt tatsächlich > nachgewiesen wird, dass die Maßnahme das Problem tatsächlich behebt und > ohne die Maßnahme das Problem weiterbesteht, sich aber in Deinem Fall > erst nach einigen Jahren zeigt. Da dauert der Nachweis, wennn er > signifikant seion soll. Achso, ja da stimme ich dir zu, das ist nicht einfach zu analysieren, vor allem wenn man nur einen Einzelfall bisher hatte. Was ich aber trotzdem sagen kann ist, dass mir dieser Einzelfall schon zu viel ist als dass ich nichts dagegen unternehmen würde. Aber mit dem Hamming Code war ich denke ich eh auf dem richtigen Dampfer und das ist nun mal das Beste an Daten, was ich habe. > Das könnte formal gesehen etwas knapp gewesen sein, weil das Datenblatt > korrekte Funktion je nach Taktfrequenz erst ab 2.7V - 4.5V garantiert. > In der Praxis mag das an den meisten Exemplaren trotzdem funktionieren. Ok, dann denke ich sollte der höhere Schwellenwert auch sinnvoll sein. Danke für die Klarstellungen.
Wolfgang schrieb: > c-hater schrieb: >> Na klar. Nur eben praktisch sicher niemals innerhalb der üblichen >> retention times für solche Datenträger. > > So etwas wie "praktisch sicher" kennt Statistik nicht. Es bleibt immer > eine Wahrscheinlichkeit > 0. > Das Ereignis kann also eintreten - und wenn man großes Pech hat, auch > innerhalb von 1.5 Jahren Nutzungsdauer. Bei einem einzigen beobachteten > Ereignis fehlt die statische Grundlage, um beurteilen zu können, wie oft > so etwas eintritt. Es war scheinbar ein großer Fehler von "100%ig sicher" zu schreiben. Ich bin mir sicher jedem, inkl. mir ist bewusst, dass es nie 100%ige Sicherheit gibt und alles nur eine Frage der Wahrscheinlichkeiten ist. Letztendlich bleibt das Thema aber noch immer legitim weil offensichtlich die Fehlerwahrscheinlichkeit zu hoch ist für meine Anwendung. Und es hat sich ja auch bereits herausgestellt, dass es zwei sinnvolle Gegenmaßnahmen gibt. (Fehlerkorrektur und BOD) Ich bedanke mich nochmals für diese Lösungsfindung.
wenn man eh nicht viel auf den EEPROM schreibt und noch genug Platz ist könnte man einen Wert auch in 3 Speicherzellen oder mehr ablegen. Und dann einfach sich den Wert raussuchen der mind. 2 mal übereinstimmt. Nur zu wissen das die Daten falsch sind hilft einem ja nicht weiter. Deine Schaltung braucht vielleicht noch einen weiteren Elko kurz vor die Kerkos um kurze Einbrüche etwas abzufangen. Wenn aber der µC bis 2,7V laut Datenblatt läuft finde ich es nicht gut den Brown Our Reset schon bei 4,xV anschlagen zu lassen. Interessant wäre die Schaltung was muss der AVR alles treiben, kann man dies während des EEPROM Schreibens auch unterbinden
An welcher Stelle war der Fehler? Ich hatte mal wiederholt Fehler im 1. Byte. Habe dieses dann einfach nicht mehr benutzt. War aber beim uralten 90S2313.
michael_ schrieb: > An welcher Stelle war der Fehler? > Ich hatte mal wiederholt Fehler im 1. Byte. > Habe dieses dann einfach nicht mehr benutzt. > War aber beim uralten 90S2313. Die AT90S waren dafür bekannt dass das erste Byte im Eeprom gerne mal verloren ging. Bei einem Projekt von mit einem ATtiny hatte jemand das nachgebaut und dort den selben Effekt - nur war mir von den Attinys nichts vergleichbares bekannt. Es stellte sich heraus, ich hatte den Brown-out Detektor aktiviert - sie nicht. Nach dem Aktivieren verschwand auch bei ihr der Effekt. Die alten AT90S hatte übrigens noch keinen integrierten Brown-out Detektor.
Thomas O. schrieb: > Wenn aber der µC bis 2,7V laut Datenblatt läuft finde ich es nicht gut > den Brown Our Reset schon bei 4,xV anschlagen zu lassen. Der nächstniedrigere Schwellenwert wäre 3,5V. Das erscheint mir doch wieder sehr niedrig für eine Nominalspannung von 5V? Leistung wird auch keine große gezogen und der USB Spannung sollte nicht von diesem Gerät einbrechen. Ich denke die Vermutungen mit Kabelqualität/Länge, schlechte USB Hubs und vl. sogar schlechte Steckverbindung werden eher zu einer instabilen Versorgung geführt haben und dadurch wahrscheinlich den Bitfehler ausgelöst haben. Die gezogene Leistung wird da keine große Rolle gespielt haben. Aber ist nur eine Vermutung, weil mir die anderen potentiellen Fehlerursachen unwahrscheinlicher erscheinen. Aber was meint die Mehrheit? 3,5V oder 4,3V BOD für ein low Power USB versorgtes Gerät? Wie entscheidet man sowas? Möglichst hoch aber trotzdem noch funktional? Oder möglichst knapp über den 2,7V? Oder irgendwo in der goldenen Mitte zwischen 2,7 und 5V? Ich frage mich überhaupt wie man auf diese Abstufungen gekommen ist: 2,0V, 2,2V, 2,4V, 2,6V, 3,4V, 3,5V, 4,3V Ist wahrscheinlich irgendwie HW-Technisch begründbar? Sinn machen ja dann eigentlich eh nur noch: 3,4V, 3,5V, 4,3V weil alle anderen ja unter 2,7V liegen.
das wird man austesten müssen. z.B. in dem man eine Konstantspannung immer weiter reduziert, fortlaufend aufs EEPROM schreibt und zusätzlich mit einer PWM immer mal wieder einen kleine Last über die Versorgungsspannung schalten. Nach einem BOD -Reset halt mal kurz einen LED 1 Sekunde lang leuchten lassen damit man den Reset erkennt. Nun das EEPROM auslesen und nachsehen ob falsche Daten geschrieben wurden. Je nach Last / Frequenz kann man sich dann Gedanken um den Elko und den BOD Level machen, ggf. Ansteuern und das ganze danach nochmals verschärft Prüfen.
Fpdragon F. schrieb: > Wie entscheidet man sowas? Man nimmt die Spannung, für die die CPU bei der gegebenen Taktfrequenz im Datenblatt noch als garantiert funktionierend angegeben wird und bleibt ein Epsilon dadrüber. Um welche Taktfrequenz geht es denn? (Wobei in Deinem Fall alles auf spontanen Ladungsträgerverlust hindeutet, der gar nix mit der BOD-Problematik zu tun hat.) Thomas O. schrieb: > Nach einem BOD -Reset halt mal kurz einen > LED 1 Sekunde lang leuchten lassen damit man den Reset erkennt. Nun das > EEPROM auslesen und nachsehen ob falsche Daten geschrieben wurden. Dummerweise ist bei Unterspannung aber nicht garantiert, dass das EEPROM tatsächlich kompromittiert wird. Das kann auch nur "meistens" [tm] gutgehen, je nachdem wie schnell der kritische Bereich zwischen "alles grün" und "CPU macht überhaupt gar nichts mehr" durchlaufen wird. (re)
das kann man doch durch die PWM Frequenz und die Pulsweite super austesten, wenn man dann diesen Punkt gefunden hat kann man sich um eine ausreichende Pufferung kümmern. Vielleicht auch gleich auf einen 5,5V Goldcap gehen.
hatten mal ein ähnliches problem -> während der eeprom schreibzyklen wurde eine magnetspule aktiviert. diese zog dann die versorgung in die knie und verursachte dann, sehr sehr selten aber doch, einen reset. workaround: die zeitliche abfolge etwas geändert fix: reset und bod lg
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.