Ein Problem, das bestimmt viele kennen:
Immer wieder stehe ich vor der Aufgabe: Einem µController soll als
"Webserver" Daten liefern, z.B. statische HTML Seiten, CSS, Javascript
Code, etc.
Bisher habe ich mir so beholfen, dass ich in meinem C/C++ Code einfach
entsprechende Defines oder Variablen gebaut habe, zB.:
Das funktioniert technisch natürlich einwandfrei. Aber spätestens wenn
man hier Javascript einbinden will, das noch interaktiv entwickelt wird,
ist es eine Quälerei. Bei jeder Änderung muss das Script in einen C/C++
String konvertiert werden, was mit all den verschachtelten
Anführungszeichen und Escape Strings einfach Kacke ist.
Bestimmt gibt es da geschicktere Techniken, so dass man einfach dem
Buildprozess die Quelldateien vor die Füße wirft und diese Daten
irgendwie ins Binary zum Flashen gelinkt werden. Und man braucht im
C/C++ Code natürlich noch irgendeine magisch Methode auf diese Daten
zuzugreifen.
Kann mir jemand erklären (oder auf Erklärungen stubsen), wie sowas geht?
Oder gibt es andere tolle Techniken, die noch jenseits meiner
Vorstellungskraft sind?
Hintergrundkontext: Ich entwickle meinen C/C++ Code in Eclipse mit CDT,
MCUTools, Sloeber Arduino Plugin, ... Oder auch mit STM32CubeIDE.
frutziputzi schrieb:> Kann mir jemand erklären (oder auf Erklärungen stubsen), wie sowas geht?
Im einfachsten Fall: du entwickelst dein HTML/Javascript in *.html/*.js
Dateien, und dein Buildsystem/Makefile bastelt dir daraus mit Hilfe
eines kleinen Scriptes entsprechende C-Files mit "static const char
PROGMEM index_html = ...
"xxd" kann das z.B., allerdings ohne "PROGMEM".
xxd -i index.html
Εrnst B. schrieb:> Im einfachsten Fall: du entwickelst dein HTML/Javascript in .html/.js> Dateien, und dein Buildsystem/Makefile bastelt dir daraus mit Hilfe> eines kleinen Scriptes entsprechende C-Files mit "static const char> PROGMEM index_html = ...> "xxd" kann das z.B., allerdings ohne "PROGMEM".
Wenn man noch eine Schicht einzieht, dann generiert das Script das über
make aufgerufen wird nur andere Dateien indem nur die gewandelten Daten
stehen.
Dann kann man in seiner h/cpp Datei seine Variablen/Member definieren
wie man möchte (Name, Speichertyp,...) ohne das Übersetzungsprogramm
ändern zu müssen.
In der h/cpp Datei erfolgt dann nur die Initialisierung der Variablen
anhand der Datei.
frutziputzi schrieb:> Bestimmt gibt es da geschicktere Techniken, so dass man einfach dem> Buildprozess die Quelldateien vor die Füße wirft und diese Daten> irgendwie ins Binary zum Flashen gelinkt werden.
Du kannst beliebige Datendateien (Binär/Text/Bilder/Whatever) direkt in
.o-Dateien überführen z.B. mit dem objcopy-Befehl:
Und dann einfach mit index.o linken. Im C-Code kannst du dann via
1
#ifdef __cplusplus
2
extern"C"{
3
#endif
4
5
externchar_binary_FILENAME_start;
6
externchar_binary_FILENAME_end;
7
externsize_t_binary_FILENAME_size;
8
9
#ifdef __cplusplus
10
}
11
#endif
zugreifen, wobei dann &_binary_FILENAME_start bis &_binary_FILENAME_end
der Speicherbereich ist und "(size_t) &_binary_FILENAME_size" die Größe
(ja, mit &). Mit "--set-section-alignment" kannst du das Alignment
setzen, falls das z.B. für DMA relevant ist.
Vorteil: Das funktioniert blitzschnell auch mit sehr großen Datenmengen;
C-Compiler mögen sehr große Array-Literals nicht so gern.
Nachteil: Etwas fummelig, funktioniert so nur mit den GNU-Tools
J. S. schrieb:> Es gibt eine Syntax für raw Arrays, damit entfallen die Escape> Sequenzen.
das sind die "raw string literals", und m.w. nur bei C++ vorhanden.
> R"rawliteral(
Eigentlich R"( .... )"
Allerdings kann man zwischen " und ( noch zusätzliche Zeichen angeben &
die Sequenz verlängern, falls die Ende-Sequenz sonst in den Daten
auftauchen würde.
also
R"XYZ( .... )XYZ"
"rawliteral" sagt da also nix spezielles aus, ist einfach nur die
Anpassung des String-Ende-Markers.
frutziputzi schrieb:> Bestimmt gibt es da geschicktere Techniken, so dass man einfach dem> Buildprozess die Quelldateien vor die Füße wirft und diese Daten> irgendwie ins Binary zum Flashen gelinkt werden.
Ich hatte mal ein kleines Perl Script (makefsdata) verwendet, um Dateien
in Arrays umzuwandeln. Das ließ sich recht einfach so ins Makefile
einbinden, dass es unter Linux und Windows läuft. Wenn man den Perl
Interpreter mit ins Projektverzeichnis legt, braucht man ihn nicht
einmal extra zu installieren.
Siehe http://stefanfrings.de/net_io/index.html
Eine Variante dieses Perl Scripts (makefsdata) wird übrigens auch von
lwIP verwendet, das wiederum von ST Cube MX (HAL) verwendet wird.
Offenbar kursiert davon auch eine *.exe im Netz.
Also das mit dem
R"rawliteral( blabla )rawliteral"
ist ja schonmal saugeil und in sehr, sehr vielen Fällen eine super
Lösung!
Danke!
Die Geschichte mit dem objcopy ...
Das geht bestimmt prima mit selbstgebauten Makefiles. Aber das in
Eclipse in den Buildprozess einzubauen ... UooOOOOouuu, das scheint ein
gaaanz tiefes Rabbithole zu werden! Das muss muss ich erst mal
rauskriegen.
Der erste naive Versuch einfach mal im Kontextmenü einer Datei was
einzugeben war zwar zunächst ein Fail. Aber immerhin passiert irgendwas
und jetzt muss ich mal versuchen rauszukriegen, wie ich an das richtige
objcopy komme ....
frutziputzi schrieb:> Das geht bestimmt prima mit selbstgebauten Makefiles. Aber das in> Eclipse in den Buildprozess einzubauen ... UooOOOOouuu, das scheint ein> gaaanz tiefes Rabbithole zu werden!
Ja das geht nicht so elegant.
frutziputzi schrieb:> Aber immerhin passiert irgendwas> und jetzt muss ich mal versuchen rauszukriegen, wie ich an das richtige> objcopy komme ....
Du musst halt avr-objcopy oder arm-none-eabi-objcopy eingeben je nachdem
was das Target ist. Die elf32-little Angabe muss leider auch
Target-Spezifisch angepasst werden, weiß grad nicht was dafür AVR hin
muss.
Hat der WebServer keine Überladung von send für Dateien? Damit kann die
Antwort aus einem Dateisystem kommen und das muss bei Änderungen nicht
kompiliert werden.
> Target-Spezifisch angepasst werden, weiß grad nicht was dafür AVR hin> muss.
Nicht ARM oder AVR, die ESP sind Xtensa.
J. S. schrieb:> Hat der WebServer keine Überladung von send für Dateien? Damit kann die> Antwort aus einem Dateisystem
Öhm - der "Webserver" läuft auf dem µController (z.B. ESP8266, ESP32,
o.ä.). Da gibt es gar kein Dateisystem.
Aber ein Minischrittchen bin ich doch schon weiter:
In Eclipse ist eine Environment Variable "compiler.pat" definiert. Da
drin gibt es auch ein xtensa-lx106-elf-objcopy.exe. So kann ich schon
mal das richtige Tool ansprechen mit
Nur findet es noch nicht die Quelldatei und kotzt mir
xtensa-lx106-elf-objcopy: 'script.js': No such file
Mal gucken, wie ich die Environmentvariable für den Source Folder finde
...
J. S. schrieb:> Hat der WebServer keine Überladung von send für Dateien? Damit kann die> Antwort aus einem Dateisystem kommen
Hat er überhaupt ein Dateisystem?
frutziputzi schrieb:> Da gibt es gar kein Dateisystem.
aber sicher doch, littlefs oder fatfs gibt es als fertige Komponenten
und zumindest der ESP32 hat etwas Platz dafür im Flash. Oder extern über
SDC.
Der ESPAsyncWebserver hat jedenfalls Methoden für das Senden von
Dateien.
Die 'Random Nerds Tutorials' sind da recht gut, z.B.:
https://randomnerdtutorials.com/esp32-web-server-spiffs-spi-flash-file-system/
J. S. schrieb:> frutziputzi schrieb:>> Da gibt es gar kein Dateisystem.>> aber sicher doch, littlefs oder fatfs gibt es als fertige Komponenten> und zumindest der ESP32 hat etwas Platz dafür im Flash. Oder extern über> SDC.> Der ESPAsyncWebserver hat jedenfalls Methoden für das Senden von> Dateien.
Jaja, ok, geschenkt, man KANN auch auf den ESPs sowas wie Dateisysteme
einbinden. Aber ist es klug sich das Flash damit vollzumüllen, wenn die
EINZIGE Aufgabe darin bestünde STATISCHE Daten aus den Flash zu lesen?
(Nein, ist es in den allermeisten Fällen nicht.)
frutziputzi schrieb:> xtensa-lx106-elf-objcopy: 'script.js': No such file
wimre wird der Compiler im Release oder Debug Verzeichnis aufgerufen,
probiere mal './script.js'. Die Environmentvariablen gibt es aber auch,
die kann man sich da auch irgendwo anzeigen lassen.
Gnaa, ich habe einfach zuwenig Ahnung vom Buildprozess.
Immerhin habe ich es hinbekommen, dass mir objcopy meine "script.js.o"
Datei erzeugt. In den Build Logs taucht sie immerhin auch beim archiver
Step als Parameter von xtensa-lx106-elf-ar auf.
Aber das war's dann. Insbesondere finde ich keinen Eintrag in der der
*.map Datei, woraus ich schließe, dass da kein Symbol angelegt wurde.
Fehlt da noch ein Schritt?
Datei im Linker Tab eintragen.
Espressif hat aber sein eigenes CMake Buildsystem, ich weiß nicht ob es
da in den Standardeinstellungen übernommen wird. Wenn es nicht klappt,
dann müsste es eventuell in das CMakelists.txt rein.
J. S. schrieb:> Datei im Linker Tab eintragen
Weia, ich finde keinen Linker Tab. :(
Weder in den Properties der Quelldatei, noch in den Project Properties.
Muss ich mich jetzt schämen?
Ich kann nur 1000 Dank sagen, für die Mühe!
Aber ich glaube hier resigniere ich - zumindest für heute.
Denn ich verwende kein Build System von Espressif, sondern fummle mit
diesem Sloeber arduino-eclipse-plugin rum (um ein paar Arduino Libs
bequem einbinden zu können).
Dieses IDF kenne ich (noch) nicht. Mal gucken, vielleicht ist das ja
interessant.
(Wofür auch immer IDF stehen mag... "In Die Fresse"? :D)
Auf jeden Fall vielen Dank für diesen erfreulich guten Thread!
Irgendwo ist da eingestellt ob der interne builder oder etwas externes
benutzt wird. Vermute sehr stark extern cmake, das ist Zuviel für das
alte Build System.
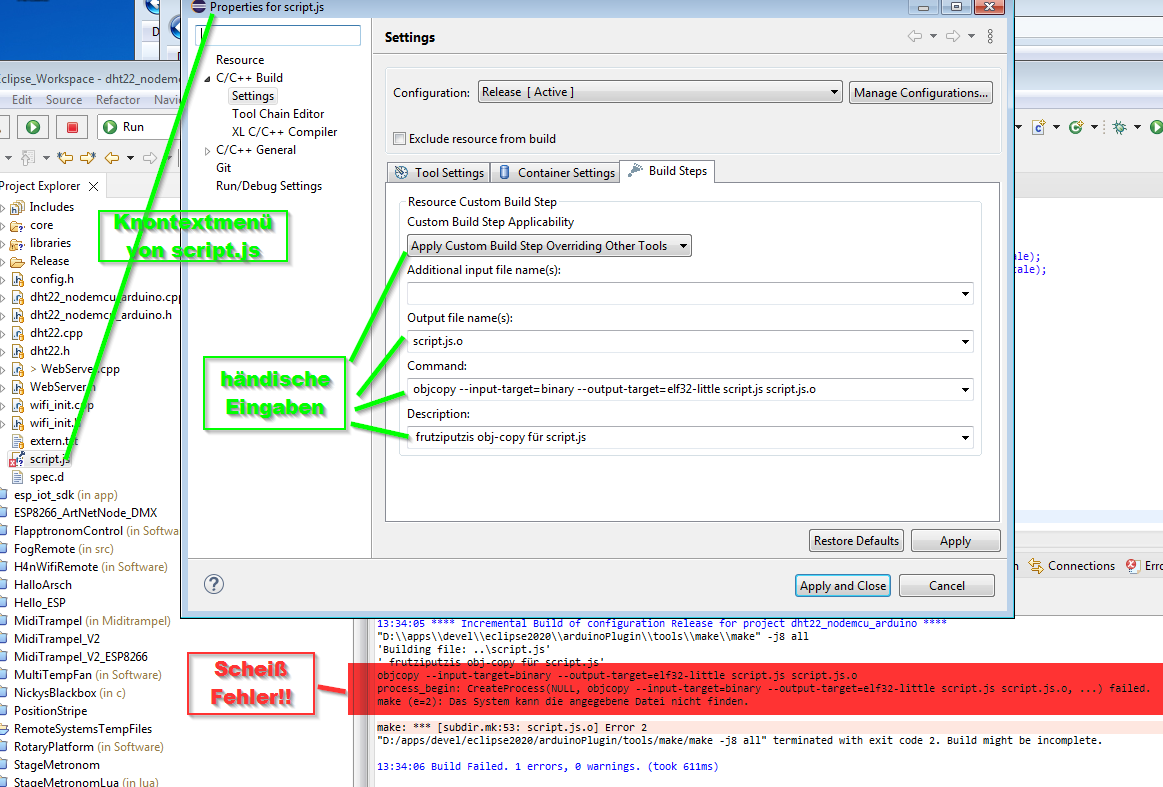
Ich bin in dem Rabbithole etwas tiefer:
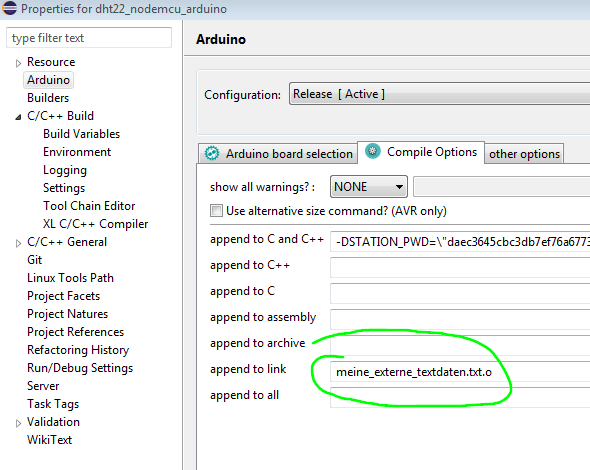
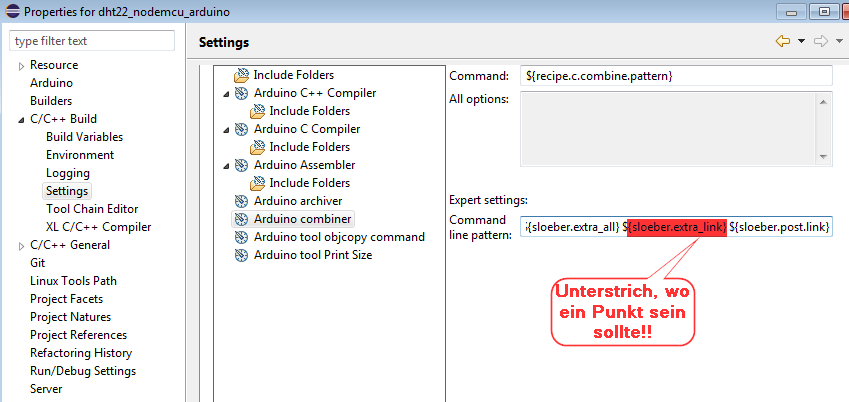
Grundsätzlich scheint es so zu sein, dass man bei diesem Sloeber Arduino
Plugin zusätzliche Link Ressourcen in den Project Properties unter
"Arduino" -> "Compile Options" -> "append to link" angibt. (erstes Bild)
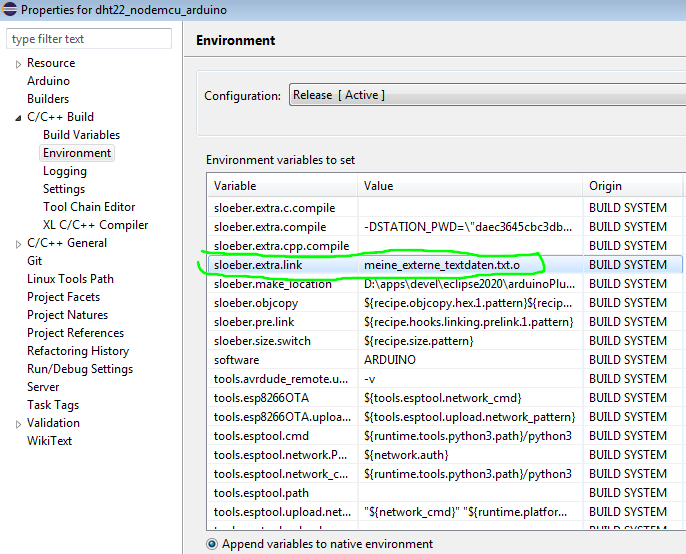
Dadurch wird offenbar die Environment Variable "sloeber.extra.link"
befüllt. (zweites Bild)
Auf diese soll wohl in den "C/C++ Build" -> "Settings" vom "Arduino
combiner" (was der Linker zu sein scheint) zugegriffen werden. Doch in
dem Eintrag, der dort generiert wurde, ist die Variable als
sloeber.extra_link falsch geschrieben (Unterstrich statt Punkt). Nachdem
ich das korrigiert hatte, versuchte tatsächlich der Buildprozess auch
meine händisch eingetragene *.o Datei zu linken. Soweit so gut ...
Aaaber! Leider kommt der Linker wohl nicht mit den per objcopy
generierten Daten klar und kotzt mich an mit:
1
d:/apps/devel/eclipse2020/arduinoplugin/packages/esp8266/tools/xtensa-lx106-elf-gcc/2.5.0-4-b40a506/bin/../lib/gcc/xtensa-lx106-elf/4.8.2/../../../../xtensa-lx106-elf/bin/ld.exe: unknown architecture of input file `meine_externe_textdaten.txt.o' is incompatible with xtensa output
Ich hatte auch andere output-target Formate versucht (elf32-xtensa-le
elf32-xtensa-be elf32-little elf32-big), aber ohne Erfolg.
Dödödöommm! (Failgeräusch bitte selber vorstellen)
Da stehe ich wieder auf dem Schlauch und weiß nicht weiter. :(
frutziputzi schrieb:> Nachdem> ich das korrigiert hatte, versuchte tatsächlich der Buildprozess auch
wo hast du das korrigiert? Ich habe den Sloeber auch nochmal installiert
und konnte das soweit nachvollziehen. Die Einträge im 'append to link'
wurden ignoriert und tauchten nicht im Linkaufruf auf.
edit: hatte die Bilder nicht angesehen, ist jetzt klar.
Ich denke du bist da in der falschen toolchain, ich habe da
xtensa-esp32-elf-objcopy.exe.
Dann ist im Symbolnamen der generiert wird der Pfad mit reinkodiert,
Punkte und slashes werden durch Unterstrich ersetzt. Die Namen sieht man
wenn man das .o file öffnet oder korrekter mit objdump -t.
kleine Korrektur: welchen ESP verwendest du, für den ESP8266 wäre das
wohl richtig.
Ja, ich verwende ein ESP8266, in diesem konkreten Fall in Form so eines
"D1 mini" Moduls, mit 3V3 Spannungsregler und CH340G USB-UART Baustein.
Schmeiße ich das *.o file dem objdump.exe vor, listet mir das durchaus
vielversprechende Informationen:
meine_externe_textdaten.txt.o: file format elf32-little
4
5
SYMBOL TABLE:
6
00000000 l d .data 00000000 .data
7
00000000 g .data 00000000 _binary_D__Usr_PhPe_e_tronic_git_work_dht22_nodemcu_arduino_Software_meine_externe_textdaten_txt_start
8
00000014 g .data 00000000 _binary_D__Usr_PhPe_e_tronic_git_work_dht22_nodemcu_arduino_Software_meine_externe_textdaten_txt_end
9
00000014 g *ABS* 00000000 _binary_D__Usr_PhPe_e_tronic_git_work_dht22_nodemcu_arduino_Software_meine_externe_textdaten_txt_size
Interessant finde ich dabei dass objdump als file format "elf32-little"
ausgibt, egal ob ich in objcopy nun elf-little oder elf32-xtensa-le
angegeben hatte.
Das bescheuerte dabei ist: prüfe ich mit objdump mal andere *.o Dateien
(die beim Compilieren erzeugt wurden), dann ist dort das file format
elf32-xtensa-le.
Das halte ich für einen starken Hinweis, dass der Linker eigentlich
elf32-xtensa-le sehen möchte. Kriege ich nur nicht per objcopy erzeugt.
Grrrr!
und deinem fix compiliert es dann.
was noch nicht heißt das es damit dann läuft...
1
#ifdef __cplusplus
2
extern"C"{
3
#endif
4
5
externconstchar_binary____script_js_start;
6
7
#ifdef __cplusplus
8
}
9
#endif
10
11
...
12
13
Serial.println("Testmessage: '");
14
Serial.println(&_binary____script_js_start);
15
Serial.println("'");
und schon funktioniert es. Wobei man noch prüfen müsste ob im objcopy
die richtige section für die Daten angegeben wurde.
und man muss noch eine 0 hintendran basteln, es ist keine Null
Terminierung vorhanden wenn man das als String betrachtet, die Ausgabe
wirft noch ein paar Müllzeichen hinterher.
Oooookaaaay! H E U R E K A A A A A!!
Es gab noch Hürden, aber jetzt geht's!
Nachdem ich die richtigen Parameter für's objcopy eingetragen hatte,
meckerte der Linker schon mal nicht mehr. Aber da ich zunächst die Daten
im Code noch nicht referenziert hatte, hat er den Inhalt offenbar weg
optimiert und in den erzeugten Binaries war nichts mehr davon drin.
Als ich dann die externen Daten referenzierte, so wie Du es mir
geschrieben hattest, kotzte der Linker zunächst wegen doppelten
Symbolen. HÄÄÄ?!?
Aber wenn ich aus den "append to link" Optionen den manuellen Eintrag
auf die *.o Datei wieder entfernte, funktionierte alles! Der
Buildprozess konnte offenbar selbsttätig irgendwo erkennen, dass die *.o
Datei jetzt gültig ist und linkte sie automatisch. Hypothese: Ohne die
objcopy Angabe "--rename-section .data=.rodata.embedded" wusste der
Linker nicht wohin mit den Binärdaten und hat sie einfach ignoriert.
Das gibt leider ein bißchen ein Henne<->Ei Problem. Solange die Labels
im Code noch nicht referenziert werden, werden sie weg optimiert. Wenn
sie weg optimiert werden, kennt man sie nicht, um sie im Code zu
referenzieren.
Fazit: Man kann Binärressourcen dazu linken.
1.) Ressourcendatei in den Projektordner werfen
2.) Im Kontextmenü der Ressourcendatei "Properties" -> "C/C++ Build" ->
"Settings" -> "Build Steps"
3.) Dort konfigurieren:
- "Apply Custom Build Step Overriding Other Tools"
- Output file name(s): <ressourcendateiname>.o
- Command: $(compiler.path)xtensa-lx106-elf-objcopy
--input-target=binary --output-target=elf32-xtensa-le
--binary-architecture xtensa --rename-section .data=.rodata.embedded
$(build.source.path)/<ressourcendateiname> <ressourcendateiname>.o
4.) erstmal kompilieren um die Labels erzeugen zu lassen
5.) im Zielverzeichnis (z.B. "Release") <ressourcendateiname>.o auf
Labels untersuchen (objdump -t).
6.) im Code referenzieren mit
(Klassische Stolperfalle: Die Binärdaten sind keine nullterminierten
Strings! :D)
@jojos: Im RL hätte ich Dir gerne zwei..drei Bier ausgegeben!
DAAAAANKEEEE!
Was an der ganzen Methode allerdings Mist ist: Der komplette Pfad zur
Ressourcendatei ist Bestandteil des Labels. Das zerstört die
Portabilität des Projekts, da diese Pfade ja nicht auf jedem
Entwicklerrechner die selben sind.
frutziputzi schrieb:> Im RL hätte ich Dir gerne zwei..drei Bier ausgegeben!> DAAAAANKEEEE!
auf den Fehler im Sloeber Plugin bin ich ja auch nicht gekommen, also
geben wir uns beide einen aus :)
Ich habe das objcopy in den pre-build step eingetragen, damit wird das
.o vorab erzeugt. Wenn das build System die Datei nicht als Quelle
erkennt, dann passiert vielleicht auch nicht das gewünschte.
Vielleicht mal ein clean machen oder das Release Verzeichnis löschen.
Das doppelte Symbol müsste eine andere Ursache haben.
Das verlinkte makefile stammt aus dem ESP-IDF, das steckt da hinter dem
embed das in deren Doku genannt wird. Etwas weiter danach sieht man das
die für die Textdateien eine 0 anhängen was für die Benutzung als String
dann bequemer ist.
mit ../resourcendateiname wird der Symbolname kürzer (wenn die Datei in
der Projektroot liegt). Man kann das Symbol auch mit --redefine-sym
umbenennen, was automatisiert aber auch nur durch die Brust ins Auge
geht. Interessant ist dazu:
https://stackoverflow.com/questions/15594988/objcopy-prepends-directory-pathname-to-symbol-name
Das über ein Assembler Templatefile zu machen finde ich dann doch etwas
nerdig, aber auch da kann man einfach die 0 anhängen.
Ich fand den Exkurs auf jeden Fall auch interessant, auch wenn Sloeber
nicht mein Liebling ist und wird. Aber ich sehe es als Bereicherung an
wenn man mit mehreren Werkzeugen umgehen kann.
edit zum Linkerfehler:
habe ich nicht, wenn ich das script.o aus dem 'append to linker'
rausnehme gibts es wie erwartet ein undefined Symbol. Hast du es bei den
Experimenten vlt. noch woanders eingebaut?
das Release wird vor dem build gelöscht, da ist also auch kein clean
nötig.
noch nicht fertig...
der Fehler tritt auf wenn der Build Step per Datei eingetragen wird, in
dem Fall baut das build System das .o in das archive ein das aus allen
Quellen erzeugt wird. Wenn es dann zusätztlich beim Linker angegeben
wird, dann existert das Symbol tatsächlich zweimal.
1
script.o: In function `_binary____script_js_end':
2
(.rodata.embedded+0x16b): multiple definition of `_binary____script_js_end'
3
C:\Users\super\Documents\sloeber-workspace\Test2\Release/arduino.ar(script.o):(.rodata.embedded+0x16b): first defined here
Also nur im Kontextmenu der Datei eintragen ist besser, das umgeht dann
auch den Linkerfehler in Sloeber. Was man im trotzdem melden sollte, bin
aber nicht im Arduino.cc Forum angemeldet.
J. S. schrieb:
> mit ../resourcendateiname wird der Symbolname kürzer (wenn die Datei
in
> der Projektroot liegt).
Super! So gehen keine absoluten Dateipfade in die Symbolnamen ein und
der ganze Hack wird wieder sinnvoll!
> Das über ein Assembler Templatefile zu machen finde ich dann doch etwas> nerdig, aber auch da kann man einfach die 0 anhängen.
Den Weg werde ich auf jeden Fall mal probieren. Das wäre deshalb toll,
weil man da nicht soviel im Buildsystem rum hacken muss.
> Sloeber nicht mein Liebling
Hast Du interessante Alternativen um einfach Arduino Bibliotheken zu
verwenden?
> edit zum Linkerfehler:> habe ich nicht, wenn ich das script.o aus dem 'append to linker'> rausnehme gibts es wie erwartet ein undefined Symbol. Hast du es bei den> Experimenten vlt. noch woanders eingebaut?
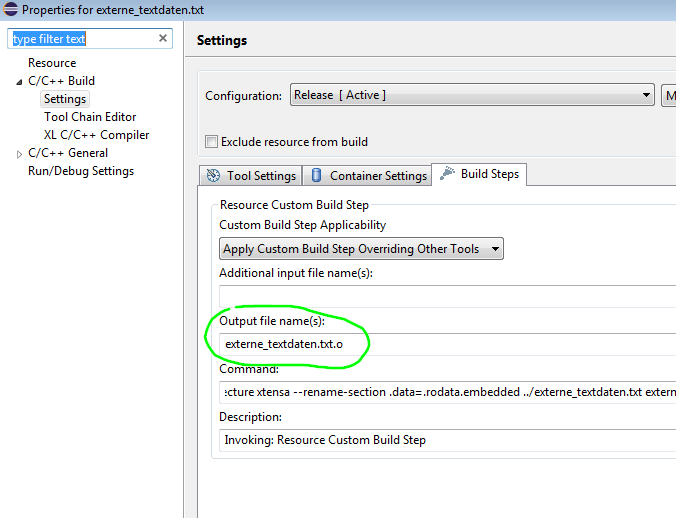
Ich habe in den spezifischen Properties der Ressource (nicht
Projektproperties) bei "Output file name(s)" eingetragen. (siehe
Screenshot). Ich denke damit ist es zu einem Target im Buildprozess
geworden und jede weitere Stelle, wo man das noch einträgt, führt dann
zu Fehlern wegen doppelten Symbolen.
frutziputzi schrieb:> Ich denke damit ist es zu einem Target im Buildprozess> geworden und jede weitere Stelle, wo man das noch einträgt, führt dann> zu Fehlern wegen doppelten Symbolen.
ja, das kann man auch im Projektbaum sehen. Archieves/Arduino.ar
aufklappen, da ist script.o mit drin, das macht das build system. Und
dann liegt da noch das script.o in Release/ was jetzt nicht noch
zusätzlich gelinkt werden darf.
frutziputzi schrieb:> Hast Du interessante Alternativen um einfach Arduino Bibliotheken zu> verwenden?
Beliebt ist ja mittlerweile Platformio. Ist für den Anfang auch
gewöhnungsbürftig, kann aber auch sehr viel. Und man kann Projekte mit
Arduino oder IDF Framework erstellen. Wobei letzteres auch 'Arduino as
component' kennt. Das hatte mir im ersten Versuch auch gleich einen
Fehler um die Ohren gehauen, finde ich aber sehr interessant wenn man
mal die IDF Beispiele durchsieht. Bei den IDF Projekten muss man aber
erstmal mit dem Configsystem klarkommen.
Und Cmake als Buildsystem, sehr mächtig aber muss man auch erstmal
lernen.
Insgesammt ist mir VisualStudio Code angenehmer, aber das ist das ja
Geschmack/Gewohnheitssache.
Ok, dieses Platformio schaue ich mir mal bei Gelegenheit an.
Zwischendurch habe ich jetzt die Variante mit dem Assembler .incbin
Trick ausprobiert: Gefällt mir wunderbar! Da steckt das Knowhow in den
Quelldateien und nicht in irgendwelchen kryptischen Tiefen des
Buildsystems, wo man sich nach zwei Wochen nicht mehr dran erinnern
kann, wie die Kniffe funktionierten. Das Stringterminierungsproblem ist
auch noch gleich erschlagen. Like!
top, was ich nicht verstanden hatte ob man für jedes File eine
Assmblersource anlegt oder mehrere Binärdateien in einem anlegt. Geht
vermutlich beides, mit Assemblermacros sogar elegant.
Zu PIO: viele 'große' Projekte wie Marlin, Tasmote, ESPEasy, FluidNC,
WLED, usw. nutzen das mittlerweile als Entwicklungsplattform. Für den
Einstieg hat die Arduino IDE ihre Berechtigung, aber für größere
Projekte/mehr Komfort sollte man sich das ansehen.
Mit .incbin habe ich das auch kompiliert, aber es crasht mit Guru
Meditation. hast du die Section definition da reingebracht?
ok, eine ConvertTextfile.S mit diesem Inhalt funktioniert:
1
.section .rodata.embedded
2
.global script_start
3
script_start:
4
.incbin "../script.js"
5
6
.global script_end
7
script_end:
8
.byte 0
9
10
.global script_size
11
script_size:
12
.int script_end - script_start
gefällt mir auch besser weil es dann unabhängiger vom build system wird.
das macht weitere Forschungen wohl überflüssig... Und es sieht sehr
portabel aus.
ich habe es noch mit dem Macro proiert, ist eigentlich auch nicht so
kompliziert. Es klappt noch nicht, die Übergabe des filename ist falsch.
Damit wäre es auch einfacher mehrere Dateien anzugeben ohne
fehlerträchtiges copy&paste der Symbolnamen.
1
.section .rodata.embedded
2
3
.macro conv_textfile symname, filename
4
.global \symname\()_start
5
\symname\()_start:
6
.incbin \filename
7
8
.global \symname\()_end
9
\symname\()_end:
10
.byte 0
11
12
.global \symname\()_size
13
\symname\()_size:
14
.int \symname\()_end - \symname\()_start
15
.endm
16
17
conv_textfile script, "../script.js"
der Neugier halber: wie macht man das richtig dem incbin den Namen aus
dem macro zu übergeben?
edit:
ok, habe es und es funktioniert: