Wenn ich die angehängte Datei unter Linux mit einem pdf-Viewer öffne, sieht sie ganz normal aus. Wenn man aber Text daraus in die Zwischenablage kopiert und in einen Editor pastet, bekommt man nur Steuerzeichensalat. Woran liegt das?
Das wird daran liegen, daß die Datei einen eingebetteten Font enthält, der nur die tatsächlich verwendeten Glyphen enthält. Um aufwendige Umcodierungstabellen wegzulassen, werden die einfach durchnumeriert und der Text so umcodiert, daß er diese durchnumerierten Glyphen nutzt.
In dem Fall bestehen die Buchstaben aus Bilddaten, sind also kein tatsächlicher Text, und die Zuordnungen in der Datei sind falsch. Kaputtes OCR, oder Absicht – wobei es bei „Absicht” wohl einfacher gewesen wäre, überhaupt keine Zuordnungen einzubetten …
Ja, das scheint plausibel zu sein: die Datei lässt sich zwar durchsuchen, aber es wird nichts gefunden, wenn man den Suchbegriff per Tastatur eingibt. Kopiert man ihn dagegen aus dem Text, dann wird der Text gefunden. Eine sinnvolle "Optimierung" ist das wohl eher nicht…
Jack V. schrieb: > In dem Fall bestehen die Buchstaben aus Bilddaten Das sind die Glyphen, von denen DerEgon schrieb.
Taucher schrieb: > Das sind die Glyphen, von denen DerEgon schrieb. Nein. Das sind schlicht Bilddaten. Die Glyphen sind in der Zuordnung. Sowas produzieren beispielsweise OCR-Programme: angezeigt wird die gescannte Seite als Bild, man kann augenscheinlich trotzdem markieren – allerdings werden nicht die Sachen, die man sieht, markiert, sondern die Sachen, die intern mit der entsprechenden Stelle auf der Seite verknüpft sind. Und diese Zuordnung ist hier falsch.
Willst du den Guttenberg machen? Selbst der wäre darauf gekommen es einfach auszudrucken und wieder einzuscannen.
Jack V. schrieb: > Nein. Das sind schlicht Bilddaten. Die Glyphen sind in der Zuordnung. Nein. Glyphen sind eine spezielle, individuelle bildliche Darstellung eines Schriftzeichens. So kann etwa die Glyphe "Trema" je nachdem einen Umlaut oder eine Diaerese markieren (auch wenn man das bei Unicode anscheinend nicht so ganz kapiert hat).
Percy N. schrieb: > Nein. Glyphen sind eine spezielle, individuelle bildliche Darstellung > eines Schriftzeichens. Ich habe „Glyphen“ in diesem Kontext übernommen, damit dem Adressaten der Bezug klar ist. Ist auch nicht der relevante Punkt – der ist, dass die PDF-Datei eben keinen Text mittels Font darstellt, sondern das, was man im Reader sieht, Bilder sind, die so in der Datei vorliegen, und man so eben gar nicht den „Text“ markieren/kopieren kann, den man sieht. Es stünde dir gut, deine Pedanterie hier unter Kontrolle zu halten, btw. – oder aber deine Analysen korrekt durchzuführen.
DerEgon schrieb: > Das wird daran liegen, daß die Datei einen eingebetteten Font enthält, > der nur die tatsächlich verwendeten Glyphen enthält. Um aufwendige > Umcodierungstabellen wegzulassen, werden die einfach durchnumeriert und > der Text so umcodiert, daß er diese durchnumerierten Glyphen nutzt. Ja. Jack V. schrieb: > In dem Fall bestehen die Buchstaben aus Bilddaten, sind also kein > tatsächlicher Text Nein. Jack V. schrieb: > Nein. Das sind schlicht Bilddaten. Die Glyphen sind in der Zuordnung. > Sowas produzieren beispielsweise OCR-Programme: Nein. Jack V. schrieb: > Es stünde dir gut, deine Pedanterie hier unter Kontrolle zu halten, btw. > – oder aber deine Analysen korrekt durchzuführen. So so. Im offensichtlichen Gegensatz zu dir habe ich solche PDF mit embeddeten komprimierten Fonts schon erzeugt - das geht völlig anders als ein PDF von aufgereihten Bildern.
MaWin schrieb: > Jack V. schrieb: >> In dem Fall bestehen die Buchstaben aus Bilddaten, sind also kein >> tatsächlicher Text > > Nein. Dann öffne diese Datei, und stelle die höchste Zoom-Stufe ein. Mach das mit einer Datei mit tatsächlichem Text. Vergleiche, und erkläre den Unterschied. MaWin schrieb: > Im offensichtlichen Gegensatz zu dir habe ich solche PDF mit embeddeten > komprimierten Fonts schon erzeugt - das geht völlig anders als ein PDF > von aufgereihten Bildern. Und wie hast du’s gemacht, dass die Markierung nicht das erfasst, was dargestellt wird? MaWin schrieb: > So so. … Bezug war Percys threadzerlegende OT-Spitzfindigkeit.
Der gimagereader braucht ziemlich lange, um nur diese Seite zu erkennen. Für einen längeren Text wäre das nervenaufreibend. Anscheinend wurden manche Zeichen durch Unicode ersetzt, hier der Apostroph, je nach Editor falsch dargestellt: the user’s requirements (clustered ‘on the fly’)
Jack V. schrieb: > Bezug war Percys threadzerlegende OT-Spitzfindigkeit. Leider hast Du nun einmal Unsinn erzählt; DerEgon hatte völlig Recht. Und da Du ja sicherlich nicht dumm genug bist, um im Irrtum beharren zu wollen, solltest Du Dich über die kleine Hilfe von der Seite eigentlich nur freuen.
Angehängte Dateien:
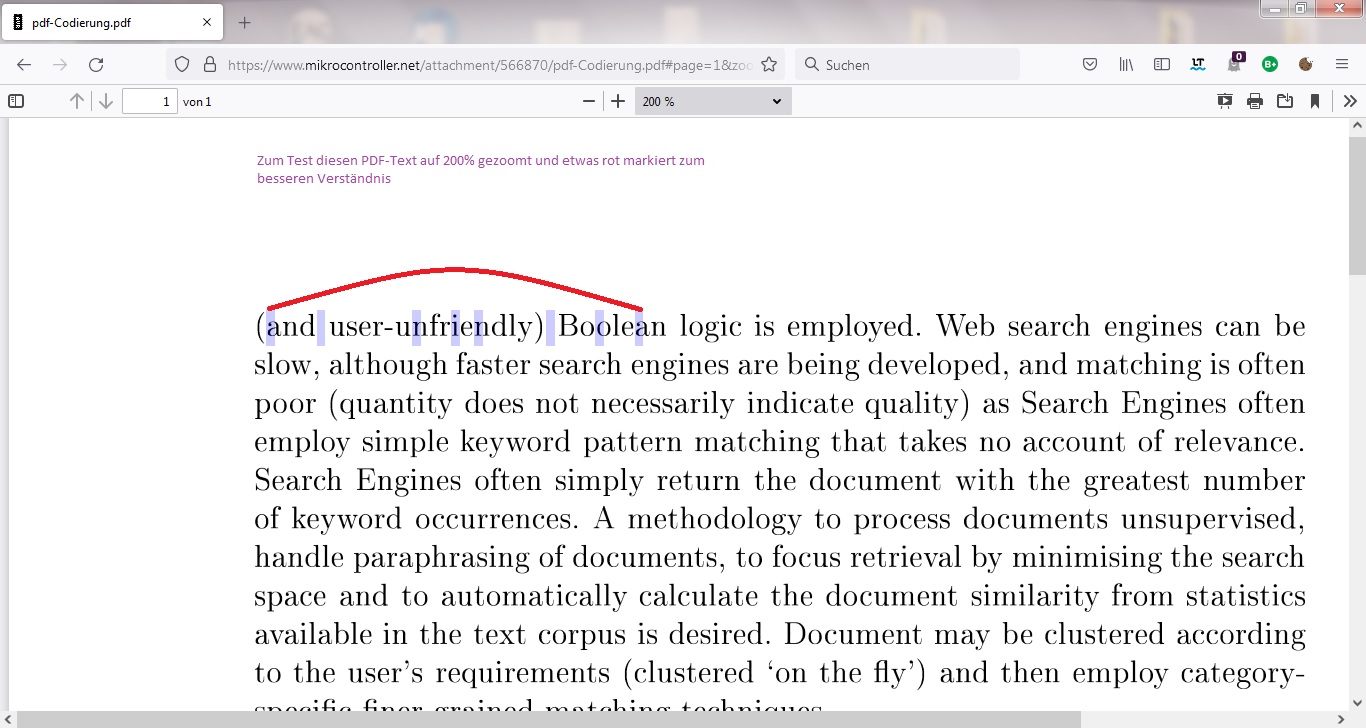
Nun habe ich mal das Taucher-Beispiel zur Analyse auf 200% gezoomt ohne Probleme und dann etwas markiert. Wie man sieht, macht schon das Markieren Probleme. Es ist anzunehmen, dass nicht einzelne Buchstaben als Bilder, sondern, sondern einige Elemente zusammengefasst zu Bildern verwurstelt wurden.
Angehängte Dateien:
-

Okular.jpg
50 KB

Der PDF-Betrachter Okular will im markierten Text nach Telefonen suchen.
Taucher schrieb: > Woran liegt das? Woran das liegt, haben andere ebenso freundliche wie kompetente Teilnehmer dieses Threads ja schon erklärt. Der Vollständigkeit halber möchte ich allerdings darauf hinweisen, wie man trotzdem mit relativ überschaubarem Aufwand an den Inhalt der PDF-Datei als Plaintext kommt: zuerst wird das PDF mit pdftoppm in ein Netpbm-Bild konvertiert und dieses dann mit dem OCR-Programm tesseract in Text umgewandelt:
1 | ein@typ$ ls |
2 | pdf-Codierung.pdf |
3 | ein@typ$ pdftoppm pdf-Codierung.pdf pdf-Codierung |
4 | ein@typ$ ls |
5 | pdf-Codierung-1.ppm pdf-Codierung.pdf |
6 | ein@typ$ tesseract pdf-Codierung-1.ppm pdf-Codierung |
7 | Tesseract Open Source OCR Engine v4.1.1 with Leptonica |
8 | Warning: Invalid resolution 0 dpi. Using 70 instead. |
9 | Estimating resolution as 193 |
10 | ein@typ$ head pdf-Codierung.txt |
11 | (and user-unfriendly) Boolean logic is employed. Web search engines [...] |
HTH, YMMV. Edit: Typo korrigiert.
Angehängte Dateien:
-

ghex.png
56 KB
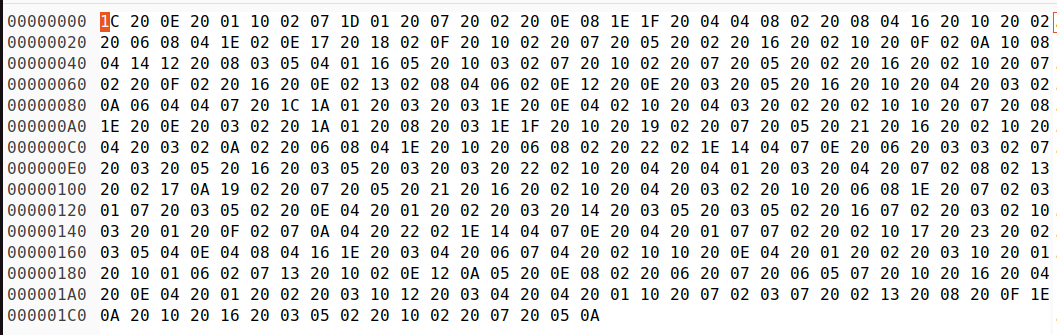
ja so ähnlich hatte ich das oben auch gemacht. gimagereader ist eine graphische Oberfläche für tesseract und mit dem PDF-Betrachter Okular konnte ich die Seite als Bild abspeichern. Die Methode Guttenberg (copy&paste) liefert mir diese Hexcodes eines Teilausschnitts. Interessant ist vielleicht die geringe Anzahl von High-Bits, was auch für eine Speicherung als Pixel spricht.
N.B. hier scheint die Quelle des Textes zu sein: https://www.academia.edu/805484/Hierarchical_word_clustering_automatic_thesaurus_generation Hier hatten wir ja einen ähnlichen Fall: Beitrag "Knacknuss Text aus PDF extrahieren"
https://www.researchgate.net/publication/220551661_Hierarchical_word_clustering_-_Automatic_thesaurus_generation hier kann man das PDF herunterladen, es ist anscheinend nachträglich mit dem Text hinterlegt, enthält auch OCR-Schreibfehler aber wenigstens durchsuchbar.
Ein T. schrieb: > Der Vollständigkeit halber > möchte ich allerdings darauf hinweisen, wie man trotzdem mit relativ > überschaubarem Aufwand an den Inhalt der PDF-Datei als Plaintext kommt: > zuerst wird das PDF mit pdftoppm in ein Netpbm-Bild konvertiert und > dieses dann mit dem OCR-Programm tesseract in Text umgewandelt: Ich habs mit ABBYY Finereader in einem Abwasch hinbekommen – und zwar, bevor ich hier gefragt habe…
Christoph db1uq K. schrieb: > hier kann man das PDF herunterladen Wow, wie hast du das gefunden? Meine Version stammt von einem Preprint-Server.
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.