

Ich generiere mit dem PLL 2 clk: 100 sowie 400MHz, beide ohne Phasenverschiebung. Mit dem 400MHz clk speise ich den Altera Serdes block welcher die SPI slave Signale (NSS, SCK, MOSI) mit 400MHZ abtastet und entsprechend in einem 12bit Vektor mit 100MHZ bereitstellt. Dieser 12bit Vektor wird beim nächsten Block welcher mit dem 100mhz Signal ge'clk't wird verwendet. Der timing analyzer meldet nun genau diesen Vektor mit negativem slack, auffällig ist der Relationship wert von 2.5. Habe ich hier ein echtes timing Problem oder versteht der Timing analyzer nicht dass der Serdes ein Signal mit 100MHZ generiert?
Angehängte Dateien:
-

TimingSlack.PNG
25 KB -

TimingSlack.PNG
25 KB
Typischerweise macht die Timinganalyse dort keine Fehler.
Vermutlich wird eines der Quell-Flipflop mit 400Mhz getaktet und du
bekommst deshalb den Taktübergang.
Kannst du leicht prüfen wenn du in Timequest die Quelle anschaust("From
Node") und im Code prüfst mit welchem Takt diese abeitet.
Angehängte Dateien:
-

serdes1.PNG
41 KB -

serdes2.PNG
51 KB -

serdes3.PNG
52 KB
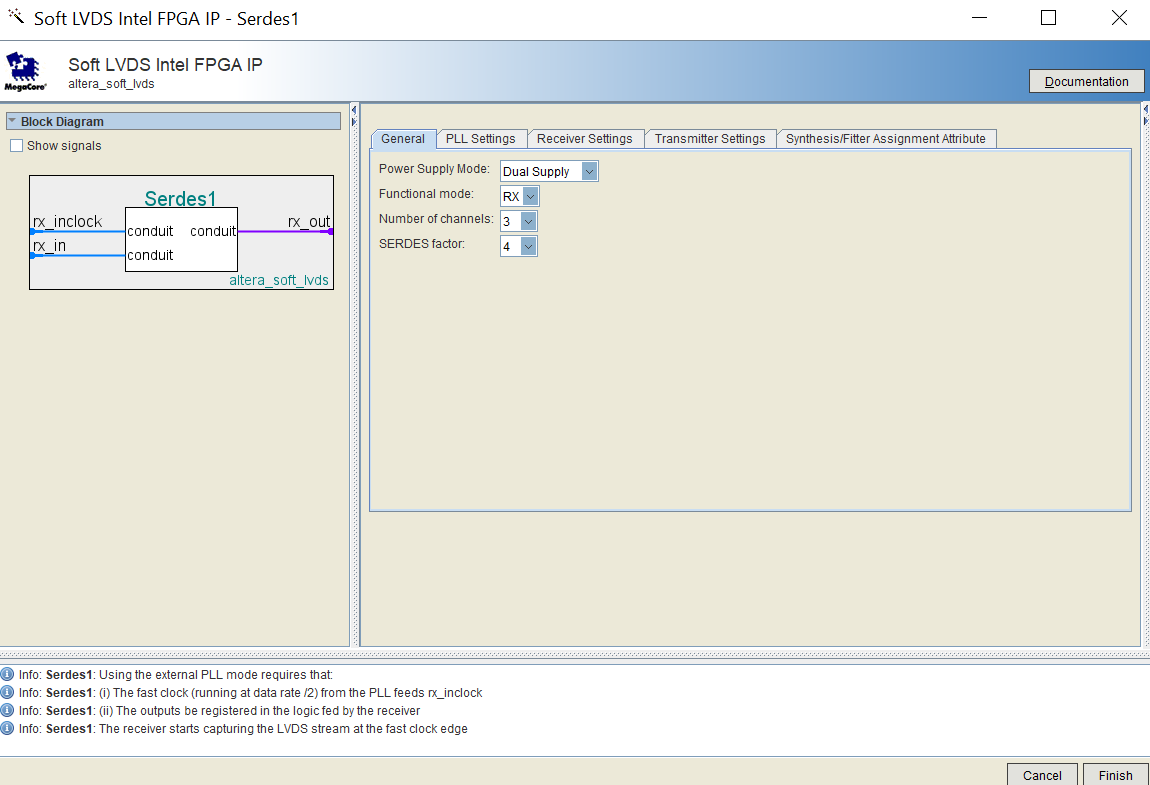
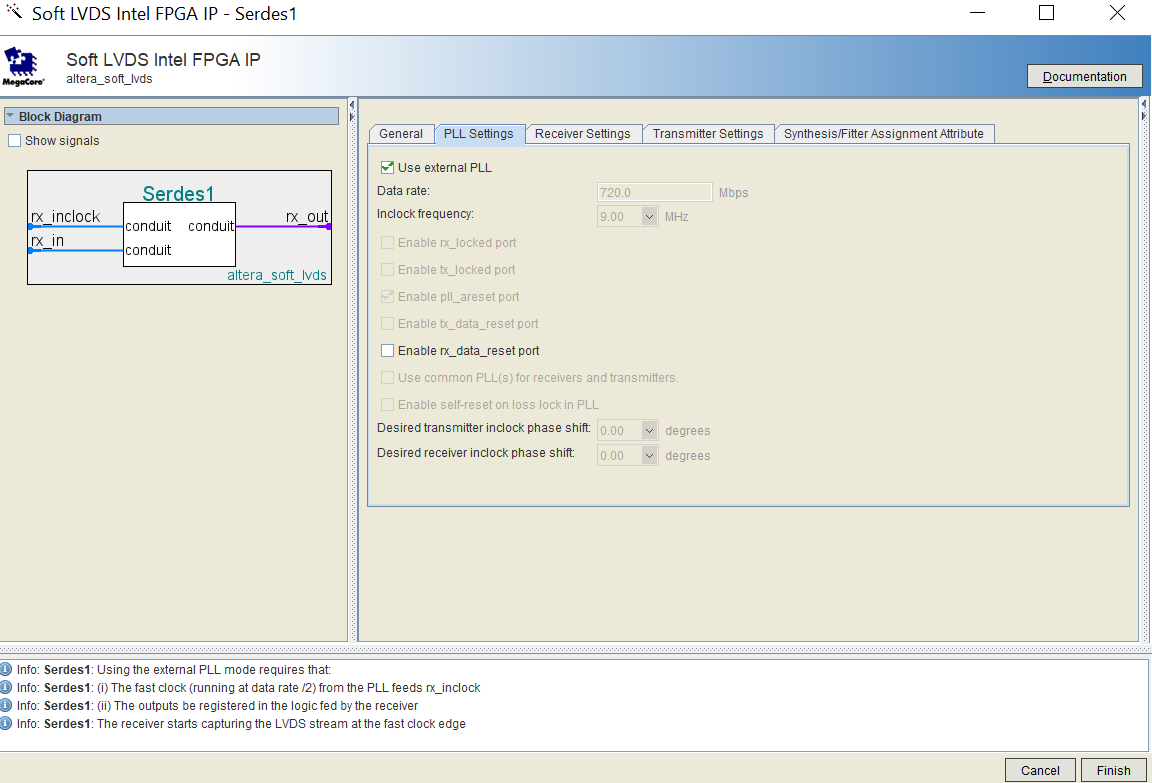
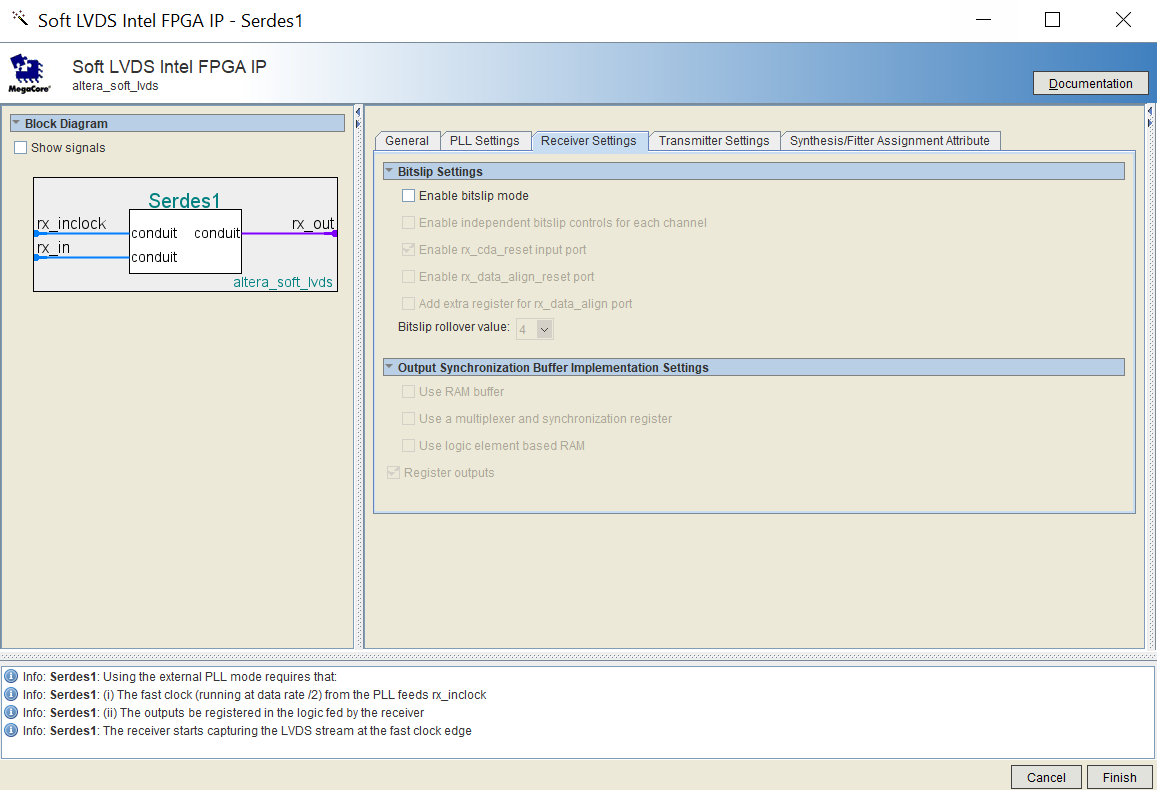
FPGAzumSpass schrieb: > Vermutlich wird eines der Quell-Flipflop mit 400Mhz getaktet und du > bekommst deshalb den Taktübergang. Danke. Dies ist gem. launch clock der Fall. Launch clock scheint der 400MHZ und Latch der 100MHZ. Launch ist im Altera SERDES block, der "datenändernde" Launch sollte gemäss funktionalität des IP Blocks nur mit 100MHz erfolgen. Deutet die Relationship von 2.5 nicht darauf hin dass der analyzer von der effektiven Datenänderung von 100MHz nichts weiss und die Sache gem. 400MHz bewertet, was das FPGA nicht schafft? Da sich die Quelle ebenfalls intern im Altera IP block befindet, die frage: wie mit diesem negativen slack Problem angehen/umgehen?
Wenn das Quellflipflop mit 400Mhz getaktet ist, dann muss die Timing Analyse auch auf 2.5ns prüfen, denn der Zustand des Quell-FF könnte sich ändern während das Nachfolgende FF mit 100Mhz latched. Das Ziel FF muss also sozusagen in 2.5ns latchen können, sonst hast du Zufall drin. Um das Problem zu lösen würde ich zuerst probieren den Vektor in 400Mhz noch einmal zu latchen, weil es das Routing dann leichter hat den Übergang auf 100Mhz zu schaffen. Dann solltest du prüfen ob bei dem Wechsel von 400 auf 100 noch irgendwelche Logik außer einem Clockenable mit im Spiel ist. Falls ja, dann erst die Daten ohne Bedingung in 100Mhz FFs überführen und erst im nächsten Takt mit diesen weiterarbeiten. Wenn das auch noch nicht klappt kann man diesen 400->100Mhz Übergang auch noch mit einem Multicycle Path versehen. Denke aber nicht das es notwendig sein wird, denn der Clock Skew scheint sehr gering zu sein, also sollte das machbar sein.
Du willst also mit dem FPGA SPI Slave spielen? Das geht auch ihne SerDes direkt mit SCK als Clock. Synchron dazu kommen die Daten auf MOSI und werden ausgegeben auf MISO. CS ist asynchron. Aber auch das kann man in der HDL Beschreibung schön abfragen.
FPGAzumSpass schrieb: > Wenn das Quellflipflop mit 400Mhz getaktet ist, dann muss die Timing > Analyse auch auf 2.5ns prüfen, denn der Zustand des Quell-FF könnte sich > ändern während das Nachfolgende FF mit 100Mhz latched. Das Ziel FF muss > also sozusagen in 2.5ns latchen können, sonst hast du Zufall drin. ist dies auch der Fall wenn das die 400MHz Quelle die Daten nur alle 4 clk ändert? Also mir scheint, dass der Timing analyser nicht weiss, dass sich der 400MHz latch nur mit effektiv 100MHz ändert und daher latchen in 10ns genügen würde. Oder verstehe ich etwas falsch und es wiederspricht Designregeln ein schneller getaktetes Latch welches den wert nicht ändert längsämer abzutasten ? FPGA NOTFALLSEELSORGE schrieb im Beitrag #7159057: > Du willst also mit dem FPGA SPI Slave spielen? > Das geht auch ihne SerDes direkt mit SCK als Clock. Synchron dazu kommen > die Daten auf MOSI und werden ausgegeben auf MISO. Ja wäre eine saubere Lösung. Es existieren 2 Probleme: 1. SCK ist nicht auf einem designierten clk input pin. Dies Aufgrund Punkt 2. 2. Der SPI Master clockt sck nur während des Transfers.
FPGAzumSpass schrieb: > Um das Problem zu lösen würde ich zuerst probieren den Vektor in 400Mhz > noch einmal zu latchen, weil es das Routing dann leichter hat den > Übergang auf 100Mhz zu schaffen. Wo soll das Vorteile bringen? Sofern nicht direkt output register aus dem SERDES-Block genutzt werden können, ist das Wurst, ob du zunächst nochmal mit 400 MHz samplest. Routing wird sich nicht verbessern. Max F. schrieb: > ist dies auch der Fall wenn das die 400MHz Quelle die Daten nur alle 4 > clk ändert? > Also mir scheint, dass der Timing analyser nicht weiss, dass sich der > 400MHz latch nur mit effektiv 100MHz ändert und daher latchen in 10ns > genügen würde. Das musst du eben constrainen. Ich kenne mich mit Intel nicht aus, dachte aber, die meisten timing constraints werden automatisch erzeugt. Hast du das Datenblatt denn mal durchforstet und bist dir sicher, dass sonst alles korrekt konfiguriert ist? > FPGA NOTFALLSEELSORGE schrieb im Beitrag #7159057: >> Du willst also mit dem FPGA SPI Slave spielen? >> Das geht auch ihne SerDes direkt mit SCK als Clock. Synchron dazu kommen >> die Daten auf MOSI und werden ausgegeben auf MISO. > > Ja wäre eine saubere Lösung. Es existieren 2 Probleme: 1. SCK ist nicht > auf einem designierten clk input pin. Dies Aufgrund Punkt 2. > 2. Der SPI Master clockt sck nur während des Transfers. Das ist eigentlich kein Problem. Du würdest die SPI SCLK ohnehin nicht als clock für ein FF nutzen. Für einen SPI slave im FPGA kannst du CSN, SCLK einsynchronisieren und mit deiner internen clock arbeiten (100 MHz?). Darauf dann in deiner Taktdomäne mit Flankenerkennung arbeiten und entsprechend MOSI samplen. Mit welcher SPI-Frequenz arbeitest du denn? Deine interne clock sollte natürlich schon deutlich schneller abtasten, damit du das timing so schaffst.
Rezy schrieb: > Für einen SPI slave im FPGA kannst du CSN, > SCLK einsynchronisieren und mit deiner internen clock arbeiten (100 > MHz?). Ja, kann man und ist eine gute Idee, wenn SCLK langsam genug im Vergleich zu interen Clock ist. Aber vermutlich ist SCLK eher schnell. Und dann ist das mit dem SerDes eigentlich exakt das: Man tastet SCLK deutlich schneller als die SCLK ab und kann dann eine Flankenerkennung machen. Max F. schrieb: > Ja wäre eine saubere Lösung. Es existieren 2 Probleme: 1. SCK ist nicht > auf einem designierten clk input pin. Dies Aufgrund Punkt 2. > 2. Der SPI Master clockt sck nur während des Transfers. Ist Beides nicht schlimm. Ausprobieren.
Gustl B. schrieb: > Aber vermutlich ist SCLK eher schnell. Min Anforderung an SCK ist 20MHz, nach möglichkeit würde ich die Transfergrösse verlängern und noch einige optionale signale einpacken. Daher ziel SCK zwischen 30-40 MHz. Um 10 Fach Überabtastung zu haben habe ich 400MHz gewählt (Das FPGA könnte meines wissens sogar ca. 700MHz) Soweit läuft auch alles gut, einige Stunden getestet und keine korrupten Daten. Anyway auf "soweit läuft gut" kann ich mich natürlich nicht verlassen. Daher die Frage wie auf den negativen Slack reagieren? Ist dies nur eine Nebenerscheinung eines unzureichenden constraints, oder besteht hier wirklich tendenziell ein Problem? Nochmals zusammengefasst: Das Quellregister wird mit 400MHz getaktet und hat alle 100MHz eine Datenänderung. 400 und 100 MHZ werden beide vom gleichen PLL generiert ohne Phasenverschiebung. Intel FPGA. 100MHz ist mein Systemclk. Das Datensenkregister wird mit diesem Systemclk betrieben. Aller Wahrscheinlichkeit nach schafft das FPGA diese diese Verbindung nicht innert 2.5ns - wohl aber in 10ns (alle SPI slacks sind nur geringfügig negativ: -0.xx bezogen auf die 2.5)
Max F. schrieb: > Soweit läuft auch alles gut, einige Stunden getestet und keine korrupten > Daten. Anyway auf "soweit läuft gut" kann ich mich natürlich nicht > verlassen. Daher die Frage wie auf den negativen Slack reagieren? Ist > dies nur eine Nebenerscheinung eines unzureichenden constraints, oder > besteht hier wirklich tendenziell ein Problem? Dein Problem entsteht durch das unzureichende constraining. Es wird so zwar funktionieren, wenn die auf 400 MHz getakteten Daten immer nur synchron zur steigenden Flanke der 100 MHz sind und dein |slack| <7.5ns ist (Rest zu den 10ns). Allerdings ist es nicht empfehlenswert, das dabei zu belassen, weil das tool unnötig versucht, ein timing zu erreichen, was nicht notwendig ist. Setz die korrekten constraints (multicycle path) und du bekommst ein sauberes Ergebnis ohne timing violations.
Rezy schrieb: > Dein Problem entsteht durch das unzureichende constraining. Es wird so > zwar funktionieren, wenn die auf 400 MHz getakteten Daten immer nur > synchron zur steigenden Flanke der 100 MHz sind und dein |slack| <7.5ns > ist (Rest zu den 10ns). Allerdings ist es nicht empfehlenswert, das > dabei zu belassen, weil das tool unnötig versucht, ein timing zu > erreichen, was nicht notwendig ist. Setz die korrekten constraints > (multicycle path) und du bekommst ein sauberes Ergebnis ohne timing > violations. Hervorragender Beitrag besten Dank! Dies bestätigt/erklärt eigentlich alles. Ebenfalls möchte ich deiner Empfehlung Folge leisten, leider kenne ich mich bez. constraints nur sehr schlecht aus. Wie könnte dies im constraint file definiert werden?
Max F. schrieb: > Hervorragender Beitrag besten Dank! Dies bestätigt/erklärt eigentlich > alles. Ebenfalls möchte ich deiner Empfehlung Folge leisten, leider > kenne ich mich bez. constraints nur sehr schlecht aus. Wie könnte dies > im constraint file definiert werden? set_multicycle_path Da gibt es genügend Doku zu ;) Du hättest (bei deiner Beschreibung) entsprechend 4 setup cycles auf der 400 MHz clock. Hold bleibt gleich. Das gilt natürlich nur, wenn die Daten aus dem SERDES mit 400 MHz wirklich nur synchron mit der 100 MHz rising edge geändert werden und diese nicht phasenverschoben sind. Also eben alle 4 cycles. Du könntest auch versuchen, die capture FFs manuell nahe an den SERDES zu legen. Vielleicht wird damit sogar schon das timing 2.5ns erreicht und du brauchst das constraint nicht mehr. Allerdings muss der router da natürlich etwas stärker arbeiten ;)
Rezy schrieb: > FPGAzumSpass schrieb: >> Um das Problem zu lösen würde ich zuerst probieren den Vektor in 400Mhz >> noch einmal zu latchen, weil es das Routing dann leichter hat den >> Übergang auf 100Mhz zu schaffen. > > Wo soll das Vorteile bringen? Sofern nicht direkt output register aus > dem SERDES-Block genutzt werden können, ist das Wurst, ob du zunächst > nochmal mit 400 MHz samplest. Routing wird sich nicht verbessern. Denke schon, dass das Verbesserungen bringt, da du ja mit dem zusätzlichen 400 MHz Register schon mal einen Teil des Routings zwischen SERDES-Block und Ziellogik hinter dich bringen kannst. Solche zusätzlichen Register müssen manchmal auch eingefügt werden, wenn Signale durch einen grossen Chip hindurch müssen, zwischen weit entfernten Logikteilen. Bei Daten mit Ready-Signal muss natürlich nur das Ready die zusätzlichen Register bekommen und die Daten wie im Fall des TO eine Multi-Cycle Constraint.
Christoph Z. schrieb: > Denke schon, dass das Verbesserungen bringt, da du ja mit dem > zusätzlichen 400 MHz Register schon mal einen Teil des Routings zwischen > SERDES-Block und Ziellogik hinter dich bringen kannst. > Solche zusätzlichen Register müssen manchmal auch eingefügt werden, wenn > Signale durch einen grossen Chip hindurch müssen, zwischen weit > entfernten Logikteilen. Bei Daten mit Ready-Signal muss natürlich nur > das Ready die zusätzlichen Register bekommen und die Daten wie im Fall > des TO eine Multi-Cycle Constraint. Ja, das nennt sich pipelining. Aber: Wenn du dieses Register so platziert bekommst, dass es die 2.5ns erfüllt, kannst du eben dieses "pipelining"-Register direkt mit 100 MHz takten. Unter den Annahmen von oben hat man identische timing-Anforderungen.. Nur die clock distribution bringt vielleicht eine kleine weitere Unsicherheit mit rein.
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.