Hallo Leute, ich habe mal eine Frage - und zwar geht es um den konzeptionellen Ansatz. Ich habe 8 ADC's an einem FPGA angeschlossen, die mit einer relativ hohen Sample-Rate Daten einfangen (200 kHz). Diese Daten sollen in ein embedded Linux System, möglichst via SPI. Meine Idee war -> der FPGA fängt die Daten in einem FIFO auf und gibt zyklisch einen Interrupt an den Linux-SoC (so im evtl. 500 Hz takt). Das Linux reagiert auf den Hardware-IRQ und startet einen SPI-Request. (im FPGA sitzt ein SPI slave, der an den FIFO angebunden ist). Ich habe mal ein paar Tests auf der Linux-Platform gemacht und schaffe es (selbst in einer User-Space Applikation, allerdings mit RT-Prio) auf den IRQ in einem Zeitrahmen von 100-200 µs später ca die SPI zu starten. Die SPI scheint auch recht flexibel. Kann bis 100 MHz Taktfrequenz und richtig lange Sequenzen (mehrere kByte in einem Transfer möglich). Also rein vom Datenvolumen sollte es machbar sein, das über die SPI Schnittstelle rüberzubekommen. Allerdings habe ich im Scope gesehen, dass je nachdem ob die DMA im SoC irgendwas anderes im Hintergrund macht, die SPI Transaktion möglicherweise nicht komplett fertig ist, bis ein neuer IRQ vom FPGA kommen würde. (teilweise mal paar Aussetzer in der SPI-Clock, geht aber dann korrekt weiter). Prinzipiell ist es verschmerzbar, wenn hier und da ein paar samples verloren gehen in meiner Applikation, weil die SPI nicht hinterherkommt, was mir aber eher Schmerzen macht ist, dass das Alignment der Daten passen muss. Sobald eine SPI Transaktion startet, sollte die SPI immer erwarten, dass die Daten der ADCs immer in der korrekten Reihenfolge kommen (ADC0, ADC1, ADC2, etc...) was dann mit einem normalen FIFO so erstmal nicht machbar ist, wenn ich da alle Daten in den Fifo schaufle und potenziell Daten nicht rechtzeitig abgeholt werden. Hat jemand schonmal was ähnliches gemacht und hat paar Ideen dazu? Danke & Gruß
Du kannst die Daten taggen, zusammen als ein einziges FIFO-Wort buffern oder dafür sorgen, dass dein Buffer nicht überläuft. Wie sehr ist dein SPI denn ausgelastet?
Samuel C. schrieb: > Du kannst die Daten taggen, zusammen als ein einziges FIFO-Wort > buffern > oder dafür sorgen, dass dein Buffer nicht überläuft. > > Wie sehr ist dein SPI denn ausgelastet? Also ich werde im Linux SoC eine dedizierte SPI nur für diesen use-case reservieren. Also keine weitere Kommunikation sonst. Das mit dem Taggen der Daten habe ich schon drüber nachgedacht, würde es aber wirklich so haben wollen, dass wenn ich einen SPI-Transfer mit der Größe X starte, dann sollen die Daten alle passennd alligned da drinnen liegen im Buffer dann. Ein reshuffeling würde ich gerne verhindern. Ja... irgendwie wird es auf einen ausreichend großen Fifo hinauslaufen, der möglicherweise einfach Panik-Bedingungen (wie z.B. FIFO Überlauf) erkennen muss und dann einen FIFO-clean oder so macht (sollte der Linux SoC mal nicht hinterherkommen die Daten rechtzeitig zu abzuholen).
Markus W. schrieb: > Samuel C. schrieb: >> Wie sehr ist dein SPI denn ausgelastet? > Also ich werde im Linux SoC eine dedizierte SPI nur für diesen use-case > reservieren. Also keine weitere Kommunikation sonst. Das sagt leider nichts über die Auslastung aus. Mit welchem Takt läuft dein SPI effektiv und mit welcher Datenrate laufen die Samples in deinen FIFO. > Ja... irgendwie wird es auf einen ausreichend großen Fifo hinauslaufen, > der möglicherweise einfach Panik-Bedingungen (wie z.B. FIFO Überlauf) > erkennen muss und dann einen FIFO-clean oder so macht (sollte der Linux > SoC mal nicht hinterherkommen die Daten rechtzeitig zu abzuholen). Du brauchst den FIFO nicht clearen, wenn du die Daten die zusammen gehören parallel darin ablegst. Dann können sie niemals nicht aligned aus dem FIFO kommen.
Je nach SoC und Linux-Version ist das ein recht prekaeres Unterfangen, das SPI-Subsystem ist nicht auf robusten Datenempfang ausgerichtet, auch wenn einige SoCs theoretisch ein vernuenftiges Autobuffer-DMA mitbringen. Damals (ca. 2008) habe ich das Problem ueber den SPORT (I2S mit TDM) eines DSP-Systems geloest und einen Realtime-Patch eingesetzt. Nur damit ging es wirklich abrissfrei im Dauerbetrieb und ohne Verlust des Framings. Denn funkt dir irgendwo ein Prozess dazwischen, kann es mal locker 1-6ms hakeln, bevor deine Queue weiterlaeuft. Also: eventuell ist ein radikaler Kurswechsel vonnoeten. Inzwischen sehe ich sogar relativ radikal von Linux fuer Echtzeitanwendungen in der Messtechnik ab, da neuere Kernels eine Menge Ueberraschungen mitbringen - aber auch hier wieder je nach SoC unterschiedlich. Der Aufwand, das dann einigermassen sauber verifiziert zu bekommen, dass man auch fuer haften kann, liegt deutlich ueber dem des Neudesigns einer hardwareoptimierten und beweisbaren Loesung.
Angehängte Dateien:
-

DSC_023aa3.JPG
240 KB

Ja, die immer neuen Kernel-Versionen. Ich habe ein Messprogramm, das Daten von einem Agilent 89441A Fourieranalyzer entgegen nimmt, über den Frequenzbereich mehrere Messungen veranstaltet, die Ergebnisse zusammenmontiert und mit Gnuplot über viele Dekaden ausgibt. Das wurde im Laufe der Jahre immer unzuver- lässiger. Das Programm hat das Socket-Interface über das LAN benutzt. Ich habe erstmal geglaubt, dass der 89441A langsam verrottet. Dem war aber nicht so. Wenn man bei einem Socket die Transferrichtung ändert, muss man erst mal seek()en, egal ob man das zu brauchen glaubt, oder auch nicht. Bei den alten Kerneln war das egal, aber bei den neueren traten Fehler auf. Ich habe dann als Notbehelf einen LTC2500-32-ADC zusammen mit einem Beaglebone Black versucht. Das 1/f-Rauschen des 89441A ist sowieso nicht so toll. Da hat sich dann rausgestellt, dass die Dokumentation im Netz und auch das Buch von Moley(sp?) hoffnungslos veraltet und inkonsistent sind. Da habe ich unglaublich viel Zeit versenkt. Immerhin sind die PRUs des BBB eine schöne Sache. Das sind 200 MHz-RISCs die Zugang zu den IO-Pins haben und nicht unbedingt Interrupts brauchen. Programmierter IO im 5 ns- Raster ohne Probleme. Als Interface zur ARM-CPU gibt es ein Dualport-RAM ohne Waitstates, egal was der ARM treibt. Wenn man dem ARM seine eigenen Resourcen wegnehmen will, dann ist man halt nur 2. Sieger und muss warten. Aber man muss das ja nicht wollen. 3 ADCs mit 32-Bit-Wörtern/1MHz auf SPI war chancenlos; ich habe ein Xilinx Coolrunner CPLD spendiert das den ADC seriell ausgelesen hat (in der Zeit, wo er gerade nicht konvertiert) und das dann byteweise von der PRU leergenuckelt wurde. Gruß, Gerhard
8 ADWandler mit 16 Bit und 200KHz , das macht 25.6MBit/sek. Also 25 MHz für den SPI Bus. Auf meinem STM32H7 komme ich auf 18 MHz, bevor der Bus schlapp macht. Diverse Embedded Linuxe lasse ich auch nur mit 8 MHz laufen, weil es darüber schon Probleme mit schlechten Signalen gab. Irgendwelche Experten werden sicherlich hier auch die 100MHz herausholen, doch ob das wirklich stabil ist, da habe ich andere Erfahrungen.
Ja, und dann sagt das Datenblatt des ADCs, dass man ihn während > 3/4 der Zeit, also bei der Konversion, gefälligst in Ruhe lassen soll, sonst kann man den SPI-Transfer in den Daten sehen und das Resultat gleich in die Tonne treten. Und schon ist man mit der nötigen Übertragungsgeschwindigkeit in einer völlig anderen Liga. Und die Probleme mit der Signalqualität kommen nicht mit der Bitrate, sondern mit der rise time und kontrollierter Impedanz. Gerhard
Gerhard H. schrieb: > Und die Probleme mit der Signalqualität kommen nicht mit > der Bitrate, sondern mit der rise time und kontrollierter > Impedanz. Wobei ohne eine gewisse rise time bestimmte Bitraten nicht zu erreichen sind... PittyJ schrieb: > Also 25 MHz für den SPI Bus. > Auf meinem STM32H7 komme ich auf 18 MHz, bevor der Bus schlapp macht. Gerade bei den STMs muß man genau hinschauen. Die maximal erreichbare Transferrate bzw. SPI-CLK-Frequenz ist von der verwendeten SPI-Schnittstelle abhängig, weil die intern an verschiedenen Bussen hängen. Bei einem Test mit einem iMX-Linux-System vor einigen Jahren, ließ sich die Datenrate oberhalb von 20 MHz nicht mehr nennenswert steigern. Dort konnte man effektiv ca. 4 MBit/s nutzen. Mit den auch von anderen beobachteten Ausreißern bei der Latenz. Markus W. schrieb: > Meine Idee war -> der FPGA fängt die Daten in einem FIFO auf und gibt > zyklisch einen Interrupt an den Linux-SoC (so im evtl. 500 Hz takt). FIFO ist schonmal gut. Wie wäre es, wenn der FPGA einen gewissen Füllstand (half full) an das Linux signalisiert, was dann weiß, das es eine entsprechende Anzahl Bytes lesen kann. Ob die Signalleitung gepollt wird oder einen Interrupt auslöst ist dabei erstmal egal. Über eine zweite Leitung (FIFO full), weiß Du, ob Datenverlust im FIFO auftritt. Dann muß der (die? das?) FIFO größer werden oder das Linux schneller auslesen... Duke
Moin, Markus W. schrieb: > Allerdings habe ich im Scope gesehen, dass je nachdem ob die DMA im SoC > irgendwas anderes im Hintergrund macht, die SPI Transaktion > möglicherweise nicht komplett fertig ist, bis ein neuer IRQ vom FPGA > kommen würde. Wenn nur das das Problem ist, dann bau' halt ins FPGA eine IRQ-Sperre ein, und die gibst du in deinem SoC halt erst wieder frei, wenn du ausge-spi-t hast. Und mach' den FIFO im FPGA entsprechend groesser, dass der halt nicht ueberlaeuft, auch wenn dein SPI-DMA mal troedelt. Ansonsten waer' ich bei hohen Datenraten via SPI unter Linux auch etwas vorsichtig, weil ich nicht voraussetzen wuerde, dass die jeweilige Anbindung der SPI-HW an den Kernel etc. dafuer auch gedacht wurde. Ist im FPGA zwar etwas mehr Aufriss, aber da koennte man z.b. die Samples in UDP-Pakete verpackeln und die ueber ein ((R)G)MII Interface und ggf. kleinen 3 Portswitch dem SoC rueberschaufeln. Im Netzwerkstack ist Linux eher drauf getrimmt, auch mit hoeheren Datenraten nicht gleich Hiccups zu kriegen. Gruss WK
Also ich werde an meiner Idee jetzt erstmal festhalten und das ganze einfach mal ausprobieren. Bin gerade schon dabei das VHDL entsprechend vorzubereiten und zu simulieren. An so eine Art intelligentes IRQ-signaling habe ich auch schon gedacht. Und dann mal schauen was passiert. Wenn's schlecht läuft sind halt 2-3 Tage Arbeit in den Sand gesetzt :) Immerhin habe ich die Unterstützung vom Chef es mal auszuprobieren. Als Backup stände tatsächlich auch Ethernet dann zur Verfügung. Allerdings haben wir nur 100 MBit/s am Linux. Ist tatsächlich eine ziemliche low-cost Plattform (Allwinner).
Markus W. schrieb: > Wenn's schlecht läuft sind halt 2-3 Tage Arbeit in den Sand > gesetzt :) Auch an gescheiterten Projekten kann man was lernen ;-)
Markus W. schrieb: > Als Backup stände tatsächlich auch Ethernet dann zur Verfügung. > Allerdings haben wir nur 100 MBit/s am Linux. > Ist tatsächlich eine ziemliche low-cost Plattform (Allwinner). Ein Xilinx Zynx wäre die deutlich bessere Plattform dafür. Da ist das FPGA viel dichter an den Prozessor gekoppelt. fchk
Angehängte Dateien:
-

Zynq_block.png
47 KB
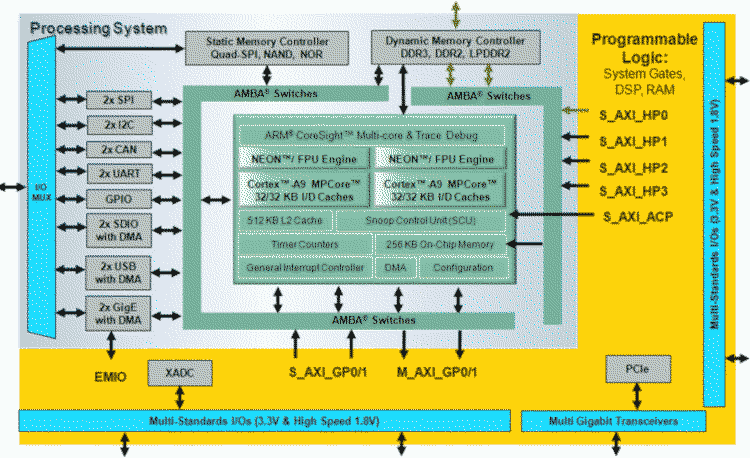
Frank K. schrieb: > Ein Xilinx Zynx wäre die deutlich bessere Plattform dafür. Da ist das > FPGA viel dichter an den Prozessor gekoppelt. "Zynq" nicht Zynx, anbei Blockbild (aus: https://cse.usf.edu/~haozheng/teach/cda4253/slides/zynq.pdf) . Und schon die ersten Zybo-Evalboards (heute 11 Jahre alt) brachten 1 Gigabit ethernet: https://digilent.com/reference/programmable-logic/zybo/start PCIe passt auch mit dem Chip. Für das geschilderte low performance Szenario des TO aber reichlich übermotorisiert. Dem sollten bspw. die softcores auf einem cyclone komplett reichen.
Frank K. schrieb: > Ein Xilinx Zynx wäre die deutlich bessere Plattform dafür. Da ist das > FPGA viel dichter an den Prozessor gekoppelt. Bei den Kosten und der jetzigen Verfuegbarkeit? Zudem: Auf Zynq brockt man sich eine Menge mehr Gefuddel ein, und der Klassiker Push -> FIFO -> Pull (variable Latenz) ist damit auch nicht vom Tisch. Das Konzept sollte gruendlich ueberdacht werden :-) Zwischen Stirnrunzel-Loesungen wie Allwinner und Zynq gibt es elegantere Quasi-Fertigloesungen, die wie n-Kanal-Soundkarten laufen, und kein Kernelspace-RT Gefuddel mehr erfordern. Allerdings stellt sich hier wirklich die Frage, warum man ueberhaupt noch ein embedded Linux einsetzt, wenn es ueber die 'naechste Stufe' der Evovlution per UDP/RTP auch mit zwei Chips geht (FPGA+Phy). Mit einfach zu implementierender Kompression ist das deutlich skalierbarer.
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.