Wie kann man beim AKTUELLEN! Notepad++ die Tab-Breite einstellen Die Deppen haben es WIEDER mal woanders hingerückt und es unauffindbar gemacht. Die Hilfen im Internet sind damit nutzlos. Weis das jemand? Ich möchte a) eine Einstellung passend zum Standard meines Editors und B Leerzeichen! Leider schaffen es die dämlichen Programmierer nicht, ihre SW konsistent zu halten und einmal gemachte Einstellungen beim update zu übernehmen.
Mirko schrieb: > Die Hilfen im Internet sind damit nutzlos. Komisch, bei mir zeigt Google die Lösung wenn man eingibt
1 | tab width notepad++ |
Nutze allerdings N++ 8.4.7, keine Ahnung ob dies die neuste ist.
Einstellungen -> Ränder .. In das Feld in der Mitte die Tabs mit zahlen (5 = 5 Zeichen) eingeben. Mit leerzeichen trennen. Version : V 8.4.7
Meine Lösung nach Test dieses Editors: einen anderen nutzen. Muss ja nicht der in Windows eingebaute Standard-Editor sein. ;) Das hilft dir jetzt evtl. nicht aber ich finde das Ding ist eine Katastrophe.
Mirko schrieb: > die dämlichen Programmierer Die kostenfreie Software nutzen und dann noch deren Entwickler beschimpfen.
900ss D. schrieb: > ich finde das Ding ist eine Katastrophe. Naja, ist eigentlich nicht schlecht. Aber er will zu viel machen. Ich habe den neusten neulich installiert weil er mit als Alternative zur IDE von Arduino empfohlen wurde. Aber irgendwie bekommt der das nicht richtig auf die Reihe. z.b. Rückmeldungung des Serial-Monitor ect. Aber ich habe ihn drauf gelassen. Weil ich öfters mal "einfach formatierten" Text bearbeiten muss.
die Tab Einstellung ist Sprachabhängig, Einstellungen/Sprache/Tabulatorbreite. Da war es aber schon immer. Oder zumindest sehr sehr lange.
Michael schrieb: > Das Ding ist genial, was ihr immer alle für Probleme habt... Hab keins. Setzt ihn halt nur für besondere Aufgaben ein. ;) Besonders dann wenn ich Text-Files OHNE TEXTFILE-Erkennungsbits haben will.
Michael schrieb: > Das Ding ist genial, was ihr immer alle für Probleme habt... Und wer doch Probleme hat: Emacs existiert! (Ja, ja, vi auch…)
Schlaumaier schrieb: > Besonders dann wenn ich Text-Files OHNE TEXTFILE-Erkennungsbits haben > will. Was sind "TEXTFILE-Erkennungsbits"?
Hmmm schrieb: > Schlaumaier schrieb: >> Besonders dann wenn ich Text-Files OHNE TEXTFILE-Erkennungsbits haben >> will. > Was sind "TEXTFILE-Erkennungsbits"? Das sind Schlaumaiers Blähungen seines oberen Hohlgefäßes. 1. Rechte Maustaste - Neu - Textdatei, 0 Byte. Mit Windows-Notepad einen Text rein schreiben. 2. Notepad++ starten, Text schreiben, speichern unter. 3. Wordpad starten, Text schreiben, speichern als Text-DOS. 4. Die Dateien per Hexeditor (HxD) anschauen. Ergebnis: Es gibt keinen Unterschied und vor allem keinen Dateiheader, wie man es von pdf oder Bilddateien kennt.
Es könnte sein, daß "Schlaumaier" eine UTF-8-codierte Datei mit BOM
gesehen (und natürlich nicht verstanden) hat.
Das mit Windows mitgelieferte Notepad unterstützt seit geraumer Zeit
auch UTF-8 anstelle von CP1252 ("ANSI").
DerEinzigeBernd schrieb: > Es könnte sein, daß "Schlaumaier" eine UTF-8-codierte Datei mit BOM > gesehen (und natürlich nicht verstanden) hat. Klor habe ich das BOM gemeint. Nur ist mir der Begriff auf die Schnelle nicht eingefallen. Das ist ein 2 Bytes Zeichen was aber die Angewohnheit hat, bei Programmen die noch das DOS-File-Format voraussetzen zu einen sehr großen Problem wird. Ich habe selbst eine Software entwickelt die Daten in einen Format schreibt wo das BOM tödlich ist, für die Software. Für die Superprofis hier. In Handel + Wirtschaft werden noch genormte Formate benutzt die zur DOS-Zeit entwickelt wurden.
Schlaumaier schrieb: > In Handel + Wirtschaft werden noch genormte > Formate benutzt die zur DOS-Zeit entwickelt wurden. UTF-8 sollte sich selbst in trägen Branchen mittlerweile durchgesetzt haben. Gerade (internationaler) Handel wird ohne UTF8 zum Problem...
Es gibt ein Projekt das hilft über alle möglichen IDEs / texteditoren hinweg. https://editorconfig.org/
Schlaumaier schrieb: > Ich habe selbst eine Software entwickelt die Daten in einen Format > schreibt wo das BOM tödlich ist, für die Software. Tja, Zeit, das zu bereinigen, wie? Du gibst ja vor, zu wissen, was das ist, dann solltest Du das auch a) erkennen und b) bei Vorhandensein damit sinnvoll umgehen können. Wenn Dein Programm beispielsweise von einem reinen 8-Bit-Zeichensatz wie CP437/CP850 ausgeht (das, was man unter DOS auf PCs halt so hatte), oder wie CP1252 ("ANSI" bzw. ISO-8859-1), dann sollte eine Datei mit BOM entsprechend umcodiert werden, damit Umlaute nicht zu Irritationen führen. Das sollte für Dich ja eine leichte Übung sein; vor allem, wo Dir Windows sogar dabei hilft (die Win32-API enthält schon seit mehreren Jahrzehnten die dafür benötigten Funktionen).
DerEinzigeBernd schrieb: > Tja, Zeit, das zu bereinigen, wie? Du gibst ja vor, zu wissen, was das > ist, dann solltest Du das auch a) erkennen und b) bei Vorhandensein > damit sinnvoll umgehen können. Das ist NICHT das Problem. Das Problem ist das schreiben der Datei OHNE BOM. Und das genormte Format heißt witzigweise DATANORM. Ist im Handwerk gang+gebe. Und ich erstelle sogenannte DATANORM-Dateien. Das sind genormte TEXT-Dateien wo ALLES genormt ist. Sogar der Zeichensatz, logoweis Satzaufbau etc. Für ca. 60-80 Euro hast du vielleicht die Möglichkeit das offizielle Buch des Normausschuss dir zu besorgen falls du mir nicht glaubst.
Schlaumaier schrieb: > Das Problem ist das schreiben der Datei OHNE BOM. Nicht als UTF-* abspeichern, wo ist das Problem? Schlaumaier schrieb: > Das sind genormte TEXT-Dateien wo ALLES genormt ist. Sogar der > Zeichensatz Und da der Zeichensatz nicht UTF-* ist, gibt's auch kein BOM-Problem.
Schlaumaier schrieb: > Das ist NICHT das Problem. > > Das Problem ist das schreiben der Datei OHNE BOM. Dann hast Du das Problem falsch beschrieben. Du schriebst: > Ich habe selbst eine Software entwickelt die Daten in einen Format > schreibt wo das BOM tödlich ist, für die Software. Das liest sich so, als würde DEINE Software auf die Fresse fallen, wenn sie ein BOM zu sehen bekommt. Und das ist DEIN Fehler. Dich mit irgendeiner Norm rauszureden, ist offenkundig falsch. Wer nicht unfähig ist, schreibt Software, die mit unvorhergesehenen Eingabedaten entweder eine Fehlermeldung ausgibt oder --sofern das möglich ist-- die unvorhergesehenen Eingabedaten repariert, um dann trotzdem zu funktionieren.
Schlaumaier schrieb: > DerEinzigeBernd schrieb: >> Tja, Zeit, das zu bereinigen, wie? Du gibst ja vor, zu wissen, was das >> ist, dann solltest Du das auch a) erkennen und b) bei Vorhandensein >> damit sinnvoll umgehen können. > > Das ist NICHT das Problem. > > Das Problem ist das schreiben der Datei OHNE BOM. > > Und das genormte Format heißt witzigweise DATANORM. Datanorm verwendet CP850. Dort gibts kein BOM. Was auch immer du meinst zu sehen, weißt auf grobe Fehlbedienung hin. Wenn du das falsche Encoding verwendest wirds halt nicht funktionieren.
Vn N. schrieb: > Datanorm verwendet CP850. Dort gibts kein BOM. Genau richtig. Aber wenn du unter VB z.b. eine Text-Datei so schreibst/anfügst dann hast du ein BOM. Die Lösung die ich mache ist folgende. utf_code = 437 If File.Exists(s_datei$) = False Then My.Computer.FileSystem.WriteAllText(s_datei$, kopf_zeile_1$, False, System.Text.Encoding.GetEncoding(utf_code)) My.Computer.FileSystem.WriteAllText(s_datei$, kopf_zeile_2$, True) End If If File.Exists(s_datei_all$) = False Then My.Computer.FileSystem.WriteAllText(s_datei_all$, kopfzeile_all$, False, System.Text.Encoding.GetEncoding(utf_code)) End If Unter euren heißgeliebten C+ geht es so. https://learn.microsoft.com/de-de/dotnet/api/system.text.utf8encoding.getpreamble?view=net-7.0 Meine Methode funktioniert und mehr brauch ich nicht. ABER es kommt auch hin+wieder vor das ich keine ini o.s. Dateien bearbeiten muss und die haben auch ihre liebe Mühe und Not mit den BOM. Ergo nutze ich dafür entweder den Notpad++. Oder wie vorher auch den Editor von Total-Commander.
Wie bereits erwähnt, wenn du es nicht schaffst das korrkte Encoding zu verwenden ist das in erster Linie ein Bedienfehler von deiner Seite. Schlaumaier schrieb: > Aber wenn du unter VB z.b. eine Text-Datei so schreibst/anfügst dann > hast du ein BOM. Wenn man kein UTF8-File will sollte man halt einfach kein UTF8-File erstellen.
Schlaumaier schrieb: > Aber wenn du unter VB z.b. eine Text-Datei so schreibst/anfügst dann > hast du ein BOM. Was auch immer "so" heissen soll. Schlaumaier schrieb: > My.Computer.FileSystem.WriteAllText "The UTF-8 encoding is used to write to the file. To specify a different encoding, use a different overload of the WriteAllText method." Wenn man das beachtet, geht auch nichts schief. Schlaumaier schrieb: > ABER es kommt auch hin+wieder vor das ich keine ini o.s. Dateien > bearbeiten muss und die haben auch ihre liebe Mühe und Not mit den BOM. > > Ergo nutze ich dafür entweder den Notpad++. Oder wie vorher auch den > Editor von Total-Commander. Selbst in Notepad kannst Du das Encoding einstellen. Unter Win7 ist ANSI voreingestellt, nur wenn Du explizit UTF-8 auswählst, wird mit BOM gespeichert. Unter Win11 ist zwar UTF-8 voreingestellt, aber für ein BOM musst Du auch da tätig werden und auf "UTF-8 with BOM" umschalten. Du faselst hier von einem Problem, das nicht existiert, solange man sich nicht extrem doof anstellt.
Angehängte Dateien:
-

rand.gif
62 KB
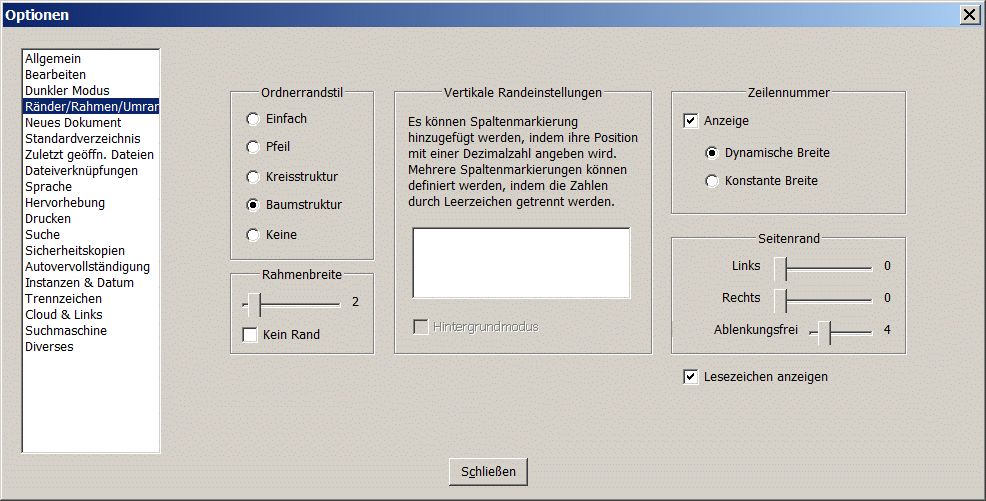
Schlaumaier schrieb: > Einstellungen -> Ränder .. > > In das Feld in der Mitte die Tabs mit zahlen (5 = 5 Zeichen) eingeben. > Mit leerzeichen trennen. Das hier? Das ist doch keine Tab-Einstellung. Ich sucher die Einstellung, mit der man festlegen kann, wieviele Zeichen statt des TAB eingefügt werden. Das sind derzeit 3 in einem Editor. Ich brauche aber z.B. 4.
Mikro schrieb: > Das ist doch keine Tab-Einstellung. Wenn Schlaumaier schreibt, ist nur selten etwas Nützliches dabei. Mikro schrieb: > Ich sucher die Einstellung, mit der > man festlegen kann, wieviele Zeichen statt des TAB eingefügt werden. Das > sind derzeit 3 in einem Editor. Ich brauche aber z.B. 4. Falls sich seit März (v8.3.3) nichts geändert hat: Settings - Preferences - Language, die Tabelle auf der rechten Seite. Da gibt es einmal den Default-Wert, man kann aber auch für einzelne Sprachen abweichende Werte konfigurieren.
Hmmm schrieb: > Settings - Preferences - Language, die Tabelle auf der rechten Seite. Da > gibt es einmal den Default-Wert, man kann aber auch für einzelne > Sprachen abweichende Werte konfigurieren. Was auch ich allerdings selber auch nicht für eine besonders glückliche Wahl halte. Was sollte die Zahl der Leerzeichen-Equivalents für einen Tab mit der verwendeten Sprache zu tun haben? Aber: Der Editor ist für lau. Wem er nicht gefällt, der braucht ihn ja auch nicht zu benutzen. Benutzt man ihn, dann muss man halt damit leben, wie er ist. Und wer nicht in der Lage ist, eine benötigte Option in einem komfortablen Konfig-GUI nötigenfalls auch an unerwarteter Stelle aufzustöbern, der ist sowieso zu blöd, um auch nur einen Eimer Wasser umzukippen...
c-hater schrieb: > der ist sowieso zu blöd, um auch nur einen Eimer Wasser > umzukippen... Hast Du damit gerade den "Schlaumaier" beschrieben? Hmm. Du gefällst mir.
Angehängte Dateien:
-

tab.PNG
27 KB
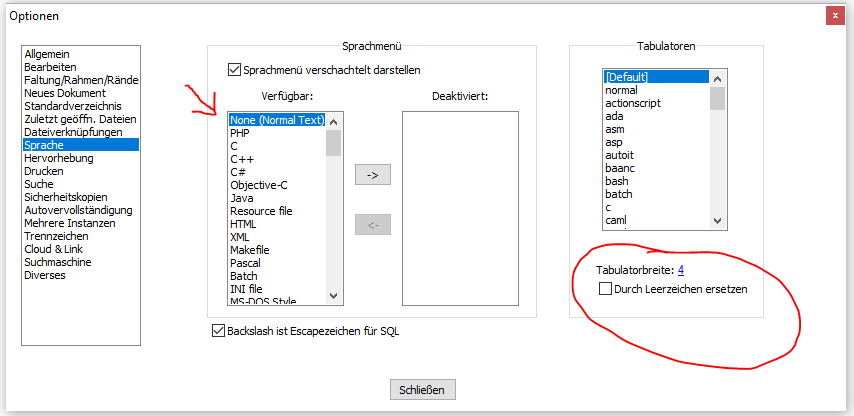
Mirko schrieb: > Ich möchte a) eine Einstellung passend zum Standard meines Editors und B > Leerzeichen! Einstellungen -> Einstellungen... siehe Bild. Meinst du das?
Und nun eine ergänzende Frage: kann man diese Tab-Breite inkl. der Umwandlung in Leerzeichen auch bei einer benutzerdefinierten / selbsterstellten Sprache festlegen? Da habe ich bisher keine Einstellung gefunden... Danke Euch.
Scheint nicht möglich zu sein. Sollte man den Machern eventuell einwerfen?
Papa S. schrieb: > Scheint nicht möglich zu sein. Sieh Dir an, wo die Sprachdefinitionen gespeichert sind, und lege für Deine "Sprache" eine eigene an. https://npp-user-manual.org/docs/user-defined-language-system/ Wenn Du das hinbekommen hast, wirst Du auch Deine eigenen Tab- und sonstwas-Settings bekommen.
Mirko schrieb: > Leider schaffen es die dämlichen Programmierer nicht, Na ja, klug ist, wer begriffen hat, dass Einrückungstiefe was ganz anderes ist als Tabulatorpositionen. Genügend Geräte (Drucker) und Umwandlungssysteme (PDF Writer etc.) wandeln TABs immer auf die nächste 8er Position um. TAB ist lediglich ein Whitespace-Kompressionszeichen. Wer da Dokumente mit abweichender Tab-Breite erstellt hat, bekommt ein zerrissenes Layout. Nur der Dümmste glaubt, dass SEIN Dokument immer mit SEINER Softwareumgebung und sonst gar nichts bearbeitet wird. Wobei er recht hat: niemand fasst den Scheiss freiwillig an, den er erst auf geratene Positionen detabben muss. Ricardo .. schrieb: > kann man diese Tab-Breite Besser nicht. Belass sie auf 8. Lege nur eine Einruckungstiefe fest.
natürlich meine ich die Einrücktiefe ;-))) Harald K. schrieb: > Wenn Du das hinbekommen hast, wirst Du auch Deine eigenen Tab- und > sonstwas-Settings bekommen. Und genau das ist aktuell nicht der Fall. Hab mir eine eigene Sprache "Brooks Robot" erstellt und definiert. Die Sprache wird erfolgreich genutzt / vom NPP++ automatisch gezogen, sobald ich entsprechende Dateien öffne. Soweit so gut. Nur unter Einstellungen >> Einstellungen >> Sprache >> Tabulatoren erscheint diese nicht als Auswahl für die 2 von mir in der Sprache angegebenen Dateitypen. Schau mal nach...
Harald K. schrieb: > Wenn Du das hinbekommen hast, wirst Du auch Deine eigenen Tab- und > sonstwas-Settings bekommen. Nee, iss nicht. Ich benutze auch eine eigene Sprachdatei für Endungen und die sind in dieser Liste, bei denen man die Sprachen aufführt nicht drin.
> Die Deppen haben es WIEDER mal woanders hingerückt und es unauffindbar > gemacht. > Leider schaffen es die dämlichen Programmierer nicht, ihre SW konsistent > zu halten und einmal gemachte Einstellungen beim update zu übernehmen. Nette Einleitung. Echt Gentleman like und mit Top-Chance das sich jemand die maximale Muehe bei der Antwort gibt. Der riskiert ja sonst wuest beschimpft zu werden. Also auch maximale Motivation. Weiter so, aus dem Material werden Fuehrungskraefte gemacht. Aus dir wird noch was.
Dein Beitrag ist jetzt aber der Brüller, was? Statt einen nutzlosen Kommentar abzugeben, wäre ein Beitrag zum Thema sinnvoller gewesen. Der TE bringt wenigstens noch Inhalt, abgesehen von der überdrehten Darstellung! Der Frust ist außerdem nachvollziehbar: Das andauernde Umändern von Menüs ist Volkssport unter den Softwareentwicklern und wir wissen auch warum: Sie kriegen es nicht hin, Menüs sinnvoll zu strukturieren und Ratschläge nehmen sie auch keine an. TABs sind nicht mit Sprachen verknüpft sondern mit Tools und Projekten. Dort kommen die Vorgaben her. Es macht überhaupt keinen Sinn das der Spracheinstellung zuzuordnen. Auf die Idee kann nur ein Softi kommen.
A. F. schrieb: > Es macht überhaupt keinen Sinn das der Spracheinstellung zuzuordnen. Das ist Deine Sichtweise. Andere sehen das komplett anders, und würden in spontanes Strahlkotzen verfallen, wenn die Tabbreite vom Projekt abhinge. Wirkklich gute Software erlaubt dem Anwender, auf unterschiedlichen Wegen nach Rom zu kommen, d.h. die gleiche Einstellung an kontextabhängig unterschiedlichen Stellen vorzunehmen.
A. F. schrieb: > Sie kriegen es nicht hin, Menüs sinnvoll zu strukturieren und Ratschläge > nehmen sie auch keine an. TABs sind nicht mit Sprachen verknüpft sondern > mit Tools und Projekten. Dort kommen die Vorgaben her. Es macht > überhaupt keinen Sinn das der Spracheinstellung zuzuordnen. Auf die Idee > kann nur ein Softi kommen. Tabs sind auch nicht mit Tools und Projekten verbunden, sondern mit Hardware (Drucker) und Software (TXT in PDF) und stehen daher immer auf 8. Ein Tab ist ein Kompressionszeichen für bis zu 8 Leerzeichen, sonst nicht. Mit Sprachen ist aber sehr wohl eine Einrückungstiefe verbunden, und einrücken macht man in manchen Editoren mit einem Druck auf die TAB Taste, produziert aber kein Tab. Das werden manche aber nie verstehen.
Michael B. schrieb: > Das werden manche aber nie verstehen. In Deiner Welt mag das so aussehen, in anderer Leute Welt sieht das anders aus. Aber das wirst Du nie verstehen.
Harald K. schrieb: > In Deiner Welt mag das so aussehen, in anderer Leute Welt sieht das > anders aus. Aber das wirst Du nie verstehen. Und für beide Welten hat der N++ passende Einstellungen. Und es hat auch seine Berechtigung das für verschiedene Programmiersprachen separat zu behandeln. Ein makefile braucht zwingend Tabs da nützen keine Leerzeichen was. Python ist in meinen Augen ganz krank weil die Einrückungstiefe Teil der Sprache ist. Da wird es dann mit 4 Leerzeichen übersichtlicher. Da wo Block-Klammern ins Spiel kommen wie bei C++, js und viele andere mehr reichen mir 2 aber als richtige Leerzeichen. N++ ist schon ein toller Editor, man muss aber auch damit umgehen können. Klar ist das schwer wenn man gerade von der Arduino IDE kommt....
Jürgen L. schrieb: > Python ist in meinen Augen ganz krank weil die > Einrückungstiefe Teil der Sprache ist. Nö.
Ein T. schrieb: >> Python ist in meinen Augen ganz krank weil die >> Einrückungstiefe Teil der Sprache ist. > > Nö. Mein lieber Nörgler, wie kommst du dazu mein persönliches Empfinden zu negieren? Das ist Anmaßung! Du kannst auch denken was du willst und es ist mir komplett egal. Aber was in meinen Augen krank ist und was nicht entscheidet kein anderer als ich selbst. Punkt und Ende der Diskussion.
Kommt runter Leute. Es geht lediglich um TabBreiten und Einrücktiefen... Nicht um eine Kriegsführung. Danke. Meine Brooks Controller kommen jedenfalls nicht mit einem Tab als Einrücker klar. Leerzeichen hingegen machen keine Probleme. Daher meine Frage ob die Art und Anzahl der Einrücktiefen direkt einer Sprache zugeordnet werden kann. Dem ist aktuell nicht so. Das ist schade. Mehr aber auch nicht.
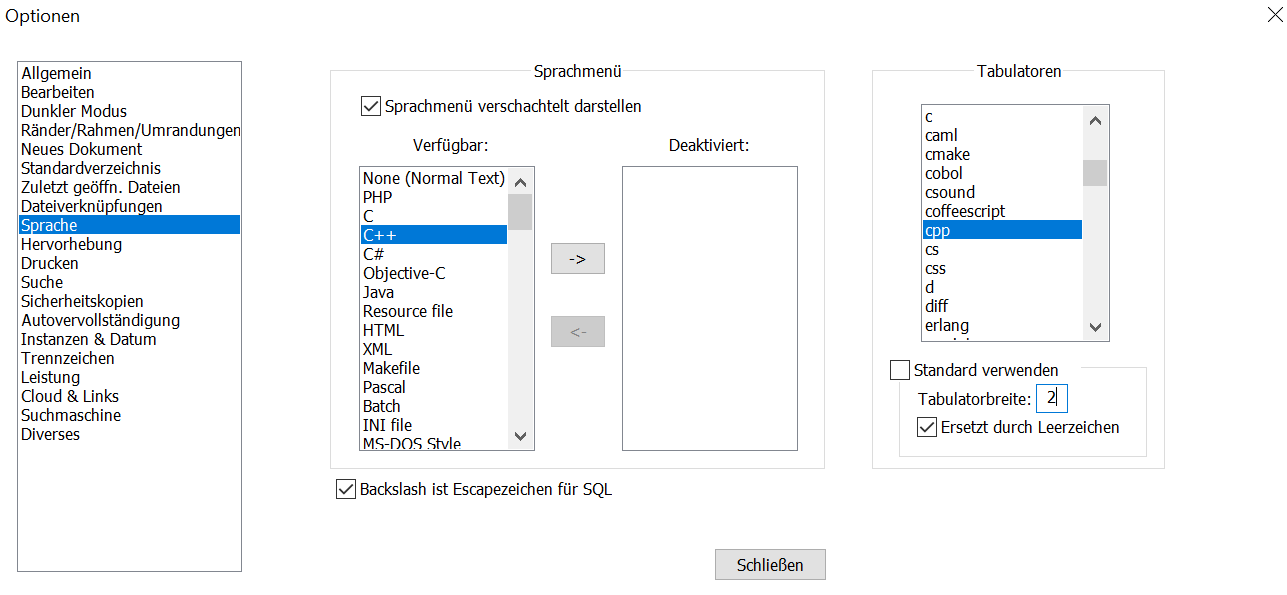
Ricardo .. schrieb: > Daher meine Frage ob die Art und Anzahl der Einrücktiefen direkt einer > Sprache zugeordnet werden kann. > > Dem ist aktuell nicht so. > > Das ist schade. Mehr aber auch nicht. Im n++ geht das. Im Feld Tabulatoren ist eine Sprachliste. Wähle ich dort cpp aus steht ein Haken bei Standard verwenden. Den kann man abklicken und anderes eintragen. Das gilt dann nur für cpp.
{kind=link}
Jürgen L. schrieb: > Ein T. schrieb: >>> Python ist in meinen Augen ganz krank weil die >>> Einrückungstiefe Teil der Sprache ist. >> >> Nö. > > Mein lieber Nörgler, wie kommst du dazu mein persönliches Empfinden zu > negieren? Das ist Anmaßung! Ich negiere nicht Dein "persönliches Empfinden", sondern lediglich Deine falsche Behauptung. Natürlich ist die Einrückungstiefe auch in Python nicht "Teil der Sprache". Es ist dem Interpreter vollkommen gleichgültig, wie und wie tief man einrückt, solange es konsistent bleibt. Nachtrag: ich hab's gerade nochmal mit zwei Python-Dateien getestet, eine mit einem einzelnen Leerzeichen und eine mit einmal einem und einmal sogar zwei Tabs. Die Datei mit dem Leerzeichen kann die Funktion der anderen natürlich problemlos importieren und ausführen, die Einrückungen müssen also nur pro Datei konsistent sein. Ob man dann ein oder mehrere Leerzeichen oder Tabs verwendet, spielt also offensichtlich keine Rolle. Etwas anderes ist übrigens Go(lang), das einen Tabulator vorsieht und das mit dem integrierten Formatierungstool gofmt(1) auch hart durchsetzt. Edit: Typo, Nachtrag.
Jürgen L. schrieb: > Ricardo .. schrieb: >> Daher meine Frage ob die Art und Anzahl der Einrücktiefen direkt einer >> Sprache zugeordnet werden kann. >> Dem ist aktuell nicht so. >> Das ist schade. Mehr aber auch nicht. > > Im n++ geht das. Im Feld Tabulatoren ist eine Sprachliste. Wähle ich > dort cpp aus steht ein Haken bei Standard verwenden. Den kann man > abklicken und anderes eintragen. Das gilt dann nur für cpp. Und genau da ist meine benutzerdefinierte Sprache nicht gelistet... Vlt. Habe ich mich auch nur unklar ausgedrückt 😏
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.