Guten Tag, wie schafft es ein RISC Prozessor wie ARM oder AVR einen Befehl in nur einem Zyklus durchzuführen? Es muss ja der Befehl geholt werden, dekodiert werden, die nötigen Variablen geladen werden eine Berechnung mit der ALU durchgeführt werden und dann das Ergebnis und mögliche Statussignale gesetzt werden. https://cseweb.ucsd.edu/~j2lau/cs141/week3.html Thx
jochenPizz schrieb: > wie schafft es ein RISC Prozessor wie ARM oder AVR einen Befehl in nur > einem Zyklus durchzuführen? Des Rätels Lösung: Er schafft es keineswegs in einem Takt. Aber er schafft es, im Idealfall pro Takt ein Befehl zu starten und zu beenden. https://de.wikipedia.org/wiki/Pipeline_(Prozessor)
(prx) A. K. schrieb: > Des Rätels Lösung: Er schafft es keineswegs in einem Takt. Doch der AVR schafft das, außsser bei JMP. >Es muss ja der Befehl geholt werden, Kein Problerm bei Onchip ROM wie AVR >dekodiert werden, Kein Problem bei RISC, da werden wenige bits (ca. 8) decodiert, der Rest geht direct als addressbit an die registerbank > die nötigen Variablen geladen werden Kein Problem bei RISC typischen 'großen Registerbanken' und onchip RAM > eine Berechnung mit der ALU durchgeführt werden Kein Problem, wenn man komplexe Befehle wie MUL an Coprozessoren auslagert >und dann das Ergebnis und mögliche Statussignale gesetzt werden. Flags setzt die ALU nebenher. >Thx Tipp: besorg dir ein Buch über Computerarchitektur, dann kannst du Dich selber schlau machen und musst nicht das Forum mit theoretischen Pillepalle beschäftigen. Du kannst dir auch den source code von Sngle cycle CPU's anschauen, bspw. hier im Forum: https://www.mikrocontroller.net/articles/PiBla
> einen Befehl in nur einem Zyklus durchzuführen?
Ein wichtiger Aspekt dabei ist das Design des Befehlssatzes: man achtet
z.B. darauf, dass jeder Befehl einen Bus maximal einmal benutzt. D.h.
z.B., dass man eine feste Befehlslänge hat und dass Immediate-Operanden
direkt im Opcode stehen und keinen zweiten Zyklus auf dem Instructionbus
benötigen. Man hat keine Read-Modify-Write-Befehle auf's RAM, würden
den Datenbus zweimal benutzen. Usw.
Den Tackt in Mikroschritte zu zerlegen konnte schon die Oktale CDC Maschine auf der ich meine Technikerausbildung gemacht habe. 8kB Ringkernspeicher Papertape Reader Konsole aus einer Kugelkopf Schreibmaschine und ein Bandlaufwerk mit 8" Spulen sowie eine 6MB Wechselfestplatte ware da angesagt. MfG Michael
Nachdem ihr jetzt die einfache Frage geklaert habt, wie schaffen es superscalare Microcontroller (z.B SH2A) zwei Befehle pro Takt auszufuehren? :) Olaf
Fred Focus schrieb: > Du kannst dir auch den source code von Sngle cycle CPU's anschauen, ah na klar man kann das/ muss das ja auch in HDL beschreiben können. Also ich finde vor allem interessant welche Schaltung da verwendet wird, um die Befehle rechtzeitig zu bearbeiten.
Fred Focus schrieb: > (prx) A. K. schrieb: >> Des Rätels Lösung: Er schafft es keineswegs in einem Takt. > > Doch der AVR schafft das, außsser bei JMP. Üblicherweise bezieht man den gesamten Ablauf mit ein. Und Fetch-Execute sind 2 Takte.
jochenPizz schrieb: > Fred Focus schrieb: >> Du kannst dir auch den source code von Sngle cycle CPU's anschauen, > > ah na klar man kann das/ muss das ja auch in HDL beschreiben können. > > Also ich finde vor allem interessant welche Schaltung da verwendet wird, > um die Befehle rechtzeitig zu bearbeiten. Rechtzeitig ist einfach wenn der Takt nur langsam genug ist. Single cycle CPUs haben, verglichen mit pipelined CPUs, sehr niedrige Taktfrequenzen (bei gleicher Fertigungstechnologie).
olaf schrieb: > Nachdem ihr jetzt die einfache Frage geklaert habt, wie schaffen > es superscalare Microcontroller (z.B SH2A) zwei Befehle pro Takt > auszufuehren? :) Wo siehst du da ein Problem?
(prx) A. K. schrieb: >> Doch der AVR schafft das, außsser bei JMP. > > Fetch - Execute sind 2 Stufen. Richtig. Deshalb brauchen Sprünge mehr Takte. Der AVR schafft es durch Pipelining nur scheinbar einen Befehl in einem Takt auszuführen. https://www-user.tu-chemnitz.de/~heha/hsn/chm/ATmegaX8.chm/7.htm
(prx) A. K. schrieb: >> Nachdem ihr jetzt die einfache Frage geklaert habt, wie schaffen >> es superscalare Microcontroller (z.B SH2A) zwei Befehle pro Takt >> auszufuehren? :) > > Wo siehst du da ein Problem? Das Problem ist doch offensichtlich. In einer CPU ohne Pipelining ginge das gar nicht. Und was, wenn eine Data-Dependency zwischen den Befehlen besteht?
MaWin schrieb: > In einer CPU ohne Pipelining ginge das gar nicht. Doch, natürlich. Es macht nur niemand, mangels Sinn. Im Prinzip geht VLIW auch ohne Pipelinung.
MaWin schrieb: > Und was, wenn eine Data-Dependency zwischen den Befehlen besteht? Finden und blockieren. Oder Schrott rein Schrott raus bei VLIW.
(prx) A. K. schrieb: > Doch, natürlich. Es macht nur niemand, mangels Sinn. Im Prinzip geht > VLIW auch ohne Pipelinung. (prx) A. K. schrieb: > Finden und blockieren. Oder Schrott rein Schrott raus bei VLIW. Ja klar. Also eine massive Steigerung der Silicon-Komplexität mit einhergehender niedrigerer Taktrate. Null Gewinn. Es ist schon klar, warum das niemand macht.
MaWin schrieb: > Ja klar. > Also eine massive Steigerung der Silicon-Komplexität mit > einhergehender niedrigerer Taktrate. > Null Gewinn. Mumpitz. Komplex wird ein Design erst durch das Pipelining. Und was heisst schon niedrige Taktrate, für einen 8 MHz AVR in einer Kaffeemascine ist die Taktrate schon mehr als genug. Oder der multi-cycle 6502 auf 1 MHz im Apple II, der hatte noch genügend Takt für bit-toggling und Sound erzeugung übrig. Jaja Katzenvideaos laufen darauf nicht, aber wer braucht die schon. Bei den heutigen IC-Strukturbreiten ist es kein problem eine single-cycle RISC-CPU im zweistelligen MHz Bereich laufen zu lassen.
Fred Focus schrieb: > Komplex wird ein Design erst durch das Pipelining. Und was heisst schon > niedrige Taktrate Fred Focus schrieb: > Bei den heutigen IC-Strukturbreiten ist es kein problem eine > single-cycle RISC-CPU im zweistelligen MHz Bereich laufen zu lassen. Lies dir bitte noch einmal durch, worauf ich geantwortet habe.
AVR haben zwei separate Speicher und Busse für Befehle und Daten. Deswegen können diese unabhängig voneinander gleichzeitig angesprochen werden. Dazu kommt, das der Programmspeicher einen 16 Bit Bus hat, so dass der nächste Befehl und sein Operand gleichzeitig geladen werden können. AVR laden den nächsten Befehl schon, während der vorherige noch abgearbeitet wird. Und dann solltest du bedenken, dass ein Taktzyklus zwei Flanken hat, die man nutzen kann. Zum Beispiel (weiss jetzt nicht ob das bei AVR exakt so ist): Steigende Flanke: Eingabe holen und Befehl ausführen Fallende Flanke: Ergebnis ausgeben und nächsten Befehl holen.
Ein ST62 schafft 13 Befehle per Takt. Oder waren es 13 Takte je Befehl. Ein Takt per Befehl ist ein alter Hut. Das konnten die DSPs schon lange bevor jemand R.I.S.C. ueberhaupt buchstabieren konnte. Oder mehrere Operationen per Befehl in separaten Adressraeumen.
... schrieb: > Ein Takt per Befehl ist ein alter Hut. > Das konnten die DSPs schon lange Hier geht es um Microcontroller. Dass Spezialhardware in Spezialfällen mehr kann, sollte klar sein. Der Extremfall ist der FPGA, der alles in einem Takt machen kann, wenn er genug Gates hat. Begrenzende Faktoren sind aber immer - Data dependencies - Bus contention - Busbreiten - Anzahl der parallel vorhandenen Funktionsblöcke (z.B. ALU) - Signallaufzeiten
Stefan F. schrieb: > Zum Beispiel (weiss jetzt nicht ob das bei AVR exakt so ist): > > Steigende Flanke: Eingabe holen und Befehl ausführen > Fallende Flanke: Ergebnis ausgeben und nächsten Befehl holen. Wurde ja schon hier gepostet: https://www-user.tu-chemnitz.de/~heha/hsn/chm/ATmegaX8.chm/7.htm
> Der Extremfall ist der FPGA, der alles in einem Takt machen kann, wenn > er genug Gates hat. Da begibst du dich jetzt aber auf ganz duennes Eis. Ein solches Design waere asynchron. Nicht das es nicht grundsaetzlich ginge. Es macht aber keiner ohne ganz grosse Not. Wenn man Pech hat, schmilzt einem das Silizium im Package weg. Solange noch Silizium uebrig ist, versicht sich der arme Kaefer dann neu zu konfigurieren. > Hier geht es um Microcontroller. Wenn man von einem D.S.P. das D. und das S. weglaesst, bleibt ein P. uebrig. Es ist sicherlich ein wenig dekadent seine Strings in etwas groessere :) Wortbreiten zu packen. Aber es geht auch! Ich habe es probiert.
... schrieb: > Ein Takt per Befehl ist ein alter Hut. > Das konnten die DSPs schon lange bevor jemand R.I.S.C. > ueberhaupt buchstabieren konnte. Erster DSP: TMS 5100, 1978 Erster RISC: IBM 801, 1974
... schrieb: > Da begibst du dich jetzt aber auf ganz duennes Eis. Aha. > Nicht das es nicht grundsaetzlich ginge. Also habe ich recht. > Es macht aber keiner ohne ganz grosse Not. Habe ich auch nicht behauptet. Thread lesen, bitte. > Wenn man von einem D.S.P. das D. und das S. weglaesst, bleibt > ein P. uebrig. Ein DSP ist kein universeller RISC-Mikrocontroller. Und darum geht es hier in dieser Diskussion. Dass Spezialhardware in Spezialfällen schneller als ein universeller RISC-Mikrocontroller sein kann, hat niemand bestritten. Thread lesen, bitte.
jochenPizz schrieb: > wie schafft es ein RISC Prozessor wie ARM oder AVR einen Befehl in nur > einem Zyklus durchzuführen? Hi, lese gerade ganz gespannt, habe mich das auch schon oft gefragt. Kam derzeit eher aus der PIC (Harvard) Welt, dort wurde der Takt immer erstmal durch 4 geteilt auf den Taktverteilungs Blockschaltbildern ... da war klar, okay, die Dinger nutzen dann also die Flanken dazwischen um das zu schaffen, zumindest habe ich mir das immer so zurecht gereimt, zumal die PICs ja wirklich alles nach und nach durch die ALU bewegen... Das spiegelte sich auch in den Assembler Befehlstrukturen wieder, beim PIC waren das immer ein Operanden Befehle und nun beim AVR sind es ja eher drei Operanden Befehle. MaWin schrieb: > Der AVR schafft es durch Pipelining nur scheinbar einen Befehl in einem > Takt auszuführen. Stefan F. schrieb: > Steigende Flanke: Eingabe holen und Befehl ausführen > Fallende Flanke: Ergebnis ausgeben und nächsten Befehl holen. Machen die AVR dann nun tatsächlich ein Pipelining oder machen sie es so wie von Stefan beschrieben? Gruß M.
> Das Problem ist doch offensichtlich. > In einer CPU ohne Pipelining ginge das gar nicht. > Und was, wenn eine Data-Dependency zwischen den Befehlen besteht? Ich fand es immer sehr bizarr wenn man im Singlestep im Debugger durch den Code gegangen ist und man sah wie sich dann der Positionsbalken geteilt hat weil manchmal nur ein Befehl abgearbeitet wurde, dann zwei, dann warte der eine auf den anderen, dann springt er vor. Und der Compiler bemueht sich auch die Befehle optimal anzuordnen. Da steckt schon eine Menge Gehirnschmalz drin. Dagegen ist eine MCU die nur 1Befehl pro Zyklus macht doch das nahe liegende. Wuerde ich ganz ahnungslos selber eine MCU designen, wuerde vermutlich sowas rauskommen. Viele Zyklen waren dann irgendwann ein Teil von Luxus. (vgl: DJNZ beim Z80) oder das man Gatter sparen wollte. (Multiplikation) Olaf
> Also habe ich recht. Wie ich sehe, hast du es noch nicht verstanden. Wenn man einen FPGA mit einem asynchronen Design fuettert, hat man keine Kontrolle ueber die Anzahl der parallel ausgefuehrten Operationen. Und die ist eben, entgegen deiner Meinung, doch limitiert. Weil solche Schaltvorgaenge als laestiges Nebenprodukt Waerme durch die Schaltverluste erzeugen. Diese Limitierung laesst also ein "Grundsaetzlich" praktisch nicht zu. Ansonsten wuerden es alle machen. Weil es natuerlich schneller ist. Ein mit einem asynchronen Design zu 100 % gefuellter FPGA, wuerde binnen weniger Sekunden seinen magischen Rauch entweichen lassen sobald er etwas tun soll. > Ein DSP ist kein universeller RISC-Mikrocontroller. Wie gut das meine verbauten DSPs das nicht wissen. Scheinbar kann ich auf das "universelle" recht gut verzichten. > Erster RISC: IBM 801, 1974 Gab es da auch einen Cobol-Compiler dafuer?
Martin S. schrieb: > Machen die AVR dann nun tatsächlich ein Pipelining oder machen sie es so > wie von Stefan beschrieben? Ich poste den Link einfach noch ein drittes Mal: https://www-user.tu-chemnitz.de/~heha/hsn/chm/ATmegaX8.chm/7.htm
olaf schrieb: > Ich fand es immer sehr bizarr wenn man im Singlestep im Debugger > durch den Code gegangen ist und man sah wie sich dann der > Positionsbalken geteilt hat weil manchmal nur ein Befehl abgearbeitet > wurde Das hat viel mit Optimierung durch den Compiler zu tun, wenig mit dem betrachteten Thema.
... schrieb: >> Erster RISC: IBM 801, 1974 > > Gab es da auch einen Cobol-Compiler dafuer? Ja, Designziel Fortran und Cobol. Und für deinen DSP? ;-)
... schrieb: > Wenn man einen FPGA mit einem asynchronen Design fuettert, ... schrieb: > Wie gut das meine verbauten DSPs das nicht wissen. Es geht hier nicht um FPGAs und DSPs. Du hast meine Aussage vollkommen aus dem Kontext gerissen. Das hier war der Ausgang (mit den Zitaten) der Diskussionskette, aus der du dich ausgekoppelt hast: Beitrag "Re: 1 Befehl pro Zyklus" Und jetzt lies den Thread ab da. Ich habe dir niemals widersprochen. Weil das gar nicht das Thema war. Du redest am Thema vorbei.
Sieht so aus, als wenn der AVR 3 Takte pro Takt macht: https://www-user.tu-chemnitz.de/~heha/hsn/chm/ATmegaX8.chm/bild/b7-5.png
> Du hast meine Aussage vollkommen aus dem Kontext gerissen. Moeglicherweise. Weil du so ein lustiges Kerlchen bist :). > Und für deinen DSP? ;-) Es sind mehrere! Fuer die allerersten waere ein selbst gehosteter Compiler vielleicht doch etwas viel vom Gewicht her. Aber wenn man sich die ganz alten UNIX®-Quellen so anschaut, koennte man es wohl doch nicht ganz ausschliessen sich da einen CC zu zimmern. Die allerzweiten sind schon vom Hersteller mit (Cross-)compilern versorgt. Bei der IBM® musste Mann natuerlich nach Cobol fragen. Und so schlecht ist Fortran 1 ja auch nicht. Aber immer die Lochkarten mit Zeilennummern stanzen!
Angehängte Dateien:
-

KarlMarxProzessor.PNG
5,1 KB
Christoph M. schrieb: > Sieht so aus, als wenn der AVR 3 Takte pro Takt macht: > > https://www-user.tu-chemnitz.de/~heha/hsn/chm/ATmegaX8.chm/bild/b7-5.png Bildfehler? Der arbeitet lt. Bild nur im ersten Takt, alle anderen sind idle. Jajaja, die in Karl-Marx-Stadt denken nochn auch eine CPU hat einen acht von 24 Stunden Arbeitsrhythmus.
jochenPizz schrieb: > wie schafft es ein RISC Prozessor wie ARM oder AVR einen Befehl in nur > einem Zyklus durchzuführen? Beim AVR weiß ich nicht - aber beim ARM kann man so grob sagen: mehrere Optimierrunden - und Abhängigkeiten. Beispielsweise Befehl a 1 Takt, danach aber für 2 Takte blockiert. Um bei gewissen Vorgängen wie Sprüngen, Cache-Nutzung oder Programmwechseln weniger Zeit zu verbrauchen werden Vohersage-Techniken eingesetzt. Man schaut sich besser die Timing-Tabellen zu den einzelnen Prozessormodellen und den Befehlen genauer an, und sollte die auch vergleichen, um 1) Optimierungen/Relativierungen zu erkennen 2) Abhängigkeiten zu erkennen. 3) Pipelines ziehen einen verzögerten Datenzugriff hinter sich her.
Angehängte Dateien:

Fred Focus schrieb: > Bildfehler? > Der arbeitet lt. Bild nur im ersten Takt, alle anderen sind idle. > Jajaja, die in Karl-Marx-Stadt denken nochn auch eine CPU hat einen acht > von 24 Stunden Arbeitsrhythmus. So lange die Einen den gesamten Ablauf betrachten und die Anderen sich daraus die Rosinen rauspicken, redet man nebeneinander her.
Der Ur-8051 teilte den Quarztakt durch 12 je Befehl. Damit gab es keine Probleme, um z.B. eine Flagregister per Interrupt zu setzen, bzw. per Befehl zu löschen. Beides erfolgte per Read-Modify-Write in verschiedenen Phasen der 12 Takte. Z.B. mit dem JBC-Befehl kann man einen Interrupt abfragen und löschen, ohne einen Interrupt zu verlieren. Als dann aber die 8051 mit Teiler 1:1 rauskamen (z.B. AT89LP51), gab es massive Probleme und Bugreports, um das gleiche Verhalten in nur einem Takt zu erreichen.
Beitrag #7308483 wurde von einem Moderator gelöscht.
Angehängte Dateien:
-

InsSet.PNG
22 KB -

SCAVR.PNG
31 KB
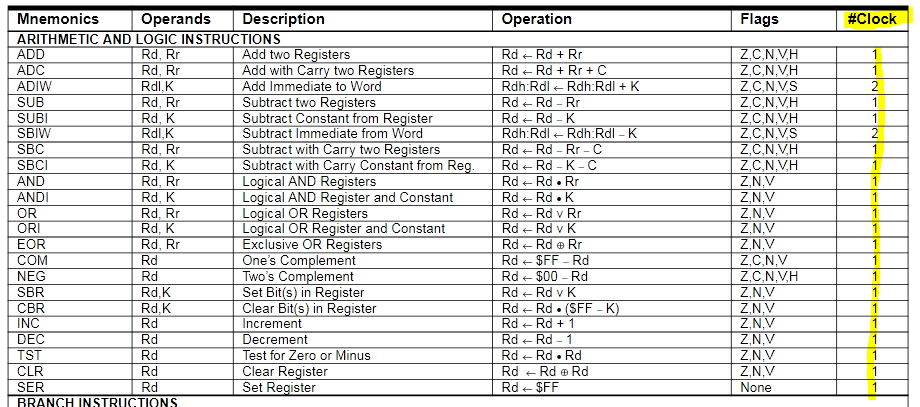

(prx) A. K. schrieb: > So lange die Einen den gesamten Ablauf betrachten und die Anderen sich > daraus die Rosinen rauspicken, redet man nebeneinander her. Nix rauspicken, der 3-Takt-Behaupter hat eindeutig auf das ein-Takt-Bild verlinkt. Und es steht auch schon auf der erste Seite: ein cycle für einen Befehl (meistens). Und welche meistens meint sieht man im Instruction-Set (Auszug AVR-Datasheet ebenfalls im Anhang). Und gerade deshalb haben RISC-Maschinen so einen tiefen registersatz.
Fred Focus schrieb: > Und es steht auch schon auf der erste Seite: ein cycle für einen Befehl > (meistens). Fehlschluss. Wenn ein Prozessor einen Befehl pro Takt ausführt, dann bedeutet dies nicht, dass der Befehl nur einen Takt dauert. Ebendies wird erst durch Pipelining erreicht, wenn auch beim AVR nur rudimentär. Weil in diesem Fall beim AVR stets zwei Befehle gleichzeitig in Arbeit sind, in verschiedenen Stadien ihres Ablaufs.
(prx) A. K. schrieb: > Wenn ein Prozessor einen Befehl pro Takt ausführt, dann > bedeutet dies nicht, dass der Befehl nur einen Takt dauert. Doch genau das bedeutet es hier. > Ebendies > wird erst durch Pipelining erreicht, wenn auch beim AVR nur rudimentär. Nein, bei den single-cycle-Befehlen macht der AVR kein Pipeling. Deshalb röttelt er ja auch mit langsamen einstelligen Takten. Und beim ARM gibt es welche mit und welche Ohne Pipelining. Wahrscheinlich hat pipeling für embedded mehr Nach- als Vorteile (Ruhestrom, Echtzeit-vorhersagbarkeit).
Fred Focus schrieb: >> Wenn ein Prozessor einen Befehl pro Takt ausführt, dann >> bedeutet dies nicht, dass der Befehl nur einen Takt dauert. > > Doch genau das bedeutet es hier. Nein, tut es nicht. Lies den Link, den ich jetzt nicht zum vierten Male posten werde. > Nein, bei den single-cycle-Befehlen macht der AVR kein Pipeling. Ja doch. Natürlich macht er das. Fred Focus schrieb: > Und beim ARM gibt es welche mit und welche Ohne Pipelining. > Wahrscheinlich hat pipeling für embedded mehr Nach- als Vorteile > (Ruhestrom, Echtzeit-vorhersagbarkeit). Kann es sein, dass du gar nicht weißt, was Pipelining ist?
Fred Focus schrieb: > Und es steht auch schon auf der erste Seite: ein cycle für einen Befehl > (meistens). Du interpretierst das falsch. Ja, von sehr vielen Instruktionen können einer pro Takt abgearbeitet werden. Das heißt aber nicht, dass die auch nur einen Takt dauern würden, tatsächlich dauern sie (die mit einem Takt Durchsatz angegebenen) zwei Takte. In einem wird das Befehlswort geholt und decodiert, im zweiten erfolgt die Abarbeitung. Der entscheidende Trick ist: WÄHREND dieser Abarbeitung wird bereits das Befehlswort der nächsten Instruktion geholt und decodiert. So ergibt sich der Durchsatz von einem Takt pro Instruktion. Das ist die simpelste Form von Pipelining. Im übrigen kann man das selbst in der Instruktionstabelle an vielen Stellen sehen, nämlich überall dort, wo Code-Verzweigungen auftreten. Denn dann kann logischerweise nur für einen Zweig das Holen des nächsten Befehlsworts verschachtelt werden. Geht's auf Grund der Bedingung in den anderen Zweig, war der Prefetch nutzlos und es hagelt einen "Straftakt", nämlich genau den, der nötig ist, um das erste Befehlsort dieses alternativen Codezweigs einzulesen und zu decodieren. Siehe z.B. all die br*-Instruktionen. > Und welche meistens meint sieht man im Instruction-Set (Auszug > AVR-Datasheet ebenfalls im Anhang). Tja, zwischen einfach nur lesen und wirklich verstehen liegen manchmal halt auch Welten. Aber immerhin sehr löblich, dass du wenigstens liest. Viele schaffen ja nichtmal dies...
Fred Focus schrieb: > Und beim ARM gibt es welche mit und welche Ohne Pipelining. Hier ein Pipelining-Beispiel für Arm (Die verschiedenen Arm-Prozessoren unterscheiden sich hier stark untereinander): https://developer.arm.com/documentation/100026/0103/Cycle-Timings-and-Interlock-Behavior/About-cycle-timings-and-interlock-behavior/Pipeline-information Die einzelnen Befehle brauchen nicht alle die volle Pipelinelänge (hier Main-Result): https://developer.arm.com/documentation/100026/0103/Cycle-Timings-and-Interlock-Behavior/Instructions-cycle-timings/Base-instructions-cycle-timings Aber in einer Stage (also ohne Pipelining) läuft keine der Instruktionen durch. Das früheste ist Ex1, wenn ich jetzt nichts übersehe. Das wäre in diesem Fall 3 Stages.
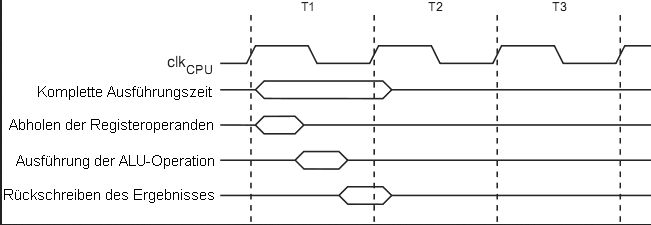
MaWin schrieb: > Ich poste den Link einfach noch ein drittes Mal: > > https://www-user.tu-chemnitz.de/~heha/hsn/chm/ATmegaX8.chm/7.htm Bild 7-5: Zeitablauf ALU-Operation Beitrag "Re: 1 Befehl pro Zyklus" Sieht man ja, dass es mehr Takte braucht um einen Zyklus auszuführen, also werden intern mehr Taktflanken inerhalb eines Taktes erzeugt oder nicht? Zumal -> wenn man zwei Operanden über einen Bus holt, geht das doch schlecht gleichzeitig, verstehe ich dort schon gar nicht... Das ist doch die Frage, wie bekommen sie zwei Operanden und in einem Takt an die ALU und vor allem dann noch das Ergebnis wieder dort weg... Also ich komme mit den Darstellungen dort nicht zurecht... M.
MaWin schrieb: > Hier ein Pipelining-Beispiel für Arm (Die verschiedenen Arm-Prozessoren > unterscheiden sich hier stark untereinander): Wobei dort auch schon der eminent wichtige vordere Teil der Pipeline fehlt, nämlich Fetch/Predict. Aber für Anfänger sind diese Highends zwei Klassen zu komplex. Etwas illustrativer ist die Pipeline vom ersten ARM: https://en.wikichip.org/wiki/acorn/microarchitectures/arm1#Pipeline
Martin S. schrieb: > Sieht man ja, dass es mehr Takte braucht um einen Zyklus auszuführen, > also werden intern mehr Taktflanken inerhalb eines Taktes erzeugt oder > nicht? Ziemlich sicher nicht. Dazu bräuchte man eine PLL. > Zumal -> wenn man zwei Operanden über einen Bus holt, geht das doch > schlecht gleichzeitig, verstehe ich dort schon gar nicht AVR ist Harvard und RISC. Da geht immer nur ein Datum zugleich über den jeweiligen Bus. > und vor allem dann noch das Ergebnis wieder dort weg... Gar nicht. Ist RISC.
Martin S. schrieb: > also werden intern mehr Taktflanken inerhalb eines Taktes erzeugt oder > nicht? 6502 und der eben verlinkte ARM1 verwenden mit ihren Takten Φ1 und Φ2 auch irgendwo Taktflanken innerhalb einer Taktperiode. Aber das ist nicht wirklich massgeblich für die Betrachtung hier. Man kann innerhalb eines Taktes auch mehrere Aktionen nacheinander durchführen, ohne dazwischen Latches/Register zu setzen. Exakt wie die oben gezeigten 3 Phasen der Execute-Stage des AVR ablaufen, ist nicht dokumentiert.
Lustig ist in dem Zusammenhang evtl., dass der ATMega328P Nachbau namens MD-328D und seine Brüder, an vielen Stellen 1 Takt fixer sind, als das Original. Wenn ich mich richtig erinnere, war die Begründung, dass da drin ein zurecht gestutzter 16 Bit Kern werkelt.
Angehängte Dateien:
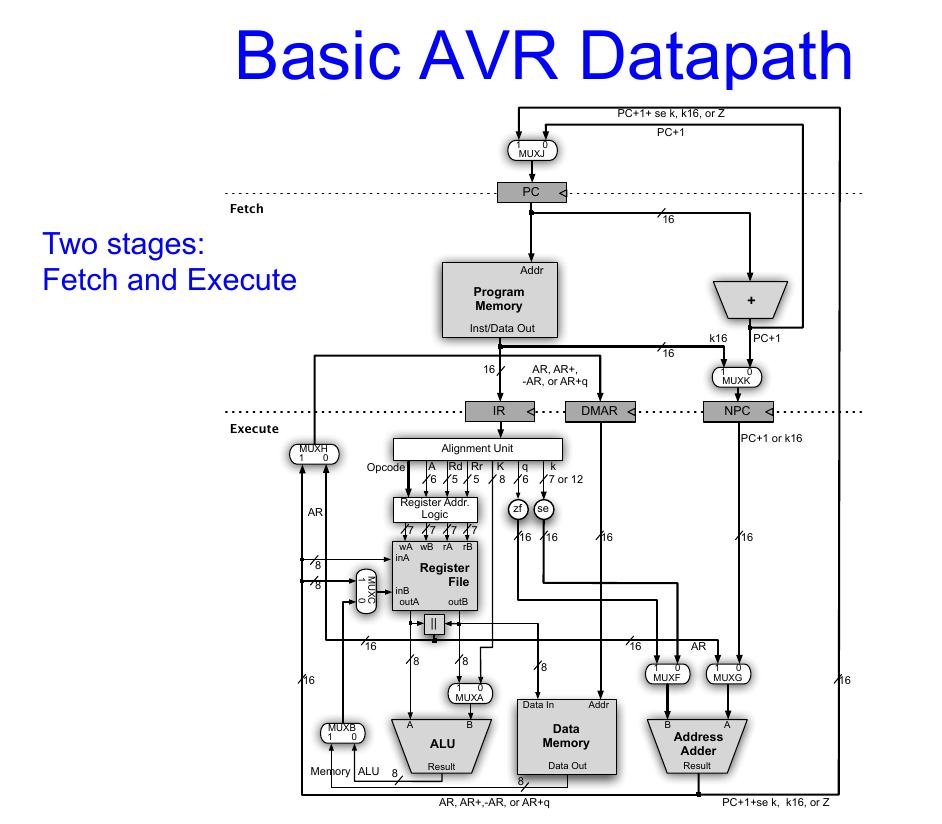
Martin S. schrieb: > Zumal -> wenn man zwei Operanden über einen Bus holt, geht das doch > schlecht gleichzeitig, Ist auch nicht so. Register werden über mehrere Ports und Busse gleichzeitig angesprochen. Obiges Diagramm fand ich einstmals in einem Paper der Oregon State University. Das Paper beschreibt den Ablauf in einem AVR sehr detailliert. Link wäre mir lieber, fand ich jetzt aber nicht. Quelle dürfte Reverse Engineering sein, nicht Atmel.
EAF schrieb: > Lustig ist in dem Zusammenhang evtl., dass der ATMega328P Nachbau namens > MD-328D und seine Brüder, an vielen Stellen 1 Takt fixer sind, als das > Original. Auch beim Original gibt es hier Varianten. Siehe ATXmega und vor allem dessen Erben, die ganzen neueren AVR8-Baureihen. Vermutlich haben die Chinesen einen raubkopierten XMega-Core mit der (ebenfalls raubkopierten) ollen ATMega-Peripherie kombiniert. Naja, wenn die Chinesen irgenwas können, dann ist das: Kopieren. Wenn sie das Ergebnis dann wirklich umfassend dokumentieren würden, wäre dagegen ja nichtmal etwas einzuwenden...
Beitrag #7308626 wurde von einem Moderator gelöscht.
(prx) A. K. schrieb: > wird erst durch Pipelining erreicht, wenn auch beim AVR nur rudimentär. ?Rudimentäres Pipelining", ist das sowas wie der "rudimentäre Schwanz des Homosapiens", auch Coccyx???? Also Pipeling wird nach Stufen unter Angabe einer Ganzzahl klassifiziert. Beispielsweise 6-stufige Pipeline beim MC68040 oder 20-stufige beim Pentium 4 'Prescott'. Was soll dann "rudimentäres Pipelining" sein?? Eine 1.5708963268-stufige Pipieline? Oder doch eher 0.5 stufige. Also da hat man schon den Eindruck, da wird des Wort "rusimentäre" aus dem Hut gezaubert, wenn man unbedingt über etwas sprechen will, dessen Vorhandensein/Aufbau/Struktur aber man überhaupt nicht beschreiben kann. Diese Vorgehensweise soll im Marketing häufig vorkommen.
Fred Focus schrieb: > Was soll dann "rudimentäres Pipelining" sein?? Ein zweistufiges. Die kleinstmögliche Variante. Aber Hauptsache gelabert, gell?
Fred Focus schrieb: >>Thx > Tipp: besorg dir ein Buch über Computerarchitektur, dann kannst du Dich > selber schlau machen und musst nicht das Forum mit theoretischen > Pillepalle beschäftigen Dafür ist das Forum da.
Aus dem Bild: Beitrag "Re: 1 Befehl pro Zyklus" geht eindeutig hervor dass es eine ganze menge 8 Bit Verbindungen gibt, gerade unter ALU, Registern und RAM, anders kanns ja auch gar nicht gehen...sonst kommt man nie auf diese Geschwindigkeit bei der Abarbeitung ohne eine PLL. Das Bild: Beitrag "Re: 1 Befehl pro Zyklus" https://www-user.tu-chemnitz.de/~heha/hsn/chm/ATmegaX8.chm/bild/b7-5.png ist somit verwirrend und falsch. Das hier trifft zumindest das mini "Pipelining" https://www-user.tu-chemnitz.de/~heha/hsn/chm/ATmegaX8.chm/bild/b7-4.png
Martin S. schrieb: > ist somit verwirrend und falsch. Verwirrend, weil es nur die zweite Stufe der Pipeline beschreibt. Als solches aber nicht unbedingt falsch.
Martin S. schrieb: > ist somit verwirrend und falsch. Nö. Ist nicht falsch. Ist lediglich vereinfacht. In Wirklichkeit sind da ja noch viel mehr Einzelschritte in den Signalverläufen.
MaWin schrieb: > Aber Hauptsache gelabert, gell? Danke, gleichfalls! >> Was soll dann "rudimentäres Pipelining" sein?? > Ein zweistufiges. Die kleinstmögliche Variante. Nein. Ja. Zweistufiges Pipelining, also die Einführung einer zweiten Delay-Flipflop-Stufe in einen bestehenden Pfad zwischen zwei FF-Stufen ist tatsächlich die einfachste Variante des Pipelining. Hier (AVR) wird aber kein kombinatorischer Pfad zur Taktsteigerung aufgebrochen. Hier ist bestenfalls eine Bufferstufe zwischen internen Flash und CPU-Core integriert. Das entspricht aber keiner Pipelinenestufe sondern einer BusInterfaceUnit - BIU, die fälschlicherweise dem Pipeling zugerechnet wird. Und bei µC mit internen Programmspeicher meist überflüssig ist, da bei 100 ns (10MHz) ausreichen Laufzeitreserve ist. Zur Erinnerung, Konservativ gerechnet, schafft ein Signal auf Kupfer in 100 ns 20 Meter 'gerade' Strecke.
(prx) A. K. schrieb: > Das Paper beschreibt den Ablauf in einem AVR sehr > detailliert. Link wäre mir lieber, fand ich jetzt aber nicht. Quelle > dürfte Reverse Engineering sein, nicht Atmel. Eher nicht Reverse Engineering, das ist der Standard-Entwurf für einen Prozessor ohne Pipeling, aber mit Auftrennung in ProgrammSpeicherInterface (bei CPU mit externen Süpeicher auch BIU BusInterfaceUnit) und Ausführungseinheit. Beide Einheiten sind über taktgesteuerte FF-Stufen verbunden. Die Ausgangstufe der Ausgangseinheit ist das register PC (ProgrammCounter) die Ausgangsstufe des Programmspeicher besteht aus drei weiteren register: *IR (Instruction read), register für (einen Teil) des Instructionsword *NPC (Next Programm counter: entweder PC+1(1 clock befehl) oder Sprungaddresse (2clock Befehle) *DMA (Data Memory Address), die Adresse bei (Data-)Memory Zugriffen (also weder register noch intermediate) Die selbe Struktur findet man auch in dem oben refenzierten PiBla-HDL-FPGA Code. Oder eben in Standard-Lehrbüchern zu Computerarchitektur, insbesonders Hennessey-Patterson. Da braucht man kein Silicon abschleifen und re-engineering, das erschliesst sich aus dem Verständnis der Computerarchitektur.
Fred Focus schrieb: > Das entspricht aber keiner > Pipelinenestufe sondern einer BusInterfaceUnit - BIU Ja. Das Businterface ist keine Pipelinestufe. Ein Businterface ist ein Businterface. Aber das Businterface wird in einer Pipelinestufe betrieben. Fred Focus schrieb: > Zur Erinnerung, Konservativ gerechnet, schafft ein Signal auf Kupfer in > 100 ns 20 Meter 'gerade' Strecke. Die Instruktionen kommen bei AVR aus dem Flash und die Daten aus einem SRAM. Da geht es nicht nur um reine kombinatorische Signallaufzeiten.
Fred Focus schrieb: > Eher nicht Reverse Engineering, das ist der Standard-Entwurf für einen > Prozessor ohne Pipeling Ob mit oder ohne Pipelining hat mit dem Entwurf selbst erst einmal wenig zu tun. Wenn man diesen Entwurf ohne Pipelining betreiben würde, würden die Befehle halt 2 Takte brauchen, statt effektiv 1 Takt. Ich verstehe gar nicht, warum du hier herumdiskutierst. AVR hat Pipelining und es ist zweistufig. Und damit ist es rudimentär. Da gibt es doch überhaupt nichts zu diskutieren.
Soweit ich AVR verstehe, werden 1-Tick Instruktionen wie folgt ausgeführt, wobei AA die erste Instruktion ist etc:
1 | 123456 |
2 | AA |
3 | BB |
4 | CC |
5 | DD |
6 | EE |
7 | 123456 |
8 | ABCDE = Ready |
Um n Instruktionen auszuführen braucht's also n+1 Ticks, was bedeutet dass man i.W. 1 Instruktion / Tick hat? Es gibt aber auch Instruktionen die 2 (z.B. LDS, STS, BR**) oder mehr brauchen (z.B. BR**, LPM, RETI) wobei das auch vom Core abhängt, und bei BR** ob eine 2-Byte oder 4-Byte Instruktion übersprungen wird. Falls B, D und E 2-Tick Instruktionen sind:
1 | 12345678901 |
2 | AA |
3 | BBB |
4 | CC |
5 | DDD |
6 | EEE |
7 | FF |
8 | GG |
9 | 12345678901 |
10 | A BC D EFG = Ready |
Das sind dann 4*1+3*2+1 = 11 Ticks. Das "+1" bedeutet effektiv, das ab Programmstart gerechnet, alle Instruktionen 1 Tick "zu spät" ihre Wirkung entfalten.
Johann L. schrieb: > Das "+1" bedeutet effektiv, das ab Programmstart gerechnet, alle > Instruktionen 1 Tick "zu spät" ihre Wirkung entfalten. So könnte man es auch ausdrücken.
MaWin O. schrieb: > Ich verstehe gar nicht, warum du hier herumdiskutierst. > AVR hat Pipelining und es ist zweistufig. Und damit ist es rudimentär. > Da gibt es doch überhaupt nichts zu diskutieren. Stimmt, das ist nicht-diskussionswürdiger Unsinn. Erst schreibste rudimentär ist gleich zweistufig, also Pipelinegrad = 2. Und jetzt fabuliert Du von zweistufig plus rudimentär, also Pipelinegrad = 2.x Das ist doch Unsinn. Der AVR hat kein Pipeline, Registerdaten sind im folgenden Takt prozessiert, also normale Taktlatenz, keine zusätzliche Pipilinelatenz. Anders als bspw. gepipelinden Multiplizierer, bei dem es länger als einen Takt dauert bis die Eingangsdaten fertig multipliziert sind (Pipilinelatenz). http://courses.csail.mit.edu/6.111/f2008/handouts/L09.pdf S.17ff
Fred Focus schrieb: > Stimmt, das ist nicht-diskussionswürdiger Unsinn. Ich gebe es auf. Das ist mir jetzt zu dumm.
Fred Focus schrieb: > Der AVR hat kein Pipeline Doch hat er. Eine zweistufige (Fetch&Execute)-Pipeline. > Registerdaten sind im folgenden Takt > prozessiert, also normale Taktlatenz, keine zusätzliche Pipilinelatenz. Doch, diese beträgt genau einen Takt. Und jeder Nicht-Vollidiot kann das alleine schon der InstructionSetReference entnehmen.
MaWin O. schrieb: > Und damit ist es rudimentär. > Da gibt es doch überhaupt nichts zu diskutieren. Na doch, dass der Begriff hier etwas holperig rüberkommt, kann damit zu tun haben, dass das Pipeline-Know bzw. der Schritt dahin, alles andere als trivial war. Sprungvorhersage, Mikrocodierung, Register Renaming und all solche Scherze enthalten eine Menge Gehirnschmalz und Blut, selbst die CPU-Logik gehört da noch mit dazu - und wer meint (mit rudimentär) das könne man gewissermaßen alles in 21 Tagen lernen, wie C++ (oder mal eben an einem Nachmittag durch Lesen einer Forendisskussion) - sollte sich nicht über Beschwerden wundern.
rbx schrieb: > Sprungvorhersage, Mikrocodierung, Register Renaming und all solche > Scherze enthalten eine Menge Gehirnschmalz und Blut, selbst die > CPU-Logik gehört da noch mit dazu Ja. Und das alles hat mit dem Pipelining, wie es im AVR vorkommt, nichts zu tun. Eben weil das Pipelining im AVR rudimentär ist. Der AVR nutzt eine simple fetch- und eine execute-stage.
rbx schrieb: > Na doch, dass der Begriff hier etwas holperig rüberkommt, Ich ja schon gut, ich nehme den Begriff "rudimentär" zurück und ersetze ihn durch "minimal". ;-) Fred Focus schrieb: > Der AVR hat kein Pipeline, Registerdaten sind im folgenden Takt > prozessiert, also normale Taktlatenz, keine zusätzliche Pipilinelatenz. Auch mein PC Prozessor kann Integer-ALU Ergebnisse meist im Takt darauf in einer ALU verwenden, und nicht zwingend in der gleichen. Deinem Kriterium zufolge wäre er also nicht pipelined. ;-) Die von dir vermisste Latenz bei Registerdaten gibt es aber durchaus. Nämlich zwischen dem Z-Register und dem PC-Register bei IJMP. Da geht der Weg vom Output der zweiten Stufe der Pipeline zurück zum Input der ersten, was einen Takt kostet. Ob die Execute-Stage das direkt aus Z durchschiebt, wie bei IJMP, oder was reinaddiert, wie in PC = PC + Offset bei den relativen Sprüngen, ist in dieser Hinsicht aber egal.
Fred Focus schrieb: > Der AVR hat kein Pipeline, Registerdaten sind im folgenden Takt > prozessiert, also normale Taktlatenz, keine zusätzliche Pipilinelatenz. Vielleicht liegt das Missverständnis darin, dass es in der Mikroarchitektur von Prozessoren Pipelining auf mehreren Ebenen geben kann. Und du eine andere Pipeline meinst als ich. Einerseits gibt es Pipelining im Gesamtablauf. Sowas wie Fetch-Decode-Execute beim ersten ARM und eben Fetch-Execute bei AVR. Von dem ist hier die Rede, weil es um den Gesamtablauf der Befehle geht. Andererseits kann es Pipelining in Execution Units geben. Wenn beispielsweise der Multiplizierer zwar 3 Takte braucht, bis er das Ergebnis liefert, aber in jedem Takt eine neue Multiplikation durchführen kann. In diesem Sinn ist die ALU des AVR nicht gepipelined.
Bei komplexeren CPUs hat man auch den Effekt, daß nach Interruptfreigabe oder RETI direkt nach dem Löschen des Interruptflags der Interrupt trotzdem noch angesprungen wird. Da muß auch erst noch eine Pipeline durchlaufen werden, ehe das Löschen angekommen ist.
Peter D. schrieb: > Bei komplexeren CPUs hat man auch den Effekt, daß nach Interruptfreigabe > oder RETI direkt nach dem Löschen des Interruptflags der Interrupt > trotzdem noch angesprungen wird. Da muß auch erst noch eine Pipeline > durchlaufen werden, ehe das Löschen angekommen ist. Bei den alten AVRs hatte SEI ja eine Latenz von 1 Instruktion, aber CLI nicht. Keine Ahnung, wie diese Asymmetrie entsteht. Bei XMega wirkt SEI unmittelbar, d.h. vor der nächsten Instruktion kann eine IRQ triggern. Vermutlich überträgt sich dieses Verhalten auch auf RETI?
Johann L. schrieb: > Bei den alten AVRs hatte SEI ja eine Latenz von 1 Instruktion, aber CLI > nicht. Keine Ahnung, wie diese Asymmetrie entsteht. Das hat ausnahmsweise einmal nichts mit Pipelining zu tun, sondern mit der SLEEP-Instruktion. Mit einer 1er-Latenz für SEI ist es möglich sicher schlafen zu gehen, ohne durch eine Interrupt-Racecondition unendlich lange zu schlafen, falls der Interrupt vor dem sleep kommt.
1 | sei |
2 | sleep ; sei wird erst hier - gleichzeitig mit sleep - aktiv und ein Interrupt weckt sleep wieder auf. |
(prx) A. K. schrieb: > Fred Focus schrieb: >> Der AVR hat kein Pipeline, Registerdaten sind im folgenden Takt >> prozessiert, also normale Taktlatenz, keine zusätzliche Pipilinelatenz. > > Vielleicht liegt das Missverständnis darin, dass es in der > Mikroarchitektur von Prozessoren Pipelining auf mehreren Ebenen geben > kann. Und du eine andere Pipeline meinst als ich. Man nähert sich. Dem Graben, der unüberbrückbar ist. Es wird auf mehreren ebenen von Pipelining "gesprochen" was aber nicht bedeutet, das es tatsächlich pipeling ist. Ich hab mal das entsprechende Kapitel aus der deutschsprachigen Fachliteratur (P.Pirsch: "Architekturen der digitalen Signalverarbeitung") gescannt und angehangen. Pipeling ist das Einfügen von Pipeline-Register um den kritischen Pfad in der Kombinatorik zu verkürzen. > Einerseits gibt es Pipelining im Gesamtablauf. Sowas wie > Fetch-Decode-Execute beim ersten ARM und eben Fetch-Execute bei AVR. Von > dem ist hier die Rede, weil es um den Gesamtablauf der Befehle geht. Eben das ist Hardwaretechnisch kein Pipeling, wie schon 2006 hier diskutiert: Beitrag "AVR +Pipelining" Das sind zwei parallel arbeitsfähige Units: Prefetch und Execute. Das AVR_Manual (oder das -Marketing) führt dafür den Begriff single-level-pipelining ein, was die Auswahl der hier im Thread gemachten Klassifizierungen für ein und die desselbe Architektur weiter Vergrössert: *kein Pipeling *rudimentäres Pipelining *single level pipelining *Zweistufige Pipeline (==kleinstmögliches) ############ PC-Freak schrieb: > Fred Focus schrieb: >> Tipp: besorg dir ein Buch über Computerarchitektur, dann kannst du Dich >> selber schlau machen und musst nicht das Forum mit theoretischen >> Pillepalle beschäftigen > > Dafür ist das Forum da. Nöö, das Forum ist nicht dazu da dir die Mühen des (Selbst-)studiums abzunehmen. Hier hat keiner Bock Dir den privaten und unbezahlten Hochschullehrer zu geben. Und wie man an der Kakophonie der hingeworfenen Begriffe/Antworten zu ein und der selben Frage sieht ist "das Forum" praktisch dazu garnicht in der Lage.
Fred Focus schrieb: > Eben das ist Hardwaretechnisch kein Pipeling Eine Beschreibung von Pipelining der von mir skizzierten zweiten Art schliesst nicht die Verwendung des Begriffs in der ersten Art aus. Ich stecke in dem Thema schon recht lange und recht tief drin, um ausgiebig beiden Verwendungen begegnet zu sein. Man kann anderen eine Brücke bauen, aber drüber laufen müssen sie selber. Weiter darüber zu diskutieren, halte ich für sinnlos.
MaWin O. schrieb: > Johann L. schrieb: >> Bei den alten AVRs hatte SEI ja eine Latenz von 1 Instruktion, aber CLI >> nicht. Keine Ahnung, wie diese Asymmetrie entsteht. > > Das hat ausnahmsweise einmal nichts mit Pipelining zu tun, sondern mit > der SLEEP-Instruktion. > > Mit einer 1er-Latenz für SEI ist es möglich sicher schlafen zu gehen, > ohne durch eine Interrupt-Racecondition unendlich lange zu schlafen, > falls der Interrupt vor dem sleep kommt. > > sei > sleep ; sei wird erst hier - gleichzeitig mit sleep - aktiv und ein > Interrupt weckt sleep wieder auf. Und wie ist das aus XMega gelöst, wo SEI keine Latenz hat? Auf die Schnelle hab ich in avr/sleep.h nix gefunden, sleep_cpu() bildet einfach nur auf SLEEP ab.
Johann L. schrieb: > Und wie ist das aus XMega gelöst, wo SEI keine Latenz hat? Das weiß ich leider nicht. Mit XMega kenne ich mich nicht aus.
(prx) A. K. schrieb: > Fred Focus schrieb: >> Eben das ist Hardwaretechnisch kein Pipeling > > Ich > stecke in dem Thema schon recht lange und recht tief drin, um ausgiebig > beiden Verwendungen begegnet zu sein. Soso, willste jetzt Alterspoker spielen? Wer am frühesten das Wort Pipeling im Gehörgang hatte gewinnt?! > Man kann anderen eine Brücke bauen, aber drüber laufen müssen sie > selber. Nicht jede Brücke ist tragfähig. Und nicht jede Grenzüberschreitung ist der sprichwörtliche Schritt nach vorn (siehe Zeitenwende). > Weiter darüber zu diskutieren, halte ich für sinnlos. Dann hättest Du dir diesen beitrag besser gespart. Und statt Worte drüber auszutauschen ist die Selbsterfahrung, sprich der Eigenbau einer CPU bspw. im FPGA Erfahrungsreicher. Da macht den Unterschied zwischen marketinggetöse und technischer Terminologie schnell klar.
Fred Focus schrieb: > er am frühesten das Wort > Pipeling im Gehörgang hatte gewinnt?! Kannst du nicht einfach aufhören? Jeder hat verstanden, dass du eine andere Definition von Pipelining verwendest. Und das ist auch in Ordnung. Ich bleibe bei meiner und du bei deiner. Ok?
Fred Focus schrieb: > Soso, willste jetzt Alterspoker spielen? Wer am frühesten das Wort > Pipeling im Gehörgang hatte gewinnt?! Mir reicht, was Hennessy/Patterson über Computer Architecture schreiben. https://www.amazon.de/-/en/John-L-Hennessy/dp/012383872X
MaWin O. schrieb: > Fred Focus schrieb: >> er am frühesten das Wort >> Pipeling im Gehörgang hatte gewinnt?! > > Kannst du nicht einfach aufhören? Warum ist es wichtig, wer hier wann aufhört? Meinst Du derletzte gewinnt? Also doch Poker? Oder Hasenfußrennen? > Jeder hat verstanden, dass du eine andere Definition von Pipelining > verwendest. > Und das ist auch in Ordnung. > Ich bleibe bei meiner und du bei deiner. > Ok? Nein, ist nicht OK, wenn es (mindestens) vier verschiedene Antworten auf die Frage "Wieviel Pipelinestufen hat der AVR" gibt. Fragt Dich einer nach dem Ergebnis von 1 + 2, antwortest du ja auch "Drei" und nicht: Die Antwort ist "Rudimentär, also 3, was die kleinstmögliche Variante ist" ?!
(prx) A. K. schrieb: > Fred Focus schrieb: >> Soso, willste jetzt Alterspoker spielen? Wer am frühesten das Wort >> Pipeling im Gehörgang hatte gewinnt?! > > Mir reicht, was Hennessy/Patterson über Computer Architecture schreiben. > https://www.amazon.de/-/en/John-L-Hennessy/dp/012383872X Und, was schreiben sie? Ich habe 978-3-486-59190-3 vorliegen.
Fred Focus schrieb: > Und, was schreiben sie? Ich habe 978-3-486-59190-3 vorliegen. Ich nicht, andere Ausgabe. Dort ab A.1. "Pipeline: Basic and Intermediate Concepts".
Fred Focus schrieb: > Nein, ist nicht OK Ja, dann. Gut. Du wirst aber damit leben müssen, dass ich eine andere Meinung habe als du. > Warum ist es wichtig, wer hier wann aufhört? Weil diese Diskussion zu nichts führt. Du bist genau so wenig bereit von deinem Standpunkt abzurücken, wie ich. Wir haben beide unsere Standpunkte begründet und definieren eine Sache eben etwas anders. Beide mit Begründung. Damit wirst du leben müssen. Ich kann es sehr gut. Damit war das dann das letzte Wort von mir zu diesem Thema zu dir.
MaWin O. schrieb: > Damit war das dann das letzte Wort von mir zu diesem Thema zu dir. OK, dann behalte ich mal: "AVR hat Pipelining und es ist zweistufig. Und damit ist es rudimentär. " als Deine Meinung in Erinnerung. Wie auch den Text aus dem AVR-manual "Instructions in the program memory are executed with a single level pipelining." Und trage damit in das Wörterbuch "MarWin-English/English-MarWin" die Zeile "zweistufiges Pipelining" (Marwin) = "single level pipelining" (engl.) ein.
(prx) A. K. schrieb: > Ich nicht, andere Ausgabe. So ungefähr die hier, aber -2 am Ende. Hat etliche Seiten mehr. https://www.amazon.de/-/en/John-L-Hennessy/dp/1558607242
Beitrag #7309835 wurde von einem Moderator gelöscht.
(prx) A. K. schrieb im Beitrag #7309835: > Womit er nicht alleine ist: "The AVR has a 2 stage single level > pipeline, which is a simple pre-fetch and execute system." Ich vermute einmal, dass er kein Informatiker, sondern ein Hardwareentwickler ist. Das würde es erklären. Es ist halt ein Begriff, der in unterschiedlichen Fachbereichen leicht unterschiedliche Bedeutungen hat. Die Arm-Pipeline - am R52 Beispiel - habe ich ja auch schon hier gepostet: https://developer.arm.com/documentation/100026/0103/Cycle-Timings-and-Interlock-Behavior/About-cycle-timings-and-interlock-behavior/Pipeline-information Soweit ich das verstehe (achtung hier könnte ich falsch liegen) ist two-way = two-level.
Angehängte Dateien:
-

HenPatS333.jpg
170 KB

(prx) A. K. schrieb: > (prx) A. K. schrieb: >> Ich nicht, andere Ausgabe. > > Die hier. Hat etliche Seiten mehr. > https://www.amazon.de/-/en/John-L-Hennessy/dp/1558607242 Und soll ich jetzt, mehr Seiten kopieren um 'Unentschieden' zu erreichen? Also was ist jetzt konkret das was: >Mir reicht, was Hennessy/Patterson über Computer Architecture schreiben. Ganz abgesehen davon, das du hier keinen Hennessey/Patterson als ISB verlinkst sondern einen Hennessey als einzig genannten Autor? Anbei ein Scan aus 'meinem' Exemplar. Darin wird genannt, das man aus der Anzahl der Takte in der Ausführungszeit auf die Einzal der Pipelinestufen schliessen kann. Und da nun der AVR die meisten Opcodes in einem Takt ausführt (siehe die Scanschnipsel gestern) kann man bestenfalls von einer einstufigen Pipeline sprechen, aber keinesfalls von einer zweistufigen. Und dies stimmt auch mit dem AVR-Manual überein "single level pipelining". Ob man eine einstufige Pipeline, also ein Förderband mit einer "Arbeitsstation" noch als Pipeling bezeichnen kann, ist vielleicht ein weiterer Disput. Aber von zweistufig kann man bei AVR wirklich nicht reden. Der HenPat unterscheidet in Pipelining im Daten-Pfad und Pipeling im Steuerwerkvielleicht begründet das ja die Verwirrung. Ferner konzentriert er sich auf den Entwurf ganze Befehlssätze, die dann eben auf Pipeling optimiert sind. Beim AVR ist eben der Befehlssatz so optimiert, das die häufigsten Befhle (registeroperationen) durch Pipeling nicht optimiert werden können. Ein typischer Entwurfsansatz bei RISC-maschinen.
MaWin O. schrieb: > Ich vermute einmal, dass er kein Informatiker, sondern ein > Hardwareentwickler ist. Das würde es erklären. Zumindest steckt er offenbar nicht wirklich in Rechnerarchitektur drin. Denn sonst wäre er schon längst massenhaft über https://en.wikipedia.org/wiki/Instruction_pipelining gestolpert. Kann man beim besten Willen nicht vermeiden. Hennessey diese Art von Pipeline absprechen zu wollen, entbehrt nicht einer gewissen Komik. Immerhin gilt er als Schöpfer der Standford MIPS Prozessoren, ausgeschrieben Microprocessor without Interlocked Pipeline Stages. Und damit sind genau diese Art von Pipelines gemeint, und die Vermeidung von Locks durch Delay-Slots bei Lade- und Sprungbefehlen. > Es ist halt ein Begriff, der in unterschiedlichen Fachbereichen leicht > unterschiedliche Bedeutungen hat. Wobei Pipelining von Execution Units auch Teil von Rechnerarchitektur ist. > Soweit ich das verstehe (achtung hier könnte ich falsch liegen) ist > two-way = two-level. Der "single level pipelining" Ausdruck war mir bisher neu. Aber auch Google findet den fast nur im Kontext von AVRs. Generell ist der Begriff "level" im Kontext von Pipelining nicht üblich. Dein "way" übrigens auch nicht, der gehört zu Caches.
Angehängte Dateien:
-

ARM-Cortex_Blockbild.jpg
100 KB
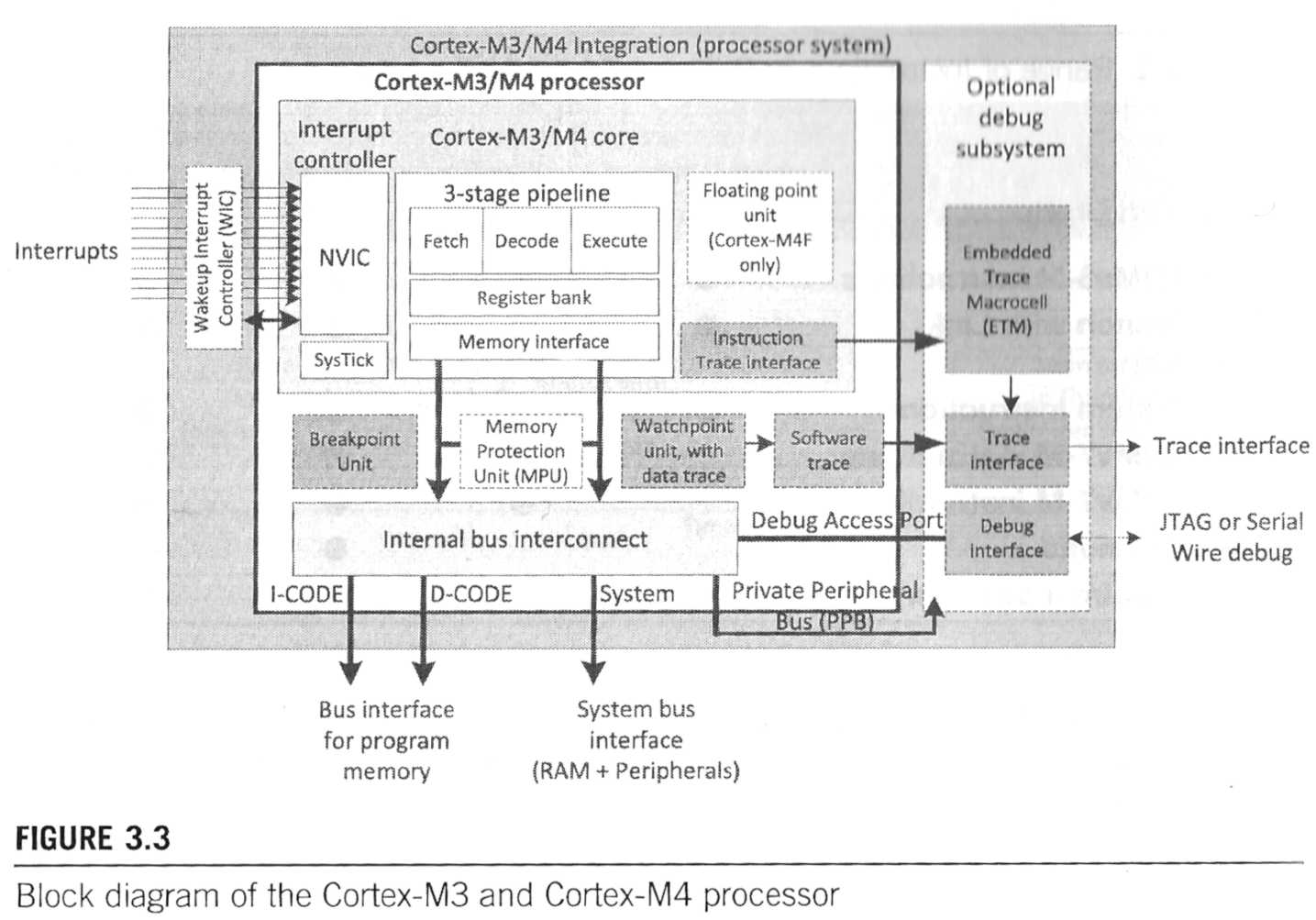
MaWin O. schrieb: > Die Arm-Pipeline - am R52 Beispiel - habe ich ja auch schon hier > gepostet: > > https://developer.arm.com/documentation/100026/0103/Cycle-Timings-and-Interlock-Behavior/About-cycle-timings-and-interlock-behavior/Pipeline-information > > Soweit ich das verstehe (achtung hier könnte ich falsch liegen) ist > two-way = two-level. Naja Wert auf eine gepflegte Hand-Bibliothek scheint man ja hier nicht zu legen ... Anbei das Blockbild für Cortex-M3 und -M4 aus ISBN: 978-01-12-408082-9. Da steht 3-stage Pipeline und das bezieht sich wohl auf die Execution-Unit allein (Fetch/Decode/Execute), das Speicherinterface ist extra aufgeführt und wird wohl nicht zu den Pipeline-Stages hinzugerechnet. Aber da ARM ein ganzer Zoo an CPU's ist, gibt es wohl auch einige mit höheren Angaben zu pieline-stages, eher aus der auf Performance gezüchteten A-Reihe, statt der für (stronspar-embedded) optimierten M-Reihe. Beim ARM-11 sollen es wohl 7 stages sein.
(prx) A. K. schrieb: > Denn sonst wäre er schon längst massenhaft über > https://en.wikipedia.org/wiki/Instruction_pipelining gestolpert. Kann > man beim besten Willen nicht vermeiden. Scherzkeks, wikipedia hat nicht unbedingt den Status einer referenzierbarer fachliteratur, jedenfalls nicht allgemein. Den Artikeln über Fußballspieler mag man glauben, bei vielen anderen ist gesunde Skepsis angesagt. Die IT-Artikel gehen selten über das Niveau von Computermagazin hinaus und oftmals verschlechtern sich die Artikel im Laufe der Zeit, weil irgendein Studiosis sich und seinen Nickname verweigen will und reinpresst was er gerade beim Mensagespräch von denen aufgeschnappt hat, die nicht die Vorlesung schwänzten.
(prx) A. K. schrieb: > Der "single level pipelining" Ausdruck war mir bisher neu. Aber auch > Google findet den fast nur im Kontext von AVRs. Generell ist der Begriff > "level" im Kontext von Pipelining nicht üblich. Dein "way" übrigens auch > nicht, der gehört zu Caches. Ja, das sehe ich auch so. "Level" und "way" ist mir vorher im Zusammenhang mit Pipelines auch noch nicht untergekommen. Google findet da auch praktisch nichts. Festhalten kann man lediglich, dass weder "level" noch "way" das gleiche bedeuten wie "stages".
Fred Focus schrieb: > Da steht 3-stage Pipeline Solche Bilder sind für die Aussage zu den Pipeling-Stufen ungeeignet. Dafür sind sie auch nicht da. Fred Focus schrieb: > Ganz abgesehen davon, das du hier keinen Hennessey/Patterson als ISB > verlinkst sondern einen Hennessey als einzig genannten Autor? Och menno. Was kann ich dafür, wie Amazon die Links nennt. Einmal draufgeklickt kommt "English edition by John L. Hennessy (Autor), David A. Patterson (Autor)" und auf dem Titelbild stehen auch beide. In beiden Ausgaben. Ist das Standardwerk zu Rechnerarchitektur. > Anbei ein Scan aus 'meinem' Exemplar. Darin wird genannt, das man aus > der Anzahl der Takte in der Ausführungszeit auf die Einzal der > Pipelinestufen schliessen kann. Kann man nicht, weil der Begriff "Ausführungszeit" mehrdeutig ist. Atmel/Microchip geben das an, was man in der Branche als "Latency" bezeichnet. Wie lange man drauf warten muss, bis es weiter geht. Die Fetch-Stage ist da nur drin, wenn sie relevant ist: bei Sprüngen. Das interessiert den Programmierer nämlich weit mehr als die Details der Mikroarchitektur. Wenn beim 32-Bit Pentium 4 in diesem Sinn eine Ausführungszeit von 0,5 Takten für ADD reg,reg genannt wird, dann ändert das nichts an der von Intel genannten 20-stufigen Pipeline.
Fred Focus schrieb: > Scherzkeks, wikipedia hat nicht unbedingt den Status einer > referenzierbarer fachliteratur Such halt woanders, du Scherzkeks. ARM verwendet den Ausdruck "Instruction Pipeline" ebenfalls, uvam. Die Erwähnung in der Wikipedia macht ihn ja nicht automatisch falsch.
Fred Focus schrieb: > Beim ARM-11 sollen es wohl 7 stages sein. Wie ist das möglich, wo ARM doch 1 Takt für ADD dokumentiert? ;-)
(prx) A. K. schrieb: > Such halt woanders, du Scherzkeks. ARM verwendet den Ausdruck > "Instruction Pipeline" ebenfalls, uvam. Die Erwähnung in der Wikipedia > macht ihn ja nicht automatisch falsch. Und der WP-Artikel "Instruction-Code" bedeudet jetzt genau ?was? in Bezug auf die Anzahl der Pipelinstufen im AVR? Und in dem Bild aus der ARM-Literatur oben findet sich der Begriff "Instruction Pipeline" nicht sondern "3-stage pipeline" . Was kommt als nächstes? Kaffekochen auf einem Kaffeemaschine mit ARM-Prozessor und Interpretation der Muster die sich im Kaffeesatz bilden?!
Beitrag #7309950 wurde von einem Moderator gelöscht.
Angehängte Dateien:
-

ARM11_ADD.PNG
140 KB
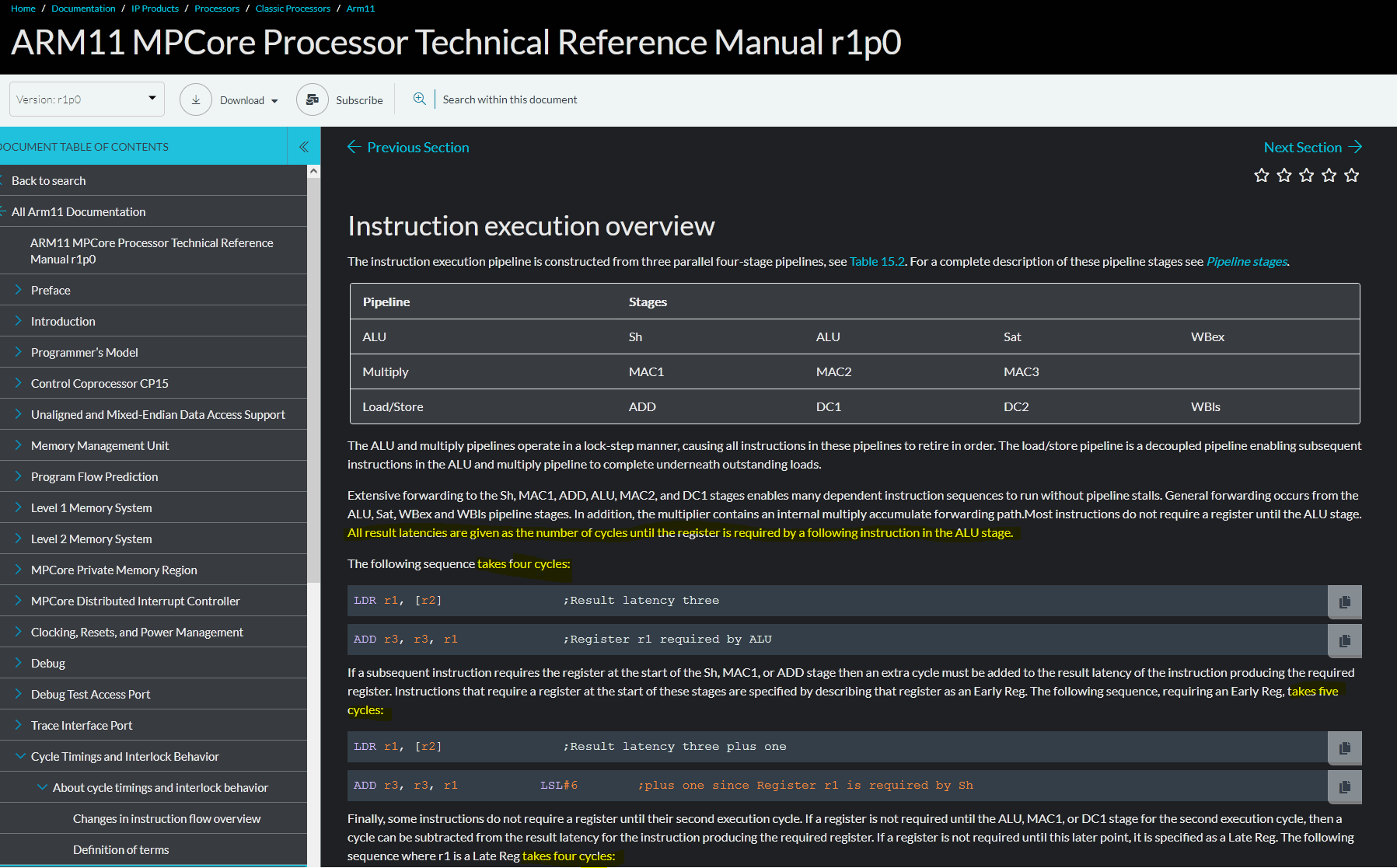
(prx) A. K. schrieb: > Fred Focus schrieb: >> Beim ARM-11 sollen es wohl 7 stages sein. > > Wie ist das möglich, wo ARM doch 1 Takt für ADD dokumentiert? ;-) Weil die latencies einfach auf den Ladebefehl davor resp. danach geschlagen werden, siehe Anhang. Wobei dort von 4 stages pipeline die Rede ist. ARM ist halt ein Zoo an Prozessoren.
(prx) A. K. schrieb: > Ich ja schon gut, ich nehme den Begriff "rudimentär" zurück und ersetze > ihn durch "minimal". ;-) Oder eben einfach, vereinfacht, oder genauer "x-stufig". Naja, ist Haarspalterei hier, ganz abgesehen von dem Hintergrund, dass Pipelining eher der schnelleren Programmabarbeitung dient - aber nicht unbedingt nahe bei der Ausgangsfrage ist. Deswegen ja auch der Hinweise auf "Relativierungen" oben. Vor allem beim ARM sollte man aber, sofern man nicht nur theoretisch unterwegs ist, das konkrete Modell genauer untersuchen, mit welchem man es zu tun hat.
Beitrag #7310039 wurde von einem Moderator gelöscht.
Beitrag #7310050 wurde von einem Moderator gelöscht.
rbx schrieb: > aber nicht unbedingt nahe bei der Ausgangsfrage ist. Die war: jochenPizz schrieb: > Es muss ja der Befehl geholt werden, dekodiert werden, die nötigen > Variablen geladen werden eine Berechnung mit der ALU durchgeführt werden > und dann das Ergebnis und mögliche Statussignale gesetzt werden. Die Frage war also, wie der Gesamtablauf eines Befehls bei AVR und ARM in einem Takt möglich sei. Also mit allem Gedöns, angefangen mit dem Fetch. Und das ähnelt der Frage, wie es möglich sei, dass die Sonne blau-weiss kariert ist. Weil die Voraussetzung der Frage falsch ist: Das dies alles in einem Takt geschähe. Will man also auf diese falsch gestellte Frage sinnvoll antworten, kommt man um das Thema Pipelining nicht herum. Und auch nicht um die Erkenntnis, dass es von Fetch bis Writeback beim AVR 2 Takte sind, bei dem ARMen mehr. Und erst dann spielen die Unterschiede zwischen ARM1 und ARM11 eine Rolle.
(prx) A. K. schrieb im Beitrag #7310050: > Da hat sich nämlich von ARM1 bis Cortex A55 nichts verändert. Also die ersten ARM's waren wohl nochmit Transfer Gates also 'dynamisch' fabriziert und skalierten so garnicht auf andere Taktfrequenzen. Zumal brauchte er zwei sich nicht überlappende takte die erst zusammen einen cycle realisierten. Der ARM2 hatte dann zwei register mehr, mit ARM3 kam ein ein Swap Befehl hinzu Bedingte Befehlsausführung und damit ein ziemliche Kombinatorischer Knoten kam IMHO auch ers später hinzu. Den größten Sprung machte IMHO der ARM6, weil in dem alles reingepresst wurde was Apple für den newton PDA brauchte. Also "nichts verändert" ist ne ziemlich übermütige Ansage.
Fred Focus schrieb: > Also "nichts verändert" ist ne ziemlich übermütige Ansage. Es ging dabei nicht um den gesamten Prozessor, sondern weshalb ADD reg,reg (scheinbar) nur einen Takt benötige. Und das ist im ARM1 genauso falsch oder genauso richtig wie beim A55, je nachdem, ob man den Gesamtablauf oder die Latenz betrachtet.
Fred Focus schrieb: > Bedingte Befehlsausführung und damit ein ziemliche Kombinatorischer > Knoten kam IMHO auch ers später hinzu. Nein. Erst informieren, dann blamieren.
(prx) A. K. schrieb: > Die Frage war also, wie der Gesamtablauf eines Befehls bei AVR und ARM > in einem Takt möglich sei. Also mit allem Gedöns, angefangen mit dem > Fetch. ... Weil die Voraussetzung der Frage falsch ist: Das > dies alles in einem Takt geschähe. Nein die Voraussetzung ist nicht falsch, klar kann man Eintaktmaschinen bauen und hat auch gebaut. Im einstelligen MHZ ist das seit den neunzigern kein Problem. Haben wir alles schon gestern durchgekaut: Beitrag "Re: 1 Befehl pro Zyklus" Und der TO hat auch einen link auf Blockbild und Grundstruktur einer singlecyclemaschine gegeben. Aber natürlich kann man eine Frage immer so umbiegen, das man sie mit dem eigenen Viertelwissen beantworten kann. Wenn etwas an der Voraussetzung fehlerhaft ist, dann das sie keinen quantitiven Rahmen aka Taktdauer nennt.
Fred Focus schrieb: > Weil die latencies einfach auf den Ladebefehl davor resp. danach > geschlagen werden, siehe Anhang. Ladebefehle bei ARMs sind wieder eine andere Baustelle, weil da die dokumentierte Latenz grösser als 1 ist, sie somit überhaupt nicht in den Thread passen. Und inweit man da auf eine Durchsatz von 1 käme, erst recht.
Fred Focus schrieb: > klar kann man Eintaktmaschinen bauen Das war aber nicht die Frage. Es gab nie einen RISC Prozessor, der den gesamten Ablauf ein einem Takt erledigt hätte. jochenPizz schrieb: > wie schafft es ein RISC Prozessor wie ARM oder AVR einen Befehl in nur > einem Zyklus durchzuführen? > und hat auch gebaut. Kann sein. Ich kenne allerdings keinen. Beispiel?
(prx) A. K. schrieb: > Fred Focus schrieb: >> Bedingte Befehlsausführung und damit ein ziemliche Kombinatorischer >> Knoten kam IMHO auch ers später hinzu. > > Nein. Doch, Stichwort THUMB, kann keine bedinget Befehlsausführung (ausser dem üblich JMP). Steht sogar in deiner gepriesenen Wikipedia > Erst informieren, dann blamieren. Das sagt der richtige. Kein Fachbuch zur Hand, aber groß von Informieren tröten.
(prx) A. K. schrieb: > Fred Focus schrieb: >> Weil die latencies einfach auf den Ladebefehl davor resp. danach >> geschlagen werden, siehe Anhang. > > Ladebefehle bei ARMs sind wieder eine andere Baustelle, weil da die > dokumentierte Latenz grösser als 1 ist, sie somit überhaupt nicht in den > Thread passen. Nein das ist die selbe Baustelle, weil eben Register und ALU in der selben Pipeline stecken.
Fred Focus schrieb: > Doch, Stichwort THUMB, kann keine bedinget Befehlsausführung (ausser dem > üblich JMP). Steht sogar in deiner gepriesenen Wikipedia Herrje, krieg wenigstens die Fakten gerade, wenn schon nicht die Ansichten. Thumb kam mit ARM7T(DMI), und damit lange nach ARM1.
(prx) A. K. schrieb: > Fred Focus schrieb: >> klar kann man Eintaktmaschinen bauen > > Das war aber nicht die Frage. Es gab nie einen RISC Prozessor, der den > gesamten Ablauf ein einem Takt erledigt hätte. Doch das ist die Frage, folge einfach dem Link, der in dem allerersten Post mitgegeben wird. > Kann sein. Ich kenne allerdings keinen. Beispiel? Wurden schon mehrmals genannt. Wenn Du Deine Sonnenbrille beim Lesen nicht absetzen willst, weil Du ohne deren Coolness-Faktor nicht ernst genommen wird kann ich Dir leider auch nicht weiterhelfen. > Herrje, krieg bitte die Fakten gerade, wenn schon nicht die Ansichten. > Thumb kam mit ARM7T(DMI), und damit lange nach ARM1. Fakt ist, du hast behauptet es wäre diesbezüglich alles gleich von ARM1 bis ARM55. Ist es nun aber nicht. Also hat rbx schon recht, wenn er daraufbesteht das das konkrete ARM-Modell genannt wird wenn man über Architektur-spezifica spricht.
Fred Focus schrieb: >> Das war aber nicht die Frage. Es gab nie einen RISC Prozessor, der den >> gesamten Ablauf ein einem Takt erledigt hätte. > > Doch das ist die Frage, folge einfach dem Link, der in dem allerersten > Post mitgegeben wird. Habe ich. Dort steht keiner. Nur ein theoretisches Konzept, wie die Turing-Maschine.
Beitrag #7310109 wurde von einem Moderator gelöscht.
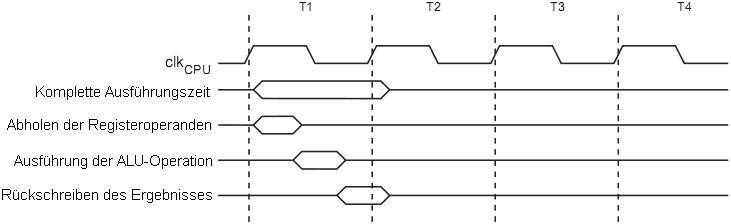
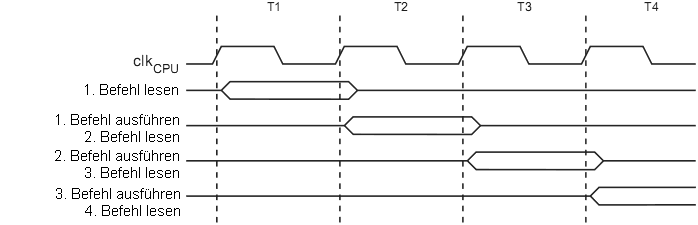
Eine 1-Stufen-Pipeline macht genauso wenig Sinn zu erwähnen wie eine Autoschlange bestehend aus nur einem Auto. Der AVR hat (auch wenn hier das jemand nicht wahr haben will) eine 2-Stufen-Pipeline. (beim XMEGA kann es wohl nicht anders sein) > Ein ST62 schafft 13 Befehle per Takt. Wohl eher nicht. > Ein DSP ist kein universeller RISC-Mikrocontroller. Und darum geht es > hier in dieser Diskussion. Es können in 'MCU's auch DSP-Funktionalit. mit eingebaut sein, wie auch in 'DSP's General-Purpose-Funktionalit. mit eingebaut sein kann. Nur, als 'MCU' verkauft es sich besser. > Ein Takt per Befehl ist ein alter Hut. > Das konnten die DSPs schon lange bevor jemand R.I.S.C. > ueberhaupt buchstabieren konnte. DSP bedeuted nicht zwangsläufig, dass jeder Befehl in einem Takt ausgeführt wird. Es weisst auf mehrere Busse hin. > Sieht man ja, dass es mehr Takte braucht um einen Zyklus auszuführen, > also werden intern mehr Taktflanken inerhalb eines Taktes erzeugt oder > nicht? Nein.
Angehängte Dateien:
-

CyclusGen.png
140 KB
{kind=link}
{kind=link}
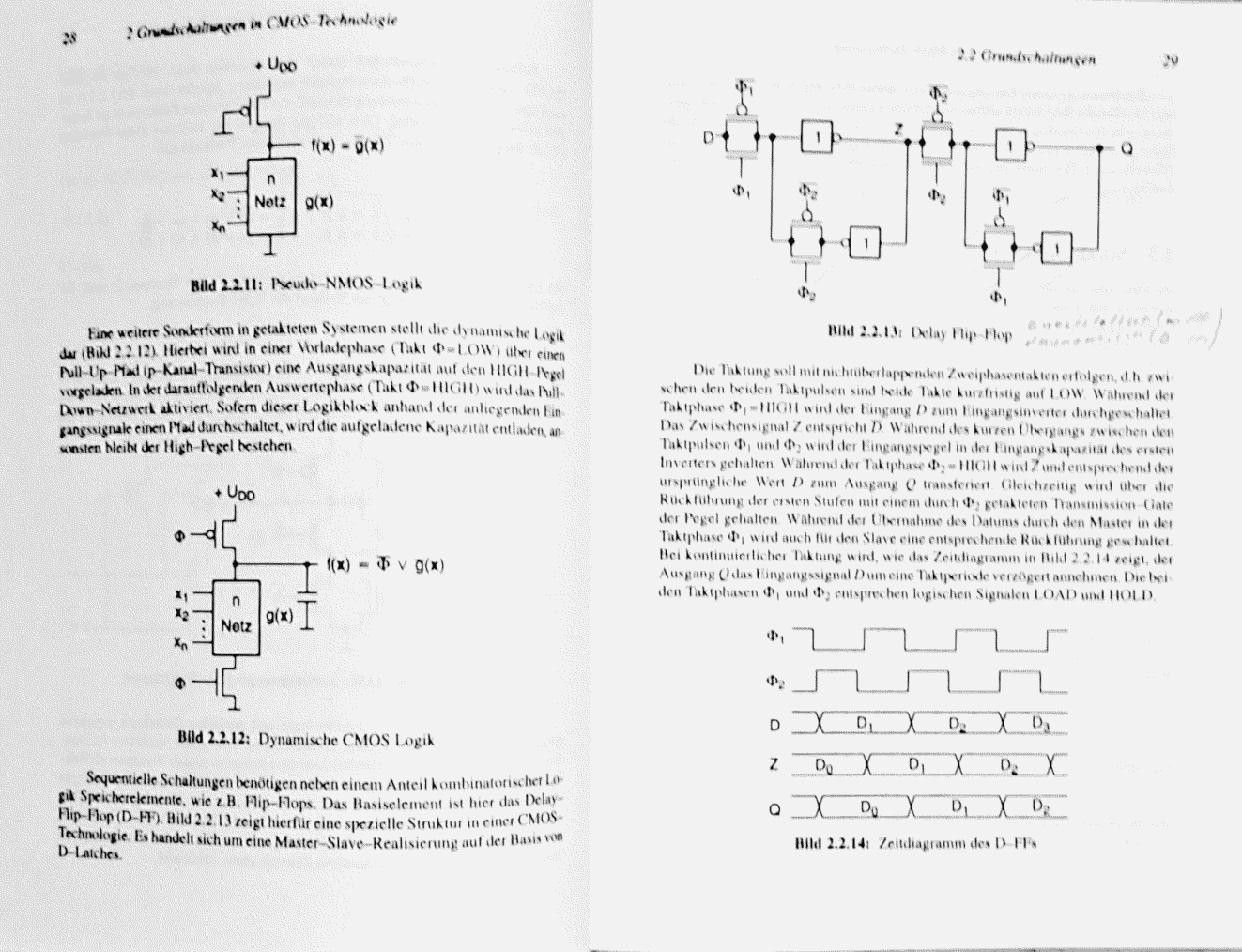
MaWin schrieb: > Martin S. schrieb: >> Sieht man ja, dass es mehr Takte braucht um einen Zyklus auszuführen, >> also werden intern mehr Taktflanken inerhalb eines Taktes erzeugt oder >> nicht? > > Ziemlich sicher nicht. Dazu bräuchte man eine PLL. Doch. Nein. PLL ist nur eine Variante der Implementierung eines Maschinen-Zyklusgenerators. Andere sind DLL (delay looked loop) und bei vorgegebenen Takt-Tastverhältniss 1:1 resp. duty cycle 50% einfache Inverter. In der ARM-Historie ist das sehr gut erkennbar, anfangs wurden extern zwei nicht überlappende Rechtecksignale φ1 und φ2 erzeugt und eingespeist. Irgendwannführte man dann mehrere clock domains ein, eine für das Speicher subsytem eine ander für den Processing-Core. Siehe auch, den Pirsch-Auszug im Anhang. Im AVR Blockbild heisst es gleich vielsagend clock circuit/clock generation.
Fred Focus schrieb: > Doch, Stichwort THUMB, kann keine bedinget Befehlsausführung (ausser dem > üblich JMP). Da spricht mal wieder der Experte Fred. Selbstverständlich kann Thumb mit der IT-Instruktion bedingte Befehlsausführung. Für bis zu vier aufeinanderfolgende nahezu beliebige Instruktionen. (Und außerdem hat Thumb noch die cbz und cbnz Instruktionen, die eine Prüfung und einen Sprung in einem Befehl machen.) https://www.cs.princeton.edu/courses/archive/fall12/cos375/ThumbRefCard.pdf
MaWin schrieb: > Fred Focus schrieb: >> Doch, Stichwort THUMB, kann keine bedinget Befehlsausführung (ausser dem >> üblich JMP). > Selbstverständlich kann Thumb mit der IT-Instruktion bedingte > Befehlsausführung. Für bis zu vier aufeinanderfolgende nahezu beliebige > Instruktionen. Hier wird Thumb und Thumb-2 verwechselt. https://developer.arm.com/documentation/ddi0308/d/Introduction-to-Thumb-2/About-Thumb-2#:~:text=Thumb%2D2%20is%20a%20major,of%20the%20ARM%20instruction%20set. Da bei der Einführung des Thumb Codedichte im Fokus war, musste halt der Zoo an Instructionen eingedampft werden, Da mussten halt die bits für conditional execution dran glauben. Vielleicht habe ja die deutschen ein Problem damit, weil es bei Daumen keine extra Pluralform gibt: der Daumen, die Daumen, zwei linke Hände und rings nur Daumen ...
Fred Focus schrieb: > Hier wird Thumb und Thumb-2 verwechselt. Nein. Du hast nur keine Ahnung von Arm. Aber wen wundert es, nach dem ganzen Quatsch, den du hier bereits abgelassen hast. Thumb-2 ist gar kein eigener Befehlssatz. > Da bei der Einführung des Thumb Codedichte im Fokus war, musste halt der > Zoo an Instructionen eingedampft werden, Da mussten halt die bits für > conditional execution dran glauben. Du wirst es kaum glauben, aber trotzdem hat Thumb conditional execution. (IT-Instruktion). Lies und verstehe doch einmal zur Abwechslung meine Beiträge und die Links, die ich poste.
MaWin schrieb: > Lies und verstehe doch einmal zur Abwechslung meine Beiträge und die > Links, die ich poste. Soso und eigene Recherche und Links wie oben reicht nicht, es muß immer über den Informationsmonopolisten MaWin laufen?! Der bis jetzt kein einziges Fachbuch zu dem Thema aus seiner Handbibliothek ziehen konnte?! Als ganz nach dem erstes Gebot: DU SOLLST NICHT ANDERE MaWins HABEN NEBEN MIR! ICH BIN DER HERR, DEIN MaWin. SCNR > Thumb-2 ist gar kein eigener Befehlssatz. Es gibt Thumb, Thumb2, ThumbEE (inzwischen eingestellt) und auch die Unterschiede zwischen diesen. So wie es eben nicht "den" ARM-Prozessor gibt, sondern einen über Jahrzehnten gewachsenen Dschungel.
Fred Focus schrieb: > Es gibt Thumb, Thumb2, ThumbEE (inzwischen eingestellt) und auch die > Unterschiede zwischen diesen Thumb ist der Name des Befehlssatzes. In allen Fällen. Zu sagen Thumb hätte keine bedingte Befehlsausführung ist ganz einfach falsch. Was willst du mir eigentlich sagen? Dass du sowohl von Pipelining, als auch von Arm keine Ahnung hast? Das ist dir gelungen.
MaWin schrieb: > Was willst du mir eigentlich sagen? > Dass du sowohl von Pipelining, als auch von Arm keine Ahnung hast? Howgh, der Große MaWin hat gesprochen! Nichts zur Sache, nichts mit Beleg, sowie das eben sein Ding ist.
foobar schrieb: > Man hat keine Read-Modify-Write-Befehle auf's RAM, würden > den Datenbus zweimal benutzen. Wobei man eine Pipeline auch darauf einrichten kann. Cyrix's M1/M2 Prozessoren der x86 Szenerie taten dies, während Intels Pentium zwar mit Load-Execute klar kam, aber bei Load-Execute-Store ins Stocken kam.
(prx) A. K. schrieb: > Wobei man eine Pipeline auch darauf einrichten kann. Cyrix's M1/M2 > Prozessoren der x86 Szenerie taten dies Natürlich kann man das. Aber es geht hier im Thread um RISC. Dort geht das eben nicht.
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.