Hallo zusammen Eine Frage an die Experten. Ich habe 14 Switches, die ich über Daisy Chain Topology verbunden sein müssen. Die Frage, die ich mir stelle, ist halt "Broadcasting" und Performanz? 1) Ist Broadcasting mit mehrere Switches über Daisy Chain Topology überhaupt möglich? Es sind ja mehrere Switches . . . 2) Performanz: Hat jemand Erfahrung mit so viele Switche? Danke & Grüsse Nxitimi
Innerhalb einer verbundenen Gruppe von Layer-2 Switches werden Broadcasts über alle Switches verteilt. Egal wie die verbunden sind. Wenn die Kaskadierung in gleicher Technik erfolgt, wie die Ports der Switches, also z.B. alles 1 Gbit/s, ist der Flaschenhals natürlich die Verbindung der Switches untereinander.
Nxitimi schrieb: > 1) Ist Broadcasting mit mehrere Switches über Daisy Chain Topology > überhaupt möglich? Es sind ja mehrere Switches Wenn das "dumme" unmanaged Switches sind, werden auch Broadcasts einfach so durchgereicht. Nxitimi schrieb: > 2) Performanz: Hat jemand Erfahrung mit so viele Switche? So Viele hab ich noch nie hintereinander gehängt, aber am besten, du misst selbst nach. iperf ist dein Freund. https://iperf.fr/iperf-doc.php Ansonsten ist der Performance-Verlust bei einzelnen Switches normalerweise vernachlässigbar.
Nxitimi schrieb: > Ist Broadcasting mit mehrere Switches über Daisy Chain Topology > überhaupt möglich? Ja. Nxitimi schrieb: > Performanz: Hat jemand Erfahrung mit so viele Switche? Daisy Chaining riecht nach Flaschenhälsen, sofern die nicht dafür schnellere Ports haben.
Harry L. schrieb: > Wenn das "dumme" unmanaged Switches sind, werden auch Broadcasts einfach > so durchgereicht. Managed Switches müssen das an eine Broadcast-Adresse notwendigerweise auch. Was sollen sie damit denn sonst machen?
Nxitimi schrieb: > "Broadcasting" und Performanz Wenn du vorhast, hohe Last per Broadcasts zu verschicken, dann Vorsicht: Während zielgerichtete Frames per Hardware durchgereicht werden, geschieht das bei Broadcasts u.U. zu Fuss über einen langsamen Steuerprozessor. Der Durchsatz wird dann durch ebendiesen begrenzt. Bei intelligenten Switches kann dir zudem eine Schutz einen Strich durch die Rechnung machen. Die machen dann den Port dicht, der das Netz mit Broadcasts flutet.
(prx) A. K. schrieb: > Innerhalb einer verbundenen Gruppe von Layer-2 Switches werden > Broadcasts über alle Switches verteilt. Egal wie die verbunden sind. Natürlich wird die Information verteilt. Aber sagen wir mal so ich habe Switches mit 2 Ports die so verkettet werden und ich denke schon dass die Frames von jedem Switch angeschaut werden und weiter gereicht werden. Das müsste schon Zeit in Anspruch nehmen??? Das heisst ob ich Broadcaste oder nicht bei meinem Fall bekomme ich die Information doch nicht parallel?? > > Wenn die Kaskadierung in gleicher Technik erfolgt, wie die Ports der > Switches, also z.B. alles 1 Gbit/s, ist der Flaschenhals natürlich die > Verbindung der Switches untereinander.
(prx) A. K. schrieb: > Nxitimi schrieb: >> "Broadcasting" und Performanz > > Wenn du vorhast, hohe Last per Broadcasts zu verschicken, dann Vorsicht: > Während zielgerichtete Frames per Hardware durchgereicht werden, > geschieht das bei Broadcasts u.U. zu Fuss über einen langsamen > Steuerprozessor. Der Durchsatz wird dann durch ebendiesen begrenzt. > > Bei intelligenten Switches kann dir zudem eine Schutz einen Strich durch > die Rechnung machen. Die machen dann den Port dicht, der das Netz mit > Broadcasts flutet. Es sind maximal 200 Bytes die aber so eine Art HartBit Funktion spielen müssen sprich jede 300 ms an alle Teilnehmern - Sicherheitsrelevante Funktionen.
Nxitimi schrieb: > Das müsste schon Zeit in Anspruch nehmen??? Das heisst ob ich > Broadcaste oder nicht bei meinem Fall bekomme ich die Information doch > nicht parallel?? Natürlich kommt das nacheinander. Von einem Ende der Kette zum anderen dauert es länger. In üblichen Gebrauch spielt das keine Rolle, aber wenn du um Mikrosekunden kämpft, dann ist die Daily Chain Topologie ungünstig.
Nxitimi schrieb: > HartBit Du meinst vmtl Heartbeat (Herzschlag). Die Laufzeit von Broadcasts Ende zu Ende ist nicht theoretisch ermittelbar, weil die im Switch u.U. auf völlig andere und weit weniger effiziente Art berhandelt werden.
(prx) A. K. schrieb: > Nxitimi schrieb: >> HartBit Sorry. > > Du meinst vmtl Heartbeat (Herzschlag). Yes. Danke dir.
(prx) A. K. schrieb: > Nxitimi schrieb: >> Das müsste schon Zeit in Anspruch nehmen??? Das heisst ob ich >> Broadcaste oder nicht bei meinem Fall bekomme ich die Information doch >> nicht parallel?? > > Natürlich kommt das nacheinander. Von einem Ende der Kette zum anderen > dauert es länger. In üblichen Gebrauch spielt das keine Rolle, aber wenn > du um Mikrosekunden kämpft, dann ist die Daily Chain Topologie > ungünstig. Innerhalb von 300[ms] muss die Information da sein, sonst geht alles in die Hose. Und wir haben mit mehrere Kollegen diskutiert und konnte die nicht überzeugen dass Broadcasting in dem Fall einfach nichts bringt. Weil eben die Information nacheinander fliesst.
Warum überhaupt Broadcasts? Muss jeder den Status von jedem direkt erfahren?
Hmmm schrieb: > Warum überhaupt Broadcasts? Muss jeder den Status von jedem direkt > erfahren? Das ist auch eine Anforderung. Status muss überall bekannt sein.
Nxitimi schrieb: > Das ist auch eine Anforderung. Status muss überall bekannt sein. Gibt es einen Master, oder sind alle Teilnehmer gleichberechtigt?
Hmmm schrieb: > Nxitimi schrieb: >> Das ist auch eine Anforderung. Status muss überall bekannt sein. > > Gibt es einen Master, oder sind alle Teilnehmer gleichberechtigt? Wir könnten einen Master definieren. Es wäre möglich. Wird uns dabei helfen?
Nxitimi schrieb: > Innerhalb von 300[ms] muss die Information da sein, sonst geht alles in > die Hose. Sehe ich nicht als Problem. Aber wenn dir ein Patient verreckt, wenn der Broadcast einmal dank Volllast 301ms braucht, oder ganz absäuft, dann wirst du wohl oder übel eine länger Mess-Sitzung einplanen müssen. Wie gesagt, nicht alle Switches sind gleich, besonders nicht bei Broadcasts.
(prx) A. K. schrieb: > Nxitimi schrieb: >> Innerhalb von 300[ms] muss die Information da sein, sonst geht alles in >> die Hose. > > Sehe ich nicht als Problem. Aber wenn dir ein Patient verreckt, wenn der > Broadcast einmal dank Volllast 301ms braucht, oder ganz absäuft, dann > wirst du wohl oder übel eine länger Mess-Sitzung einplanen müssen. Wie > gesagt, nicht alle Switches sind gleich, besonders nicht bei Broadcasts. Was würden Sie von dem halten? Haben Sie evtl. Erfahrungen in der Richtung. https://www.mouser.ch/datasheet/2/609/adin2111-2891062.pdf
Nxitimi schrieb: > Was würden Sie von dem halten? Moooment - in Zeiten von Switches mit 10 Gbit/s geht es hier um archaische 10 Mbit/s? Das kommt etwas überraschend. > Haben Sie evtl. Erfahrungen in der Richtung. Mit Ethernet unter Echtzeitbedingungen nicht.
Nxitimi schrieb: > Wir könnten einen Master definieren. Es wäre möglich. > Wird uns dabei helfen? Mein Ansatz wäre, dass die Slaves sich per Unicast beim Master melden und der Master periodisch einen Broadcast rausschickt, in dem er mitteilt, welche Slaves am Leben sind. Das hat den Vorteil, dass die Heartbeat-Meldungen zuverlässiger ankommen, nicht alle Ports zugemüllt werden, die Slaves weniger Pakete verarbeiten müssen und jeder Slave anhand des Master-Broadcasts auch noch herausfinden kann, ob sein Heartbeat-Paket vom Master empfangen wurde.
Dein Vorgehen ist für eine Sicherheitsrelevante Anwendung gefährlich! Wenn dir ein Switch in der Kette abraucht, sind alle nachfolgenden Geräte ebenfalls weg. Besser wäre, wenn du eine Baumstruktur aufbaust. Bei hohen Distanzen dann eventuell auch via Multimode oder Singlemode Glasfaser. Deine 300ms sind in keinem Fall ein Problem, deine Pakete werden viel schneller sein solange die Leitungen nicht ausgelastet sind.
Nxitimi schrieb: > Was würden Sie von dem halten? Kann immerhin cut through switching. Das reduziert die Latenz, weil die Frames nicht zwingend in jedem Hop zwischengespeichert werden. ABER: Ob das auch für Broadcasts und Multicasts gilt? Ggf Hersteller fragen.
Darf's vielleicht noch eine Scheibe mehr Salami sein? Also das wäre ja vielleicht eine Info für früher gewesen bevor man schon über eine Daisychain von 14 Switches mit hunderten angeschlossenen Devices nachgedacht hat und wie die Broadcasts sich benehmen wenn die Links durch anderen Treaffic voll sind... Jetzt sag noch bitte wie viel andere Informationen (wie viel Traffic) da noch auf dieser 10Mbit Leitung sein soll? Oder ist die dediziert nur für diesen Hartbeat und die damit zu bauende Überwachung da? Btw. der Chip hat ein Broadcast Frame Counter, da wird er mit Broadcasts umgehen können...
Angehängte Dateien:
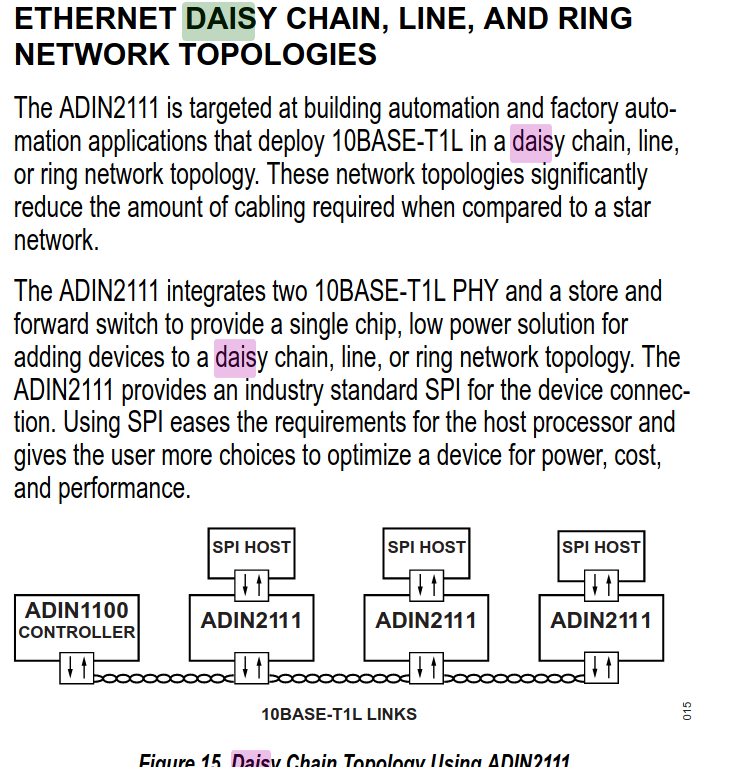
Fleischwarenfachverkäufer schrieb: > Also das wäre ja vielleicht eine Info für früher gewesen bevor man schon > über eine Daisychain von 14 Switches mit hunderten angeschlossenen > Devices nachgedacht hat Bei 14 linear kaskadierten 2-Port Switches sind es maximal 16. Jene Nodes am SPI, plus 2 an den Enden. Diese Chips sind offensichtlich explizit für solche Szenarien gebaut.
> Es sind maximal 200 Bytes die aber so eine Art HartBit Funktion spielen > müssen sprich jede 300 ms an alle Teilnehmern - Sicherheitsrelevante > Funktionen. Mit UDP alleine wirst du diese Garantie nie bekommen. IP (und auch UDP) arbeiten so, dass, wenn ein Paket nicht übertragen werden kann, es sang und klanglos weggeschmissen wird. Eine dieser Situationen ist, wenn ein Port überlastet ist (volle Bandbreite ausgenutzt). Und dies ist kein seltenes Ereignis, das passiert bei jeder TCP-Verbindung: die Übertragungsrate wird Schritt für Schritt erhöht, bis Pakete verloren gehen. Und dein UDP-Broadcast ist auch nur ein normales IP-Paket. Wenn auf dem Port gerade viel los ist, wird das Paket weggeschmissen. Wenn das gesamte Netz nicht ausschließlich für diese sicherheitsrelevante low-bandwidth Anwendung reserviert ist, dürfte das schwierig werden.
Die im Screeenshot erwähnte Ringtopologie sollte man evtl mal näher beleuchten, zwecks Ausfallsicherheit. In ein übliches Ethernet-Kabel kriegt man ja zwei 10-Mbit-Stränge rein, einer hin und einer wieder zurück. Das hilft nicht gegen die Axt, aber gegen eine defekte Node. Und vielleicht auch mal reinsehen, wozu der ominöse ADIN1100 gut ist.
Nxitimi schrieb: > Hallo zusammen > > Eine Frage an die Experten. Ich habe 14 Switches, die ich über Daisy > Chain Topology verbunden sein müssen. Die Frage, die ich mir stelle, ist > halt "Broadcasting" und Performanz? > > 1) Ist Broadcasting mit mehrere Switches über Daisy Chain Topology > überhaupt möglich? Es sind ja mehrere Switches . . . > > 2) Performanz: Hat jemand Erfahrung mit so viele Switche? > Und viele Beiträge später kommt dann „compliant with the IEEE® 802.3cg-2019TM Ethernet standard for long reach 10 Mbps single pair Ethernet (SPE). …“
Nxitimi schrieb: > Und wir haben mit mehrere Kollegen diskutiert und konnte die nicht > überzeugen dass Broadcasting in dem Fall einfach nichts bringt. Weil > eben die Information nacheinander fliesst. Auf Absenderseite bringts natürlich trotzdem was, denn der muss nur ein Paket raus hauen, nicht 100. Und deine Switches müssen nur 1 Paket weiterleiten, nicht 100. Also ja, Broadcasting bringt natürlich was, man darf halt nur nicht so naiv sein zu glauben das Paket käme bei allen Empfängern in der gleichen Mikrosekunde an. Die Latenz pro Switch wird irgendwo zwischen 1µs und 150µs liegen (bei Kollisionen am Netz entsprechend mehr, aber das hat ein shared Medium so an sich). Den Rest kannst du ja ausrechnen, die 300ms sind da weit weg davon.
Das Zeitverhalten dieser Switch-Kette bei 10BaseT1L dürfte nur unwesentlich besser sein als das, was man in der vorderen Altsteinzeit (also kurz nach dem Aussterben der Dinosaurier) als 10Base2 oder 10Base5 kannte. Das war 10-MBit-Ethernet auf Koaxkabel, halbduplex-Betrieb, und eine Kollisionsdomäne (d.h. jeder Teilnehmer am Bus sieht jedes einzelne Paket). Zwar sind die Dinger hier Switches, so daß die angeschlossenen Geräte das Elend auf dem Bus nur dann mitbekommen, wenn sie selbst beteiligt sind, aber ein Paket von einem Teilnehmer an eine Ende zum anderen Ende der Stichleitung muss logischerweise jeden einzelnen Switch passieren. Bei viel Traffic zwischen den einzelnen Teilnehmern wird sich das entsprechend auswirken. Immerhin ist hier von nur 14 Switches die Rede, so daß das Limit von 16 MAC-Adressen dieser Switches keine Probleme machen wird.
Bichael M. schrieb: > Die Latenz pro Switch wird irgendwo zwischen 1µs und 150µs liegen Store-and-Forward-Architektur, d.h. ein Frame muss erst komplett empfangen werden, bevor er weitergesendet wird. Minimale Framegröße 64 Byte = 512 bit (+ 64 Preamble) = 576 bit Minimale Übertragungszeit 576 bit / 10 MBit/s = 58µs. Schneller wird's auf keinen Fall.
Man könnte ja auch Gbit-Switche mit Gbit-Interconnects nehmen und nur die Endgeräteports auf 10Mb drosseln ... LG, Sebastian
foobar schrieb: >> Es sind maximal 200 Bytes die aber so eine Art HartBit Funktion spielen >> müssen sprich jede 300 ms an alle Teilnehmern - Sicherheitsrelevante >> Funktionen. > > Mit UDP alleine wirst du diese Garantie nie bekommen. > > IP (und auch UDP) arbeiten so, dass, wenn ein Paket nicht übertragen > werden kann, es sang und klanglos weggeschmissen wird. Eine dieser > Situationen ist, wenn ein Port überlastet ist (volle Bandbreite > ausgenutzt). Und dies ist kein seltenes Ereignis, das passiert bei > jeder TCP-Verbindung: die Übertragungsrate wird Schritt für Schritt > erhöht, bis Pakete verloren gehen. Und dein UDP-Broadcast ist auch nur > ein normales IP-Paket. Wenn auf dem Port gerade viel los ist, wird das > Paket weggeschmissen. > > Wenn das gesamte Netz nicht ausschließlich für diese > sicherheitsrelevante low-bandwidth Anwendung reserviert ist, dürfte das > schwierig werden. TCP ist eben durch diesen Retrymechanismus für Echtzeitanwendungen unbrauchbar, weshalb Profinet und Co entweder direkt auf Ethernet oder UDP aufsetzen. Wer ein Echtzeit-Protokoll basteln möchte ist gut beraten es davon abzukupfern. Entweder ohne Retry und Busfehler bei Paketverlust, oder einem geschickten Retrymechanismus.
Sebastian schrieb: > Man könnte ja auch Gbit-Switche mit Gbit-Interconnects nehmen und nur > die Endgeräteports auf 10Mb drosseln ... Könnte man, genauso wie man einen Brief per 40-Tonner bis direkt vor die Haustüre fahren kann und dann vom Briefträger in den Briefkasten einwerfen lassen kann.
DerEinzigeBernd schrieb: > Das Zeitverhalten dieser Switch-Kette bei 10BaseT1L dürfte nur > unwesentlich besser sein als das, was man in der vorderen Altsteinzeit > (also kurz nach dem Aussterben der Dinosaurier) als 10Base2 oder 10Base5 > kannte. Andersrum. Es ist schlechter als im Koax. Abgesehen von Kollisionen spielte da nur die begrenzte Ausbreitungsgeschwindigkeit im Kabel eine Rolle. Selbst - im Idealfall - cut through quer durch die Kette sind hier einige gespeichterte Bits pro Node zu überwinden. Allerdings hätte man in dieser Ära Token-Ring in Erwägung gezogen. Das braucht zwar auch einige Bits pro Node, arbeitete aber deterministisch. In manchen Maschinensteuerungen ist aus solchen Gründen auch noch das archaische ARCNET im Einsatz.
(prx) A. K. schrieb: > Der Chip kann cut through. Ja, aber dann arbeitet er nur unmanaged, ohne CPU, als Repeater zwischen beiden Ports. Das ist hier nicht brauchbar.
Nxitimi schrieb: > Eine Frage an die Experten. Ich habe 14 Switches, die ich über Daisy > Chain Topology verbunden sein müssen. Die Frage, die ich mir stelle, ist > halt "Broadcasting" und Performanz? Du solltest Dir mal Ethercat anschauen. Das ist zwar eine Art Ethernet, aber ein spezielles. Dort ist es üblich, dass jeder Slave einen Input-Port und einen Output-Port hat und alle Slaves in einer Kette hängen. Jeder Slave hat einen speziellen Ethercat-Chip (normale Ethernet-Hardware geht hier nicht), der ein Ethercat-Paket empfängt, sich die für ihn vorgesehenen Informationen aus dem Paket extrahiert, seine eigenen Daten in das Paket an die dafür vorgesehenen Stellen einfügt und dann an den nächsten Slave schickt - alles in Hardware, während das Paket durch den Ethercat-Chip durchläuft. Der letzte Slave schickt die Daten dann wieder an den Master. Das ist dann alles exakt deterministisch und kollisionsfrei und ist hunderttausendfach im industriellen Einsatz. Dabei wird kein IP und kein TCP oder UDP verwendet. fchk
(prx) A. K. schrieb: > Nxitimi schrieb: >> Was würden Sie von dem halten? > > Moooment - in Zeiten von Switches mit 10 Gbit/s geht es hier um > archaische 10 Mbit/s? Das kommt etwas überraschend. Klar. Du hast die Reichweite nicht. Sorry. 2km Entfernung. Innerhalb von diesem Abstand werden 14 Teilnehmer einpaltziert, aus dem Grund "Single Pair Ethernet". >> Haben Sie evtl. Erfahrungen in der Richtung. > > Mit Ethernet unter Echtzeitbedingungen nicht.
Nxitimi schrieb: >> Nxitimi schrieb: >>> Was würden Sie von dem halten? >> >> Moooment - in Zeiten von Switches mit 10 Gbit/s geht es hier um >> archaische 10 Mbit/s? Das kommt etwas überraschend. > Klar. Du hast die Reichweite nicht. Sorry. 2km Entfernung. Innerhalb von > diesem Abstand werden 14 Teilnehmer einpaltziert, aus dem Grund "Single > Pair Ethernet". Bei einer sicherheitskritischen Anwendung würde ich vor allem eines halten: ganz viel Abstand. Da sind einfach zu viele Komponenten, die das System zum Einsturz bringen können. Von der Zuverlässigkeit, der Latenz und der Anzahl der Fehlerquellen insbesondere unter dem Hintergrund einer sicherheitskritischen Anwendung ist eine Sterntopologie mit einem zentralen gemanageten Switch (der kann dann Alarm schlagen, wenn eine Verbindung weg ist), von dem je eine Verbindung zu jedem Teilnehmer abgeht, deutlich besser. Die Reichweite kannst Du mit Monomode-Glasfaser und LX(Long Range)-SFP-Modulen (1310nm) problemlos überbrücken. fchk
Nxitimi schrieb: > Innerhalb von 300[ms] muss die Information da sein, sonst geht alles in > die Hose. Servus, UDP und sichere (im Sinne von: garantierte) Übertragung ist ein Widerspruch. UDP ist eben per sich NICHT gesichert, sondern die Daten werden ins Netzwerk gebrüllt, und wenn diese ankommen: gut - wenn nicht: merkt weder Absender noch Empfänger. Wenn es schon unbedingt UDP sein muß, daß auf einer höheren Protokollebene noch eine Absicherung rein. Was heißt denn: "Alles geht in die Hose"? Stirben dann hunderte Leute auf einen Schlag, oder kommt nur ein Fehler ins Log? Wahrscheinlich liegt die Auswirkung irgendwo dazwischen. Das beste Vorgehen ist hier vermutlich in 2 Stoßrichtungen. 1. Fehlervermeidung Ein möglichst robustes Protokoll mit geeigneter Datenübertragung, damit innerhalb von 300ms auch unter möglichst vielen Störeinflüssen die Informationen ankommen 2. Fehlerbeherrschung Sollten die Daten nicht (rechtzeitig) ankommen (völlig egal aus welchem Grund, es wird einfach fix angenommen, die Daten kommen nicht an), soll die Auswirkung möglichst klein sein. Also kein Personen- oder Sachschaden, sondern ... [das kommt jetzt sehr auf die Anlage an, also selber nachdenken]. Gruß
(prx) A. K. schrieb: > Die im Screeenshot erwähnte Ringtopologie sollte man evtl mal näher > beleuchten, zwecks Ausfallsicherheit. In ein übliches Ethernet-Kabel > kriegt man ja zwei 10-Mbit-Stränge rein, einer hin und einer wieder > zurück. Das hilft nicht gegen die Axt, aber gegen eine defekte Node. > > Und vielleicht auch mal reinsehen, wozu der ominöse ADIN1100 gut ist. ADIN1100 gut? Du meinst PHY to PHY Verbindung ohne Switch(ADIN2111) ?
DerEinzigeBernd schrieb: > Immerhin ist hier von nur 14 Switches die Rede, so daß das Limit von 16 > MAC-Adressen dieser Switches keine Probleme machen wird. Wo siehst du das mit 16 MAC-Adressen? An einem Switch? Oder Maximal im Netz?
(prx) A. K. schrieb: > Fleischwarenfachverkäufer schrieb: >> Also das wäre ja vielleicht eine Info für früher gewesen bevor man schon >> über eine Daisychain von 14 Switches mit hunderten angeschlossenen >> Devices nachgedacht hat > > Bei 14 linear kaskadierten 2-Port Switches sind es maximal 16. Jene > Nodes am SPI, plus 2 an den Enden. Diese Chips sind offensichtlich > explizit für solche Szenarien gebaut. Maximal 16 ?? WO steht das?
Frank K. schrieb: > Nxitimi schrieb: > >> Eine Frage an die Experten. Ich habe 14 Switches, die ich über Daisy >> Chain Topology verbunden sein müssen. Die Frage, die ich mir stelle, ist >> halt "Broadcasting" und Performanz? > > Du solltest Dir mal Ethercat anschauen. > fchk Die Übertragungsgeschwindigkeit bei 2 km?
Nxitimi schrieb: > Wo siehst du das mit 16 MAC-Adressen? An einem Switch? Oder Maximal im > Netz? Das steht im Datenblatt des Switches. Da alle Switches in Reihe geschaltet werden (die haben nur zwei Ports!), ist die Auswirkung bei mehr als 16 beteiligten Geräten (jedes Gerät benutzt so einen Switch zur Anbindung) recht einfach zu verstehen. Stell' Dir z.B. 32 Geräte vor, also 32 in Reihe geschaltete Switches. Ein Gerät am Ende der Kette sendet Daten an alle anderen Geräte, damit läuft in den ersten Geräten der Kette der MAC-Buffer über, denn es werden mehr als 16 verschiedene Adressen verwendet. Nicht überlaufen werden nur die letzten 16 Geräte der Kette. Und nun möchte z.B. das achte Gerät in der Kette Daten an ein benachbartes Gerät senden. Da der MAC-Buffer übergelaufen ist, kann es nicht anders, als die Daten in beide Richtungen zu senden (d.h. auf beiden Ports gleichzeitig auszugeben).
DerEinzigeBernd schrieb: > Nxitimi schrieb: >> Wo siehst du das mit 16 MAC-Adressen? An einem Switch? Oder Maximal im >> Netz? > > Das steht im Datenblatt des Switches. Würde Broadcast die Lage etwas entspannen?
DerEinzigeBernd schrieb: > Ein Gerät am Ende der Kette sendet Daten an alle anderen Geräte, damit > läuft in den ersten Geräten der Kette der MAC-Buffer über, denn es > werden mehr als 16 verschiedene Adressen verwendet. Bei Broadcast wird nur eine MAC-Adresse (halt eine Broadcast-MAC-Adresse) verwendet. LG, Sebastian
Nxitimi schrieb: > ADIN1100 gut? Du meinst PHY to PHY Verbindung ohne Switch(ADIN2111) ? Die Rolle, die er im Bild im Datasheet hat. Hab nicht näher nachgeforscht.
Nxitimi schrieb: >> Bei 14 linear kaskadierten 2-Port Switches sind es maximal 16. Jene >> Nodes am SPI, plus 2 an den Enden. Diese Chips sind offensichtlich >> explizit für solche Szenarien gebaut. > > Maximal 16 ?? WO steht das? Wenn jede Node zwei Nachbar-Switches hat, dann sind beide Ports belegt und jedes Gerät hängt am SPI seines Chips. Die beiden Endnodes haben je einen Port frei, ergibt maximal 14+2=16 Geräte und maximal 16 MAC-Adressen von Geräten, wenn kein weiterer Switch an den Endnodes hängt und jedes Gerät nur 1 MAC-Adresse nutzt.
(prx) A. K. schrieb: > Nxitimi schrieb: >>> Bei 14 linear kaskadierten 2-Port Switches sind es maximal 16. Jene >>> Nodes am SPI, plus 2 an den Enden. Diese Chips sind offensichtlich >>> explizit für solche Szenarien gebaut. >> >> Maximal 16 ?? WO steht das? > > Wenn jede Node zwei Nachbar-Switches hat, dann sind beide Ports belegt > und jedes Gerät hängt am SPI seines Chips. Die beiden Endnodes haben je > einen Port frei, ergibt maximal 14+2=16 Geräte und maximal 16 > MAC-Adressen von Geräten, wenn kein weiterer Switch an den Endnodes > hängt und jedes Gerät nur 1 MAC-Adresse nutzt. Gibts evtl. andere Switche die mehr können? Finde grad nicht :-(
Selbst billige Netgear-Switches für den Heimgebrauch können tausende MAC-Adressen halten. Vergiss die Frührentner hier, die leben im vorigen Jahrtausend. Ändert natürlich nix dran dass es Blödsinn ist Unicast zu verwenden wenn ich eigentlich Broadcast/Multicast möchte, und die ganze Sache nicht gerade schneller macht.
Nxitimi schrieb: > Frank K. schrieb: >> Nxitimi schrieb: >> >>> Eine Frage an die Experten. Ich habe 14 Switches, die ich über Daisy >>> Chain Topology verbunden sein müssen. Die Frage, die ich mir stelle, ist >>> halt "Broadcasting" und Performanz? >> >> Du solltest Dir mal Ethercat anschauen. >> fchk > Die Übertragungsgeschwindigkeit bei 2 km? Lichtgeschwindigkeit? Wobei Ethercat eh nur 100MBit ist. fchk
Bichael M. schrieb: > Selbst billige Netgear-Switches für den Heimgebrauch können tausende > MAC-Adressen halten. Vergiss die Frührentner hier, die leben im vorigen > Jahrtausend. > > Ändert natürlich nix dran dass es Blödsinn ist Unicast zu verwenden wenn > ich eigentlich Broadcast/Multicast möchte, und die ganze Sache nicht > gerade schneller macht. Nachsatz vergessen: es muss sich halt wer dran setzen der halbwegs Ahnung hat und nicht den erstbesten Chip auswählt der ihm vor die Maus läuft.
Klaus schrieb: > Ja, aber dann arbeitet er nur unmanaged, ohne CPU, als Repeater zwischen > beiden Ports. Das ist hier nicht brauchbar. Cut through (port to port or SPI host to port). steht drin. Sollte eigentlich funktionieren.
Frank K. schrieb: > Lichtgeschwindigkeit? Wobei Ethercat eh nur 100MBit ist. Aber wie können wir 2 km abdecken? Ethercat kann doch nur 100 m Reichweite bedienen.
Nxitimi schrieb: > Aber wie können wir 2 km abdecken? Dann braucht ihr halt 21 Switches, alle 100m einen ... LG, Sebastian
Nxitimi schrieb: > Es sind maximal 200 Bytes die aber so eine Art HartBit Funktion spielen > müssen sprich jede 300 ms an alle Teilnehmern - Sicherheitsrelevante > Funktionen. Und dann 14 hintereinander, wo bleibt da die Sicherheit?
Hier sprechen die Blinden von der Farbe. Dabei steht im Netz der Netze alles zum Nachlesen bereit. Im Zeitalter wo alle, sogar an unseren Hochschulen, nur noch "Kompetenzen" erwerben, nutzen diese Kompetenzträger noch nicht mal die freien "Kompetenzquellen". Möglicherweise fehlen die Links in den ausgehändigten und vorgekauten Scripts?
Nxitimi schrieb: > Frank K. schrieb: >> Lichtgeschwindigkeit? Wobei Ethercat eh nur 100MBit ist. > > Aber wie können wir 2 km abdecken? Ethercat kann doch nur 100 m > Reichweite bedienen. Mit LWL-Umsetzern natürlich mehr. Aber ich würde das mit der Daisy-Chain Geschichte eh ganz lassen. Siehe meinem Beitrag Beitrag "Re: UDP Broadcast mehrere Switches" Einen zentralen Switch mit SFP(+)-Schächten verwenden. Sowas z.B. https://mikrotik.com/product/crs317_1g_16s_rm Dafür passende SFP-Module für jede Seite: https://mikrotik.com/product/S-31DLC20D-181 Die können 20km mit Singlemode-Fasern OS1/OS2 überbrücken. Es gibt auch Module für 40km und für 80km. Auf der anderen Seite ein entsprechendes Gerät mit dem gleichen SFP-Modul. Das lässt sich zentral überwachen, ist erweiterbar, und wenn es irgendwo im Feld ein Problem gibt, dann ist nur diese eine Station weg und nicht die halbe oder die ganze Kette. Und diese Technik ist nicht brandneu wie SPE, sondern wie wird in der Industrie seit >20 Jahren zu tausenden eingesetzt, mit Geschwindigkeiten bis zu 25GBit/s pro Faser und mehr. Wenn Ihr erweiterten Temperaturbereich braucht, gibts auch dafür Lösungen. Erdkabel ist auch kein Problem, auch fertig konfektioniert mit LC-Steckern. fchk
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.