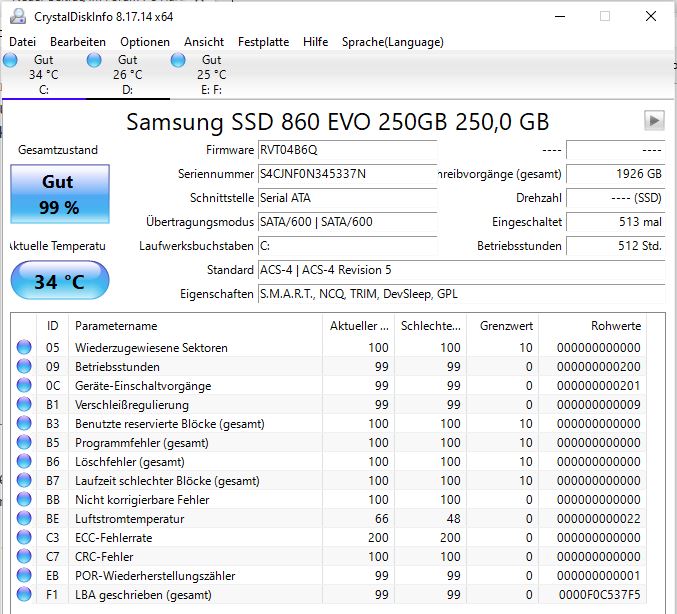
Moin, vermtl die 100ste Frage dazu - aber wieso zeigt ChystalDiskInfo zwar Werte einer internen (!) SSD an, aber diese sind offensichtlich fake? Bei einem externen 2,5" IDE sieht es genau so aus, ein externes 2,5" SATA zeigt was plausibles an. Klaus.
Angehängte Dateien:
-

smart.JPG
110 KB
PS: Falls du wenig Übung in solchen Werten hast: Deren Interpretation ist gewöhnungsbedürftig. Zum Vergleich eine 10 Jahre alte Sysdisk, eine Samsung 830:
1 | ID# ATTRIBUTE_NAME FLAG VALUE WORST THRESH TYPE UPDATED WHEN_FAILED RAW_VALUE |
2 | 5 Reallocated_Sector_Ct 0x0033 100 100 010 Pre-fail Always - 0 |
3 | 9 Power_On_Hours 0x0032 094 094 000 Old_age Always - 26914 |
4 | 12 Power_Cycle_Count 0x0032 094 094 000 Old_age Always - 5820 |
5 | 177 Wear_Leveling_Count 0x0013 081 081 000 Pre-fail Always - 687 |
6 | 179 Used_Rsvd_Blk_Cnt_Tot 0x0013 100 100 010 Pre-fail Always - 0 |
7 | 181 Program_Fail_Cnt_Total 0x0032 100 100 010 Old_age Always - 0 |
8 | 182 Erase_Fail_Count_Total 0x0032 100 100 010 Old_age Always - 0 |
9 | 183 Runtime_Bad_Block 0x0013 100 100 010 Pre-fail Always - 0 |
10 | 187 Reported_Uncorrect 0x0032 100 100 000 Old_age Always - 0 |
11 | 190 Airflow_Temperature_Cel 0x0032 081 061 000 Old_age Always - 19 |
12 | 195 Hardware_ECC_Recovered 0x001a 200 200 000 Old_age Always - 0 |
13 | 199 UDMA_CRC_Error_Count 0x003e 253 253 000 Old_age Always - 0 |
14 | 235 Unknown_Attribute 0x0012 099 099 000 Old_age Always - 18 |
15 | 241 Total_LBAs_Written 0x0032 099 099 000 Old_age Always - 22324934443 |
Ich hätte hier noch eine 5 oder 6 Jahre alte, auch sysdisk (gespiegelt mit 'ner zweiten):
1 | ID# ATTRIBUTE_NAME FLAG VALUE WORST THRESH TYPE UPDATED WHEN_FAILED RAW_VALUE |
2 | 5 Reallocated_Sector_Ct 0x0033 100 100 010 Pre-fail Always - 0 |
3 | 9 Power_On_Hours 0x0032 090 090 000 Old_age Always - 48353 |
4 | 12 Power_Cycle_Count 0x0032 099 099 000 Old_age Always - 38 |
5 | 177 Wear_Leveling_Count 0x0013 097 097 000 Pre-fail Always - 50 |
6 | 179 Used_Rsvd_Blk_Cnt_Tot 0x0013 100 100 010 Pre-fail Always - 0 |
7 | 181 Program_Fail_Cnt_Total 0x0032 100 100 010 Old_age Always - 0 |
8 | 182 Erase_Fail_Count_Total 0x0032 100 100 010 Old_age Always - 0 |
9 | 183 Runtime_Bad_Block 0x0013 100 100 010 Pre-fail Always - 0 |
10 | 187 Uncorrectable_Error_Cnt 0x0032 100 100 000 Old_age Always - 0 |
11 | 190 Airflow_Temperature_Cel 0x0032 069 044 000 Old_age Always - 31 |
12 | 195 ECC_Error_Rate 0x001a 200 200 000 Old_age Always - 0 |
13 | 199 CRC_Error_Count 0x003e 100 100 000 Old_age Always - 0 |
14 | 235 POR_Recovery_Count 0x0012 099 099 000 Old_age Always - 23 |
15 | 241 Total_LBAs_Written 0x0032 099 099 000 Old_age Always - 81056214974 |
Sieht m.E. sehr ähnlich aus.
Ist 'ne Samsung EVO 850. Gut, die Power-on hours sind mehr bei viel weniger Power cycles. ;-)
Fake da 3 IDs = 99, was unplausibel ist? Oder wie sollte man das "interpretieren"? 😄 Danke!
Klaus R. schrieb: > Fake da 3 IDs = 99, was unplausibel ist? Oder wie sollte man das > "interpretieren"? So ungefähr wie 100% Restlebensdauer, 99% , 98%, ... und wenn der Wert runter auf dem Grenzwert 10 ist, solltest du dir langsam Gedanken machen.
(prx) A. K. schrieb: > Airflow_Temperature_Cel 0x0032 081 061 000 Old_age Always > - 19 > Airflow_Temperature_Cel 0x0032 069 044 000 Old_age Always > - 31 Auch hier gehts mit den linken Werten rückwärts. Meine dürfte gerade 19°C gehabt haben, war maximal auf 39°C. Jörgs Server hat gerade 31°C, hatte maximal 56°C.
Klaus R. schrieb: > Fake da 3 IDs = 99, was unplausibel ist? Du hast diesen S.M.A.R.T.-Kram einfach nicht verstanden. Da wird alles auf einen Wertebereich von 100 … 0 (manchmal wohl auch 200 … 0) abgebildet, wobei 100 = bestmöglich bis 0 = kaputt reicht. Die ebenfalls auslesbaren Rohdaten (raw values) sind herstellerspezifisch, nicht genormt und daher in ihrer Interpretation völlig offen. Die umgerechneten Daten bei A.K. und mir zeigen für den bei SSDs wohl wichtigsten Faktor Wear_Leveling_Count also 6 % (= 94) bzw. 3 % (= 97) Abnutzung. Das finde ich gemessen an der jeweiligen Betriebsdauer so schlecht nicht, allerdings garantiert einem natürlich niemand, dass die Abnutzung linear gleichmäßig so weiterhin verläuft.
Jörg W. schrieb: > Faktor Wear_Leveling_Count also 6 % (= 94) bzw. 3 % (= 97) Da bist du in der Zeile verrutscht, der 177er hat bei mir 81.
Verschiedene Hersteller liefert da sehr verschiedene Werte. Hier eine Kingston SKC400, die ihr erstens Leben in einem Büro-PC verbrachte, um dann als Sysdisk in einem Server zu landen.
1 | ID# ATTRIBUTE_NAME FLAG VALUE WORST THRESH TYPE UPDATED WHEN_FAILED RAW_VALUE |
2 | 1 Raw_Read_Error_Rate 0x000b 100 100 050 Pre-fail Always - 0 |
3 | 2 Not_In_Use 0x0005 100 100 050 Pre-fail Offline - 0 |
4 | 3 Not_In_Use 0x0007 100 100 050 Pre-fail Always - 0 |
5 | 5 Retired_Block_Count 0x0013 100 100 050 Pre-fail Always - 0 |
6 | 7 Not_In_Use 0x000b 100 100 050 Pre-fail Always - 0 |
7 | 8 Not_In_Use 0x0005 100 100 050 Pre-fail Offline - 0 |
8 | 9 Power_On_Hours 0x0012 100 100 000 Old_age Always - 39270 |
9 | 12 Power_Cycle_Count 0x0012 100 100 000 Old_age Always - 65 |
10 | 168 SATA_Phy_Error_Count 0x0012 100 100 000 Old_age Always - 0 |
11 | 170 Bad_Blk_Ct_Erl/Lat 0x0003 100 100 010 Pre-fail Always - 0/594 |
12 | 173 MaxAvgErase_Ct 0x0012 100 100 000 Old_age Always - 81 (Average 23) |
13 | 175 Not_In_Use 0x0013 100 100 050 Pre-fail Always - 0 |
14 | 187 Reported_Uncorrect 0x0012 100 100 000 Old_age Always - 0 |
15 | 192 Unsafe_Shutdown_Count 0x0012 100 100 000 Old_age Always - 28 |
16 | 194 Temperature_Celsius 0x0023 076 061 030 Pre-fail Always - 24 (Min/Max 18/39) |
17 | 196 Reallocated_Event_Count 0x0002 100 100 010 Old_age Always - 0 |
18 | 197 Not_In_Use 0x0032 100 100 000 Old_age Always - 0 |
19 | 199 SATA_CRC_Error_Count 0x000b 100 100 050 Pre-fail Always - 0 |
20 | 218 CRC_Error_Count 0x000b 100 100 050 Pre-fail Always - 0 |
21 | 231 SSD_Life_Left 0x0013 100 100 000 Pre-fail Always - 100 |
22 | 233 Flash_Writes_GiB 0x000b 100 100 000 Pre-fail Always - 6308 |
23 | 240 Not_In_Use 0x0013 100 100 000 Pre-fail Always - 0 |
24 | 241 Lifetime_Writes_GiB 0x0012 100 100 000 Old_age Always - 4178 |
25 | 242 Lifetime_Reads_GiB 0x0012 100 100 000 Old_age Always - 17611 |
26 | 244 Average_Erase_Count 0x0002 100 100 000 Old_age Always - 23 |
27 | 245 Max_Erase_Count 0x0002 100 100 000 Old_age Always - 81 |
28 | 246 Total_Erase_Count 0x0012 100 100 000 Old_age Always - 1631360 |
Hier fehlt beispielsweise der 177er, dafür gibt es ganz andere Werte.
(prx) A. K. schrieb: > Da bist du in der Zeile verrutscht, der 177er hat bei mir 81. Ah ja. Das ist schon ein Stück, für die kurze Zeit, die sie in Betrieb ist. :-) Habe hier noch eine 3 Jahre alte SSD in einem Server im Angebot:
1 | ID# ATTRIBUTE_NAME FLAG VALUE WORST THRESH TYPE UPDATED WHEN_FAILED RAW_VALUE |
2 | 5 Reallocated_Sector_Ct 0x0033 100 100 010 Pre-fail Always - 0 |
3 | 9 Power_On_Hours 0x0032 094 094 000 Old_age Always - 27701 |
4 | 12 Power_Cycle_Count 0x0032 099 099 000 Old_age Always - 13 |
5 | 177 Wear_Leveling_Count 0x0013 096 096 000 Pre-fail Always - 46 |
6 | 179 Used_Rsvd_Blk_Cnt_Tot 0x0013 100 100 010 Pre-fail Always - 0 |
7 | 181 Program_Fail_Cnt_Total 0x0032 100 100 010 Old_age Always - 0 |
8 | 182 Erase_Fail_Count_Total 0x0032 100 100 010 Old_age Always - 0 |
9 | 183 Runtime_Bad_Block 0x0013 100 100 010 Pre-fail Always - 0 |
10 | 187 Uncorrectable_Error_Cnt 0x0032 100 100 000 Old_age Always - 0 |
11 | 190 Airflow_Temperature_Cel 0x0032 076 060 000 Old_age Always - 24 |
12 | 195 ECC_Error_Rate 0x001a 200 200 000 Old_age Always - 0 |
13 | 199 CRC_Error_Count 0x003e 100 100 000 Old_age Always - 0 |
14 | 235 POR_Recovery_Count 0x0012 099 099 000 Old_age Always - 4 |
15 | 241 Total_LBAs_Written 0x0032 099 099 000 Old_age Always - 98686474597 |
Betriebsstundenzahl ähnlich zu deiner, allerdings etwa viermal so viele Schreibzugriffe, berichtete 4 % Abnutzung.
Jörg W. schrieb: > Das finde ich gemessen an der jeweiligen Betriebsdauer so > schlecht nicht Woran man gut erkennt, wie unbegründet die "Reichweitenangst" vieler Anwender bei normaler Nutzung ist. Etwas heftiger geht es bei zentralen SAN Speichersystemen des Unternehmens zu, die 24x7 viel Arbeit haben. Da passt dann eine Abnutzung von um die 70% relativ gut zur geplanten Einsatzdauer des Systems. Zum Vergleich die 2 Jahre alte NVMe Disk vom Laptop, eine Samsung 970 EVO Plus. Deren Log ist netterweise nicht so verwirrend wie SMART:
1 | > sudo nvme smart-log /dev/nvme0 |
2 | Smart Log for NVME device:nvme0 namespace-id:ffffffff |
3 | critical_warning : 0 |
4 | temperature : 32 C |
5 | available_spare : 100% |
6 | available_spare_threshold : 10% |
7 | percentage_used : 0% |
8 | data_units_read : 40.651.334 |
9 | data_units_written : 20.030.343 |
10 | host_read_commands : 258.022.639 |
11 | host_write_commands : 263.043.277 |
12 | controller_busy_time : 1.111 |
13 | power_cycles : 904 |
14 | power_on_hours : 1.439 |
15 | unsafe_shutdowns : 51 |
16 | media_errors : 0 |
17 | num_err_log_entries : 2.007 |
18 | Warning Temperature Time : 0 |
19 | Critical Composite Temperature Time : 0 |
Jörg W. schrieb: > Du hast diesen S.M.A.R.T.-Kram einfach nicht verstanden. > Da wird alles auf einen Wertebereich von 100 … 0 (manchmal wohl auch 200 > … 0) abgebildet, wobei 100 = bestmöglich bis 0 = kaputt reicht. Ahhh, jetzt hats klick gemacht. Find ich aber nicht naheliegend... 😋 Danke!
Ja, habe ich auch eben bei einer gerade erst in Betrieb genommenen NVMe SSD so gesehen. Etwas, naja, seltsam finde ich diese "Unsafe shutdowns" – sollte ja eher eine Sache des Betriebssystems sein.
1 | SMART/Health Information (NVMe Log 0x02) |
2 | Critical Warning: 0x00 |
3 | Temperature: 50 Celsius |
4 | Available Spare: 100% |
5 | Available Spare Threshold: 5% |
6 | Percentage Used: 1% |
7 | Data Units Read: 434,137 [222 GB] |
8 | Data Units Written: 1,110,519 [568 GB] |
9 | Host Read Commands: 9,965,643 |
10 | Host Write Commands: 12,048,447 |
11 | Controller Busy Time: 27 |
12 | Power Cycles: 906 |
13 | Power On Hours: 300 |
14 | Unsafe Shutdowns: 71 |
15 | Media and Data Integrity Errors: 0 |
16 | Error Information Log Entries: 39 |
17 | Warning Comp. Temperature Time: 0 |
18 | Critical Comp. Temperature Time: 0 |
19 | Thermal Temp. 1 Transition Count: 6 |
20 | Thermal Temp. 1 Total Time: 976 |
(Die war mir letztens beim Compilieren bissel warm geworden.) Muss man halt dran denken, dass S.M.A.R.T. ja aus dem Zeitalter rotierender Scheiben stammt. Viele dieser Parameter haben eigentlich nur in dem Kontext Sinn, und die SSDs hat man danach versucht, da hinein abzubilden.
Jörg W. schrieb: > Etwas, naja, seltsam finde ich diese "Unsafe shutdowns" > – sollte ja eher eine Sache des Betriebssystems sein. Wo die herkommen habe ich mich auch schon gefragt. Denn den Laptop hatte ich ganz sicher keine 51 mal hart abgeschaltet. Andererseits wird die Disk offenbar in irgendwelchen Ruhezuständen ebenfalls voll abgeschaltet, und wenn da das Timing zwischen Betriebssystem und Disk nicht perfekt stimmt, schaltet das System möglicherweise gelegentlich schon ab, bevor die Disk das für ihre Statistik gerne hätte.
Dieses Phänomen durchzieht alle Betriebssysteme, von Windows über Linux zu BSD. Fragen dazu gibts haufenweise, Erklärungen weniger. Aber dann doch eine, die genau zu meiner vorigen These passt: https://bugs.freebsd.org/bugzilla/show_bug.cgi?id=211852#c2
Angehängte Dateien:
-

cdi_samsung860.jpg
400 KB
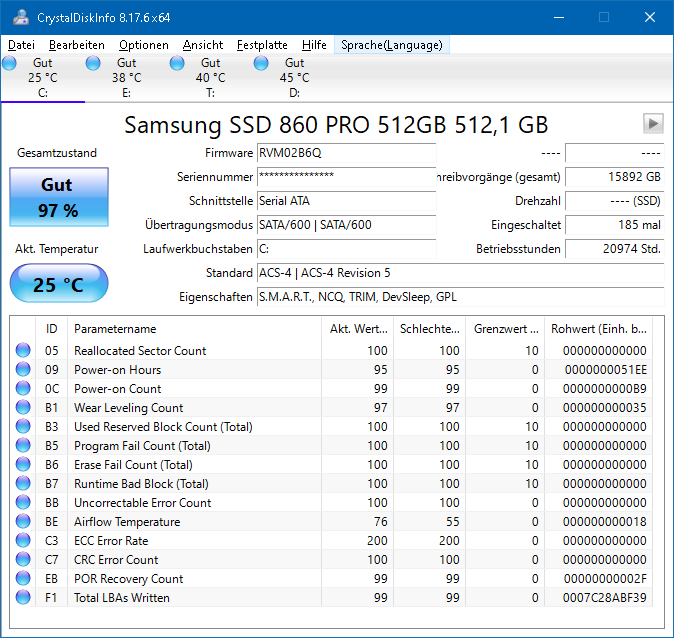
Klaus R. schrieb: > Jörg W. schrieb: >> Du hast diesen S.M.A.R.T.-Kram einfach nicht verstanden. >> Da wird alles auf einen Wertebereich von 100 … 0 (manchmal wohl auch 200 >> … 0) abgebildet, wobei 100 = bestmöglich bis 0 = kaputt reicht. > > Ahhh, jetzt hats klick gemacht. Find ich aber nicht naheliegend... 😋 Warte einfach mal eine paar Jahre ab, dann hast du auch Werte unterhalb von 99:-)
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.