Oha, da möchte man mal bestehende "Software" einbinden und dann verzweifelt man fast, weil die Vorlage doch nicht alles abdeckt. Ich bastele im Moment an einem CAN Viewer (ja da gibt es schon ein paar). Jedenfalls wollte ich den CANdb Parser ( https://github.com/GENIVI/CANdb ) welcher auch im GENIVI CANdevStudio genutzt wird integrieren. Das wäre auch geschafft. Der CANdb Parser basiert auf dem cpp-peglib Projekt ( https://github.com/yhirose/cpp-peglib ). So Recht steige ich bei dem "Grammar" des PEG nicht durch. Das Problem welches sich zeigt ist, dass die aktuelle Grammar-Beschreibung ein Grad-Zeichen ( wie bei °C ) in den Einheiten nicht akzeptiert. Damit schlägt der gesamte Parsingvorgang fehl. Also der sauberste Weg wäre die Grammar-Beschreibung zu erweitern. Meine Versuche das zu tun waren nicht erfolgreich :-( Irgendwo in der Beschreibung des "phrase" Elementes, in der Zeile 41 muss das mit rein. Kann mir für den Einstieg vielleicht jemand erklären, wie die verschiedenen Klammern, also: () [] {} <> zu lesen sind? Ein Slash scheint ein oder zu sein. ( ) sehen aus, als würden sie nur etwas als zusammen gehörig definieren [ ]+ das sieht nach einer Beschreibung von wahlweise vielen Elementen jener in der Klammer aus.
Scheint wohl niemand helfen zu können :-( Naja mein Wissensstand ist jetzt ein klitze klein wenig weiter. Die Zeile
1 | string_char <- (!["] .) |
ist ausschlaggebend. Wobei der . entsprechend den Regular Expressions doch eigentlich jeden Character akzeptieren sollte. Nun frage ich mich warum ist das Gradzeichen kein Charakter :-/
Jens R. schrieb: > Nun frage ich mich warum ist das Gradzeichen kein Charakter :-/ Das Gradzeichen gibt's bei ASCII nicht. peglib nutzt anscheinend UTF-8. Stelle also sicher dass der Text UTF-8 ist (ggf. konvertieren). Das Gradzeichen sollte dort als Bytes C2 B0 vorliegen.
Niklas G. schrieb: > Jens R. schrieb: >> Nun frage ich mich warum ist das Gradzeichen kein Charakter :-/ > > Das Gradzeichen gibt's bei ASCII nicht. peglib nutzt anscheinend UTF-8. > Stelle also sicher dass der Text UTF-8 ist (ggf. konvertieren). Das > Gradzeichen sollte dort als Bytes C2 B0 vorliegen. Naja, ganz so einfach ist es leider auch nicht. Notepad++ meint, dass die dbc Files von Vector in ANSI codiert sind. Die wxWidgets View-Klassen zeigen das Gradzeichen aus der dbc Datei an ohne zu meckern. Aber danach suchen funktioniert nicht. Aktuell habe ich es gefixt in dem ich beim Einlesen der Datei alle Nicht-ASCII ausfiltere. Wie ich das später beim Schreiben mache, muss ich noch sehen. Jedenfalls scheint es mehr als nur ein Gradzeichen zu geben 🙄
Jens R. schrieb: > Naja, ganz so einfach ist es leider auch nicht. > Notepad++ meint, dass die dbc Files von Vector in ANSI codiert sind. Das wäre ja genau das Problem. Ich meine mich auch zu erinnern dass DBC-Files mit Windows-1252 kodiert sind. Das heißt du musst von Windows-1252 nach UTF-8 konvertieren vorm Parsen. Jens R. schrieb: > Die wxWidgets View-Klassen zeigen das Gradzeichen aus der dbc Datei an > ohne zu meckern. Das ist kein Wunder, denn wxWidgets erwartet bei "narrow" (char*) Strings dass sie in der lokalen Kodierung, bei deutschem Windows also eben Windows-1252, vorliegen. Es konvertiert intern nach Unicode. Auf anderen Sprachen oder unter Unix würde es schief gehen, weil dort andere Codepages bzw. UTF-8 erwartet werden.
Ich verstehe dann aber nicht ganz warum ich dann den eingelesenen und damit eigentlich nach UTF konvertierten wxString nicht erfolgreich nach dem Gradzeichen durchsuchen kann 🤔
Vielleicht weil du das Gradzeichen falsch an die Suchfunktion übergibst? Machst du die Suche nach dem Parsen, d.h. nachdem die peglib den ANSI-String schon fälschlicherweise als UTF-8 -String interpretiert hat und Unsinn ausspuckt? Oder machst du es vor dem Parsen und übergibst die Bytes aus der Datei falsch an den wxString?
Ich werde später mal noch den Code zu hause ergänzen.
Folgenden Ablauf habe ich probiert.
Die dbc Datei mit der wxFile Class geöffnet.
Den Inhalt in ein wxString Objekt gelesen.
Dann wollte ich die wxStringObject.Replace("°","irgendwas",alle=true)
nutzen.
Das Replace findet aber keine °. Also muss die Konvertierung es
irgendwie verbogen haben.
Was ich noch nicht probiert habe, wäre das "°" bei der Übergabe an
Replace als nicht UTF zu deklarieren.
Jens R. schrieb: > Was ich noch nicht probiert habe, wäre das "°" bei der Übergabe an > Replace als nicht UTF zu deklarieren. Das ist, wie vermutet, der Fehler. Wenn du einfach "°" schreibst ist die Kodierung unspezifiziert/compiler-abhängig, wahrscheinlich tatsächlich schon UTF-8 - aber wxWidgets erwartet hier die lokale Kodierung, also z.B. Windows-1252. Schreibt einfach mal L'°' um ein "wide"-Literal zu nehmen und Unicode zu erzwingen. wxFile scheint beim Einlesen auch Unicode anzunehmen. z.B. bei wxFile::ReadAll solltest du dann Windows-1252 angeben damit es korrekt eingelesen wird.
Angehängte Dateien:
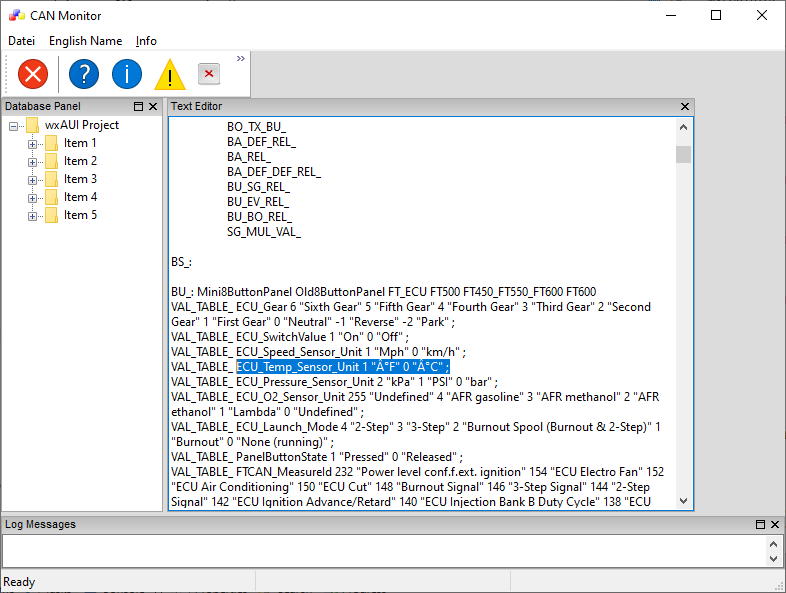
Niklas G. schrieb: > Schreibt einfach mal L'°' um ein "wide"-Literal zu > nehmen und Unicode zu erzwingen. Das war (mit einer kleinen Korrektur) genau die Lösung für die Replace Funktion :-)
1 | readLine.Replace(L"°", "°", true); |
Und dann erkennt der Parser das ° auch als Character und nicht als Steuerzeichen. PS: Replace arbeitet mit kompletten Strings und nicht mit Einzelcharacter Edit: irgendwie weiß wxWidgets nicht was es will :-/ Jetzt wird das ° Zeichen aber im Standard View nicht richtig dargestellt :-O Naja, da finde ich jetzt auch noch ein Weg. Vielen Dank
Jens R. schrieb: > readLine.Replace(L"°", "°", true); Was soll das werden? Du doktorst an Symptomen herum statt das eigentliche Problem zu lösen. Das macht sich dann damit bemerkbar dass die Anzeige immer noch nicht funktioniert. Willst du dieses Spielchen jetzt mit jedem einzelnen Nicht-ASCII-Zeichen machen? Konvertiere den Text aus der Datei von Windows-1252 nach UTF-8 bevor du ihn nach peglib fütterst. Damit dürfte es erledigt sein und es sollte auch mit allen Zeichen funktionieren, nicht nur dem Gradzeichen.
Niklas G. schrieb: > Konvertiere den Text aus der Datei von Windows-1252 nach UTF-8 bevor du > ihn nach peglib fütterst. Damit dürfte es erledigt sein und es sollte > auch mit allen Zeichen funktionieren, nicht nur dem Gradzeichen. Und genau da steige ich eben nicht durch, wann welche Codec noch vorhanden ist. Noch einmal: Ich lese die Datei mit der Standard Funktion nach wxString ein. Hier sollte doch laut wxWidgets Doku aus der Windows-kodierten Datei ein UTF-Codierter String entstehen. Richtig? In diesem UTF codierten String lässt sich aber das ° Zeichen eben nicht als UTF-codiertes Gradzeichen finden. Es wird also nicht in UTF konvertiert, es scheint noch immer Windows kodiert zu sein. Deswegen habe ich es jetzt in diesem Anlauf ausgetauscht. Nun war ich eben verwundert, dass das UTF-kodierte ° Zeichen in der wxWidgets textCtrl nicht als solches angezeigt wird, obwohl doch eigentlich UTF der wxWidgets Standard ist. Das Ganze hatte ich 10 min nach dem ich nach Hause gekommen probiert und berichtet :-/ Ich sitze also erst jetzt wieder davor. Also bitte nicht gleich steinigen, wenn ich mal nen Zwischenstand liefere ;-) Ach übrigens, das CANdevStudio hat auch das Problem dass es dbc Files mit einem ° drin ablehnt :-D
Jens R. schrieb: > wird also nicht in UTF konvertiert, es scheint noch immer Windows > kodiert zu sein. > Deswegen habe ich es jetzt in diesem Anlauf ausgetauscht. Das ist halt der völlig falsche Ansatz und kann auch beliebig schief gehen. Was spricht dagegen, in der wxFile::ReadAll Funktion beim 2. Parameter die Kodierung der Datei (Windows-1252) anzugeben? Dann wird direkt automatisch konvertiert und alles ist richtig.
Niklas G. schrieb: > Jens R. schrieb: >> wird also nicht in UTF konvertiert, es scheint noch immer Windows >> kodiert zu sein. >> Deswegen habe ich es jetzt in diesem Anlauf ausgetauscht. > > Das ist halt der völlig falsche Ansatz und kann auch beliebig schief > gehen. > > Was spricht dagegen, in der wxFile::ReadAll Funktion beim 2. Parameter > die Kodierung der Datei (Windows-1252) anzugeben? Dann wird direkt > automatisch konvertiert und alles ist richtig. Es spricht nichts dagegen. Wie gesagt, das war vorhin der erste Test um heraus zufinden ob das geht. Normal bin ich auf dem µC unterwegs. Da bin ich bisher nicht über unterschiedlich kodierte Dateien gestolpert. Das mit dem Einzelzeichen war jetzt eben, weil ich auch zuvor das Einzelzeilen-lesen gebastelt hatte um die nicht-ASCII Zeichen erst einmal rauszuschmeißen. Und jetzt werde ich das wohl wieder alles vereinfachen. :-D
UTF8 ist nicht zwingend das gleiche wie "Unicode" im wxWidgets, bzw gibt es da noch ein paar Fallstricke. Das Problem war versteckt in:
1 | const auto db = parser.parse(LoadFile(filename).ToStdString()); |
ToStdString() konvertiert in das Systemspezifische Format. Damit parser.parse() richtig funktioniert muss es aber mit UTF8 gefüttert werden. Der saubere Weg ist nun den wxString vor dem ToStdString in UTF8 zu Konvertieren (wxString basiert auf 32bit bzw UTF32):
1 | wxString tmCanDatabaseFile::LoadFile(const wxString& filename) |
2 | {
|
3 | wxString str; |
4 | do
|
5 | {
|
6 | // open the file
|
7 | /* try to convert on file read */
|
8 | wxFile tfile; |
9 | tfile.Open(filename); |
10 | tfile.ReadAll(&str) |
11 | }
|
12 | while(false); |
13 | return str.mb_str(wxConvUTF8); |
14 | }
|
Warum das Gradzeichen mit dem zuvor genutzten Replace erkannt wurde, ist mir trotzdem schleierhaft. Jedenfalls hat mich das Probieren damit, in die falsche Richtung suchen lassen :-( Fazit: Wenn jemand den peglib Parser nutzen möchte, muss darauf geachtet werden dass dieser auch unbedingt UTF8 bekommt.
Jens R. schrieb: > Fazit: > Wenn jemand den peglib Parser nutzen möchte, muss darauf geachtet werden > dass dieser auch unbedingt UTF8 bekommt. Sag ich doch 🤣 Niklas G. schrieb: > Stelle also sicher dass der Text UTF-8 ist (ggf. konvertieren)
Ja das ist mir auch schon aufgefallen, dass du mich da schon drauf hingewiesen hattest. Aber wie gesagt mir war der Unterschied zwischen UTF8 und Unicode nicht klar 🙄 Das ich die Begriffe bisher wild durch einander genutzt hatte, ist leider nicht aufgefallen.
Jens R. schrieb: > wxString tmCanDatabaseFile::LoadFile(const wxString& filename) > { > wxString str; > do > { … > } > while(false); Wozu ist denn das seltsame do/while da?
Das stammt noch aus den Examples 🙈 von wxWidgets. Bin noch nicht fertig mit aufräumen. Bei den Beispielen steckt innerhalb des do - whiles eine Abbruchbedindung wenn das laden fehl schlägt.
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.