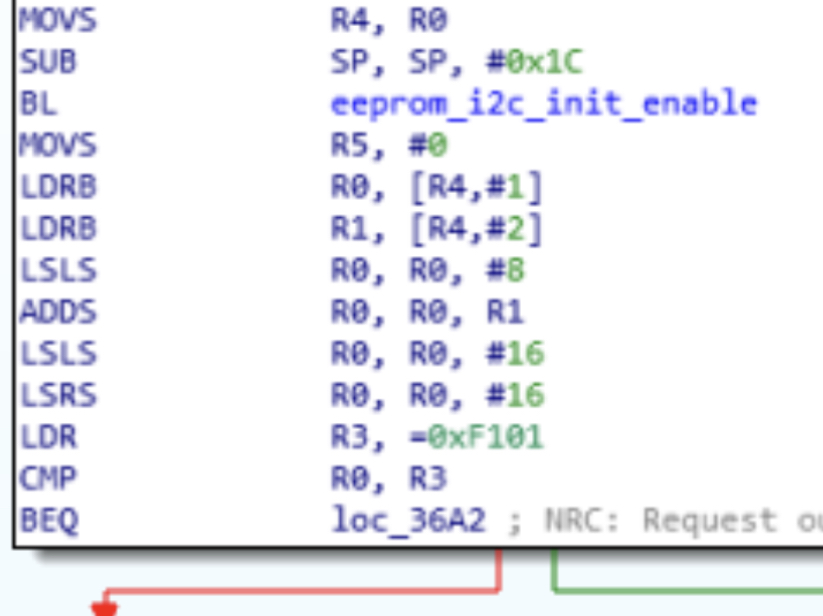
Ich versuche den Sinn dieses ARM codeschnippsel zu verstehen, mit der
Bitte um Kommentierung. Der Code stammt aus einer Steuergeräte-Firmware.
Im Einsprung ist R4 mit einer Speicheradresse im RAM geladen. Hier
können 2-Byte Werte von 0xF100 an aufwärts stehen.
1) R5 wird mit 0 geladen
2) R0 wird mit dem Byte aus Speicheradresse R4+1 geladen
3) R1 wird mit dem Byte aus Speicheradresse R4+2 geladen
4) R0 wird um 8 Bit nach links geschoben (die rechts eintretenden Bits
sind 0)
5) R0 wird mit R0 + R1 geladen
6) R0 wird um 16 Stellen nach links geschoben
7) R0 wird um 16 Stellen nach rechts geschoben
8) R3 wird mit 0xF101 geladen
9) R0 wird mit R3 verglichen (Flags werden gesetzt)
10) Bei Gleichheit von R0 und R3 wird nach loc_36a2 verzweigt, ansonsten
geht es nach diesem Befehl weiter.
Aus meiner Sicht sind die Befehle 2-5 dazu da einen 16 Bit Wert mit dem
offset R4+1 in das Register R0 zu laden.
Die Befehle 6 und 7 sind quasi eine Maskierung der oberen 16 Bit auf 0
(hier wäre auch ein AND R0 mit 0x0000FFFF genauso gut gewesen, evtl. ist
Shift schneller?)
Olli Z. schrieb:
> Die Befehle 6 und 7 sind quasi eine Maskierung der oberen 16 Bit auf 0
Richtig. Das ist allerdings unnötig, weil diese Bits durch das LDRB
bereits auf 0 gesetzt wurden. Das passiert bei schlechter/abgeschalteter
Compiler-Optimierung, besonders wenn man zwischen verschiedenen
Integertypen hin und her wandelt. IIRC machen alte GCC-Versionen sowas.
r0 und r1 einzeln zu laden (statt direkt 16bit mit LDRH zu laden) wird
wahrscheinlich gemacht weil die Adresse nicht aligned ist (d.h. R4 ist
gerade, dadurch ist R4+1 ungerade).
Olli Z. schrieb:
> (hier wäre auch ein AND R0 mit 0x0000FFFF genauso gut gewesen, evtl. ist
> Shift schneller?)
Den Immediate-Wert 0x0000FFFF zu laden ist auch aufwendig. Ist es ein
ARMv6 oder v7? Weiß die Details gerade nicht auswendig, aber ich meine
insbesondere bei ARMv6 dürfte das 2x shiften effizienter sein.
Ja, die Firmware stammt aus 2005 rum, vielleicht sogar noch älter. Danke
für die Erklärungen, dann liege ich ja nicht so falsch :-)
Das hier macht übrigens ein IDA Pro ARM-Decompiler daraus:
1 | signed int __fastcall uds_readDataByIdentifier(unsigned __int8 *a1)
| 2 | {
| 3 | unsigned __int8 *v1; // r4
| 4 | signed int v2; // r5
| 5 | int v3; // r0
| 6 | unsigned int v4; // r0
| 7 | unsigned int v5; // r0
| 8 | unsigned int v6; // r0
| 9 | int v8; // [sp+0h] [bp-30h]
| 10 |
| 11 | v1 = a1;
| 12 | eeprom_i2c_init_enable();
| 13 | v2 = 0;
| 14 | v3 = ((v1[1] << 8) + v1[2]) & 0xFFFF;
| 15 | ...
| 16 | }
|
Da wünscht man sich doch einen Decompiler mit ChatGPT Unterstützung der
einen richtig schönen C/C++ Code aus dem ARM generiert :-)
Olli Z. schrieb:
> Ja, die Firmware stammt aus 2005 rum, vielleicht sogar noch älter. Danke
> für die Erklärungen, dann liege ich ja nicht so falsch :-)
> [code]
> signed int __fastcall uds_readDataByIdentifier(unsigned __int8 *a1)
Oh, UDS und der RDBI, das mache ich immer noch beruflich. Ich schätze,
das war damals CAN-basiert. Heutzutage mit DoIP.
Thomas
Ein weiteres Artefakt was vermutlich seinen Ursprung in fehlender
Compiler-Optimierung hat?
Ich finde öfter solche Konstrukte im Code die auf den ersten Blick wenig
Sinn machen: 1 | LDR R1, =byte_0x400017F0
| 2 | MOVS R0, #8
| 3 | STRB R0, [R1,#(byte_400017F3 - 0x400017F0)]
| 4 | MOVS R0, #0x30
| 5 | STRB R0, [R1,#(byte_400017F4 - 0x400017F0)]
| 6 | MOVS R0, #0x61
| 7 | STRB R0, [R1,#(byte_400017F5 - 0x400017F0)]
| 8 | MOVS R0, #0x55
| 9 | STRB R0, [R1,#(byte_400017F6 - 0x400017F0)]
| 10 | MOVS R0, #0xAA
| 11 | STRB R0, [R1,#(byte_400017F7 - 0x400017F0)]
|
Da werden 8-Bit Werte im Speicher (RAM) gesetzt, vermutlich ein Array.
In R1 wird die Basis-Adresse geladen und dann nachfolgend in den STRB
die Index-Methode genutzt. Der Offset wird dabei jedesmal berechnet aus
der Differenz zweier 32-Bit Speicheradressen. Ich hätte da jetzt eher
einfach einen Index gesehen, z.B.
1 | LDR R1, =byte_0x400017F0
| 2 | MOVS R0, #8
| 3 | STRB R0, [R1,#3]
| 4 | MOVS R0, #0x30
| 5 | STRB R0, [R1,#4]
| 6 | MOVS R0, #0x61
| 7 | STRB R0, [R1,#5]
| 8 | MOVS R0, #0x55
| 9 | STRB R0, [R1,#6]
| 10 | MOVS R0, #0xAA
| 11 | STRB R0, [R1,#7]
|
Denke ich da einfach wieder nicht wie ein Compiler, oder gibt es auch
hierfür eine gute Erklärung?
Thomas S. schrieb:
>> signed int __fastcall uds_readDataByIdentifier(unsigned __int8 *a1)
> Oh, UDS und der RDBI, das mache ich immer noch beruflich. Ich schätze,
> das war damals CAN-basiert. Heutzutage mit DoIP.
Ja genau, auch wenn das hier prinzipiell nichts zur Sache tut, aber ich
versuche gerade eine Automotive Firmware in Teilen zu verstehen
(Reverse-Engineering) und gleichzeitig ARM-Code lesen zu lernen. Es ist
sicher nicht möglich eine komplette Firmware zu rückwärts zu entwickeln,
aber bestimmte Komponenten und daraus wird man dann wieder schlauer was
die Funktion angeht.
Olli Z. schrieb:
> Da werden 8-Bit Werte im Speicher (RAM) gesetzt, vermutlich ein Array.
Ja, einzelne Byte-Zugriffe wahrscheinlich wieder wegen Alignment.
Olli Z. schrieb:
> Der Offset wird dabei jedesmal berechnet aus
> der Differenz zweier 32-Bit Speicheradressen.
Das ist ein Artefakt des Disassemblers, ARM-Instruktionen können so
etwas gar nicht enthalten.
Olli Z. schrieb:
> Ich hätte da jetzt eher
> einfach einen Index gesehen, z.B.
Genau das steht da auch in den Instruktionen. Das "byte_400017F3 -
0x400017F0" hat der Disassembler da "hilfreich" eingefügt damit du
siehst dass es an die Stelle byte_400017F3 kommt.
PS:
Olli Z. schrieb:
> Ja, die Firmware stammt aus 2005 rum, vielleicht sogar noch älter.
Also ist es vermutlich ein ARM7TDMI, der war ja sehr verbreitet. Dessen
Thumb Instruction Set kann maximal 11bit Immediates in eine Instruktion
kodieren, und auch das nur für Sprünge. Für arithmetische Operationen
und Speicherzugriffe sind nur 8bit-Immediates möglich:
https://developer.arm.com/documentation/ddi0210/c/Introduction/Instruction-set-summary/Thumb-instruction-summary?lang=en
Somit können eine Bitmaske wie 0x0000FFFF oder gar 2 32bit-Werte wie
"byte_400017F7 - 0x400017F0" bei Weitem nicht in einer Instruktion
kodiert werden.
Ich habe eine weitere Subroutine gefunden wie den aktuellen Wert des
16-Bit CAN Timers zurück gibt:
1 | 000027C0 mscan_timerValue
| 2 | 000027C0 LDR R0, =FC0A0000 ; FlexCAN D Base Register (datasheet 23.5.2.1)
| 3 | 000027C2 LDRH R0, [R0,#0x0A] ; Read 0xFC0A000A = TIMER (datasheet 23.5.2.3)
| 4 | 000027C4 BX LR ; R0 = 0x0000TTTT
|
Laut Datenblatt vom Prozessor wird hier ein 16-Bit Wert hochgezählt mit
Überlauf. D.H. diese Routine gibt einen "Zufallswert" im Bereich
0000-FFFF zurück, im Takt des Bit-Clocks für diesen Port (125 kbit/s).
Interessant ist die Verwendung davon: 1 | 000031B4 createRandom
| 2 | 000031B4 PUSH {R4-R6,LR}
| 3 | 000031B6 MOVS R4, #0
| 4 | 000031B8 LDR R5, =seed ; Hier hin werden die berechneten Zufallsdaten geschrieben
| 5 | 000031BA loc_31BA
| 6 | 000031BA BL mscan_timerValue ; Hier nach enthält R0 den 16-Bit Zufallswert
| 7 | 000031BE MOVS R1, #0
| 8 | 000031C0 loc_31C0
| 9 | 000031C0 LSLS R3, R0, #1 ; Multiplikation mit 2, also R3=R0*2
| 10 | 000031C2 ADDS R0, R3, R0 ; Doppelter Zufallswert aufaddieren
| 11 | 000031C4 ADDS R0, #0x1D ; R0 = R0 + 29
| 12 | 000031C6 LSLS R0, R0, #16 ; R0 = R0 << 16 = Oberen 16 Bits werden rausgeschoben
| 13 | 000031C8 LSRS R0, R0, #16 ; R0 = R0 >> 16
| 14 | 000031CA ADDS R1, #1 ; R1 = R1 + 1
| 15 | 000031CC LSLS R1, R1, #24
| 16 | 000031CE LSRS R1, R1, #24 ; LSL und LSR maskieren die oberen 24 Bits weg
| 17 | 000031D0 CMP R1, #5 ; Setze Carry-Flag wenn R1 > 5
| 18 | 000031D2 BCC loc_31C0 ; Entspricht: for (R1=0; R1 =< 5; R1++) { ... }
| 19 | ; das sieht mir aus wie eine Endian-Anpassung von Big auf Little
| 20 | 000031D4 LSRS R1, R0, #8 ; R1 = R0 >> 8
| 21 | 000031D6 STRB R1, [R5,#2] ; Speichere MSB von Zufallswert in seed[2]
| 22 | 000031D8 STRB R0, [R5,#1] ; Speichere LSB von Zufallswert in seed[1]
|
Bis hierhin würde ich das so in C übersetzen:
1 | uint8 R4 = 0;
| 2 | uint8 seed[3];
| 3 | do
| 4 | {
| 5 | uint16 R0 = timerValue();
| 6 | for ( uint8 i=0; i<=5; i++ ) {
| 7 | R0 = ( R0 + ( R0 * 2 ) + 29 ) & 0xFFFF;
| 8 | }
| 9 | seed[1] = ( R0 & 0xFF );
| 10 | seed[2] = ( R0 >> 8 );
|
1 | 000031DA BL nullsub_4538 ; die macht nur "BX PC", also nix
| 2 | 000031DE BL mscan_timerValue ; R0 mit neuem Zufallswert laden
| 3 | 000031E2 MOVS R1, #0
| 4 | 000031E4 loc_31E4
| 5 | 000031E4 MOVS R3, #0x1D
| 6 | 000031E6 MULS R0, R3 ; R0 = R0 * R3 (Zufallswert * 29)
| 7 | 000031E8 ADDS R0, #3 ; R0 = R0 + 3
| 8 | 000031EA LSLS R0, R0, #16
| 9 | 000031EC LSRS R0, R0, #16 ; R0 = R0 & 0xFFFF
| 10 | 000031EE ADDS R1, #1
| 11 | 000031F0 LSLS R1, R1, #24
| 12 | 000031F2 LSRS R1, R1, #24
| 13 | 000031F4 CMP R1, #5
| 14 | 000031F6 BCC loc_31E4 ; for (R1=0; R1 =< 5; R1++) { ... }
| 15 | 000031F8 LDRB R1, [R5,#1] ; R1 = seed[1]
| 16 | 000031FA LSRS R2, R0, #8 ; R2 = R0 >> 8
| 17 | 000031FC EORS R1, R2 ; R1 = R1 XOR R2
| 18 | 000031FE STRB R1, [R5,#1] ; seed[1] = R1
| 19 | 00003200 LSLS R0, R0, #24
| 20 | 00003202 LSRS R0, R0, #24 ; R0 = R0 & 0xFF
| 21 | 00003204 STRB R0, [R5] ; seed[0] = R0
| 22 | 00003206 ADDS R4, #1 ; R4 = R4 + 1
| 23 | 00003208 LSLS R4, R4, #24
| 24 | 0000320A LSRS R4, R4, #24 ; R4 = R4 & 0xFF
| 25 | 0000320C CMP R0, #0
| 26 | 0000320E BNE loc_3230 ; if ( R0 == 0 ) return
| 27 | 00003210 CMP R1, #0
| 28 | 00003212 BNE loc_3230 ; if ( R1 == 0 ) return
|
Dieses Stück lese ich so:
1 | uint16 R0 = timerValue();
| 2 | for ( uint8 i=0; i<=5; i++ ) {
| 3 | R0 = ( ( R0 * 29 ) + 3 ) & 0xFFFF;
| 4 | }
| 5 | seed[0] = ( R0 & 0xFF );
| 6 | seed[1] = seed[1] ^ ( R0 >> 8 );
| 7 | R4 = R4 + 1;
| 8 | if ( R0 == 0 ) return;
| 9 | if ( seed[1] == 0 ) return;
|
Soweit so gut (stimmt hoffentlich alles?)
Kommen wir zum Endgegner ;-)
1 | 00003214 LDRB R0, [R5,#2]
| 2 | 00003216 MOVS R1, R5
| 3 | 00003218 CMP R0, #0
| 4 | 0000321A BNE loc_3230
| 5 | 0000321C CMP R4, #5
| 6 | 0000321E BCC loc_322C
| 7 |
| 8 | 00003220 MOVS R0, #3
| 9 | 00003222 STRB R0, [R1]
| 10 | 00003224 MOVS R0, #0x1D
| 11 | 00003226 STRB R0, [R1,#1]
| 12 | 00003228 MOVS R0, #0x65
| 13 | 0000322A STRB R0, [R1,#2]
| 14 |
| 15 | 0000322C loc_322C
| 16 | 0000322C CMP R4, #5
| 17 | 0000322E BCC loc_31BA
| 18 |
| 19 | 00003230 loc_3230
| 20 | 00003230 POP {R4-R6}
| 21 | 00003232 POP {R3}
| 22 | 00003234 BX R3
|
1 | if ( seed[2] == 0 ) return;
| 2 | if ( R4 > 5 ) {
| 3 | seed[0] = 0x03;
| 4 | seed[1] = 0x1D;
| 5 | seed[2] = 0x65;
| 6 | }
| 7 | } while( R4 <= 5 );
|
Nochmal zusammengefasst und etwas optimiert auf Lesbarkeit:
1 | uint8 n = 0;
| 2 | uint8 seed[3];
| 3 | uint16 rnd;
| 4 | do
| 5 | {
| 6 | rnd = timerValue();
| 7 | for ( uint8 i=0; i<=5; i++ )
| 8 | {
| 9 | rnd = ( rnd + ( rnd * 2 ) + 29 ) & 0xFFFF;
| 10 | }
| 11 | seed[1] = ( rnd & 0xFF );
| 12 | seed[2] = ( rnd >> 8 );
| 13 |
| 14 | rnd = timerValue();
| 15 | for ( uint8 i=0; i<=5; i++ )
| 16 | {
| 17 | rnd = ( ( rnd * 29 ) + 3 ) & 0xFFFF;
| 18 | }
| 19 | seed[0] = ( rnd & 0xFF );
| 20 | seed[1] = seed[1] ^ ( rnd >> 8 );
| 21 |
| 22 | if ( seed[0] == 0 || seed[1] == 0 || seed[2] == 0 ) return;
| 23 |
| 24 | n = n + 1;
| 25 | if ( n > 5 )
| 26 | {
| 27 | seed[0] = 0x03;
| 28 | seed[1] = 0x1D;
| 29 | seed[2] = 0x65;
| 30 | }
| 31 | } while( n <= 5 );
|
Wie man erkennt legt die Routine großen Wert darauf das im Ergebnis
keine 0x00 Bytes vorkommen.
Eines macht mich stutzig... die "if (n>5)" würde ja praktisch bei der
letzten Iteration aufgerufen und alle so mühsam zuvor berechneten Werte
mit diesen statischen überschreiben?!?
Ich glaube ich habe diesen code falsch interpretiert
1 | 000031BE MOVS R1, #0
| 2 | 000031C0 loc_31C0
| 3 | ...
| 4 | 000031CA ADDS R1, #1
| 5 | 000031D0 CMP R1, #5
| 6 | 000031D2 BCC loc_31C0
|
Das Carry-Flag wird bereits gesetzt wenn R1 den Wert 5 hat. Damit hab
ich nicht gerechnet, denn Carry ist für mich ein Übertrag und CMP macht
doch nichts anderes als SUBS R1, 5# wo ja 0 raus kommt. Das finde ich
reichlich merkwürdig, ja sogar unlogisch irgendwie...
So wäre die richtige Schleife also: 1 | for ( uint8 i=0; i<5; i++ )
| 2 | {
| 3 | rnd = ( rnd + ( rnd * 2 ) + 29 ) & 0xFFFF;
| 4 | }
|
Bei manchen Prozessoren entspricht das C-Flag einer Subtraktion nicht
der intuitiven Vorstellung, sondern der Addition des Einerkomplements.
Das ist dann genau umgekehrt.
Für sporadische Tests habe ich diesen Online-ARM Assembler/Debugger
gefunden: https://cpulator.01xz.net/?sys=arm
Damit kann man flux mal Code (Assembler) einstellen und durchsteppen.
So müsste es jetzt dann stimmen 1 | #include <stdint.h>
| 2 |
| 3 | uint8_t n = 0;
| 4 | uint8_t seed[3];
| 5 | uint16_t rnd;
| 6 | uint8_t i;
| 7 |
| 8 | do
| 9 | {
| 10 | rnd = timerValue();
| 11 | for ( i=0; i<5; i++ )
| 12 | {
| 13 | rnd = ( rnd + ( rnd * 2 ) + 29 ) & 0xFFFF;
| 14 | }
| 15 | seed[1] = ( rnd & 0xFF );
| 16 | seed[2] = ( rnd >> 8 );
| 17 |
| 18 | rnd = timerValue();
| 19 | for ( i=0; i<5; i++ )
| 20 | {
| 21 | rnd = ( ( rnd * 29 ) + 3 ) & 0xFFFF;
| 22 | }
| 23 | seed[0] = ( rnd & 0xFF );
| 24 | seed[1] = seed[1] ^ ( rnd >> 8 );
| 25 |
| 26 | // if we have a least one non-zero value, we are done
| 27 | if ( seed[0] != 0 || seed[1] != 0 || seed[2] != 0 ) return;
| 28 |
| 29 | n = n + 1;
| 30 |
| 31 | // put fixed value in unlikely case we have all seed bytes zero after five iterations
| 32 | if ( n >= 5 )
| 33 | {
| 34 | seed[0] = 0x03;
| 35 | seed[1] = 0x1D;
| 36 | seed[2] = 0x65;
| 37 | }
| 38 | } while( n < 5 );
|
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
|