In meiner Anwendung soll jede Millisekunde etwas parallel gemacht
werden.
Ich befürchte, ich habe den falschen Ansatz, da ich aus der µC Welt
komme.
Als GUI nutze ich wxWidgets. Ich habe zwei Ansätze, in beiden Fällen
werden die 1 Millisekunde natürlich nicht eingehalten, es sind eher ein
paar 100 Millisekunden Abstand zwischen den Aufrufen. In der
1
loop()
werden wirklich nur ein paar Additionen durchgeführt, keine große
Berechnung.
1. Einen std::thread laufen lassen:
Norbert schrieb:> Bei einem 1ms Intervall sollten aber besser keine GUI Interaktionen im> Thread passieren.
Wenn dieser 1ms Thread etwas af der GUI machen soll, erzeuge ich ein
Event.
EDIT: Geändert. Der Thread braucht ca. 15ms statt 1ms. Keine GUI
Interaktionen, nur ggf. ein Event.
Moin,
ohne es zu wissen, nehme ich mal der TO benutzt ein OS aus Redmond.
Ich habe mir mal eben wxWidgets gezogen und in die Sourcen geschaut.
Intern wird bei Windows (TM) ::Sleep aufgerufen.
Dazu finden sich hier ein paar Hinweise zur Genauigkeit:
https://learn.microsoft.com/en-us/windows/win32/api/synchapi/nf-synchapi-sleep#remarks
Gruß
Olaf
Keine A. schrieb:> EDIT: Geändert. Der Thread braucht ca. 15ms statt 1ms. Keine GUI> Interaktionen, nur ggf. ein Event.
Na ja, wenn der Thread einmal pro ms laufen soll, dann schuldest du ihm
jedes mal 14ms. Das läppert sich aber… ;-)
Nur mal so nebenbei, 14ms sind ja gleich mehrere Ewigkeiten, löst du da
drin das 3n+1 Problem?
Sofern das ganze unter Windows läuft, kann die Timergranularität mit den
sogenannten "Multimediafunktionen" verfeinert werden. Normalerweise
liegt die Granularität bei 10 oder sogar 15 msec, mit der
Win32-API-Funktion timeBeginPeriod kannst Du das in ganzen Millisekunden
auf 1 msec reduzieren.
https://learn.microsoft.com/en-us/windows/win32/api/timeapi/nf-timeapi-timebeginperiod
Harald K. schrieb:> Sofern das ganze unter Windows läuft, kann die Timergranularität> mit den> sogenannten "Multimediafunktionen" verfeinert werden. Normalerweise> liegt die Granularität bei 10 oder sogar 15 msec, mit der> Win32-API-Funktion timeBeginPeriod kannst Du das in ganzen Millisekunden> auf 1 msec reduzieren.
Muss wohl echt ein Windows Ding sein. Selbst mit Python und wxPython ist
die eine Millisekunde bei Linux überhaupt kein Problem (und die CPU Last
nicht wahrnehmbar).
Und das obwohl (Standard)Python und Threading keine besonders
effizienten Freunde sind.
Das hat nichts mit Effizienz, sondern der Frequenz des Timerinterrupts
zu tun. Und die liegt halt auf Windowssystemen üblicherweise bei 100 Hz.
Früher™ war das noch schlimmer, da lag sie bei nur 18.2 Hz.
Keine A. schrieb:> da ich aus der µC Welt> komme.
Willkommen in der Welt der nicht Echtzeit tauglichen Betriebssysteme:-)
Vereinfacht: Wenn du einen Thread für eine bestimmte Zeit Schlafen
schickst, bedeutet das für das OS nur das die angegebenen Zeit die
frühest mögliche Zeit ist wo dein Thread überhaupt mal wieder in der
Warteschlange Platznehmen darf. Und wenn das OS dann irgendwann mal Lust
dazu hat bekommt dein Thread auch mal wieder etwas Rechenzeit zugeteilt.
Je nach Priorität und anderen Aufgaben kann das durchaus mal einige
Millisekunden (zusätzlich) dauern bis du mal wieder dran bist.
Das ganze ist also kein Timer der eine genau definierte Zeit wartet und
danach unverzüglich weiter arbeitet. Windows, Linux und Unix geben sich
da übrigens praktisch nichts, die arbeiten da alle sehr ähnlich.
- https://de.wikipedia.org/wiki/Completely_Fair_Scheduler
- https://de.wikipedia.org/wiki/Prozess-Scheduler
- https://github.com/uu-os-2018/slides/find/master (vorallem die wo es
um scheduling geht)
Norbert schrieb:> Muss wohl echt ein Windows Ding sein. Selbst mit Python und wxPython ist> die eine Millisekunde bei Linux überhaupt kein Problem
LOL
Du hast ja mal definitiv überhaupt keine Ahnung. Was glaubst du, wozu es
die Echtzeit-Patches für den Kernel gibt, wenn Linux das schon von Hause
aus angeblich so problemlos handeln kann?
Harald K. schrieb:> Das hat nichts mit Effizienz, sondern der Frequenz des Timerinterrupts> zu tun. Und die liegt halt auf Windowssystemen üblicherweise bei 100 Hz.> Früher™ war das noch schlimmer, da lag sie bei nur 18.2 Hz.
Naja, das hat sehr wohl auch was mit der Effizienz zu tun. Es gibt (für
Windows genauso wie für Linux) Echtzeit-Patches, die das Task-Switching
in die Größenordnung 1ms bringen. Allerdings: bei beiden OS ist das
erwartungsgemäß mit insgesamt einer deutlichen Verschlechterung der
Leistung des Gesamtsystems verbunden.
Genau deshalb wendet man diese Patches auch nicht für normale
Installationen an.
C-hater schrieb:> Norbert schrieb:>>> Muss wohl echt ein Windows Ding sein. Selbst mit Python und wxPython ist>> die eine Millisekunde bei Linux überhaupt kein Problem>> LOL>> Du hast ja mal definitiv überhaupt keine Ahnung. Was glaubst du, wozu es> die Echtzeit-Patches für den Kernel gibt, wenn Linux das schon von Hause> aus angeblich so problemlos handeln kann?
Glaubst du Clown allen Ernstes das eine MILLISEKUNDE ein
ernstzunehmendes Problem darstellt? Du meine Güte, ich habe so etwas
ständig hier laufen.
Manchmal sind es vielleicht 1020µs, manchmal auch 1050µs. Aber das ist
es dann auch.
Möglicherweise magst du dich auch einmal mit NUMA/Prioritäten/expliziten
Kernzuweisungen usw. beschäftigen.
Du kannst aber auch gerne weiter rumquatschen.
Norbert schrieb:> Glaubst du Clown allen Ernstes das eine MILLISEKUNDE ein> ernstzunehmendes Problem darstellt?
C-Hater hat vollkommen recht.
Ohne PREEMPT_RT ist das Einhalten der Millisekunde pure Glückssache.
MaWin O. schrieb:> C-Hater hat vollkommen recht.> Ohne PREEMPT_RT ist das Einhalten der Millisekunde pure Glückssache.
Es geht nicht um das präzise Einhalten, soviel sollte doch klar sein.
Es ging hier die ganze Zeit um einen 1ms Timerevent.
Und wenn man mit einer seltenen Abweichung im - sagen wir 100µs Bereich
- leben kann.
Schnell hingeklopfter Beispielcode (und ein Log):
1
#!/usr/bin/python3
2
# -*- coding: utf-8 -*-
3
importarray
4
importtime
5
importsignal
6
7
defcb_signal(signum,stackframe):
8
globalidx,end_all
9
arr[idx]=time.time()
10
idx+=1
11
ifidx>=MAX_COLLECT:
12
signal.setitimer(signal.ITIMER_REAL,0,0)
13
end_all=True
14
15
MAX_COLLECT=1000+1
16
end_all=False
17
arr=array.array('d',(0for_inrange(MAX_COLLECT)))
18
idx=0
19
signal.signal(signal.SIGALRM,cb_signal)
20
signal.setitimer(signal.ITIMER_REAL,0.001,0.001)
21
whilenotend_all:
22
time.sleep(.1)
23
24
foriinrange(1,MAX_COLLECT):
25
delta_us=(arr[i]-arr[i-1])*1E6
26
print(f'{1000-delta_us:+8.3f} µs')
Aufruf:
python3 PC_test_timer.py
und dann:
nice -10 python3 PC_test_timer.py
Und wenn das noch nicht reichen mag, kann man auch noch exklusiv einen
Kern reservieren. Dann wird's noch schöner.
Erzählt mir bitte nicht das Dinge nicht gehen, wenn ich sie hier ständig
laufen habe. Nun kann's jeder ausprobieren. Danke.
MaWin O. schrieb:> Norbert schrieb:>> Glaubst du Clown allen Ernstes das eine MILLISEKUNDE ein>> ernstzunehmendes Problem darstellt?>> C-Hater hat vollkommen recht.> Ohne PREEMPT_RT ist das Einhalten der Millisekunde pure Glückssache.
Erfahrungsgemäß funktioniert es ohne PREEMPT_RT mit einer Millisekunde
schon recht gut, wenn nicht gerade noch andere rechenlastige Prozesse
oder eine Auslagerungsorgie läuft. Aber man muss mit ein paar Ausreißern
rechnen. Mit PREEMPT_RT ist die Millisekunde tatsächlich kein Problem.
Und der Prozess muss natürlich für sich realtime-Scheduling aktivieren
und sich gegen Auslagerung sperren - und vorher die Berechtigung dazu
bekommen haben. Weiterhin wartet man nicht für eine bestimmte Dauer,
sondern bis zu einem bestimmten Zeitpunkt, den man dann immer in
Millisekundenschritten hochzählt. Das habe ich seit fast 15 Jahren in
mehreren Systemen erfolgreich so im Einsatz.
Rolf M. schrieb:> Erfahrungsgemäß funktioniert es ohne PREEMPT_RT mit einer Millisekunde> schon recht gut, wenn nicht gerade noch andere rechenlastige Prozesse> oder eine Auslagerungsorgie läuft. Aber man muss mit vereinzelten> Ausreißern rechnen.
Auch wenn man explizit einen Kern nur für diese Anwendung sperrt? Und
die Priorität erhöht (den nice Wert absenkt)? Dafür sind ja nur wenige
Zeilen in einer Konfigurationsdatei einzutragen und man darf das als
normaler User.
Ausreißer? So etwas ist mir noch nie unter gekommen - was aber nicht
heißt das es nicht möglich wäre. Allein der sich dahinter versteckende
Mechanismus würde mich natürlich interessieren.
> Weiterhin wartet man nicht für eine bestimmte Dauer, sondern bis> zu einem bestimmten Zeitpunkt, den man dann immer in> Millisekundenschritten hochzählt.
Genau das macht ›titimer‹, darum hat man manchmal wenige Mikrosekunden
weniger, dann wieder wenige Mikrosekunden mehr.
Norbert schrieb:> Rolf M. schrieb:>> Erfahrungsgemäß funktioniert es ohne PREEMPT_RT mit einer Millisekunde>> schon recht gut, wenn nicht gerade noch andere rechenlastige Prozesse>> oder eine Auslagerungsorgie läuft. Aber man muss mit vereinzelten>> Ausreißern rechnen.>> Auch wenn man explizit einen Kern nur für diese Anwendung sperrt? Und> die Priorität erhöht (den nice Wert absenkt)? Dafür sind ja nur wenige> Zeilen in einer Konfigurationsdatei einzutragen und man darf das als> normaler User.
Man darf als normaler User einen Kern komplett für eine spezifische
Anwendung reservieren? Aber so habe ich das noch nicht getestet.
> Ausreißer? So etwas ist mir noch nie unter gekommen - was aber nicht> heißt das es nicht möglich wäre. Allein der sich dahinter versteckende> Mechanismus würde mich natürlich interessieren.
Woher sie genau kommen, weiß ich nicht, aber ich konnte sie durchaus
messen. Das war aber wie gesagt ohne PREEMPT_RT. Mit dem Preempt-Kernel
waren diese Ausreißer nicht zu sehen. Das hat mir dann auch deutlich
gezeigt, dass Preempt durchaus wichtig ist.
>> Weiterhin wartet man nicht für eine bestimmte Dauer, sondern bis>> zu einem bestimmten Zeitpunkt, den man dann immer in>> Millisekundenschritten hochzählt.>> Genau das macht ›titimer‹, darum hat man manchmal wenige Mikrosekunden> weniger, dann wieder wenige Mikrosekunden mehr.
Ich nutze clock_nanosleep(), das auch zu den Realtime-Funktionen zählt.
Dem kann man sagen, welche "clock" es nehmen soll, und man kann wählen,
ob man relativ oder absolut warten will.
Rolf M. schrieb:> Man darf als normaler User einen Kern komplett für eine spezifische> Anwendung reservieren?
Grins. Na ja, root muss es ihm schon irgendwann mal erlauben…
Genau wie die Prioritätserhöhung.
Core spezifizieren geht ohne Erlaubnis, da es sich ja um ein selbst
auferlegtes weiteres Limit handelt.
> Woher sie genau kommen, weiß ich nicht, aber ich konnte sie durchaus> messen. Das war aber wie gesagt ohne PREEMPT_RT. Mit dem Preempt-Kernel> waren diese Ausreißer nicht zu sehen. Das hat mir dann auch deutlich> gezeigt, dass Preempt durchaus wichtig ist.
Muss ich mir bei Gelegenheit mal bauen, vielleicht macht's einige Dinge
noch einfacher. Wie gesagt, kleine Unschärfen im sub100µs Bereich
beobachte ich auch. Stören aber keine meiner Routinen.
> Ich nutze clock_nanosleep(), das auch zu den Realtime-Funktionen zählt.> Dem kann man sagen, welche "clock" es nehmen soll, und man kann wählen,> ob man relativ oder absolut warten will.
Ja, so wie bei setitimer: ITIMER_REAL,ITIMER_VIRTUAL,ITIMER_PROF
Nur da muss man nicht selber warten und zählen, es gibt einen konstanten
Strom von Signalen die callbacks auslösen.
Norbert schrieb:> sagen wir 100µs Bereich
Dieser Bereich ist PREEMPT_RT vorbehalten.
Norbert schrieb:> Erzählt mir bitte nicht das Dinge nicht gehen, wenn ich sie hier ständig> laufen habe. Nun kann's jeder ausprobieren. Danke.
Du bist ein Schwätzer.
Dass es bei dir funktioniert, beweist rein gar nichts.
Norbert schrieb:> Rolf M. schrieb:>> Man darf als normaler User einen Kern komplett für eine spezifische>> Anwendung reservieren?>> Grins. Na ja, root muss es ihm schon irgendwann mal erlauben…> Genau wie die Prioritätserhöhung.
Ok, das passt schon eher zu dem, wie ich es mir vorstelle.
> Muss ich mir bei Gelegenheit mal bauen, vielleicht macht's einige Dinge> noch einfacher.
Das ist das schöne bei Debian. Da gibt's den immer fertig als Paket.
Einfach apt install linux-image-rt, booten und fertig.
> Ja, so wie bei setitimer: ITIMER_REAL,ITIMER_VIRTUAL,ITIMER_PROF> Nur da muss man nicht selber warten und zählen, es gibt einen konstanten> Strom von Signalen die callbacks auslösen.
Bei clock_nanosleep gibt's noch CLOCK_MONOTONIC, für das es bei
setitimer soweit ich weiß keine direkte Entsprechung gibt. Und ich muss
dann eben nicht den Umweg über einen Signalhandler gehen, sondern
arbeite direkt in einer while-Schleife, die am Ende jedes Durchlaufs
einfach auf den nächsten Tick wartet. Und warten musst du ja auch
irgendwie.
MaWin O. schrieb:> Norbert schrieb:>> sagen wir 100µs Bereich>> Dieser Bereich ist PREEMPT_RT vorbehalten.
So große Abweichungen habe ich bei PREEMPT_RT aber auch noch nicht
gesehen.
MaWin O. schrieb:> Rolf M. schrieb:>> So große Abweichungen habe ich bei PREEMPT_RT aber auch noch nicht>> gesehen.>> Habe ich das behauptet?
Ist das eine Fangfrage?
Schade, dass das hier wieder in ein Gemätzel abdriftet. Was kann ich
praktisch tun, damit es besser läuft?
Ich habe die gleiche Anwendung einmal in Qt und einmal mit wxWidgets
gebastelt. Bei Qt läuft das mit einem QTimer wesentlich besser, bzw. ich
merke keine Verzögerung.
MaWin O. schrieb:> Norbert schrieb:>> sagen wir 100µs Bereich>> Dieser Bereich ist PREEMPT_RT vorbehalten.>> Norbert schrieb:>> Erzählt mir bitte nicht das Dinge nicht gehen, wenn ich sie hier ständig>> laufen habe. Nun kann's jeder ausprobieren. Danke.>> Du bist ein Schwätzer.> Dass es bei dir funktioniert, beweist rein gar nichts.
Ich lese hier seit vielen Jahren mit und habe seit der
Registrierungsumstellung noch nichts geschrieben. Aber für das oben
stehende musste ich mich anmelden, weil das so nicht unkommentiert
stehen bleiben darf.
Ich halte eigentlich sehr viel von MaWin Original, aber so pauschal ist
seine Aussage leider ziemlich falsch.
Ich habe beruflich mit komplexeren Echtzeitregelungssystemen zu tun. Wir
setzen dafür AMD EPYC Server mit viel RAM, cores (große
Matrixmultiplikationen, AMD EPYCs wegen Speicherbandbreite Sensoren ->
Server(MVM) -> Aktoren) ein, sowie 10/25/100 GbE Ethernet, um mit den
Steuerelementen zu kommunizieren.
PREEMPT_RT braucht man nur, wenn man mehrere Prozesse auf dem selben
Kern laufen lassen muss (z.B. weil CPU klein gewählt wegen Energiebedarf
oder Bauteilkosten). Wenn man genügen Kerne hat und sie fest für je
einen Thread reservieren kann, dann ist Echtzeit auch ohne PREEMPT_RT
kein Problem.
Wir senden hier Ethernetpakete mit DPDK raus und haben auch den
Messaufbau zum relativ genauen timestampen (100 GbE Sniffer mit PTP und
PPS). Wir bekommen 0.2 µs Standardabweichung und max. 0.5 µs
Absolutfehler vom Sollzeitpunkt. Über Tage. Fast saturierte 10GbE, Jubmo
packets. Vanilla Kernel 5.15.106. Nimmt man normale UDP sockets statt
DPDK sind es immer noch <10µs vom user Prozess bis zum Kabel. Mit XDP
sockets + BPF könnte man vermutlich auch auf DPDK verzichten, bei gleich
niedriger Latenz.
Man muss Linux entsprechend tunen, dass das geht. Kernel cmdline opts:
- isolcpus=<cores>: auf die Kerne setzen, die isoliert werden sollen.
Das weist den scheduler an, keine User-Tasks auf den Kernen zu
schedulen, aber kernel threads und IRQs usw können schon noch vorkommen.
- irqaffinity=<cores>: auf die anderen Kerne setzen (Komplement) als
die, die isoliert werden sollen. Dadurch werden die ganzen IRQs by
default nicht mehr auf den isolierten Kernen gescheduled. Das sollte man
über die kernel cmdline machen anstatt im userspace, weil es manche IRQs
gibt, die sich später nicht mehr verschieben lassen (AFAIK habe ich das
mal mit nem RAID controller gesehen)
- tsc=reliable: Bei modernen CPUs ist die TSC stabil. Linux schaut
dennoch alle paar ms mal nach und prüft, ob der TSC gut ist. Mit
"reliable" kann man das abschalten.
- Dann haben wir noch nohz_full=<cores>, rcu_nocbs=<cores>, iommu=pt,
aber die sind IIRC gar nicht notwendig.
- cstates kann man auf entsprechende timeouts setzen. Manuell aus der
Applikation oder mit tuned. Aber die bewegen sich IIRC so in 20µs
Bereich.
Die Anwendung im userspace setzt beim Start die CPU affinity von den
threads auf die isolierten Kerne, ein Startup-script schiebt die
Netzwerk IRQs auf isolierte benachbarte cores davon.
Man kann das ganze dann noch weiter spinnen mit hugepages + mlock.
(Wahrscheinlich kann man viele von den Sachen auch über cgroupsv2 setzen
und nicht in der kernel cmdline, haben wir aber noch nicht ausprobiert.)
Prozessprioritäten muss man dann gar nicht nutzen. Wieso auch? Es läuft
ja eh nur ein (gepinnter) Thread auf dem Kern.
Zum überprüfen kann (sollte) man das kernel tracing verwenden. Die
Dateien kann man mit Kernelshark analysieren.
Josef schrieb:> Wir setzen dafür AMD EPYC Server mit
Also wieder ein Beispiel.
Und was sagt es aus? Dass es in deinem Fall funktioniert. Nicht mehr und
nicht weniger.
> PREEMPT_RT braucht man nur, wenn man mehrere Prozesse auf dem selben> Kern laufen lassen muss (z.B. weil CPU klein gewählt wegen Energiebedarf> oder Bauteilkosten). Wenn man genügen Kerne hat und sie fest für je> einen Thread reservieren kann, dann ist Echtzeit auch ohne PREEMPT_RT> kein Problem.
Das ist ganz großer Quatsch mit Soße.
Auch ein Exclusiv-CPU-Task kann aufgehalten werden, wenn er durch
Kernelressourcen blockiert wird, die in !PREEMPT_RT blockierend sind.
> Wir senden hier
Schön.
Was macht PREEMPT_RT? Es liefert einen unterbrechbaren Kernel. D.h. z.B.
dass busy loops im Kernel durch andere Locking-Mechanismen ersetzt
werden. Es liefert Prozessprioritäten, die sogar höher als Kernel
threads sein können. Es liefert threaded IRQs, sodass ein IRQ später
behandelt werden kann, wenn gerade ein hochpriorisierter task
gescheduled werden muss.
Wenn man keine tasks hat, die um die selbe CPU "kämpfen", braucht man
PREEMPT_RT nicht. Wenn man die RT priorities nicht nutzt, braucht man es
eigentlich auch nicht, weil es sich wie ein normales Linux verhält.
PREEMPT_RT ist eine wirklich schöne Sache, wenn man auf limitierten
Systemen arbeiten muss (z.B. nur 1 core, embedded). Aber wenn man für
die Anwendung sowieso genügend cores hat (z.B. dual socket à 64 cores),
dann bringt PREEMPT_RT gar nichts bzw. ist sogar langsamer/hat eine
höhere Latenz, weil threaded IRQs und nicht-spinlocks verwendet werden.
Wie immer gilt: nicht blind glauben, sondern messen!
Wir haben früher PREEMPT_RT verwendet ("wegen der Echtzeit", "normaler
Linux kann das doch gar nicht") und haben aber diesen Mythos durch
Messung und Tuning (und Kontakt mit Linux maintainern) aufklären können.
Wieso sollte es auch anders sein? Wenn man alle Störquellen (andere
tasks, IRQs, TSC watchdog, ...) beseitigt hat, wieso sollte Linux einen
Task von seiner CPU reißen? Um den idle task du schedulen? Ne...
Josef schrieb:> Es liefert threaded IRQs,
Die sind immer vorhanden. RT erzwingt sie für alle Interrupts.
> Wenn man keine tasks hat, die um die selbe CPU "kämpfen", braucht man> PREEMPT_RT nicht.
Ja. Wenn das in deinem Fall so ist, dann ist das in deinem Fall so.
In meiner Kernelversion nimmt mein Task ein Kernel-Spinlock. Plötzlich
ist die CPU blockiert. Was nun?
> Aber wenn man für> die Anwendung sowieso genügend cores hat (z.B. dual socket à 64 cores),> dann bringt PREEMPT_RT gar nichts
Das ist halt Quatsch. Kannst du jetzt gerne noch 10 mal wiederholen.
Bleibt Quatsch.
> Wie immer gilt: nicht blind glauben, sondern messen!
Genau. Aber auch nicht von einem System auf die Welt schließen.
> und haben aber diesen Mythos durch> Messung und Tuning (und Kontakt mit Linux maintainern) aufklären können.
Schön für euren Fall.
> wieso sollte Linux einen> Task von seiner CPU reißen?
Es gibt noch mehr, als den Scheduler.
MaWin O. schrieb:> In meiner Kernelversion nimmt mein Task ein Kernel-Spinlock. Plötzlich> ist die CPU blockiert. Was nun?
Wieso sollte mein Task in kernel space gehen?
In DPDK mache ich keine syscalls und in XDP wären es schnelle read/write
für die flags. Natürlich kann man nicht universell sagen, dass es nie
vorkommen kann, aber für konkrete Systeme kann man das sehr wohl:
Im heißen Pfad gibt es wenige und immer die gleichen syscalls (read,
write). clock_gettime geht über die VDSO, kein syscall.
Speicherallozierung macht man im heißen Pfad nicht. Also wo soll das
spinlock herkommen? Man kann auch einfach das tracing mitlaufen lassen,
solange man sich nicht sicher ist.
MaWin O. schrieb:> Ohne PREEMPT_RT ist das Einhalten der Millisekunde pure Glückssache.
Wenn du einen Nieschenkerneltreiber verwendest, der nicht auf PREEMPT_RT
angepasst wurde, ist das Einhalten der Millisekunde auch unter
PREEMPT_RT pure Glückssache.
Und egal ob PREEMPT_RT oder nicht, die SMIs bleiben (noch nicht im
echten Leben gemessen). In unserem Setup sind wir jetzt aber soweit,
dass wir die PCIe4 Latenzen sehen können, z.B. mehrere NICs auf der
selben Karte aber verschiedene cores/threads, die darauf schreiben. Das
ist für uns ein tolerierbares Hintergrundrauschen.
Josef schrieb:> Man muss Linux entsprechend tunen, dass das geht. Kernel cmdline opts:> - isolcpus=<cores>: auf die Kerne setzen, die isoliert werden sollen.> Das weist den scheduler an, keine User-Tasks auf den Kernen zu> schedulen, aber kernel threads und IRQs usw können schon noch vorkommen.
Vielen Dank für Deine Ausführungen aus der Praxis, diese Methoden
verwende ich auch schon seit einigen Jahren erfolgreich. Habt Ihr auch
schon einmal eine Kombination mit exklusiven "cpusets" experimentiert?
MaWin O. schrieb:> Also wieder ein Beispiel.> Und was sagt es aus? Dass es in deinem Fall funktioniert. Nicht mehr und> nicht weniger.
Ich warte ja immer noch auf eine Gegenbeispiel von dir. Solange das
fehlt, sind deine Aussagen nichts weiter als heiße Luft.
Bisher steht es: 3 Praxis-Beispiele, wo es funktioniert zu ein paar
Rants, die behaupten, dass es eigentlich nicht funktioniert.
Keine A. schrieb:> In meiner Anwendung soll jede Millisekunde etwas parallel gemacht> werden.
Warum?
Welches Ereignis ist so wichtig, dass bei einer PC-Applikation der
eigentliche Ablauf des Programms tausend mal pro Sekunde unterbrochen
werden muss?
> Ich befürchte, ich habe den falschen Ansatz, da ich aus der µC Welt> komme.
Wenn Du uns sagen würdest, was Du eigentlich machen willst, könnten wir
Dir da weiterhelfen...
Josef schrieb:> Wieso sollte mein Task in kernel space gehen?
Ja, wie mehrfach gesagt.
Du hast einen Spezialfall, in dem es geht.
Nicht mehr und nicht weniger.
> Wenn du einen Nieschenkerneltreiber verwendest, der nicht auf PREEMPT_RT> angepasst wurde
Was soll denn da angepasst werden müssen?
Allenfalls sollte man solche Zeitanforderunegen an externe Hardware
auslagern. Sonst wird das eh nichts. Ein PC ist ein
Visualisierungsgeraet, kein Controller. Ein externer Controller kann das
Timing viel besser, zur visualisierung zurueck auf den PC.
Purzel H. schrieb:> Sonst wird das eh nichts. Ein PC ist ein> Visualisierungsgeraet, kein Controller
Mit PREEMPT_RT ist das eben nicht so.
Sicher ist man auch mit PREEMPT_RT nicht ganz unabhängig von der
Hardware. Wenn z.B. ein SMI oder NMI ständig reinhaut, dann kann das OS
da gar nichts machen.
Aber generell sind mit PREEMPT_RT, geeigneter HW und z.B. dem
Deadline-Scheduler Deadlines von 100 µs problemlos und zuverlässig
möglich. Eine 1 ms Deadline is geradezu ewig lang für PREEMPT_RT und
erzeugt einem solchen Kernel keinerlei Schweißperlen auf der Stirn.
Wenn es mit der Deadline-Anforderung deutlich unter 100 µs geht, dann
sollte man tatsächlich so langsam über einen eigenen Controller
nachdenken.
Harald K. schrieb:> mit der Win32-API-Funktion timeBeginPeriod kannst Du das in ganzen> Millisekunden auf 1 msec reduzieren.
Jittert aber wie blöd.
Josef schrieb:> Nieschenkerneltreiber
"Nieschen" wie der Name "Lieschen"? Oder wie die bekannte "Nische"?
Beckhoff hat auch so eine Treiberschicht für sein TwinCAT. Wenn das
läuft (und das tut es automatisch, weil der beim Booten geladen wird),
dann hast du auch mal eine Chance, nach langer Zeit wieder einen
Bluescreen zu sehen.
Und den anderen Kollegen hat es deswegen laufend aus den
Teams-Besprechungen rausgehauen. Jetzt hat er die Beckhoff-SW wieder vom
Office-Rechner deinstalliert und einen eigenen PC dafür aufgesetzt.
Josef schrieb:> Und egal ob PREEMPT_RT oder nicht, die SMIs bleiben (noch nicht im> echten Leben gemessen).
Das soll wohl sehr vom Board abhängig sein. Teilweise werden darüber in
dem BIOSen irgendwelche Work-Arounds für Hardware-Bugs integriert.
Deshalb macht OSADL Messungen mit aller möglicher Hardware, um solche
Problemkinder zu finden.
Lothar M. schrieb:> Josef schrieb:>> Nieschenkerneltreiber> "Nieschen" wie der Name "Lieschen"? Oder wie die bekannte "Nische"?
Vielleicht wenn jemand niest: "Ich habe ein Nieschen gemacht". 😉
Sheeva P. schrieb:> Vielen Dank für Deine Ausführungen aus der Praxis, diese Methoden> verwende ich auch schon seit einigen Jahren erfolgreich. Habt Ihr auch> schon einmal eine Kombination mit exklusiven "cpusets" experimentiert?
Wie weiter oben schon geschrieben, haben wir das noch nicht ausprobiert
aber wie haben es vor. Eigentlich sollte es funktionieren, aber testen
muss man es trotzdem. Der Vorteil wäre, dass man nicht ab Boot die Cores
für normale Nutzung im System verliert (Software auf einem 128 Kerner
bauen ist schon schön), sondern dynamisch mit den cpusets einschalten
kann, wann man sie isoliert/exklusiv braucht.
Habe was ähnliches gestern mit C# ausprobiert, einmal mit einem endlos
loopenden backgroundworker + sleep,
https://learn.microsoft.com/en-us/dotnet/api/system.componentmodel.backgroundworker?view=net-7.0
und einmal mit einem timer, der regelmäßig feuert,
https://learn.microsoft.com/en-us/dotnet/api/system.threading.timer?view=net-7.0.
Beides war recht ernüchternd.
Der Timer hat einen overhead von ~8-12 ms pro Event - man kann einen
Offset, der vermutlich nur für mein System gilt abziehen, damit wird die
Genauigkeit bei periodischen Triggern etwas höher - aber kleiner als 15
ms ohne dass irgendwas in dem callback gemacht wird, kam ich nicht.
Ein endlos (lang) laufender BGW ist eigentlich nicht empfohlen (wird
aber häufig auf SO mit einem cancellation token gezeigt), insbesondere,
wenn dort ein Sleep vorkommt, um timings zu simulieren - funzt aber
besser als die Timer Lösung. Auch da gibt es einige ms overhead, die man
offenbar abziehen kann. Minimale sample time (Sleep(1)) war dann so bei
5-8 ms.
Hätte auch gedacht da geht mehr.
Der PC (Windows 10, dicke CPU) hat sich in allen Varianten gelangweilt,
instrumentation hat gezeigt, dass die meiste Zeit im Kernel drauf geht -
ich denke schneller ist das Kontextwechseln einfach nicht.
Edit: https://stackoverflow.com/a/73535286/3620376 kommt auf ähnliche
Zahlen (5-8 ms), offenbar gibt es 15 ms Zeitscheiben, interessant.
Naja, Windows ist halt immer noch kein echtes Multitasking- System.
Dank der neuen Prozessoren und mit mehr Kernen ist es seit
dem Anfang schon ziemlich nahe dran gekommen, aber halt
immer noch nicht ganz (Zeitscheiben).
Deshalb denke ich, daß da immer ein paar ms bleiben, egal
wie man es nun anstellt.
Hallo!
Wer unter Windows "mehr" braucht als Sleep() bietet, der kann auch die
ntdll.dll anzapfen. Dieser kleine Thread unten hält beispielsweise die
256-Bit-Stages auf Trab, indem aller 0,7 ms (das ist die -7000 unten)
ein entsprechender Befehl ausgeführt wird. Das funktioniert bis -5000,
also 2000 mal pro Sekunde. Die Zeiteinheit ist also 100ns, das Minus
bedeutet "relative Zeiten".
Das ist kein Busy-Loop, die CPU-Last geht nur etwa 1-2% hoch. Viel mehr
sollte man dort aber wirklich nicht erledigen wollen. Wer den "counter"
alle paar Sekunden ausliest wird sehen, daß das funzt.
Heinz B. schrieb:> Deshalb denke ich, daß da immer ein paar ms bleiben, egal> wie man es nun anstellt.
Ich habe in Tcl/Tk eine Zählroutine gestartet, die eine Variable um eins
hochzählt und sich dann nach 1 ms (mit "after 1 zaehlroutine") erneut
aus der Eventqueue startet. Erstaunlicherweise (und völlig unerwartet)
habe ich alle Sekunde die Zählvariable um 1000 hochgehen sehen. Könnte
sein, daß Windows inzwischen besser ist, als gedacht. Habe aber gerade
keine Hardwarekarte zur Hand, um das Ganze auch auf dem Oszi zu
verifizieren.
Gruß Klaus (der soundsovielte)
Hier ein Oszillogramm einer Ausgabe von 0xC0 auf UART mit 115,2 KBaud
jede Millisekunde in Windows 10 auf einem 10 Jahre alten Fujitsu-Rechner
(Haswell). scheint gut zu funktionieren, selbst in einer Skriptsprache
wie Tcl. Der von Heiko (zwergnr8) beschriebene Weg wird wohl vermutlich
die Grundlage dafür abgeben.
Gruß Klaus (der soundsovielte)
Klaus S. schrieb:> scheint gut zu funktionieren, selbst in einer Skriptsprache wie Tcl
Dann beschäftige den Rechner mal während der Messung. Ich fürchte dann
sieht das nicht mehr so gut aus. Z.B. Firefox starten.
Also meiner Erfahrung nach kannst du unter Windows nicht wirklich unter
10ms kommen. Was aber eventuell möglich wäre, über NOPs den aktuellen
Thread blockieren (habe ich selber noch nie gemacht).
Und solange Standard-Windows kein Echtzeit-OS wurde (was komplett an mir
vorbei gegangen wäre) kannst du dich nie und nimmer auf "Echtzeit"
verlassen.
900ss D. schrieb:> Dann beschäftige den Rechner mal während der Messung. Ich fürchte dann> sieht das nicht mehr so gut aus. Z.B. Firefox starten.
Wäre jetzt auch mein Ansatz gewesen, oder irgend ein Virenscanner,
OneDrive-Aktualisierung im Hintergrund laufen lassen...
Klaus S. schrieb:> aus der Eventqueue startet. Erstaunlicherweise (und völlig unerwartet)> habe ich alle Sekunde die Zählvariable um 1000 hochgehen sehen. Könnte> sein, daß Windows inzwischen besser ist, als gedacht. Habe aber gerade> keine Hardwarekarte zur Hand, um das Ganze auch auf dem Oszi zu> verifizieren.
Unter Linux hat man immer ~80ms zusätzlich in Summe, egal wie oft man
after aufruft.
Habe noch drei weitere Versuche gemacht. Wenn ich (wie Herbert) in Tcl
den Befehl "after 1" verwende, bekomme ich (wie von Harald erklärt) die
Prozeßgranularität von Windows zu sehen, alle 12 bis 15 Millisekunden
gibts eine Ausgabe (war unter XP auch nicht anders).
Unter Debian12 (Bookworm) bekomme ich mit "after 1" alle 2,5
Millisekunden eine Ausgabe und mit der sich selbst replizierenden
Prozedur "einsaus" mit der Anweisung "after 1 einsaus" darin etwa alle
1,2 Millisekunden eine Ausgabe.
Das sehe ich auf dem Oszi und das sind für mich die Fakten. Plattitüden
wie die Tatsache, daß das Timing unter Last in die Knie geht wissen nur
blutige Anfänger nicht. Es geht meines Erachtens in diesem Thread nicht
darum, wie man eine 1-ms-Routine verhindert, sondern wie man sie
erreichen kann. Verhindern geht am Besten ohnehin durch Ausschalten, das
spart dann auch noch Energie.
Gruß Klaus (der soundsovielte)
P.S. Für alle Nicht-Tcler: Der Befehl mit dem schönen Namen "after"
macht je nach Aufrufart 2 verschiedene Dinge. Mit einem einzigen
übergebenen Parameter legt er den gesamten Prozeß schlafen, mit 2
übergebenen Parametern sortiert er den als Parmeter2 übergebenen Namen
eines Unterprogramms mit der als Parameter1 übergebenen Wartezeit in die
Eventqueue ein.
PS2: Danke Heiko und Harald, ich habe was dazugelernt.
Klaus S. schrieb:> Plattitüden wie die Tatsache, daß das Timing unter Last in die Knie geht> wissen nur blutige Anfänger nicht.
Ach das hatte ich ganz vergessen, die lesen hier ja nicht mit. ;)
Und es wäre durchaus interessant gewesen, wie stark der Einfluss ist.
Ansonsten ist es immer noch reine Theorie die gezeigt wird. Es könnte
theoretisch so sein aber in der Praxis hat ein Rechner nun mal auch mit
Rechenlast zu tun.
900ss D. schrieb:> Und es wäre durchaus interessant gewesen, wie stark der Einfluss ist.> Ansonsten ist es immer noch reine Theorie die gezeigt wird. Es könnte> theoretisch so sein aber in der Praxis hat ein Rechner nun mal auch mit> Rechenlast zu tun.
Ich habe gezeigt, daß es geht, praktisch, nicht theoretisch. Es hat mich
selbst erstaunt, ich hätte vor diesen Experimenten gesagt: über 100 Hz
läuft nix, da braucht man ein Echtzeitsystem. Ich habe eine frei
verfügbare Scriptsprache verwendet, deren Grundzüge in 10 Minuten
erlernbar sind, so daß jeder meine Messungen wiederholen kann. Wenn also
jemand daran interessiert ist, weitere Informationen zu erhalten, so
steht ihm nichts im Weg. Ich weiß, wie ein Rechner unter Last reagiert.
Wenn Du es nicht weißt, dann bekomme einfach das Hinterteil in die Höhe
und mache diese Experimente. Zeig einfach, daß Du mehr kannst, als was
Du bisher gezeigt hast.
Möchtest Du die 10 Minuten Tcl-Lernerei vermeiden, so kann ich auch mein
Programm komplett vöffentlichen, bisher bin ich davon ausgegangenen, daß
die hier Anwesenden das auch ohne Nachhilfe hinbekommen. Ich irre mich
aber öfters mal.
Gruß Klaus (der soundsovielte)
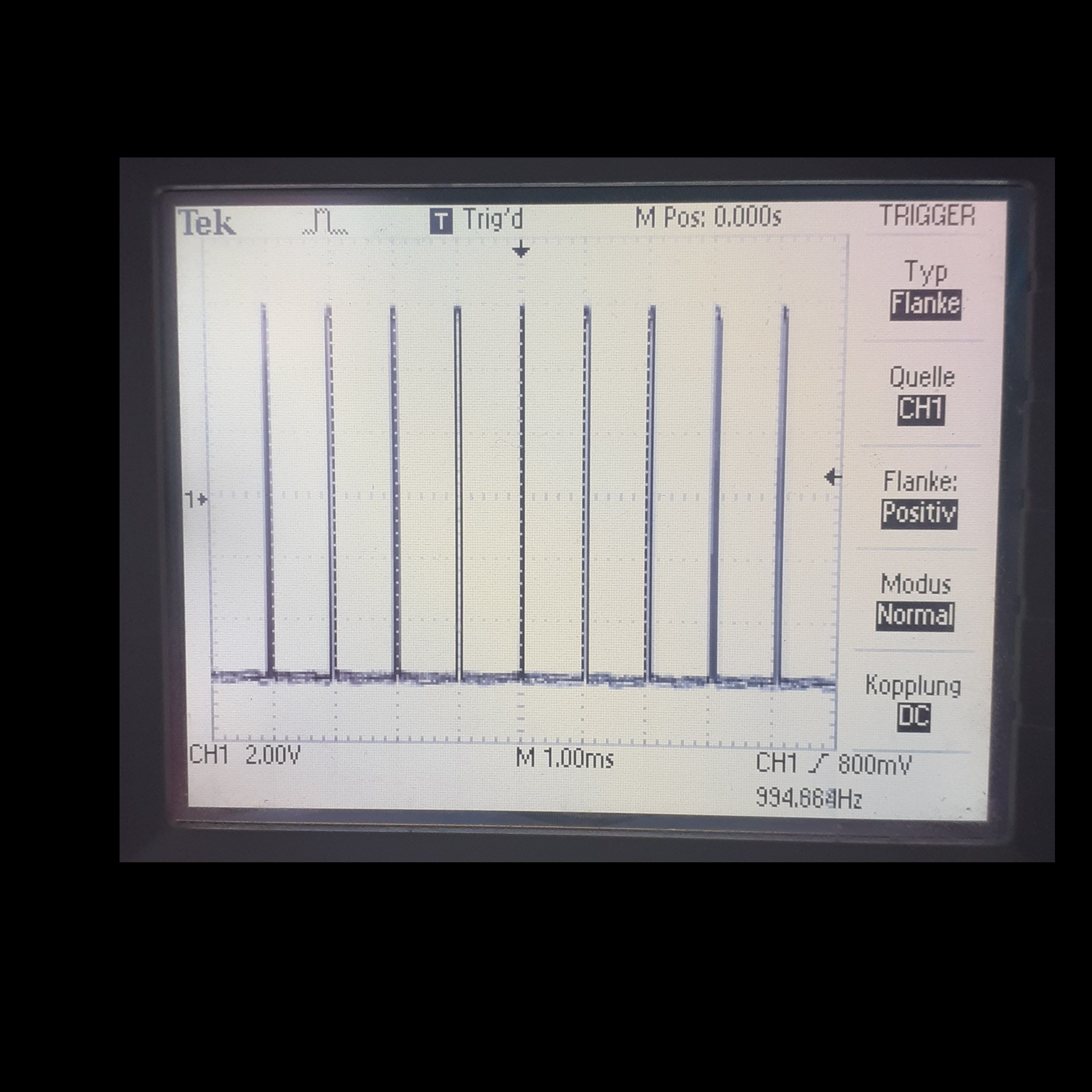
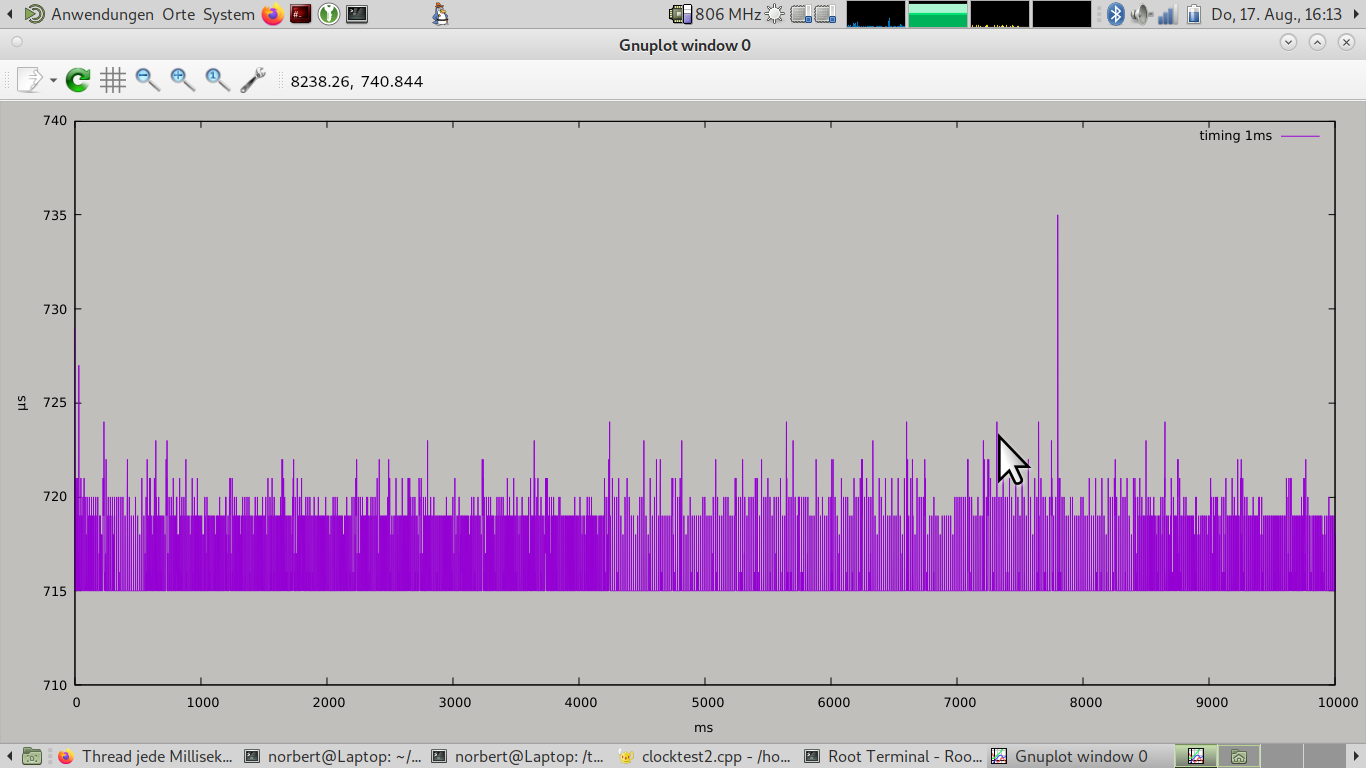
…und hier mal kurz einen Quickie vom Laptop herunter-gerotzt.
KEIN RT-LINUX!
Standard debian, lahmarschige CPU, einen Kern isoliert und das (c++)
Progrämmchen mit nice -10 für 10 Sekunden (10000 events) laufen
lassen.
Timer feuert jede Millisekunde (1000µs).
Die 10k Timings in array geschrieben und zum Ende ausgegeben und in
GnuPlot geschoben.
Timer beim Start nicht auf Millisekunden-Beginn synchronisiert (egal um
Regelmäßigkeit zu messen), feuert zumeist bei xxx715µs, hat aber oftmals
bis zu 4µs Verspätung und gelegentliche Ausreißer um 9µs, einmal sogar
um 20µs.
Aber bitte ignoriert diese Ergebnisse, es wurde ja bereits zuvor
festgelegt das so etwas nicht möglich ist. ;-)
Und ja, das ist selbstverständlich kein RT Verhalten, aber um einmal
jede Millisekunde etwas zu machen…
Norbert schrieb:> Und ja, das ist selbstverständlich kein RT Verhalten, aber um einmal> jede Millisekunde etwas zu machen…
Um beispielsweise eine 50-Hz-Unterdrückung durch Aufsummierung von 20
ADC-Werten zu machen, sollte das völlig ausreichen.
Gruß Klaus (der soundsovielte)
Klaus S. schrieb:> daß die hier Anwesenden das auch ohne Nachhilfe hinbekommen
Äh? Was hat dich denn so schlecht gelaunt gemacht? Meine Güte....
Klaus S. schrieb:> Ich habe gezeigt, daß es geht, praktisch, nicht theoretisch.
Unter Last hat du es nicht gezeigt. Und genau das(!) wäre praktisch
interessant gewesen und nicht dieses Aufgeplustere dass du in der Lage
bist, in 10 Minuten ein Tcl-Programm zu schreiben was eine Zeitmessung
macht. Und so wie die gemacht wurde ist die völlig irrelevant weil
praxisfern. Ja ich weiß schon, du hast es praktisch gemacht...
Respekt, ich bin wirklich beeindruckt. Du bist in der Lage eine
Zeitmessung durchzuführen :)
900ss D. schrieb:> Unter Last hat du es nicht gezeigt. Und genau das(!) wäre praktisch> interessant gewesen und nicht dieses Aufgeplustere dass du in der Lage> bist, in 10 Minuten ein Tcl-Programm zu schreiben was eine Zeitmessung> macht.
Läuft zuverlässig, solange du dem Task eine hohe Priorität gibst, am
besten Realtime, sonst funken irgendwelche superwichtigen Windows
Hintergrunddienste dazwischen. Benötigter Speicher muss vorher
alloziert werden, und Dateizugriffe müssen ganz am Anfang oder am Ende
durchführt werden - dann läuft das stabil. Den Defender ausmachen.
Linux funktioniert ähnlich gut, da habe ich keine Unterscheide gesehen.
Der Jitter der Uart Kommunikation liegt typisch unter 0.5 Millisekunden.
Zumindest einfache Sachen wie editieren und kompilieren geht nebenbei
ganz gut.
Unter Windows verwendet man CreateWaitableTimer und WaitForSingleEvent.
Wenn man unter 15 ms kommen möchte, dann muss man die Timer Resolution
mit NtSetTimerResolution reduzieren, was die Grundlast durch die
Interrupts etwas erhöht.
900ss D. schrieb:> Unter Last hat du es nicht gezeigt. Und genau das(!) wäre praktisch> interessant gewesen
Dann miß es endlich selbst und zeige, daß Du mehr kannst als Sprüche zu
klopfen. Dann wird sich auch meine schlechte Laune schlagartig bessern
;-)
Gruß Klaus (der soundsovielte)
Klaus S. schrieb:> daß Du mehr kannst als Sprüche zu klopfen
Der einzige der unfreundlich Sprüche geklopft hat warst du. Mein Gedanke
war, wenn du eh den Test schon am laufen hast, wäre Aufwand nicht mehr
sehr hoch, das nochmal laufen zu lassen und dabei auch Last zu erzeugen.
Aber es gibt Leute die schaffen das nicht, können nur unfreundlich
werden und das Thema "Last" als Platitüde abtun.
Deshalb schrieb ich dieses:
900ss D. schrieb:> Dann beschäftige den Rechner mal während der Messung.
Udo K. schrieb:> Läuft zuverlässig, solange du dem Task eine hohe Priorität gibst, am> besten Realtime
Danke, das ist doch mal eine Aussage, die Leuten weiter hilft.
Eine Messung im "Idle" ist nicht brauchbar da in der Praxis das System
kaum im "Idle"-Zustand ist.
Meine Erfahrung mit diversen RT-Linuxen hat mich gelehrt, dass es selbst
auf Echtzeitsystemen nicht so einfach ist, bspw. 1ms auch unter Last
reproduzierbar sauber hinzubekommen.
Das hängt von einigen Faktoren - gerade auch der Hardware - ab. Nicht
umsonst gibt es bspw. bei LinuxCNC Listen von Boards, die gut, die
weniger gut und die gar nicht geeignet sind.
Unter LinxcCNC laufen üblicherweise zwei RT-Threads: ein sehr schnell
getakteter mit 40-50kHz und einer mit eben dieser 1ms.
Selbst wenn man den schnellen Thread rauswirft (weil die
Schritterzeugung für einen Schrittmotor nicht notwendig ist bzw. von
externen FPGAs erledigt wird), hat man immer noch ordentlich Jitter
(hier aktuell 40-50µs) drin. Damit kann ich in meinem Fall aber leben.
Deutlich reduzieren kann man den Jitter unter Linux (wie schon oben
geschrieben) durch Isolierung von einzelnen Kernen, die der Kernel bei
der Verteilung der Prozesse dann einfach ignoriert. Auf diesen lässt man
dann (nur) seine Echtzeitanwendung laufen.
Stichworte dazu sind "isolcpu" als Kernelparameter und "taskset" für die
manuelle Zuteilung von Prozessen auf bestimmte Kerne. Damit komme ich
hier auf unter 10µs Jitter für den 1ms-Thread.
Zu den Tcl-Programmen:
Ich würde vermutlich mit "clock microseconds" arbeiten. Selbst bei einem
Jitter hätte man dann doch relativ feste 1ms-Zeitscheiben, die nicht
"wandern". Falls das wichtig ist.
Norbert schrieb:> …und hier mal kurz einen Quickie vom Laptop herunter-gerotzt.> KEIN RT-LINUX!> Standard debian, lahmarschige CPU, einen Kern isoliert und das (c++)> Progrämmchen mit nice -10 für 10 Sekunden (10000 events) laufen> lassen.
Du weisst aber schon, dass (wie auch Chris angemerkt hat) eine isolierte
CPU und entsprechend hohe Priorität einem RT-Gepatchten Linux schon
verdammt nahe kommt. Wenn du dann explizit nur 1 Thread auf dieser CPU
laufen lässt hat du die exklusiv zur Verfügung. Je nach Setup kommen
dann maximal noch ein paar Interrupts auf der CPU, respektive wenn keine
Last da ist nicht einmal das.
Ausserdem teile ich die Erfahrungen (meine beziehen sich explizit auf
TSN und Echtzeit-Ethernet im Steuerungsbereich) von Chris auch, dass es
selbst bei einem RT-Linux verdammt schwierig ist, den Jitter
langzeitstabil tief zu halten. Weil wenn du nach 1 Woche Laufzeit einen
einzigen Ausreisser von 10ms von deinem 1ms Task hast, hast du halt
schon nicht erfüllt. Selbst wenn alle anderen bei 10us sind.
Patrick B. schrieb:> Du weisst aber schon, dass (wie auch Chris angemerkt hat) eine isolierte> CPU und entsprechend hohe Priorität einem RT-Gepatchten Linux schon> verdammt nahe kommt.
Nein, das kommt dem überhaupt nur nahe, wenn man einen reinen
Compute-Thread hat, der keinerlei Syscalls macht.
Sobald Syscalls gemacht werden, ist es hin mit der RT-Fähigkeit, wenn
kein RT-Kernel verwendet wird.
Patrick B. schrieb:> Du weisst aber schon, dass (wie auch Chris angemerkt hat) eine isolierte> CPU und entsprechend hohe Priorität einem RT-Gepatchten Linux schon> verdammt nahe kommt.
Ja klar, ich mach' den Senf schon Jahrzehnte.
Es ging mir darum zu zeigen, das ›normale‹ Aufgaben sich sehr wohl recht
nah an den vorgegebenen Timeslices ausrichten lassen.
Zudem wurde vom TE auch niemals RT-Fähigkeit und extremeste Präzision
gefordert.
Dies wurde erst später - und völlig unnötigerweise - in den Thread
hinein gequetscht um Unruhe und Verwirrung zu stiften.
Und dann wurde verzweifelt nach Möglichkeiten mit blockierenden Syscalls
gesucht, nur um doch noch irgendwie ein wenig Recht zu behalten.
Aber da war der Thread schon längst entgleist und verloren.
Leider nicht wirklich überraschend hier auf µC-Net.
Norbert schrieb:> Dies wurde erst später - und völlig unnötigerweise - in den Thread> hinein gequetscht um Unruhe und Verwirrung zu stiften.>> Aber da war der Thread schon längst entgleist und verloren.>> Leider nicht wirklich überraschend hier auf µC-Net.
Eine Diskussion, die nicht nach deiner Meinung verläuft, ist entgleist,
verloren und Unruhe.
Werd mal erwachsen.
MaWin O. schrieb:> Eine Diskussion, die nicht nach deiner Meinung verläuft, ist entgleist,> verloren und Unruhe.> Werd mal erwachsen.
Du solltest lernen Meinungen von Fakten zu unterscheiden.
Hilft dir auch im restlichen Leben.
Norbert schrieb:> Du solltest lernen Meinungen von Fakten zu unterscheiden.> Hilft dir auch im restlichen Leben.
Du bist ja ein sehr freundlicher Zeitgenosse.
Wenn du wegen fehlenden Fakten nicht weiterkommst, musst du beleidigen.
Denk mal darüber nach.
Norbert schrieb:> Aber da war der Thread schon längst entgleist und verloren.
Ich hab aber eine Menge Interessantes dabei gelernt. So wie man ein Ei
aus der Schale pellt, so kann man auch eine Menge Info aus
unerfreulichen Wortwechseln klauben. Wir sind eben zum Großteil nur
Menschen, bessere haben wir nicht.
Gruß Klaus (der soundsovielte)