Wir haben in der Firma eine größere Anzahl (ca. 600) von Datenblättern im PDF-Format, deren Inhalt wir gerne "strukturiert" (also nach dem Key-Value-Prinzip) in unsere interne (relationale) Datenbank einspeisen würden. Dummerweise liegen diese Dokumente in nahezu 15...20 verschiedenen Formaten bzw. Strukturen vor, so dass es nicht einfach so möglich ist, sie einheitlich zu verarbeiten. Weil es nun gerade "inn" ist und es uns auch tatsächlich möglich erscheint (nach manuellen Versuchen mit ChatGPT), würden wir dazu gerne OpenAI in Anspruch nehmen. Passender Programmcode ist vorhanden. Wir haben aus den PDFs die Texte extrahiert und würden OpenAI damit beauftragen, nach einer vorgegebenen Liste von Keys die dazu gehörenden Values herauszusuchen. Das Problem: Wir können die Kosten nach den von OpenAI propagierten "Tokens" zur Berechnung nicht wirklich einschätzen. Auf deren Webseite steht, dass das "so ähnlich ist, wie Worte oder Silben". Sehr nebulös. Nicht die Preise selbst, die stehen da ganz klar, aber deren Basis. Weiss hier jemand, was da nun genau gezählt wird? Sind das die "Worte", die zur Analyse übergeben werden, oder die, die dabei als Antwort herauskommen, oder am Ende beides in Summe? Oder die formulierte Aufgabenstellung?
Frank E. schrieb: > Weiss hier jemand, was da nun genau gezählt wird? Sind das die "Worte", > die zur Analyse übergeben werden, oder die, die dabei als Antwort > herauskommen, oder am Ende beides in Summe? Oder die formulierte > Aufgabenstellung? Wäre das nicht eine Frage an die KI?
600 Datenblätter! Da setzt man 1-2 armseelige Praktikanten dran die das innerhabl der Semesterferien katalogisieren.
Benedikt L. schrieb: > Da setzt man 1-2 armseelige Praktikanten dran die das innerhabl der > Semesterferien katalogisieren. Aber die Praktikanten sollen doch etwas lernen, das sie in Zukunft dann auch in der Wirtschaft brauchen :-) Lieber die Praktikanten an die AI setzen und rumfrickeln lassen, bis die Datenblätter drin sind, dann können sie sich danach wenigstens als "Prompt Engineer" bewerben: https://www.srf.ch/news/traumjob-prompt-engineer-ki-fluesterer-gesucht
KI ist ein nettes Spielzeugt fuer unterbelastete Arbeitskraefte. Der Aufwand etwas Erwartetes in vernuenftiger Zeit zu erreichen ist nicht abschaetzbar. Deswegen .. ja macht mal .. allenfalls ist es sogar lehrreich, bei zu wenig Aufwand kann's auch frustrierend sein. Als nicht unterbelastete Arbeitskraft wuerde ich mir einen halben Tag goennen und das Abstact jeweils selbst schreiben. Dann ist zumindest abschaetzbar wie lange es dauert. Und der Aufwand skaliert mit der Anzahl.
Christoph Z. schrieb: > danach wenigstens als > "Prompt Engineer" bewerben: > https://www.srf.ch/news/traumjob-prompt-engineer-ki-fluesterer-gesucht Bis dann eine KI kommt, welche diesen Job übernimmt und für eine andere KI eine gute Abfrage formuliert.
also ich habe ja von programmieren und so keine ahnung, aber ist es nicht immer so daß eine regex-engine nach den vorgegebenen ausdrücken sucht. https://de.wikipedia.org/wiki/Regul%C3%A4rer_Ausdruck. das notepad++ forum beschäftigt sich oft mit anfragen von usern, die nicht wissen wie man regex-suchen richtig "schreibt". prinzipiell ist es einfach. ich glaube so ein regex-suchbegriff darf bis zu 200 buchstaben lang sein. also die regex sucht dann nach den schlüsselbegriffen und könnte dann die hoffentlich nachfolgenden werte-buchstaben mit eventuell zu ignorierenden leerstellen ausgeben. regex sollte in jeder schule unterrichtet werden. oder bin ich jetzt zu einfach ? es ist viel komplizierter, oder ?
Carypt C. schrieb: > oder bin ich jetzt zu einfach ? Aus einem PDF lässt sich nicht mehr so genau ermitteln, welche Texte zusammengehören. Vorallem noch, wenn Text in einer Tabelle untergebracht ist. Ein PDF ist ja eher nur eine optische Repräsentation von einem Dokument als ein wirkliches Datenaustauschformat. Es ist ähnlich wie wenn Du von einem PCB nur Gerberdaten hast und dann versuchst, aus diesen wieder die Leiterbahnen, Kupferflächen und Footprints voneinander zu trennen. Oder wenn Du eine ausführbare Datei (Maschinencode) hast und aus diesem wieder C-Code generieren willst.
Frank E. schrieb: > Das Problem: Wir können die Kosten nach den von OpenAI propagierten > "Tokens" zur Berechnung nicht wirklich einschätzen. Auf deren Webseite > steht, dass das "so ähnlich ist, wie Worte oder Silben". Sehr nebulös. > Nicht die Preise selbst, die stehen da ganz klar, aber deren Basis. > > Weiss hier jemand, was da nun genau gezählt wird? Sind das die "Worte", > die zur Analyse übergeben werden, oder die, die dabei als Antwort > herauskommen, oder am Ende beides in Summe? Oder die formulierte > Aufgabenstellung? Nunja... die Token halt, und das ist tatsächlich nicht so einfach. Im Natural Language Processing gibt es sehr unterschiedliche Verfahren zur sogenannten "Feature Extraction", also: Zeichenketten (Strings) in Zahlen umzuwandeln, die ein Machine-Learning-Modell verstehen und benutzen kann. Eines dieser Modelle sind zum Beispiel N-Gramme mit einer fixen Länge. Dabei werden Zeichenfolgen dieser Länge extrahiert, bei Bigrammen -- also N-Grammen der Länge 2 -- würde das Wort "Haus" in die Token "Ha", "au" und "us" zerlegt, bei Trigrammen (3-grammen) in "Hau" und "aus":
1 | def make_ngrams(s, n): |
2 | return list(set([s[idx:idx+n] for idx in range(len(s) - n+1)])) |
Dabei ist zu beachten, daß durchaus auch N-Gramme unterschiedlicher Länge miteinander kombiniert werden, beispielsweise Bigramme, Trigramme und 4-gramme; auch 1-gramme -- also: einzelne Zeichen -- werden benutzt. Eine andere Methode ist, einfach die einzelnen Worte zu nutzen, also die Eingabe einfach anhand von Leer- und Satzzeichen getrennt. Dann werden die Ergebnisse dieser sogenannten Tokenisierung jeweils Zahlen zugeordnet, meistens ihr Index in einem Set (mit nur eindeutigen Inhalten) oder einer Liste, und die können Machine- und Deep-Learning_Modelle dann verarbeiten. Hie und da werden die Indizes allerdings auch auf Floats zwischen 0 und 1 gemappt, weil manche Modelle damit besser zurecht kommen. Je nachdem können dabei auch Satz- und Leerzeichen mitgenommen werden oder die Strings vor der Verarbeitung in (meist) Lowercase umgewandelt werden. Eine andere Methode sind die sogenannten Word Embeddings. Dabei wird den Worten anhand von ihrer Nähe im Text ein Vektor von Zahlen zugeordnet, und die Nähe der Vektoren bildet dabei die inhaltliche Ähnlichkeit der Token anhand der Häufigkeit ihres gemeinsamen Vorkommens ab. Auf diese Weise können beispielsweise Berechnungen wie "König - Mann + Frau = Königin" durchgeführt werden, wenn die Embeddings korrekt trainiert sind -- dies erfordert allerdings ziemlich große Trainingskorpora und -Zeiten. Die GPT-Modelle verwenden allerdings einen eigenen Tokenizer, dessen Regeln ich bislang nicht durchschaut habe -- sie dürften allerdings auch Ergebnis eines Trainings sein, denn sie haben weder eine feste Länge noch andere (für mich) erkennbare Muster. Du kannst das aber Herausfinden, indem Du selbst einmal damit herumexperimentierst. Alles, was dazu notwendig ist, sind eine Installation von Python und eine des "Transformers"-Moduls von Huggingface, auf der Shell
1 | python -m venv env |
2 | . env/bin/activate |
3 | pip install transformers |
und dann in Python:
1 | #!/usr/bin/env python
|
2 | from argparse import ArgumentParser |
3 | import pandas as pd |
4 | import transformers as trf |
5 | |
6 | if __name__ == '__main__': |
7 | parser = ArgumentParser(description='ChatGPT2 tokenizer') |
8 | parser.add_argument('--save', '-s', help='pickle') |
9 | parser.add_argument('words', nargs='+', help='the words to tokenize') |
10 | args = parser.parse_args() |
11 | |
12 | tokenizer = trf.GPT2TokenizerFast.from_pretrained("gpt2") |
13 | print(tokenizer(' '.join(args.words))) |
Das verwendet den Tokenizer von ChatGPT2, der dem Vernehmen nach derselbe wie jener von ChatGPT3 sein soll. Nebenbei bemerkt, hört sich Deine Anforderung für mich an wie etwas, bei dem man sicherlich einen KI-Ansatz ausprobieren kann, für das ich jedoch auch einen Blick auf Elastic- und / oder OpenSearch empfehlen würde. Das sind sehr leistungsfähige und performante Volltext-Suchmaschinen, die mit entsprechend konfigurierten Input-Pipelines auch direkt Texte aus PDFs lesen und indexieren können, wahlweise über das direkte Auslesen der PDFs oder über eine OCR. Danach wird das PDF zusammen mit den Extrakten in die Suchmaschine eingespeist; die Suche arbeitet dann unscharf (zum Beispiel mit dem Levenshtein- oder dem Damerau-Levenshtein-Algorithmus) und als Ergebnis können die PDFs direkt aus den Treffern zurückgegeben werden. Sowas funktioniert dank der clusteringfähigen Suchmaschinen auch über mehrere Rechner hinweg, wenn die Datenbestände zu groß werden für eine einzelne Maschine. Der große Vorteil ist die unscharfe Suche, die auch dann noch recht gute Ergebnisse liefert, wenn die OCR einzelne Buchstaben nicht korrekt erkannt oder der Ersteller Deines Dokuments eventuell Tippfehler eingebaut hat. Ich habe damit gute Erfahrungen gemacht, aber: YMMV.
Purzel H. schrieb: > KI ist ein nettes Spielzeugt fuer unterbelastete Arbeitskraefte. Der > Aufwand etwas Erwartetes in vernuenftiger Zeit zu erreichen ist nicht > abschaetzbar. Deswegen .. ja macht mal .. allenfalls ist es sogar > lehrreich, bei zu wenig Aufwand kann's auch frustrierend sein. Es ist doch immer wieder spannend, wie wenig Ahnung manche Menschen haben, die sich dann aber trotzdem abfällig zu Wort melden. Zum Glück hat Dieter Nuhr dazu schon das Passende gesagt: "Wenn man keine Ahnung hat [...]". Carypt C. schrieb: > also ich habe ja von programmieren und so keine ahnung, aber ist es > nicht immer so daß eine regex-engine nach den vorgegebenen ausdrücken > sucht. https://de.wikipedia.org/wiki/Regul%C3%A4rer_Ausdruck. Das ist zwar tatsächlich richtig, aber Du hast leider das Thema verfehlt. Hier geht es nämlich nicht um Regular Expressions.
Johnny B. schrieb: > Aus einem PDF lässt sich nicht mehr so genau ermitteln, welche Texte > zusammengehören. Vorallem noch, wenn Text in einer Tabelle untergebracht > ist. Das... kommt darauf an. Mit Software wie dem Python-Paket "pdfplumber" können unter Umständen auch Tabellen recht gut erkannt und ausgelesen werden, aber bei unterschiedlichen Formatierungen ist das schwierig und kaum allgemeingültig machbar. > Ein PDF ist ja eher nur eine optische Repräsentation von einem Dokument > als ein wirkliches Datenaustauschformat. Naja... ich würde sagen: "ein PDF kann [...] sein". > Es ist ähnlich wie wenn Du von einem PCB nur Gerberdaten hast und dann > versuchst, aus diesen wieder die Leiterbahnen, Kupferflächen und > Footprints voneinander zu trennen. > Oder wenn Du eine ausführbare Datei (Maschinencode) hast und aus diesem > wieder C-Code generieren willst. ;-)
Ein T. schrieb: Oh, huch, in meinem letzten Skript ist der Import von Pandas natürlich überflüssig. Das benutze ich in meinem Spielcode nur, um mir auch die jeweiligen Zahlen ausgeben zu lassen, die das Modell für die einzelnen Token zurück gibt. Diese Zeile: >
1 | > import pandas as pd |
2 | > |
... also bitte einfach weglassen, HF.
um jetzt nicht einfach reaktionslos auf die fleißigen antworten zu bleiben , schreibe ich nur so als dankende rückmeldung ; wobei ich auch einfach besser die klappe halten sollte. danke für die erklärungsversuche also den rest einfach vergessen: ok, da war ich zu einfach, danke. ja, was weiß ich überhaupt von computer-learning ? anscheinend geht es von den verschnitt-freien tischlerplatten-zuschnitt-optimierungs-programmen aus, wo nach simplem ausprobieren parkettierungen nach der verschnitt-abfallrate bewertet werden. das überträgt man dann auf andere "themen", die wiederum "parkettiert" und bewertet werden. das problem scheint zu sein die daten-extraktion aus den pdfs in programmanweisungen zu übertragen, die dann ja auch noch ergebnisse in verschiedenen zielsetzungsebenen erarbeiten sollen. aaber den schritt hinzu maschinenverarbeitbareb zahlwerten verstehe ich nicht, deshalb ist für mich ende. allerdings bleibt ja auch die frage: welchen logischen mehrwert soll es den haben einen im text gefundenem zahlenwert einem bestimmten keyword eher zuzuorden. durch logisches denken lassen sich leistungswerte von bauteilen ja nicht unbedingt ergrübeln.
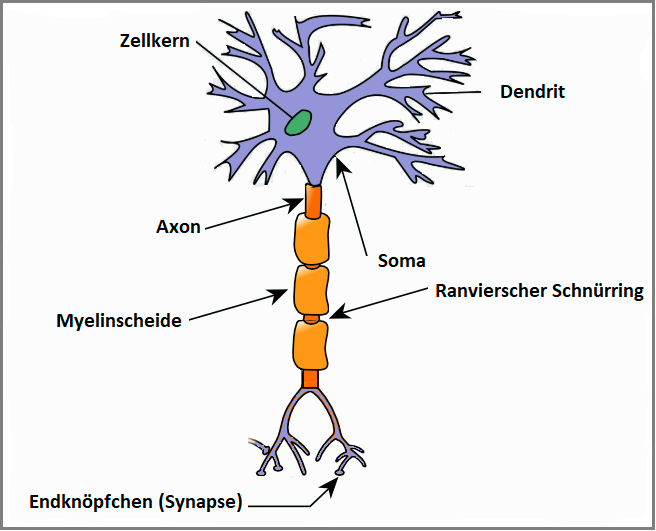
Carypt C. schrieb: Lieben Dank für Deine Antwort. :-) > ja, was weiß ich überhaupt von computer-learning ? > anscheinend geht es von den verschnitt-freien > tischlerplatten-zuschnitt-optimierungs-programmen aus, wo nach simplem > ausprobieren parkettierungen nach der verschnitt-abfallrate bewertet > werden. das überträgt man dann auf andere "themen", die wiederum > "parkettiert" und bewertet werden. Hmmm... ja, nein, vielleicht... > das problem scheint zu sein die daten-extraktion aus den pdfs in > programmanweisungen zu übertragen, die dann ja auch noch ergebnisse in > verschiedenen zielsetzungsebenen erarbeiten sollen. > aaber den schritt hinzu maschinenverarbeitbareb zahlwerten verstehe ich > nicht, deshalb ist für mich ende. Machine- und Deep Learning arbeiten aber nicht mit Programmanweisungen. Ein klassisches Programm hat zwei Eingänge und einen Ausgang; und seine Eingänge sind die Daten und die Regeln, mit denen die Daten verarbeitet werden sollen, um zum Ausgang, also dem Ergebnis zu gelangen. Sowas ist klassische Programmierung: wir legen die Programmanweisungen fest. Bei den modernen Ansätzen aus der Künstlichen Intelligenz ist das aber deutlich anders. Wir geben demselben Programm nur die Daten und unser gewünschtes Ergebnis, und die Regeln, die wir früher selbst entwickeln mußten, die findet das Programm bei seinem Training selbst. Das macht es, indem es die Eingangsdaten und die Ausgangsdaten in seinem Training immer wieder miteinander vergleicht. Dabei seine Funktionen (die Regeln) so anpaßt, daß der vorgegebene Eingang und der gewünschte Ausgang nach jedem Rechenschritt miteinander verglichen, und dahingehend optimiert werden, daß der gegebene Eingang möglichst nah am errechneten Ausgang ist. Die eigentlichen Funktionen in unserem Programm bleiben dabei dieselben, und sind mathematisch sogar sehr einfach. Einzelne künstliche Neuronen in einem Neuronalen Netzwerk bestehen, im Grunde genommen, aus zwei simplen Funktionen mit Parametern. Die erste Funktion ist für die Eingänge zuständig, bei einer Nervenzelle wären das die Dendriten [1]. Jeder dieser Dendriten nimmt in jedem Schritt nur einen einzigen Datenpunkt entgegen, eine Zahl. Diese Zahl wird dann in dem Dendrit mit einem "Gewicht" multipliziert, welches im Modell gespeichert ist. Dann werden die Ergebnisse all dieser Multiplikationen addiert und, je nach Modell, noch eine Verfälschung (der "Bias") hinzu addiert. Das Ergebnis dieser Berechnungen wird dann an die zweite Funktion gegeben, die das Ergebnis dieser einzelnen Zelle ausgibt. Bei einer Nervenzelle wär diese Ausgabe dann eine Synapse. Auch diese zweite Funktion ist einfach, häufig sogar nur eine lineare oder eine Sigmoid-Funktion [2]. Wie lernt denn so ein Machinelearning-Algorithmus denn nun? Wie bereits gesagt, indem die Eingangs- mit den Ausgangsdaten verglichen werden: mit einer Fehlerfunktion, die die Abweichung zwischen den Soll- und Istdaten ausrechnet. Mit dem Ergebnis der Fehlerfunktion wird aber nicht nur die Abweichung zwischen den Eingangs- und Ergebnisdaten berechnet, sondern zusätzlich eine weitere Funktion gefüttert: der Optimierer. Was macht der Optimierer? Der kann ja weder die Funktionen im künstlichen Neuron noch die Ein- und Ausgangsdaten beeinflussen. Also macht er genau das, was er kann: die Gewichte (und eventuell die Biases) anpassen, und damit beeinflußt er das, was aus jedem einzelnen Neuron heraus kommt. Nun ist es so, daß wir bisher nur die Funktion eines einzelnen künstlichen Neurons betrachtet haben. In einem Neuronalen Netzwerk gibt es aber meist sehr viele, sogar bei kleinen Neuronalen Netzen oft sogar schon mehrere Millionen Neuronen, und jedes einzelne davon hat seine eigenen Gewichte (und, je nach Modell, jeweils auch ein Bias). Diese Neuronen sind jeweils miteinander verbunden: die Ausgänge (Synapsen) eines Neurons sind die Eingänge (Dendriten) des nächsten. Haargenau diese Verknüpfungen machen die Fähigkeiten eines Neuronalen Netzwerks aus. Wenn Du es genauer verstehen und selbst nachprogrammieren möchtest, will ich Dir ein Buch empfehlen: "Neuronale Netze selbst programmieren" von Tariq Rashid. Niemand kann diese Dinge so gut erklären wie er, davon bin ich fest überzeugt und meine Ausführungen hier sind eigentlich seine. [1] https://www.studienkreis.de/fileadmin/lernen/assets/courses/media/nerv-ca.png [2] https://en.wikipedia.org/wiki/Sigmoid_function > allerdings bleibt ja auch die frage: welchen logischen mehrwert soll es > den haben einen im text gefundenem zahlenwert einem bestimmten keyword > eher zuzuorden. durch logisches denken lassen sich leistungswerte von > bauteilen ja nicht unbedingt ergrübeln. Das stimmt, aber die Umwandlung von Textteilen in Zahlenwerte ist ja nur die Vorverarbeitung. Neuronen, mithin: Neuronale Netze müssen mit ihren Eingaben und den gewünschten Ausgaben rechnen können, und das ist mit Texten naturgemäß... schwierig. Wenn man also Texte mit einem Neuronalen Netzwerk verarbeiten möchte, dann muß man dem Neuronalen Netzwerk etwas geben, mit dem es Rechnen kann, also kurz gesagt: Zahlen. Es gibt verschiedene Möglichkeiten, Texte in Zahlen umzuwandeln, einige davon habe ich oben ja schon erzählt -- und jede von diesen Methoden hat ihre Stärken und Schwächen... Erschwerend kommt hinzu, daß die Neuronalen Netzwerke, die ich in diesem Beitrag zu erklären versucht habe, nunja... ein bisschen blöd und für die Verarbeitung von Texten nur sehr bedingt geeignet sind. Mit anderen Daten funktionieren die allerdings wirklich oft beeindruckend gut. Aber Texte, vor allem nicht formalisierte Freitexte, stellen noch einmal eine ganz eigene (und, wie ich finde, besonders spannende) Herausforderung dar. Aber da gleiten wir in einen anderen, heute zwar verwandten Teil ab, weil Freitexte -- egal, auf welche Weise man sie aufbereitet -- nunmal nicht standardisiert werden können. Das ist aber ein anderes, hochinteressantes Wissenschaftsgebiet, in das Du Dich bei Interesse gerne bei der Uni zu Hannover [3] einlesen kannst, wenn Du magst. Unter dem Link "Tutorials" dieser Seite findest Du einige spannende Einführungen von Herrn Prof. Dr. Christian Wartena, die ich bei Interesse wärmstens empfehlen möchte. Viel Spaß und Erfolg! Wenn Du Fragen, Ideen oder Anregungen hast, bist Du mir jederzeit herzlich willkommen. Viel Spaß und Erfolg! ;-) PS: Könnten wir uns bitte auf eine halbwegs korrekte Recht-, Groß- und Kleinschreibung verständigen? Normalerweise antworte ich auch solche Beiträge gar nicht, weil mich das Lesen zu sehr anstrengt und ich auch leider zu faul bin, mir einen entsprechenden Filter zu schreiben. Danke. [3] https://textmining.wp.hs-hannover.de/
{kind=link}
aahh. Um bei meiner Materialzuschnitt-optimierung zu bleiben. Es gibt das einfache zufällige Ausprobieren der einzelnen Puzzle-stücke (zeitaufwändig), die Bewertung des Verschnitt-Verlustes, die Neu(-an-)ordnung des Zufalls, sowie das Material vorher und nachher. Die Bewertung des Verschnittes wäre in der künstlichen intelligenz der Vergleich der Ergebnisse mit zB der Normalverteilungskurve (Sigmoid-f.) (Regressionsanlyse, Hinweis eines Freundes) um das Optimum (Zielannäherung) zu finden. Die Neu(-an-)ordnung des Zufalls wäre beim neuronalen Netzwerk die Neugewichtung eines Neurons, bzw der Optimierer. Das Neuron wäre eine evtl mögliche Berechnungsfunktion (Operation-Datentransformation) oder auch ein Puzzle-stück, davon kann es viele Unterschiedliche geben, und die KI-Aktivität probiert einfach viele Möglichkeiten aus(zeitaufwändig). Darf man sagen, daß das Neuron ein Token darstellt ? Soweit interpretiere ich das mal (begreife ich ?). OT (Textmining) die Verabeitung der Bedeutung und Logik von Texten erscheint eigentlich einfach, wären nicht die Doppelbedeutungen von Wörtern. Erfreut sehe ich, daß prof Wartena sich an der Bedeutungsanalyse von Gesetzestexten versucht, das wäre auch das Erste (nach der Philosophie) was ich versuchen würde, leider mangelt mir dazu etwas an intelligenz bzw Kapazität, einfach Fähigkeit. Um nochmal zu den Datenbätter-pdfs zu kommen. Es wären dort quasi zufällige Leistungsdaten (von einer Typengruppe von elektrischen Bauteilen ?) den key-words zuzuorden. Die Plausibilität dieser zuordnung könnte mit Vergleichsdaten (aus dem internet ?) validiert werden, ansonsten müßte das neuronale Netzwerk eine reverse engineering betreiben, quasi einen Bauteil-Design-Algorithmus finden, nur um die Plausibilität der key-value-Beziehung zu bewerten.(viele Token ?) Da erscheint es mir einfacher die Daten in der grafischen Darstellung des pdfs nach der Nähe zu den keys (horizontal und vertikal) zu bewerten. Aber das wurde ja schon erwähnt. ich wollte eigentlich nix mehr sagen, aber Danke für den Unterricht. ps: rechtschreibung und grammatik wird immer versucht. die groß- und kleinschreibung erfordert allerdings das erlernen eines "zweiten" alphabets an der tastatur, das lenkt ab und stört. ich verstehe aber nicht wie man, wenn man bei falscher kleinschreibung probleme des lesens hat, andererseits mit dem lesen englischer texte kein problem haben kann. ich verstehe es als englisches deutsch. aber für die maschinenübersetzbarkeit sowie fremdsprachigen leser mag es korrekter sein konsequente kleinschreibung zu vermeiden, aber es stört weil verkompliziert. verständlicherweise allerdings könnte eine gelernte aversion gegen kleinschreibung vorliegen, aus plausibler dilletantismus-erwartung.
Carypt C. schrieb: > ich verstehe aber > nicht wie man, wenn man bei falscher kleinschreibung probleme des lesens > hat Die Bedeutung eines Satzes kann ohne Gross-/Kleinschreibung völlig ein anderer sein. Beispiel
1 | Helft den armen Vögeln. |
2 | Helft den Armen vögeln. |
klar ist die bedeutung eine andere, aber über die bedeutung muß man sowieso immer nachdenken. es verursacht aber nicht wirklich leseprobleme.
Carypt C. schrieb: > es verursacht aber nicht wirklich leseprobleme. Doch, die Decodierung des Satzes ist bei durchgehender Kleinschreibweise weitaus schwieriger, anstrengender und auch langwieriger. Damit bürdest Du hunderten Deiner Leser eine Last auf, die durch einmalige Arbeit (des Schreibers) zu vermeiden gewesen wäre.
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.