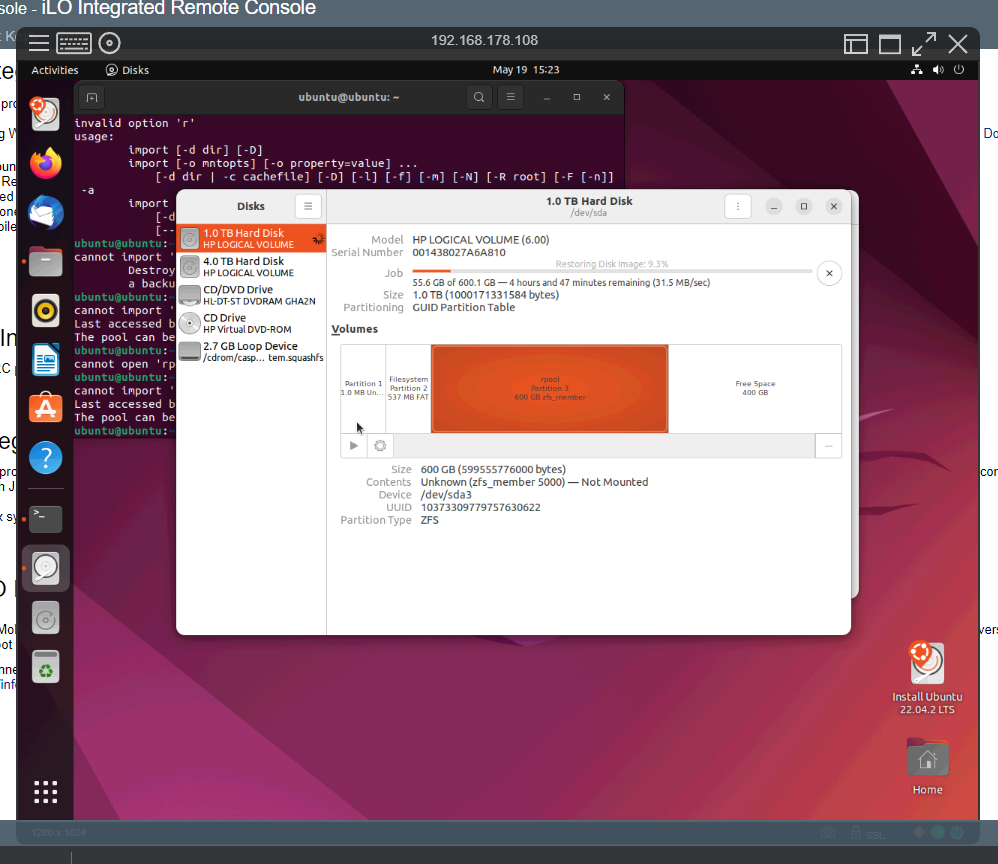
Ich habe hier einen Proxmox Server.
Darin waren 2x 600GB Platten als Raid1 verbaut, welche an ihr Lifetime
Ende kommen - für Das Stammsystem.
Nun wollte ich, Kraft meiner Wassersuppe, neue Platten einsetzen. Backup
dieses Raids wurde immer mit DD gemacht, auch auf einen anderen Rechner.
Also diese Backups liegen vor.
Nun die neuen Platten in den Rechner und mit DD das Image wieder
aufgespielt. Soweit so gut. Der Rechner bootet in Grub und bootet
weiter. Bis dann der Punkt kommt, an dem er das ZFS Volume booten will.
Dort bricht ab und sagt:
1
pool: rpool
2
id: 1858269358818362832
3
state: FAULTED
4
status: The pool metadata is corrupted.
5
action: The pool cannot be imported due to damaged devices or data.
6
The pool may be active on another system, but can be imported using
7
the '-f' flag.
8
see: http://zfsonlinux.org/msg/ZFS-8000-72
9
config:
10
11
rpool FAULTED corrupted data
12
sda3 ONLINE
und bringt mich auf die initramfs commandline. Mit der Flag -f oder -F
sagt er es liege ein I/O Error vor.
Ich lasse gerade mit zpool import -X rpool -F die Platte nochmal suchen.
Gibt es sonst noch einen Tipp, wie ich an die Daten in diesem Pool
komme?
Es gibt zwar noch einen zweiten Server, auf denen das selbe System
gespiegelt wird, dieses wird aber nur einmal im Monat gemacht. Zum 15.
liegt also nun auch wieder vier Wochen zurück.
Für die Zukunft: Wie kann ich ein ZFS Volume sichern um später darauf
wieder ohne Probleme zugreifen zu können? Wäre da ein rsync auf die
Verzeichnissstruktur die bessere Wahl gewesen? Wie kann ich dies in
Zukunft vermeiden?
Rene K. schrieb:> Für die Zukunft: Wie kann ich ein ZFS Volume sichern um später darauf> wieder ohne Probleme zugreifen zu können? Wäre da ein rsync auf die> Verzeichnissstruktur die bessere Wahl gewesen? Wie kann ich dies in> Zukunft vermeiden?
ZFS mit "zfs send" und "zfs receive" sichern.
> Backup dieses Raids wurde immer mit DD gemacht
Scheinbar fehlen dem Backup die Metadaten.
Men koennte den Verbund zum Backup auch um eine Platte erweitern.
Dann wuerden wohl auf der nicht nur ein weiterer Mirror sondern
auch gleich die Metadaten mit abgelegt.
Motopick schrieb:> Die alten Platten wieder in Betrieb zu nehmen waere wohl zu> einfach?
Wenn dies ginge, stünde ich nicht vor dem Problem. :-) Das Raid wurde
schon aus dem Verbund genommen. Eine Wiederherstellung war nicht
erfolgreich.
Motopick schrieb:> Scheinbar fehlen dem Backup die Metadaten.
Ja dies kann sein, aktuell schiebe ich die Sicherung über eine Ubuntu
Live CD noch einmal über die HDD.
Ich weiß das man diese Metadaten auslesen kann.
Da muss ich mich noch belesen. Aktuell läuft der andere Server nun -
halt mit veralteten Daten. Ich bräuchte ja halt wirklich auch nur eine
einzigste Datei aus diesem Pool. :-D
Motopick schrieb:> Men koennte den Verbund zum Backup auch um eine Platte erweitern.> Dann wuerden wohl auf der nicht nur ein weiterer Mirror sondern> auch gleich die Metadaten mit abgelegt.
Wie kann ich dies anstellen? Platten habe ich ja auch noch da. Aber wie
kann ich diese Platte mit zu einem Verbund nehmen?
Motopick schrieb:>> Wie kann ich dies anstellen?>> zpool add
Ich kann ja leider nur über initramfs darauf zugreifen. Wenn ich eine
zweite Platte dazu stecke dann mit dort folgendes tue:
1
zpool create rpool /dev/SDB
2
3
#pool auf der zweiten Platte wird erstellt
4
5
zpool add rpool /dev/sda3 -f
Wird diese Platte zwar zu dem Pool hinzugefügt, aber dieser ist
scheinbar dann leer. Zumindest finde ich nichts, oder habe auch aktuell
keine Ahnung wie ich auf diese Daten dann zugreifen oder mounten kann.
Warum so kompliziert?
Du hättest die beiden neuen Platten einfach mit "zpool add" zum Mirror
hinzufügen und sobald der Pool fertig synchronisiert hat die beiden
alten mit "zpool remove" entfernen können.
Edit: Alternativ "zpool replace"
https://docs.oracle.com/cd/E19253-01/819-5461/gazgd/index.html
Kevin M. schrieb:> Du hättest die beiden neuen Platten einfach mit "zpool add" zum Mirror> hinzufügen und sobald der Pool fertig synchronisiert hat die beiden> alten mit "zpool remove" entfernen können.
Ja, nach meinem jetzigen Wissenstand weiß ich dies nun auch. ☺️ Vorher
dachte ich, ein dd reicht völlig aus. Bei meinen anderen Linux Geräten
ohne ZFS sondern mit EXT4 Dateisystem funktioniert diese vorgensweise
sehr gut.
Foobar schrieb:> Kann es sein, dass du einen dd des laufenden Systems gemacht hast?
Jup, habe ich.
Dann darfst du dich wirklich nicht wundern.
Dd darf man nur dann nehmen, wenn die Partition nur lesend oder gar
nicht eingebunden ist. Das gilt für jedes Dateisystem
Tilo L. schrieb:> Dd darf man nur dann nehmen, wenn die Partition nur lesend oder gar> nicht eingebunden ist.> Das gilt für jedes Dateisystem
Also ich habe hier ein ganz Spezielles mit dem es ganz wunderbar geht.
Nennt sich EXT4. Hat ein Journal. Ein einfaches ›sync‹ vor dem ›dd‹
reicht aus. Nur das, was noch offen ist oder während des ›dd‹ erstellt
wird, ist für's Image verloren.
Ein einfaches ›e2fsck -f‹ nach dem ›dd‹ säubert das Image, entfernt das
›dirty‹ Flag und fertig.
Funktioniert hier regelmäßig, seit vielen Jahren!
Norbert schrieb:> Also ich habe hier ein ganz Spezielles mit dem es ganz wunderbar geht.> Nennt sich EXT4. Hat ein Journal.
Leider totaler Blödsinn.
Das Ext4 haut Dir bloss nicht sofort einen Fehler um die Ohren wenn Du
es im laufenden Betrieb mit DD kopierst - aber die Daten können trotzdem
auf interessante Weise kaputt sein sobald jemand während des DD Laufs
aufs Laufwerk schreibt.
Das hier ist sogar der fiesere Fall, denn Du bekommts das erst später
mit wenn es schief ging.
Norbert schrieb:> Nennt sich EXT4. Hat ein Journal.
Hat nur ein Metadata-Journal. Mit deiner Methode geht das Dateisystem
selbst bei dem Vorgang nicht direkt kaputt, aber was mit deinen Daten
passiert steht in den Sternen.
Wenn du sowas unbedingt machen willst, LVM nehmen, sync&snapshot, dann
dd vom snapshot, anschließend snaphot auflösen.
Ist auch nicht 100%ig, aber minimiert den Zeitraum in dem was schief
gehen kann.
Bei ZFS und BTRFS brauchst du den LVM-Snapshot nicht, da können das die
Dateisysteme selber. Auslesen des Snapshots per (zfs|btrfs) send.
Und, besonders elegant: Du kannst dir nur die Änderungen zwischen zwei
Snapshots rausschreiben lassen. Perfekt für inkrementelle Backups.
Na, dann habe ich ja wohl die vergangenen 10+ Jahre richtig fieses Glück
gehabt und auch die ganzen Journal- und Commit-Optionen völlig
fehlinterpretiert.
Das was mich gerade nur etwas ärgert ist halt einfach die Tatsache - das
ich an keinsterlei Daten mehr gelange. Das Volume ist einfach nur weg -
irreparabel.
Bei einem reinen Dateisystem wie EXT4 wäre dieses Problem nie
aufgetreten.
Gut, da können selbstverständlich einige Daten auch verloren gehen -
welche während des lesens geklonnt werden, aber nicht das komplette
Laufwerke. Ich möchte mir garnicht ausmalen was passiert wenn der
Raid-Controller den Geist aufgibt und ein ganzes Cluster weg wäre -
irreparabel obwohl einzeln abgelegt.
Fakt eins: Der Server ist nun neu aufgesetzt und ich habe kein ZFS mehr
genommen, sonder wieder EXT4.
Norbert schrieb:> Na, dann habe ich ja wohl die vergangenen 10+ Jahre richtig fieses Glück> gehabt und auch die ganzen Journal- und Commit-Optionen völlig> fehlinterpretiert.
Ja. Das Journal sichert nur Metadaten-Operationen aus der Vergangenheit
ab. Da dein "dd" nicht atomar läuft (wie's bei einem Read-Only-Snapshot
der Fall wäre): Alle Änderungen am Dateisystem, die passieren nachdem
dein dd über den Journal-Bereich drübergelaufen ist, sind natürlich
nicht in deiner Journal-Kopie erfasst.
Wenn es anders wäre, müsste das Journal in die Zukunft sehen können:
Ich starte ein "dd", halte es mit Ctrl-Z an, nehme mir fest vor, nächste
Woche eine Datei mit den Lottozahlen als Dateiname anzulegen, und
extrahiere heute den Dateinamen schonmal vorab aus der mit dd angelegten
Journal-Kopie.
Εrnst B. schrieb:> Ich starte ein "dd", halte es mit Ctrl-Z an, nehme mir fest vor, nächste> Woche
Ernsthaft jetzt? Ich weiß ja nicht wie es mit Granitplatten und
Keilschrift geht…
Hier geht's mit den Optionen:
›journal‹, ›journal_dev=‹, ›journal_ioprio=‹, ›commit=‹
Norbert schrieb:
> Na, dann habe ich ja wohl die vergangenen 10+ Jahre richtig fieses Glück> gehabt
Das weißt du ja erst, wenn du versuchst, eine Sicherung wieder
einzuspielen.
> und auch die ganzen Journal- und Commit-Optionen völlig fehlinter-> pretiert.
Nicht nur das. Auch wenn Daten mit im Journal wären, würde das nicht
helfen. Diese absturzsicheren Dateisysteme sind sehr pingelig, was die
Reihenfolge der Schreibzugriffe angeht. Man darf diesen Strom zwar an
einer beliebigen Stelle unterbrechen (Absturz, Stromausfall) und hat
trotzdem noch ein konsistentes Dateisystem, man darf aber nicht wahllos
Zugriffe entfernen. Genau das passiert aber bei einem dd, der eine
Weile dauert.
Beispiel: der dd hat zu einem Zeitpunkt die erste Hälfte der Platte
gesichert. Jetzt wird eine neue Datei angelegt. Erstmal werden die
Daten geschrieben, zufälligerweise in die erste Hälfte der Platte (der
dd bekommt davon nichts mit, diese Schreibzugriffe gehen verloren). Nun
wird das Verzeichnis (liegt in der zweiten Hälfte der Platte)
aktualisiert - zeigt nun auf die neuen Daten. Das wird vom dd später
auch noch gesichert. Ergebnis: das gesicherte Verzeichnis zeigt auf
alten Schrott.
Ernst schrieb:
> Wenn du sowas unbedingt machen willst, LVM nehmen, sync&snapshot, dann> dd vom snapshot, anschließend snaphot auflösen.
Snapshots, egal ob LVM oder auf Filesystemebene bieten auf unterster
Blockebene auch keine Konsistenz. Die Sicherung muß jeweils eine Ebene
höher stattfinden. Bei LVM mag ein dd der Snapshot-Volume gehen, bei
Filesystemsnapshots (z.B. btrfs, zfs) entsprechend auf Dateisystemebene
(rsync/tar/cpio/send).
Noch mein Standardhinweis: Dieses Gehampel mit Snapshots im laufenden
Betrieb ist nur Schlangenöl! Snapshots garantieren keine konsistenten
Anwendungsdaten. Sie stellen nur die Konsistenz des Dateisystems
sicher, nicht die der Anwendungsdaten. Triviales Beispiel: während
gerade ein Archiv erstellt wird, wird mittendrin ein Snapshot gemacht
und der gesichert. Die Sicherung enthält dann ein halb erstelltes und
vermutlich kaputtes Archiv - merkt man aber erst, wenn man versucht, es
zu benutzen.
Ein sicherer Backup geht nur, wenn man das System runterfährt (also alle
Anwendungen stoppt), den Backup macht und dann wieder hochfährt. Mit
Snapshots kann man allerdings die Downtime drastisch reduzieren
(runterfahren, snapshot, hochfahren, backup des snapshots).
Foobar schrieb:> Noch mein Standardhinweis: Dieses Gehampel mit Snapshots im laufenden> Betrieb ist nur Schlangenöl!
Snapshots auf Storage-Ebene beinhalten ein gewisses Risiko auf Ebene der
Daten, sind aber fast immer nutzbar, soweit es die Bootfähigkeit des
Betriebssystem angeht. Technisch unterscheidet sich das nur gering von
Power Loss, und das können Systeme heute ganz gut wegstecken. Eine Image
Kopie des laufenden Inhalts ohne Snapshot, wie es hier ja wohl der Fall
war, ist etwas völlig Anderes.
Das hat auch etwas mit Aufwand zu tun. Ein Storage Snapshot dauert keine
nennenswerte Zeit. Getrennte Datensicherungen ersetzt das nicht, aber
nicht immer sind sie notwendig. Etwa wenn ein System nur durchlaufend
verarbeitet, aber nicht selbst signifikant speichert.
Ich hatte mal so eine ähnliche Situation. 2 Partitionen waren in einem
mdadm Raid 1. Dann ist mir aufgefallen, ich wollte da ja noch eine Swap
Partition da drauf machen. Also habe ich erst mal das Dateisystem auf
dem md verkleinert, und dann mit mdadm noch den Bereich den es nutzt
verkleinert. Dann das raid gestoppt, und die Partition verkleinert.
Wurde nicht mehr erkannt, waren wohl Metadaten irgendwo noch am Ende der
Partition oder so. Aber mdadm --detail sah alles sauber aus... Also alte
Partitionstabelle wieder eingespielt, ging wieder. Aber Partition
grösser / kleiner machen, wollte es einfach nicht. Ich weiss nicht mehr,
welche magischen Optionen ich "mdadm --grow" in welcher Reihenfolge
mitgegeben habe, ich weiss nur noch, ich brauchte mehrere Aufrufe in
unterschiedlicher Reihenfolge, aber irgendwie habe ich es dann doch
hinbekommen, dass es die Metadaten an den richtigen Ort schreibt, und
konnte die Partition dann doch verkleinern.
Ich weiss nicht, wie das mit ZFS ist, aber vielleicht hat das ja auch
Probleme, wenn sich plötzlich die Grösse seines Speicherbereichs
verändert, auch wenn es gross genug wäre?
Bezüglich dd, das während der Verwendung zu nehmen ist natürlich
wirklich schlecht, das stimmt schon. Aber aus FS Sicht das sollte ja
nicht gross anders sein, als ein plötzlicher PC Absturz oder so, wo
nicht alles geschrieben wurde. In so einem Fall würde ich schon
mindestens erwarten, dass man es noch RO mounten kann, immer noch besser
als wenn man gar nicht mehr an die Daten kommt. Einem FS, das gleich
komplett dicht macht, würde ich meine Daten nicht anvertrauen.
Daniel A. schrieb:> Bezüglich dd, das während der Verwendung zu nehmen ist natürlich> wirklich schlecht, das stimmt schon. Aber aus FS Sicht das sollte ja> nicht gross anders sein, als ein plötzlicher PC Absturz oder so, wo> nicht alles geschrieben wurde.
Nein, das ist völlig anders. Heutige Filesysteme sind darauf
eingerichtet, einen schlagartigen Ausfall zu überleben. Nicht aber mit
einer Disk-Kopie eines lebenden Systems zu arbeiten, die hinten eine
halbe Stunde neuer ist vorne.
Rene K. schrieb:> Fakt eins: Der Server ist nun neu aufgesetzt und ich habe kein ZFS mehr> genommen, sonder wieder EXT4.
ZFS ist nicht ohne Grund ein sehr verbreitetes und gerne genutztes
Dateisystem im Serverbereich. Es kann nichts dafür das du es nicht
richtig verwenden kannst.
Ich benutze es schon seit Jahren ohne Probleme bei meinem Home Server
und bei meinem Root.
Foobar schrieb:> Ein sicherer Backup geht nur, wenn man das System runterfährt (also alle> Anwendungen stoppt), den Backup macht und dann wieder hochfährt. Mit> Snapshots kann man allerdings die Downtime drastisch reduzieren> (runterfahren, snapshot, hochfahren, backup des snapshots).
Windows enthält im Rahmen der Volume Shadow Copy Infrastruktur einen
Mechanismus, bei dem ein Snapshot auf Storage-Ebene sich dem
Betriebssystem sowie darauf laufenden Anwendungen ankündigen kann. Damit
können beispielsweise Anwendungen wie Datenbanksysteme sicherstellen,
dass ein Snapshot auch auf deren Ebene konsistent ist. Downtime ist dann
nicht erforderlich.
Dies kennzeichnet quiesced Snapshots in VMware, insoweit die
Anwendungssoftware sich in den VSS einklinkt. Ein Backup-System für
VM-Images, oder ein NAS-System auf dem die Images liegen, kann mit
VMware kommunizieren, um temporäre Snapshots auf diese Art einzurichten.