Moinsen, ich habe einen ESP32 Server, der mit einem anderen ESP32 quasselt. Der Server bietet seine Daten im Format (erster Gedankenschuss!) BEGIN,1245,020523,12.56,28.5,100,200,END Startsignatur, Uhrzeit hhmm, Datum ttmmyy, %.2f float, %.2ffloat, int,int, END sprintf Formatstring ist "%02d%02d%02d,%02d%02d%02d,%.2f,%.2f,%u,%u,END" an, d.h. dieser String erscheint auch auf meinem Handy, wenn ich meine Fritzbox anfunke mit dem Browser. Klar kann man den String auch mühsam zerlegen mit den ganzen String Funktionen, wobei ChatGPT sehr wertvolle Hilfe liefert aber mit sscanf soll das doch besser gehen. Ich weiss nicht mal ob ich die optimale Ausgabe gewäöhlt habe mit den führenden Nullen und dem %u Sieht dann der sscanf Formatstring genauso aus? ich habe es noch nicht programmiert auf einem Test ESP32, wo ich das alles vorher ausprobiere aber ich frage mal vorher..... ist das komma der richtige Dilimeter? Sind die Formate ok? Uhrzeit zerlegen: stunde = zeit / 100; min = zeit % 100; usw. JSON ist einfacher, man muss sich dann auch nicht drum kümmern das zu parsen. ChatGPT erzeugt da klasse Code Snippets, als Eingabe mit ein struct und raus kommt ein json konstrukt. mfrg Thorsten
Thorsten M. schrieb: > ChatGPT Ist das dein neuer Freund/Geliebter? Ich werde nicht mal versuchen, mit der Gehirnprothese zu konkurrieren.
Thorsten M. schrieb: > ist das komma der richtige Dilimeter? D_e_l_i_miter. Welchen Du verwendest, bleibt komplett Dir überlassen. Punkt wäre ungünstig, weil das bei Deinen Float-Zahlen auch der Dezimalpunkt ist. Ja, die Formatstrings von sscanf und sprintf sind sich sehr ähnlich, was Du bei sscanf weglassen kannst, sind Angaben wie Feldbreite oder führende Nullen. Json zu parsen ist deutlich mehr Aufwand (den aber nimmt Dir irgendeine Library ab, die Rechenleistung brauchts trotzdem), dafür aber deutlich sicherer, weil fehlende Elemente/ungültige Zeichen etc. je nach Qualität der verwendeten Library brauchbar abgefangen werden. Wobei helfen "Begin" und "End"? Was spricht dagegegen, einfach einzelne Textzeilen zu verwenden (die also mit CR, LF oder CRLF getrennt werden)?
Harald K. schrieb: > Wobei helfen "Begin" und "End"? > > Was spricht dagegegen, einfach einzelne Textzeilen zu verwenden (die > also mit CR, LF oder CRLF getrennt werden)? Bei gar nichts, wird gar nicht verwendet. Spricht nichts gegen. Macht das was besser? Ich rechne nicht mit Übertragungsfehlern bei tcp/ip.... vermute ich zumindest.
Beitrag #7426044 wurde von einem Moderator gelöscht.
Thorsten M. schrieb: > Spricht nichts gegen. Macht das was besser? Du willst herausfinden, wo der String beginnt, den Du sscanf übergibst. Daher ist eine definierte Trennung einzelner Strings nicht unwichtig. Ein Stringende-Zeichen (CR, LF oder CRLF) macht halt klar, daß jetzt ein vollständiger String empfangen wurde. tcp überträgt üblicherweise einen Bytestrom, d.h. Dein Musterstring > BEGIN,1245,020523,12.56,28.5,100,200,END kann auch durchaus in mehreren Häppchen ankommen: > BEGIN,1245,020523,12.56,28 > .5,100,200,END oder auch mehrere davon hintereinander (je nachdem, wie schnell die Dinger gesendet werden): > BEGIN,1245,020523,12.56,28.5,100,200,ENDBEGIN,1245,020523,12.56,28.5,100 ,200,ENDBEGIN,1245,020523,12.56,28.5,100,200,END
Also was heisst das jetzt? Doch besser so? 1245\r\n 020523\r\n 12.56\r\n 28.5\r\n 100\r\n 200\r\n und mit welchem Format String? Auf dem Handy erscheint immer nur eine Zeile, ich sende mit server.send(200,"text/plain", message); PS: Ein Server kann nicht senden. Der antwortet nur auf die Anfragen des Client. Also immer wenn ich mit dem Finger runter wische, alias F5 wird eine neue URI an den Server geschickt und die Seite wird neu aufgebaut. Da ich kein html verwende sind die Daten maschinenlesbar.
Harald K. schrieb: > Ja, die Formatstrings von sscanf und sprintf sind sich sehr ähnlich, was > Du bei sscanf weglassen kannst, sind Angaben wie Feldbreite oder > führende Nullen. Wenn du aber das Datum 020523 wieder in 3 Variablen speichern möchtest, musst du auch beim scanf die Feldbreite angeben. Besser wäre aber, sich beim Zeitformat an die ISO 8601 zu halten https://de.wikipedia.org/wiki/ISO_8601 Als Trennzeichen bietet sich auch Leerzeichen oder Tabulator an. Die werden von fast allen Formatspecifier am Anfang einfach überlesen.
Thorsten M. schrieb: > Also was heisst das jetzt? Doch besser so? Nein. > 1245,020523,12.56,28.5,100,200\r\n Deine Empfangsroutine empfänge einzelne Zeichen oder Blöcke vom Netzwerk, stoppelt die solange zu einer Zeile zusammen, bis \r\n (o.ä.) empfangen wurde, und ruft dann erst sscanf damit auf.
Dirk B. schrieb: > Besser wäre aber, sich beim Zeitformat an die ISO 8601 zu halten > https://de.wikipedia.org/wiki/ISO_8601 Du kannst auch die Epoch Time als 32 Bit übergeben und das alles mit localtime und mktime beim Empfänger wieder zusammen tüddeln..... Wenn 12.45 Uhr als 1245 zahl übertragen werden also mit atoi zerlegt werden, dann ist zeit.tm_hour = 1245 / 100; zeit.tm_min = 1245 % 100; sehr einfach.
Harald K. schrieb: > empfangen wurde, und ruft dann erst sscanf damit auf. ich weiss nicht was man da stöppeln muss http.begin(serverPath.c_str()); int httpResponseCode = http.GET(); if (httpResponseCode>0) { String payload = http.getString(); holt einfach alles in einen String rein und fertig.
Wenn du einen festen Formatstring hast, musst du bei jeder Erweiterung und auch bei manchen Bugfixes Server und Client gleichzeitig ändern. Das solltest du nur machen, wenn es bei 2 ESPs bleibt. Spätestens, wenn du eine zusätzliche Weboberfläche für die Fehlersuche schreibst, wird dein eigenes Format aufwendig. JSON kodieren und Parsen machst so ein ESP nebenbei.
Thorsten M. schrieb: > String payload = http.getString(); Wenn die dort verwendete Klasse sich darum kümmert, musst Du Dich natürlich nicht selbst drum kümmern. Wurde bislang irgendwo erwähnt, daß Du das Zeug verwendest?
Angehängte Dateien:
-

1685705087326.jpg
400 KB
{kind=link}
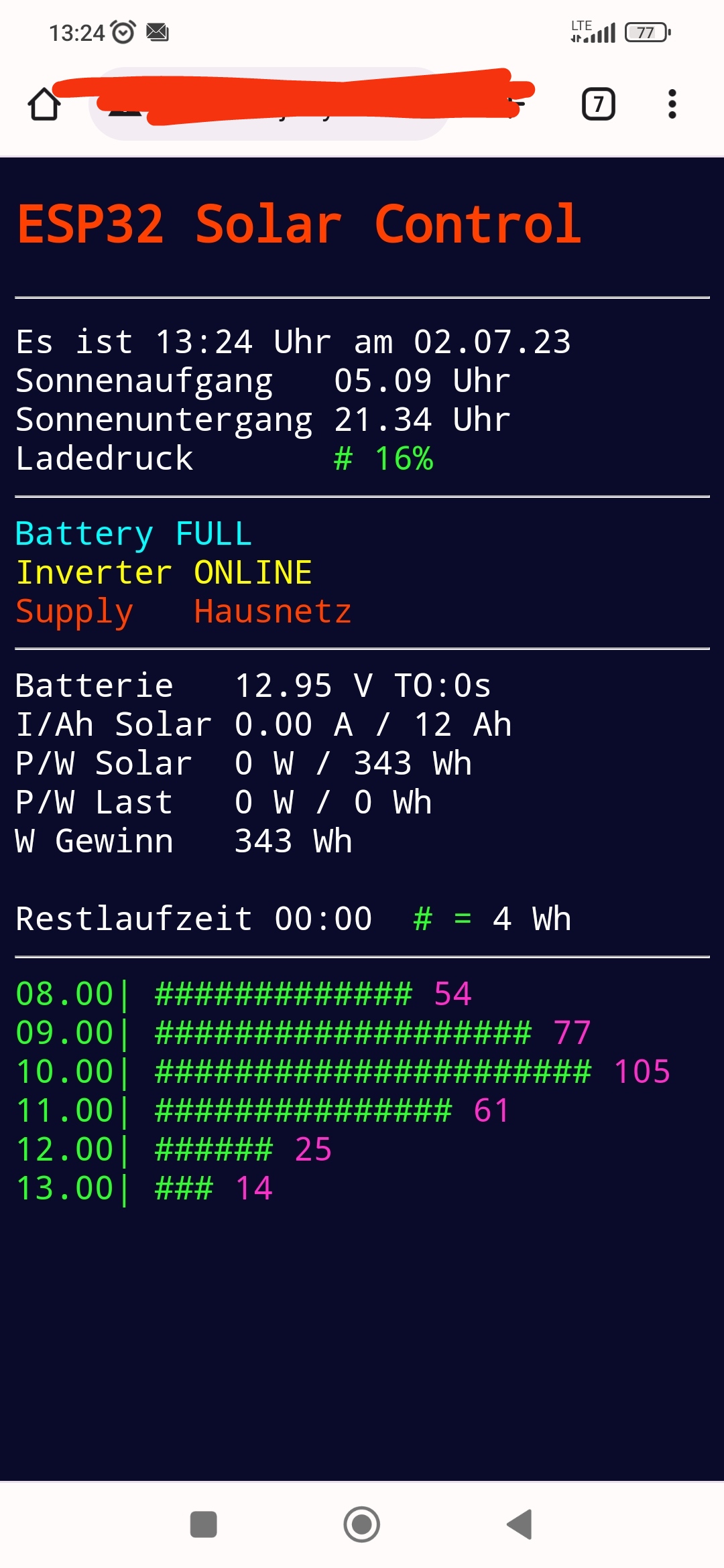
Xanthippos schrieb: > JSON kodieren und Parsen machst so ein > ESP nebenbei. Jupp... bei JSON kann ich den ganzen Struct umwandeln, rüberschieben und den genauso wieder zusammensetzen. Trotzdem muss man bei Änderungen immer beide ändern. Für den Browser habe ich schon alles fertig, in bunt und schön optisch aufbereitet (Monat noch falsch). Jetzt fehlt nur noch ein Display im Wohnzimmer, wo die Daten auf Displays geschickt werden.
> genauso wieder zusammensetzen
Nein, du kannst auch einen Parser nehmen, der ein JSON-Objekt erzeugt.
Hat dann Methoden, mit denen du nachfragen kannst, welche Attribute
vorhanden sind.
Es gibt noch eine einfachere Methode... den ganzen Datenstruct, der zudem noch zwei interne Struct hat als reine Heex-Binärdaten rüberschieben, quasi Intel Hex Format für Flash Brenner. 563df28373f738e20a7b37673... usw und auf der Gegenseite, die die gleiche CPU hat alles zurückbauen in den gleichen Struct. ggf. mit Packed arbeiten. Das geht mit atoi und strncpy ganz einfach. Checksumme hintendran und fertig.
Xanthippos schrieb: > Nein, du kannst auch einen Parser nehmen, der ein JSON-Objekt erzeugt. Vielleicht bin ich ja blöd aber ich erzeuge das alles manuell doc["Strom"] = stromwert, Create JSOnObject Zeit; doc[Data][Zeit]["stunde"] = .... SerializeJSON(....); und auf der Gegenseite das gleiche umgekehrt. Der Struct füllt sich ja nicht von allein.
Viele Wege führen bekanntlich nach Rom. - wenn man leichter debuggen will, dann ist ein "Plain-Text" sicher von Vorteil, aber binäre Daten brauchen weniger Platz - "Plain-Text" kann auch zur Plausibliätsprüfung verwendet werden, Zahlen enthalten keine Buchstaben oder Sonderzeichen - als Delimiter ist ';' üblich, Merkhilfe: De_limiter kommt von Limit (wer noch nie etwas falsch geschrieben hat, der werfe den ersten Stein, aber Hinweise helfen es in Zukunft besser zu machen) - Formatierungsangaben (%02d oder %2d machen nur Sinn, wenn der gesamte Datensatz immer gleich lang sein soll und helfen nur wenn die Platzreserve genügen groß ist (z.B. 4711 braucht mindestens %04d oder %4d) - BEGIN und END bzw. STX und ETX sind nicht notwendig, da die Daten in TCP/IP bzw. UDP/IP eingebettet sind - eine Stunde hat 60 und nicht 100 Minuten, also stunde = zeit_in_minuten / 60; minuten = zeit_in_minuten % 60; - "Plain Text" abstelle von binäre Daten macht Sinn wenn zwischen verschiedenen Rechnerplattformen kommuniziert wird. Stichwort: Byteorder
Thorsten M. schrieb: > BEGIN,1245,020523,12.56,28.5,100,200,END > Startsignatur, Uhrzeit hhmm, Datum ttmmyy, %.2f float, %.2ffloat, > int,int, END Bei Zeit-/Datums-Angaben hält man sich vorteilhafterweise an die ISO 8601. Zusammenfassung (aus https://de.wikipedia.org/wiki/ISO_8601): "Die Norm enthält verschiedene Datums- und Zeitformate, die jedoch rein formal und in den meisten Fällen schon durch die Anzahl der verwendeten Ziffern unterscheidbar sind. Die Norm ist vor allem bekannt für das Datumsformat YYYY-MM-DD, das oft auch als „internationales Datumsformat“ bezeichnet wird. Das üblichste Zeitformat der Norm ist hh:mm:ss. Ein Beispiel für das Datum ist 2004-06-14 (14. Juni 2004) und für die Uhrzeit 23:34:30 (23 Uhr, 34 Minuten und 30 Sekunden) und für beides zusammen 2004-06-14T23:34:30." just my 2 ct
Joe L. schrieb: > Bei Zeit-/Datums-Angaben hält man sich vorteilhafterweise an die ISO > 8601. Welchen Vorteil bietet das? Wenn die Datums-/Zeitangabe in einer Datenbank gespeichert werden soll, d'accord, aber wenn nur zwei µCs miteinander reden, würde das alte Unix-Zeitformat (Sekunden seit 1970) völlig ausreichen, oder eine Abwandlung mit bekanntem festen Offset, damit das Jahr-2038-Problem verzögert wird. So etwas ist erheblich simpler zu parsen (eine Zahl, mehr nicht) und reicht völlig aus, um z.B. zwei Softwareuhren zu synchronisieren.
Harald K. schrieb: > Joe L. schrieb: >> Bei Zeit-/Datums-Angaben hält man sich vorteilhafterweise an die ISO >> 8601. > > Welchen Vorteil bietet das? Wenn die Datums-/Zeitangabe in einer > Datenbank gespeichert werden soll, d'accord, aber wenn nur zwei µCs > miteinander reden, würde das alte Unix-Zeitformat (Sekunden seit 1970) > völlig ausreichen, oder eine Abwandlung mit bekanntem festen Offset, > damit das Jahr-2038-Problem verzögert wird. So etwas ist erheblich > simpler zu parsen (eine Zahl, mehr nicht) und reicht völlig aus, um z.B. > zwei Softwareuhren zu synchronisieren. Und hat zusätzlich den nicht zu unterschätzenden Vorteil, daß Alarmzeitpunkte mit einem einzigen Vergleich erkannt werden können.
Der einzige Nachteil: Es ist halt nicht menschenlesbar, was bei der Fehlersuche etwas lästig sein kann. Aber wie oft will man sich schon das Gelaber von Microcontrollern ansehen?
Harald K. schrieb: > Der einzige Nachteil: Es ist halt nicht menschenlesbar, was bei der > Fehlersuche etwas lästig sein kann. Aber wie oft will man sich schon das > Gelaber von Microcontrollern ansehen? Das wird aber -besonders von Anfänger- vollkommen überbewertet. Der effektive Anteil der menschen-lesbaren Ein- und Ausgaben in einem Programm ist -gemessen an den Taktzyklen- i.d.R. verschwindend gering.
Kommt drauf an, in welcher Häuftigkeit entsprechende Telegramme in einer Kommunikation verwendet werden. Und je nach Schnittstelle kann auch die reine Telegrammlänge relevant sein (hier nicht, hier wird Netzwerk genutzt, aber es gibt ja auch serielle Schnittstellen, die mit ganz erheblich geringeren Datenraten arbeiten). Wenn nur alle paar Sekunden oder gar Minuten so ein Telegramm ausgetauscht wird, ist die für das Erstellen und Zerlegen erforderliche Rechenleistung ziemlich sicher völlig wurscht, wenn aber so etwas mit höherer Datenrate übertragen wird, kann die Angelegenheit schon sehr anders aussehen. Man muss sich also schon auch das Umfeld und das Anwendungsszenario betrachten, bevor man sich für eine bestimmte Lösung entscheidet. Andererseits: eine programmiertechnisch simplere Lösung richtet selten Schaden an, auch wenn es nicht auf Performance, Codegröße o.ä. ankommt.
Harald K. schrieb: > Man muss sich also schon auch das Umfeld und das Anwendungsszenario > betrachten, bevor man sich für eine bestimmte Lösung entscheidet. > Andererseits: eine programmiertechnisch simplere Lösung richtet selten > Schaden an, auch wenn es nicht auf Performance, Codegröße o.ä. ankommt. Nein, das muß man in so einem Fall nicht. Menschen-lesbare Ausgaben sind immer die absolute Ausnahme gemessen am tatsächlichen Programflow. Solche Ausgaben erfolgen maximal nur wenige Male pro Sekunde, und in der Zwischenzeit dreht dein µC Millionen Runden. Das seltene Umstellen in Menschen-lesbare Form fällt da absolut nicht mehr ins Gewicht. Eine zusätzliche Debug-Funktion, die so einen Wert lesbar ausgibt hat man sich auch schnell geschrieben. Mit Unix- oder Epoch-Time lässt sich nun mal ausnahmslos sehr viel besser und effizienter arbeiten. Ausserdem finden sich in der Standardlib auch gleich so praktische Dinge wie die Ermittlung des Wochentags etc.
Harry L. schrieb: > Solche Ausgaben erfolgen maximal nur wenige Male pro Sekunde Wer legt das fest? Ist das irgendwo genormt?
Harald K. schrieb: > Harry L. schrieb: >> Solche Ausgaben erfolgen maximal nur wenige Male pro Sekunde > > Wer legt das fest? Ist das irgendwo genormt? Nicht "genormt", aber unser Auge lässt nun mal nicht mehr zu.
Harry L. schrieb: > Nicht "genormt", aber unser Auge lässt nun mal nicht mehr zu. Das weißt Du, das weiß ich, aber weiß es der unbedarfte Programmierer (oder neudeutsch "Progger"), der sich irgendein Protokoll einfallen lässt?
Harald K. schrieb: > Harry L. schrieb: >> Nicht "genormt", aber unser Auge lässt nun mal nicht mehr zu. > > Das weißt Du, das weiß ich, aber weiß es der unbedarfte Programmierer > (oder neudeutsch "Progger"), der sich irgendein Protokoll einfallen > lässt? Nein, weiss er nicht, und deshalb ist es auch so wichtig, daß die Erfahreneren das erklären.
Harald K. schrieb: > das alte Unix-Zeitformat (Sekunden seit 1970) völlig ausreichen, oder > eine Abwandlung mit bekanntem festen Offset, damit das Jahr-2038-Problem > verzögert wird. Mikrosekunden seit 1.1.1970. Dann braucht man eh 64 Bit, und dann hat man kein 2038-Problem mehr ... LG, Sebastian
Waren nicht die meisten Zeitfunktionen iso8601 kompatibel? Ist schon ein bisschen her, habe auch hin und her geparst, mit der ISO war das nicht mehr viel Arbeit.
Ok,
Schluss mit dem sscanf Zirkus, so sieht es jetzt aus und den Code habe
nicht ich geschrieben sonder ChatGPT mit der Eingabe des Structs als
Input und der Aufforderung die daten zu verpacken. Noch ein wenig dran
herum geschliffen und der Client sieht jetzt ganz sauber das hier und
das steht auch in den Variablen nach dem parsen des Strings.
Und eines begrüsse ich wirklich bei KI wie ChatGPT: Dinge, die man nicht
wirklich verstehen muss, die einfach nur funktionieren sollen, dafür ist
dieses Tool klasse. Denn die Einarbeitung in JSON interessiert mich
überhaupt nicht weil ich das ganz sicher nie wieder nutzen werde oder
nur rudimentär. In einem anderen projekt mit den Wetterdaten musste
JSON5 auf JSON6 portiert werden, auch den Code hat er oder besser es
einwandfrei gemeistert.
{
"UBatt": 26.08999634,
"PLast": 0,
"PSolar": 28.23621559,
"ILast": 0,
"ISolar": 1.082262158,
"AhSolar": 12.04978657,
"WhSolar": 336.913147,
"WhLast": 138.8211365,
"ISolSensorCal": 1.602132797,
"ILastSensorCal": 1.648699164,
"ActualState": 49,
"MinOfDay": 1145,
"Solar": {
"sunRiseMinute": 307,
"sunSetMinute": 1296
},
"Timecode": {
"tm_year": 2023,
"tm_mon": 6,
"tm_mday": 4,
"tm_hour": 19,
"tm_min": 5,
"tm_sec": 33
},
"WhSolarHour": [
1.345246526e-43,
1.401298464e-45,
0,
0,
0,
0,
0,
0,
0
]
}
1:1 Code von ChatGPT
1 | void createJson() { |
2 | StaticJsonDocument<512> doc; // Größe des JSON-Dokuments anpassen, je nach Bedarf |
3 | |
4 | /* JSON Struktur erzeugen */
|
5 | doc["UBatt"] = Data.UBatt; |
6 | doc["PLast"] = Data.PLast; |
7 | doc["PSolar"] = Data.PSolar; |
8 | doc["ILast"] = Data.ILast; |
9 | doc["ISolar"] = Data.ISolar; |
10 | doc["AhSolar"] = Data.AhSolar; |
11 | doc["WhSolar"] = Data.WhSolar; |
12 | doc["WhLast"] = Data.WhLast; |
13 | doc["ISolSensorCal"] = Data.ISolSensorCal; |
14 | doc["ILastSensorCal"] = Data.ILastSensorCal; |
15 | doc["ActualState"] = Data.ActualState; |
16 | doc["MinOfDay"] = Data.MinOfDay; |
17 | |
18 | JsonObject solar = doc.createNestedObject("Solar"); |
19 | solar["sunRiseMinute"] = Data.Solar.sunRiseMinute; |
20 | solar["sunSetMinute"] = Data.Solar.sunSetMinute; |
21 | |
22 | JsonObject timecode = doc.createNestedObject("Timecode"); |
23 | timecode["tm_year"] = Data.Timecode.tm_year; |
24 | timecode["tm_mon"] = Data.Timecode.tm_mon; |
25 | timecode["tm_mday"] = Data.Timecode.tm_mday; |
26 | timecode["tm_hour"] = Data.Timecode.tm_hour; |
27 | timecode["tm_min"] = Data.Timecode.tm_min; |
28 | timecode["tm_sec"] = Data.Timecode.tm_sec; |
29 | |
30 | JsonArray whSolarHour = doc.createNestedArray("WhSolarHour"); |
31 | for (int i = 0; i < 24; i++) { |
32 | whSolarHour.add(Data.WhSolarHour[i]); |
33 | }
|
34 | |
35 | /* JSON Buffer mit Pretty Funktion ausgeben */
|
36 | char jsonBuffer[512]; |
37 | serializeJson(doc, jsonBuffer, sizeof(jsonBuffer)); |
38 | server.send(200, "text/plain",jsonBuffer); |
39 | }
|
Kein Wunder, warum auch für Trivialaufgaben immer fettere Hardware benötigt wird.
Harald K. schrieb: > Kein Wunder, warum auch für Trivialaufgaben immer fettere Hardware > benötigt wird. "Script-Kiddies" eben...
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.