Hi,
Ich habe im Microchip Studio ein Projekt für ATXMEGA64A1U erstellt.
GCC, bzw Toolchain scheint Version 5.4.0 zu sein.
Folgender c/c++ code (optim. -Os):
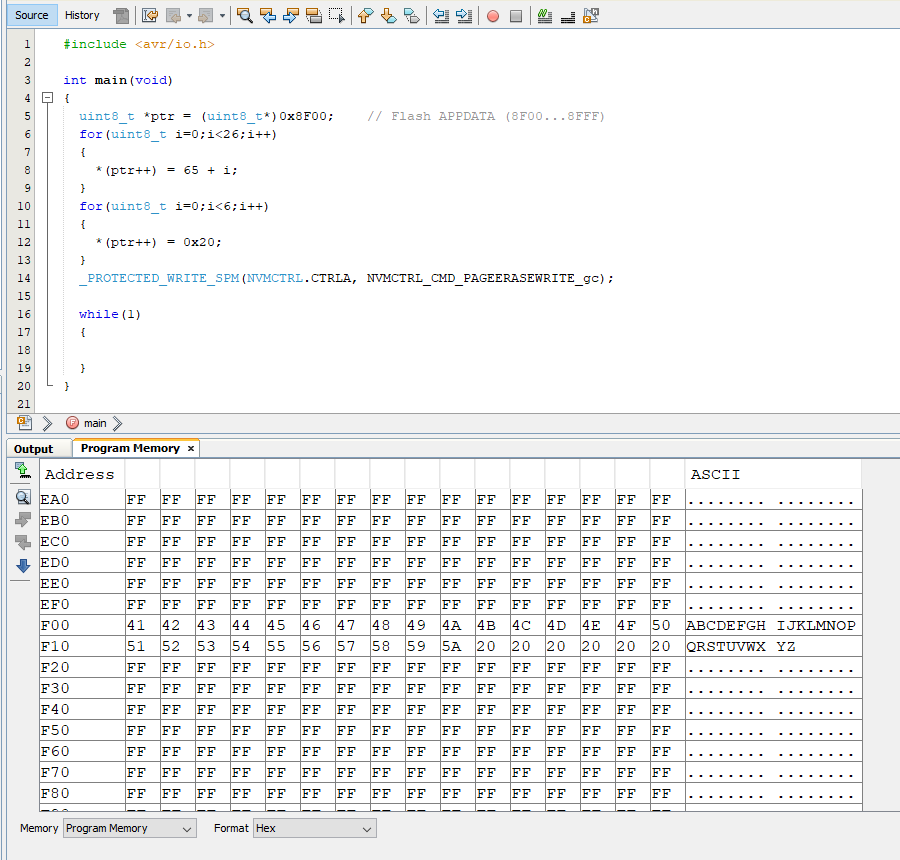
1
Temp=pgm_read_byte(ptr++);
Für nicht dazu, dass der compiler
1
LPMrX,Z+
benutzt.
Gleiches gilt komischerweise auch für pointer im normalen SRAM space.
Zumindest kenne ich *ptr++ also normale C schreibweise für
post-increment.
Gibt es da mittlerweile ein built-in oder sowas, sodass man nicht eigene
asm routinen schreiben muss?
Gab ja mal einen Beitrag, wo jmd einen workaround gepostet hat. Gab
sogar mal ein Bug Report bei GCC selbst, allerdings für mich etwas zu
cryptisch.
Den Report poste ich später, ist aber auch über AVR GCC Bug-Liste zu
finden.
VG
>> benutzt.>> Gleiches gilt komischerweise auch für pointer im normalen SRAM space.
Das kann im Sinne der Optimierung eben auch durchaus die richtige
Entscheidung sein. Insbesondere bezüglich des SRAM-Zugriffs. Bei
Optimierung auf Speed könnte eine abgerollte Schleife tatsächlich (u.U.
sogar deutlich) effzienter sein, wenn sie mit Index+Offset zugreift.
Das kann man aber nur dann beurteilen, wenn Schleifen-Count zur
Compilezeit bekannt und >64 ist. Spätestens dann sollte der Compiler auf
jeden Fall zu der Addressierungsart mit Postincrement umschwenken.
Was den Flash-Zugriff angeht dürfte es sich aber um eine fehlende
Optimierung handeln, denn da geht kein Index+Offset. Ist kein Bug, nur
eben suboptimal. Aber heh: ist Hochsprache, das ist eher selten wirklich
optimal...
Von diesen Compiler-Mankos lebe ich doch. Gäbe es die nicht zu Unmassen,
würde Assemblerprogrammierung ja keinen Spass mehr machen ;o)
Der vom Compiler erzeugte Code benötigt unfaßbare 1 word flash und
irrsinnige 1 cycle Ausführungszeit mehr als mit postinkrement.
Was für eine Anwendung erfordert denn dafür eine eigene ASM-Routine?
Oliver
Wim M. schrieb:> sodass man nicht eigene asm routinen schreiben muss
Weshalb muss man das denn? Funktioniert der Code nicht? Ich meine auch
der zeitliche Rahmen? Oder ist das Flash voll?
Wim M. schrieb:> Gibt es da mittlerweile ein built-in oder sowas, sodass man nicht eigene> asm routinen schreiben muss?
So wie ich das sehe, ist pgm_read_byte() ein Macro, das bereits Inline
Assembler benutzt. Der Compiler kann das gar nicht optimieren, weil er
den Assembler-Quelltext aus dem Macro weitgehend unbesehen einfach in
seinen Assembler-Output einbaut (in der Phase ist er mit seinen eigenen
Optimierungen längst durch).
Wenn das also ein Fehler sein soll (sehe ich nicht), dann höchstens in
der avr-libc.
Markus F. schrieb:> in der Phase ist er mit seinen eigenen> Optimierungen längst durch
Das ist so nicht richtig. GCC asm statements werden in der Optimierung
mitbedacht. Aber natürlich nur soweit es die Schnittstellendefinition,
Constraints und Clobbers erlauben.
Das lpm in ein postinc-lpm umzuformen kann er aber tatsächlich nicht.
Die Optimierung schaut nicht in den Asm-Code selbst rein. Nur in die
Schnittstellenbeschreibung.
MaWin O. schrieb:> Das ist so nicht richtig.
Haarspalterei. Alles, was der gcc hier noch tun kann, ist z.B. ein
Ergebnis verwerfen, wenn es unbenutzt erscheint oder das Inline-Assembly
aus einer Schleife herausziehen, falls das möglich ist. "Echte"
Optimierungen finden da nicht mehr statt.
Aber auch das passiert hier nicht, weil das aus dem Macro expandierte
Inline-Assembly in pgmspace.h _volatile_ spezifiziert ist.
Wim M. schrieb:> Folgender c/c++ code (optim. -Os):> Temp = pgm_read_byte(ptr++);>> Für nicht dazu, dass der compiler> LPM rX,Z+>> benutzt.
Sondern? Was macht er stattdessen?
Ich hab da nicht soo die Ahnung, interessiert mich natürlich daher
umsomehr.
Wim M. schrieb:> Gibt es da mittlerweile ein built-in oder sowas, sodass man nicht eigene> asm routinen schreiben muss?
DAS wäre natürlich die Lösung. Jetzt müsste man nur das Problem dazu
finden.
MaWin O. schrieb:> Das lpm in ein postinc-lpm umzuformen kann er aber tatsächlich nicht.> Die Optimierung schaut nicht in den Asm-Code selbst rein. Nur in die> Schnittstellenbeschreibung.
Ja. Er verändert den Code nicht, sondern lässt ihn höchstens komplett
weg, wenn er an der Stelle laut Schnittstellenbeschreibung keine
Auswirkung auf das Programm hat - und wenn er nicht als volatile
definiert ist.
Markus F. schrieb:> So wie ich das sehe, ist pgm_read_byte() ein Macro, das bereits Inline> Assembler benutzt.
Ja.
Rolf M. schrieb:> ist pgm_read_byte() ein Macro
Ungeachtet vom geschilderten Problem:
Man sollte bei Macros auf Argumente mit gleichzeitigem
Pre-/Post-Increment generell verzichten. Wird ein Argument im Macro
tatsächlich mehrfach genutzt, wird auch mehrfach inkrementiert. Das will
man nicht.
Beispiel:
1
#include<stdio.h>
2
3
#define CHECKSUM(x,y) ((x) * (x) + (y))
4
5
intmain()
6
{
7
inta=2;
8
intb=1;
9
intc=CHECKSUM(a++,b);
10
11
printf("%d\n",c);
12
return0;
13
}
Rätselfrage: Was wird ausgegeben? Und warum?
Da man als Programmierer nicht immer nachschauen möchte, ob man da nun
ein Makro oder eine Funktion aufruft, habe ich es mir prinzipiell
abgewöhnt, Pre-/Post-Increment in Parametern zu verwenden. Das war vor
vielen Jahren noch eine manuelle Anweisung an den damaligen dummen
C-Compiler, hier zu optimieren. Das ist aber heute nicht mehr notwendig
und damit auch obsolet.
Frank M. schrieb:> Rolf M. schrieb:>> ist pgm_read_byte() ein Macro
Ähm, das habe nicht ich geschrieben.
> Ungeachtet vom geschilderten Problem:>> Man sollte bei Macros auf Argumente mit gleichzeitigem> Pre-/Post-Increment generell verzichten. Wird ein Argument im Macro> tatsächlich mehrfach genutzt, wird auch mehrfach inkrementiert. Das will> man nicht.
Das ist bei diesem Makro aber nicht der Fall.
> Rätselfrage: Was wird ausgegeben?
Der Sinn des Lebens - oder gar nichts - oder 42. Alles korrekt.
> Und warum?
Weil wegen UB.
Frank M. schrieb:> Ingo L. schrieb:>> 7, wegen des Postincrements (2) * (3) + 1>> Korrekt :)
Ja, aber jede beliebige andere Antwort wäre genauso korrekt.
> Da man als Programmierer nicht immer nachschauen möchte, ob man da nun> ein Makro oder eine Funktion aufruft, habe ich es mir prinzipiell> abgewöhnt, Pre-/Post-Increment in Parametern zu verwenden.
Die Konvention ist, dass Makros durch GROSSSCHREIBUNG als solche
gekennzeichnet werden. Vielleicht hat man das in diesem Fall bewusst
nicht gemacht, weil es hier kein Problem darstellt.
Ingo L. schrieb:> Rolf M. schrieb:>> Ja, aber jede beliebige andere Antwort wäre genauso korrekt.> Warum?
Weil das Verhalten undefinert ist, wenn man eine Variable ohne
dazwischen liegenden Sequenzpunkt mehr als einmal ändert. Und
undefinertes Verhalten heißt, dass beliebiges passieren darf.
(a++) * (a++) ändert a zweimal, ohne dass ein Sequenzpunkt dazwischen
ist.
Rolf M. schrieb:> Die Konvention ist, dass Makros durch GROSSSCHREIBUNG als solche> gekennzeichnet werden.
Leider wird zu oft diese Konvention nicht eingehalten. Von daher würde
ich es nicht darauf ankommen lassen. Es ist sogar so, dass mit Hilfe von
Conditional Compilation von der libc oft zu Funktionen alternative
Makros aus Performancegründen angeboten werden, siehe z.B. ctype.h.
> Vielleicht hat man das in diesem Fall bewusst> nicht gemacht, weil es hier kein Problem darstellt.
Das ist lediglich eine Vermutung. Ich würde nicht drauf wetten.
Axel R. schrieb:> Sondern? Was macht er stattdessen?> Ich hab da nicht soo die Ahnung, interessiert mich natürlich daher> umsomehr.
Ausprobieren und selber nachschauen sollte doch Motivation genug sein
bei einem „interessiert mich natürlich daher umsomehr“.
Oliver
Eine Frage vorweg:
Sind auf diesem Forum eigentlich 99% der Trolle Deutschlands unterwegs
oder einfach nur schlecht gelaunt? Verglichen zu englisch-sprachigen
Foren sind deu. Foren auf ner Skala von 1-10 leider 12...und zwar
toxisch. Ahnung scheint ihr ja aber auch nicht zu haben, oder teilt sie
nicht, weil der Stolz ebenso bei 12 ist. Wie halten seriöse Menschen das
hier auf dem Forum nur aus?
Zurück zum Thema:
Danke and MaWin:
MaWin O. schrieb:> Das lpm in ein postinc-lpm umzuformen kann er aber tatsächlich nicht.> Die Optimierung schaut nicht in den Asm-Code selbst rein. Nur in die> Schnittstellenbeschreibung.
Ja genau, deshalb ja kein "Z+". Deswegen alternative zu Marko oder
eigener ASM.
Danke auch an den Ein oder Anderen für eine vernünftige Antwort!
Die restlichen Antworten haben leider nichts mit meiner Frage zu tun.
Die Alternative habe ich jetzt auch gefunden:
__flash mit -std-gnu99.
Hier ein Beispielcode, der "Z+" mit Optimierung -Os erzeugt:
1
#include<avr/io.h>
2
#include<avr/pgmspace.h>
3
4
constchar__flashstring[16]="Hello world!";
5
6
intmain(void)
7
{
8
volatilecharfoo;
9
__flashconstchar*ptr=string;
10
11
for(uint16_ti=0;i<16;++i)
12
{
13
foo=*(ptr)++;
14
// oder:
15
// foo = string[i]; // (erzeugt gleichen asm)
16
}
17
18
19
while(1);
20
}
Allerdings programmiere ich lieber mit einem C++ Projekt. Dort müsste
ich das dann in extern "C" packen? Nur "checkt" der Compiler "__flash"
irgendwie nicht, obwohl der C-Compiler -std-gnu99 gesetzt hat. Was hab
ich vergessen?:
1
extern"C"
2
{
3
constchar__flashstring[16]="Hello World!";
4
};
Comp. Error: "expected initializer before 'string'"
Wenn ich __flash an eine andere Stelle setzte (davor):
Error: "'__flash' does not name a type"
Wen der Thread zum Compiler-"Bug" interessiert: (geht aber nicht primär
um 'lpm')
siehe
https://www.mikrocontroller.net/articles/Avr-gcc_Bugs
siehe
https://gcc.gnu.org/bugzilla/show_bug.cgi?id=81611
VG
EDIT:
achso ja, die Post-Increment-Pointer für SRAM wurden mit sicherheit
wegoptimiert.
Im obigen Beispiel optimiert der Compiler "Z+" bei for-Schleife "i<5"
auch weg.
Wim M. schrieb:> Nur "checkt" der Compiler "__flash"> irgendwie nicht, obwohl der C-Compiler -std-gnu99 gesetzt hat. Was hab> ich vergessen?:
__flash kennt nur der C-Compiler, aber nicht der C++-Compiler. Auch weil
du da extern C hinschriebst, wird die Zeile nicht mit dem C-Compiler
compiliert.
Oliver
Wim M. schrieb:> Sind auf diesem Forum eigentlich 99% der Trolle Deutschlands unterwegs
Das dachte ich als erstes, als ich deinen Nicknamen laß.
Zum Thema: Du könntest ein eigenes kleines C-Modul mit den
Flashzugriffen schreiben, welches du dann zum C++ Rest dazulinkst.
Ich hatte ja oben schon gefragt, weshalb es dir auf eine Instruktion
ankommt. Scheint aber ein großes Geheimnis zu sein? Solch
Mikrooptimierung ist in der Regel "Unsinn" und hilft im ernsthaften Fall
nur sehr selten weiter. Die Fehler liegen meistens woanders.
Oliver S. schrieb:> Der vom Compiler erzeugte Code benötigt unfaßbare 1 word flash und> irrsinnige 1 cycle Ausführungszeit mehr als mit postinkrement.
Es sind zwei Zyklen. Siehe ISRM->adiw
Und natürlich fällte der Zusatzaufwand in jeder Iteration einer Schleife
an, was wohl in der überwiegenden Zahl der Fälle für Flashzugriffe der
Normalfall sein dürfte. Und dann summiert sich der Mehrbedarf leicht
merklich auf.
Noch störender ist das bei SRAM-Zugriffen, denn auf neueren AVR8 kosten
die in vielen ADressierungsarten nur noch einen Takt. Sprich: der
Overhead durch die unnütze Zusatzinstruktion beträgt dann satte 200% des
Aufwands für den Nutzcode. Beim Flash-Zugriff (3 Takte) sind's "nur"
67%.
C-hater schrieb:> Es sind zwei Zyklen. Siehe ISRM->adiw
Da widersprechen sich die verschiedenen Versionen des Instruction Set
manuals, aber die aktuellste schreibt tatsächlich 2, was auch irgendwie
zu vermuten ist.
Olivet
C-hater schrieb:> Sprich: der> Overhead durch die unnütze Zusatzinstruktion beträgt dann satte 200% des> Aufwands für den Nutzcode.
Unter der Voraussetzung, dass du die Werte nur liest und dann verwirfst,
ohne was damit zu machen. Sobald du sie auch nutzt, wird sich der
Prozentsatz mehr oder weniger weit, aber in der Regel sehr deutlich,
verringern.
Wim M. schrieb:> Nur "checkt" der Compiler "__flash" irgendwie nicht, obwohl der> C-Compiler -std-gnu99 gesetzt hat. Was hab ich vergessen?:
Dass es __flash bei C++ nicht gibt.
Wim M. schrieb:> Für nicht dazu, dass der compiler>> LPM rX,Z+>> benutzt.
Das liegt einfach daran, dass dein pgm_read_byte() Inline-Assembler-Code
ist, bei dem der Compiler zwar die Parameter optimieren kann, aber nicht
die Assemblerbefehle selbst.
Oliver S. schrieb:> Da widersprechen sich die verschiedenen Versionen des Instruction Set> manuals
Ist das so? Ich habe noch keins gesehen, in dem adiw mit einem Takt
spezifiziert gewesen wäre.
Kannst du mal ein Beispiel zeigen?
MaWin O. schrieb:> Kommt halt immer darauf an.> Wenn das Programm funktioniert, warum dann optimieren? Um nun 50% statt> 60% der CPU-Leistung zu nutzen?
Das ist nicht der Punkt. Der Punkt ist:
Wenn das Programm nicht optimiert halt 105% der verfügbaren
Rechenleistung benötigt, optimiert aber nur 95%.
Dann mach das nämlich den Unterschied zwischen "geht" und "geht nicht"
aus.
Capisce, stupido?
Jörg W. schrieb:> Dass es __flash bei C++ nicht gibt.
Warum eigentlich nicht?
__flash ist zwar auch noch nicht das "Gelbe vom Ei", aber doch immerhin
schon deutlich besser als die pgm-Geschichte.
Besser übrigens nicht nur bezüglich der möglichen Optimierungen, sondern
auch rein syntaktisch "logischer". Natürlich nur soweit man bei C/C++
überhaupt von einer Logik der Syntax sprechen kann...
Hi,
Oliver S. schrieb:> Wim M. schrieb:>> Nur "checkt" der Compiler "__flash">> irgendwie nicht, obwohl der C-Compiler -std-gnu99 gesetzt hat. Was hab>> ich vergessen?:>> __flash kennt nur der C-Compiler, aber nicht der C++-Compiler. Auch weil> du da extern C hinschriebst, wird die Zeile nicht mit dem C-Compiler> compiliert.>> Oliver
Ja dann muss ich mir das mal anschauen, wofür EXTERN genau da ist, bzw.
wie man halt C in C++ implementiert. Danke soweit.
Für mich ist das Thema erledigt damit.
VG
__flash ist ein named address space, und das Konzept gibt es nur in C,
nicht in C++. Daher kennt g++ das nicht, und du kannst es ihm auch nicht
durch die Hintertür beibringen.
Oliver
Oliver S. schrieb:> https://ww1.microchip.com/downloads/en/devicedoc/atmel-0856-avr-instruction-set-manual.pdf
Interessantes Teil. Wo hast du denn das her?
In den Changes taucht nicht einmal adiw/sbiw auf. D.h.: das Dokument
meinte offiziell auch in allen Vorfahren, dass adiw/sbiw nur einen Takt
benötigt.
Dem ist aber nachweislich nicht so.
Also: du hast wohl die einzige fehlerhafte Spezifikation aus 20 Jahren
rausgefischt. Und zwar sehr wahrscheinlich eine, die offiziell niemals
hätte zugänglich sein dürfen. Denn sonst hätte die entsprechende
Korrektur wiederum in der nächsten Version erscheinen müssen...
Das tat sie aber nicht.
MC hat sich die Sache jetzt übrigens viel einfacher gemacht.
Nachvollziehbare Changes gibt es einfach nicht mehr...
Rotz, wie er von MC nicht anders zu erwarten war...
C-hater schrieb:> Also: du hast wohl die einzige fehlerhafte Spezifikation aus 20 Jahren> rausgefischt. Und zwar sehr wahrscheinlich eine, die offiziell niemals> hätte zugänglich sein dürfen.
Nicht ich, sondern Google. Das war halt die nöchstbeste, die ich „mal
eben schnell“ zum nachschauen aufgemacht habe. Wo die herkommt, keine
Ahnung.
Oliver
Rolf M. schrieb:> Unter der Voraussetzung, dass du die Werte nur liest und dann verwirfst,> ohne was damit zu machen. Sobald du sie auch nutzt, wird sich der> Prozentsatz mehr oder weniger weit, aber in der Regel sehr deutlich,> verringern.
Natürlich. Es bleibt aber: Es ist (mehr oder weniger deutlich)
suboptimal.
Nur für Leute, die ernsthaft glauben, ein Compiler macht alles optimal,
eine kaum glaubhafte Überraschung...
Ich denke mal, du gehörst genau so wenig zu diesem Personenkreis wie
Oliver S. Warum, zum Teufel fällt es euch dann so schwer zu sagen: Ja,
das geht besser? Und zu sagen: Ja, in Asm kann man es besser machen?
Wenn jeder der kompetenten Leute bereit wäre, diese offensichtliche
Wahrheit auch genauso offen zuzugeben, wäre diese ewige Diskussion doch
praktisch beendet.
Die wird immer nur wieder von den Bibeltreuen angeheizt, die eben immer
wieder und gegen jede Vernunft und gegen offensichtliche Fakten
unverbrüchlich und wiederholt behaupten: Der Compiler macht das schon
alles perfekt. Nein, das tut er eben nicht.
C-hater schrieb:> Nur für Leute, die ernsthaft glauben, ein Compiler macht alles optimal,
Niemand hat das jemals geglaubt.
> Und zu sagen: Ja, in Asm kann man es besser machen
Das war jedem hier im Thread vom Anfang an klar.
Das Thema des Threads ist aber AVR-GCC, nicht AVR-ASM.
> Wenn jeder der kompetenten Leute bereit wäre, diese offensichtliche> Wahrheit auch genauso offen zuzugeben, wäre diese ewige Diskussion doch> praktisch beendet.
Nein, ganz und gar nicht.
Asm statt C zu nehmen löst kein einziges Problem des C-Optimierers.
Es ist lediglich ein Workaround.
C-hater schrieb:> Und zu sagen: Ja, in Asm kann man es besser machen?
Weil es nicht stimmt.
Der Fehler liegt nicht in der Sprache C sondern wie jemand das Macro
implementiert hat. Und mit __flash in C funktioniert es ja
offensichtlich auch mit dem Compiler.
C-hater schrieb:> ein Compiler macht alles optimal,
Wie ich oben schon schrieb: der Compiler hat halt hier gar keine Chance
– eben weil es sich dabei um (inline) Assembler-Code handelt, den er
natürlich nicht verändern darf.
Mit __flash hat er dagegen die Chance – und nutzt sie auch
C-hater schrieb:> Ich denke mal, du gehörst genau so wenig zu diesem Personenkreis wie> Oliver S. Warum, zum Teufel fällt es euch dann so schwer zu sagen: Ja,> das geht besser? Und zu sagen: Ja, in Asm kann man es besser machen?
Da du mich ja direkt ansprichst, also dann: ja, man kann da in ASM 2
Zyklen sparen. Bestreitet niemand.
Eine sicherlich typische Anwendung wäre jetzt z.B eine CRC-Berechnung
übers ganze Flash. Was bei den 64kB des Prozessors, um den es hier geht,
dann 128k verschwendete Zyklen ergibt. Bei schnarchlangsamen 1Mhz sind
das 0.13s, bei 16Mhz halt 1/16 davon.
Wenn das für eine Anwendung funktionsentscheidend ist, muß man das in
ASM basteln, wenn nicht, dann nicht.
Dafür musst due jetzt hier wirklich nicht den Moby machen.
Oliver
Handgeschriebenen (in diesem Fall Inline-, aber nichtsdestotrotz
handgeschriebenen), suboptimalen Assembler-Code als Beweis für die
unanfechtbare Überlegenheit von Assembler gegenüber Compiler-generiertem
Code zu verargumentieren, entbehrt nicht einer gewissen Komik, ehrlich.
Ja, man kann mit Assembler oft den besseren Code schreiben. Wenn man's
kann.
Man kann das aber (offensichtlich) auch so verbissen sehen, dass man den
Wald vor Bäumen nicht mehr erkennt.
Markus F. schrieb:> Handgeschriebenen (in diesem Fall Inline-, aber nichtsdestotrotz> handgeschriebenen), suboptimalen Assembler-Code als Beweis für die> unanfechtbare Überlegenheit von Assembler gegenüber Compiler-generiertem> Code zu verargumentieren, entbehrt nicht einer gewissen Komik, ehrlich.
Ja, ich stimme dir für voll zu :)
Oliver S. schrieb:> Wenn das für eine Anwendung funktionsentscheidend ist, muß man das in> ASM basteln, wenn nicht, dann nicht.
Wäre lustig, wenn die angesprochene langsame Funktion nicht schon in ASM
wäre.
(prx) A. K. schrieb:> Die ASM vs C Diskussion flammt immer wieder auf, immer mit C-hater als> Verfechter vom ASM, und ist immer sinnlos.
Und dabei wissen wir doch alle, dass sowohl C als auch Asm auf den
Müllhaufen der Geschichte gehören. Vernünftige Entwicklung kann im Jahr
2023 nur mit Rust stattfinden. ;)
MaWin O. schrieb:> Vernünftige Entwicklung kann im Jahr> 2023 nur mit Rust stattfinden. ;)
Ob ein Produkt bzw. eine Programmiersprache eine GLÄNZENDE Zukunft hat,
das sich Rost nennt, wage ich zu bezweifeln ;-)
MaWin O. schrieb:> Und dabei wissen wir doch alle, dass sowohl C als auch Asm auf den> Müllhaufen der Geschichte gehören.
Man könnte so weit gehen, C, C++ und ASM als Vogelschiss der Geschichte
zu bezeichnen.
Jörg W. schrieb:> Mit __flash hat er dagegen die Chance – und nutzt sie auch
Du hältst also __flash für der Weisheit letzten Schluß?
Bitte, bitte, sag' ja!!!
Cyblord -. schrieb:> MaWin O. schrieb:>> Und dabei wissen wir doch alle, dass sowohl C als auch Asm auf den>> Müllhaufen der Geschichte gehören.>> Man könnte so weit gehen, C, C++ und ASM als Vogelschiss der Geschichte> zu bezeichnen.
Dem würde ich mich anschliessen. Das Problem ist eben einfach nur, dass
es Targets gibt, deren Resourcen für den Overhead wirklich brauchbarer
Programmierprachen unzureichend sind.
Und die programmiert man in C/C++, wenn das Speichermodell dieser
Sprachen wenigstens annähernd passt, ansonsten halt sinnvollerweise eher
doch in Assembler. Was halt bei den AVR8 mit Harvard-Architektur,
mehreren Adressräumen, diversen Mappings(incl. Banking) zwischen diesen
Adressräumen die einzige logische Entscheidung eines wirklich
kompetenten Programmierers sein kann.
MaWin O. schrieb:> C-hater schrieb:>> Du hältst also __flash für der Weisheit letzten Schluß?>> hä?
Was ist dein Problem? Hast du noch nie was von __flash gehört oder sind
dir nur die Grenzen nicht bewußt?
Hinweis: Das ist (in erster Näherung für Blöde) einfach ein anderes
"API" für den Zugriff auf Daten im Flash. Eine Alternative zu dem
elenden "progmem"-Zeugs.
C-hater schrieb:> Eine Alternative zu dem> elenden "progmem"-Zeugs.
Verdammt, vergessen zu erwähnen: eine deutlich bessere Alternative. Aber
immer noch: far away from to be perfect.
C-hater schrieb:> Hast du noch nie was von __flash gehört
Ja doch. Aber wer soll denn behauptet haben
> Du hältst also __flash für der Weisheit letzten Schluß?
?
Niemand hat auch nur annähernd sowas gesagt. Das basiert nur auf deinem
Beißreflex
> far away from to be perfect.
Ja, wir wissen ja, dass nur Asm perfekt sein kann, nach deiner
Definition.
Falk B. schrieb:> C-hater schrieb:>> immer noch: far away from to be perfect.>> Done is better than perfect!
No way. Done perfectly without the need to use such strange workarounds
is perfect. I did it. Many times.
And you could do so. If you want. You only must want to be perfect and
learn how to to it and proceed...
The joke is: in many times it is much more simple to do it in in asm
than in C/C++. Especially of course for "C-inkompatible" targets like
AVR8.
MaWin O. schrieb:> Ja, wir wissen ja, dass nur Asm perfekt sein kann, nach deiner> Definition.
Nicht nach meiner Definition, sondern nach den Grungesetzen der
Informatik. Das ist ein himmelweiter Unterschied, der dir aber
anscheinend nicht wirklich klar ist. (Aber klar sein sollte!)
C-hater schrieb:> Nicht nach meiner Definition, sondern nach den Grungesetzen der> Informatik. Das ist ein himmelweiter Unterschied, der dir aber> anscheinend nicht wirklich klar ist. (Aber klar sein sollte!)
Die Grundgesetze der Logik sagen mir, dass ein Compiler, der optimalen
Asm-Code ausgibt, optimal ist.
Welches Grundgesetz der Informatik dagegen sprechen sollte, bleibt wohl
dein Geheimnis.
MaWin O. schrieb:> Die Grundgesetze der Logik sagen mir, dass ein Compiler, der optimalen> Asm-Code ausgibt, optimal ist.
Neeeiiiin.
Optimal wäre er, wenn er das immer und unter allen Umständen tun würde.
Davon ist aber jeder existierende Compiler sehr weit weg. Der avr-gcc
natürlich auch. Allerdings (das muss man wohl auch mal sagen): nicht
viel weiter als die kommerzielle Konkurrenz, manchmal ist er sogar näher
dran am Optimum.
C-hater schrieb:> Davon ist aber jeder existierende Compiler sehr weit weg.
Darüber habe ich keine Aussage getroffen.
Pack deinen Beißreflex mal wieder ein.
Du warst derjenige, der hier mit Informatiker-Theorie angefangen hat.
C-hater schrieb:>> Done is better than perfect!>> No way. Done perfectly without the need to use such strange workarounds> is perfect. I did it. Many times.
Not the point.
https://en.wikipedia.org/wiki/Overengineering
Perfection is a dangerous illusion, especially in engineering!
C-hater schrieb:> Davon ist aber jeder existierende Compiler sehr weit weg
Jeder real existierende Assemblerprogrammierer mit real existierendem
Zeitbudget für real große Projekte allerdings auch. ;-)
{kind=link}