DSGV-Violator schrieb:> Nichtmal die benutzte Programmiersprache, Compiler oder µC haste> genannt.
Oder wenigstens, was denn passieren soll und wie sich dann das "nicht
klappen" bemerkbar macht.
Allerdings eine Frage hätte ich an den TO: Was denkst du, was
> tut?
-s>8 - Hochzählen, bis der Wert 8 erreicht ist.
-v==B00000001 - Bit schieben, bis B00000001 erreicht ist.
Der soll von der oberen linken Ecke bis zur unteren rechten Ecke,
diagonal, den Punkt bewegen. Das Display ist ein 8x8 von Max7219:
B10000000
B01000000
B00100000
B00010000
B00001000
B00000100
B00000010
B00000001
Der Ausdruck x,y als Bedingung ist, was das Ergebnis angeht, mit y
identisch. Der x Term ist also wirkungslos.
Zudem ist das im for() eine while-Bedingung, kein until.
Bitte noch einmal auf Deutsch :D
Wenn ich nur s nutze, funktioniert es. Bloß nicht mit der Ergänzung.
B10000000
B10000000
B10000000
B10000000
B10000000
B10000000
B10000000
B10000000
Die Kenntnisse sind da! Nur fehlt mir aktuell noch die Übung, alles, in
der jeweiligen Situation, auch richtig zu nutzen.
Danke. Leider funktioniert es so nicht:
Tim schrieb:> Die Kenntnisse sind da! Nur fehlt mir aktuell noch die Übung, alles, in> der jeweiligen Situation, auch richtig zu nutzen.
Falls du es noch nicht gemerkt hast: Manche versuchen, dich in die
richtige Richtung zu lenken, statt dir ein fertiges Programm zu
servieren. Denken lernen bringt mehr als abschreiben.
(prx) A. K. schrieb:> statt dir ein fertiges Programm zu> servieren.
Das erwarte ich auch nicht. Offensichtlich hatte ich nur zwei Zeichen
vergessen. Das würde ich nicht ein fertiges Programm nennen
Tim schrieb:> Offensichtlich hatte ich nur zwei Zeichen vergessen.
Echt jetzt: "nur"?
Tim schrieb:> Die Kenntnisse sind da!
Du hast offensichtlich ganz grundlegend die verwendeten Operatoren nicht
verstanden. Und deshalb wirst du solche simplen Anfängerfehler völlig
unbedarft wieder machen, weil du "nur" irgendwas "nur" irgendwie machst.
Tim schrieb:> Bitte noch einmal auf Deutsch :D
Der Kommaoperator macht nicht das, was du dir denkst.
Besonders nicht bei (Abbruch-)Bedingungen.
Dort gehören komplette logische Verknüpfungen mit && bzw. || hin.
Tim schrieb:> Dann wäre ein Forum überflüssig, wenn ich nicht irre ;)
Viel besser: zum Aneignen solcher grundlegenden Kentnisse gibt es
Tutorials. Und jetzt mach dich zum Thema "Kommaoperator" schlau, da ist
auf jeden Fall Nachholbedarf.
Tim schrieb:> Die Kenntnisse sind da! Nur fehlt mir aktuell noch die Übung, alles, in> der jeweiligen Situation, auch richtig zu nutzen.
"v >> 1" macht was gleich noch mal?
Tipp: Dein Namensvetter Tim Peters, ein begnadeter Software Ingenieur
hatte schon vor einen 1/4 Jahrhundert das "Zen of Python" formuliert. Du
verstößt mit deinen wenigen Zeilen Code zumindest gegen die ersten 7
Regeln.
- Beautiful is better than ugly.
- Explicit is better than implicit.
- Simple is better than complex.
- Complex is better than complicated.
- Flat is better than nested.
- Sparse is better than dense.
- Readability counts.
just my 2ct
Den Kommaoperator sollte man nie ohne große Not verwenden. Ich verwende
ihn gar nicht.
Berechtigung hat er nur in Macros, z.B. wenn ein Rückgabewert evaluiert
werden soll.
https://en.wikipedia.org/wiki/Comma_operator
Volker B. schrieb:> "v >> 1" oder nicht doch eher "v >>= 1"?Wie ich schrieb:>>> offensichtlich ganz grundlegend die verwendeten Operatoren nicht>>> verstanden.
Für einen Anfänger besser noch "v = v>>1".
Und das nicht in der Schleifendeklaration, sondern im Schleifenkörper.
Tim schrieb:> Leider funktioniert es so nicht:> for (byte s=0, v=figure[0]; s<8 && v==B00000001; s++, v >> 1){
Da steht: führe die Schleife aus, solange "s kleiner 8" UND
GLEICHZEITIG "v gleich 1" ist. Das ist nie der Fall. Die Schleife wird
vor dem ersten Durchlauf abgebrochen.
Tim schrieb:> So funktionierts tatsächlich :))
Glaube ich nicht...
Einfach selber mal probieren:
- https://onlinegdb.com/Mi6X31Y9D
- https://onlinegdb.com/aYBRDevtj
Peter D. schrieb:> Den Kommaoperator sollte man nie ohne große Not verwenden.
Wenn ich die verlinkte Seite so anschaue, dann gibt es für mich nur die
Anwendung als Separator:
int a=1, b=2, c=3, i=0;
Alles andere führt bei mir als Gelegenheitsprogrammierer nur zu
Verständnisfehlern ... 😀
Was hätte ich denn davon, selbst wenn mir das auf dieser Seite alles
glasklar wäre? Ein paar Zeichen/Zeilen beim Schreiben eingespart? Und
dafür ausführlicher kommentiert?
Wo würde denn die 'große Not' auftreten?
Klaus H. schrieb:> Peter D. schrieb:>> Den Kommaoperator sollte man nie ohne große Not verwenden.>> Was hätte ich denn davon, selbst wenn mir das auf dieser Seite alles> glasklar wäre? Ein paar Zeichen/Zeilen beim Schreiben eingespart? Und> dafür ausführlicher kommentiert?>> Wo würde denn die 'große Not' auftreten?
Zen of Python #8:
- Special cases aren't special enough to break the rules.
Und selbst wenn die 'große Not' noch 100x größer wäre:
Man verwendet - wie am Beispiel 'Tim' selbst dem letzten Honk deutlich
geworden sein dürfte - niemals nicht (!) irgendwelche kryptischen
Konstrukte, die man am Ende selbst als Autor nicht mehr versteht. PUNKT!
Selbst nicht, wenn 'Honk' denkt das wäre ober-cool.
@ Tim: 3-mal den gleichen Fehler machen ist absolut un-cool und zeugt
nur von besonders ausgeprägter Dämlichkeit!
just my 2ct
Joe L. schrieb:> @ Tim: 3-mal den gleichen Fehler machen ist absolut un-cool und zeugt> nur von besonders ausgeprägter Dämlichkeit!
Tim , nimms leicht, manche können nur Beleidigen.
Solche Fehler welche du begehst haben hier viele gemacht.
Das wird nur vergessen.
,,aber es gibt immer Einige welche ehrlich helfen können.
Helfen muss auch erst gelernt werden.
MfG
alterknacker
@Joe L.
Ich wollte nur ein Beispiel sehen, weil mir dazu nichts sinnvolles
einfällt.
Naja, es gibt so Wettbewerbe, wo man maximal kryptischen Code schreibt;
vielleicht da?
Joe L. schrieb:> Man verwendet - ... - niemals nicht (!) irgendwelche kryptischen> Konstrukte, die man am Ende selbst als Autor nicht mehr versteht.
Genau! Man schreibt Code, der nicht funktioniert und muss hier im Forum
fragen, warum er es nicht tut. Das ist doch das beste Beispiel ...
Und erst recht versteht es ein Dritter nicht, der den Code
weiterverwenden soll.
[Offtopic]
Al. K. schrieb:> Joe L. schrieb:>> @ Tim: 3-mal den gleichen Fehler machen ist absolut un-cool und zeugt>> nur von besonders ausgeprägter Dämlichkeit!>> Tim , nimms leicht, manche können nur Beleidigen.
Das war keine Beleidigung, sondern eine Feststellung.
Wenn man (noch) keine Ahnung von der Materie (egal welcher) hat, sollte
man klein anfangen. C-Code kann man "obfuscaten" - der Komma-Operator
hilft dabei.
Wenn man jemanden (mehrfach) auf seinen Fehler hinweist und der trotzdem
nicht akzeptiert, dass das ein Fehler ist, dann wird es umso
schwiertiger, ihm zu helfen.
[/Offtopic]
Al. K. schrieb:> Solche Fehler welche du begehst haben hier viele gemacht.
Aber ganz viele sind dann von selber auf die Lösung gekommen. Denn sie
wussten: "Die Kenntnisse sind NICHT da, sie müssen erst noch erlernt
werden."
Und dass die Kenntnisse fehlen erkennt man auch daran, dass da eine
doppelte Abbruchbedingung drin ist, von der (wenn sie denn korrekt
programmiert wurde) eine einzige reichen würde, weil beide Variabelen
exakt das selbe machen. Nämlich 8 Durchläufe abzählen:
- https://onlinegdb.com/F8JSlZz4f
- https://onlinegdb.com/yLcFugNtF
Ich muss da nicht v UND s auswerten, es reicht eines davon.
> Helfen muss auch erst gelernt werden.
"Dazulernen" und "daraus Lernen" auch.
Klaus H. schrieb:> dann gibt es für mich nur die> Anwendung als Separator:> int a=1, b=2, c=3, i=0;
Das ist nicht der Kommaoperator (Sequenz Operator).
Auch wenn er ähnlich/gleich ausschaut.
So wie auch das = dort keine Zuweisung, sondern eine Initialisierung
ist.
> dann gibt es für mich nur
Und als Separator von Funktionsparametern
Und in z.B. Array oder Konstruktor Initialisierungslisten
Also nix "nur"
Grundsätzlich:
Es gibt keine bösen Sprachmittel!
Allerdings falsche oder unglücklich gewählte Einsatzorte.
Menschlich:
Wenn man einmal begriffen hat, wie ein Hammer funktioniert, sieht alles
plötzlich wie ein Nagel aus.
Warum ist figure ein Array mit acht Elementen, von denen nur eines
genutzt wird?
Da v immer ein Resultat einer Operation von s ist, gibt es keinen Grund,
v als Abbruchkriterium zu verwenden.
Steve van de Grens schrieb:> Um keinen Knoten im Kopf zu bekommen schlage ich diese Schreibweise> vor:> for (byte s=0; s<=8; s++)> {
Warum soll die Schleife neunmal durchlaufen werden?
Georg M. schrieb:>> "Ein Byte speichert eine vorzeichenlose 8-Bit-Zahl von 0 bis 255."> Alles andere wäre erklärungsbedürftig.
Bei überraschenderweise vorzeichenbehafteten **char** stolpern auch die
allermeisten... ;-)
Tim schrieb:> for (byte s=0, v=figure[0]; s<8, v==B00000001; s++, v >> 1)
Ganz ehrlich, wieso so kompliziert (haben ja andere auch schon
bemängelt)? Optimierter Code ist nicht gleichbedeutend mit "möglichst
wenig Zeilen"! Der Compiler macht das ja dann für dich.
Und wenn das Zeug dann noch über Jahre wartbar bleiben soll, und im
professionellen Umfeld von mehreren Personen betreut wird, dann würde
ich von solchen Konstrukten abraten.
Georg M. schrieb:> Lothar M. schrieb:>> Und dort:>> "Ein Byte speichert eine vorzeichenlose 8-Bit-Zahl von 0 bis 255.">> Alles andere wäre erklärungsbedürftig.
Nein.
Ein Byte ist erstmal nur ein Tupel von 8-Bits. Ein Byte ist kein
numerischer Datentyp.
Für einen numerischen Datentyp mit 8-Bit gibt es uint8_t als
vorzeichenloser Typ, oder int8_t als vorzeichenbehafteter Typ.
Hat man zwei Bitmuster, etwa um in einer (internen) Peripherie eine
Aktion auszulösen, wie etwa `b1 = 0b0001'0100` oder `b2 = 0b0001'0001`,
dann mag man die ggf. noch hexadezimal aus Bequemlichkeit hinschreiben
als `0x14` oder `0x11`, aber es sind keine numerischen Datentypen, denn
`b1 * b2` macht keinen Sinn.
Leider trifft das auch für den primitven DT `char` zu, was viele dazu
verleitet zu glauben, das seit der Typ für ein (ASCII) Zeichen. Auch
`char` ist leider numerisch. Jedoch macht es keinen Sinn, die Zeichen
`'a'` und `'b'` zu dividieren ...
Üblicherweise (wenn überhaupt) macht es Sinn, Bytes logisch (and, or,
xor) miteinander zu verknüpfen, oder ggf. noch Bitmasken als Bytes zu
verschieben (<<).
Arduino ist ja C++, und im C++-Standard (seit C++17, davor waren
ähnliche Lösungen üblich und in Gebrauch) gibt es genau für ein Byte
(ein Tupel von 8 Bits) den DT `std::byte`, was kein arithmetische DT
ist. Als arithmetischer Typ mit 8-Bit stehen seit langem schon (vor
Arduino) uint8_t und int8_t zur Verfügung.
Wilhelm M. schrieb:> Leider trifft das auch für den primitven DT `char` zu, was viele dazu> verleitet zu glauben, das seit der Typ für ein (ASCII) Zeichen.
Dafür ist es ja auch gedacht, daher auch der Name. Das ist aber auch das
einzige, wofür man diesen Typ je nutzen sollte. Dass er trotzdem zum
Rechnen verwendet werden kann, ist unglücklich, aber kommt eben aus der
Historie.
> Arduino ist ja C++, und im C++-Standard (seit C++17, davor waren> ähnliche Lösungen üblich und in Gebrauch) gibt es genau für ein Byte> (ein Tupel von 8 Bits)
…soviele Bits wie unsigned char hat.
> den DT `std::byte`, was kein arithmetische DT ist.
Allerdings über die Krücke einer enum class ohne Members.
> Also arithmetischer Typ mit 8-Bit stehen seit langem schon (vor Arduino)> uint8_t und int8_t zur Verfügung.
Tatsächlich gab es bei Arduino das byte-Typedef schon Jahre bevor die
[u]intX_t-typedefs Teil des C++-Standards wurden.
Wilhelm M. schrieb:> Ein Byte ist kein numerischer Datentyp.
Wenn es unbedingt sehr streng typisiert sein soll, dann musst du VHDL
nehmen. Da läuft nichts implizit und "hintenrum".
> Ein Byte ist kein numerischer Datentyp.
Kommt wie gesagt auf die Programmiersprache an:
- https://wiki.freepascal.org/Byte/de
-
https://learn.microsoft.com/de-de/dotnet/visual-basic/language-reference/data-types/byte-data-type
Dass die Arduinisten das byte trotz erprobtem uint8_t und int8_t
unnötigerweise wieder hervorgezerrt haben, steht auf einem ganz anderen
Blatt. Aber die sind eh' recht schmerzfrei und hurgeln ja auch jahrelang
ohne Debugger herum...
Rolf M. schrieb:> Wilhelm M. schrieb:>> Arduino ist ja C++, und im C++-Standard (seit C++17, davor waren>> ähnliche Lösungen üblich und in Gebrauch) gibt es genau für ein Byte>> (ein Tupel von 8 Bits)>> …soviele Bits wie unsigned char hat.
Nenn mir ein aktuelles Data-Model (außer den 4 gängigen), wo ein char
keine 8-Bit hat (sondern mehr).
>> den DT `std::byte`, was kein arithmetische DT ist.>> Allerdings über die Krücke einer enum class ohne Members.
Krücke? Nein.
>> Also arithmetischer Typ mit 8-Bit stehen seit langem schon (vor Arduino)>> uint8_t und int8_t zur Verfügung.>> Tatsächlich gab es bei Arduino das byte-Typedef schon Jahre bevor die> [u]intX_t-typedefs Teil des C++-Standards wurden.
Nö. Arduino hat erst ca. 2005 gestartet, da gab es mit C99 schon längst
uint8_t, ...
Wilhelm M. schrieb:>> Tatsächlich gab es bei Arduino das byte-Typedef schon Jahre bevor die>> [u]intX_t-typedefs Teil des C++-Standards wurden.>> Nö. Arduino hat erst ca. 2005 gestartet, da gab es mit C99 schon längst> uint8_t, ...
C != C++
Arduino setzt auf C++ auf, und dort kam das erst mit C++11.
Lothar M. schrieb:> Dass die Arduinisten das byte trotz erprobtem uint8_t und int8_t> unnötigerweise wieder hervorgezerrt haben, steht auf einem ganz anderen> Blatt. Aber die sind eh' recht schmerzfrei und hurgeln ja auch jahrelang> ohne Debugger herum...
Du kannst es auch nicht lassen. Warum muss man laut deiner Meinung immer
gleich mit Debugger loslegen? Für 99,9% der Fehlersuche reicht eine
serielle Ausgabe vollkommen aus. Oder auf einem Display. Zudem dieser
Minimalismus noch einen großen Vorteil hat. Man kann zur Laufzeit, ohne
weitere Bremse, mit vollen Speed sich irgendwelche Werte ausgeben
lassen. Anstatt das Programm beim Breakpoint immer stoppt.
Wilhelm M. schrieb:> Arduino ist ja C++, und im C++-Standard (seit C++17, davor waren> ähnliche Lösungen üblich und in Gebrauch) gibt es genau für ein Byte> (ein Tupel von 8 Bits) den DT `std::byte`, was kein arithmetische DT> ist. Als arithmetischer Typ mit 8-Bit stehen seit langem schon (vor> Arduino) uint8_t und int8_t zur Verfügung.
Du arroganter Besserwisser...
AVR Arduino ist per default C++11
Und deine std::irgendwas blabla ist auch nicht im Lieferumfang.
Woher auch?
Harald K. schrieb:> Warum soll die Schleife neunmal durchlaufen werden?
Vielleicht, damit man sehen kann, wie das Bit am Ende ganz heraus
geschoben wurde.
Warum streitet ihr euch darüber, was ein Byte ist?
Arduino will eine eigene Programmiersprache sein, die zu Processing
kompatibel ist. Dort war das "byte" genau so definiert, wie auch in
Arduino: Als vorzeichenloser Integer mit dem Bereich 0..255. Genau so
funktioniert es auch.
Wie das früher oder heute mal in C/C++ genannt war, spielt nur eine
untergeordnete Rolle. Arduino benutzt viele Begriffe anders, das gehört
zum System.
Man bekommt den Eindruck, dass Leute hier Probleme machen, weil sie
sonst keine haben.
Arduino F. schrieb:> Wilhelm M. schrieb:>> Arduino ist ja C++, und im C++-Standard (seit C++17, davor waren>> ähnliche Lösungen üblich und in Gebrauch) gibt es genau für ein Byte>> (ein Tupel von 8 Bits) den DT `std::byte`, was kein arithmetische DT>> ist. Als arithmetischer Typ mit 8-Bit stehen seit langem schon (vor>> Arduino) uint8_t und int8_t zur Verfügung.>> AVR Arduino ist per default C++11
Nein, eine Untermenge davon, wie Du selbst bemerkt hast (s.u.).
Aber es gibt doch auch non-AVR Arduino, oder nicht?
> Und deine std::irgendwas blabla ist auch nicht im Lieferumfang.
s.o.
Stefan F. schrieb:> Warum streitet ihr euch darüber, was ein Byte ist?
Ich streite mich nicht, ich stelle nur fest, dass für Arduino ein Byte
immer eine nicht-negative Ganzzahl im 2'er-Komplement ist. Und das halte
ich für großen Mist, also bspw. jedes Byte, was über SPI reinkommt, als
ein solche Zahl zu interpretieren. Aber wenn die Arduino-Leute damit
glücklich sind ...
> Arduino will eine eigene Programmiersprache sein, die zu Processing> kompatibel ist. Dort war das "byte" genau so definiert, wie auch in> Arduino: Als vorzeichenloser Integer mit dem Bereich 0..255. Genau so> funktioniert es auch.
Ok, soll mir recht sein. Noch ein weiterer Grund, darum ein großen Bogen
zu machen.
> Man bekommt den Eindruck, dass Leute hier Probleme machen, weil sie> sonst keine haben.
Stimmt, ich habe damit gar kein Problem ;-)
Falk B. schrieb:> Wilhelm M. schrieb:>> Nenn mir ein aktuelles Data-Model (außer den 4 gängigen), wo ein char>> keine 8-Bit hat (sondern mehr).>> Beim PICCOLO.
Das soll ein Compiler sein?
Wilhelm M. schrieb:> Aber es gibt doch auch non-AVR Arduino, oder nicht?
Ignorant!
Siehe:
Tim schrieb:> Arduino Uno
Offensichtlich bist du so ein deiner Welt gefangen, dass es rein Rechts
kein Links und keine Fakten mehre Geltung erlangen können.
Wenn ich mich richtig erinnere, dann heißt die Krankheit Hybris.
Arduino F. schrieb:> Wilhelm M. schrieb:>> Aber es gibt doch auch non-AVR Arduino, oder nicht?>> Ignorant!
Echt. Ich wollte Dir gerade etwas Gutes tun ;-) Wollte Dich gerade aus
der AVR Welt erlösen ...
> Siehe:> Tim schrieb:>> Arduino Uno
Ja, sorry. Überlesen.
> Offensichtlich bist du so ein deiner Welt gefangen, dass es rein Rechts> kein Links und keine Fakten mehre Geltung erlangen können.
Mmh, meinst Du nicht, dass Du gerade mit Deinen Kommentaren zeigst, dass
das jetzt auch für Dich gilt?
Wilhelm M. schrieb:> Ja, sorry. Überlesen.
Nix "sorry", so einfach nicht
Arrogantes Gehabe in Verbindung mit Wahrnehmungsverweigerung?
Da hilft kein sorry, sondern: Das hast du zu ändern!
Wilhelm M. schrieb:> Aber es gibt doch auch non-AVR Arduino, oder nicht?
Klar gibt es auch ARM-Arduinos, die möglicherweise ein vollständigeres
C++ einschließlich std::Byte unterstützen.
Nur, was nützt dir std::Byte mit der Breite eines char, wenn die
Hardwareregister, auf die du den Datentyp anwenden willst, alle viermal
so groß sind?
Gibt es in C++ auch so etwas wie ein std::QByte, das viermal so breit
wie ein char ist, oder ein Byte32, das genau 32 Bit hat?
Wilhelm M. schrieb:> ich stelle nur fest, dass für Arduino ein Byte immer eine> nicht-negative Ganzzahl im 2'er-Komplement ist.
Darf ich fragen, was eine nicht-negative Ganzzahl im 2'er-Komplement
ist? ;-)
Wilhelm M. schrieb:> Das soll ein Compiler sein?
Oh Mann, da stellt sich aber einer wieder mal maximal dumm ;-)
Der Compiler folgt der Hardwarearchitektur, und wenn diese keine
direkten 8-Bit-, sondern nur 16-Speicherzugriffe zulässt, dann ist die
Breite von char und std::Byte eben 16 Bit. Ist das so schwer zu
verstehen?
Und ja, es gibt auch einen C/C++-Compiler für PICCOLO:
https://www.ti.com/tool/C2000-CGT
Es gibt auf der Welt eben nicht nur PCs und AVRs.
Wilhelm M. schrieb:>>> Nenn mir ein aktuelles Data-Model (außer den 4 gängigen), wo ein char>>> keine 8-Bit hat (sondern mehr).>>>> Beim PICCOLO.>> Das soll ein Compiler sein?
Natürlich NICHT! Aber eine CPU + Compiler von TI!
Wilhelm M. schrieb:> Ich streite mich nicht, ich stelle nur fest, dass für Arduino ein Byte> immer eine nicht-negative Ganzzahl im 2'er-Komplement ist. Und das halte> ich für großen Mist, also bspw. jedes Byte, was über SPI reinkommt, als> ein solche Zahl zu interpretieren.
Zunächst ist sie ja auch nichts anderes. Wie es ein Byte schon immer war
(jedenfalls in der konkreten Ausprägung mit 8 Bits, also der einzig
heute noch relevanten).
Ein extrem sinnvoller Typ!
So lange das Teil nur über irgendeine Kommunikationsleitung geht, spielt
der innere Gehalt eines Bytes nämlich absolut keine Rolle. Es ist nur
ein Muster aus 8 Bits. Es kann sein: signed oder unsigned. Das ist
gut, denn das spielt überhaupt nur dann eine Rolle, wenn es das
höchstwertige Byte eines breiteren Datentyps ist oder das einzige Byte.
Eine tiefere Bedeutung hat es also nur vor dem Versand und nach dem
Empfang.
Der Sender muß halt deklarieren, wie die Bytes entsprechend ihrer
Position im Frame zu interpretieren sind, zu welchen größeren Datentypen
sie ggf. gehören und wie sie entsprechend ihrer dortigen Position zu
bewerten sind.
Der Empfänger hingegen muß sie entsprechend behandeln und ihnen ihre
volle Bedeutung geben. Also: sie entsprechend der eigenen endianess
korrekt im Speicher anordnen und den entstehenden, mehr oder weniger
breiten Bitmonstern eine weitere Bedeutung zuordnen, nämlich einen Typ
mit einer bestimmten Signedness.
Diese inhaltlichen Sachen fließen halt nicht huckepack im Datenstrom,
sondern per Vor-Vereinbarung per Deklaration.
Zusammenfassend: das Arduino-"Byte" ist der bestmögliche Datentyp für
jede Art von binärer Kommunikation oder binärer Speicherung.
Und letztlich wird in allen Sprachen effektiv der Typ dafür verwendet,
der der Sache noch am nächsten kommt...
Siehe das heillose C-Gebastel, wo mal char (mit unklarer signedness)
oder signed char oder unsigned char oder uint8_t für diese Aufgabe
verwendet wird. Keiner dieser Ansätze passt so wie das Arduino-Byte.
Entweder legt es sich beim Vorzeichen fest oder es läßt die Bitzahl
offen, das (möglicherweise) zu verwendende Komplement sowieso...
Also: C ist Dreck, das war ja sowieso klar. C++ ist schon besser, denn
das erlaubt immerhin, sowas wie ein "byte" sauber zu deklarieren.
Arduino hat diese Chance genutzt. Wow, ich hätte nicht gedacht, dass ich
irgendwann mal etwas gutes über Arduino zu sagen hätte...
C-hater schrieb:> Wow, ich hätte nicht gedacht, dass ich> irgendwann mal etwas gutes über Arduino zu sagen hätte...
Ich auch nicht!
Kann dir aber auch nicht wirklich glauben.
Warten wir es mal ab.....
C-hater schrieb:> Siehe das heillose C-Gebastel, wo mal char (mit unklarer signedness)> oder signed char oder unsigned char oder uint8_t für diese Aufgabe> verwendet wird. Keiner dieser Ansätze passt so wie das Arduino-Byte.
Du hast schon gesehen, dass das byte in Arduino ein Alias von uint8_t
ist?
> Entweder legt es sich beim Vorzeichen fest oder es läßt die Bitzahl> offen,
Rate mal, was das "u" und die "8" in "uint8_t" bedeuten.
> das (möglicherweise) zu verwendende Komplement sowieso...
Das ist in C++ und demnächst auch in C genau festgelegt.
Du stellst hier gerade mal wieder vortrefflich deine Ahnungslosigkeit
zur Schau ;-)
Yalu X. schrieb:> Wilhelm M. schrieb:>> Aber es gibt doch auch non-AVR Arduino, oder nicht?>> Klar gibt es auch ARM-Arduinos, die möglicherweise ein vollständigeres> C++ einschließlich std::Byte unterstützen.
Definitiv. Übrigend heißt es std::byte.
> Nur, was nützt dir std::Byte mit der Breite eines char, wenn die> Hardwareregister, auf die du den Datentyp anwenden willst, alle viermal> so groß sind?
Ein Byte ist ein Byte, egal ob irgendein Register 32 Bit breit ist.
> Gibt es in C++ auch so etwas wie ein std::QByte, das viermal so breit> wie ein char ist, oder ein Byte32, das genau 32 Bit hat?
Warum nicht. Es steht Dir frei.
> Wilhelm M. schrieb:>> ich stelle nur fest, dass für Arduino ein Byte immer eine>> nicht-negative Ganzzahl im 2'er-Komplement ist.>> Darf ich fragen, was eine nicht-negative Ganzzahl im 2'er-Komplement> ist? ;-)
Ups, streiche das 2'er Komplement ;-)
> Wilhelm M. schrieb:>> Das soll ein Compiler sein?>> Oh Mann, da stellt sich aber einer wieder mal maximal dumm ;-)>> Der Compiler folgt der Hardwarearchitektur, und wenn diese keine> direkten 8-Bit-, sondern nur 16-Speicherzugriffe zulässt, dann ist die> Breite von char und std::Byte eben 16 Bit. Ist das so schwer zu> verstehen?
Ein Byte ist ein Byte, egal ob die HW 16 oder 32 Bit breit ist. C/C++
beschreibt erst einmal ein abstrakte Maschine und es ist erstmal egal,
was die HW ist.
> Und ja, es gibt auch einen C/C++-Compiler für PICCOLO:>> https://www.ti.com/tool/C2000-CGT
Prima, und welches data-model legt er zugrunde?
>> Es gibt auf der Welt eben nicht nur PCs und AVRs.
Och, jetzt habe ich Euch schon Brücken gebaut, und Du hast sogar auch
ARM erwähnt.
Yalu X. schrieb:> Das ist in C++ und demnächst auch in C genau festgelegt.
Eben: demnächst. Aber jetzt doch noch nicht, gelle?
> Du stellst hier gerade mal wieder vortrefflich deine Ahnungslosigkeit> zur Schau ;-)
Nö, du stellst hingegen deine Pro-C-Idiotie, die jede Schwäche dieser
unsäglich schlecht designten Sprache gnadenlos ausblendet, erneut zur
Schau.
Inclusive natürlich der allfälligen Herabwürdigung der tatsächlich
wissenden Kritiker dieser unseligen Altlast des Sprachdesigns...
C-hater schrieb:> Zunächst ist sie ja auch nichts anderes. Wie es ein Byte schon immer war> (jedenfalls in der konkreten Ausprägung mit 8 Bits, also der einzig> heute noch relevanten).>> Ein extrem sinnvoller Typ!>> So lange das Teil nur über irgendeine Kommunikationsleitung geht, spielt> der innere Gehalt eines Bytes nämlich absolut keine Rolle. Es ist nur> ein Muster aus 8 Bits. Es kann sein: signed oder unsigned. Das ist> gut, denn das spielt überhaupt nur dann eine Rolle, wenn es das> höchstwertige Byte eines breiteren Datentyps ist oder das einzige Byte.>> Eine tiefere Bedeutung hat es also nur vor dem Versand und nach dem> Empfang.
Lies bitte alles, was ich geschrieben habe: ein Byte ist ein Tuple von 8
Bit. Und das ist nicht notwendigerweise eine Ganzzahl. Deswegen sage ich
ja, dass die arithmetischen Operationen für ein Byte keinen Sinn machen.
Aber das verstehen hier manche eben nicht. Und Arduino hat leider byte
als alias zu uint8_t deklariert. Und das ist großer Mist.
Hallo,
das wird wohl dann zum Henne <> Ei Problem ausarten. Arduino hat byte
vorm C++ Standard definiert. C++ hat es nun anders definiert. Kann man
von halten was man will. Ist nun einmal so.
Unabhängig davon eine Frage. Wofür benötigt der C++ Standard ein byte
wenn es schon uint8_t und int8_t bzw. char und unsigned char gibt? So
ganz naiv gefragt.
Veit D. schrieb:> Warum muss man laut deiner Meinung immer gleich mit Debugger loslegen?
Man muss nicht "immer gleich" mit dem Debugger loslegen. Aber dann, wenn
man einen braucht, ist das Herumgehurgel mit der Ausgabe auf dei SIO und
auf ein Display wie annodazumal das Debuggen mit LEDs.
Zur Info: auch ich nehme die Arduino-Toolchain, wenn ich was schnell mal
zusammenfrickeln muss. Wenn es aber ein richtiges Programm mit ein wenig
Anspruch und Arithmetik ist, dann will ich einen anständigen Debugger
mit all dem, was ein Debugger zu haben hat. Nicht umsonst hat heute
jeder µC sepzielle Hardware und ggfs. sogar eine spezielle Schnittstelle
im Silizium, die allein dem Debuggen dient.
> Für 99,9% der Fehlersuche reicht eine serielle Ausgabe vollkommen aus.
"Ausreichend" war schon in der Schule eine eher schlechte Note.
> Oder auf einem Display. Zudem dieser Minimalismus noch einen großen> Vorteil hat. Man kann zur Laufzeit, ohne weitere Bremse, mit vollen> Speed sich irgendwelche Werte ausgeben lassen.
Man kann sich das SIO- und LED-Debuggen auch mit Gewalt schönsaufen.
Dass die Echtzeit dann von Anfängern z.B. wegen der Displayausgaben in
der ISR kaputtgemacht wird, das ist die Kehrseite der Medaille.
> Anstatt das Programm beim Breakpoint immer stoppt.
Das Programm stoppt am Breakpoint nur, wenn ich will, dass es da stoppt.
> Du kannst es auch nicht lassen
Ja, klar, wie auch? Die Toolchain hat ja auch keinen Debugger. Und wer
vorher schon mal eine funktionierende Toolchain mit Debugger hatte, dem
fehlt er eben, wenn er ihn braucht.
Und wenn man mal die rosafarbene Arduino-Brille abnimmt und über den
Tellerrand rausschaut, dann ist es schon so, dass jede ernstzunehmende
Sotwareentwicklungsumgebung einen Debugger hat. Oder sogar mehrere, die
unterschiedliche Teile der Software und des Softwareverhaltens
analyisieren.
Gut, das wars jetzt wieder zu diesem Thema. Ich werde auch weiterhin
meine Arduino-Programme vorher schon so gut durchdenken, dass mir die
serielle Schnitte zur Fehlersuche reicht. Auch wenn ich die vermutlich
bei genau diesem Projekt gerne für was anderes verwenden würde...
Veit D. schrieb:> Wofür benötigt der C++ Standard ein byte wenn es schon uint8_t und> int8_t bzw. char und unsigned char gibt? So ganz naiv gefragt.
Um dem Nutzer und der statistischen Codeanalyse klar zu machen, dass
hier keine Zahl (17) oder Zeichen ('a') gefordert ist.
Veit D. schrieb:> Lothar M. schrieb:>>> Dass die Arduinisten das byte trotz erprobtem uint8_t und int8_t>> unnötigerweise wieder hervorgezerrt haben, steht auf einem ganz anderen>> Blatt. Aber die sind eh' recht schmerzfrei und hurgeln ja auch jahrelang>> ohne Debugger herum...>> Du kannst es auch nicht lassen. Warum muss man laut deiner Meinung immer> gleich mit Debugger loslegen? Für 99,9% der Fehlersuche reicht eine> serielle Ausgabe vollkommen aus. Oder auf einem Display. Zudem dieser> Minimalismus noch einen großen Vorteil hat. Man kann zur Laufzeit, ohne> weitere Bremse, mit vollen Speed sich irgendwelche Werte ausgeben> lassen. Anstatt das Programm beim Breakpoint immer stoppt.
Serielle Ausgabe?
Weisst du überhaupt was Debugging ist?
Das ist nicht Debugging, Serielle Ausgabe ist ein Schrei nach Hilfe!
https://www.youtube.com/watch?v=7wx27FcluMg
Lothar M. schrieb:> Und wenn man mal die rosafarbene Arduino-Brille abnimmt und über den> Tellerrand rausschaut,
Die sich langsam etablierende Arduino IDE V2.xxx kann mittlerweile
debuggen. leider bisher nur bei ARM µC (soweit mir bekannt)
In wie weit das eine Grundsteinlegung ist und was da noch kommt, kann
ich nicht prognostizieren.
Veit D. schrieb:> Unabhängig davon eine Frage. Wofür benötigt der C++ Standard ein byte> wenn es schon uint8_t und int8_t bzw. char und unsigned char gibt?
Das Byte kommt im C++ Standard zwar vor, aber mindestens in älteren
Standards nicht als Datentyp, sondern als Begriff aus der
Rechnerarchitektur. Es hat daher die älteren Rechte und existierte
bereits vor C++ und auch vor C.
Was nicht heisst, dass jeder Rechner eine sinnvolles Adressierungeinheit
hat(te), die mit diesem Begriff in Sprachen wie C und C++ gemeint ist.
Viele früheren Rechner waren überhaupt nicht in der Lage, einzelne
Zeichen ihres üblichen Zeichensatzes direkt und unabhängig zu
adressieren. Bytes gab es dann nicht. Was auch bedeuten konnte, das ein
einzelnes Zeichen auf der gleichen Maschine je nach Programm und Kontext
z.B. 6 oder 8 Bits breit war.
Wilhelm M. schrieb:> Übrigend heißt es std::byte.
Sorry, ja, natürlich mit kleinem b, ist ja englisch :)
Wilhelm M. schrieb:>> Nur, was nützt dir std::Byte mit der Breite eines char, wenn die>> Hardwareregister, auf die du den Datentyp anwenden willst, alle viermal>> so groß sind?>> Ein Byte ist ein Byte, egal ob irgendein Register 32 Bit breit ist.
Die Frage war nach dem Nutzen. Gibt es sinnvolle Anwendungen eines
8-Bit-Integertyps, den man der vier Grundrechenarten beraubt hat, auf
einer Plattform, die hardwareseitig kaum einen Bezug zu diesen 8 Bit
hat?
>> Gibt es in C++ auch so etwas wie ein std::QByte, das viermal so breit>> wie ein char ist, oder ein Byte32, das genau 32 Bit hat?>> Warum nicht. Es steht Dir frei.
Also ist die Antwort nein, und ich muss mir das selber zusammenstricken.
Ich habe mir mal die Definition von std::byte und der zugehörigen
Operatoren in cstddef¹ im GCC-Paket nachgeschaut: 116 Zeilen Code für
einen Datentyp, der einem unsigned char entspricht, nur dass es eben ein
neuer Typ ist und auf ihm ausschließlich Bit-, Vergleichs-² und
Konvertierungsoperatoren definiert sind, die der zugrunde liegende Typ
unsigned char sowieso schon hat?
Es gibt Programmiersprachen, da geht das in einer einzelnen Zeile.
Wilhelm M. schrieb:>> Der Compiler folgt der Hardwarearchitektur, und wenn diese keine>> direkten 8-Bit-, sondern nur 16-Speicherzugriffe zulässt, dann ist die>> Breite von char und std::Byte eben 16 Bit. Ist das so schwer zu>> verstehen?>> Ein Byte ist ein Byte, egal ob die HW 16 oder 32 Bit breit ist. C/C++> beschreibt erst einmal ein abstrakte Maschine und es ist erstmal egal,> was die HW ist.
Es ging um die Frage, ob in C++ das std::byte größer als 8 Bit sein
kann. Die Antwort ist ja.
Wilhelm M. schrieb:>> Und ja, es gibt auch einen C/C++-Compiler für PICCOLO:>>>> https://www.ti.com/tool/C2000-CGT>> Prima, und welches data-model legt er zugrunde?
Auf jeden Fall eines, wo char, signed char, unsigned char und damit auch
std::byte nicht wie üblich 8, sondern 16 Bit breit sind. Es gibt andere
Prozessoren von TI, da ist ein char sogar 32 Bit breit. Mancher ist
dabei verwirrt, wenn er sieht, dass sizeof (float) == 1 ist.
─────────────
¹) Wieso eigentlich in cstddef, wo ich doch nur C-Datentypen und -Makros
erwarten würde?
²) Wegen der Deklaration von std::byte als enum class sind auch die
Operatoren <, <=, > und >= möglich, die ja genauso wenig wie +, -, *
und / zur Natur eines Bytes passen. Hätte man std::byte nicht besser
als echte Klasse realisiert, in der auch diese Operatoren
unimplementiert sind?
C-hater schrieb:> Yalu X. schrieb:>>> Das ist in C++ und demnächst auch in C genau festgelegt.>> Eben: demnächst. Aber jetzt doch noch nicht, gelle?
Da es in diesem Thread um Arduino, also um C++ geht, können wir das
"demnächst auch in C" auch streichen, da irrelevant.
Da du wohl kaum Zugriff auf einen Rechner (mitsamt dem zugehörigen
C-Compiler) haben wirst, der im 1er-Komplement rechnet, kannst du auch
in C bedenkenlos vom 2er-Komplement ausgehen.
Meine Güte, 80% von den Beiträgen haben überhaupt keine Relevanz zur
ursprünglichen Frage!
Und zu dem Ganzen Byte-Blabla...
Ich habe das mal so gelernt: Von den CPU-Architekturen her gibt es
historisch Bit, Byte, Word. Das definiert nur die Registerbreite und
sagt nichts über deren Inhalt.
Dass hier nun ein heilloses Durcheinander ist, ist wohl mehr an den
Programmiersprachen geschuldet (-> C# hat Byte als 0-255 Wert, bei C/C++
war ursprünglich soweit ich weiss char). Und weil die Leute lieber beim
altbekannten bleiben, machen sie dann solche Typedefs im Falle eines
Wechsels...
Die vielen Typisierungen machen aber auch Sinn, wenn man sie korrekt
verwendet -> Zur Compile-Zeit schon viele (mögliche) Fehler aufdecken.
Patrick B. schrieb:> ist wohl mehr an den Programmiersprachen geschuldet
Eher der Unkenntnis und Ignoranz.
Gegen Unkenntnis könnte ein Fachbuch helfen.
Gegen Ignoranz und Arroganz ist kein Kraut gewachsen. Einzig Einsicht
mag helfen.
Übrigens:
C und C++ Compiler/Libs haben nicht ohne Grund die "Konstante" CHAR_BIT
Patrick B. schrieb:> 80% von den Beiträgen haben überhaupt keine Relevanz zur ursprünglichen> Frage!
Naja, die eigentliche **Frage** ist ja schon ausführlich beantwortet:
das Programm funktioniert nicht, weil einige Operatoren falsch verwendet
wurden.
Aber die eigentliche **Aufgabe** war die hier:
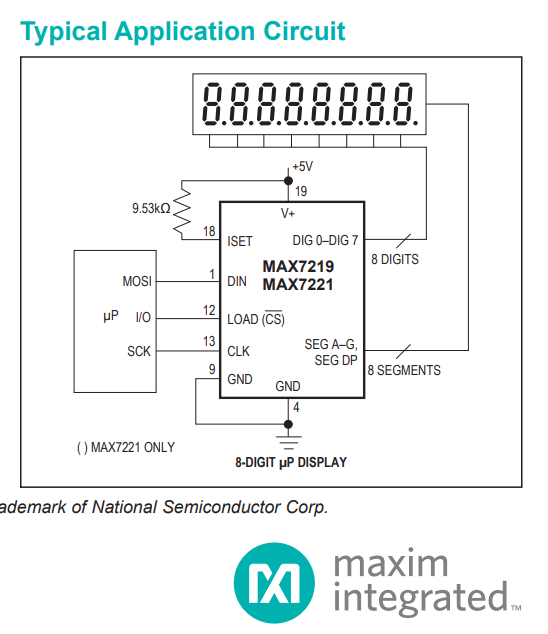
Tim schrieb:> Der soll von der oberen linken Ecke bis zur unteren rechten Ecke,> diagonal, den Punkt bewegen. Das Display ist ein 8x8 von Max7219
Und das geht im Grunde viel einfacher:
1
bytez,s;// zeile, spalte
2
3
for(s=0,s<8,s++){
4
z=0x80>>s;
5
lc.setRow(0,s,z);
6
delay(1000);
7
}
Und ja, mir ist klar, dass 0x80>>s für den AVR ein wenig aufwendig zu
berechnen ist, weil er keinen Barrelshifter hat. Aber solange da noch
ein delay(1000) drin steht, ist das egal.
> Das Display ist ein 8x8 von Max7219
Ja, der soll eigentlich 7-Segmentanzeigen treiben. Alle
Beispielschaltungen im Datenblatt zeigen derartige Bilder. Du musst also
was Spezielleres haben...
Lothar M. schrieb:> z = 0x80 >> s;
Ich habe den Eindruck, dass der Tim diesen Wert nur für den ersten Test
verwendet hat. Letztendlich möchte er unterschiedliche Bitmuster
schieben, die er vorher in einem Array bereit stellt.
Lothar M. schrieb:> Ja, der soll eigentlich 7-Segmentanzeigen treiben.
Hast du die Dinger echt noch nicht gesehen? Solche Anzeigen werden
überall wo es Elektronik-Module gibt in zahlreichen Varianten angeboten.
https://www.az-delivery.de/products/64er-led-matrix-display
Steve van de Grens schrieb:> Letztendlich möchte er
Mag schon sein, aber wenn ich Teller jonglieren möchte, dann fange ich
erst mal mit 1 Teller an. Und wenn ich verstanden habe, wie das geht,
dann nehme ich den 2. dazu. Und dann den dritten.
Aus Erfahrung geht es schief, gleich am Anfang alle 5 Teller in die Luft
zu schmeißen und drauflos zu strampeln.
Lothar M. schrieb:> Aus Erfahrung geht es schief, gleich am Anfang alle 5 Teller in die Luft> zu schmeißen und drauflos zu strampeln.
Wenn fünf Teller runterfallen, gibt es vier Möglichkeiten:
[ ] Man nimmt vier Teller
[ ] Man nimmt sechs Teller
[ ] Man nimmt weiterhin fünf Teller
[ ] Man wendet sich einer anderen Herausforderung zu
Yalu X. schrieb:> Wilhelm M. schrieb:>>> Nur, was nützt dir std::Byte mit der Breite eines char, wenn die>>> Hardwareregister, auf die du den Datentyp anwenden willst, alle viermal>>> so groß sind?>>>> Ein Byte ist ein Byte, egal ob irgendein Register 32 Bit breit ist.>> Die Frage war nach dem Nutzen. Gibt es sinnvolle Anwendungen eines> 8-Bit-Integertyps, den man der vier Grundrechenarten beraubt hat, auf> einer Plattform, die hardwareseitig kaum einen Bezug zu diesen 8 Bit> hat?
Ja sicher. Ein großer Anwendungsbereich ist der Datenaustausch mit der
(int. / ext.) Peripherie. Bspw. ist bei einem STM32 das Datenregister
eines der USARTs zwar 32Bit breit, aber davon sind nur 8Bit relevant.
Bei manchen µC steht sogar im Ref-Man., dass die nicht-relevanten nicht
verändert werden dürfen bzw. auf ihrem Reset-Wert bleiben müssen.
>>> Gibt es in C++ auch so etwas wie ein std::QByte, das viermal so breit>>> wie ein char ist, oder ein Byte32, das genau 32 Bit hat?>>>> Warum nicht. Es steht Dir frei.>> Also ist die Antwort nein, und ich muss mir das selber zusammenstricken.
Die Antwort wäre: ja, du kannst es Dir gut und effektiv zusammenstellen,
wenn Du es brauchst.
> Ich habe mir mal die Definition von std::byte und der zugehörigen> Operatoren in cstddef¹ im GCC-Paket nachgeschaut: 116 Zeilen Code für> einen Datentyp, der einem unsigned char entspricht, nur dass es eben ein> neuer Typ ist und auf ihm ausschließlich Bit-, Vergleichs-² und> Konvertierungsoperatoren definiert sind, die der zugrunde liegende Typ> unsigned char sowieso schon hat?
In eine gut gemachten Bibliothek sind manche Dinge eben etwas
umfangreicher. Das beinhaltet bestimmt auch einige Dinge, an die der
Otto-Normal-Programmierer im ersten Ansatz nicht gedacht hat. Aber ich
habe mir die Deklaration von std::byte jetzt gerade nicht nochmal
angesehen.
Aber ja, vllt. wäre die Anzahl der Library-Zeilen etwas geringer
gewesen, wenn man statt eines enum class ein struct genommen hätte. Aber
das ist für den Anwender ja vollkommen egal.
Es ist übrigens explizit erwünscht, dass std::byte auf die
Relationalen-Operatoren unterstützt. Denn damit kann man ihn auf in
assoziativen Containern bzw. in Algorithmen einsetzen. Und es ist
beabsichtigt, dass std::byte seine relationalen Eigenschaften vom
underlying-type erhält.
> Es gibt Programmiersprachen, da geht das in einer einzelnen Zeile.
Ja, welche?
> Wilhelm M. schrieb:>>> Der Compiler folgt der Hardwarearchitektur, und wenn diese keine>>> direkten 8-Bit-, sondern nur 16-Speicherzugriffe zulässt, dann ist die>>> Breite von char und std::Byte eben 16 Bit. Ist das so schwer zu>>> verstehen?>>>> Ein Byte ist ein Byte, egal ob die HW 16 oder 32 Bit breit ist. C/C++>> beschreibt erst einmal ein abstrakte Maschine und es ist erstmal egal,>> was die HW ist.>> Es ging um die Frage, ob in C++ das std::byte größer als 8 Bit sein> kann. Die Antwort ist ja.
Richtig!
> Wilhelm M. schrieb:>>> Und ja, es gibt auch einen C/C++-Compiler für PICCOLO:>>>>>> https://www.ti.com/tool/C2000-CGT>>>> Prima, und welches data-model legt er zugrunde?>> Auf jeden Fall eines, wo char, signed char, unsigned char und damit auch> std::byte nicht wie üblich 8, sondern 16 Bit breit sind. Es gibt andere> Prozessoren von TI, da ist ein char sogar 32 Bit breit. Mancher ist> dabei verwirrt, wenn er sieht, dass sizeof (float) == 1 ist.
Ja, er hat 16/16/32, so wie es TI beschreibt. Der C++-Compiler ist auf
dem Stand C++03, also es dauert von ein paar Jahrzehnte, bis auch da ein
std::byte Einzug hält.
> ─────────────> ¹) Wieso eigentlich in cstddef, wo ich doch nur C-Datentypen und -Makros> erwarten würde?
Weil es ein C++-Standard-Library-Header ist. Also, was ist daran
verwunderlich?
> ²) Wegen der Deklaration von std::byte als enum class sind auch die> Operatoren <, <=, > und >= möglich, die ja genauso wenig wie +, -, *> und / zur Natur eines Bytes passen. Hätte man std::byte nicht besser> als echte Klasse realisiert, in der auch diese Operatoren> unimplementiert sind?
s.o.
Im Übrigen habt Ihr natürlich alle Recht, dass ein Byte nicht
notwendigerweise ein Oktett ist, auch wenn es das für die
Mainstream-Plattformen ist. Aber das ändert rein gar nichts an der
Sinnhaftigkeit des Datentyps std::byte.
Wilhelm M. schrieb:>> Die Frage war nach dem Nutzen. Gibt es sinnvolle Anwendungen eines>> 8-Bit-Integertyps, den man der vier Grundrechenarten beraubt hat, auf>> einer Plattform, die hardwareseitig kaum einen Bezug zu diesen 8 Bit>> hat?>> Ja sicher. Ein großer Anwendungsbereich ist der Datenaustausch mit der> (int. / ext.) Peripherie. Bspw. ist bei einem STM32 das Datenregister> eines der USARTs zwar 32Bit breit, aber davon sind nur 8Bit relevant.> Bei manchen µC steht sogar im Ref-Man., dass die nicht-relevanten nicht> verändert werden dürfen bzw. auf ihrem Reset-Wert bleiben müssen.
Und inwiefern hilft dir der kastrierte Datentyp dabei? Gar nicht?
Er verhindert vielleicht, daß du eine Dummheit (eben Arithmetik) damit
anstellst. Aber andere Dummheiten verhindert er nicht.
Ich sehe das als einen weiteren Versuch, eine Programmiersprache
idiotensicher zu machen. Die Praxis zeigt, daß das nicht funktioniert.
Idioten sind zu erfinderisch.
Die andere Seite der Medaille ist, daß idiotensichere Dinge am Ende auch
nur von Idioten benutzt werden.
Axel S. schrieb:> Und inwiefern hilft dir der kastrierte Datentyp dabei? Gar nicht?>> Er verhindert vielleicht, daß du eine Dummheit (eben Arithmetik) damit> anstellst. Aber andere Dummheiten verhindert er nicht.>> Ich sehe das als einen weiteren Versuch, eine Programmiersprache> idiotensicher zu machen. Die Praxis zeigt, daß das nicht funktioniert.> Idioten sind zu erfinderisch.
Die Argumentation "Idioten machen Dummheiten, egal welche Maßnahmen wir
ergreifen. Und Profis machen keine Fehler" ist mir schon bekannt.
Die Folgerung daraus wäre dann, dass jegliche Merkmale einer Sprache,
die versuchen, etwas Sicherheit (oder auch Ausdrucksstärke) zu bringen,
unnützt sind.
Bei C/C++ würde das dann bedeuten, dass etwa `const` oder Zusicherungen
oder sager das ganze Typsystem abschafft. Dann gehörst Du also zu der
Fraktion: alles ist ein `int`, und wenn nicht, dann ein String?
Wilhelm M. schrieb:> Die Argumentation "Idioten machen Dummheiten, egal welche Maßnahmen wir> ergreifen. Und Profis machen keine Fehler" ist mir schon bekannt.
Na ja, der zweite Teil vielleicht etwas anders:
»Und Profis machen keine idiotischen Dummheiten.«
Die Profis haben aber einen enormen evolutionären Vorteil:
Sie können lesen und verstehen (und tun das auch).
Wilhelm M. schrieb:> Dann gehörst Du also zu der Fraktion: alles ist ein int, und wenn nicht,> dann ein String?
Es gibt auch noch die radikalere Variante "Alles ist ein String" -> Tcl.
Obwohl: Selbst in Tcl gibt es zwei Datentypen, nämlich Strings und
Dictionaries :)
LG, Sebastian
Wilhelm M. schrieb:>> Die Frage war nach dem Nutzen. Gibt es sinnvolle Anwendungen eines>> 8-Bit-Integertyps, den man der vier Grundrechenarten beraubt hat, auf>> einer Plattform, die hardwareseitig kaum einen Bezug zu diesen 8 Bit>> hat?>> Ja sicher. Ein großer Anwendungsbereich ist der Datenaustausch mit der> (int. / ext.) Peripherie. Bspw. ist bei einem STM32 das Datenregister> eines der USARTs zwar 32Bit breit, aber davon sind nur 8Bit relevant.
Wenn von Hunderten von 32-Bit-I/O-Registern einige wenige einen oder
mehrere 8-Bit-Teilbereich haben, dann nimmst du für diese den Typ
std::byte, für alle anderen Register aber ganz klassisch uint32_t? Oder
machst du dir wirklich die Mühe, einen std::byte-ähnlichen Typ für 16
und 32 Bit zu schreiben?
> Bei manchen µC steht sogar im Ref-Man., dass die nicht-relevanten nicht> verändert werden dürfen bzw. auf ihrem Reset-Wert bleiben müssen.
Das ist immer so, deswegen macht man, wenn man nur Teile eines Registers
beschreiben möchte, üblicherweise ein Read-Modify-Write (ggf. mit
Hardwareunterstützung durch den Controller).
Prinzipiell ist auch ein 8-Bit-Schreibzugriff denkbar, aber nur, wenn
dies von der Peripherie unterstützt wird. Das kann man im jeweiligen
Datenblatt nachlesen und ist keineswegs selbstverständlich.
Aus dem Datenblatt des RP2040:
"Memory-mapped IO registers on RP2040 ignore the width of bus read/write
accesses. They treat all writes as though they were 32 bits in size.
This means software can not use byte or halfword writes to modify part
of an IO register: any write to an address where the 30 address MSBs
match the register address will affect the contents of the entire
register."
Wenn du also beim RP2040 versuchst, mit std::byte in die I/O-Register zu
schreiben, wirst du ganz gewaltig auf die Nase fallen. In den Headers
des Raspberry-Pico-SDK wird deswegen ausschließlich uint32_t als
Datentyp verwendet.
Wilhelm M. schrieb:>> Es gibt Programmiersprachen, da geht das in einer einzelnen Zeile.>> Ja, welche?
Bspw. Haskell, das ist aber sicher nicht die einzige.
Hier ist die Definition von QByte, das auf dem Word32 (entspricht
uint32_t) aus der Standardbibliothek basiert, aber einen eigenen Typ
darstellt und auf Bitfunktionen beschränkt ist.
1
newtype QByte = QByte Word32 deriving (Eq, Bits)
Da Word32 als Instanz der Klassen Eq und Bits bereits alle gewünschten
Funktionen implementiert hat, müssen diese nicht neu geschrieben werden,
sondern werden einfach geerbt.
Wenn man wie bei std::byte auch für QByte eine Totalordnung wünscht,
fügt man einfach noch die Klasse Ord hinzu. Die Klasse Show ist ganz
grob das Analogon zum Ausgabestreamoperator in C++ und bringt das QByte
in eine menschenlesbare Darstellung:
Yalu X. schrieb:> Wenn von Hunderten von 32-Bit-I/O-Registern einige wenige einen oder> mehrere 8-Bit-Teilbereich haben, dann nimmst du für diese den Typ> std::byte, für alle anderen Register aber ganz klassisch uint32_t?
Nein, natürlich nicht. Ich benutze schlicht die C-Header-Files
des Herstellers.
Sinnvollerweise ist bspw. bei STM32 bei solchen Registern der
Reset-Value 0, so dass das, was der bspw. GCC daraus macht, auch ohne
ein RMW korrekt ist: es wird einfach ein 32-Bit store (str) benutzt
entsprechend dem Zieltyp des Registers, ggf. natürlich mit eine
entsprechend breiten Maskierung.
Wobei ich dazu sagen muss, dass natürlich die
üblichen Header der Hersteller mit uint32_t (oder
andere uintXX_t) als Register-Typen
schon falsch sind: die wenigsten Register sind als Ganzzahlen
zu interpretieren (bis auf Ausnahmen wie etwa Counter-Werte oder
Baudraten, etc.). Die meisten Register sind einfach nur ein
Sammelsurium von Bits und damit kein uint32_t. Manche Hersteller
machen sich teilweise ein klein wenig mehr Mühe, und
deklarieren Register, die ggf. einen Byte-Zugriff ermöglichen
sollen als C-union. Wobei ich nicht weiß, ob das mehr Verwirrung
als Klarheit stiftet, denn das eigentliche Problem (Ganzzahl)
bleibt ja bestehen. Macht zudem bspw. auf STM32 wieder ganz
besonders wenig Sinn, weil str und strb jeweils die gleiche
Anzahl von Zyklen brauchen (bei 8Bittern ist das anders).
Das habe ich auch schon oft hier im Forum geschrieben: die
Hesteller könnten ohne viel Aufwand auch C++-Header ausliefern,
in denen die Register alle unterschiedliche Typen
(sinnvollerweise generische Typen mit den möglichen Werten
des Registers als Parameter-Typen) haben. So etwas kann man
aus den eh vorliegenden Beschreibungsdaten einer MCU
(XML o.ä. wie bei MicroChip) erzeugen (für die AVR habe ich
das sogar).
> Oder> machst du dir wirklich die Mühe, einen std::byte-ähnlichen Typ für 16> und 32 Bit zu schreiben?
Natürlich nicht, weil ich das auch nicht in Assembler codiere, sondern
ganz einfach den 8-Bit Wert in das 32-Bit Register schreibe. Es findet
ja
ein zero-padding in die oberen Bits statt, daher passt das.
>> Bei manchen µC steht sogar im Ref-Man., dass die nicht-relevanten nicht>> verändert werden dürfen bzw. auf ihrem Reset-Wert bleiben müssen.>> Das ist immer so, deswegen macht man, wenn man nur Teile eines Registers> beschreiben möchte, üblicherweise ein Read-Modify-Write (ggf. mit> Hardwareunterstützung durch den Controller).
Ist aber auch gar nicht nötig (s.o.).
Oder man ist in der komfortablen Situation, getrennte set- und
reset-Register
zu haben, wie etwa GPIOx.BSRR beim STM32 oder anderen.
> Prinzipiell ist auch ein 8-Bit-Schreibzugriff denkbar, aber nur, wenn> dies von der Peripherie unterstützt wird. Das kann man im jeweiligen> Datenblatt nachlesen und ist keineswegs selbstverständlich.
Wie schon gesagt: es ist auch gar nicht notwendig. Zudem ist ein strb
nicht
schneller als ein str.
> Wenn du also beim RP2040 versuchst, mit std::byte in die I/O-Register zu> schreiben, wirst du ganz gewaltig auf die Nase fallen. In den Headers> des Raspberry-Pico-SDK wird deswegen ausschließlich uint32_t als> Datentyp verwendet.
Genau. Und bei anderen 32-Bit µC ja auch.
Deswegen falle ich oder Du da auch gar nicht auf die Nase, weil nämlich
das
Register schon als *(volatile uint32_t*)(0x4711) o.ä. definiert ist (in
diesem Beispiel ist die Adresse des Registers 0x4711). Der Wert
des std::byte wird daher zu int promoted und dann in ein uint32_t
gewandelt.
Daher ist das schlicht falsch, was Du schreibst. Sonst würdest Du selbst
auf die Nase Fallen, wenn Du bspw. einen Wert des Typs char diesem
Register
zuweist, was Du ja machst, weil Du kein std::byte benutzt.
> Wilhelm M. schrieb:>>> Es gibt Programmiersprachen, da geht das in einer einzelnen Zeile.>>>> Ja, welche?>> Bspw. Haskell, das ist aber sicher nicht die einzige.>> Hier ist die Definition von QByte, das auf dem Word32 (entspricht> uint32_t) aus der Standardbibliothek basiert, aber einen eigenen Typ> darstellt und auf Bitfunktionen beschränkt ist.>>
Ok, wenn Du von einem entsprechenden Typ ableiten kannst: geschenkt!
Das geht natürlich dann z.B. in C++ auch (dort würde man das allerdings
wohl eher mit statischer Polymorphie als mixin lösen).
Um auf die Frage nach std::byte zurück zu kommen (s.o.): dies ist zum
einen
ein sog. vocabulary-type, und zum anderen eben ein non-arithmetic type.
Warum er anordbar ist, habe ich oben schon geschrieben.
Als vocabulary-type erhöht er eben auch die Expressivität des Codes. Ein
std::array<std::byte, 10> ist eben etwas anderes als ein
std::array<char, 10> oder ein std::array<AsciiChar, 10>. Ersteres ist
ganz klar
ein Menge von 10 Bytes (ja, nicht notwendigerweise Oktetts) mit
Zielspezifischer Bedeutung eines Bits, das zweite mag
evtl. eine Folge von Ascii-Zeichen sein, kann aber auch einfach nur
Bytes
sein, kann aber auch Ganzzahlen sein. Das dritte wiederum ist ganz klar
eine Folge von Ascii-Zeichen.
Wenn ich also per I2C ein paar Bytes an meine
RTC senden möchte, dann ist dies für die SW-Abstraktion der
HW-I2C-Schnittstelle
ganz klar eben eine Folge von Bytes (hier jetzt als Oktetts, wer
mag kann eine Zusicherung über CHAR_BIT dazu schreiben). Und die
entsprechende Elementfunktionssignatur sieht dann evtl. so aus:
Wilhelm M. schrieb:> Alexander schrieb:>> Der Thread läuft bei 255 über. bitte ein Bit. 🍺>> ... so Zeug trinke ich nicht ...
Dann muss der Thread wohl dezimal sein, und du hast ihn hiermit zum
Überlauf gebracht, weil es genau der hundertste Beitrag war. 😉
Wilhelm M. schrieb:> Yalu X. schrieb:>> Wenn von Hunderten von 32-Bit-I/O-Registern einige wenige einen oder>> mehrere 8-Bit-Teilbereich haben, dann nimmst du für diese den Typ>> std::byte, für alle anderen Register aber ganz klassisch uint32_t?>> Nein, natürlich nicht. Ich benutze schlicht die C-Header-Files> des Herstellers.
In deinem letzten Beitrag las sich das allerdings noch etwas anders:
Wilhelm M. schrieb:> Ja sicher. Ein großer Anwendungsbereich [von std::byte] ist der> Datenaustausch mit der (int. / ext.) Peripherie.Wilhelm M. schrieb:>> Oder machst du dir wirklich die Mühe, einen std::byte-ähnlichen Typ>> für 16 und 32 Bit zu schreiben?>> Natürlich nicht, ...
Das beruhigt mich. Ich dachte schon, du würdest die Header-Files
komplett umschreiben, nur damit die darin verwendeten Datentypen deiner
Philosophie entsprechen. Wobei ..., ich hätte dir das fast zugetraut ;-)
Wilhelm M. schrieb:>> newtype QByte = QByte Word32 deriving (Eq, Bits)>> Ok, wenn Du von einem entsprechenden Typ ableiten kannst: geschenkt!>> Das geht natürlich dann z.B. in C++ auch (dort würde man das allerdings> wohl eher mit statischer Polymorphie als mixin lösen).
Wie soll das gehen? Ich glaube nicht, dass C++ so etwas hergibt. Falls
doch, hätten die Entwickler von std::byte von dieser Möglichkeit sicher
Gebrauch gemacht.
Wilhelm M. schrieb:> Dahingegen ist ein Signatur wie>> void write(uint8_t adress, uint8_t data, uint32_t offset = 0);>> einfach nur Mist, weil ich ohne Compilefehler auf der Aufruferseite> die Argumente beliebig permutieren könnte (ohne es zu merken).
Nach dieser Argumentation ist der Subtraktionsoperator in C++ ebenfalls
Mist, weil die beiden Operanden permutiert werden können und deren
Reihenfolge das Ergebnis beeinflusst. Du hast deswegen sicher zwei
Wrapperklassen eingeführt, um statt
Yalu X. schrieb:> Wie soll das gehen? Ich glaube nicht, dass C++ so etwas hergibt. Falls> doch, hätten die Entwickler von std::byte von dieser Möglichkeit sicher> Gebrauch gemacht.
In meiner Realisierung sieht es in zwei Zeilen so aus so aus:
Wilhelm M. schrieb:> In meiner Realisierung sieht es in zwei Zeilen so aus so aus:>> enum class byte : uint8_t {};> template<> struct enable_bitmask_operators<byte> : true_type {};
Zwei Zeilen sind schon mal deutlich weniger als die 116 in cstddef. Aber
was ist enable_bitmask_operators? Ich kann das in der Standardbibliothek
nicht finden.
Yalu X. schrieb:> Wilhelm M. schrieb:>> In meiner Realisierung sieht es in zwei Zeilen so aus so aus:>>>> enum class byte : uint8_t {};>> template<> struct enable_bitmask_operators<byte> : true_type {};>> Zwei Zeilen sind schon mal deutlich weniger als die 116 in cstddef. Aber> was ist enable_bitmask_operators? Ich kann das in der Standardbibliothek> nicht finden.
Nein, die Meta-Funktion enable_bitmask_operators gibt es auch in der
GCC-stdlibc++ nicht. Das entstammt meiner eigenen Realisierung von
Teilen der stdlibc++ für AVR. Dort habe ich die Bit-Masken-Operationen
als Template schrieben mit der Meta-Funktion enable_bitmask_operators
als Constraint (ab C++20, davon hatte ich das mit enable_if). Damit kann
ich dann diese Operatoren mit der einen Zeile (s.o.) einem bestimmten
Datentyp hinzufügen.
Wilhelm M. schrieb:> Yalu X. schrieb:>> Wilhelm M. schrieb:>>> In meiner Realisierung sieht es in zwei Zeilen so aus so aus:>>>>>> enum class byte : uint8_t {};>>> template<> struct enable_bitmask_operators<byte> : true_type {};>>>> Zwei Zeilen sind schon mal deutlich weniger als die 116 in cstddef. Aber>> was ist enable_bitmask_operators? Ich kann das in der Standardbibliothek>> nicht finden.>> Nein, die Meta-Funktion enable_bitmask_operators gibt es auch in der> GCC-stdlibc++ nicht. Das entstammt meiner eigenen Realisierung [...]
Das ist doch die Leute veräppelt!
Kann man auch auf "Wie programmiere ich einen Roboterarm?" antworten
Johann L. schrieb:> Wilhelm M. schrieb:>> Yalu X. schrieb:>>> Wilhelm M. schrieb:>>>> In meiner Realisierung sieht es in zwei Zeilen so aus so aus:>>>>>>>> enum class byte : uint8_t {};>>>> template<> struct enable_bitmask_operators<byte> : true_type {};>>>>>> Zwei Zeilen sind schon mal deutlich weniger als die 116 in cstddef. Aber>>> was ist enable_bitmask_operators? Ich kann das in der Standardbibliothek>>> nicht finden.>>>> Nein, die Meta-Funktion enable_bitmask_operators gibt es auch in der>> GCC-stdlibc++ nicht. Das entstammt meiner eigenen Realisierung [...]>> Das ist doch die Leute veräppelt!
Nein, das ist dieselbe Qualität wie:
Yalu X. schrieb:> newtype QByte = QByte Word32 deriving (Eq, Bits)
Wilhelm M. schrieb:> Nein, das ist dieselbe Qualität wie:>> Yalu X. schrieb:>> newtype QByte = QByte Word32 deriving (Eq, Bits)
Ist es nicht.
Ob du es glaubst oder nicht: Diese Zeile ist tatsächlich alles, was man
selber schreiben muss. Es werden dafür ausschließlich Dinge aus der
offiziellen Standardbibliothek verwendet, so das auch keine zusätzlichen
Module installiert werden müssen.
Yalu X. schrieb:> Ob du es glaubst oder nicht: Diese Zeile ist tatsächlich alles, was man> selber schreiben muss. Es werden dafür ausschließlich Dinge aus der> offiziellen Standardbibliothek verwendet, so das auch keine zusätzlichen> Module installiert werden müssen.
Komisch, mein C-Compiler versteht die Zeile nicht, ist der kaputt?
Yalu X. schrieb:> Wilhelm M. schrieb:>> Nein, das ist dieselbe Qualität wie:>>>> Yalu X. schrieb:>>> newtype QByte = QByte Word32 deriving (Eq, Bits)>> Ist es nicht.>> Ob du es glaubst oder nicht: Diese Zeile ist tatsächlich alles, was man> selber schreiben muss. Es werden dafür ausschließlich Dinge aus der> offiziellen Standardbibliothek verwendet, so das auch keine zusätzlichen> Module installiert werden müssen.
Du scheinst es nicht zu kapieren: die beiden Zeilen sind auch alles. Der
Rest verbirgt sich ebenfalls in der Standardbibliothek. Deswegen ist das
qualitativ identisch.
Du kannst ja auch mal raussuchen, wie viele Zeilen in Deiner
Haskell-Bibliothek dafür benötigt werden. Aber das ist auch irrelevant.
Genauso ist es irrelevant, wie viele Zeilen in meiner Realisierung der
Standard-Bibliothek für meine Realisierung benötigt werden. Ja, ich habe
es eben anders gemacht, als in der aktuellen Version der StdLibC++. Ob
das jetzt besser oder schlechter ist als in der offiziellen Version,
weiß ich nicht. Aber es war für mich sinnvoller. Und warum habe ich das
gemacht: weil es für AVR nun mal keine StdLibC++ gibt.
Und hier mal der Library-Code:
Das entspricht genau dem, was ich oben in Prosa geschrieben habe. Jeder,
der auch nur ein wenig darüber nachgedacht hat, hätte das aus meinen
Worten direkt so hinschreiben können, wenn er denn etwas von modernem
C++ versteht.
Klaus schrieb:> Komisch, mein C-Compiler versteht die Zeile nicht, ist der kaputt?
Der Thread ist mittlerweile stark von der eigentlichen Frage (die
bereits vollständig beantwortet wurde) wegdiffundiert. Die Diskussion
ging über das von Wilhelm ins Spiel gebrachte std::byte über einen
entsprechenden 32-Bit-Datentyp bis hin zur Frage, wie ein solcher Typ
implementiert werden kann. Dass dies ist in C++ zwar möglich, aber recht
aufwendig ist, führte zu folgender Frage:
Yalu X. schrieb:> Wilhelm M. schrieb:>>> Es gibt Programmiersprachen, da geht das in einer einzelnen Zeile.>>>> Ja, welche?>> Bspw. Haskell, das ist aber sicher nicht die einzige.
C war ohnehin kein Thema des Threads, weder am Anfang noch danach.
Klaus schrieb:> Yalu X. schrieb:>> Ob du es glaubst oder nicht: Diese Zeile ist tatsächlich alles, was man>> selber schreiben muss. Es werden dafür ausschließlich Dinge aus der>> offiziellen Standardbibliothek verwendet, so das auch keine zusätzlichen>> Module installiert werden müssen.>> Komisch, mein C-Compiler versteht die Zeile nicht, ist der kaputt?
Es ist ja auch Haskell. Stand ein paar Postings drüber.
Apropos: das C++ das Arduino standardmäßig verwendet, versteht auch kein
C-Compiler. Nur um dich vor Enttäuschungen zu bewahren...
Wilhelm M. schrieb:> Du scheinst es nicht zu kapieren: die beiden Zeilen sind auch alles. Der> Rest verbirgt sich ebenfalls in der Standardbibliothek. Deswegen ist das> qualitativ identisch.
Jetzt machst du dich aber wirklich lächerlich. Ich darf dich zitieren:
Wilhelm M. schrieb:> template<> struct enable_bitmask_operators<byte> : true_type {};Wilhelm M. schrieb:> Nein, die Meta-Funktion enable_bitmask_operators gibt es auch in der> GCC-stdlibc++ nicht.
Yalu X. schrieb:> Wilhelm M. schrieb:>> Du scheinst es nicht zu kapieren: die beiden Zeilen sind auch alles. Der>> Rest verbirgt sich ebenfalls in der Standardbibliothek. Deswegen ist das>> qualitativ identisch.>> Jetzt machst du dich aber wirklich lächerlich. Ich darf dich zitieren:>> Wilhelm M. schrieb:>> template<> struct enable_bitmask_operators<byte> : true_type {};>> Wilhelm M. schrieb:>> Nein, die Meta-Funktion enable_bitmask_operators gibt es auch in der>> GCC-stdlibc++ nicht.
Ich glaube Dir fehlt einfach der Kaffee heute morgen ;-) Streng noch mal
ein bisschen an, und Du wirst es schon verstehen ...
Ja, das ist der nächste Schritt..
Andere für blöd erklären!
Auch wie gehabt... längst nicht das erste mal.
Fachlich mag ihn es ja auf dem Schirm haben, aber menschlich deutlich
unter dem Niveau einer Bordsteinkante.
Gestern habe ich einen Post von mir gelöscht, weil ich nicht so offensiv
sein wollte.
Leider hat er sich mehr als bewahrheitet!
Hier das gelöschte Original:
Betreff: Re: for-Schleife - Bit verschieben
Datum: 18.08.2023 15:23
Der gelöschte Beitrags:
==============================================
Yalu X. schrieb:> Aber was ist enable_bitmask_operators?
Sowas frage ich ihn gar nicht mehr....
Denn davon ernährt er sich mental. Ist alle male eine Gelegenheit für
ihn, sich herablassend zu geben.
Wilhelm M. schrieb:> Du scheinst es nicht zu kapieren: die beiden Zeilen sind auch alles. Der> Rest verbirgt sich ebenfalls in der Standardbibliothek. Deswegen ist das> qualitativ identisch.
Irgendwie widersprichst du dir selber. Einmal sagst du, es ist Teil
einer von dir selbst geschriebenen Bibliothek, dann wieder ist es Teil
der Standardbibliothek. Einmal schreibst du, die beiden Zeilen sind das
einzige, was man braucht, dann schreibst du eine Reihe weiterer Zeilen
hin, die offenbar auch nötig sind.
Auch im aktuellsten Draft vom Standard gibt eine Suche nach
'enable_bitmask_operators' keine Ergebnisse. Also vielleicht bist du es,
dem er Kaffee fehlt.
Wilhelm M. schrieb:> Ich glaube Dir fehlt einfach der Kaffee heute morgen ;-) Streng noch mal> ein bisschen an, und Du wirst es schon verstehen ...
Um deinen wirren Gedankengänge folgen zu können, bedarf es weit härterer
Drogen als Koffein ;-)
Rolf M. schrieb:> Wilhelm M. schrieb:>> Du scheinst es nicht zu kapieren: die beiden Zeilen sind auch alles. Der>> Rest verbirgt sich ebenfalls in der Standardbibliothek. Deswegen ist das>> qualitativ identisch.>> Irgendwie widersprichst du dir selber. Einmal sagst du, es ist Teil> einer von dir selbst geschriebenen Bibliothek, dann wieder ist es Teil> der Standardbibliothek.
Du kannst auch nicht lesen, oder willst es nicht. Lies den folgenden
Absatz nochmal:
Wilhelm M. schrieb:> Genauso ist es irrelevant, wie viele Zeilen in meiner Realisierung der> Standard-Bibliothek für meine Realisierung benötigt werden. Ja, ich habe> es eben anders gemacht, als in der aktuellen Version der StdLibC++. Ob> das jetzt besser oder schlechter ist als in der offiziellen Version,> weiß ich nicht. Aber es war für mich sinnvoller. Und warum habe ich das> gemacht: weil es für AVR nun mal keine StdLibC++ gibt.
Und davor habe ich sogar geschrieben:
Wilhelm M. schrieb:> Nein, die Meta-Funktion enable_bitmask_operators gibt es auch in der> GCC-stdlibc++ nicht. Das entstammt meiner eigenen Realisierung von> Teilen der stdlibc++ für AVR. Dort habe ich die Bit-Masken-Operationen> als Template schrieben mit der Meta-Funktion enable_bitmask_operators> als Constraint (ab C++20, davon hatte ich das mit enable_if). Damit kann> ich dann diese Operatoren mit der einen Zeile (s.o.) einem bestimmten> Datentyp hinzufügen.
Fassen wir nochmal zusammen:
1) Für den AVR gibt es keine Realisierung der Standardbibliothek (ist
allg. bekannt).
2) Ich habe eine Realisierung der Standardbibliothek in Teilen
geschrieben.
3) Die Standardbibliothek ist bekanntermaßen eine
Schnittstellenbeschreibung, keine Implementierungsbeschreibung, wie auch
der gesamte Sprachstandard keine Implementierungsbeschreibung ist.
4) Eine Realisierung einer Schnittstellenbeschreibung muss mindestens
die Elemente der Beschreibung realisieren, hat aber üblicherweise weit
mehr Anteile.
5) Dies gilt für die GNU-C++-Standardbibliothek wie auch für meine
Realisierung.
6) In meiner Realisierung gibt es die Meta-Funktion
enable_bitmask_operators (s.o.). Der Name ist selbsterklärend.
7) In der GNU-C++-Standardbibliothek sind die Bit-Masken-Operatoren für
std::byte anders realisiert. Yalu X. findet die 116 Zeilen schrecklich,
sagt aber auch nicht, wie es intern in Haskell realisiert ist.
8) Meine Realisierung des Typs std::byte umfasst zwei Zeilen, und greift
dabei auf andere Komponenten meiner Realisierung der Standardbibliothek
zurück.
9) Yalu X. legt nicht offen, wie intern in Haskell die Typen Bit oder Eq
oder die Vererbungsbeziehung aufgebaut sind, bzw. was die sonst noch
alles benötigen.
10) Was in meiner Realisierung für die Bit-Masken-Operatoren noch nötig
habe ich ebenfalls geschrieben. In dem Beitrag heißt es "Und hier mal
der Library-Code:"
Wenn Du das jetzt einmal alles zusammen nimmst, dann ist es doch klar,
und selbst Yalu X. hatte das schon erkannt, dass es in der
Standardbibliothek keine Meta-Funktion enable_bitmask_operators gibt.
Daher ist es komplett sinnlos, dies nochmals zu versuchen zu finden:
> Auch im aktuellsten Draft vom Standard gibt eine Suche nach> 'enable_bitmask_operators' keine Ergebnisse. Also vielleicht bist du es,> dem er Kaffee fehlt.
Entweder wollt Ihr nicht verstehen oder Ihr könnt es einfach nicht. Oder
es fehlen Euch einfach die Grundlagen. Aber das ist nicht mein Problem
(so oder ähnlich kommt es ja auch von Euch, wenn jemand für Euch simple
Dinge nicht auf dem Schirm hat). Also, haltet mal den den Ball flach mit
Euren Beschimpfungen (v.a. Arduino F).
Wilhelm M. schrieb:> 6) In meiner Realisierung gibt es die Meta-Funktion> enable_bitmask_operators (s.o.).
Und wen interessiert das?
...außer dich natürlich
Wilhelm M. schrieb:> Fassen wir nochmal zusammen:
Du betreibst einen nicht unerheblichen Aufwand in die Entwicklung einer
Bibliothek.
Und um zu zeigen, wie einfach du das bei dir ist ("zwei Zeilen!"),
unterschlägst du eben diesen Aufwand.
Das hat in der Tat exakt die gleiche Qualität wie
Johann L. schrieb:> Das ist doch die Leute veräppelt!> Kann man auch auf "Wie programmiere ich einen Roboterarm?" antworten>> RoboterArm arm;>> arm.moveRight (10_cm);Wilhelm M. schrieb:> Entweder wollt Ihr nicht verstehen oder Ihr könnt es einfach nicht. Oder> es fehlen Euch einfach die Grundlagen.
Jawohl Herr Arroganz!
> Also, haltet mal den den Ball flach mit> Euren Beschimpfungen
Glashaus, Steine.
Vielleicht sollten wir est mal Einigkeit darüber haben, was denn die
Frage war. Die war, wie man ausschließlich mit Mitteln der
Standardblibliothek in zwei Zeilen einen Typ definieren kann, der alle
Vergleichsoperatoren besitzt, aber keine anderen arithmetischen
Operatoren wie z.B. Addition.
Wilhelm M. schrieb:> 1) Für den AVR gibt es keine Realisierung der Standardbibliothek (ist> allg. bekannt).> 2) Ich habe eine Realisierung der Standardbibliothek in Teilen> geschrieben.> 3) Die Standardbibliothek ist bekanntermaßen eine> Schnittstellenbeschreibung, keine Implementierungsbeschreibung, wie auch> der gesamte Sprachstandard keine Implementierungsbeschreibung ist.> 4) Eine Realisierung einer Schnittstellenbeschreibung muss mindestens> die Elemente der Beschreibung realisieren, hat aber üblicherweise weit> mehr Anteile.> 5) Dies gilt für die GNU-C++-Standardbibliothek wie auch für meine> Realisierung.
Diese Punkte sind für die obige Frage allesamt nicht relevant. Es ging
weder um AVR, noch um spezifische Implementationen der
Standardbibliothek.
> 6) In meiner Realisierung gibt es die Meta-Funktion> enable_bitmask_operators (s.o.). Der Name ist selbsterklärend.
Das macht sie aber nicht zu einem Teil des Standards. "Mit Mitteln der
Standardbibliothek" heißt, dass man die im Standard definierten
Schnittstellen nutzt und nicht irgendwelche Implementationsdetails einer
spezifischen Umsetzung davon.
> 7) In der GNU-C++-Standardbibliothek sind die Bit-Masken-Operatoren für> std::byte anders realisiert. Yalu X. findet die 116 Zeilen schrecklich,> sagt aber auch nicht, wie es intern in Haskell realisiert ist.
Das lag ja hauptsächlich daran, dass er nicht std::byte wollte, sondern
etwas äquivalentes für 32 Bit. C++ bietet so etwas nicht, also muss er
es sich in seinem Programm selbst definieren. In Haskell bräuchte er
seiner Aussage nach dafür rein auf Standard-Schnittstellen basierend nur
eine Zeile und keine 116. Du hast jetzt behauptet, das ginge in C++ in
zwei Zeilen, setzt dafür aber auf deine Implementation auf und nutzt
Funktionalitäten, die der Standard so nicht bietet.
Er wird sowas abgesehen davon vermutlich auch nicht für AVR brauchen,
denn der hat eher wenige 32-Bit-Register. Damit kann er dann eh nicht
auf deine AVR-Umsetzung der Standardbibliothek zurückgreifen.
> 8) Meine Realisierung des Typs std::byte umfasst zwei Zeilen, und greift> dabei auf andere Komponenten meiner Realisierung der Standardbibliothek> zurück.
Genau, deiner Realisierung. Die ist aber so vom Standard nicht
garantiert.
> 9) Yalu X. legt nicht offen, wie intern in Haskell die Typen Bit oder Eq> oder die Vererbungsbeziehung aufgebaut sind, bzw. was die sonst noch> alles benötigen.
Das ist auch wiederum nicht relevant, für die Frage, wie man sich
mangels Standard-Typ selbst so einen Typ definiert.
> 10) Was in meiner Realisierung für die Bit-Masken-Operatoren noch nötig> habe ich ebenfalls geschrieben. In dem Beitrag heißt es "Und hier mal> der Library-Code:"
Ebenfalls nicht relevant, denn das liegt eben außerhalb von "zwei
Zeilen".
Rolf M. schrieb:> Diese Punkte sind für die obige Frage allesamt nicht relevant. Es ging> weder um AVR,
Doch doch genau darum ging es in der Eingangsfrage.
Rolf M. schrieb:> Die war, wie man ausschließlich mit Mitteln der> Standardblibliothek in zwei Zeilen einen Typ definieren kann, der alle> Vergleichsoperatoren besitzt, aber keine anderen arithmetischen> Operatoren wie z.B. Addition.
Nein.
Es sollte ein Byte geschoben werden.
Unsern Wilhelm hat das alles nicht interessiert.
Ihm will nur mit seinem Kram einen auf dicke Hose machen und alle
anderen zu Dummköpfe erklären
Narzisstisches Gehabe...
Arduino F. schrieb:> Rolf M. schrieb:>> Diese Punkte sind für die obige Frage allesamt nicht relevant. Es ging>> weder um AVR,> Doch doch genau darum ging es in der Eingangsfrage.
Du weißt sehr wohl, dass wir in dem Thread schon lange nicht mehr über
die Eingangsfrage diskutieren, da die schon früh zur Zufriedenheit des
Fragestellers beantwortet wurde. Also tu nicht so, als wäre dir das
nicht klar.
Arduino F. schrieb:> Rolf M. schrieb:>> Diese Punkte sind für die obige Frage allesamt nicht relevant. Es ging>> weder um AVR,> Doch doch genau darum ging es in der Eingangsfrage.
Rischtisch!
>> Rolf M. schrieb:>> Die war, wie man ausschließlich mit Mitteln der>> Standardblibliothek in zwei Zeilen einen Typ definieren kann, der alle>> Vergleichsoperatoren besitzt, aber keine anderen arithmetischen>> Operatoren wie z.B. Addition.>> Nein.> Es sollte ein Byte geschoben werden.
Rischtisch!
> Unsern Wilhelm hat das alles nicht interessiert.
Falsch!
Genau das hat mich interessiert.
Was hier geschoben werden sollte, war eine Sammlung von Bits (8-Bits),
und es sollte nicht eine Ganzzahl durch 2 dividiert werden.
Ja, und ich wollte auf die völlige Sinnfreiheit der Deklaration des Typs
byte bei Arduino aufmerksam machen.
Wilhelm M. schrieb:> Fassen wir nochmal zusammen:>> ...>> 4) Eine Realisierung einer Schnittstellenbeschreibung muss mindestens> die Elemente der Beschreibung realisieren,
Richtig.
> hat aber üblicherweise weit mehr Anteile.
Ob das in C++ erlaubt oder nur schlechter Stil ist, kann ich nicht genau
sagen, weil der C++-Standard diesbezüglich wenig explizit ist. In C wäre
die Einführung des öffentlichen Identifiers "enable_bitmask_operators"
in der Standardbibliothek definitiv nicht zulässig.
> 6) In meiner Realisierung gibt es die Meta-Funktion> enable_bitmask_operators (s.o.). Der Name ist selbsterklärend.
Wenn du enable_bitmask_operators nur innerhalb der Standardbibliothek
verwendest, um std::byte zu definieren, und der Identifier nach außen
nicht sichtbar ist, ist das völlig in Ordnung. Allerdings nützt sie dann
dem Anwendungsprogrammierer, der neue, std::byte-ähnliche Datentypen
definieren möchte, auch nichts.
> Yalu X. findet die 116 Zeilen schrecklich,
Nein, ich finde sie nicht schrecklich, da sie bereits existieren und ich
sie normalerweise gar nicht zu Gesicht bekomme. Ich finde es nur
schrecklich, dass ich, wenn ich neue std::byte-ähnliche Datentypen
definieren möchte, diese 116 Zeilen in leicht abgewandelter Form selber
noch einmal eintippen muss (egal, ob als Teil eines Anwendungsprogramms
oder als Erweiterung der Standardbibliothek).
> sagt aber auch nicht, wie es intern in Haskell realisiert ist.
Das ist für mich genauso irrelevant wie die interne Definition von
std::byte. Solange ich nicht gezwungen bin, denselben Code noch einmal
für meine eigenen Datentypen einzutippen, stört mich das überhaupt
nicht.
> ...
Vielleicht verstehst du meine Kritik besser, wenn wir das Ganze aus der
Perspektive des Anwendungsprogrammierers betrachten:
Ausgangssituation:
Ich möchte ein Anwendungsprogramm in C++ schreiben. In diesem
Anwendungsprogramm brauche ich einen 32-Bit-Datentyp, auf den ich
ausschließlich Bit-Operationen ausführen möchte. Klar kann ich dafür
uint32_t verwenden, und das Problem ist sofort gelöst.
Dein Einwand:
Für dich ist das Problem damit noch nicht gelöst, was die Diskussion
über std::byte & Co auslöste.
Du empfindest die Verwendung von Bit-Operationen auf uint*_t als
schlechten Stil mit der Begründung, dass uint*_t eigentlich Zahlen
(Integers) repräsentiert, Bit-Operationen aber auf Bit-Tupeln definiert
sind. Deswegen sollte deiner Ansicht nach statt uint*_t ein Typ
verwendet werden, der keine numerischen Rechenoperationen wie +, -, *
und /, sondern ausschließlich Bit-Operationen erlaubt. Ich kann diese
Begründung durchaus nachvollziehen (zumindest ein ganz kleines
Bisschen).
Was nun zu tun ist:
Da der gewünschten Datentyp für 32 Bit noch nicht existiert, werde ich
ihn wohl selber irgendwie definieren müssen. Um eine Vorlage zu
erhalten, wie dies geschehen könnte, schaue ich mir die Definition von
std::byte im Header cstddef von GCC an und finde dort 116 Zeilen Code.
Ich könnte diesen Code natürlich abschreiben und und ihn dabei so
modifizieren, dass er für die gewünschten 32 Bit passt.
Warum mir das widerstrebt:
Es geht mir ja nicht darum, einen völlig neuen Datentyp mit völlig
neuen Operationen zu kreieren. Ich möchte lediglich ein Ebenbild eines
bereits existierenden Typs (uint32_t) schaffen und dabei einige
Operationen weglassen. Deswegen frage ich mich, wieso das simple
Weglassen von Operationen in einer Sprache die sich das Thema
Code-Reuse auf die Fahnen geschrieben hat, so viele Codezeilen
erfordert. Ok, vielleicht ist das eine Art sprachübergreifendes
Naturgesetz, und es geht generell nicht besser. Interessehalber schaue
ich kurz nach, wie das Problem in anderen Programmiersprachen gelöst
wird, und stelle fest, dass man in Haskell dafür nur eine einzige Zeile
braucht.
Mögliche Alternativen:
Vielleicht sind die Entwickler von GCC ja alle Anfänger, und es gibt
eine wesentlich kürzere Definition von std::byte und ähnlichen Typen.
"Ja, gibt es", behauptest du, "definiere den neuen Typ doch einfach mit
enable_bitmask_operators, dann brauchst du nur zwei Zeilen". Dumm nur,
dass es diese Funktion noch nirgends gibt, weswegen ich sie selber
schreiben müsste. Ich müsste also
2 + die Anzahl der Zeilen von enable_bitmask_operators
schreiben, um den neuen Datentyp zu definieren. Habe ich damit etwas
gewonnen? Nein, denn ich muss mir nach wie vor die Finger wundtippen.
Vielleicht sollte ich stattdessen auf deine private "Standardbibliothek"
zurückgreifen, die neuerdings (wohl getrieben durch die Diskussion in
diesem Thread) als Erweiterung zum offiziellen Standard auch die
Metafunktion enable_bitmask_operators enthält. Aber selbst wenn du deine
Bibliothek veröffentlichen würdest, wäre die Verwendung der Funktion
dennoch unklug, weil sie die Portabilität zunichte machen würde und das,
obwohl sie keinerlei Hardwarebezug zum AVR hat.
Damit sind IMHO sämtliche Alternativen erschöpft und es bleibt die
Wahl, entweder
- den langwierigen Code selber zu schreiben oder
- auf den neuen Datentyp zu verzichten und beim bewährten uint32_t zu
bleiben.
IMHO gewinnt bei einem Kosten-Nutzen-Vergleich ganz klar die zweite
Option ;-)
Noch eine Anmerkung zum Nutzen von enable_bitmask_operators:
Diese Metafunktion erfüllt zwar ihren Zweck, ist aber sehr spezifisch
auf die vorliegende Problematik zugeschnitten. Was ist, wenn ich das
Gegenstück von Byte benötige, also einen Datentyp, der nur numerische
Operationen zulässt? Dann müsste ich in C++ ich eine zweite Metafunktion
namens enable_numeric_operators schreiben, die ähnlich lang wie
enable_bitmask_operators sein dürfte.
Auch hier zeigt Haskell seine Stärken. Hier ist die Implementierung
eines rein numerische 8-Bit-Integer-Typs in zwei Varianten:
1. Ohne Division (eine echte Division ohnehin ist nicht möglich, weil
für Ganzzahlen die Multiplikation mit einer Zahl nicht invertierbar
ist):
Natürlich funktioniert das newtype und das Beerben von Klasseninstanzen
nicht nur für vordefinierten Typen und Klassen der Standardbibliothek,
sondern auch für beliebige selbst geschrieben Typen und Klassen.
Schon in solch einfachen Beispielen zeigt sich die Mächtigkeit des
Typsystems von Haskell, das – obwohl flexibler als in C++ – nicht nur
viele Programmierfehler schon beim Kompilieren aufdeckt, sondern auch
die Wiederverwendung von Code enorm erleichtert. Im Gegensatz dazu
basiert das Typsystem von C++ aus Kompatibilitätsgründen immer noch auf
dem von C aus den 70ern, kombiniert dieses mit dem aus einigen Makro-
und Skriptsprachen bekannten Duck-Typing und erbt von beiden vor allem
die Nachteile.
Ok, ich sehe mittlerweile ein, dass man mit C oder C++ auf µC auf der
vollkommen falschen Spur ist.
Da ich Haskell nicht wirklich kenne, möchte ich das ursprüngliche
Problem des TO nun einmal in Haskell auf einem Arduino Uno als
bare-metal nachvollziehen. Was muss ich tun bzw. der TO dazu tun. Wie
muss man die IDE für Haskell konfigurieren? Ich konnte kein HowTo
finden.
Was für ein absurdes Strohmann Argument, mal wieder....
Sach mal, du aufgeblasenes "Ding":
Wie viele Entwickler haben in DE-Land einen AVR-GCC mit aktivierten
concepts und Eigenbau libstdc++ im praktischen Einsatz?
Mehr als 5?
Oder eher so null bis zwei?
Arduino F. schrieb:> Wie viele Entwickler haben in DE-Land einen AVR-GCC mit aktivierten> concepts und Eigenbau libstdc++ im praktischen Einsatz?
Och, weder C++20 oder concepts oder libstdc++ sind dafür notwendig.
Es reicht eine gescheite Deklaration von byte oder arduino::byte in der
großen Arduino-Bibliothek.
Wilhelm M. schrieb:> Es reicht eine gescheite Deklaration von byte oder arduino::byte in der> großen Arduino-Bibliothek.
Ja, dann los!
Was hält dich auf?
Das einspielen in den Arduino Core dauert 5 Minuten, wenn man etwas
Übung hat. Mit etwas Glück und einer Begründung incl. Doku wird das gar
übernommen.
Als Lib wird es sofort akzeptiert.
Wilhelm M. schrieb:> Ok, ich sehe mittlerweile ein, dass man mit C oder C++ auf µC auf der> vollkommen falschen Spur ist.> Da ich Haskell nicht wirklich kenne, möchte ich das ursprüngliche> Problem des TO nun einmal in Haskell auf einem Arduino Uno als> bare-metal nachvollziehen.
Jetzt spiel nicht die beleidigte Leberwurst.
Ich habe nirgends behauptet, dass Haskell für kleine Mikrocontroller
(wie bspw. den AVR) die bessere Programmiersprache ist (es gibt ja nicht
einmal einen Compiler dafür :)). Ich habe nur behauptet, dass die von
dir vorgeschlagene Definition von std::byte-ähnlichen Datentypen in C++
gemessen am Nutzen sehr aufwendig ist und dass dies mit einer anderen
Programmiersprache mit einem fortschrittlicheren Typsystem sehr viel
leichter vonstatten geht.
Ein Typsystem mit den entsprechenden Eigenschaften wäre durchaus auch in
einer Programmiersprache für Mikrocontroller denkbar und würde neben den
hier diskutierten noch viele weitere Vorteile bieten. Bspw. zeigt Rust
zumindest ansatzweise schon in die richtige Richtung.
Deine Bestrebungen, mit Templates, Metaprogrammierung und dergleichen zu
zeigen, was C++ auch im Bereich der Mikrocontrollerprogrammierung
leisten kann, finde ich durchaus interessant. Leider muss ich bei
näherem Hinsehen oft feststellen, dass die von dir propagierten Vorteile
nicht out-of-the-box verfügbar, sondern mit einem unverhältnismäßig
hohen Schreibaufwand verbunden sind. Um dies nicht so sehr durchscheinen
zu lassen, veröffentlichst du hier meist nur die wenigen Codezeilen, die
zeigen, wie deine vorgestellten Programmiertechniken angewandt werden
können, aber fast nie den sehr viel umfangreicheren Code, der hierfür
vorab implementiert werden muss.
Es ist deswegen kein Wunder, dass sich immer mehr Leser von dir abwenden
und, statt deine C++-Vorschläge nachzuvollziehen, ganz pragmatisch beim
altgewohnten C bleiben.
Ich habe meine früheren Experimente mit C++ auf Mikrocontrollern
inzwischen auch komplett eingestellt, und auch auf PCs verwende ich C++
nur noch, wenn in irgendeiner Form ein äußerer Zwang dazu besteht.
Arduino F. schrieb:> Wilhelm M. schrieb:>> Es reicht eine gescheite Deklaration von byte oder arduino::byte in der>> großen Arduino-Bibliothek.>> Ja, dann los!> Was hält dich auf?
... ich nutze den Arduino-Kram nicht.
> Als Lib wird es sofort akzeptiert.
Kann ich mir kaum vorstellen, wenn nicht einmal Du den Nutzen erkennen
kannst. Und falls es doch akzeptiert würde, ohne das jemand den Nutzen
erkennt, dann wäre es weiteres Zeichen für die Sorgfalt im
Arduino-Projekt.
Yalu X. schrieb:> Wilhelm M. schrieb:>> Ok, ich sehe mittlerweile ein, dass man mit C oder C++ auf µC auf der>> vollkommen falschen Spur ist.>> Da ich Haskell nicht wirklich kenne, möchte ich das ursprüngliche>> Problem des TO nun einmal in Haskell auf einem Arduino Uno als>> bare-metal nachvollziehen.>> Jetzt spiel nicht die beleidigte Leberwurst.
???
Ich bin überaus gut gelaunt ...
> Ich habe nirgends behauptet, dass Haskell für kleine Mikrocontroller> (wie bspw. den AVR) die bessere Programmiersprache ist (es gibt ja nicht> einmal einen Compiler dafür :)). Ich habe nur behauptet, dass die von> dir vorgeschlagene Definition von std::byte-ähnlichen Datentypen in C++> gemessen am Nutzen sehr aufwendig ist und dass dies mit einer anderen> Programmiersprache mit einem fortschrittlicheren Typsystem sehr viel> leichter vonstatten geht.
Genau.
Und es ist daher vollkommen irrelevant, ob das mit Haskell kürzer geht,
weil es einfach für µC nicht anwendbar ist.
> Ein Typsystem mit den entsprechenden Eigenschaften wäre durchaus auch in> einer Programmiersprache für Mikrocontroller denkbar und würde neben den> hier diskutierten noch viele weitere Vorteile bieten. Bspw. zeigt Rust> zumindest ansatzweise schon in die richtige Richtung.
Richtig. Aber das war bislang noch nicht im Fokus in diesem Thread.
Genauso wie vermutlich viele andere Sprachen, die einfach auf vielen µC
mangels Compiler nicht anwendbar sind. Deswegen war Dein Hinweis auf
Haskell zwar grundsätzlich interessant, aber in diesem Thread ein dicke
Nebelkerze.
Wobei der GHC ja C-Code als IL produzieren kann ...
> Deine Bestrebungen, mit Templates, Metaprogrammierung und dergleichen zu> zeigen, was C++ auch im Bereich der Mikrocontrollerprogrammierung> leisten kann, finde ich durchaus interessant. Leider muss ich bei> näherem Hinsehen oft feststellen, dass die von dir propagierten Vorteile> nicht out-of-the-box verfügbar, sondern mit einem unverhältnismäßig> hohen Schreibaufwand verbunden sind. Um dies nicht so sehr durchscheinen> zu lassen, veröffentlichst du hier meist nur die wenigen Codezeilen, die> zeigen, wie deine vorgestellten Programmiertechniken angewandt werden> können, aber fast nie den sehr viel umfangreicheren Code, der hierfür> vorab implementiert werden muss.
Das ist bei allen Bibliotheken so. Der Aufwand steckt immer in den
Bibliotheken oder in versteckten Ecken der Sprache selbst. Und es ist
ungleich schwieriger, guten Bibliothekscode zu schreiben als in der
Applikationsebene. Deswegen ist Arduino eben so wie es ist.
Ich möchte Anregungen geben, keine Libraries (Lebenswerke) verteilen.
> Es ist deswegen kein Wunder, dass sich immer mehr Leser von dir abwenden> und, statt deine C++-Vorschläge nachzuvollziehen, ganz pragmatisch beim> altgewohnten C bleiben.
Damit habe ich kein Problem ;-)
Jeder soll es nach seinem Wissen und Können machen. Allerdings ist dies
hier ein Diskussionsforum, in dem ich weiterhin fröhlich meine Meinung
äußern werde ;-)
So, wie ich auch immer wieder auf die kleinen Goodies von C++ im
Vergleich zu C (nicht Haskell) oder schlechten Abstraktionen in
C++-Framworks hinweisen werde. Und ja, wer sich tatsächlich ernsthafter
mit C++ auseinander setzen will, der kommt an Metaprogrammierung nicht
vorbei. Sind die Grundlagen erst einmal verstanden, ist der Rest einfach
(auch wenn die Syntax geschwätzig ist). Denn die Möglichkeit einer
Typalgebra ist ein wesentliches Kernstück von C++ und unterscheidet C++
von C oder ASM.
Dazu und zur allgemeineren Empörung ein "Leitsatz", der zugespitzt für
den ambitionierten Umsteiger hilfreich sein kann: "Primitive Datentypen
sind nur dazu da, nicht benutzt zu werden."
> Ich habe meine früheren Experimente mit C++ auf Mikrocontrollern> inzwischen auch komplett eingestellt, und auch auf PCs verwende ich C++> nur noch, wenn in irgendeiner Form ein äußerer Zwang dazu besteht.
Das ist mir auch recht. Du bist (hoffentlich) ein freier Mann ;-)
Wenn ich das richtig verstehe:
Du nutzt Arduino nicht und willst das auch nicht nutzen.
Du weißt wie man sowas baut.
Arduino ist eine Open Source Geschichte, so gebaut, dass jeder
Verbesserungen/Features einpflegen kann.
Das willst du offensichtlich nicht.
Aber schimpfst wie ein Rohrspatz und nörgelst an dem bestehenden rum.
Dir ist sicher klar, wie man Leute nennt, die an allem rum nörgeln, aber
an keiner Verbesserung interessiert sind!
Tipp:
Der Volksmund kennt da genügend Begriffe.
Leider merkst du nicht, wie antisozial dein Verhalten ist.
Selbst wenn man es dir sagt, kommt es nicht an.
Wilhelm M. schrieb:> Kann ich mir kaum vorstellen,
Bist halt voll der Checker.
Arduino F. schrieb:> Wenn ich das richtig verstehe:> Du nutzt Arduino nicht und willst das auch nicht nutzen.
Rischtisch.
Und das weißt Du doch schon lange.
> Du weißt wie man sowas baut.
Vielleicht.
> Arduino ist eine Open Source Geschichte, so gebaut, dass jeder> Verbesserungen/Features einpflegen kann.
OpenSource lebt davon, dass Leute sich beteiligen, weil sie selbst davon
wieder einen Nutzen haben.
> Das willst du offensichtlich nicht.
Genau (s.9., weil ich mangels Nutzung keinen Nutzen daraus habe.
> Aber schimpfst wie ein Rohrspatz und nörgelst an dem bestehenden rum.
Ich "nörgele" sogar an käuflichen "Produkten" herum, an deren
Entwicklung ich gar nicht beteiligt war ;-) Genauso wie Du.
> Dir ist sicher klar, wie man Leute nennt, die an allem rum nörgeln, aber> an keiner Verbesserung interessiert sind!
Falsch: wie Du siehst, bin ich an einer Verbesserung sogar interessiert,
allerdings muss ich ja nicht alles selbst machen, oder.
Mach Du das doch, wenn es so einfach ist. Die Lösung findest Du doch
sogar in diesem Thread fertig. Und Du als Nutzer hast sogar einen Nutzen
davon.
> Leider merkst du nicht, wie antisozial dein Verhalten ist.
Du möchtest einfach keine Kritik hören an Deinem Arduino-Kram. Deswegen
wirst Du auch mal ausfällig (s.o.):
Arduino F. schrieb:> Oder Schlimmer: Darauf holt der sich einen runter.