Habe mit dem GateMate FPGA etwas mehr gespielt, hier die Resultate 1) RISC-V mit microcode engine (engine-V code): 1270 CPE, max clock 43MHz design läuft, da kommt das Zephyr RTOS Philosophers ausgang aus dem UART raus. 1K16 microcode ROM und 32Kbyte emulator RAM richtig erkannt. 2) Claire Wolfs PicoRV32 mit default einstellungen: 4730 CPE, max clock 14MHz 3) Claire Wolfs PicoRV32 ohne barrelshift, ohne mul/div: 3800 CPE, max clock 21MHz PicoRV32 konnte ich nicht testen, keine passende firmware :( ROM wurde erkannt. 4) InstantSoC mit UART TX 6880 CPE, 19MHz, hier wurde der ROM aus CPE gebaut, deswegen soviele CPE.. Yosys kann leider den InstantSoC generierten SystemVerilog nicht fressen, habe mit sv2v ins verilog transliert wobei ich eine zeile manuell konvertieren müsste. Und leider funktioniert das translierte verilog nicht (auch nicht auf AMD FPGA), dh den InstantSoC kontte auf dem FPGA auch nicht testen. Kurz: GateMate FPGA und tools laufen schon, aber wenn das Design etwas grösser wird geht max Clock schon schnell runter. Um mehrfache kleiner als bei sagen wir Spartan-7.
Antti L. schrieb: > 1) RISC-V mit microcode engine (engine-V code): > 1270 CPE, max clock 43MHz design läuft, da kommt das Zephyr RTOS > Philosophers ausgang aus dem UART raus. 1K16 microcode ROM und 32Kbyte > emulator RAM richtig erkannt. Ist da echtes TDP RAM mit dabei? Die Mapping-Resultate der Synthese (vor und nach dem technology mapping auf die Zielarchitektur) waeren interessant. 1270 ist ganz gut, wenn das eine pipelined Architektur ist.
Zum Vergleich: Hier läuft auf einem Artix-7 ein RISC-V-SoC mit CV32E40P CPU (32-bit, 4 pipeline stages), Interconnect, 128kB BlockRAM, Bootrom, AXI4-Bridge, DDR3-Controller, APB-Bridge, UART, I2C, SPI usw. mit 50Mhz, ziemlich auf Kante genäht, aber auch ohne irgendwelche Optimierungen im Design.
Vancouver schrieb: > Artix-7 ... mit 50Mhz, Hm, was ist denn da die Bremse? AXI voll asynchron oder ist es der Proz? Den RISC kenne ich nicht, aber ein praktisch voll ausgebauter 100er Artix mit DDR und ähnlichen Innereien, dazu S/PDIF und einem Haufen Signalverarbeitung dudelt hier auf fast 200 - mit etwas Nachhilfe durch FFs an den richtigen Stellen. 50MHz ist eher so das, was ich vor 15 Jahren mit dem NIOS und dem Cyclone III hatte.
Der kritische Pfad ist das Handshake zwischen CPU und Speicher (Blockram) über den Interconnect, wenn ich mich recht erinnere, das momentan rein kombinatorisch abläuft, also in einem Clockcycle. Die CPU ist nicht das Problem, die takten wir auf einem 22nm ASIC mühelos mit 1.1GHz. Wie gesagt, da ist nichts irgendwie optimiert, es ging erstmal darum, das SOC überhaupt auf den FPGA zu bringen, und 50MHz sind ehrlich gesagt schon mehr, als ich erwartet habe. Aber die Timingoptimierung steht noch auf der Agenda.
Martin S. schrieb: > Antti L. schrieb: >> 1) RISC-V mit microcode engine (engine-V code): >> 1270 CPE, max clock 43MHz design läuft, da kommt das Zephyr RTOS >> Philosophers ausgang aus dem UART raus. 1K16 microcode ROM und 32Kbyte >> emulator RAM richtig erkannt. > > Ist da echtes TDP RAM mit dabei? Die Mapping-Resultate der Synthese (vor > und nach dem technology mapping auf die Zielarchitektur) waeren > interessant. > 1270 ist ganz gut, wenn das eine pipelined Architektur ist. 1270, 43MHz war für "microcoded" RISC-V dabei läuft mit 43Mhz das microcode enginge was die RISC-V opcodes interpretiert.. der RISC-V läuft dabei mit 1 MIPS oder so etwa. Die "echten" RISC-V cores sind alle 3K+ und laufen viel langsamer.
Antti L. schrieb: > Die "echten" RISC-V cores sind alle 3K+ und laufen viel langsamer. Genauer, mit kleinerer Taktfrequenz, aber dafür mit einer Instruktion pro Clockcycle. Über den Sinn von Microcode-gesteuerten RISC-Architekturen kann man ja ohnehin diskutieren. Aber für das FPGA-Benchmarking spielt das keine Rolle. Wenn du noch Lust hast, könntest du mal versuchen, die IBEX-CPU (https://github.com/lowRISC/ibex) auf den Gatemate zu bringen. Vorausgesetzt, der Pincount reichts auch, das ist nur die nackte CPU, trotzdem wäre die Größenordnung des erreichbaren Taktes mal interessant.
Vancouver schrieb: > Antti L. schrieb: >> Die "echten" RISC-V cores sind alle 3K+ und laufen viel langsamer. > > Genauer, mit kleinerer Taktfrequenz, aber dafür mit einer Instruktion > pro Clockcycle. Über den Sinn von Microcode-gesteuerten > RISC-Architekturen kann man ja ohnehin diskutieren. Aber für das > FPGA-Benchmarking spielt das keine Rolle. > > Wenn du noch Lust hast, könntest du mal versuchen, die IBEX-CPU > (https://github.com/lowRISC/ibex) auf den Gatemate zu bringen. > Vorausgesetzt, der Pincount reichts auch, das ist nur die nackte CPU, > trotzdem wäre die Größenordnung des erreichbaren Taktes mal interessant. Da bin ich mir ziemlich sicher sogar das "micro" ibex würde in ein CCGM1A1 nicht reinpassen, es ist 17kGE (was immer kGE ist..), das wir sicherlich über 20K CPE gehen!
17kGE = 17000 gate equivalents. Das bedeutet dass der IBEX die gleiche Komplexität hat wie ein ASIC-Design, das aus 17000 NAND-Gates aufgebaut ist. Das ist nur ein sehr grober Richtwert, mit dem sich große ASIC-Designs vergleichen lassen. Wieviel FPGA-Ressourcen so ein Design benötigt, lässt sich daraus kaum sinnvoll abschätzen, insbesondere wenn im FPGA DSP-Cells oder andere Hardmacros verfügbar sind.
Vancouver schrieb: > 17kGE = 17000 gate equivalents. Das bedeutet dass der IBEX die gleiche > Komplexität hat wie ein ASIC-Design, das aus 17000 NAND-Gates aufgebaut > ist. Das ist nur ein sehr grober Richtwert, mit dem sich große > ASIC-Designs vergleichen lassen. Wieviel FPGA-Ressourcen so ein Design > benötigt, lässt sich daraus kaum sinnvoll abschätzen, insbesondere wenn > im FPGA DSP-Cells oder andere Hardmacros verfügbar sind. dumm von mir, ja wenn 17K Gates sind, dann könnte es in 20K CPE reinpassen schon.
Antti L. schrieb: > 1270, 43MHz war für "microcoded" RISC-V dabei läuft mit 43Mhz das > microcode enginge was die RISC-V opcodes interpretiert.. der RISC-V > läuft dabei mit 1 MIPS oder so etwa. Ich kenne die Engine nicht, klingt aber weniger nach pipelined, damit haette sich die TDP-Frage somit erledigt, korrekt? Die Frage ist bei dem CPU-Jonglieren immer, worauf's hinauslaufen soll, mit minimalem Platzbedarf ist man mit anderen Architekturen besser beraten. Bei der gezielten Optimierung auf f_max hat sich bisher bei mir herausgestellt: - Lokalen MMR-Bus (memory mapped register) mit Write-Delay-Pipes versehen. Wenn die Architektur unmittelbar zurücklesen koennen muss, muss man leider halt bypasses einbauen (bus Error Exceptions sind allenfalls bevorzugt). - Die CSR-Erweiterungen sind u.U. eine massive Bremse, kann man sich ähnlich ins Knie schiessen - Was yosys angeht, muss man Logik-Optimierung teils muehsam per Trial & Error machen. Die f_max Flaschenhaelse sind somit kein Gatemate-spezifisches Problem, die sehe ich auch bei Lattice-Architekturen im Zusammenhang mit yosys. Ein RISC-V-Kern (nur pipelined Kern mit Wishbone) sollte eigentlich so bei modernen Architekturen schon 100-120 MHz schaffen, typischerweise ist es beim vollen SoC mit Peripherie a la Blackfin und Hintertuer-DMA (wo die obige TDP-Frage sehr relevant wird) in etwa die Haelfte, das sollte allerdings mit yosys schon gehen.
Angehängte Dateien:
-

Artix7_timing.PNG
52 KB
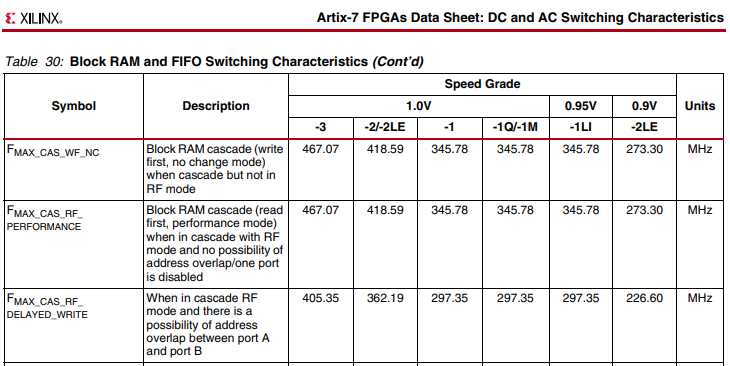
J. S. schrieb: > Vancouver schrieb: >> Artix-7 ... mit 50Mhz, > Hm, was ist denn da die Bremse? AXI voll asynchron oder ist es der Proz? Da hier der Speedgrade des verwendeten Artix nicht genannt wird, ist eine Angabe wie "läuft mit xyz MHz" glatt für die Tonne. Anbei ein Ausschnitt aus den vielen Timing-detail Angaben des Artix-7 Datenblatt "DC an AC Switching Characteristics" (DS181). Daraus erkenntlich das der langsamste Speedgrad mit ca 60% vom schnellsten rennt - und das für die selbe Baureihe. https://docs.xilinx.com/v/u/en-US/ds181_Artix_7_Data_Sheet Aus dem Ausschnitt ist ebenfalls zu erkennen, wie BRAM-Einsrellungen wie Readbeforewrite o.ä. die Taktrate bestimmen. > Den RISC kenne ich nicht, aber ein praktisch voll ausgebauter 100er > Artix mit DDR und ähnlichen Innereien, dazu S/PDIF und einem Haufen > Signalverarbeitung dudelt hier auf fast 200 - mit etwas Nachhilfe durch > FFs an den richtigen Stellen. Stream-Signalverarbeitung und CPU-Core kann man nicht unbedingt vergleichen. DSP Strukturen sind Datenpfad optimiert mit wenig Logik zwischen den FF, während bei CPU's schon einiges an kaskadierten LUT zum decodieren der Intruction, effektive addresse und Rechenwerksteuerung braucht. Insbesonders bei höheren Fan-In wie 32bit versus 8bit Maschine. Das treibt den Logiclevel (Anzahl der hintereinander geschaltetetn LUT/Slices zwischen zwei FF schnell in die Höhe. Und der höchste Logiclevel bestimmt die maximale Taktung, Routing-Optimierung bringt (ausser bei goben Schnitzer) wenig Verbesserung an der Taktrate. https://docs.xilinx.com/r/2021.2-English/ug949-vivado-design-methodology/Allow-Register-Replication > 50MHz ist eher so das, was ich vor 15 Jahren mit dem NIOS und dem > Cyclone III hatte. Nach meiner Erfahrung sind CPU-Softcores nicht sonderlich schneller geworden. Deshalb hat wohl Xilinx auch den Zynq mit ARM als Hardcore rausgebracht, der dann auf 500 (fünfhundert) MHz taktet, während man für einen ARM-SoftCore auf Xilinx FPGA eher Taktangaben um (40) Vierzig MHz findet. Bei aufLowCost-FPGA wie Artix/Spartan angepassten Soft-Cores wie Mikroblaze sieht das besser aus ist aber immer noch weit vom Hardcore weg.
Es handelt sich um ein Arty-7-Board mit einem XC7A100TCSG324-1, also Speedgrade 1. Der gezeigte Ausschnitt aus dem Datenblatt bezieht sich auf kaskadierte Blockrams mit optimaler Platzierung. Der kritische Pfad in meinem Fall kommt aber rein durch die vielen LUT-Level im Interconnect zusammen. Softcore-CPUs sind irgendwann ausoptimiert, wenn man man bei der gleichen LUT- und Routing- Architektur bleibt. Dann werden sie nur noch schneller wenn man einen FPGA mit einer neuen Technologie verwendet. Auf einem Virtex Ultrascale-II gingen vermutlich locker 150Mhz out of the box. Und natürlich sind Soft-CPUcores nur bedingt sinnvoll, außer man hat eine offene Architektur wie RISC-V, deren Befehlssatz man ändern kann. Btw, wäre mal interessant zu wissen, ob und wann Xilinx ZYNQs mit RISC-V Hardcores rausbringt.
> Btw, wäre mal interessant zu wissen, ob und wann Xilinx ZYNQs mit RISC-V Hardcores rausbringt. Wird bestimmt passieren, andere machen's: Microsemi’s 64-bit RISC-V SoC FPGA https://riscv.org/news/2018/12/electronic-design-article-hard-core-risc-v-cores-mate-with-fpga/ Interessant wäre ein FPGA mit mehren RISC-V nach dem Big-Little Architektur. https://en.wikipedia.org/wiki/ARM_big.LITTLE
Christoph M. schrieb: >> Btw, wäre mal interessant zu wissen, ob und wann Xilinx ZYNQs mit RISC-V > Hardcores rausbringt. > > Wird bestimmt passieren, andere machen's: > Microsemi’s 64-bit RISC-V SoC FPGA > https://riscv.org/news/2018/12/electronic-design-article-hard-core-risc-v-cores-mate-with-fpga/ > > Interessant wäre ein FPGA mit mehren RISC-V nach dem Big-Little > Architektur. > https://en.wikipedia.org/wiki/ARM_big.LITTLE AMD wird sicherlich kein RISC-V machen. Die sind in ARM boot!
> Und natürlich sind Soft-CPUcores nur bedingt sinnvoll, außer man hat > eine offene Architektur wie RISC-V, deren Befehlssatz man ändern kann. So ziemlich jeder eingesetzter Softcore liegt als änderbarer Quelltext vor. oder es gibt einen "Nachbau" der quellofen ist. Opencores.org quillt fast über vor lauter Prozessor-Softcores. https://opencores.org/projects?expanded=Processor > Btw, wäre mal interessant zu wissen, ob und wann Xilinx ZYNQs mit RISC-V > Hardcores rausbringt. Als Hardcore wäre aber der oben genannte Vorteil des änderbaren Befehlsatzes im Arsch. Und die Ingenieure die Risc-V entwickeln können werden heutzutage gefeuert: https://www.heise.de/news/Es-brodelt-in-der-RISC-V-Welt-9343103.html https://www.electropages.com/blog/2023/01/intel-terminates-risc-v-development-project-what-happened
Klaus K. schrieb: > Als Hardcore wäre aber der oben genannte Vorteil des änderbaren > Befehlsatzes im Arsch. Nicht zwingend. Bei den alten Virtex2Pro und Virtex4 mit PPC konnte man benutzerspezifische Befehle zur hardcore CPU hinzufügen. Keine Ahnung ob das auch genutzt wurde und ob es schnell war. Vermutlich ist es besser, das ganze ausserhalb des Befehlssatzes zu machen. Speicheradresse für Quelle und Ziel in die Logik senden. Die Logik/Beschleuniger macht dann sein Ding per DMA komplett autonom und macht dann einen Interrupt wenn er fertig ist.
Klaus K. schrieb: > Als Hardcore wäre aber der oben genannte Vorteil des änderbaren > Befehlsatzes im Arsch. Und die Ingenieure die Risc-V entwickeln können > werden heutzutage gefeuert: Der Hardcore macht meist nur Standard OS-Drumherumgemüse im Sinne von Rahmenwerk mit Zugriff auf eine Menge Softwarebibliotheken. Da sind Abweichungen vom Befehlssatz kontraproduktiv und in der Software (zumindest von Seiten gcc) ein Wartungsalbtraum. Methode "Christoph Z." macht deutlich mehr Spass :-) Mit pfiffigen Architekturen, die allerdings vom MIPS/RISC-V Einheitsbrei abweichen, kann man das deutlich vereinfachen, ein extra Kern kostet so weniger Overhead als murksige Multithread-Ansätze auf RISC-Befehlssätzen und bietet dazu noch mehr funktionale Sicherheit.
... und hardcores sind auch geringfügig stromsparender, als softies. Beitrag "AMD MicroBlaze V RISC processor"
Vielleicht sollte man mal einen Risc-V FPGA-Thread aufmachen. Hier der neue BeagleV: https://hackaday.com/2023/11/04/beaglev-catches-fire/ Kennt jemand den Microchip PolarFire MPFS025T FCVG484E ? Das Ding hat 5 Risc-V Kerne: 4XRV64GC, 1XRV64IMAC und einen FPGA Teil: Logic Elements: 23K Math Blocks 18x18: 68 Die Frage ist: Wie lange braucht man, um die Toolchain aufzusetzen?
Christoph M. schrieb: > Die Frage ist: Wie lange braucht man, um die Toolchain aufzusetzen? Vier mal schneller als AMD/Xilinx, weil sie nur etwa einen viertel so gross ist. :-) Bei Microchip ist alles ein bisschen rudimentärer und sieht weniger hübsch aus. Läuft aber soweit zuverlässig. Wie bei anderen Herstellern ist das Zeugs mit den Schematics (Block design, Smart design) kaum zu gebrauchen, aber ist auch nicht nötig. Einen sauberen Make/TCL Flow aufzusetzen braucht schon mehr Zeit.
Christoph Z. schrieb: > Vier mal schneller als AMD/Xilinx, weil sie nur etwa einen viertel so > gross ist. :-) Super argument :-)
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.