Hallo, eine 2012 gespeicherte HTML-Seite zeigt mir auf dem Samsung S5 sämliche Umlaute als ? an. Auf dem PC unter MSIE, FF, Opera ist dies nicht so. Allerdings wird eine aktuelle gespeicherte Seite auf dem S5 richtig angezeigt. Wo liegt der Hund begraben? Gustav
Gustav K. schrieb: > Wo liegt der Hund begraben? Der Zeichensatz (charset oder character set) ist falsch, den kannst Du im HTTP-Header vom Server setzen oder im HTML-Head.
Gustav K. schrieb: > Auf dem PC unter MSIE, FF, Opera Gustav K. schrieb: > auf dem Samsung S5 Unter ????????????????
Max M. schrieb: > Unter ???????????????? Öffnen der Datei mit "HTML-Anzeige" wurde mir angeboten und erschien mir passend. Nachtrag: Sehe eben, dass der Inhalt der Seite nur zwischen <body> und </body> steht. Da fehlt offensichtlich was.
Samsung geht wohl hartnäckig von UTF-8 codiertem HTML aus, das vermutlich aber in ISO8859 vorliegt. MSIE, FF, Opera sind da wohl "flexibler" und erkennen, daß das HTML in ISO8859 codiert ist.
Angehängte Dateien:
-

FF_Win.png
556 Bytes -

FF_Ubu.png
738 Bytes -

FF_Quell.png
473 Bytes


Habe die Seite nun durch Hinzufügen von <html>, <head> und <title> komplettiert, wie in Selfhtml dargestellt. Konkret:
1 | <!doctype html>
|
2 | <html lang="de"> |
3 | <head>
|
4 | <meta charset="utf-8"> |
5 | <meta name="viewport" content="width=device-width, initial-scale=1.0"> |
6 | <title>Text</title> |
7 | </head>
|
8 | <body>Inhalt</body> |
9 | </html>
|
Was die Seite nun komplett unbrauchbar macht :-( Ich sehe nun auch unter MSIE, FF und Opera keine Umlaute mehr und auf dem S5 hat sich nichts verändert. Bild 1 zeigt die Umlaute unter FF und Windows, Bild 2 unter FF und Ubuntu. So wie in Bild 2 werden die Umlaute auch auf dem S5 dargestellt. In Bild 3 lasse ich mir unter FF und Ubuntu den Quelltext anzeigen. Bereits hier werden mir die Umlaute nicht mehr angezeigt ??? Benenne ich *.htm in *.txt um, sehe ich die Umlaute wie üblich. Jetzt blicke ich nicht mehr durch :-(
Gustav K. schrieb: > <meta charset="utf-8"> Das ist ja auch ISO-8859-1 (alternativ -15, wird aber nur fürs Euro-Symbol gebraucht) und eben kein UTF-8.
Markus L. schrieb: > Samsung geht wohl hartnäckig von UTF-8 codiertem HTML aus, das > vermutlich aber in ISO8859 vorliegt. MSIE, FF, Opera sind da wohl > "flexibler" und erkennen, daß das HTML in ISO8859 codiert ist. So scheint es zu sein, denn mit ISO8859 stimmt nun unter MSIE, FF und Opera alles wieder. Nicht aber bei Samsung. Für die Alben in der Galerie gibt es offensichtlich ein 120 Dateien Limit, denn danach bleibt hier unter Ubuntu zuverlässig die Übertragung stehen. Dann tauchen die Ordner der HTML-Dateien in der Galerie auf und so weiter. Nach derart viel Theater habe ich das Speichern von HTML-Dateien verworfen. Überhaupt klappt das Sortieren von Bildern mittels Zeitstempel nur bei jpg Dateien. Hat man in seinem Album zusätzlich Bilder in anderen Bildformaten (gif, png, bmp) oder Videos, klappt das mit dem Sortieren nicht mehr. Hier hat es geholfen, den Zeitstempel der jpg Dateien zu entfernen, dann sortiert das S5 zuverlässig in der Reihenfolge der Übertragung.
Gustav K. schrieb: > Benenne ich *.htm in *.txt um, sehe ich die Umlaute wie üblich. > Jetzt blicke ich nicht mehr durch :-( Und warum speicherst du die HTML-Datei nicht einfach als UTF-8? LG, Sebastian
Gustav K. schrieb: > Für die Alben in der Galerie gibt es offensichtlich ein 120 Dateien > Limit, denn danach bleibt hier unter Ubuntu zuverlässig die Übertragung > stehen. .... > Überhaupt klappt das Sortieren von Bildern mittels Zeitstempel nur bei > jpg Dateien. Erklär mal was du da machst. Mit welcher Software übertragst Du die Dateien? Und was haben die jpg mit den html zu tun?
Gustav K. schrieb: > So scheint es zu sein, denn mit ISO8859 stimmt nun unter MSIE, FF und > Opera alles wieder. Nicht aber bei Samsung. Versuch's mal zusätzlich mit dieser Zeile: <meta http-equiv="Content-Type" content="text/html; charset=ISO-8859-1">
Gustav K. schrieb:1 | <!doctype html> |
Bist du sicher, das das so richtig ist? Ich kenne das eher so:
1 | <!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01//EN" "http://www.w3.org/TR/html4/strict.dtd">
|
Steve van de Grens schrieb: > Bist du sicher, das das so richtig ist? Ich kenne das eher so Weil Du kein HTML5 kennst. https://www.w3.org/QA/2002/04/valid-dtd-list.html
Angehängte Dateien:
-

2024-01-21_19-22.png
130 KB
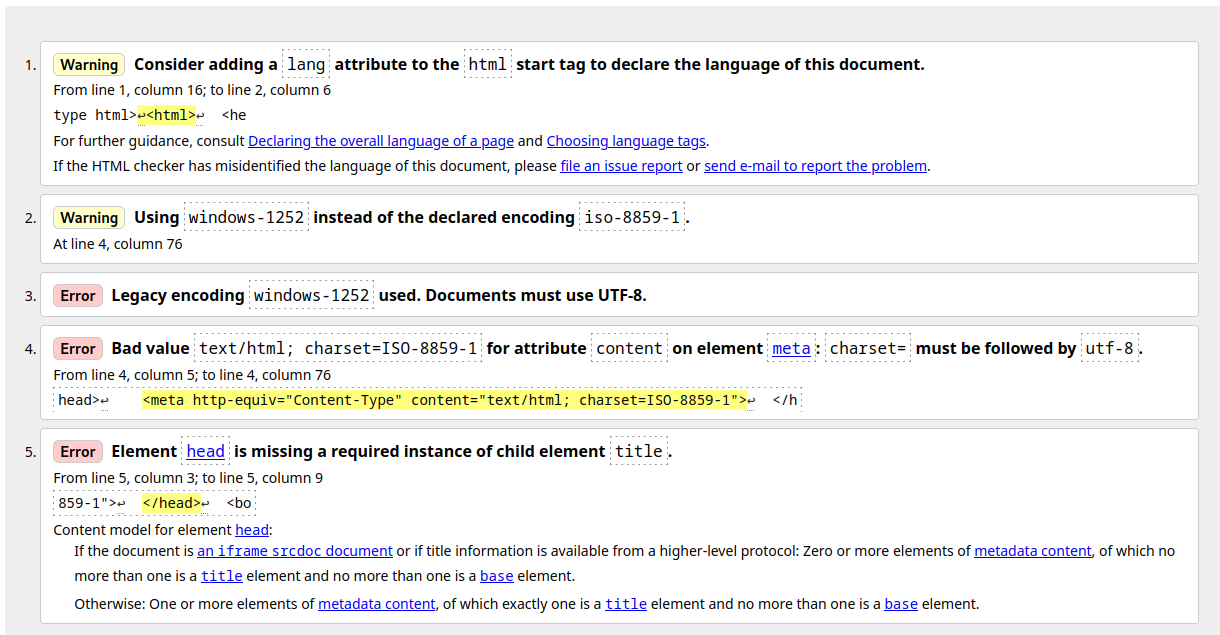
Hmmm schrieb: > https://www.w3.org/QA/2002/04/valid-dtd-list.html OK, aber da ist DOCTYPE groß geschrieben. Vielleicht ist das wichtig. Ich finde es allerdings fragwürdig, keine HTML Version anzugeben. Die dahinter stehende Annahme, dass alle Versionen ab 5.0 immer zueinander kompatibel sein werden finde ich ziemlich naiv. Als hätten wir damit keine Erfahrung aus der Vergangenheit. Naja, so ist das jetzt halt. Gut, dass das nicht meine Idee war. Ich wasche meine Hände in Unschuld. Mir fällt da gerade was ein: Hatten wir nicht erst vor kurzem die Diskussion, dass ISO8859-1 in HTML 5 nicht mehr zulässig ist? Jupp, wird prompt vom W3C Check moniert.
Klaus H. schrieb: > Erklär mal was du da machst. Mit welcher Software übertragst Du die > Dateien? Keine Software. Einfach beide Geräte (Notebook und Smartphone) mit dem originalen Samsung USB-Kabel verbinden und dann von einem Ordner in den anderen Ordner kopieren. Sebastian W. schrieb: > Und warum speicherst du die HTML-Datei nicht einfach als UTF-8? Die betreffende Seite habe ich vor ca. 10 Jahren gespeichert. Die Seite ist heute nicht mehr im Netz. Der Hintergrund ist, dass ich einige Projekte (mit allen möglichen Dateitypen) auf dem Smartphone haben wollte. Ich dachte, das verhält sich wie auf dem Notebook. Dem ist aber nicht so. Also werde ich unterwegs weiterhin das Notebook nutzen.
Gustav K. schrieb: > Sebastian W. schrieb: >> Und warum speicherst du die HTML-Datei nicht einfach als UTF-8? > > Die betreffende Seite habe ich vor ca. 10 Jahren gespeichert. > Die Seite ist heute nicht mehr im Netz. In einem geeigneten Editor aufmachen, Codierung umstellen, abspeichern. Fertig.
immer wieder interessant, dass sowas immer wieder auftritt. und dabei haben wir sowenig Zeichen, die wir nutzen. Ich hatte kürzlich auch wieder eine "[" Klammer in meinem Namen - war Behördenpost. Da frage ich mich nach wie vor, wie man das in Sprachen geht, die überhaupt garkeine lat. Zeichen haben: कैसे कंप्यूटर सिस्टम में बिना लैटिन अक्षरों के बोले जाने वाले भाषाओं में उनकी चिन्हों को प्रोसेस किया जाता है? அவர்கள் கணினி அமைப்புகள் அந்த கருவிகளைப் பின்னுக்கிறதா?
●DesIntegrator ●. schrieb: > Da frage ich mich nach wie vor, wie man das in Sprachen geht, > die überhaupt garkeine lat. Zeichen haben: Auch nicht anders als bei uns. Die verwenden entweder eine 8-Bit-Codepage, die halt anders aussieht bei uns, oder sie verwenden UTF-8. Früher™ war man halt der Ansicht, mit Varianten von 7-Bit-ASCII zurechtzukommen, und es gab mal eine deutsche Ausführung davon, die eckige und geschweifte Klammern sowie Backslash und vertikalen Strich durch Umlaute ersetzte, und noch ein Zeichen, das ich jetzt nach über drei Jahrzehnten vergessen habe, wurde durch das ß ersetzt. Wenn Du also Behördenpost bekommst, in der in Deinem Namen eine "[" auftaucht, ist damit ein 'Ä' gemeint. Das wiederum lässt darauf schließen, daß der entsprechende Datensatz irgendwann vor 1995 angelegt wurde ...
Angehängte Dateien:
-

Post.jpg
48 KB

●DesIntegrator ●. schrieb: > Da frage ich mich nach wie vor, wie man das in Sprachen geht, > die überhaupt garkeine lat. Zeichen haben: Da kennt dann hoffentlich ein freundlicher Post-Mitarbeiter die üblichen Fehl-Kodierungen und bastelt aus den handschriftlichen Umlauten etc. wieder die richtige Kodierung, hier Kyrillisch... https://de.wikipedia.org/wiki/Zeichensalat >> Im Japanischen wird das Problem als >> Mojibake (japanisch 文字化け, „Buchstabenverwandlung“) bezeichnet, >> im Russischen als krakosjábry (кракозябры) und im >> Chinesischen als luànmǎ (亂碼 / 乱码, „wirre Kodierung“).
Harald K. schrieb: > Früher™ war man halt der Ansicht, mit Varianten von 7-Bit-ASCII > zurechtzukommen, und es gab mal eine deutsche Ausführung davon, die > eckige und geschweifte Klammern sowie Backslash und vertikalen Strich > durch Umlaute ersetzte, und noch ein Zeichen, das ich jetzt nach über > drei Jahrzehnten vergessen habe, wurde durch das ß ersetzt. Das war ungefähr zu der Zeit, als wir für die Erbsen-Nadeldrucker noch eigene character-set EEPROMs gebastelt und gebrannt hatten, um dem Anspruch der Behörden bzw. Gesetzesvorgaben Genüge zu tun. Gleiches für die 3270 Terminals.
Harald K. schrieb: > noch ein Zeichen, das ich jetzt nach über drei Jahrzehnten vergessen > habe, wurde durch das ß ersetzt. Das war die Tilde. Und das @ fiel dem § zum Opfer: https://de.wikipedia.org/wiki/DIN_66003
Hmmm schrieb: > Das war die Tilde. Und das @ fiel dem § zum Opfer: Danke für die Erinnerung. Früher war vielleicht das eine oder andere gut, aber auch verdammt viel einfach nur schlecht.
Harald K. schrieb: > Wenn Du also Behördenpost bekommst, in der in Deinem Namen eine "[" > auftaucht, ist damit ein 'Ä' gemeint. Das wiederum lässt darauf > schließen, daß der entsprechende Datensatz irgendwann vor 1995 angelegt > wurde ... Tja, scheint EBCDIC zu sein, und man kann sich offensichtlich nicht für eine Zeichencodierung entscheiden, und das Zeichen geht durch unterschiedliche Zeichensätze ... Ä und [ teilen sich beide in EBCDIC den Codepoint 0x4A, einmal in Codeset 273 (deutsch als Ä), und in 500 (international, aber auch speziell Schweiz) als [ ... Scheint also noch irgendein Mainframe-System zu sein
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.