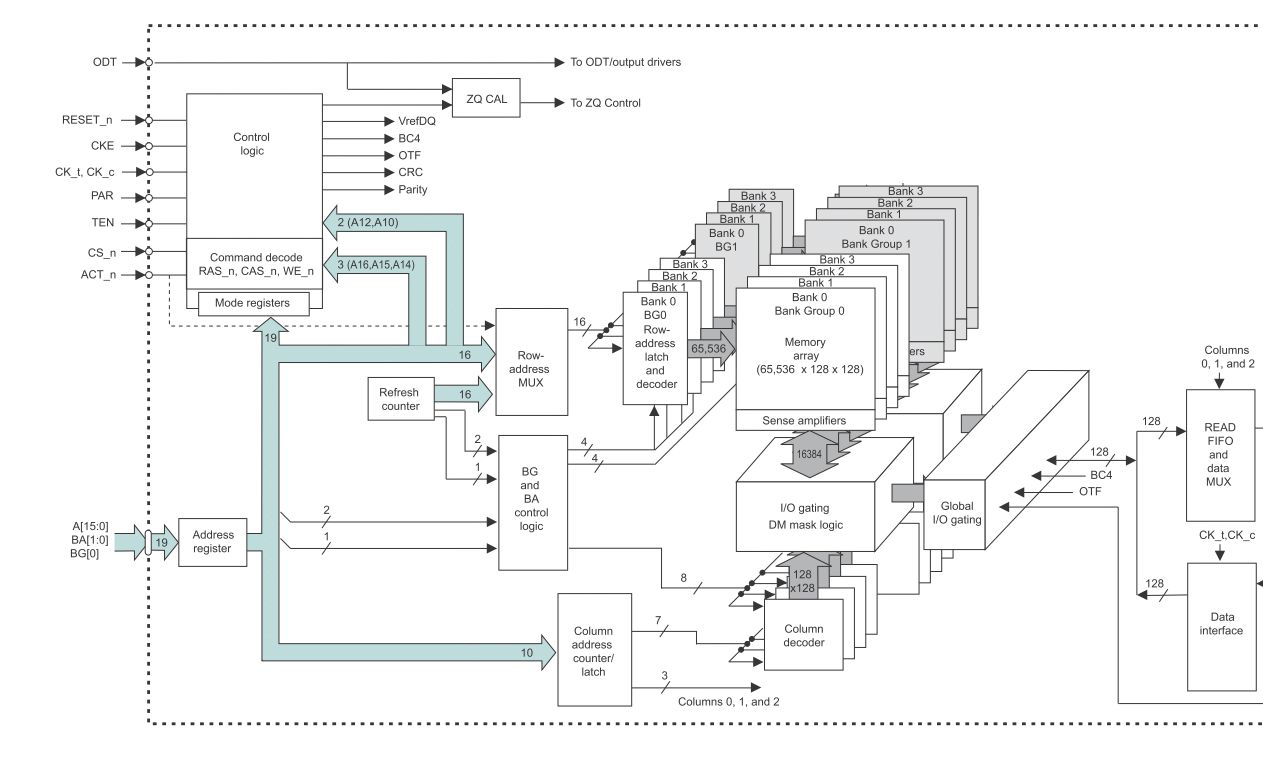
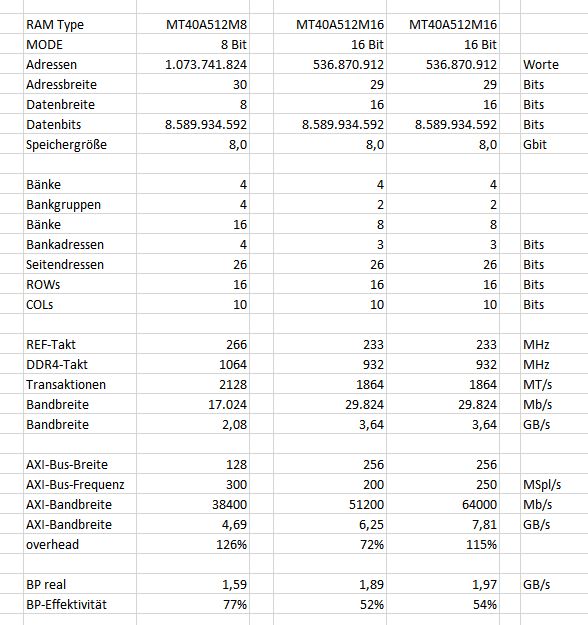
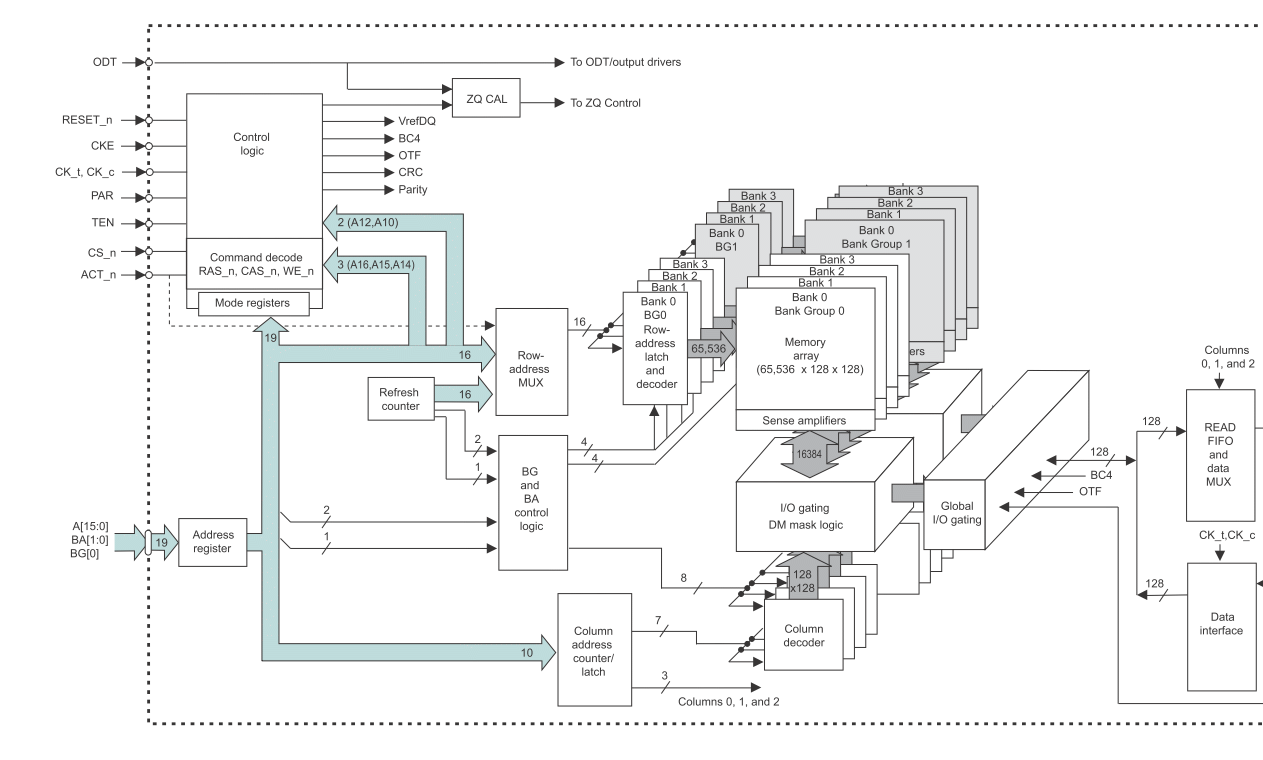
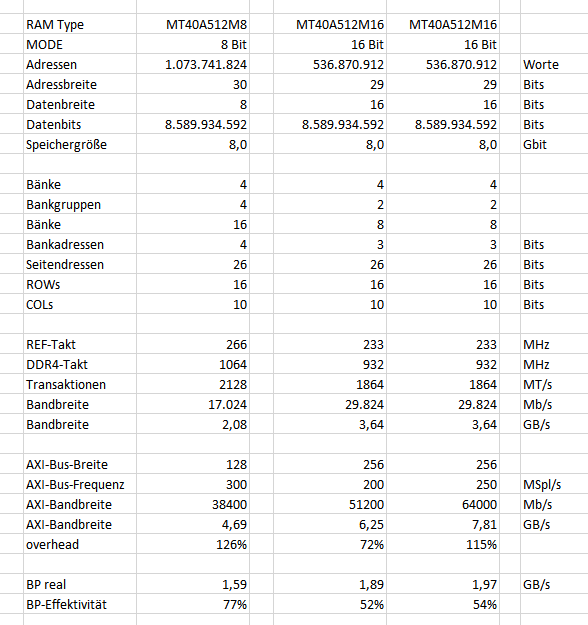
Wir benutzen einen FPGA mit DDR4-Interface und Automotive DRAM. Haben von 8B auf 16B umgestellt, um mehr Bandbreite zu bekommen. Wegen Busverdrahtung und anderer Gründe läuft das Interface zum RAM nicht mehr auf der vorherigen Bandbreite, was aber vom RAM her nichts ausmachen sollte. Wie in der Tabelle belegt, sollten es bis zu 3,6GB/s statt 2,1 sein. Angeschlossen ist ein AXI4MM auf jetzt 200MHz wegen Kompatibiltität zum Controller, statt vorher 300MHz. Die Bandbreite vom AXI-Bus hat damit 1,7x mehr, als nötig. Sollte also reichen für 2/3 Transaktionsdichte, bei maximaler RAM-Bandbreite. Jetzt ist die tatsächlich gemessene Bandbreite aber gerade knapp 1,9 von 3,6 möglichen. Zuvor waren es 1,6 von 2,1. Obwohl der RAM-Baustein also mehr Daten anliefern können müsste, ist die Steigerung gering. Zuvor waren es 77% (von 90% möglichen wegen Refreshs ein guter Wert) und jetzt sind es nur noch 52%. Warum ist das so? Ist der AXI die Bremse im System?
Angehängte Dateien:
-

ddr4.gif
84 KB
Angehängte Dateien:
-

ramberechnung.gif
20 KB
{kind=link}
{kind=link}
Wir haben testweise auf 250 MHz AXI erhöht und trotzdem kaum mehr Bandbreite. Ich habe ein Bild angehängt mit den Daten wie ich sie berechnet habe. Stimmt das so oder findet jemand einen Fehler? Der Controller krebst bei gut 50% herum. ???
Gute Frage - 8 Bytes / 8 Worte nehme ich an. Testmuster ist linear / stochastisch. Unterscheidet sich auch nicht so groß. Rückfrage: Sind denn bei dem DDR4 die bursts nicht automatisch 8 Bytes? Er muss ja seinen AXI füllen. Da kann natürlich was passieren, weil er noch sortieren darf. Muss ich checken.
Moin, B. schrieb: > Rückfrage: Sind denn bei dem DDR4 die bursts nicht automatisch 8 Bytes? Keine Ahnung, mein letztes FPGA-RAM Interface war noch mit DDR2. Nagel mich nicht mehr auf die Zahlen fest, aber iirc hat's damals immer erst mal mindestens 12 Takte nach Anlegen von Adresse und "ich will lesen" gedauert, bis dann mal was kam. Wenn man dann nur 1 Wort lesen wollte, also 13 Takte / Wort. Bei einem 16er Burst halt 29 takte / 16 Worte = 1.813 Takte / Wort. Also 7x "schneller". Ist aber eben schon was lange her. Gruss WK
Die Verzögerungen des RAMs haben sich aber nicht geändert und können auch rechnerisch nicht verantwortlich sein. Ich vermute eher etwas mit Bankumschaltungen oder so. Die Adress-Pins wurden untereinander getauscht. Angeblich so, dass es keinen Schaden macht. Da bin ich dran, dass zu checken. Meines Wissens darf man das nicht beliebig, weil die Adresssleitungen auch Sonderbedeutungen haben. Ich nehme an, dass es zwar grundsätzlich geht, aber durch das Zerwürfeln ungünstige Speicherkonstellationen entstehen.
Moin, B. schrieb: > Die Adress-Pins wurden untereinander > getauscht. Angeblich so, dass es keinen Schaden macht. Uaaarg. Da hab' ich Zweifel, dass das schadenfrei geht. Wenn sich das nicht beim DDR4 grundsaetzlich vom DDR2 unterscheidet, dann gehen da beim Load Mode Command so Infos drueber wie eben Burstgedoens, CAS latency etc. bla... Gruss WK
Also laut https://docs.xilinx.com/r/en-US/pg313-network-on-chip/DDR4-Pin-Rules darf man die Addressleitungen nicht swappen. Ja, bei DDR sollte das grundsätzlich eingeschränkt möglich sein, aber ob das mit dem MIG von Xilinx geht weiß ich nicht. A10 ist z. B. zusätzlich noch für auto precharge zuständig.
Das dachte ich mir schon. Ich kenne die Thematik noch vom alten DDR3. Da gab es auch schon Einschränkungen.
B. schrieb: > Angeschlossen ist ein AXI4MM auf jetzt 200MHz wegen Kompatibiltität zum > Controller, statt vorher 300MHz. Die Bandbreite vom AXI-Bus hat damit > 1,7x mehr, als nötig. Sollte also reichen für 2/3 Transaktionsdichte, > bei maximaler RAM-Bandbreite. Na, wenn ich rechnen kann, sind das nur 0,7 x mehr, als nötig - aber immerhin deutliche Reserve.
B. schrieb: > Das dachte ich mir schon. Ich kenne die Thematik noch vom alten DDR3. Da > gab es auch schon Einschränkungen. Wenn die relevanten Adressleitungen vertauscht wären, dürfe es gar nicht funktionieren, hätte ich jetzt gesagt, aber es könnte ja theoretisch sein, dass hohe und niedrige Adressenleitungen, je nach Nutzung andauernd zu Seiten- / Bankgruppenumschaltungen führen und damit unnötige Latenzen erzeugen. Das müsste man wohl näher betrachten. Kay-Uwe R. schrieb: > Sollte also reichen für 2/3 Transaktionsdichte, >> bei maximaler RAM-Bandbreite. > Na, wenn ich rechnen kann, sind das nur 0,7 x mehr, als nötig - aber > immerhin deutliche Reserve. 2/3 Auslastung des AXI-Busses ist schon recht, wie ich lernen musste, besonders, wenn es zu unwillkürlichen Umschaltungen kommt und mehrere Nutzer. Meine Erfahrungen mit dem UltraScale HBM reichen dahin, dass man mit einer Matrix maximal 35% auslasten darf, wenn man nicht an Grenzen stossen will. Mit einem optimalen Pattern (AWG Mode, linear, exklusivem Zugriff) habe ich 65% geschafft. Das allerdings waren Bandbreiten für eine 900MHz Anbindung des DDR4 und teilweise AXI-Matrix in HW. Wenn ich das gedanklich übertrage, dann deutet dein erster Wert von 75% nicht auf eine Verlangsamung durch das AXI. Wie sieht denn die reale Dichte aus? Wenn nur 50% Bandbreite kommen, dürfte der AXI nur zu 1/3 ausgelastet sein. Das kann dann keine Wirkung haben, behaupte ich mal. Der Fehler dürfte woanders liegen.
Kay-Uwe R. schrieb: > Na, wenn ich rechnen kann, sind das nur 0,7 x mehr, richtig, "0,7 mehr" oder "Faktor 1,7". Es muss aber meines Erachtens so oder so reichen, weil die maximale RAM-Bandbreite ja schon seitens des RAMs nicht angeliefert wird. J. S. schrieb: > Wenn nur 50% Bandbreite kommen, > dürfte der AXI nur zu 1/3 ausgelastet sein. Eben.
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.