Wir haben eine Möglichkeit, state machines in Verilog umzusetzen und sind dabei auf eine Frage gestoßen: Nehmen wir an, wir haben unterschiedliche Abläufe für unterschiedliche Maschinen und fassen state machines dadurch zusammen, dass wir sie überlagern und von außen multiplexen, d.h. von Zuständen und Variablen abhängig machen, ohne das explizit IN die state machine zu schreiben, wodurch in der Software bei manchen Fällen redundante Beschreibungen entstehen. Es sieht dann z.B. so aus, dass wir 4 x die gleiche state machine hintereinander haben, die aber mit den Parametern 00,01,10,10 angesprungen werden, wobei i.A. des Wertes 0,1,2,3 einige Variablen die in der FSM abgefragt werden, auf den Abfragewert gesetzt werden, oder genullt, sodass die Abfrage immer klappt oder nie, was dazu führt, dass diese Zweige irrelevant werden oder abfragefrei zum nächsten Punkt gegangen wird. Das führt zu einer einfachen Programmierarbeiten und zu einem aufgeblähten Code. In C ist das egal, weil es einfach Flash belegt und beim Einsprung 2-3 Abfragen mehr braucht. In VHDL ist es so, dass mehr hardware angefordert wird, die meines Wissens bei der Synthesumsetzung wieder zusammenfällt, weil Redundanz eliminiert werden sollte. Was ich an Ergebnissen sehe, ist das auch so: Es kommt in etwas das heraus, was auch herausgekommen wäre, wenn man die einzige alleinge state machine innen um diese Abfragen erweitert hätte. Wie ist das aber jetzt mit den Codierungen? Wie "one hot"? Geht das dann auch? Wie verh
Ja so mache ich das auch immer. Mehrere unabhängige Sachen werden in einem einzigen Code zusammengemischt. Das spart mindestens 3 LUTs, bei einer Belegung von 40%. Der Vorteil ist, dass den Code dann keiner mehr versteht, und nur ich den noch warten darf/kann. Das sichert meinen Arbeitsplatz. Modularität, Wartbarkeit??? Egal, solange der Job sicher ist. Und wenn ich eine Handvoll LUTs einspare, kann ich das sogar noch positiv verkaufen.
🐻 Bernie - Bär schrieb: > In VHDL ist es so, dass mehr hardware angefordert wird, die meines > Wissens bei der Synthesumsetzung wieder zusammenfällt, weil Redundanz > eliminiert werden sollte. Sofern das tool diese Redunanz erkennt, sollte das der Fall sein. Ob das bei nebenläufigen FSMs der Fall ist, hängt wohl von der Intelligenz des tools ab. Ich würde sagen, "Ausprobieren". Was die XI-Synthese in jedem Fall nicht gut kann, ist über einige Zeitscheiben hinwegzuschauen, also zu erkennen, dass etwas zeitversetzt arbeitet und zählt oder rechnet. Nutze ich z.B. mehrfach denselben Phasenvektor in meinen DDS-Vorschriften, dann führt ein Zeitversatz zur Nichterkennung und die Teile werden nicht zusammengefasst. Das kann man u.A. daran erkennen, dass er ohne die Syntheseeinstellung, die FFs zu erhalten, ein besseres Timing herausbekommt, als im anderen Fall, weil jede Schaltung autark läuft. Ich löse das dadurch, dass ich an die Rechenergebnisse und die Vektoren pauschal verzögerte Versionen dranhänge. Diese liegen dann der Synthese vor und sie kann zeitliche Überlappungen sehen und nutzen. Gleichzeitig kommandiere ich der Synthese die FFs zu erhalten, damit diese erst nach dem Platzieren der Implementierung zum Opfer fallen. Das macht die Schaltung "flexibler".
Peter schrieb: > Mehrere unabhängige Sachen werden in > einem einzigen Code zusammengemischt. Nein, sie werden eben nicht gemischt. Nehmen wir das Beispiel einer FSM, die an etlichen Stellen zwischen zwei Maschinen unterscheiden muss und dort eine Verzweigung macht, dann steht irgendwo: xxx xxx xxxx if maschine = 1 then parameter = 67 else maschine = 2 then parameter = 45 end ; und das an vielen Stellen. Statt den Code aufzubrechen, kopiere ich einfach beide state machines in einen code und unterscheide oben ein einziges mal, welcher ausgeführt wird. Da sich die Codes zu 70% ähneln steht vieles 2x drin, macht aber nicht, es wird nur einmal ausgeführt. Wie ist das bei VHDL? Wird beim Aufbauen die Redundanz entfernt?
🐻 Bernie - Bär schrieb: > Statt den Code aufzubrechen, kopiere ich einfach beide state machines in > einen code und unterscheide oben ein einziges mal, welcher ausgeführt > wird. Du kommst aus der Software, richtig? Statt den Code aufzubrechen, mache ich eine entity draus und gebe dieser per generic unterschiedlich Parameter beim Instanziieren mit. Aber eine FSM ist es einfach in der Regel nicht wert (vom Ressourcenverbrauch her) um sie mit zusätzlichen Multiplexern zwischen verschiedenen Designteilen hin- und herzuschalten.
Rick D. schrieb: > Du kommst aus der Software, richtig? Teilweise richtig. Rick D. schrieb: > st es einfach in der Regel nicht wert (vom > Ressourcenverbrauch her) um sie mit zusätzlichen Multiplexern zwischen > verschiedenen Designteilen hin- und herzuschalten. Das war nicht die Frage. Es geht darum, EINE FPGA-Software zu machen, die für 5 Maschinen passt. Jede Maschine hat ihre eigenen state machines mit Modulen, die an die HW angepasst sind. Manche Module fehlen, manche sind doppelt, viele sind ähnlich. In der STM-Software machten wir das anfänglich so, dass überall dort, wo sich die state machines unterscheiden, eine Abfrage reinkommt, die die Maschine prüft und dann das Richtige tut. Z.B. fährt eine Maschine 6 Regler, eine andere nur 4, die aber komplizierter sind und andere Filter in der Rückführung haben. Als es mehr Maschinen wurden, haben wir die Abfragen einfach aussen drüber gestülpt: Es gibt nun nur noch eine SW, die von allen Maschinen den Code enthält. Sagen wir 5 isolierte Zweige. Das haben wir gemacht, um den Pflegeaufwand zu reduzieren, als die Maschinen konfigurierbar wurden. D.h. der Kunde steckt ein spezielles Modul, zieht was ab und die SW verhält sich entsprechend. Sie ist also die Vereinigungsmenge aller möglichen Fälle. Das macht nichts, weil die alle ein großes Flash haben. Mache ich das beim FPGA, bekomme ich z.B. 5 Schaltungen parallel. Wird dann das, was in state machines gleich ist, auf einen Zweig reduziert? Das ist essenziell, weil die state machines sehr groß und umfangreich sind.
Das soll einer verstehen ... Man nimmt doch FPGAs, damit alles parallel, schnell und unabhängig voneinander läuft. Du willst das Gegenteil? Ich würde nicht einmal ausschließen, jeder Maschine ein eigenes FPGA zu verpassen - schon wegen der Betriebssicherheit. Unter Optimierung verstehe ich, Abfragen zu eliminieren, statt sie einzufügen. Klar gibt es verschiedene Kriterien zur Optimierung, wie Speed, Space, Dissipation etc. Aber man muss auch Entwicklungszeit, Fehleranfälligkeit, Supportmöglichkeiten gegen Hardwarekosten abwiegen. Je nach Stückzahl auf das nächstgrößere FPGA auszuweichen erspart einem kontraproduktiven Aufwand. Außerdem zahlt der Kunde oft gerne etwas drauf für das dann leistungsfähigere System. Ansonsten kann ich Rick nur beipflichten. Man verpackt das Teil als Entity und schließt dort die entsprechenden Signale und Parameter (port/generic) an und so oft, wie man es braucht. Es reicht eine gemeinsame Source, wenn auch mit ein paar Fallunterscheidungen. Die gibt es dafür nicht mehr zur Laufzeit. Optimierungen durch die Synthese (oder auch beim PAR) können weiterhin sogar bewirken, dass hier und da Schaltungsteile repliziert - also noch größer - werden! Das passiert häufig, um Fan-out-Beschränkungen einzuhalten. Es kommt sogar vor, dass ganze Entities (dt. Entitys) repliziert werden. Und hier muss man gerade bei FSMs besonders aufpassen: Asynchrone Eingangssignale müssen atomar synchronisiert werden. Nur mit speziellen Attributen kann das Replizieren dieser Eingangsregister unterdrückt werden, sonst arbeitet die Schaltung fehlerhaft. (Und in der Simulation gibt es dieses Problem nicht!)
Berni-Bär 🐼 schrieb: > Maschinen Was meinst du denn damit? Berni-Bär 🐼 schrieb: > Jede Maschine hat ihre eigenen state machines mit Modulen, die an die HW > angepasst sind. Manche Module fehlen, manche sind doppelt, viele sind > ähnlich. Ja, dafür gibt es Generics, generate, ... wenn man will, dann kann man sein VHDL sehr generisch schreiben und dann nur mit unterschiedlichen Werten in einem Package für ganz unterschiedliche Ziele bauen. Berni-Bär 🐼 schrieb: > Mache ich das > beim FPGA, bekomme ich z.B. 5 Schaltungen parallel. Ist doch super, deshalb verwendet man FPGAs. Berni-Bär 🐼 schrieb: > Das ist essenziell, weil die state machines sehr groß und umfangreich > sind. Nein. FSMs sind typischerweise eher sehr klein im Vergleich zum restlichen Design. Das sind nur ein paar Bits (auch bei vielen Zuständen) und ein paar Bedingungen/Komparatoren für Zustandswechsel. Wenn ich bei meinen Designs irgendwo optimieren muss oder möchte, dann dort wo wirklich Ressourcen verbraten werden.
Gustl B. schrieb: > Berni-Bär 🐼 schrieb: >> Maschinen > > Was meinst du denn damit? Ein Geräte, ein Produkt. Die haben jeweils andere Sensoren und Aktoren, erfordern also unterschiedlich gebaute Software. Maschine != State Machine Kay-Uwe R. schrieb: > Das soll einer verstehen ... Man nimmt doch FPGAs, damit alles parallel, > schnell und unabhängig voneinander läuft. Du willst das Gegenteil? NEIN! Es geht darum, ob man die unterschiedlichen Verhaltensweisen der einzelnen Zweige hinsichtlich der Maschinen INNERHALB der fsm behandeln muss, wobei nur Änderungen entstehen, die nötig sind und redundante Pfade einzigartig bleiben, oder ob man es einfach nebeneinander stehen lassen kann und die FPGA-Erzeugersoftware das selber zusammenfasst.
Berni-Bär 🐼 schrieb: > Ein Geräte, ein Produkt. Die haben jeweils andere Sensoren und Aktoren, > erfordern also unterschiedlich gebaute Software. Genau. Und welche Sensoren und welche Aktoren die haben kann man doch als Konstanten in ein (generic)Package schreiben. Das Design das dann gebaut wird hängt nur von diesen Konstanten ab. Wenn das Gerät also eine I2C Schnittstelle haben soll, dann setzt man dort eine Konstante auf True und es wird der I2C Master - mit seiner FSM - instantiiert. Wenn nicht, dann nicht. Berni-Bär 🐼 schrieb: > Es geht darum, ob man die unterschiedlichen Verhaltensweisen der > einzelnen Zweige hinsichtlich der Maschinen INNERHALB der fsm behandeln > muss, wobei nur Änderungen entstehen, die nötig sind und redundante > Pfade einzigartig bleiben, oder ob man es einfach nebeneinander stehen > lassen kann und die FPGA-Erzeugersoftware das selber zusammenfasst. Verstehe ich nicht. Was meinst du mit "der fsm"? Es Design hat üblicherweise mehrere viele FSMs die jeweils für verschiedene Dinge zuständig sind. Der I2C Master hat eine, der UART vielleicht ebenfalls, der DRAM Controller auch, ... und die muss man doch gar nicht anfassen. Wenn man zwei Geräte einmal mit und einmal ohne eine Funktionalität baut, dann wird/werden die dafür benötigten Komponente(n) eben mir reininstantiiert oder eben nicht. Genau dafür gibt es Generics, generic Packages, generate Statements und auch Configurations im VHDL.
Angehängte Dateien:
-

beispiel.gif
2,5 KB
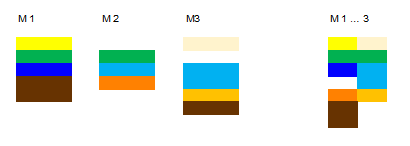{kind=link}
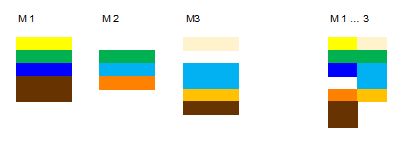
Gustl B. schrieb: > Genau. Und welche Sensoren und welche Aktoren die haben kann man doch > als Konstanten in ein Es sind nicht nur Konstanten sondern auch teilweise andere Funktionen. Es gibt Abläufe, die nur in einigen Maschinen exisitieren. Und einige sind anders: Z.B. Muss bei manchen Konstellationen noch einige Extraprüfungen ablaufen, die es woanders nicht gibt. Hier ist ein Beispiel: Die SW-Komponenten einer gleichen Farbe definieren andere Funktionen, die ähnlicher Farbe ähnliche Funktionen, wo es nur um kleine Abweichungen geht und manche sind eben doppelt. Rechts ist die Vereinigungsmenge:
Berni-Bär 🐼 schrieb: > Es sind nicht nur Konstanten Habe ich auch nicht behauptet. Du hast eine Sammlung an Funktionen und Komponenten die alle in irgendeiner Variante von deinem Gerät gebraucht werden sollen - so wie eben das mit den Farben. Und dann definierst du in Konstanten an einem Ort, optimalerweise in einem Pakage, welche dieser Funktionen und Komponenten in der jeweiligen Variante benötigt werden. Variante 123 braucht I2C, aber kein SPI dafür 2x UART mit 115200 und 9600 Baud. Das schreibst du in Konstanten. Und dann kommt die Synthese, liest das Package, sieht die Konstanten und baut das dann so wie es in den Konstanten steht. Damit das geht muss man eben die oben von mir genannten Möglichkeiten verwenden um Code generisch zu schreiben. if G_INSTANTIATE_I2C = True generate inst_ic2_master : entity work.is2_master port map ( ... Oder beim UART dann für die Baudrate den jeweiligen Wert aus dem Package verwenden. So macht man das typischerweise. Hier https://stnolting.github.io/neorv32/#_processor_top_entity_generics ist eine Liste der Generics vom neorv32 RISC-V Prozessor/SoC. Wie man sieht wird da nur über Gnerics dem Toplevel gesagt was alles in das SoC reingebaut werden soll und wenn je mit welchen Eigenschaften. Edit: Berni-Bär 🐼 schrieb: > Rechts ist die Vereinigungsmenge: Die sollte dann aber auch die gleiche Dimmension haben. Also nur eine Spalte und keine zwei. Aber ja, jede Komponente muss erstmal existieren. Aber man braucht auch nur einen UART z. B. den muss man dann so schreiben dass man dem die Baudrate und so per Generic übergeben kann. Dann kann man den sooft man will mit unterschiedlichen Parametern verbauen.
Nein, es sind bisweilen ganz andere Formen von Schleifen.
Schleifen werden es sein. Bei FPGAs und den zugehörigen HDLs denkt man eher in Hardware. Aber auch da kann man natürlich Zustandsautomaten bauen die wiederkehrend Zustände durchlaufen. Man muss auch nicht alles generisch bauen, das kostet Zeit und lohnt sich vielleicht nicht. Wenn deine Geräte jeweils nur einen Zustandsautomaten haben, gleich im Toplevel, und sonst nicht viel passiert und es kaum andere Komponenten gibt. Ja dann kann man auch für jede Variante der Geräte schnell die FSM anpassen. Gut wäre vielleicht mal ein Beispiel was da in Gerät a und was in Gerät b rein soll und was du vor hast. Schön ist ja auch, dass man eine Simulation und Synthese ganz ohne FPGA machen kann. Das ist sogar sinnvoll. Denn dann sieht man was wegoptimiert wird, wieviele Ressourcen man von was braucht um danach das passende FPGA auszusuchen das nicht zu teuer aber auch nicht zu klein ist.
Berni-Bär 🐼 schrieb: > Es sind nicht nur Konstanten sondern auch teilweise andere Funktionen. > Es gibt Abläufe, die nur in einigen Maschinen existieren. > Und einige sind anders: Z.B. Muss bei manchen Konstellationen noch > einige Extraprüfungen ablaufen, die es woanders nicht gibt. Wenn man ähnliche Funktionen in C zusammenkopiert und alternativ ablaufen lässt, optimieren das doch schon die C-Compiler weitgehend weg und ersetzen die Funktionen durch identische Aufrufe. Das können die FPGA-tools doch noch viel besser. Als Beispiel werden doch auch Signal unterschiedlichen Namens zusammengefast, wenn sie zu allen Zeiten die gleichen Werte haben. Es wird sogar erkannt, wenn Bits sich nicht ändern, weil eventuell eine Adresse nicht richtig dekodiert ist und als Folge alles, was von diesem Bit abhängt, statisch codiert.
Und ganz im Ernst: Wenn sich die Maschinen mehr unterscheiden als sie Gemeinsames haben – dann entwerfe ich auch getrennte FSM. Wäre ja mit dem Klammerbeutel gepudert, wenn nicht.
Hallo Leute, ich habe mir jetzt den Thread teilweise durchgelesen. Wenn Berni-Bär es so meint wie ich es verstanden habe, dann hat er irgendwie ne zentrale state machine. Und je nach Maschine (also das Stück HW, das vom FPGA gesteuert werden soll, und von dem es verschiedene "Ausführungen" gibt), will er dann für alle Maschinentypen eine einzige FPGA-Version verwenden, in der dann abhängig von der konkreten Maschine über Parameter gesteuert verschiedene Teile der FSM ausgeführt werden sollen oder nicht. Also sowas gibt es in der Steuerungstechnik auch. Und jedenfalls dort ist ein solcher Entwicklungsansatz nahezu ein Garant für Chaos und spätere Unwartbarkeit des "Universalprogramms". Es entstehen immer, ich nenne es mal "Kreuzabhängigkeiten", d.h. die "Teil-FSMs" sind dann oft doch nicht völlig unabhängig voneinander. Ich habe sowas schon mehrfach erlebt, und es endete jedes Mal nicht optimal. Der ursprüngliche Gedanke, EINE Software für verschiedene Maschinenversionen zu pflegen, klingt verlockend, man muss Bugfixes etc. nur in einem Code nachziehen. Wenn man so entwas tun will, sollte man narrensichere Strukturen und Vorgehensweisen einfallen lassen! Falls ich die Intention von Berni-Bär komplett falsch verstanden habe, dann sorry für eure vergeudete Lesezeit. ciao Marci
Ich habe Berni-Bär so verstanden, dass er beklagt, für fünf Maschinen auch fünf FSM zu erzeugen. Er will das mit einer FSM erschlagen. Ich liege da aber sicher genauso falsch und Berni-Bär ist nur ein Chat-GPT-Robot, der uns testen will ... :-(
Kay-Uwe R. schrieb: > für fünf Maschinen > auch fünf FSM zu erzeugen. Mehr als 10 und die state machines sind schon da. Es geht nur darum wie man sie ohne viel Aufwand zusammenfassen kann. Kay-Uwe R. schrieb: > Wenn sich die Maschinen mehr unterscheiden als sie > Gemeinsames haben Sie unterscheiden sich zwischen 20% und 40% schätze ich mal. Marci W. schrieb: > Wenn man so entwas tun will, sollte man > narrensichere Strukturen und Vorgehensweisen einfallen lassen! Das möchten wir eben nicht. Jede SW wird an ihrer Maschine von der jeweiligen Abteilung gepflegt und erweitert. Durch das parallele Halten müssten die Codes nicht verändert werden, wenn sie zu einer neuen Universalsoftware vereinigt werden. Kay-Uwe R. schrieb: > und Berni-Bär ist nur ein > Chat-GPT-Robot, der uns testen will ... :-( Mist, enttarnt. Du hast es erfasst: Bill Gates hat mich erfunden, um ein schnudeliges kleines Forum in good old germany zu testen
Berni-Bär 🐼 schrieb: > Es geht nur darum wie man sie ohne viel Aufwand zusammenfassen kann. Warum denn zusammenfassen? Und hast die diese vielen FSMs alle in deinem Toplevel? Wieso nicht in einzelnen Komponenten? Wieso nicht generisch geschrieben?
Berni-Bär 🐼 schrieb: > Das möchten wir eben nicht. Jede SW wird an ihrer Maschine von der > jeweiligen Abteilung gepflegt und erweitert. Dann würde ich von der Idee einer "Universal-Software" Abstand nehmen und statt dessen einen Pool von "Features" pflegen. Aus diesem Pool wird dann mit Hilfe eines wie auch immer gearteten Konfigurationstools die für die jeweilige Maschine passende Version zusammengestellt. Die von dir geplante "Universalsoftware" hat einen Nachteil: in jeder Maschine ist der Code für alle Maschinentypen vorhanden. Selbst 20% bis 40% können ja ziemlich viel "Overhead" sein. Der Vorteil, "kenne ich eine, kenne ich alle" lässt sich auch in der konfigurierten Version durch eine konsistente Struktur erreichen. Jedenfall ist meine Erfahrung: es macht keinen Spaß, in einer wie auch immer gearteten "Software" sich durch die 60% des Codes zu wühlen, die auch tatsächlich mit der Maschine zu tun haben. Besser, dieser Ballast ist erst gar nicht vorhanden. Und noch zwei: wenn sich die "Features" nicht strikt voneinander trennen lassen, dann ist das ganze Konzept insgesamt shice. Und, wichtig: wie man das ganze sinnvoll aufbaut, hängt natürlich wesentlich davon ab, wie viele Features die Universalsoftware enthalten soll, wie viele Features die Maschinen dann davon verwenden und wie stark und ob die jeweiligen Features voneinander abhängig sind. Deshalb beruhen meine o.g. Aussagen auf gewissen Annahmen. ciao Marci
Marci W. schrieb: > Dann würde ich von der Idee einer "Universal-Software" Abstand nehmen > und statt dessen einen Pool von "Features" pflegen Ich auch. Bei mir gibt es auch ein Projekt mit einem 'Universal-FPGA-Design'. Da wird von außen über vier Leitungen eine Adresse und damit zwischen drei verschiedenen Funktionalitäten ausgewählt. Dabei ist die Hardware 100% identisch. Falls noch ein Controller im System steckt, könnte der das richtige FPGA-Design raussuchen und das FPGA entsprechend konfigurieren...
Gustl B. schrieb: > Berni-Bär 🐼 schrieb: >> Es geht nur darum wie man sie ohne viel Aufwand zusammenfassen kann. > > Warum denn zusammenfassen? Weil sie alle in ein file sollen und das mit möglichst wenig Aufwand. Es soll nichts geändert werden, um keine Risiken einzugehen und das neue aufwändig verifizieren zu müssen. Peter schrieb: > Der Vorteil ist, dass den Code dann keiner mehr versteht, und nur ich > den noch warten darf/kann. Das sichert meinen Arbeitsplatz. Anders herum: Die gelieferten FSMs werden nicht angetastet und bleiben unverändert. Keine Änderungen, kein Aufwand, keine Fehler. Wir wollen uns nur versichern, dass das Konzept nicht zu überbordenden code-Mengen führt.
Bernd schrieb: > Weil sie alle in ein file sollen und das mit möglichst wenig Aufwand. Seltsames Ziel. Mit HDLs kann man wunderbar generische Designs bauen. Bernd schrieb: > dass das Konzept nicht zu überbordenden code-Mengen führt. Wo ist das Problem dabei? Viel Code führt nicht automatisch zu hoher FPGA-Belegung und anders herum bekommt man ein FPGA auch schon mit sehr wenigen Zeilen Code voll wenn man es drauf anlegt oder wenn man z. B. nicht in Hardware denkt und gerne for-Schleifen verwendet.
Gustl B. schrieb: > Bernd schrieb: >> Weil sie alle in ein file sollen und das mit möglichst wenig Aufwand. > Seltsames Ziel. Das Vorgehen als solches halte ich schon für richtig. Mit Rücksicht auf Anforderungen aus Sicherheitsbereichen ist das sogar empfehlenswert. Wie groß der Code dabei letztenendes wird, hängt (wie schon vermutet) von dessen Gleichartigkeit ab. Wie gesagt würde ich es einfach ausprobieren. Das sollte schon gehen. Im Grunde ist es ja für die software nichts anderes, als das althergebrachte Auswerten von Abhängigkeiten. Die Synthese muss es ja auch bezüglich irgendwelcher IO-Jumper können, die ganze Funktionen und Funktionsblöcke umschalten. Die Redundanz fliegt da immer raus. Was ich mir nur vorstellen könnte: Wenn die FSMs aus unterschiedlichen Händen kommen und mit abweichenden Strukturen formuliert wurden, dann könnte da eventuell nicht alles beseitigt werden, was theoretisch raus könnte. Ohne einen konkreten Code anzusehen, ist da aber wenig zu sagen. Was man nur pauschal sagen kann: Die Synthese erkennt sehr gut, wenn irgendwelche bits nicht togglen oder gar nicht beschaltet sind und wirft große Zweige aus einem entstehenden design, nur weil vorne ein Registeranschluss fehlte etc. Das kann bisweilen zu bösen Überraschungen führen, wenn ein Entwickler lange glaubt, dass seine Schaltung noch in den FPGA passt, während er munter weiter baut.
Bernd schrieb: > In VHDL ist es so, dass mehr hardware angefordert wird, die meines > Wissens bei der Synthesumsetzung wieder zusammenfällt, weil Redundanz > eliminiert werden sollte. Sorry aber bei diesem "Satz" überfiel mich ein spontaner Kotzreiz und ich musste mir erstmal ne neue Tastatur besorgen. (1) lerne endlich mal FPGA von der Picke auf oder stelle jemanden ein, der das mal gelernt hat. State Maschine und deren Implementierung ist in Embedded C und in FPGA nicht dasselbe. Wo das C-Codierschwein eine state machine zur Protokoll-/Ablauf-steuerung/codierung sagt, verwendet man im FPGA eher einen "sequenzer" der prior nachgeordnete FSM anstösst, die wiederum data path umschalten. Bei den Abfragen auf die Maschinencodierung kommt es darauf an, ob diese Abfrage zur Compile- oder zur Laufzeit ausgeführt wird. Ersteres kann unter Umstanden automatisch bei der Code-übersetzung entfernt werden, wenn "dead code elimination" aktiv ist. Natürlich sollte auf "area" optimiert werden und bei einer "umfänglichen" aka vom C-Codierheini unnötig aufgeblähten" FSM ist eine one-hot" Codierung eher kontraproduktiv, da passt besser "binary". Und macht dir mal Gedanken was "Modulares Design" bedeutet und wie in diesem Zusammenhang die Konzepte "HAL" und device driver genutzt werden. Für eine saubere Umschaltung zwischen maschinenspez. Varianten muss man saubere Schnittstellen/Interface einführen und nicht irgendwo "Abfragen" in die Codebasis einstreuen . Buchtipp: https://shop.elsevier.com/books/hardware-firmware-interface-design/stringham/978-1-85617-605-7
Superbus schrieb: > Sorry aber bei diesem "Satz" überfiel mich ein spontaner Kotzreiz Dann suche bitte einen Arzt auf und unterlasse es, dich hier auszukotzen. Das braucht es nicht. Superbus schrieb: > State Maschine und deren Implementierung ist in Embedded C und in FPGA > nicht dasselbe. Vollkommen richtig. Hat aber auch niemand behauptet. Ich zumindest nicht. Ich schrieb: Bernd schrieb: > die state machines sind schon da. > Es geht nur darum wie man sie ohne viel Aufwand zusammenfassen kann. Superbus schrieb: > Für eine saubere Umschaltung zwischen maschinenspez. Varianten muss man > saubere Schnittstellen/Interface einführen und dann praktisch alles state machines neu schreiben. Wir haben es heute gestestet und der zusätzliche Platzbedarf hält sich in Grenzen.
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.