Hallo Forum, gleich vorweg möchte ich um Verzeihung für den langen Beitrag bitten. Danke für Euer Verständnis, dass ich keine wichtige Information auslassen möchte. Ich betreibe einen kleinen Docker Swarm Cluster mit aktuell nur einem Manager Node, darin verwende ich Traefik als Ingress Reverse Proxy. Auf dem "Cluster" laufen aktuell nur neun Services (inklusive Traefik, Docker Registry, Docker-Registry-Ui und Redis), und die übrigen fünf sind Webservices, alle in Golang und mit dem Framework Gofiber entwickelt. Ein geplanter weiterer Service für den Dateiaustausch in einer kleinen Gruppe wurde ebenfalls in Golang mit Gofiber gebaut, und er ist mein Sorgenkind. Lokal auf meinen Entwicklungsrechnern funktioniert die Software, und das tut sie auch, wenn ich sie zwar mit Docker, aber ausserhalb des Cluster starte. Aber sobald ich den Service in den Cluster und damit hinter Traefik und das Docker Networking packe, brechen Uploads bei ungefähr ca. 15 MB ab, und ich erhalte einen HTTP-Fehler 502 "Bad Gateway", als ob der Service nicht liefe oder sein Label für den TCP-Port nicht korrekt gesetzt wäre. Ich weiß jedoch zuverlässig, dass der Service läuft, denn das Upload-Formular erhalte ich auch nach einem solchen Fehler. Der Fehler tritt sowohl mit dem Mozilla Firefox als auch mit curl(1) auf. Gofiber loggt überhaupt nichts, als käme der Request dort gar nicht an. Auch die Gofiber-Einstellungen für solche Dateiuploads (StreamRequestBody und BodyLimit) sind (IMHO korrekt) gesetzt. Von Traefik erhalte ich sogar mit dem Loglevel TRACE lediglich den Hinweis, dass der Request mit einem HTTP 502 "Bad Gateway" beantwortet wurde. So weit, so schlecht, habe ich zum Testen und Eingrenzen der Fehlerursache eine entsprechende Software in Python geschrieben. Und das Komische ist nun: siehe da, die funktioniert dann perfekt hinter Traefik und dem Docker Swarm Networking. Zuletzt konnte ich mit Firefox als auch mit curl(1) jeweils 12 Gigabyte große Videodateien zur Python-Version hochladen. So, nun habe ich verschiedene Möglichkeiten überlegt, allerdings bin ich in der Umgebung leider etwas eingeschränkt, ist nur ein Virtual Private Server. Mich einfach mal mit gdb(1), tcpdump(1), strace(1) und / oder ltrace(1) dort hinein zu hängen scheidet daher leider aus Performance- und Ressourcengründen aus. In meiner Not habe ich mal die Timeouts und die Buffering-Middleware von Traefik konfiguriert und ausprobiert, das hat aber nichts genutzt. Sorry, ich stochere im Nebel, und so langsam gehen mir die Ideen aus. Klar, ich könnte die Python-Variante ausentwickeln, es geht ja eh primär um I/O. Aber während mein Ehrgeiz geweckt ist, ist mein Latein kurz vor dem Ende. Hat hier vielleicht jemand eine kluge Idee? Dann bitte, her damit. Ansonsten lieben Dank für das Lesen und Durchhalten dieses langen Beitrags, habt einen schönen Abend und einen frohen Feiertag. Liebe Grüsse, Sheeva
Eine kleine Skizze, die alle aktiven und passiven Einheiten in Deinem Netzwerk zeigt, würde schon mal sehr helfen. Ich verstehe auch nicht genau, was Deine Python-Software nun macht? Beschreibe mal genau: Welcher Prozess initiiert einen Datentransfer. Wo genau läuft dieser Prozess? Wie konnektiert er den Reverse Proxy, wie konnektiert dieser dann das endgültige Ziel? Welches Transportprotokoll wird verwendet? Ich lese TCP heraus, stimmt das? Gibt es nur eine Session für den Transfer, oder werden einzelne Chunks in parallelen Sessions übertragen? Gibt es im Falle des Ingress-Proxys ggf. MTU Reduktionen? Ersetzt Dein Python-Programm das Ziel, oder hängt es als weitere Instanz dazwischen? Du hast also einen Transfer-Initiator und einen Transfer-Empfänger. Wenn Du beide Softwareinstanzen auf unterschiedlichen Hosts startest, funktioniert der Transfer. Auch wenn der Initiator in einen Docker-Container geschoben wird, klappt noch alles. Wie und wo läuft der Empfänger/Datensenke? Das Problem tritt erst dann auf, wenn Du in die HA/Lastverteilung gehen willst und den Ingress-Proxy dazwischen packst? Letztendlich ist es dann sehr interessant, das Routing und das Binding der verschiedenen Komponenten zu sehen. Gesetzt den Fall, ich liege mit meiner Vermutung richtig, dass Deine Python-Software das Ziel ersetzt, wie bindet diese an das entsprechende Interface? Welche IP-Adresse/Port wird dadurch verwendet? Wie bindet das Original?
Hallo Peter, Peter schrieb: > Eine kleine Skizze, die alle aktiven und passiven Einheiten in Deinem > Netzwerk zeigt, würde schon mal sehr helfen. Lieben Dank fürs Lesen und Deine Antwort. Ich werde die Skizzen malen und nachliefern, das bekomme ich aber heute leider nicht mehr ordentlich hin. > Ich verstehe auch nicht genau, was Deine Python-Software nun macht? Im Kern dasselbe wie die Go-Software: es wird ein HTML-Formular <form> mit einem <input type="file" name="document"> und ein <input type="submit"> dargestellt, das Formular selbst ist in beiden Fällen mit method="POST", action="/upload" und enctype="multipart/form-data" gesetzt. Dann: Datei auswählen, auf "Ok" klicken, warten. :-) > Beschreibe mal genau: Welcher Prozess initiiert einen Datentransfer. (M)Ein Client, mithin: einer meiner Client-Rechner bzw. Desktops. Das ist in einem Fall ein Dell Latitude 5580, im anderen Fall ein selbst gebauter Ryzen, beide mit NVMEs. Beide zeigen allerdings exakt dasselbe Verhalten, und auch noch mir verschiedener Software (Firefox und curl(1). Clientseitige Fehler wären daher aus meiner Sicht eher ungewöhnlich und wenig wahrscheinlich. Dasselbe Verhalten tritt aber auch mit einem Edge-Browser unter Windows11 auf, so bin ich erst auf die Nummer gekommen. > Wo genau läuft dieser Prozess? Wie konnektiert er den Reverse Proxy, wie > konnektiert dieser dann das endgültige Ziel? Die Clientprozesse laufen auf meinem Desktop bzw. meinem Laptop, beide unter Kubuntu 22.04 LTS, und konnektieren den Reverse Proxy über HTTPS (HTTP mit TLS / SSL). Der Reverse Proxy terminiert in beiden Fällen die TLS-Verschlüsselung und geht mit nicht verschlüsseltem HTTP auf das Backend (dabei ist das Docker-Netzwerk zwischen Traefik und Prozess jedoch symmetrisch verschlüsselt). > Welches Transportprotokoll wird verwendet? Ich lese TCP heraus, stimmt > das? HTTP und HTTPS laufen zumindest bis inklusive Version 2 meines Wissens über TCP, bei HTTP(S) Version 3 gibt es wohl auch einen UDP-Transport. Aber dafür ist meines Wissens keine der beteiligten Komponenten ausgelegt. Trotzdem eine gute Idee, das könnte ich mal lokal beschnüffeln, nicht dass da irgendwelche komischen Vögel UDP nutzen. Danke für die Idee! > Gibt es nur eine Session für den Transfer, oder werden einzelne Chunks > in parallelen Sessions übertragen? Oh, danke, das könnte ein Ansatz sein. AFAIR limitiert Traefik HTTP/2 auf 250 Verbindungen pro Client, das könnte den Unterschied ausmachen. > Gibt es im Falle des Ingress-Proxys ggf. MTU Reduktionen? Noch so eine gute Idee, das teste ich mal und melde zurück. Dankeschön! > Ersetzt Dein Python-Programm das Ziel, oder hängt es als weitere Instanz > dazwischen? Das Python-Programm ersetzt das Ziel. > Du hast also einen Transfer-Initiator und einen Transfer-Empfänger. Wenn > Du beide Softwareinstanzen auf unterschiedlichen Hosts startest, > funktioniert der Transfer. Auch wenn der Initiator in einen > Docker-Container geschoben wird, klappt noch alles. > Wie und wo läuft der Empfänger/Datensenke? Dazu habe ich drei getestete Szenarien. Erstens, die Datensenke läuft als Container im Docker Swarm Cluster, was für Golang nicht, aber für Python funktioniert. Zweitens, die Datensenke läuft als Container, aber nicht im Cluster, was für Golang und Python funktioniert. Drittens, die Datensenke läuft lokal, auch da funktionieren beide. > Das Problem tritt erst dann auf, wenn Du in die HA/Lastverteilung gehen > willst und den Ingress-Proxy dazwischen packst? Ich gehe ja nicht einmal in die Lastverteilung, der "Cluster" besteht ja nur aus einem Testnode im Swarm-Modus. Ausserhalb dieses Swarm-Node, mithin auch dann, wenn ich daselbe Golang-Image mit "docker run --publish 3001:3001" ohne Swarm nur in Docker starte, geht auch alles. > Letztendlich ist es dann sehr interessant, das Routing und das Binding > der verschiedenen Komponenten zu sehen. Da stimme ich absolut zu! Wenn Du Ideen hast... you're very welcome! :-) > Gesetzt den Fall, ich liege mit meiner Vermutung richtig, dass Deine > Python-Software das Ziel ersetzt, wie bindet diese an das entsprechende > Interface? Welche IP-Adresse/Port wird dadurch verwendet? > Wie bindet das Original? Sowohl Python als auch Golang binden den Container an Port 3001, das Swarm-Label für die Portkonfiguration in Traefik zeigt in beiden Fällen auf 3001; die Golang-Implementierung nutzt an dieser Stelle <code> const ADDRESS = ":3001" // ... log.Fatal(app.Listen(ADDRESS)) </code> und Python (schneller Hack zum Testen...): <code> app.run(host='0.0.0.0', port=3001, debug=True) </code> Offensichtlich gibt es da einen Unterschied jenseits der verwendeten Sprache, und ich scheine zu doof zu sein, den zu sehen. Die Grafiken, nach denen Du gefragt hast, werde ich narürlich so schnell wie möglich nachliefern. Für morgen kann ich nichts versprechen, aber am Freitag sollte ich das hoffentlich hinbekommen. Lieben Dank für Deine Antwort! Liebe Grüsse, Sheeva </code>
Reverse-Proxy-Config (vom traefic) anschauen. Wenn du plump per "type=file"-POST den upload machst, muss die ganze Datei (nach encoding) in die "maxRequestBodyBytes" passen. Die Datei wandert komplett in den Reverse-Proxy, und erst wenn die dort zu 100% angekommen und gebuffert ist, schickt der den Request an den Backend-Service weiter. Darum siehst du dort auch nichts im Log. Den Wert beliebig groß stellen hilft irgendwann auch nichts mehr, dann kriegt der Client wegen der doppelten Wartezeit Timeouts. Du kannst den Dateiupload "streamen", in Chunks senden, braucht aber Javascript am Client. Evtl. kannst du das Buffering im traefik auch ganz abschalten, und den Request weitersenden lassen bevor der Request-Body komplett ist. Wenn's nicht der traefic ist: Schau dir die Memory-Limits der Container im Swarm und Nicht-Swarm Modus an.
OK, schon mal ein wichtiger Punkt dabei. Ich ging von entgegengesetzter Transferrichtung aus. Ein Punkt mehr, für eine gute Skizze! Dann ist in solchen Fällen immer sinnvoll, alle nicht für das Funktionieren der problematischen Funktion notwendigen Services etc. zu deaktivieren und dann auch in der Doku zunächst wegzulassen. Spart auch den Helfern das Nachdenken über unnötige Dinge! KISS-Prinzip. In Deiner letzten Antwort taucht nun HTTP/2 auf! Kannst Du das auch genauer spezifizieren? Was verwendet dann dein Python-Downloader? Was sagt Dir curl im Verbose-Modus, wenn es mit --http2 oder --http2-prior-knowledge gestartet wird?
Εrnst B. schrieb: > Reverse-Proxy-Config (vom traefic) anschauen. Die kenne ich bald auswendig. :-) > Wenn du plump per "type=file"-POST den upload machst, muss die ganze > Datei (nach encoding) in die "maxRequestBodyBytes" passen. Klar, deswegen hatte ich ja Traefiks Buffering-Middleware versucht und dort die maxRequestBodyBytes entsprechend groß gesetzt. Wenn der Upload nicht in den Arbeitsspeicher paßt, puffert diese Middleware laut ihrer Dokumentation alles was größer als memRequestBodyBytes auf die Disk, was für mich ja auch vollkommen okay wäre, deswegen hatte ich diesen Parameter auf 1 MB gesetzt. > Die Datei wandert komplett in den Reverse-Proxy, und erst wenn die dort > zu 100% angekommen und gebuffert ist, schickt der den Request an den > Backend-Service weiter. > > Darum siehst du dort auch nichts im Log. Just dies ist auch mein Verdacht... > Den Wert beliebig groß stellen hilft irgendwann auch nichts mehr, dann > kriegt der Client wegen der doppelten Wartezeit Timeouts. Aber nach 15 Sekunden schon? Hmmm... > Du kannst den Dateiupload "streamen", in Chunks senden, braucht aber > Javascript am Client. Puh... an sich würde ich das lieber vermeiden, zumal dieselbe Geschichte ja mit Python und Flask sauber funktioniert. > Evtl. kannst du das Buffering im traefik auch ganz abschalten, und den > Request weitersenden lassen bevor der Request-Body komplett ist. Danke für den Tipp, danach habe ich mir schon die Finger wundgesucht und nichts gefunden. Das Komische ist halt, daß es mit Python und Flask ohne irgendwelche Konfiguration funktioniert, aber mit Gofiber nicht. > Wenn's nicht der traefic ist: Schau dir die Memory-Limits der Container > im Swarm und Nicht-Swarm Modus an. Zum Testen haben die Container gar keine Memory Limits konfiguriert und könnten bis zum ENOMEM Speicher kaufen, soviel sie wollen. Peter schrieb: > OK, schon mal ein wichtiger Punkt dabei. Ich ging von entgegengesetzter > Transferrichtung aus. Ein Punkt mehr, für eine gute Skizze! Ich hab' mal drei Skizzen angehängt und hoffe, daß sie gut und verständlich sind. Wenn nicht, bitte ich um Verzeihung, der Arbeitstag war lang... > Dann ist in solchen Fällen immer sinnvoll, alle nicht für das > Funktionieren der problematischen Funktion notwendigen Services etc. zu > deaktivieren und dann auch in der Doku zunächst wegzulassen. Spart auch > den Helfern das Nachdenken über unnötige Dinge! Ich habe die anderen Services jetzt alle mal gelöscht, aber leider keine Änderung feststellen können: Python/Flask funktioniert, Gofiber nicht. > In Deiner letzten Antwort taucht nun HTTP/2 auf! Kannst Du das auch > genauer spezifizieren? Was verwendet dann dein Python-Downloader? Es geht um einen Upload einer Datei von einem Client (Firefox, curl(1)) auf einen Server. Downloads vom Server auf den Client funktionieren mit Gofiber und mit Python/Flask ohne Probleme. > Was sagt Dir curl im Verbose-Modus, wenn es mit --http2 oder > --http2-prior-knowledge gestartet wird? Das ist eine gute Idee, das werde ich mal als nächstes testen... aber sicher nicht mehr heute, wie gesagt: der Tag war schon lang genug. Vielen lieben Dank Euch beiden für Eure Bemühungen und Eure Antworten, ich hoffe, meine Skizzen erhellen die Szenerie ein wenig. Nochmals Danke und schönes Wochenende!
Kannst Du Zeichnungen nicht in einem gebräuchlichen Format wie PNG,SVG etc. einstellen? Irfanview, Faststone, Gimp, Inkscape kennen das Format nicht. :-(
Peter schrieb: > Kannst Du Zeichnungen nicht in einem gebräuchlichen Format wie PNG,SVG > etc. einstellen? > Irfanview, Faststone, Gimp, Inkscape kennen das Format nicht. :-( https://www.mikrocontroller.net/articles/Bildformate
dia Dateien? Was ist das denn?
Das scheint hiermit http://www.lysator.liu.se/~alla/dia/ erzeugt zu sein, zumindest steht das im Header der Dateien drin (die sind mit Zip o.ä. verpackt). Aber das ist 404. https://dia-list.gnome.narkive.com/sobOBsXN/http-www-lysator-liu-se-alla-dia Ist jetzt auch nicht sehr aufschlusserregend.
Angehängte Dateien:
-

Architektur.png
7,7 KB -

GrosseDatei.png
16 KB -

KleineDatei.png
15 KB
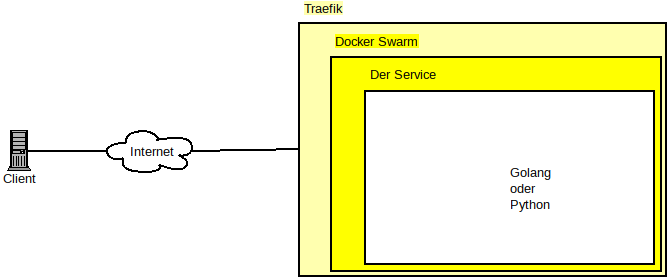
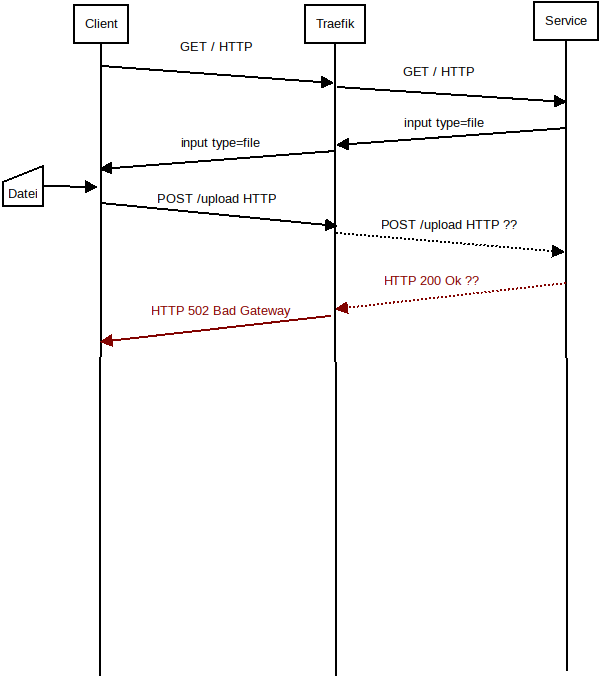
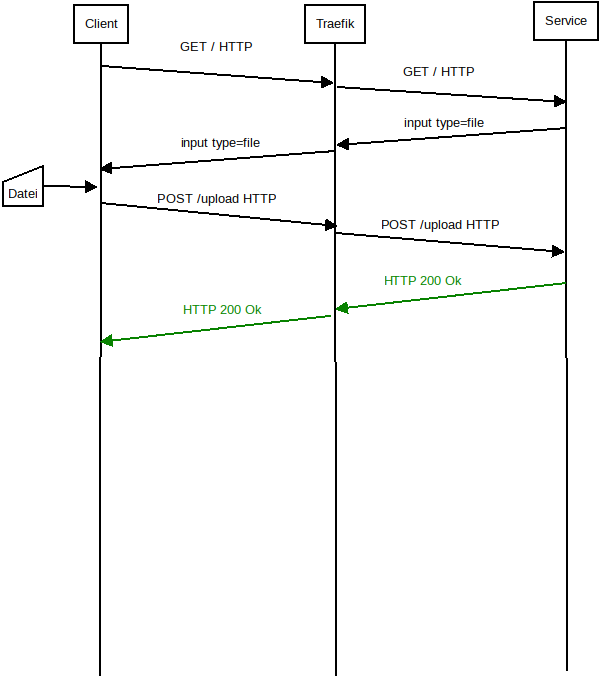
Peter schrieb: > Kannst Du Zeichnungen nicht in einem gebräuchlichen Format wie PNG,SVG > etc. einstellen? > Irfanview, Faststone, Gimp, Inkscape kennen das Format nicht. :-( Oh, huch... Verzeihung, das war keine Absicht... wie gesagt, gestern war ein langer Tag. Hier also nochmal als PNGs.
Harald K. schrieb: > Das scheint hiermit http://www.lysator.liu.se/~alla/dia/ erzeugt zu > sein, zumindest steht das im Header der Dateien drin (die sind mit Zip > o.ä. verpackt). > > Aber das ist 404. Dia gibts schon ewig, und ich bin immer wieder erstaunt, daß das sogar unter Fachleuten so wenige kennen. Dabei war das schon vor zwanzig Jahren saucoole Software: plattformübergreifend bearbeitbare Vektorgrafiken mit Objektbögen, vom Flußdiagramm bis hin zu UML-Objektdiagrammen. Ok, die sehen (ohne große Nacharbeiten) nicht so schick aus wie in MS Visio. Aber dafür hab ich schon vor > 15 Jahren damit ein PHP-Framework entwickelt, mit dem die Datenbanken mit Dia gezeichnet, und dann mit einer gepimpten Version von tedia2sql eine sofort brauchbare, verfeinerbare Webapplikation generiert werden konnte. Das ist heute in Zeiten von Django und anderen Frameworks sicherlich nicht mehr sonderlich sensationell, aber damals... Die aktuelle Seite ist [1]. [1] http://dia-installer.de/
Sheeva P. schrieb: > Die aktuelle Seite ist [1]. Der Name klingt ja total vertrauenserweckend. Immerhin steht da nicht noch "softonic" oder der Name irgendeiner anderen Crap-Seite dabei. Aber ja, ungeschickter Name, aber auf der offizielleren Seite auch verlinkt: https://wiki.gnome.org/Apps/Dia/Download (Nicht professionell ist es, in der XML-Beschreibung des Formats eine tote URL unterzubringen) -- Der Punkt bei der Diskussion ist übrigens weniger, ob man "dia" kennt und nutzt, sondern die frechdreiste Annahme, daß das jeder, der sich hier simple Bilder ansehen will, das schon auf seinem Rechner installiert haben wird. Genauso frechdreist wie die Annahme, jeder hier könne direkt etwass mit Eagle- oder KiCad-Dateien anfangen, wenn es darum geht, einen Schaltplan zu zeigen. Oder --was auch schon vorgekommen ist-- ein MS Word-Dokument, um einen simplen Screenshot zu zeigen.
Harald K. schrieb: > Der Punkt bei der Diskussion ist ... das unterschiedliche Verhalten von Gofiber und Flask beim Upload großer Dateien hinter Traefik. Dazu hast Du offensichtlich nichts beizutragen, wen wundert's. Also geh weg, hier gibt es nichts zu trollen.
Interessant wie ahnungs- und planlos und völlig ohne Intuition die Leute hier vorgehen und nicht mal ansatzweise die Zusammenhänge verstehen. Der Ursposter will mit gdb und tcpdump der Ursache auf den Grund gehen, dazu noch timinigmessungen LOL. Fehlt noch das Multimeter am Netzwerkkabel aber mit Docker und Reverseproxies rumhantieren wollen. Ich hoffe das ist nicht dein Job. Wenn man schon mal ein bisserl mit http zu tun hatte, weiss man gleich wo das Problem liegen könnte. Der nächste fragt ob TCP verwendet wird. Dümmer gehts nimmer aber wichtig mitschwafeln wollen, könnte ein Lehrer sein. Der nächste fordert für das Trivialszenario Bildchen, weil er schon mit dem Text überfordert ist und der Urposter bastelt das auch noch treurdoof zusammen und bekommt prompt eine auf den Deckel wegen dem Format. Dann kommt der Erich und gibt zuverlässig sinnvolle Antworten wenn es um Webzeugs geht. Das ist echt Comedy pur in diesem Forum.
Franko S. schrieb: > Wenn man schon mal ein bisserl mit > http zu tun hatte, weiss man gleich wo das Problem liegen könnte. Dann erzähl' doch mal, ich harre Deiner Erklärungen mit großer Spannung. > Der nächste fragt ob TCP verwendet wird. So blöd finde ich die Frage gar nicht, HTTP/3 basiert schließlich auf QUIC und somit also auf UDP.
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.