Ein Medianfilter ist gut geeignet, um Ausreißer wegzufiltern. Ich bin auf der Suche nach einer Effizienten Routine in C++. Es gibt scheinbar haufenweise Implementierungen, aber welche Art ist die effizienteste? Im Moment scheint mir die Verwendung einer "linked List" am besten: https://community.infineon.com/gfawx74859/attachments/gfawx74859/PSoC6MCU/8068/2/MedianFilter_v0_0_A.pdf Gibt es schnellere Möglichkeiten?
Da scheint eine lineare Suche beim Hinzufügen nötig zu sein? Da würde ich doch lieber eine sortierte Baumstruktur nehmen, std::set oder so.
Kommt auf die Menge der zu erfassenden Daten und den Bedarf an Rückschau an. Zu beiden hat sich der TE noch nicht eingelassen.
Die Ausreißer sind eher selten und der Filter soll eine Länge zwischen 3,5,7,9 Samples haben. Für den Rechenzeitbedarf würde ich kleiner gleich 20us auf einem Atmega328 für die Länge 3 und int16_t erwarten.
Christoph M. schrieb: > Für den Rechenzeitbedarf würde ich kleiner gleich 20us auf einem > Atmega328 für die Länge 3 und int16_t erwarten Das wären mehr als reichliche 320 Taktzyklen bei 16MHz. Da kann man's ja fast in COBOL schreiben.
Beitrag #7666602 wurde von einem Moderator gelöscht.
Christoph M. schrieb: > Gibt es schnellere Möglichkeiten? It depends... Bei kleinen Filterlängen, 3,5,7, ist binäre Suche in einem Array dessen Elemente verschoben werden oft schneller. Bei grossen Filterlängen ein B-Baum.
Michael B. schrieb: > It depends... Absolut. > Bei kleinen Filterlängen, 3,5,7, ist binäre Suche in einem Array dessen > Elemente verschoben werden oft schneller. Bei grossen Filterlängen ein > B-Baum. Die genaue Grenze hängt von der Architektur ab, vom Compiler und vor allem auch vom Signal selber. Es ist also sehr schwierig bis nahezu unmöglich, hier eine genaue genaue Grenze für die Entscheidung Array vs. B-Tree anzugeben. Da hilft nur: beides Implementieren und dann Ausprobieren, was im konketen Fall besser performt. Und nicht mal dann ist man auf der sicheren Seite: die Signaleigenschaften können sich schließlich auch ändern...
Michael B. schrieb: > Bei kleinen Filterlängen, 3,5,7, Was heißt denn hier Filterlänge? Zahl der zu untersuchenden letzten Samples? Wieviele sollen behalten werden? Und wie wird der Median bestimmt? Warum nicht gleich addieren und den kleinsten / größten mitnehmen und jeweils entscheiden? Das wäre das Einfachste, wenn immer nur ein Ausreisser gefiltert werden muss. Und dann braucht es noch eine Definition für Ausreisser, weil das ja auch ein sich ändernder Messwert sein kann.
Kati schrieb: > Und wie wird der Median bestimmt? Das ist definiert und bereits millionenfach beschrieben. > Warum nicht gleich addieren und den kleinsten / größten > mitnehmen und jeweils entscheiden? Das ist mit beinahe chirurgischer Präzision das exakte Gegenteil.
Christoph M. schrieb: > Gibt es schnellere Möglichkeiten? Möglicherweise C oder Asm. Wäre ich aber nicht so sicher, die verfügbaren Bibs sind schon sehr gut. Den Code selber ansehen, ob noch was optimiert werden kann, kann auch helfen, oder von mir aus auch so ein Peep-Hole-Optimizer. Je nachdem, ein wenig ausprobieren kostet nicht viel. Man kann ja auch selbst eine Statistik machen, welcher Code besser performt. Lesen, also theoretische Überlegungen helfen natürlich auch noch, muss man halt auch lesen bzw. durcharbeiten. https://www.ripublication.com/ijaer18/ijaerv13n12_107.pdf https://www.researchgate.net/publication/338076963_Study_of_Median_Filters_and_Fuzzy_Rules_for_Filtering_of_Images_Corrupted_With_Mixed_Noise https://www.researchgate.net/publication/261091013_Bidimensional_median_filter_for_parallel_computing_architectures
Hi, meines Kenntnisstands nach heißt 9 sample median: 9 samples der Größe nach sortieren und den Fünftgrößten nehmen. Wenn ein neuer kommt, den ältesten aus der Liste rausnehmen und den neuen einsortieren. Sortieren ist O(n*log(n)), Einsortieren in eine vorsortierte Liste ist vielleicht sogar nur O(log(n)). Das geht schnell. Interessantes Problem, wenns morgen regnet probier ich das vllt. mal aus. Cheers Detlef
Hallo Detlef_., ob das denn wohl so sinnvoll ist, mit der O()-Notation für n=9 zu argumentieren? :)
Peter M. schrieb: > Hallo Detlef_., > > ob das denn wohl so sinnvoll ist, mit der O()-Notation für n=9 zu > argumentieren? :) Ja ebent, das geht immer schnell.
Hier hab ich einen mittelmäßig effizienten medianfilter gebaut, Laufzeit ist O(n). Es wird eine sortierte Liste mitgeführt. Es wird aber noch so einiges hin und hergeschoben, das ist unschön und kostet Zeit. Mit mehr Überlegen und mehr Listen könnte man die Laufzeit vllt. auf O(log(n)) drücken, aber, wie Peter ja richtig sagte, n ist sowieso klein. Cheers Detlef
1 | #include <stdio.h> |
2 | #include <stdlib.h> |
3 | #include <stdint.h> |
4 | |
5 | /***************************************/ |
6 | float median(float neu){
|
7 | /***************************************/ |
8 | int32_t k,m; |
9 | |
10 | #define NN (7) |
11 | |
12 | static float alt[NN]; |
13 | static int32_t gross[NN]; |
14 | static int32_t w=0; |
15 | |
16 | //Ini |
17 | |
18 | if(w==0){
|
19 | for(m=0;m<NN;m++)alt[m]=0.0; |
20 | for(m=0;m<NN;m++)gross[m]=m; |
21 | w=1; |
22 | } |
23 | |
24 | // Den ältesten rausschmeissen |
25 | k=0; |
26 | while(1) {
|
27 | if(gross[k]==NN-1) break; |
28 | k++; |
29 | } |
30 | |
31 | //printf("alt %d ",k);
|
32 | |
33 | while(1) {
|
34 | if(k==0) break; |
35 | gross[k]=gross[k-1]; |
36 | k--; |
37 | } |
38 | |
39 | // Wo musser denn hin? |
40 | k=0; |
41 | while(1) {
|
42 | if(alt[gross[k+1]]>neu) break; |
43 | k++; |
44 | if(k==NN-1) {break;};
|
45 | } |
46 | //printf("hoch %d ",k);
|
47 | |
48 | // Platz da |
49 | m=0; |
50 | while(1) {
|
51 | if(k==m) break; |
52 | gross[m]=gross[m+1]; |
53 | m++; |
54 | } |
55 | |
56 | gross[k]=-1; |
57 | //printf("gr %d %d %d ",gross[0],gross[1],gross[2]);
|
58 | for(m=0;m<NN;m++) gross[m]++; |
59 | //printf("gr %d %d %d ",gross[0],gross[1],gross[2]);
|
60 | |
61 | // ruecken |
62 | m=NN-1; |
63 | while(1) {
|
64 | alt[m]=alt[m-1]; |
65 | m--; |
66 | if(m==0) break; |
67 | } |
68 | |
69 | alt[0]=neu; |
70 | |
71 | return(alt[gross[(NN-1)/2]]); |
72 | } |
73 | |
74 | |
75 | /***************************************/ |
76 | int main() |
77 | /***************************************/ |
78 | { int32_t k;
|
79 | float bla; |
80 | float ee; |
81 | |
82 | for(k=0;k<20;k++){
|
83 | bla=k+1; |
84 | if(k==13) bla=1000; |
85 | ee=median(bla); |
86 | printf("%d %.0f \r\n",k,ee);
|
87 | } |
88 | return 0; |
89 | } |
>Hier hab ich einen mittelmäßig effizienten medianfilter gebaut, Laufzeit >ist O(n). Danke für den Code. Wenn ich darauf schaue, müsste die Laufzeit gegen
gehen. Das scheint mir eher eine Debug-Version zu sein, im Code steht haufenweise:
1 | while(1) |
Angehängte Dateien:
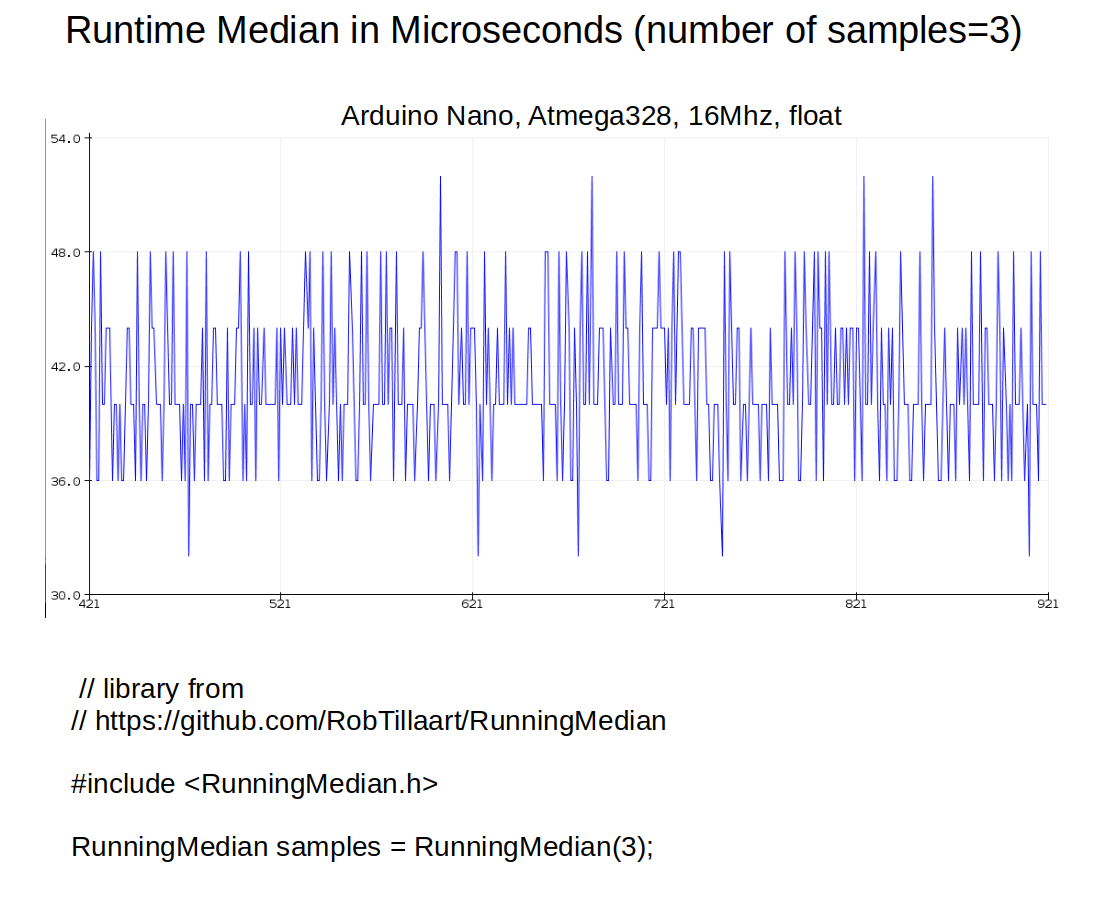
Hier mal ein Benchmark mit Float.
1 | // install median library:
|
2 | // https://github.com/RobTillaart/RunningMedian
|
3 | |
4 | #include <RunningMedian.h> |
5 | |
6 | RunningMedian samples = RunningMedian(3); |
7 | |
8 | typedef float median_t; |
9 | |
10 | void setup() |
11 | {
|
12 | Serial.begin(115200); |
13 | }
|
14 | |
15 | void loop() |
16 | {
|
17 | uint32_t ts; |
18 | median_t x = random(); |
19 | median_t y; |
20 | |
21 | ts = micros(); |
22 | //y = median(x);
|
23 | samples.add(x); |
24 | y = samples.getMedian(); |
25 | uint32_t ende = micros(); |
26 | |
27 | Serial.println("value" + String(y) + " time used [us]: " + String(ende - ts)); |
28 | delay(10); |
29 | |
30 | }
|
Angehängte Dateien:
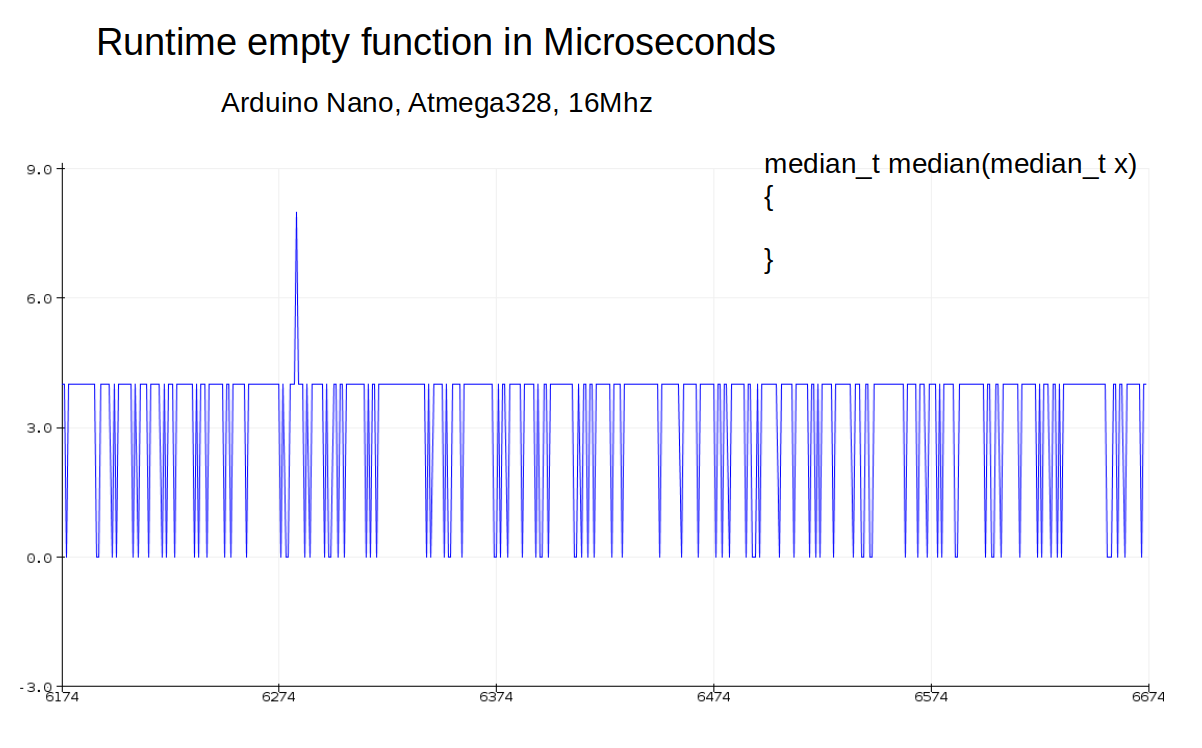
Zum Vergleich die leere Medianfunktion.
Christoph M. schrieb: > Das scheint mir eher eine Debug-Version zu sein, im Code steht > haufenweise: > while(1) Vielleicht machst du dich mal mit ›break‹ vertraut. ;-)
Detlef _. schrieb: > // Wo musser denn hin? > k=0; > while(1) { > if(alt[gross[k+1]]>neu) break; > k++; > if(k==NN-1) {break;}; > } Süß. Meine erstes Bubblesort auf dem C64 vor genau 40 Jahren war ähnlich gut lesbar.
Angehängte Dateien:
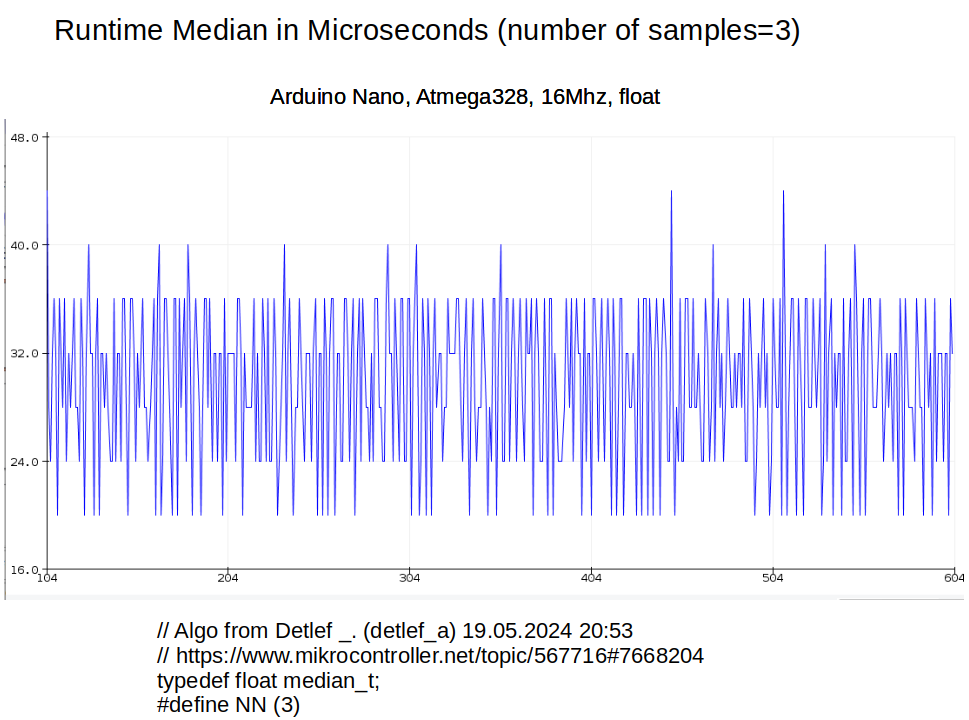
>Vielleicht machst du dich mal mit ›break‹ vertraut. ;-)
Upps, ich bin damit vertraut, aber trotz angestrengtem Hinschauen hat es
mein Hirn ignoriert.
Die Detlev'sche Version ist etwas schneller als die Tillaart'sche :-)
Ob der Median richtig sortiert, habe ich nicht geprüft, nur wie schnell
der Algo läuft ..
1 | // Algo from Detlef _. (detlef_a) 19.05.2024 20:53
|
2 | // https://www.mikrocontroller.net/topic/567716#7668204
|
3 | |
4 | typedef float median_t; |
5 | |
6 | #define NN (3)
|
7 | |
8 | median_t median(median_t neu) |
9 | {
|
10 | int32_t k, m; |
11 | static median_t alt[NN]; |
12 | static int32_t gross[NN]; |
13 | static int32_t w = 0; |
14 | |
15 | //Ini
|
16 | if (w == 0) |
17 | {
|
18 | for (m = 0; m < NN; m++) alt[m] = 0.0; |
19 | for (m = 0; m < NN; m++) gross[m] = m; |
20 | w = 1; |
21 | }
|
22 | |
23 | // Den ältesten rausschmeissen
|
24 | k = 0; |
25 | while (1) |
26 | {
|
27 | if (gross[k] == NN - 1) break; |
28 | k++; |
29 | }
|
30 | |
31 | while (1) |
32 | {
|
33 | if (k == 0) break; |
34 | gross[k] = gross[k - 1]; |
35 | k--; |
36 | }
|
37 | |
38 | // Wo musser denn hin?
|
39 | k = 0; |
40 | while (1) |
41 | {
|
42 | if (alt[gross[k + 1]] > neu) break; |
43 | k++; |
44 | if (k == NN - 1) break; |
45 | }
|
46 | |
47 | // Platz da
|
48 | m = 0; |
49 | |
50 | while (1) |
51 | {
|
52 | if (k == m) break; |
53 | gross[m] = gross[m + 1]; |
54 | m++; |
55 | }
|
56 | |
57 | gross[k] = -1; |
58 | for (m = 0; m < NN; m++) gross[m]++; |
59 | // ruecken
|
60 | m = NN - 1; |
61 | while (1) |
62 | {
|
63 | alt[m] = alt[m - 1]; |
64 | m--; |
65 | if (m == 0) break; |
66 | }
|
67 | |
68 | alt[0] = neu; |
69 | return (alt[gross[(NN - 1) / 2]]); |
70 | }
|
71 | |
72 | void setup() |
73 | {
|
74 | Serial.begin(115200); |
75 | }
|
76 | |
77 | void loop() |
78 | {
|
79 | uint32_t ts; |
80 | median_t x = random(); |
81 | median_t y; |
82 | |
83 | ts = micros(); |
84 | y = median(x); |
85 | uint32_t ende = micros(); |
86 | |
87 | Serial.println("value" + String(y) + " time used [us]: " + String(ende - ts)); |
88 | delay(10); |
89 | |
90 | }
|
Hab's gerade mal in – Obacht – Python programmiert und auf dem Mikrocontroller laufen lassen. FILTERSIZE = 9 same values: 10.21 µs linear up: 24.76 µs linear down: 23.29 µs random values: 24.09 µs Gar nicht mal so übel. Kommt zwar nicht an die Thumb Assembler Version heran, aber immerhin gut für ~40.000 Werte pro Sekunde…
Beitrag #7668736 wurde von einem Moderator gelöscht.
Klaus schrieb: > Norbert schrieb: >> FILTERSIZE = 9 > > Christoph M. schrieb: >> #define NN (3) > > Äpfel und Birnen? Nein Klaus, viel einfacher. Einmal Drei und einmal Neun. Kann man auch mit etwas Eigeninitiative ablesen. Hint: Wenn man's mit ›3‹ macht, dann wird's schneller. Wenn man's mit ›15‹ macht, dann wird's langsamer. Hint2: Es ging nicht um einen direkten Vergleich. Hint3: Bei einer Filterlänge von ›3‹ wäre der Aufwand des beschriebenen Algorithmus um Größenordnungen zu hoch! Das könnte man mit einigen wenigen simplen Vergleichen viel schneller haben.
Christoph M. schrieb: > Upps, ich bin damit vertraut, aber trotz angestrengtem Hinschauen hat es > mein Hirn ignoriert. Ist auch ein bisschen ungewöhnlich bis pervers, die Abbruchbedingung in ein if zu packen, statt direkt in das while....
>Hab's gerade mal in – Obacht – Python programmiert und auf dem > Mikrocontroller laufen lassen. Könntest du den Python-Code posten? Ich würde es gerne "nacheruieren". Welchen Mikrocontroller hast du verwendet? Da gibt es große Unterschiede in der Geschwindigkeit.
Angehängte Dateien:
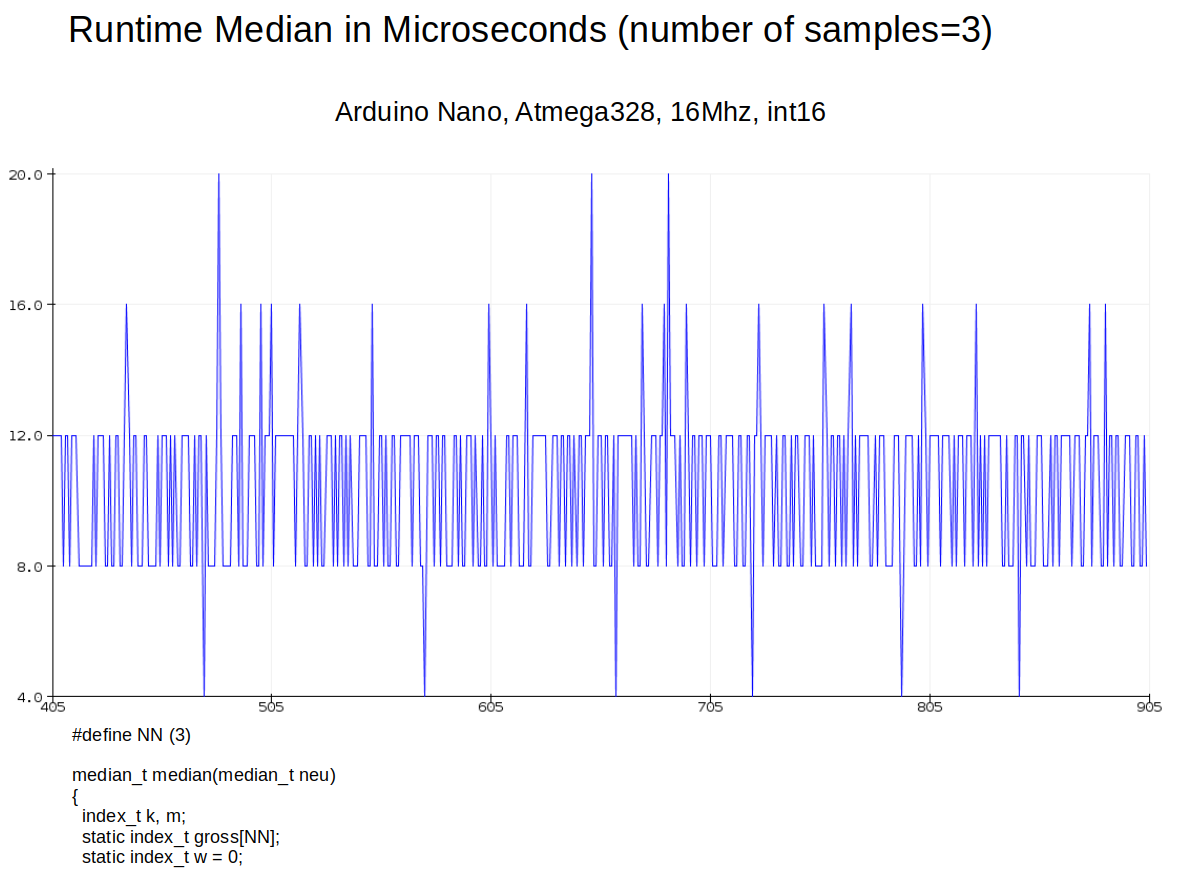
Hier mal die Laufzeit auf dem Atmega328 mit int16-Werten und Indexlänge uint8. Zieht man die Laufzeit der leeren Funktion von oben (~4us) ab, kommt man auf eine durchschnittliche Laufzeit von 6us. Nicht schlecht, würde ich sagen.
1 | typedef int16_t median_t; |
2 | typedef uint8_t index_t; |
3 | |
4 | #define NN (3)
|
5 | |
6 | median_t median(median_t neu) |
7 | {
|
8 | index_t k, m; |
9 | static index_t gross[NN]; |
10 | static index_t w = 0; |
11 | static median_t alt[NN]; |
Christoph M. schrieb: > #define NN (3) Dafür braucht es keine median-Funktion mit sage und schreibe 5 while-Schleifen.
Angehängte Dateien:
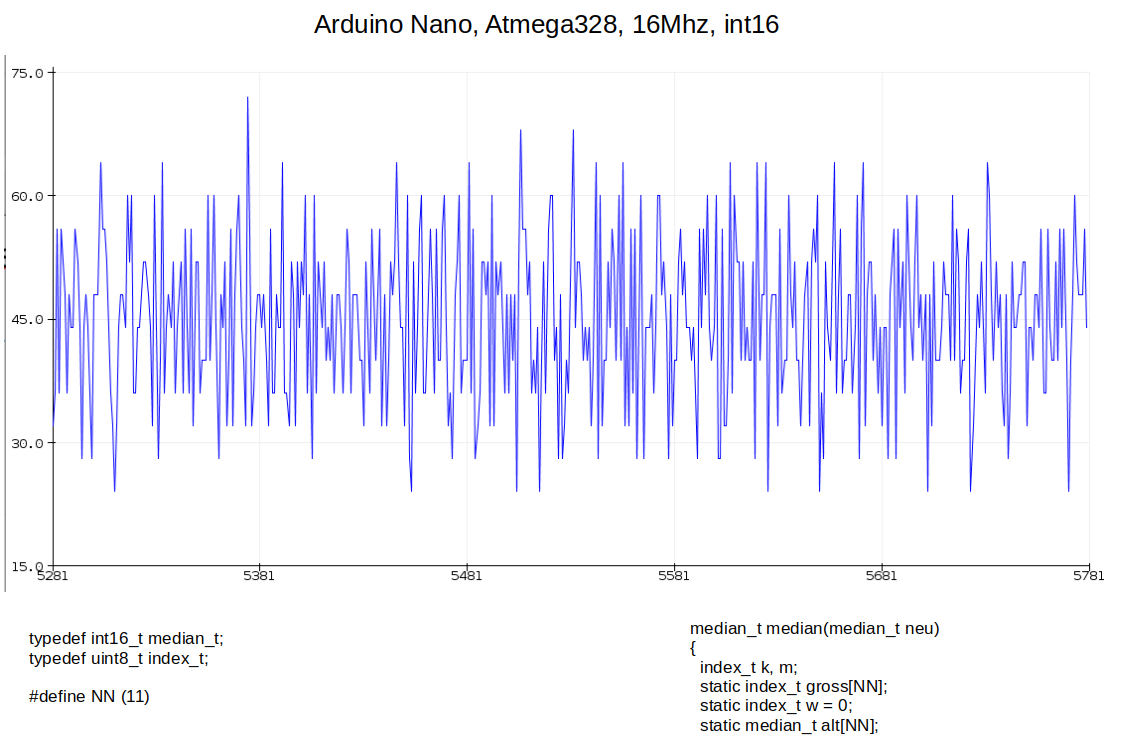
>Dafür braucht es keine median-Funktion mit sage und schreibe 5 >while-Schleifen. Jetzt besser?:
1 | #define NN (11)
|
Christoph M. schrieb: > Jetzt besser?: Genau. Vielleicht kannst Die Laufzeit mal mit einer einfachen straight-forward Implementierung vergleichen? Ich hätte das so implementiert:
1 | int cmpfunc (const void* a, const void* b) { |
2 | return ( *(median_t*)a - *(median_t*)b ); |
3 | }
|
4 | |
5 | median_t median(median_t neu) |
6 | {
|
7 | static int32_t idx = 0; |
8 | static median_t timebased[NN]; |
9 | static median_t sorted[NN]; |
10 | |
11 | timebased[idx++] = neu; |
12 | idx %= NN; |
13 | |
14 | memcpy(sorted, timebased, sizeof(sorted)); |
15 | qsort(sorted, NN, sizeof(median_t), cmpfunc); |
16 | |
17 | return (sorted[(NN - 1) / 2]); |
18 | }
|
Angehängte Dateien:
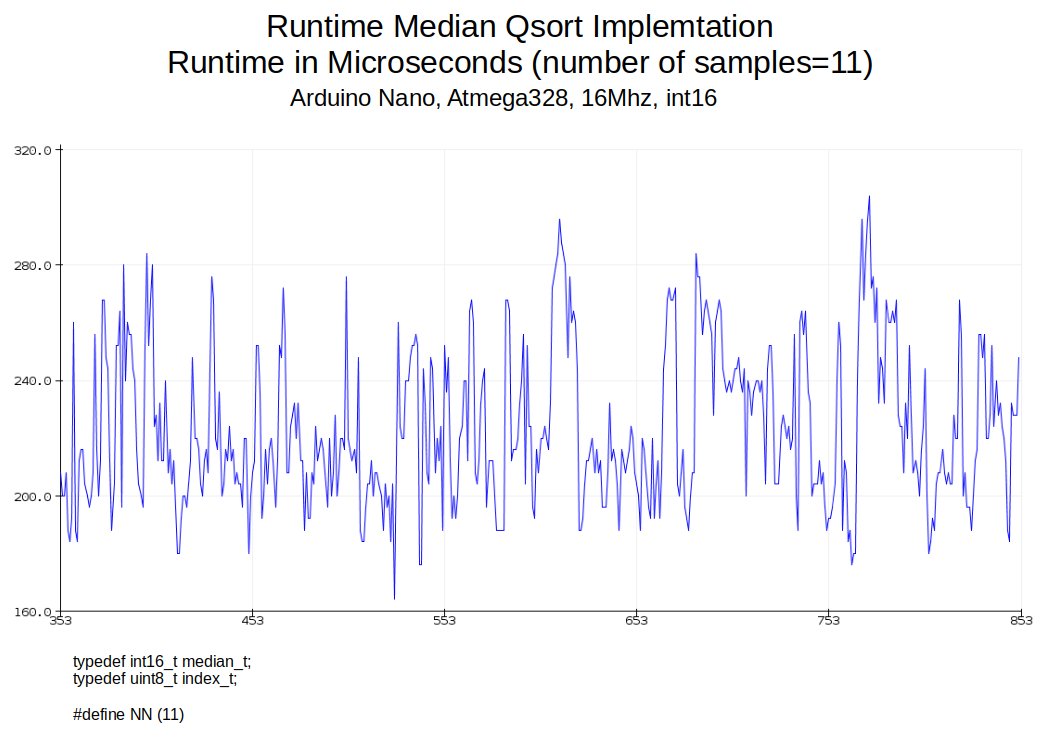
Klaus (feelfree) >Vielleicht kannst Die Laufzeit mal mit einer einfachen straight-forward >Implementierung vergleichen? Deine Implementierung ist auf jeden Fall schön übersichtlich. Ich habe ein wenig gezögert, weil ich vermutete, dass die in der in der Arduino IDE verwendete Compiler keine STD-Lib und damit kein QSort kennt. Aber siehe da, es kompiliert out of the Box. Die Performance ist allerdings nicht so gut wie bei der Detlev'schen Version. Hiermit möchte ich Detlev für seinen Beitrag ausdrücklich loben.
Hallo, vielen Dank. Ich bin noch nicht zufrieden. Dieses Umschaufeln ist nicht cool. In eine sortierte Liste ein Element neu einsortieren geht mit 'linear merge' in O(log log n), mein hochbubbeln ist O(n).Das älteste Element fliegt raus. Ich überlege an einer Datenstruktur die einerseits immer direkten Zugriff auf das älteste Element gibt aber andererseits schnelles Einsortieren des Neuen erlaubt. Wenn der Neue kommt werden alle eins älter, alle Altersangaben eins hochzählen ist aber O(n) . Hm Cheers Detlef
Detlef _. schrieb: > Wenn der Neue > kommt werden alle eins älter, alle Altersangaben eins hochzählen ist > aber O(n) Das Alter durch stures inkrementieren darstellen? Ein neues Element bekommt eine höhere Zahl. der älteste hat dann die kleinste Zahl.
Vielleicht könnte eine "Linked List" helfen, auf die zusätzlich ein Pointer mit dem Alter zeigt. Ich vermute aber, dass bei kurzen Medianfiltern dann eher der Verwaltungsaufwand zu groß ist.
Hätte nicht gedacht, dass qsort() bei kurzen Listen soo schlecht performt.... Hier mal eine Version ohne qsort. Eine binäre Suche nach der einzusortierenden Wert lohnt sich glaube ich bei so kurzen Listen kaum. Bleibt immer noch die unschöne lineare Suche nach dem ältesten Wert.
1 | median_t median3(median_t new_value) |
2 | {
|
3 | static uint8_t initialized = 0; |
4 | static int32_t act_age = 0; |
5 | |
6 | struct listelement |
7 | {
|
8 | median_t value; |
9 | uint8_t age; |
10 | };
|
11 | static struct listelement list[NN]; |
12 | |
13 | uint8_t i; |
14 | uint8_t index_new; |
15 | uint8_t index_to_delete; |
16 | |
17 | if (!initialized) |
18 | {
|
19 | for (i=0; i<NN; i++) |
20 | list[i].age = i; |
21 | initialized = 1; |
22 | }
|
23 | |
24 | for (i=0; i<NN; i++) |
25 | {
|
26 | if (new_value < list[i].value) break; |
27 | }
|
28 | index_new = i; |
29 | |
30 | for (i=0; i<NN; i++) |
31 | {
|
32 | if (list[i].age == act_age) break; |
33 | }
|
34 | index_to_delete = i; |
35 | |
36 | if (index_to_delete < index_new) |
37 | {
|
38 | index_new--; |
39 | // move elements [index_to_delete+1 .. index_new] to the left
|
40 | for (int8_t idx=index_to_delete+1; idx<=index_new; idx++) |
41 | list[idx-1] = list[idx]; |
42 | }
|
43 | else if (index_new < index_to_delete) |
44 | {
|
45 | // move elements [index_new .. index_to_delete-1] to the right
|
46 | for (int8_t idx=index_to_delete-1; idx>=index_new; idx--) |
47 | list[idx+1] = list[idx]; |
48 | }
|
49 | |
50 | list[index_new].value = new_value; |
51 | list[index_new].age = act_age; |
52 | |
53 | act_age++; |
54 | act_age %= NN; |
55 | |
56 | return (list[(NN - 1) / 2].value); |
57 | }
|
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.