Der neue Raspberry Pi Pico 2 Prozessor RP2350 enthält zwei Risc Kerne. Welchen Vorteil haben diese im Vergleich zu normalen CPU?
Martin O. schrieb: > Der neue Raspberry Pi Pico 2 Prozessor RP2350 enthält zwei Risc Kerne. Im Raspberry Pi waren schon immer ARM Kerne verbaut. Und der ARM Prozessor war schon immer RISC (ARM steht für Acorn RISC Machines). Wenn du schon Wikipedia liest zu RISC dann lies gleich noch https://de.wikipedia.org/wiki/Arm-Architektur
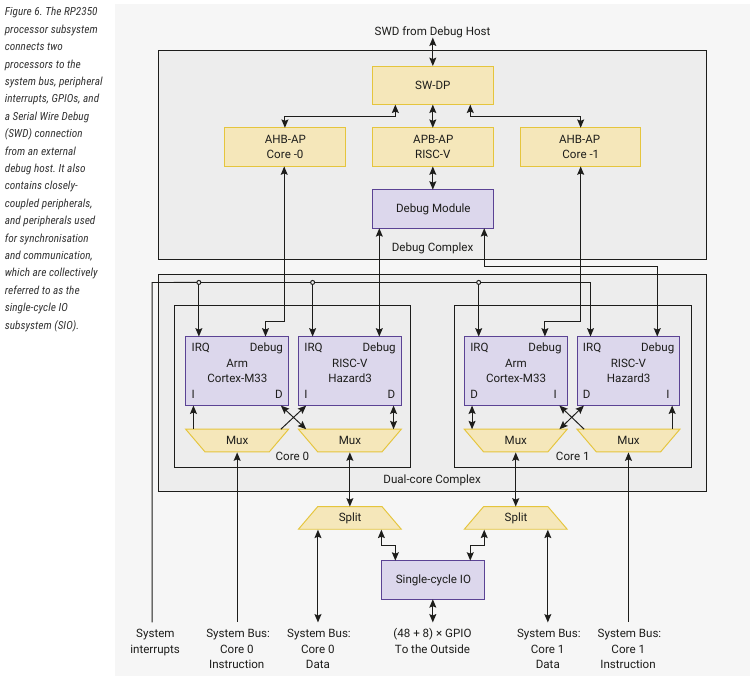
Der TO meinte wohl RISC-V, also... The unique dual-core, dual-architecture capability of RP2350 provides a pair of industry-standard Arm Cortex-M33 cores, and a pair of open-hardware Hazard3 RISC-V cores, selectable in software or by programming the on-chip OTP memory.
Martin O. schrieb: > Welchen Vorteil haben diese im Vergleich zu normalen CPU? Man spart sich die Lizenzkosten für ARM. Risc-V ist eine freie ISA, es unterliegt auch nicht irgendwelchen Exportkontrollen etc. Man findet Risc-V deswegen in immer mehr Geräten. Ein weiterer Vorteil bei Risc-V ISA ist, dass man als CPU Designer auch ohne weiteres eigene Instruktionen definieren kann.
Martin O. schrieb: > zwei Risc Kerne. Du meinst RISC-V. Vermutlich haben die derzeit keine Vorteile. Mittelfristig ist der Vorteil das man bereits damit spielen kann, die verwendetet RISC-V Architektur reifen kann und man einen direkten Vergleich mit den ARM Kernen anstellen kann, bei ansonsten gleicher HW. Geht man davon aus das RISC-V langfristig bei ausreichender Reife ARM erkleckliche Marktanteile abnehmen wird, sind das doch ganz nette Vorteile für so wenig Geld. ARM muss eben Geld verdienen für seine Eigner und tut das mit ausufernden Lizenzkosten.
Der TO meinte wohl RISC-V, also... Genau! Danke für den Hinweis. Bei Reichelt gibts den Pico 2 schon. Mal sehen was man damit anfangen kann.
Martin O. schrieb: > Der TO meinte wohl RISC-V, also... > > Genau! Danke für den Hinweis. Bei Reichelt gibts den Pico 2 schon. Mal > sehen was man damit anfangen kann. Notfalls auch bei Berrybase, Berlin. Erwarte eine harte Lernkurve: Das SDK ist wirklich schlecht, CMake ist eine weitere Herausforderung. Z.Z. funktioniert die PicoDebug (oder PicoProbe) nicht, aber das wird sicher korrigiert. Die einzige "Unterstuetzung" ist eine VSCode-Extension, die allerdings die Abhaengigkeiten nicht mit beruecksichtigt (d.h. Du musst alle Abhaengigkeiten sowohl im C-Code als auch im CMake-File mitziehen). Ich hatte den 2040 mir (wg. der PIO) angeguckt: Das Ding ist von der Hardware interessant, die "Ausgestaltung" des Software-Environment laesst sehr viel zu wuenschen uebrig. Bonne Chance.
An Thomas W. Beziehen sich Deine Aussagen auf den RP2040 Pico 1 oder schon auf den neuen RP2350 Pico 2 ? Ich programmiere den RP2040 ganz gerne, auch die PIOs
Martin O. (ossi-2) >Erwarte eine harte Lernkurve: Das SDK ist wirklich schlecht, Deshalb geht's damit https://github.com/earlephilhower/arduino-pico oder damit https://circuitpython.org/board/adafruit_metro_rp2350/ deutlich einfacher.
Martin O. schrieb: > An Thomas W. > Beziehen sich Deine Aussagen auf den RP2040 Pico 1 oder schon auf den > neuen RP2350 Pico 2 ? Ich programmiere den RP2040 ganz gerne, auch die > PIOs Dann bin ich das Problem: Ich komme mit dem Pico 1 (und Pico W) nicht sehr gut klar. Die Struktur der Doku, die "Anfaenger"-Doku war nicht Thomas-Kompatibel. Kann aber an mir liegen, denn technisch ist das Ding genial (und auch der Preis).
So, ich habe jetzt die ersten Pico-2 Boards. Bei den ersten kleinen Tests ist die Risc-V CPU deutlich langsamer als die ARM CPU. Mit der neuen VisualStudioCode Extension lässt sich, meiner Meinung nach, ganz gut arbeiten.
Martin O. schrieb: > Risc-V CPU deutlich langsamer als die ARM CPU Hm, und das wo ARM Aktienanteile an Raspberry Pi hat. Man könnte denken, das soll die Benutzer von den vorteilen der ARM-Kerne überzeugen. Darf ich fragen, welche rechenoperationen in deien Tests langsamer sind?
Wahrscheinlich kommen die mit einem reinen Risc-V µC, da ist eine Development-Platform nicht verkehrt.
Martin O. (ossi-2) >So, ich habe jetzt die ersten Pico-2 Boards. Bei den ersten kleinen >Tests ist die Risc-V CPU deutlich langsamer als die ARM CPU. Dass die Risc-V deutlich langsamer sind, wundert mich nicht. Sie sind ja nur eingebaut, weil sie kaum Chipfläche benötigen. Die ARM Cortex 33 hingegen sind mit DSP-Erweiterung und allem möglichen Schnickschnack, der entsprechend Chipfläche braucht. ARM hat ja eine Beteiligung bei Raspi, vielleicht hatten sie deshalb nichts dagegen, dass im PiPico auch Risc-V eingebaut sind, die dann entsprechend schlecht aussehen. Es ist ein unfairer Vergleich.
Thomas W. schrieb: > Das SDK ist wirklich schlecht Thomas W. schrieb: > Das Ding ist von der Hardware interessant, die "Ausgestaltung" des > Software-Environment laesst sehr viel zu wuenschen uebrig. Hab ich nicht so gesehen für den ersten Pico. Sicher gibt es etwas zu verbessern, aber ich fand es sogar recht gut gelungen. Für für Einbindung in unterschiedliche IDEs ist etwas mager aber sonst? Und es funktioniert, jedenfalls bei mir. Und ich bin mit der Docu gut klargekommen. War auch Neueinsteiger bei dem Pico. Klar gibt's da auch Dinge die besser sein könnten aber ich kenne deutlich schlimmeres.
900ss schrieb: > Thomas W. schrieb: >> Das SDK ist wirklich schlecht > > Thomas W. schrieb: >> Das Ding ist von der Hardware interessant, die "Ausgestaltung" des >> Software-Environment laesst sehr viel zu wuenschen uebrig. > > Hab ich nicht so gesehen für den ersten Pico. Sicher gibt es etwas zu > verbessern, aber ich fand es sogar recht gut gelungen. OK, dann werde ich es noch einmal versuchen (Try, Fail, try again, I will suceed). Aber warum ich ueberhaupt mit dem Ding angefangen habe war die Existenz des Debuggers (der Pico-Probe/Pico-Debug). Und das funktioniert (auch in der Arduino-Umgebung https://github.com/earlephilhower/arduino-pico) sehr gut. Wer will, auch in der Arduino-IDE 2. Gruesse Th. P.S.: Ich glaub schon, dass ich das Problem war. Deswegen: Noch ein mal.
Thomas W. schrieb: > die Existenz des Debuggers (der Pico-Probe/Pico-Debug Ich habe den nicht probiert. Black Magic Probe funktioniert und am besten der J-Link. Der ist dann auch genutzt worden bis das Projekt fertig war.
Also ich persönlich sehe die RISC-V Kerne als spannende Entwicklung für Leute die sich mit Low-Level Computertechnik beschäftigen wollen. Man hat damit jetzt einen sehr billigen Mikrocontroller mit ziemlich viel RAM, der Leistungsmäßig in der selben Klasse spielt wie "Personal Computer" der 1980er. Sprich die sind noch nicht so groß, dass man dafür ein komplexes Betriebssystem braucht, aber völlig ausreichend um darauf ein System in der Komplexitätsklasse von CP/M oder MS-DOS laufen zu lassen. Darauf könnte man, wie beim Raspberry Pi, auch gleich die Entwicklungsumgebung laufen lassen um ein "self hosting"-System zu haben. Das ist für mich als Hobbyist spannend. Man kann einen eigenen Computer bauen, der zumindest dazu taugt, seine eigene Entwicklung zu unterstützen. Natürlich ginge das auch mit ARM, aber bei ARM ist es schwierig eigene freie Kerne zu haben. Spätestens, wenn das Gerät damit verkauft wird, und sei es nur an Hobbyisten, so muss man Lizenzabgaben zahlen. Da bei einfachen Betriebssystemen häufig eine Abhängigkeit zwischen Befehlssatz und Betriebssystem existiert (manche Teile sind halt zwangsläufig in Assembler geschrieben) kann ich verstehen, dass man sich da nicht ARM ans Bein binden will. Also wie gesagt, ich finde das für Hobbyisten spannend, denke aber, dass für den Rest die praktischen Auswirkungen quasi Null sind.
> Das ist für mich als Hobbyist spannend. Man kann einen eigenen > Computer bauen, der zumindest dazu taugt, seine eigene Entwicklung zu > unterstützen. Nicht das ich sie gezaehlt habe, aber ich habe den Eindruck es gibt inzwischen mehr eigen entwickelte Computer als Probleme die man damit loesen koennte. :) Vanye
Wie ist denn der Stromverbrauch im direkten Vergleich zwischen den ARM und den RISC-V Kernen für den RP2350? Kann man die CPU als Big/Little Design verwenden? Klar, den compilierten Code müsste man doppelt vorhalten und das Umschalten ohne Reset wäre sicher nicht trivial.
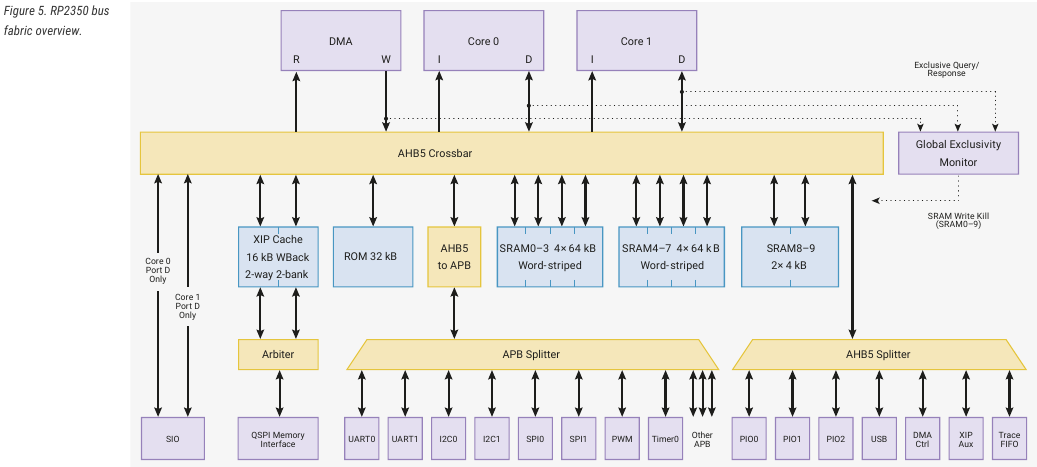
Michael D. (nospam2000) >Wie ist denn der Stromverbrauch im direkten Vergleich zwischen den ARM >und den RISC-V Kernen für den RP2350? Vielleicht brauchen die RISC-V wirklich etwas weniger Strom, weil sie im Vergleich zum Cortex-M33 sehr viel weniger aufwändig sind. Hier gibt es sogar den Verilog-Source Code: https://github.com/wren6991/hazard3 Die Cortex-M33 dagegen sind ziemlich aufgebohrt (RP2350 Datenblatt): Each Arm Cortex-M33 processor in RP2350 is configured with the following features: • FPU: Single precision FPU • DSP: DSP extension • SECEXT: Security extensions • CPIF: coprocessor interface • MPU_NS: 8 non-secure MPU regions • MPU_S: 8 secure MPU regions • SAU: 8 SAU regions ( was wohl die Säue machen? ) The Cortex-M33 features a coprocessor port which transfers up to 64 bits per cycle between the processor and certain closely-coupled hardware.
Martin O. schrieb: > Der neue Raspberry Pi Pico 2 Prozessor RP2350 enthält zwei Risc Kerne. > Welchen Vorteil haben diese im Vergleich zu normalen CPU? Was ist schon normal? Ist diese CPU anormal?
Die Integer Performance versuche ich mit dem angehängten Code zu messen. Für Float und Double nehme ich einen ähnlichen Code nur mit Float bzw. Double Variablen.
Martin O. schrieb: > An Thomas W. > Beziehen sich Deine Aussagen auf den RP2040 Pico 1 oder schon auf den > neuen RP2350 Pico 2 ? Ich programmiere den RP2040 ganz gerne, auch die > PIOs was benutzt du dafür? Mittlerweile scheint auch Keil uVision den über ein pack zu supporten wenn ich das richtig gesehen habe?
Martin O. (ossi-2)
>Die Integer Performance versuche ich mit dem angehängten Code zu messen.
Eine Tabelle mit den Ergebnissen wäre nicht schlecht.
Wobei man bei solchen Vergleichen berücksichtigen muss, daß nur die Kombination verwendeter Compiler/Prozessorkern ermittelt wird. Und es ist ja nicht so, daß alle Compiler gleich sind, geschweige denn, daß sie gleich guten Code abliefern. Aus dem hohlen Bauch heraus würde ich annehmen, daß ein ARM-Compiler erst mal besseren Code liefern dürfte, einfach, weil mit dieser Architektur schon länger gearbeitet wird und daher mehr Gehirnschmalz in Compiler, Optimierer und auch Libraries geflossen sein dürfte.
Martin O. schrieb: > Die Integer Performance versuche ich mit dem angehängten Code zu messen. > Für Float und Double nehme ich einen ähnlichen Code nur mit Float bzw. > Double Variablen. Dieser Testcode sollte bei angeschalteten Compiler Optimierungen unabhängig vom verwendeten CPU Kern gleich schnell ab laufen, in etwas 0 Zeit. Die Eingangsparameter sind dem Compiler nämlich bereits zur Compile-Zeit bekannt, er kann das Ergebniss vorberechnen. (In Deinem Code werden die globalen Variablen von Lokalen überdeckt) Mit welchen Compileroptionen wurde für jeweils ARM & Risc-V übersetzt?
Harald K. (kirnbichler) >daß ein ARM-Compiler erst mal besseren Code liefern dürfte, ARM ist nicht gleich ARM und Risc-V ist nicht gleich Risc-V. Der verwendete ARM Cortex M33 im RP2350 ist eine ganz anderer Prozessor als der im RP2040 verwendete M0+. Aber das ist hier wohl nur schwer vermittelbar. Nichtsdestotrotz ist es interessant die Geschwindigkeit des selben Compilats auf einem RP2040 und RP2350 zu vergleichen. Insbesondere wenn komplexzahlige 16 Bit Faltungsoperationen verwendet werden.
Christoph M. schrieb: > ARM ist nicht gleich ARM und Risc-V ist nicht gleich Risc-V. Ach was. Hab' ich irgendwas gegenteiliges behauptet? > Der verwendete ARM Cortex M33 im RP2350 ist eine ganz anderer > Prozessor als der im RP2040 verwendete M0+. Auch das habe ich noch nicht mal mit einem Satzzeichen irgendwo in Frage gestellt. > Aber das ist hier wohl nur schwer vermittelbar. Ich gehe stark davon aus, daß Martin sein Testprogramm auf den im RP2350 verbauten Kernen betreiben will, nicht, daß er die Performance von RP2040 mit der des RP2350 vergleichen möchte. Ja, das ist dann ein Vergleich des M33 (so, wie er im RP2350 vorhanden ist) mit einem Hazard 3. (wohl der hier: https://github.com/Wren6991/Hazard3) Daß die in unterschiedlichen Ligen spielen, ist stark anzunehmen, allein, das macht einen Vergleich dennoch nicht sinnlos, denn beide sind nun mal im RP2350 verbaut. Vielleicht hast Du von Deiner hohen "vermittelbarkeits"-Kanzel herab gar nicht so recht verstanden, worum es geht?
Jens B. schrieb: > Ist diese CPU anormal? Die einzelne CPU nicht, der Chip als Ganzes ist wirklich abartig. Man hat wohl die beiden M33 und die Peripherie sauber auf dem Silizium angeordnet und dann sind ein paar µm² frei geblieben. Dann konnte man sich nicht auf ein Motiv für eine Grafik oder einen blöden Spruch einigen... Zum Ausgleich hat man an allen anderen Stellen gespart. Kein zuverlässiges BOR, kein brauchbarer interner Oszillator (der ROSC ist nicht wirklich trimmbar), keine USB-Serienwiderstände, der ADC ist so peinlich, dass man ihm genau 4 Zeilen im Datenblatt spendiert... :( Immerhin gibt es ein ganz normales Datenblatt, fast schon vorbildlich. Christoph M. schrieb: > SAU: 8 SAU regions ( was wohl die Säue machen? )
1 | An internal processor peripheral called the Security Attribution Unit |
2 | (SAU) defines, from the processor’s point of view, which address ranges |
3 | are accessible to the Secure and Non-secure domains. The number of |
4 | distinct address ranges which can be decoded by the SAU is limited, |
5 | which is why system-level bus filters are provided for assigning |
6 | peripherals to security domains. |
Auf jeden Fall ist es ein überaus interessanter Chip. Das beste Feature ist die integrierte Selbstzerstörung: max. Core Spannung = 1.21V, Spannungsregler programmierbar bis 3.3V :) :)
Ich habe bis gestern die relativ "alte" VisualStudioCode Variante benutzt. Gestern hab ich die ersten Pico-2 Boards bekommen. Dafür habe ich die neue VisualStudioCode Extension installiert und benutze diese nun. Da kann man die CPU Version wählen und ob man die Risc-V CPUs benutzen will.
Bauform B. (bauformb) >Auf jeden Fall ist es ein überaus interessanter Chip. Das beste Feature >ist die integrierte Selbstzerstörung: max. Core Spannung = 1.21V, >Spannungsregler programmierbar bis 3.3V :) Endlich wieder mal ein Gerät mit "Killer Poke" :-) Kann mal jemand ausprobieren, ob das funktioniert? Vielleicht reicht die Leistung der Spannungsregler nicht aus.
Christoph M. schrieb: > Der verwendete ARM Cortex M33 im RP2350 ist eine ganz anderer Prozessor > als der im RP2040 verwendete M0+. Falls Du es noch nicht mitbekommen hast: Im RP2350 sind sowohl ARM- als auch RISC-V-Kerne verbaut, die wechselseitig aktiviert werden können. Es geht um einen Benchmark ARM vs. RISC-V auf dem RP2350. Mit dem RP2040 hat das überhaupt nichts zu tun.
> Falls Du es noch nicht mitbekommen hast: Im RP2350 sind sowohl ARM- als > auch RISC-V-Kerne verbaut, die wechselseitig aktiviert werden können. Ist die DSP-Extension auch von dem RISC-V-Kern nutzbar oder sollte man bei Faltungsoperationen wie bei ML heftig benötigt doch auf den ARM-Core samt extension setzen ?
Die Laufzeiten sind für Pico1,Pico2,RiscV und jeweils Int,Float,Double in der angehängten Tabelle.
Angehängte Dateien:
-

rp235x.png
52 KB -

core0_core1.png
79 KB
Bradward B. schrieb: > Ist die DSP-Extension auch von dem RISC-V-Kern nutzbar Unwahrscheinlich. Der hängt doch am Coprozessor Interface der M33-CPU oder ist sogar noch enger gekoppelt.
OK nach den gemessenen Laufzeiten ist IMHO deutlich, das Fliesskomma im ARM -M3 drastisch beschleunigt ist.
Der Unterschied in der int-Variante ist zwischen M33 und Hazard3 aber gar nicht so groß. Hier wäre ein zusätzlicher Test (dhrystone?) interessant. Daß man die Float-Performance nicht vergleichen sollte, ist klar, der M33 hat eine FPU, der Hazard3 nicht. Aber wie sieht z.B. die Performance von memmove aus, wie schnell sind übliche Schleifenkonstrukte etc., wie sehen die IRQ-Latenzen aus ...
Harald K. schrieb: > Der Unterschied in der int-Variante ist zwischen M33 und Hazard3 aber > gar nicht so groß. Um ein Drittel (17 zu 26) schneller ist aber deutlich, bei bis zu 10% Unterschied könnte man noch über "nicht spürbar" sprechen. > Hier wäre ein zusätzlicher Test (dhrystone?) interessant. Test werden leider nur verwendet um Raum für Interpretation zu schaffen. Wobei eigentlich nur eine Messung gelungen ist, die keinen "Raum für Interpretationen" bietet.
Bradward B. schrieb: > OK nach den gemessenen Laufzeiten ist IMHO deutlich, das > Fliesskomma im ARM -M3 drastisch beschleunigt ist. Vor allem sieht man, daß beide ARM CPU eine FPU haben, die RISC-V CPU jedoch nicht. Das macht einen Vergleich eher sinnlos. Äpfel sind nun mal keine Birnen. Man sieht auch daß die ARM FPU anscheinend nativ in double rechnet und daß die Umwandlung double → float in Software gemacht wird. Deswegen braucht auf ARM float sogar länger als double. Bei der Emulation in der RISC-V CPU dauert hingegen double länger als float, wie man es auch erwarten würde.
> Vor allem sieht man, daß beide ARM CPU eine FPU haben, ??? Das seher ich eher nicht, auch lt. Doku ist für ARM-M0 keine FPU-Extension möglich. > Das macht einen Vergleich eher sinnlos. Äpfel sind nun mal > keine Birnen. Doch ein Vergleich der Nicht-float-Eigenschaften ist schon sinnvoll, erst recht wenn nicht vorhandene float-Hardware durch integer rechnung emuliert werden muß. Und egal, ob man jemanden einen Apfel oder eine Birne an die Rübe knallt, der Effekt beim Getroffenen ist nicht nur vergleichbar, er ist auch nahezu gleich.
Bradward B. schrieb: > Um ein Drittel (17 zu 26) schneller ist aber deutlich, bei bis zu 10% > Unterschied könnte man noch über "nicht spürbar" sprechen. Das Ergebnis nur eines Tests hat wenig Aussagekraft, daher eben mein Vorschlag, ausführlichere Tests zu veranstalten. Bei Desktop-PCs sind übrigens Geschwindigkeitsunterschiede unter 50% mess-, aber kaum spürbar.
> Das Ergebnis nur eines Tests hat wenig Aussagekraft, daher eben mein > Vorschlag, ausführlichere Tests zu veranstalten. alle speedtests sind halt synthetisch, eine "echte" Applikation wäre da entscheidender, beispielsweise ob die Bremsen in einem Autonomen Fahrzeug 100 ms früher oder später mittels prognostischer Erkennung eine potentiell gefährlichen Situation einsetzen. > Bei Desktop-PCs sind übrigens Geschwindigkeitsunterschiede unter 50% > mess-, aber kaum spürbar. Naja, ein Desktop-PC läuft ja auch im GHz Bereich, wären die Picos (default) bei 125 MHz liegt. Je langsamer die Geschwindigkeitsklasse, desto stärker fallen auch Unterschiede im einstelligen Prozentbereich auf. und dann wäre noch die Frage nach der Laufzeit. Ob nun ein umfangreicher built 20 oder 22 Minuten dauert ist schon relevant, ob es 20 oder 22 Sekunden sind - eher nicht.
Bradward B. schrieb: > und dann wäre noch die Frage nach der Laufzeit. Ob nun ein umfangreicher > built 20 oder 22 Minuten dauert ist schon relevant, ob es 20 oder 22 > Sekunden sind - eher nicht. Nein. Ob der Buil_D_ zehn Prozent länger braucht oder nicht, ist genauso relevant, wie ob der Build zehn Prozent länger braucht oder nicht. Es sind nur zehn Prozent Unterschied.
Martin O. schrieb: > Die Laufzeiten sind für Pico1,Pico2,RiscV und jeweils Int,Float,Double > in der angehängten Tabelle. Ich finde es erstaunlich, dass der RiscV bei float und insbesondere double soviel langsamer ist als der Pico1. Die haben ja beide keine FPU. Vielleicht fehlen da ja optimierte Libs und das ist der Grund, warum man die RiscV-Kerne überhaupt eingebaut hat.
Markus K. schrieb: > Ich finde es erstaunlich, dass der RiscV bei float und insbesondere > double soviel langsamer ist als der Pico1. Könnte vielleicht am "integer divider" und "interpolator" liegen, die es im RP2040 gibt. Jemand, der sich besser in RISC-V eingelesen hat als ich, wird sicherlich mit der Beschreibung des Hazard3 auf https://github.com/Wren6991/Hazard3 herausfinden können, ob es da Äquivalente zu diesen Funktionen gibt.
Ich habe das angehängte Programmm mit dem ARM und dem RiscV laufen lassen. Die Stromaufnahme ist bei beiden ziemlich genau 18mA. Also kein deutlicher Unterschied zwischen beiden CPUs.
Martin O. (ossi-2) 28.08.2024 12:30 >Die Laufzeiten sind für Pico1,Pico2,RiscV und jeweils Int,Float,Double >in der angehängten Tabelle. Super, danke :-) Ich zieh's mal aus dem Text in die Sichtbarkeit:
1 | Für die Integer Version habe ich die folgenden Laufzeiten in us: |
2 | Pico 1 49 |
3 | Pico 2 17 |
4 | RiscV 26 |
5 | |
6 | Für die Float Version habe ich die folgenden Laufzeiten |
7 | Pico 1 1190 |
8 | Pico 2 264 |
9 | RiscV 3864 |
10 | |
11 | Für die Double Version habe ich die folgenden Laufzeiten |
12 | Pico 1 1146 |
13 | Pico 2 203 |
14 | RiscV 6132 |
15 | |
16 | Bei allen Varianten sieht man dass der Pico2 deutlich vorne liegt. |
Bradward B. schrieb: >> Vor allem sieht man, daß beide ARM CPU eine FPU haben, > > ??? Das seher ich eher nicht, auch lt. Doku ist für ARM-M0 keine > FPU-Extension möglich. Wieso bringst Du jetzt ARM-M0 ins Spiel? Wie bereits festgestellt, sind wird hier bei ARM Cortex M33. Dass diese eine FPU haben, ist unbestritten.
Es wäre mal interessant, die SIMD-Instructions für einen Filterbenchmark zu nutzen, wie hier: https://mcuoneclipse.com/2019/11/19/investigating-arm-cortex-m33-core-with-trustzone-dsp-acceleration-1/
Harald K. schrieb: > Markus K. schrieb: >> Ich finde es erstaunlich, dass der RiscV bei float und insbesondere >> double soviel langsamer ist als der Pico1. > > Könnte vielleicht am "integer divider" und "interpolator" liegen, die es > im RP2040 gibt. Jemand, der sich besser in RISC-V eingelesen hat als > ich, wird sicherlich mit der Beschreibung des Hazard3 auf > https://github.com/Wren6991/Hazard3 herausfinden können, ob es da > Äquivalente zu diesen Funktionen gibt. Ich steck da auch nicht drin, aber auf der Seite steht zumindest, dass er den RV32I Befehlssatz implementiert u.a. mit der Erweiterung M: "integer multiply/divide/modulo". Das hört sich ja schonmal nicht schlecht an.
Frank M. schrieb: > Bradward B. schrieb: >>> Vor allem sieht man, daß beide ARM CPU eine FPU haben, >> >> ??? Das seher ich eher nicht, auch lt. Doku ist für ARM-M0 keine >> FPU-Extension möglich. > > Wieso bringst Du jetzt ARM-M0 ins Spiel? Wie bereits festgestellt, sind > wird hier bei ARM Cortex M33. Dass diese eine FPU haben, ist > unbestritten. Der Pico1 hat benutzt Cortex-M0+ und der Pico2 den Cortex-M33.
Dass der RiscV bei double Operationen so langsam ist könnte natürlich auch an einer schlechten double-Bibliothek liegen. Es wäre mal interessant die Pico-2 RiscV CPU mit anderen RiscV CPUs zu vergleichen.
Und, hat der 'ne FPU? Soweit ich weiss hat der RP2040 (Pico 1) keine FPU. Das erklärt warum der RP2350 bei float und double deutlich schneller ist. Mal sehen ob ich ne FFT auf den CPUs vergleiche.
Markus K. schrieb: > Die haben ja beide keine FPU. > Vielleicht fehlen da ja optimierte Libs und das ist der Grund, warum man > die RiscV-Kerne überhaupt eingebaut hat. Der Pico 1 hat einen (8 Takte) Hardware Integer Divider den man parallel zur CPU laufen lassen kann, die Hazard Risc V können zwar auch Integer Divide, allerdings nicht parallel und das auch nur langsamer (18/19 Takte) Lt. der Hazard3 Webseite erreicht der 3.74 CoreMark/MHz und sollte damit in echten Applikationen deutlich schneller sein als ein Cortex M0+ mit seinen typischerweise 2.42 CoreMark/MHz. Die ganzen präsentierten Benchmarkergebnisse sind sowieso nur Schall und Rauch ohne die Angabe von Compiler, Version und den benutzen Compile-Flags. (Und Taktfrequenz)
Andreas M. schrieb: > Markus K. schrieb: >> Die haben ja beide keine FPU. >> Vielleicht fehlen da ja optimierte Libs und das ist der Grund, warum man >> die RiscV-Kerne überhaupt eingebaut hat. > > Der Pico 1 hat einen (8 Takte) Hardware Integer Divider den man parallel > zur CPU laufen lassen kann, die Hazard Risc V können zwar auch Integer > Divide, allerdings nicht parallel und das auch nur langsamer (18/19 > Takte) Danke für die konkreten Zahlen. > Lt. der Hazard3 Webseite erreicht der 3.74 CoreMark/MHz und sollte damit > in echten Applikationen deutlich schneller sein als ein Cortex M0+ mit > seinen typischerweise 2.42 CoreMark/MHz. Der Cortex-M33 macht 4,1 CoreMark/MHz und ist demnach nur knapp 10% schneller als der Harzard3. Bei dem, was so ein Benchmark halt misst. > Die ganzen präsentierten Benchmarkergebnisse sind sowieso nur Schall und > Rauch ohne die Angabe von Compiler, Version und den benutzen > Compile-Flags. (Und Taktfrequenz) Stimmt. Ist mir auch gerade aufgefallen, als ich mir den Compileroutput anschauen wollte. Es gibt ja diese Seite https://godbolt.org/ , bei der man Code einkippen kann und dann aus dutzenden Compilerversionen auswählen kann und dann schön vergleichen kann, was der Compiler daraus macht. Dazu muss man aber eben die genaue Version und auch die Flags kennen.
Angehängte Dateien:
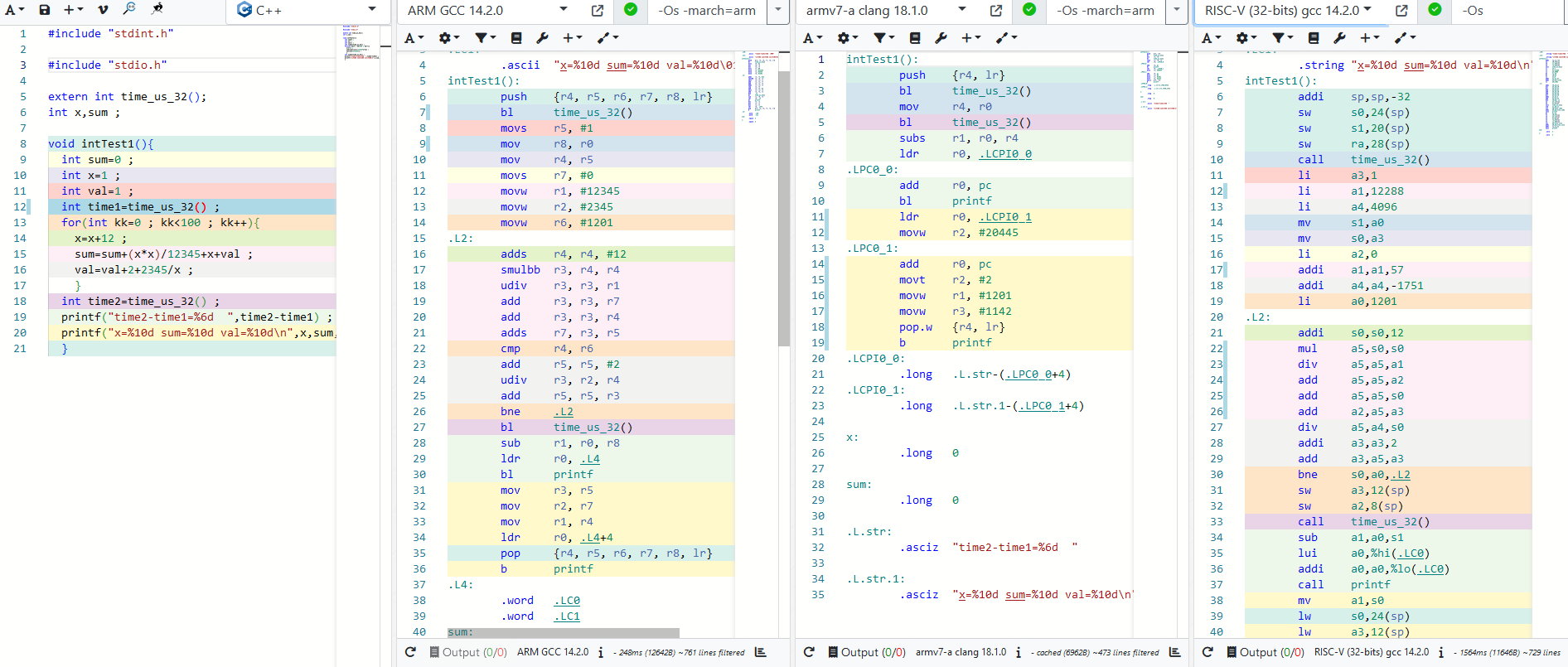
Markus K. schrieb: > Es gibt ja diese Seite https://godbolt.org/ Stimmt, da war etwas. Ich bin jetzt etwas erstaunt, wie schlecht der gcc inzwischen doch ist, ich hätte erwartet, das er das mit der Constant-Value Optimierung kann, tut er aber nicht. der clang machts
Die M3 FPU hilft doch nur bei float, nicht bei double. Double können einige M7 FPU. Da passt es nicht das double auf dem Pico2 schneller sein sollen als float. Wird die FPU wirklich genutzt?
DSP-SIMD im PiPico 2 wäre interessant. Das sollte deutlich schneller als auf dem PiPico 1 laufen. In etwas so was
1 | #include <arm_math.h> // Include CMSIS DSP header for intrinsics |
2 | // Perform the IQ demodulation
|
3 | for (int i = 0; i < length; i += 2) { |
4 | // Pack two 16-bit I and Q samples into 32-bit registers
|
5 | int32_t i_pair = __PKHBT(I[i], I[i + 1], 16); |
6 | int32_t q_pair = __PKHBT(Q[i], Q[i + 1], 16); |
7 | |
8 | // Calculate I^2 and Q^2 using SIMD multiplication (SMUAD)
|
9 | int32_t i_squared = __SMUAD(i_pair, i_pair); |
10 | int32_t q_squared = __SMUAD(q_pair, q_pair); |
11 | |
12 | // Calculate the demodulated values
|
13 | int32_t result_pair = __QADD16(i_squared, q_squared); |
14 | |
15 | // Store the results back to memory
|
16 | demodulated[i] = (int16_t)(result_pair & 0xFFFF); // Lower 16-bit |
17 | demodulated[i + 1] = (int16_t)((result_pair >> 16) & 0xFFFF); // Upper 16-bit |
18 | }
|
__SMUAD: https://developer.arm.com/documentation/dui0472/m/ARMv6-SIMD-Instruction-Intrinsics/--smuad-intrinsic __PKHBT https://developer.arm.com/documentation/dui0489/i/arm-and-thumb-instructions/pkhbt-and-pkhtb
Das float Testprogramm arbeitet auch mit Double durch die Konstanten 1.0 und 1.234. Die müssen als 1.0f und 1.234f geschrieben werden. Der Klassiker wenn man AVR Code für ARM kopiert.
J. S. schrieb: > Die M3 FPU hilft doch nur bei float, nicht bei double. Double > können einige M7 FPU. Ja, der M33 (die M3 haben ja nicht einmal float). Aber der RP2350 hat noch ein paar tausend Gatter zusätzlich. Die Frage ist nur, wie benutzt man die? Kennt der GCC solche Erweiterungen?
1 | 3.6.2. Double-precision Coprocessor (DCP) |
2 | Each Cortex-M33 CPU core is equipped with two instances of a |
3 | double-precision coprocessor that provides acceleration of |
4 | double-precision floating point operations including add, subtract, |
5 | multiply, divide and square root. The design is implemented in just |
6 | a few thousand gates and so occupies much less silicon die area than |
7 | a full double-precision floating-point unit. Nevertheless, these |
8 | coprocessors considerably speed up basic double-precision operations |
9 | compared to pure software implementations. The coprocessors also |
10 | offer support for some single-precision operations and conversions. |
11 | |
12 | The two coprocessor instances are assigned to the Secure and Non-secure |
13 | domains. [...] This duplication avoids saving and restoring the |
14 | coprocessor context during Secure/Non-secure state transitions. |
15 | |
16 | The RISC-V processors on RP2350 do not have access to the Cortex-M33 |
17 | coprocessors. |
Ok, das macht den sicher interessant für einige Rechnereien. Und das langsamere float beim Test dürfte dann an den zusätzlichen Konvertierungen liegen.
Hier ein paar neue Zahlen. Für eine 4096 Punkte Double FFT braucht der Pico2 52ms, der RiscV 1237ms und der Pico1 348ms.
Danke an jojos. Ich habe die float Programme nochmal neu laufen lassen wobei die Konstanten in xx.xxf Weise geschrieben wurden. Neue Laufzeiten: Pico2 32us(vorher 264us). Pico1: 49us (vorher 1190us) und RiscV 2167us (vorher 61342us). Wieder ist die RiscV Version ziemlich langsam.
Ich find's Klasse dass ihr Benchmarks macht, aber das ganze IO Subsystem scheint bei dem Ding kaputt zu sein. Werde zwar noch ein bisschen testen, aber befürchte das sie eine überarbeitete zweite Version auflegen müssen.
>das ganze IO Subsystem >scheint bei dem Ding kaputt zu sein. Werde zwar noch ein bisschen >testen, aber befürchte das sie eine überarbeitete zweite Version >auflegen müssen. Des scheint einen Bug zu geben:
1 | The newly released RP2350 microcontroller has a confirmed new bug in the current A2 stepping, affecting GPIO pull-down behavior. Listed in the Raspberry Pi RP2350 datasheet as errata RP2350-E9, it involves a situation where a GPIO pin is configured as a pull-down with input buffer enabled. After this pin is then driven to Vdd (e.g. 3.3V) and then disconnected, it will stay at around 2.1 – 2.2 V for a Vdd of 3.3V |
https://hackaday.com/2024/08/28/hardware-bug-in-raspberry-pis-rp2350-causes-faulty-pull-down-behavior/
>>das ganze IO Subsystem >>scheint bei dem Ding kaputt zu sein. > Des scheint einen Bug zu geben: > >
1 | > The newly released RP2350 microcontroller has a confirmed new bug in the |
2 | > current A2 stepping, affecting GPIO pull-down behavior. Listed in the |
3 | > Raspberry Pi RP2350 datasheet as errata RP2350-E9, it involves a |
4 | > situation where a GPIO pin is configured as a pull-down with input |
5 | > buffer enabled. After this pin is then driven to Vdd (e.g. 3.3V) and |
6 | > then disconnected, it will stay at around 2.1 – 2.2 V for a Vdd of 3.3V |
7 | > |
Also diese Beschreibung eines suboptimalen Pull-Down bei "unorthodoxen IO-Einstellungen" kann man jetzt nicht wirklich als ' Ganz kaputtes IO Subsystem ' bezeichnen. Wer dergleichen tut, dessem Charakter muß man schon einen besonderen Hang zur (Maßlosen) Übertreibung attestieren. Gleichzeitig Pull-Down und direction Input ist schon mal eine leicht widersprüchliche (und somit eher "seltene") Configuration, Tristate-Output mit Pulls wäre da schon eher nach Lehrbuch. Es ist aber tatsächlich ein Fehler wenn man dann von außen an den anschliessend von High auf hochohmig geschalteten (Input-) pin statt dem Pull-Dwn-Level (Low also GND) eine Spannung um 2 Volt, also verbotener Bereich misst.
Die oben gemachte Angabe der Float Laufzeit (49us) ist falsch. Richtig ist 658us. Ich hoffe ich habe jeetzt alle Fehler beseitigt.
Bradward B. schrieb: > Gleichzeitig Pull-Down und direction Input ist schon mal eine leicht > widersprüchliche (und somit eher "seltene") Configuration ??? wie meinen ??? Wie selten ist denn vergleichsweise "Pull-Up und Input"? Selten ist eher, dass an dem Fehler ein "Input Isolation Latch" beteiligt ist, das korrekt programmiert werden muss. Das wird eine FAQ :) > Ganz kaputtes IO Subsystem ist sicher übertrieben, immerhin gibt es einen Workaround:
1 | When pull-down behaviour is required, clear the pad input enable in |
2 | GPIO0.IE (for GPIOs 0 through 47) to ensure that only the pull-down |
3 | resistor is enabled. |
4 | |
5 | To read the state of a pulled-down GPIO from software, enable the |
6 | input buffer by setting GPIO0.IE immediately before reading, and then |
7 | re-disable immediately afterwards. Note that if the pad is already a |
8 | logic-0, re-enabling the input does not disturb the pull-down state. |
Norbert schrieb: > Werde zwar noch ein bisschen testen, aber befürchte das sie eine > überarbeitete zweite Version auflegen müssen. :) Nur eine zweite? Wobei dieser Pull-Down Fehler ja total harmlos ist, reproduzierbar, rein analog. Spannend werden die Timing Probleme und Race Conditions, der Chip hat ja reichlich exotische Hardware. Das wird viele Workaround-Empfehlungen geben, so in der Art "dann mach das halt nicht" ;)
> ist sicher übertrieben, immerhin gibt es einen Workaround:
GEfühlt 90% der Schreiber in diesem Forum lesen keine Datenblaetter,
wieviel Prozent lesen dann wohl Erratas? :-D
Vanye
Harald K. schrieb: > Vanye R. schrieb: >> Erratas > > Was ist der Plural eines Plurals? Ein Pluralissimo. War das ne Fangfrage?
Axel S. schrieb: > War das ne Fangfrage? Wenn der zitateverstümmelnde "vanye" Erratas schreibt, müsste er auch Datenblätters schreiben. Und Schreibers oder Schreiberse. Denn so ein Plural muss ja konsequent pluralisiert werden. Sonst ist es ja nicht genügend viele. Ja, ist mir völlig klar, ist OT.
Harald K. schrieb: > Denn so ein Plural muss ja konsequent pluralisiert werden. Sonst ist es > ja nicht genügend viele. Politisch vollkommen korrekt wäre: "Denn so ein Plural /eine Pluralin müssen ja konsequent pluralisiert werden. Sonst ist es ja nicht genügend gender-gerecht." Bei einer Genderisierung von "Schreibers" muss ich allerdings passen...
Euer langweiliges Leben möchte ich auch mal haben. Vom Blockwart gleich in die Fruehrente gerutscht? Vanye
Ich antworte mal all denjenigen, welche etwas Substantielles zum Thema schrieben. RP2350-E9 ist weit weniger deskriptiv als es sein sollte. Man könnte meinen das man um die Probleme herumprogrammieren könnte. Das sehe ich zur Zeit nicht, denn: Das Latch-Up scheint unabhängig von Pull-Down oder Pull-Up Einmal oben bleibt's oben, zumindest wenn man meinem ersten Test nach etwas hochohmiger heran geht. Möglicherweise ›schnappt‹ das Ding zurück wenn man sehr niederohmig auf Vcc oder Masse legt. Ansonsten konnte ich die korrekte Funktionsweise bisher nur durch einen Reset des gesammten IO-Subsystems wieder herstellen. (Kurzfristig, bis zum nächsten High) Sollte sich das alles bestätigen und die andere Peripherie (PIO,I2C,…) ebenso betroffen sein, dann kann man das Ding nur zum Rechnen aber nicht zu Steuern benutzen.
Norbert schrieb: > Das Latch-Up scheint unabhängig von Pull-Down oder Pull-Up > Einmal oben bleibt's oben, zumindest wenn man meinem ersten Test nach > etwas hochohmiger heran geht. Ist das vielleicht nur der normale Effekt mit einem offenen Eingang? Also ohne Pull-Down, weder intern noch extern, also wirklich hochohmig, ist das doch normal? Ich verstehe den E9 Workaround so, dass der Input Buffer nach einem Power On Reset aus ist und dass man ihn wirklich nur ganz kurz zum Lesen einschalten soll. Normalerweise initialisiert man ja alle Pin-Register gleich beim Start. Das darf man in diesem Fall nicht, GPIO0.IE muss aus bleiben. > Sollte sich das alles bestätigen und die andere Peripherie (PIO,I2C,…) > ebenso betroffen sein das betrifft sicher alle (bis auf QSPI und SWD); es passiert ja "ganz außen", direkt am Pin. Die Multiplexer zum I2C usw. sind ja dahinter, weiter "innen".
Bauform B. schrieb: > Ist das vielleicht nur der normale Effekt mit einem offenen Eingang? > Also ohne Pull-Down, weder intern noch extern, also wirklich hochohmig, > ist das doch normal? Gutes Argument, muss ich wenn ich wieder im Lab bin noch testen. Allerdings verhält sich der 2040 eindeutig anders als der 2350. Die Tatsache, das man mit Pull-Down eine 0 liest, innerhalb von wenigen Mikrosekunden den Pull-Down wegnimmt und immer noch 0 liest, mit Pull-Up eine 1 liest, dann ohne Pull-Up weiterhin eine 1 liest, sieht erst einmal gut aus. Problem: Von da an kann man tun und lassen was man will,die obige Sequenz beliebig oft wiederholen, es bleibt bei einer 1. Reset des IO-Subsystems erlöst das Ding dann von seinem Elend. > Ich verstehe den E9 Workaround so, dass der Input Buffer nach einem > Power On Reset aus ist und dass man ihn wirklich nur ganz kurz zum Lesen > einschalten soll. Normalerweise initialisiert man ja alle Pin-Register > gleich beim Start. Das darf man in diesem Fall nicht, GPIO0.IE muss aus > bleiben. Muss ich noch testen, aber wie soll das zufriedenstellend mit einem PIO_ASM-Programm gehen? Das sehe ich noch gar nicht.
>> Gleichzeitig Pull-Down und direction Input ist schon mal eine leicht >> widersprüchliche (und somit eher "seltene") Configuration > > ??? wie meinen ??? Wie selten ist denn vergleichsweise "Pull-Up und > Input"? Es ist gemeint, das Pull auf eine Pin "schreibende" Funktion hat, während man ein Pin auf Input (-only) konfiguriert, wenn man davon lesen will. Also im gewissen Sinne gleichzeitig schreibend und lesend was irgendwie widersinnig ist. Ein Pull gehört eher an einen (tristate-fähigen) output, damit auch im Falle einer Output-Abschaltung ("hochohmnig) die Leitung nicht floated sondern einen definierten Pegel aufweist. Bei I²C ist der Pull extern mittig. > Latch-Up Nein, da ist kein Latch-Up Effekt, jedenfalls nicht wie er üblicherweise gelehrt wird. https://de.wikipedia.org/wiki/Latch-up-Effekt
Bradward B. (Firma: Starfleet) (ltjg_boimler)
29.08.2024 12:02
>Ein Pull gehört eher an einen (tristate-fähigen) output,
Das siehst du falsch. Es war ein Pull-Up bzw. Pull-down Widerstand
gemeint und die macht man üblicherweise an einen Eingang.
> gemeint und die macht man üblicherweise an einen Eingang.
(ungetriebene) Konfig/Bootstrap-signale ja.
Ansonsten macht man die Pulls extern (intern nur wenn man extern im
schematic vergessen hat) und halt so, das man keine mehrere Pulls
parallel an der selben Leitung hat. Und bei I2C mit einem Master und
mehreren Slaves ist das eher der Master-Output und nicht die bis zu 127
Slave-Eingänge.
> Reset des IO-Subsystems erlöst das Ding dann von seinem Elend.
Das zeigt aber das es kein LatchUp ist sondern irgendwas im
Bereich der Logic. Wobei interessant waere zu schauen ob
sich beim eintreten der Stromverbrauch signifikant erhoeht
weil da z.B zwei Ausgaenge (im Controller) gegeneinander
arbeiten.
Vanye
>> Reset des IO-Subsystems erlöst das Ding dann von seinem Elend. > > Das zeigt aber das es kein LatchUp ist sondern irgendwas im > Bereich der Logic. Ja kein Latch-Up, lediglich das zwei Punkte mit unterschiedlichen elektrischen Potential sind durch die Schaltlogik elektrisch verbunden. Und der eine der beiden "Punkte", wird auch als "Latch" bezeichnet, also ein aus der digitalen Schaltungstechnik bekannte zustandsgesteuerte FlipFlop. https://de.wikipedia.org/wiki/Latch > Wobei interessant waere zu schauen ob > sich beim eintreten der Stromverbrauch signifikant erhoeht > weil da z.B zwei Ausgaenge (im Controller) gegeneinander > arbeiten. Der Stromverbrauch im Controller ist sicherlich erhöht weil der Inputzweig über den internen PullDown-Zweig gespeist wird. Um das zu verhindern, muss die Firmware entweder die elektrische Verbindung von der Quelle (PD) oder die Verbindung zur Senke (Input-Pad-Zweig( deaktivieren Deshalb steht ja auch im Workaround das man den Input-zweig explizit abschalten muss (aka das GPIO in Output-richtung betreiben), damit nur der PD-Treiber aktiv ist "... clear the pad input enable in GPIO0.IE ... to ensure that only the pull-down resistor is enabled. "
Bradward B. (Firma: Starfleet) (ltjg_boimler) >Ja kein Latch-Up, lediglich das zwei Punkte mit unterschiedlichen >elektrischen Potential sind durch die Schaltlogik elektrisch verbunden. >Und der eine der beiden "Punkte", wird auch als "Latch" bezeichnet, also >ein aus der digitalen Schaltungstechnik bekannte zustandsgesteuerte >FlipFlop. Dieses "Semi-Verständnis" kling ein wenig nach ChatGPT.
> Dieses "Semi-Verständnis" kling ein wenig nach ChatGPT.
Obige nichtssagende, nebulös alles-meinende Floskel sollte man sich in
Zukunft sparen, da dergleichen nix zur Klärung der Sachfragen beiträgt.
Bradward B. schrieb: > Deshalb steht ja auch im Workaround das man den Input-zweig > explizit abschalten muss (aka das GPIO in Output-richtung betreiben), > damit nur der PD-Treiber aktiv ist Nur weil man Input abschaltet (~IE) ist nicht automatisch Output aktiv. Da gibt's noch so ein Bit (OD) welches man setzen und löschen kann.
Norbert schrieb: >> Bauform B. schrieb: >> Ich verstehe den E9 Workaround so, dass der Input Buffer nach einem >> Power On Reset aus ist und dass man ihn wirklich nur ganz kurz zum Lesen >> einschalten soll. Normalerweise initialisiert man ja alle Pin-Register >> gleich beim Start. Das darf man in diesem Fall nicht, GPIO0.IE muss aus >> bleiben. Im wirklichen Leben ist es viel einfacher: GPIO0.IE muss aus bleiben, bis der Pull-Down abgeschaltet ist. Fertig. Für den einen Eingang, bei dem ein Pull-Down sinnvoll ist, spendiert man eben einen externen. An Ausgängen findet man eher einen Pull-Down, aber da tritt dieser Fehler nicht auf. Bei anderen uC muss der sowieso immer extern sein, beim RP2350 könnte man sich drauf verlassen, dass die internen auch bei Power On und Brown Out zuverlässig funktionieren. > Muss ich noch testen, aber wie soll das zufriedenstellend mit einem > PIO_ASM-Programm gehen? Das sehe ich noch gar nicht. Es wird nichts so heiß gegessen... ;)
Bauform B. schrieb: > Norbert schrieb: >>> Bauform B. schrieb: >>> Ich verstehe den E9 Workaround so, dass der Input Buffer nach einem >>> Power On Reset aus ist und dass man ihn wirklich nur ganz kurz zum Lesen >>> einschalten soll. Normalerweise initialisiert man ja alle Pin-Register >>> gleich beim Start. Das darf man in diesem Fall nicht, GPIO0.IE muss aus >>> bleiben. > > Im wirklichen Leben ist es viel einfacher: GPIO0.IE muss aus bleiben, > bis der Pull-Down abgeschaltet ist. Fertig. > > Für den einen Eingang, bei dem ein Pull-Down sinnvoll ist, spendiert man > eben einen externen. An Ausgängen findet man eher einen Pull-Down, aber > da tritt dieser Fehler nicht auf. Bei anderen uC muss der sowieso immer > extern sein, beim RP2350 könnte man sich drauf verlassen, dass die > internen auch bei Power On und Brown Out zuverlässig funktionieren. > >> Muss ich noch testen, aber wie soll das zufriedenstellend mit einem >> PIO_ASM-Programm gehen? Das sehe ich noch gar nicht. > > Es wird nichts so heiß gegessen... ;) Hehe, schöner Gedanke. Beschreibe doch einmal grob wie ein PIO_ASM-Programm das alles zufriedenstellend bewerkstelligen soll. Ach ja, noch ein Gedanke. Der SIO hieß so, weil's früher mal ein ›Single Cycle IO‹ war. Isser nu auch nicht mehr. Reine Outputs machen keine Probleme, Inputs mit kräftigem, niederohmigem externen Pull-Down auch nicht. Wenn's hochohmig wie gewohnt sein soll, dann müssen überall externe und sehr, sehr schnelle Buffer davor. Wenn man dynamisch umschalten muss, dann braucht's extreme externe Hardware-Clownereien. Letzten Endes muss jeder für seinen Anwendungsfall entscheiden ob die Anzahl der Gehhilfen noch akzeptabel ist. Achtung _Meinung_: Ich habe bei mir schon drei Fälle bei denen ich eigentlich das Ding sehr gerne einsetzen wollte, jedoch aus verschiedenen Gründen nicht kann.
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.