Hallo zusammen,
ich lerne C programmieren und möchte ein Programm schreiben, das
ausgelesene Dumps aus dem Nand Flash auf Fehler überprüft und diese dann
korrigiert.
Der Code ist offen und ich benutze Kernel als Basis. v3.1
>https://elixir.bootlin.com/linux/v3.1/source/drivers/mtd/nand/nand_ecc.c.
n der Datei nand_ecc.c ist der Algoritm schon vorhanden, ich habe nur
das Problem mit den abgelegten Variablen.
Kann mir jemand helfen oder ein Forum dafür schreiben?
Danke.
Jük P. schrieb: > ich habe nur > das Problem mit den abgelegten Variablen Axo das Problem... Ja aehh - was genau ist denn dein Problem? Gruss WK
Ok und erst auch Danke! Ich komme nicht klar mit dieser Zeile: const uint32_t eccsize_mult = eccsize >> 8; Ich finde nirgendwo im Code die Zuweisung des Wertes 256 oder 512 für das Variable unsigned int "eccsize".
Könnte aus dem Linkerscript kommen.
Moin, Jük P. schrieb: > Ich finde nirgendwo im Code die Zuweisung des Wertes 256 oder 512 für > das Variable unsigned int "eccsize". So wie ich das sehe, wird eccsize doch an die Funktionen in der Datei uebergeben, d.h. mit sowas:
1 | char[3] code; |
2 | char * buf; |
3 | ...
|
4 | __nand_calculate_ecc(buf, 256, &code) |
setzt du eccsize Gruss WK
Angehängte Dateien:
-

100.png
160 KB
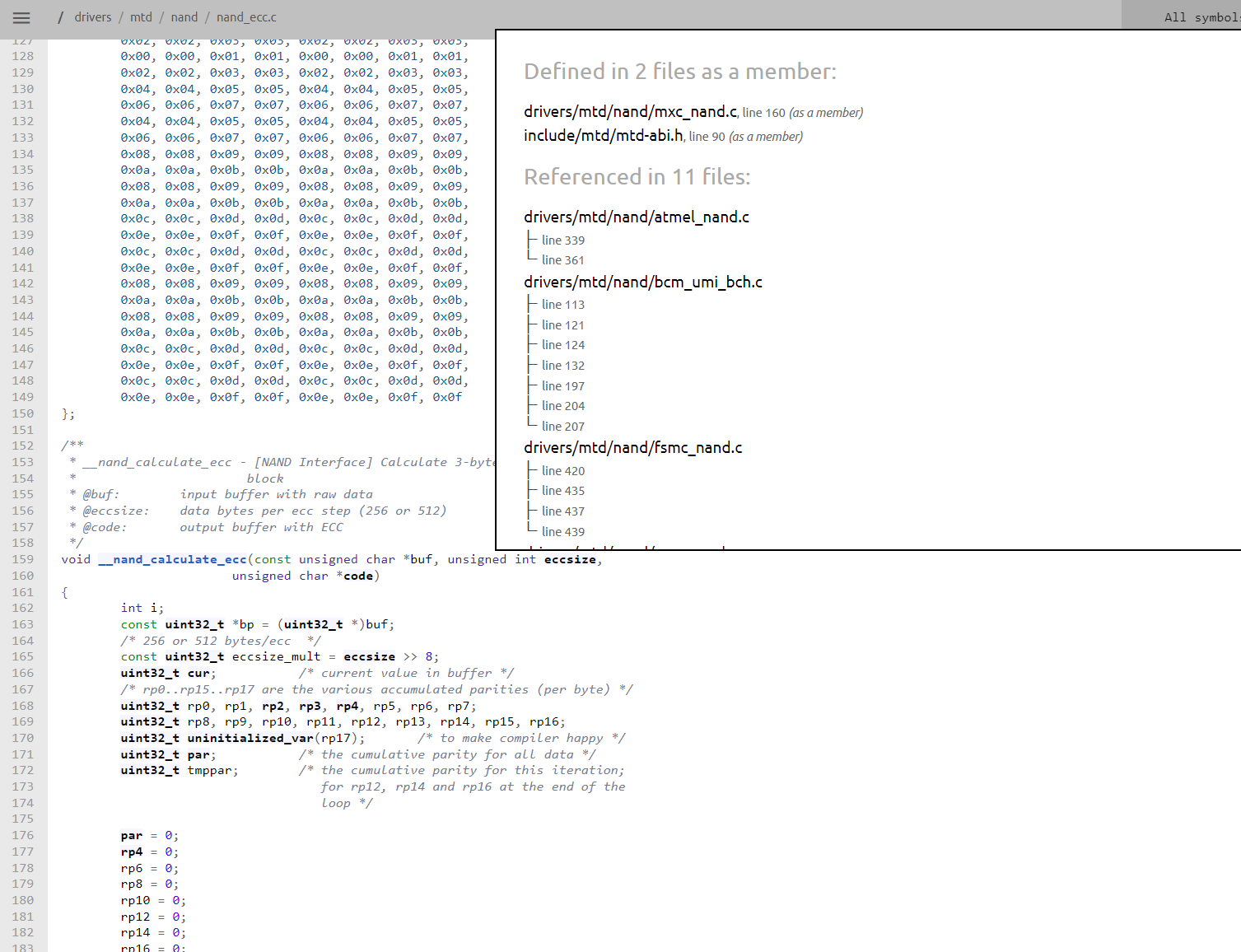
Wenn man das Dokument nand_ecc.c geöffnet hat und auf die Variable "eccsize" geht, dann wird angezeigt, wo überall die vorkommt. Ich kann leider nicht herausfinden, an welcher Stelle die definiert ist. .... https://elixir.bootlin.com/linux/v3.1/source/drivers/mtd/nand/nand_ecc.c Kennt jemand ein guter Forum, wo ich danach fragen könnte? Auch wegen anderen besonderheiten. Wenn ich heute die Code nand_ecc.c mit gcc kompiliere, wird auch korrekt übersetzt? Code nand_ecc.c muss ich auch an Microsoft Visual Studio IDE anpassen? Ich benutze Microsoft Visual Studio 2022. Das Programm soll dann zb auf Windows 10 laufen.
Fabian H. schrieb: > Könnte aus dem Linkerscript kommen. Der Script sollte doch auch eigentlich irgendwo in Kernel auftauchen oder? Wie findet man den?)
Moin, Jük P. schrieb: > Ich kann > leider nicht herausfinden, an welcher Stelle die definiert ist. Die wird dort definert, wo die Funktionen aus nand_ecc.c aufgerufen werden. Siehe mein Beispiel weiter oben. Da wird dann (aus einer anderen, selbstgebastelten Datei mit c source) die Funktion __nand_calculate_ecc() mit ein paar Parametern aufgerufen, und dabei setze ich eccsize auf 256. Jük P. schrieb: > Wenn ich heute die Code nand_ecc.c mit gcc kompiliere, wird auch korrekt > übersetzt? Die Umgebung muss halt passen. Im Linuxkernel wird das sicherlich funktionieren, sonst waere es andern schon laengst aufgefallen. > Code nand_ecc.c muss ich auch an Microsoft Visual Studio IDE anpassen? > > Ich benutze Microsoft Visual Studio 2022. Probier's halt aus, guck was fuer Fehlermeldungen dabei entstehen und "mach' dass die weggehen". So auf die Schnelle faellt mir im Code das #define STANDALONE auf. Das solltest du setzen, wenn du eben nicht die ganzen Headerfiles aus dem Kernelsrc miteinbinden willst. Also z.b. beim Aufruf von gcc noch sowas mit dazugeben: -DSTANDALONE Keine Ahnung wo/wie du das deinem Visual Studio angibst. Dann kommt bei mir noch Mecker weil struct mtd_info unbekannt ist. Also musste das fixen, indem du struct mtd_info irgendwo geeignet herzauberst. usw, bis irgendwann mal das Dingens compiliert... Gruss WK
Dergute W. schrieb: > Die wird dort definert, wo die Funktionen aus nand_ecc.c aufgerufen > werden. Das müsste doch auch irgendwo im Kernel zu finden sein?
Jük P. schrieb: > Dergute W. schrieb: >> Die wird dort definert, wo die Funktionen aus nand_ecc.c aufgerufen >> werden. > > Das müsste doch auch irgendwo im Kernel zu finden sein? 'tuerlich. Guggstu z.b. hier: https://elixir.bootlin.com/linux/v3.1/source/drivers/mtd/sm_ftl.c ab Zeile 222:
1 | static int sm_correct_sector(uint8_t *buffer, struct sm_oob *oob) |
2 | {
|
3 | uint8_t ecc[3]; |
4 | |
5 | __nand_calculate_ecc(buffer, SM_SMALL_PAGE, ecc); |
6 | if (__nand_correct_data(buffer, ecc, oob->ecc1, SM_SMALL_PAGE) < 0) |
7 | return -EIO; |
8 | |
9 | buffer += SM_SMALL_PAGE; |
10 | |
11 | __nand_calculate_ecc(buffer, SM_SMALL_PAGE, ecc); |
12 | if (__nand_correct_data(buffer, ecc, oob->ecc2, SM_SMALL_PAGE) < 0) |
13 | return -EIO; |
14 | return 0; |
15 | }
|
Da wird die Funktion __nand_calculate_ecc aufgerufen und der 2. Parameter ist - oh Wunder - SM_SMALL_PAGE. Das wiederum steht in https://elixir.bootlin.com/linux/v3.1/source/drivers/mtd/nand/sm_common.h Zeile 35:
1 | #define SM_SMALL_PAGE 256
|
Gruss WK
> Dergute W Vielen vielen Dank! Ich werde heute abend hinsetzen/ausprobieren und melde mich dann wieder) Erst muss ich Info verarbeiten und mich fragen, warum ich es nicht selber herausgefunden habe..... Wie sind Sie auf Datei "sm_ftl.c" gekommen? Dergute W. schrieb: > https://elixir.bootlin.com/linux/v3.1/source/drivers/mtd/sm_ftl.c
Moin, Mittels dieser "extrem ausgefuchsten" Kommandozeile:
1 | wk [ ~/tmp/tmp/linux-3.1/drivers ]$ find . | xargs grep __nand_calculate_ecc | less |
(Alles vor dem $-Zeichen ist Prompt; es geht mit "find" los) Gruss WK
So nächste Frage zu Zeile 302: #ifdef __BIG_ENDIAN Wie funktioniert es? An welcher stelle im Kernel wird ermittelt, ob die Daten in Big-Endian oder Little-Endian abgelegt sind? Gibt es dafür ein bestimmter Marker?
Moin, Jük P. schrieb: > So nächste Frage zu Zeile 302: > #ifdef __BIG_ENDIAN > > Wie funktioniert es? An welcher stelle im Kernel wird ermittelt, ob die > Daten in Big-Endian oder Little-Endian abgelegt sind? So ausm Stegreif: Keine Ahnung, das wird wohl irgendwo im Buildsystem mal abgefragt werden. > Gibt es dafür ein bestimmter Marker? Naja - das Datenblatt des Prozessors, auf dem das Zeugs laufen soll. Und entsprechend wuerde ich da am Anfang mal aehnlich wie bei STANDALONE das mal stumpf auf den fuer dich richtigen Wert setzen. Gruss WK
Danke. ich werde im Programm dann die Abfrage machen. Z.B. "Sind die Daten als BIG_ENDIAN abgelegt? Wenn Ja, dann bitte mit "1" bestätigen. Wenn Nein, dann bitte mit "0" bestätigen."
Moin, Jük P. schrieb: > Danke. > > ich werde im Programm dann die Abfrage machen. Z.B. "Sind die Daten als > BIG_ENDIAN abgelegt? Wenn Ja, dann bitte mit 1 bestätigen." Kannste so machen. Aber dann musst du aus dem
1 | #ifdef __BIG_ENDIAN
|
ein "normales"
1 | if (bigendian) { ... } else { ... } |
machen. Die Zeilen mit # am Anfang werden ja vom Praeprozessor beim compilieren ausgewertet und nicht zur Laufzeit des Programms. Solche Geschichten wuerde ich aber erst gegen Schluss einbauen, lieber erstmal gucken, dass der Compiler durchlaeuft und das Programm mit irgendeiner Endianess spielt. Gruss WK
Ok. Ich schaue mal nach, wie "#ifdef __BIG_ENDIAN" funktionieren in C soll. Ich möchte möglich wenig Änderungen vornehmen. So das da binde ich in den Kopf meines Codes. #ifndef __BIG_ENDIAN #define __BIG_ENDIAN 4321 #endif Siehe https://elixir.bootlin.com/linux/v3.1/source/include/linux/byteorder/big_endian.h#L5
Moin, Jük P. schrieb: > Ich möchte möglich wenig Änderungen vornehmen. Gute Idee. Dann wuerde ich auch nix am Source aendern, sondern den Compileraufruf entsprechend gestalten. Halt nicht nur gcc blabla, sondern gcc -DSTANDALONE -D__BIG_ENDIAN blabla Aber natuerlich nur, wenn du den Code auf einer Big Endian CPU laufen lassen willst (x86/x86_64 ist Little Endian, wollt' ich mal unauffaellig anmerken)... Gruss WK
Dergute W. Sie haben viel drauf) Ich lerne durch probieren, nachdem das Programm abgelaufen hat, quck ich mir die Datei + Ergebnis mit Hex Editor an und bewerte es. Im Moment habe ich ein Dump, wo die Daten in BIG_ENDIAN abgelegt sind. Da muss ich durch viele Fehler lernen) Hier ist meine Datei. https://www.file-upload.net/download-15397672/Dump_Origi.zip.html
Moin, Hui, gleich so dicke Bretter bohren, um C zu lernen. Na denn, viel Erfolg! Gruss WK
Noch die Frage.
Mit der Zeile:
fseeko64(in, pos, SEEK_SET);
fread(buf, Page_without_Spare, 1, in); /* lese 2048 bytes in buffer
*/
Dann möchte ich mit For Schleife
for (j = 0; j <= cycl_page; j++) {
uint32_t* bp = (uint32_t*)buf[step];
step = step + 256;
}
step = 256;
cycl_page = 2048/256= 8.
In den Buffer *bp je 1 Schleife 256 Bytes übergeben, klappt aber nicht)
Die Zeile denke mir was faul > uint32_t* bp = (uint32_t*)buf[step];
Moin, Jük P. schrieb: > Die Zeile denke mir was faul > uint32_t* bp = (uint32_t*)buf[step]; Vielleicht so:
1 | uint32_t* bp = (uint32_t*)&buf[j*step]; |
Ist aber unschoen. Ich weiss nicht, was buf fuer ein pointer ist und da koennt's leicht alignmentprobleme geben. Gruss WK
Angehängte Dateien:
-

Unbenannt.JPG
6,1 KB -

Unbenannt1.JPG
4,9 KB
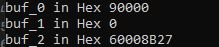

Mit Zeilen
printf("buf_0 in Hex %X ", buf[0]);
printf("\n");
printf("buf_1 in Hex %X ", buf[1]);
printf("\n");
printf("buf_2 in Hex %X ", buf[2]);
printf("\n");
Prüfe ich Inhalt, bei *buf - passt.
Ok, ich lerne nur)
Danke ich probiere Ihre Code aus.
uint32_t * buf = malloc(mem_size); /* #define mem_size 65536 */
if (buf) {
printf("");
//printf("file Spare <Spare_Out.bin> erstellt.\n");
}
else {
printf("Allocation Error.\n");
return 1;
}
/* buffer bp*/
uint32_t* bp = malloc(mem_size); /* #define mem_size 65536 */
if (bp) {
printf("");
//printf("File Spare <Spare_Out.bin> erstellt.\n");
}
else {
printf("Allocation Error.\n");
return 1;
}
Mein Plan war 2048 bytes 1 page in buffer *buf laden, dann mit schleife 8 mal je 256 bytes abarbeiten. Hier sollte *buf blockweise mit offset gelesen werden. Das weiß ich nicht wie es geht.... deswegen gebe erst mal auf. Und ändere wie folgt 256 bytes gelesen- abgearbeitet und weiter. Mal sehen was wird. Irgendwann werde zu Plan oben wieder kommen.
Jük P. schrieb: > So nächste Frage zu Zeile 302: > #ifdef __BIG_ENDIAN > > Wie funktioniert es? An welcher stelle im Kernel wird ermittelt, ob die > Daten in Big-Endian oder Little-Endian abgelegt sind? Wenn dein Zeug unter Windows laufen soll, solltest du das an die Vorgaben von deinem Windows Compiler anpassen (RTFM).
Dergute W. schrieb: >
1 | wk [ ~/tmp/tmp/linux-3.1/drivers ]$ find . | xargs grep |
2 | > __nand_calculate_ecc | less |
1 | find . -type f | xargs grep __nand_calculate_ecc |
Moin, Ich hab von NAND-Flash nicht viel Plan, ist schon ein paar Jahre her und damals hatte ich nur ein yaffs eingesetzt und nichts mit den Innereien zu tun. iirc waren da die Sektorgroessen 512Byte und danach immer 16Byte OOB extra. In den 16Bytes waren dann Filesysteminfos und ECC drinnen. Bei deinem Dump sieht mir das danach aus, als waere die Sektorgroesse 2048Byte und danach 64 Byte OOB. Und wenn ich mit "hexdump -C" da mal reinschaue, sehe ich z.b. so eine Zeile:
1 | 00048660 6e 6b 6e 55 00 6e 77 6f 00 00 00 00 00 00 00 00 |nknU.nwo........| |
Das sieht mir doch grad' so aus, als wuerde da der String "Unknown" stehen, aber eben durch unterschiedliche Endianess etwas verhackstueckt... Also wuerde ich empfehlen: Schreib dir erstmal - voellig ohne irgendwelchen Schlonz aus Kernelsourcen - ein Programm, was immer Haeppchen von 2048+64=2112 Byte aus einem File (deinem Riesendump) einliest. Dann evtl. mal was programmieren, was die Endianess "in Ordnung" bringt. Dann mal schlau machen, was da jeweils in dem OOB Bereich steht. Und erst dann mal ganz langsam in Richtung ECC streben. Gruss WK
Angehängte Dateien:
-

Unbenannt.JPG
29 KB
Ich komme tuktuk weiter) Ich lese jetzt 256 byte und es wird auch korrekt an *bp übergeben) uint32_t* bp = (uint32_t*)buf; ECC wird auch berechnet)) Nur mit Dump passt es nicht überein) Natürlich ich weiss noch nicht ob im Dump ECC mit Hamming berechnet wurde) Aber das Programm läuft schon ganz korrekt) Mein Dump hat folgende Struktur Page 2048 byte Spare 64 byte Page per Block 64 Block per Device 4096 Zum Dump Spare oder OBB. - die ersten 8 bytes sind leer auf jeden Fall nichts mit ECC zu tun haben. - 9 bis 36, gesamt 28 Bytes vermute ECC - von 37 bis 64 - leer, Ohne Bedeutung Dergute W. schrieb: > Also wuerde ich empfehlen: > Schreib dir erstmal - voellig ohne irgendwelchen Schlonz aus > Kernelsourcen - ein Programm, was immer Haeppchen von 2048+64=2112 Byte > aus einem File (deinem Riesendump) einliest. Dann evtl. mal was > programmieren, was die Endianess "in Ordnung" bringt. Das ist schon bestens erledigt) Aus Datei nand_base.c /* Define default oob placement schemes for large and small page devices */ static struct nand_ecclayout nand_oob_8 = { .eccbytes = 3, .eccpos = {0, 1, 2}, .oobfree = { {.offset = 3, .length = 2}, {.offset = 6, .length = 2} } }; static struct nand_ecclayout nand_oob_16 = { .eccbytes = 6, .eccpos = {0, 1, 2, 3, 6, 7}, .oobfree = { {.offset = 8, . length = 8} } }; static struct nand_ecclayout nand_oob_64 = { .eccbytes = 24, .eccpos = { 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63}, .oobfree = { {.offset = 2, .length = 38} } }; static struct nand_ecclayout nand_oob_128 = { .eccbytes = 48, .eccpos = { 80, 81, 82, 83, 84, 85, 86, 87, 88, 89, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99, 100, 101, 102, 103, 104, 105, 106, 107, 108, 109, 110, 111, 112, 113, 114, 115, 116, 117, 118, 119, 120, 121, 122, 123, 124, 125, 126, 127}, .oobfree = { {.offset = 2, .length = 78} } }; Hier habe ich Dump 4 Byte gedreht https://www.file-upload.net/download-15397790/Dump_Out_32Bit_gedreht.zip.html Bitte mit Hexeditor und zb Adresse 420000 Hex anqucken) und mit Dump original vergleichen. Post 11.10.2024 16:05.
So ich habe jetzt Dump Struktur geknackt) Page 2048 + 64 = Gesamt 2112 Bytes 2112 Bytes = 1024 Bytes Data + 14 bytes ECC +1010 Bytes Data + 8 Bytes Leer "FF" + 14 Bytes Data + 14 Bytes ECC + 28 Bytes Leer "FF". Also pro 1024 Bytes > 14 Bytes ECC https://patents.google.com/patent/CN102142282A/en https://ww1.microchip.com/downloads/aemDocuments/documents/MPU32/ApplicationNotes/ApplicationNotes/doc11127.pdf https://www.linux4sam.org/bin/view/Linux4SAM/PmeccConfigure?skin=print.myskin https://bootlin.com/blog/supporting-a-misbehaving-nand-ecc-engine/ hier sehr interesant https://github.com/SySS-Research/nand-dump-tools/blob/master/nand_dump_decoder.py
Warum kriegen es die Leute heute nicht mehr hin Text als Text zu posten und nicht als Grafik?
Hier habe alle Datas 1024 + 1010 + 14 Bytes aus dem Dump_Original in ein neues File Dump_only_Data.bin geschnitten. https://www.file-upload.net/download-15397967/Dump_only_Data.zip.html Hier habe ich File Dump_only_Data.bin 4 Bytes gedreht. https://www.file-upload.net/download-15397970/Dump_only_Data_Out_32Bit_gedreht.zip.html Als nächste Aufgabe die Code in C für BCH ECC of 1024 byte raw data is 112 bits (accounting for 14 bytes) zu schreiben. Also 8-bit error correction on 1024 page size NAND Flash
G. K. schrieb: > Warum kriegen es die Leute heute nicht mehr hin Text als Text zu posten > und nicht als Grafik? Zunehmende Verblödung. Ist so ein Gen-Z und Tiktok-Ding.
Noch etwas gelernt. memset(code, 0, chip->ecc.bytes); und memcpy(bch->ecc_buf, r, sizeof(r)); Ich bin sicher, damit kann ich größere Blocke in RAM laden und dann Stück für Stück abarbeiten. In RAM ganzen Block 2112 Bytes *64 = 1 Block, dann davon mit memcpy ind Buffer übergeben. Im Moment meine Code liest in RAM 256 Byte abarbeitet und wieder liest 256 Byte. Es dauert zu lange) Ich lerne nur etwas programmieren.
Jük P. schrieb: > Noch etwas gelernt. > memset(code, 0, chip->ecc.bytes); > und > memcpy(bch->ecc_buf, r, sizeof(r)); > > Ich bin sicher, damit kann ich größere Blocke in RAM laden und dann > Stück für Stück abarbeiten. In RAM ganzen Block 2112 Bytes *64 = 1 > Block, dann davon mit > memcpy ind Buffer übergeben. Ob die Daten aus einem kopierten oder einem nicht kopierten Buffer verarbeitet werden ist egal, nur ohne kopieren geht es schneller.
Gibt es in C nicht die Möglichkeit, einen größeren Block aus einer Datei in Puffer 1 zu laden und dann die Daten stückweise mit Offset von Puffer 1 an Puffer 2 für je 512 Bytes zur Verarbeitung zu übergeben? Mein Code, der immer 256 Bytes aus einer Datei liest und verarbeitet, dann wieder liest und verarbeitet und so weiter. Das dauert sehr, sehr lange. Ich bin sicher, dass es eine Möglichkeit gibt, das zu beschleunigen.
Moin, Du kannst deine Datei komplett in einen virtuellen Buffer "mappen": https://www.gnu.org/software/libc/manual/html_node/Memory_002dmapped-I_002fO.html Ich halte es aber auch fuer recht wahrscheinlich, dass dein existierender code zum Lesen der 256 Bytes evtl. noch etwas beschleunigt werden koennte. Gruss WK
Jük P. schrieb: > Gibt es in C nicht die Möglichkeit, einen größeren Block aus einer Datei > in Puffer 1 zu laden und dann die Daten stückweise mit Offset von Puffer > 1 an Puffer 2 für je 512 Bytes zur Verarbeitung zu übergeben? Natürlich kann man das in C machen, aber warum sollte man? Man kann auch einfach eine Datei in einen Puffer laden und die Daten dann an Ort und Stelle bearbeiten. Wozu sollte da ein zweiter Puffer nötig sein?
Das stimmt, 2 Puffer werde ich rausschmeißen. Meine bisherige Code liest 256 Byte in Puffer 1, dann übergibt an Puffer 2, dann bearbeitet. Beim bearbeiten habe ich pro 1 Schleife 9 Printf... eingebaut, um visuell Ergebnisse zu sehen. Dieses Programm lies ich 512 KByte bearbeiten, nach ca. 5 Minuten habe ich abgebrochen. Ich denke, wenn 2 Puffer rausnehme und 9 Printf auch, dann sollte schon schneller gehen. Sonst werde später mir genauer mmap ansehen. Sonst habe ich jetzt vor, Code für die Berechnung ecc nach BCH zaubern. Ein Dump geeignet habe ich schon gefunden. Da ist die Struktur deutlich einfacher und die Daten liegen in little endian. Dateien die bearbeiten werden sollen, manchmal überschreiten auch 2 GByte.
Jük P. schrieb: > Dateien die bearbeiten werden sollen, manchmal überschreiten auch 2 > GByte. Und? Wenn Du nicht ausgerechnet mit einem 32-Bit-Compiler unterwegs bist, kannst Du auch sowas am Stück in den Speicher laden; die Zeit, wo Computer 4 GB RAM oder sogar noch weniger hatten, ist auch schon 'ne Weile vorbei.
Also ihr Vorschlag 1. Komplett Datei in buffer 1 laden 2. Daten Komplett abarbeiten und auch Ergebnisse auch in buffer 2 laden. 3. Wenn abarbeiten fertig, Kompletten buffer 2 in die Out Datei schreiben. Das klingt nicht schlecht) Danke auch für den Tipp) Wenn ich eine Code zb BCH ECC geschrieben habe und Ergebnisse ECC mit gespeicherten im Dump gleich sind, erst dann werde ich Code optimieren. Ich melde mich dann noch etwas später. OPs da habe ich schon gleich Problem mit buffer arbeiten. Bis jetzt habe ich nicht gefunden wie man es mit offset da liest oder schreibt....
Kann mir bitte jemand noch helfen, die Angabe " ? 1 : 2;" in der Zeile zu verstehen? const u32 eccsize_mult = (step_size == 256) ? 1 : 2; Danke vielmals vorab!
Dergute W. schrieb: > Mittels dieser "extrem ausgefuchsten" Kommandozeile: > (irgendwas mit find und grep) 🙂 Für die klickibunti Generation gibt es dazu das Programm SearchMonkey. Kann nicht viel, ist dafür einfach zu benutzen - sofern man sich vorher mit regulären Ausdrücken vertraut gemacht hat, was man früher oder später eh tun muss.
G. K. schrieb: > Warum kriegen es die Leute heute nicht mehr hin Text als Text zu posten > und nicht als Grafik? Sei froh, dass es kein TikTok Clip ist. Andere Generation halt. Deren Zug ist längst ohne uns abgefahren.
Moin, Jük P. schrieb: > Kann mir bitte jemand noch helfen, die Angabe " ? 1 : 2;" in der Zeile > zu verstehen? https://learn.microsoft.com/de-de/cpp/cpp/conditional-operator-q?view=msvc-170 Gruss WK
wenn ? dann : sonst rabatt = price > 100 ? 20 : 10; Bedeutet: Wir geben 20 Euro Rabatt, wenn der Preis größer als 100 Euro ist, sonst 10 Euro Rabatt. Dort ist auch ein schönes Beispiel: https://www.programiz.com/cpp-programming/ternary-operator
Vielen Dank!) Es ist Haufen dabei zu lernen) Vor ca. 30 Jahren habe ich etwas Basic kennengelernt und jetzt finde ich schon gut, selbst kleine Programme zu schreiben.
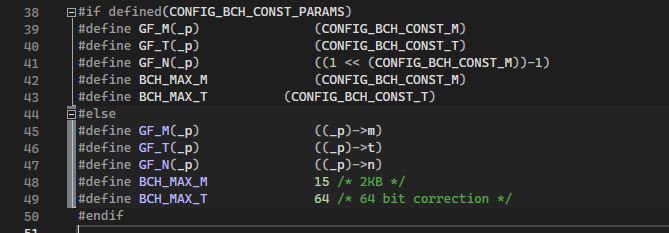
Nun bin ich wieder mit Frage. Code stammt von https://elixir.bootlin.com/linux/v3.1/source/lib/bch.c#L88 Und ich möchte für Windows umschreiben. Problem habe ich jetzt mit der Zeile #define GF_M(_p) ((_p)->m) gcc spuckt diese Fehlermeldung bb.c:47:32: error: expected declaration specifiers or '...' before '(' token #define GF_M(_p) ((_p)->m) ^ Wie kann ich es verstehen, was gcc da nicht gefällt? (_p) - Wie kann ich deuten? _p - Unterstrich "_" hat eine Bedeutung? Tut mir leid...
Moin, Jük P. schrieb: > Problem habe ich jetzt mit der Zeile > #define GF_M(_p) ((_p)->m) Nee, die Zeile macht kein Problem, guggstu:
1 | #include <stdio.h> |
2 | #define GF_M(_p) ((_p)->m)
|
3 | struct bla { |
4 | int m; |
5 | };
|
6 | int main() { |
7 | struct bla bla = {42}; |
8 | struct bla *blaptr = &bla; |
9 | printf("%d\n",GF_M(blaptr)); |
10 | }
|
Compiliert und macht, was es soll.
Da vermute ich eher das Problem:
> bb.c:47:32:
Gruss
WK
#define GF_M(_p) ((_p)->m) In der Zeile: m - ist eine Variable des Typs int _p - ist eine Pointervariable, also *_p? ((_p)->m) ist das gleiche (*_p).m -> - Arrow operator
Das ist klar, aber was steht in der Zeile 47, die Du uns nicht zeigst?
Harald K. schrieb: > Das ist klar, aber was steht in der Zeile 47, die Du uns nicht > zeigst? Die alleine wuerde wahrscheinlich nicht viel helfen. Entscheidender wird wohl sein: Jük P. schrieb: > _p - ist eine Pointervariable, also *_p? Welche Geschmacksrichtung diese Pointervariable hat - also auf was fuer ein Ding pointet dieser Pointerapparat? Gruss WK
Dergute W. schrieb: > Die alleine wuerde wahrscheinlich nicht viel helfen. Doch, denn in der wird das Macro verwendet. Der Name "_p" existiert nur in der Macrodefinition, wird bei Gebrauch aber durch was anderes ersetzt.
1 | #define GF_M(_p) ((_p)->m)
|
In Zeile 47 steht etwas in dieser Art:
1 | x = GF_M(horst); |
Und das wird ersetzt durch
1 | x = ((horst)->m); |
Der Gebrauch des Macros GF_M erwartet, daß ein Pointer auf eine Struktur übergeben wird, die ein Element namens "m" enthält.
Angehängte Dateien:
-

Unbenannt.JPG
29 KB -

Unbenannt1.JPG
80 KB
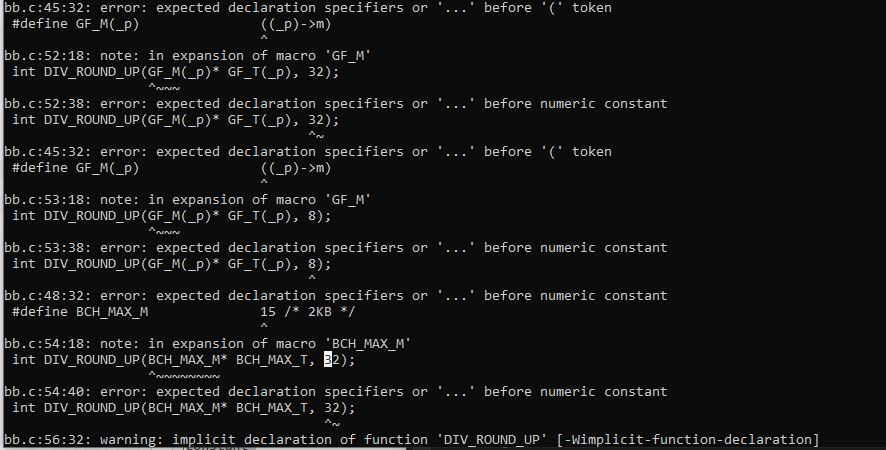
Die Code ist viel zu hoch für mich.... Ich würde für den Anfang lieber diese Quelle bevorzugen. https://github.com/cyberdong/bch_encoder_decoder/tree/master Die scheint mir einfacher zu sein.
Man kann Text auch als Text anhängen, da muss man keine Screenshots von machen. Das Problem liegt nicht an der Stelle, wo die Macros definiert werden, sondern da, wo sie verwendet werden. Da Du Dich hartnäckig weigerst, exakt den Code zu zeigen, der Deine Fehlermeldungen hervorruft, kann man Dir auch nicht helfen. Vielleicht geht es um eine Datei namens "bb.c", vielleicht heißt die aber auch [abgeschnitten], wer weiß das schon.
Angehängte Dateien:
-

Unbenannt2.JPG
60 KB
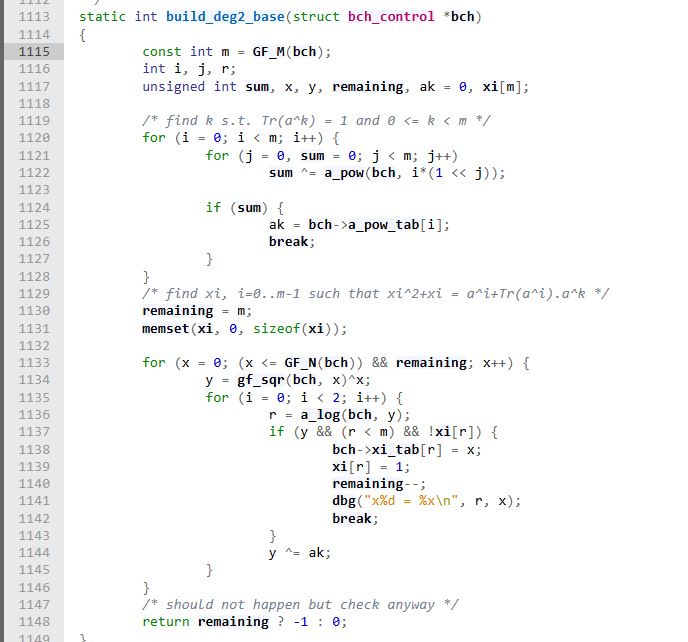
In der Zeile 1115 glaube steht https://elixir.bootlin.com/linux/v3.1/source/lib/bch.c#L1115 Tja
G. K. schrieb: > Warum kriegen es die Leute heute nicht mehr hin Text als Text zu > posten > und nicht als Grafik? Das frage ich mich so langsam auch...Und ums extra bescheuert zu machen, dann nicht mal die direkt ueber dem Antwortfenster stehende Anleitung bzgl. der Bildformate abarbeiten koennen. DIE HIER: https://www.mikrocontroller.net/articles/Bildformate scnr, WK
Okay, ich werde meinen Code überarbeiten und einstellen. Im Moment ist da zu viel Chaos. Tut mir leid...
Moin, Jük P. schrieb: > Okay, ich werde meinen Code überarbeiten und einstellen. > Im Moment ist da zu viel Chaos. Den wird sich eh' keiner antun wollen. In diesem Post: Beitrag "Re: ECC - Error Correcting Code Hamming Nand Flash selbst schreiben" Hab' ich's doch tatsaechlich geschafft, ein Minimalbeispiel auf 10 Zeilen eingedampft als Text zu posten. Das solltest du auch schaffen... Schmeiss aus deinem Code alles raus, was nix zu dem Fehler beitraegt, der dich interessiert, bevor du den hier postest. Gruss WK
Angehängte Dateien:
-

Unbenannt.PNG
14 KB -

Unbenannt1.PNG
31 KB
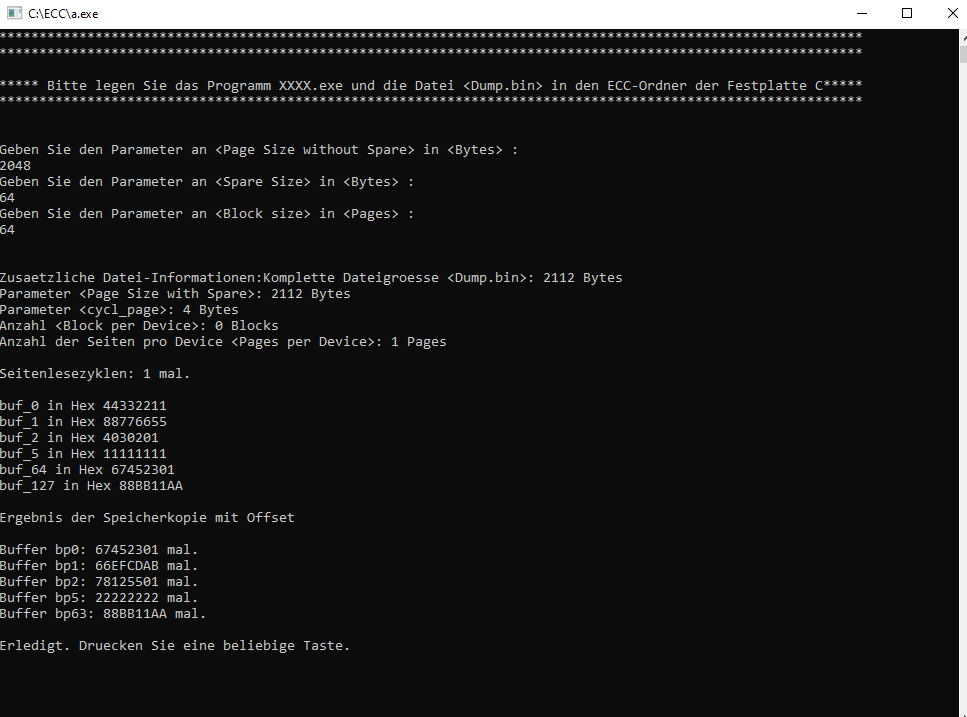
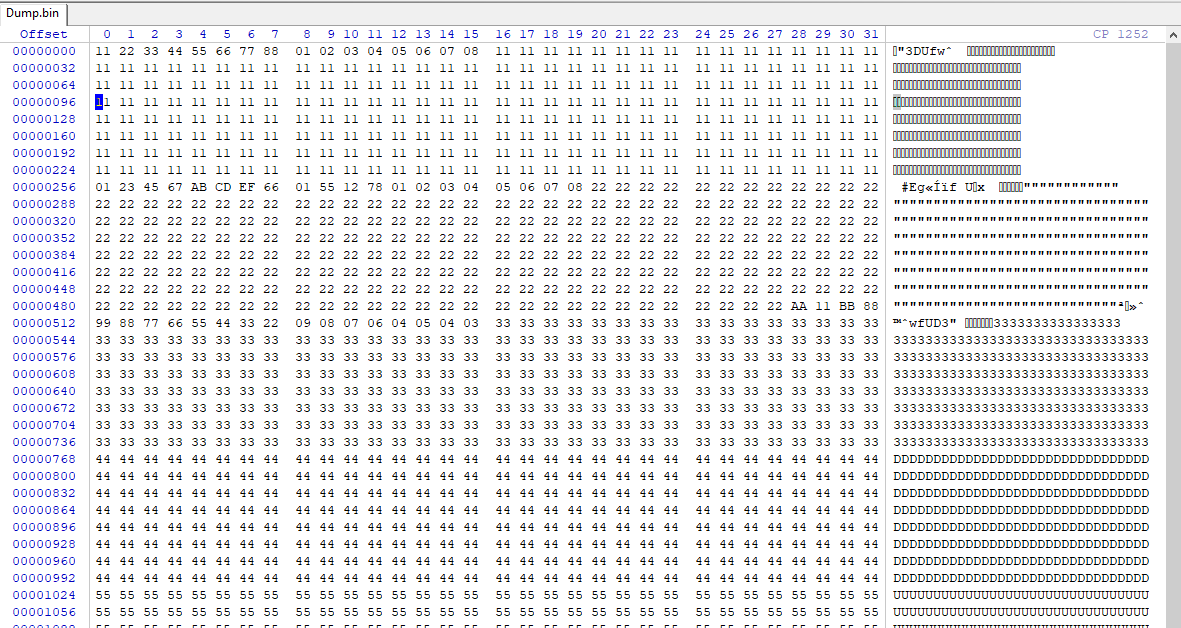
Im Anhang befindet sich der Code, ein compiliertes Programm a.exe + Testdatei Dump.bin. In der Code möchte ich dann nicht 512 Bytes von Datei einlesen und bearbeiten und wieder.. Es dauert zu lange zb. 2GByte oder mehr zu berechnen. In der Code habe ich schon die Lösung, wie ich ein Block zb. 2112 Bytes 1 Seite x 64 Seiten = 1 Block in den Buffer lade und dann per memcpy an einen weiteren Buffer weiter gebe. Da wie ober schon erwähnt wurde, Windows PC liest die Daten 4 Bytes gedreht, das muss ich dann noch eventuell einbauen. Dump.bin > Die daten da betrachte ich als little Endian und mein Programm macht draus BIG_ENDIAN. Es ist auch kein Problem, Code für habe ich schon. Das Programm + Dump.bin bitte nach C:\ECC ablegen. a.exe starten und 2048 Main area + 64 Spare + 64 Seiten eingeben. Die Code BCH da brauche ich noch etwas Zeit oder besser gesagt ein Plan... Vielen vielen Dank! Mit Ihrer Hilfe kriege ich es schon hin) Jetzt muss schlaffen gehen, morgen arbeiten) Schönen Abend noch allen! BCH Code, denke, für mich wäre einfacher von da weiter zu machen. https://github.com/cyberdong/bch_encoder_decoder/tree/master Mit C kenne ich mich nicht viel aus, muss durch viel ausprobieren kämpfen. Es macht aber Spass letztendlich. Morgen/übermorgen werde ich dann versuchen BCH einbauen.
Angehängte Dateien:
-

Unbenannt.PNG
79 KB
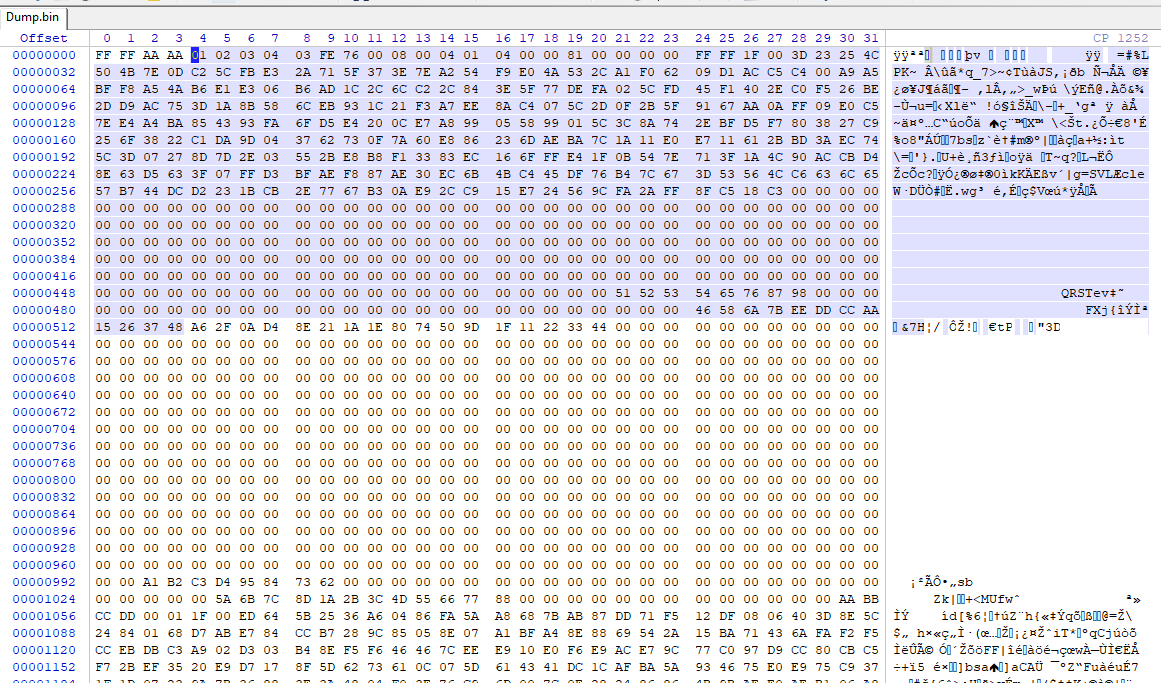
Damit ist der erste Schritt abgeschlossen. Im Anhang befindet sich der Code, eine Dump.bin und eine kompilierte .exe. Dump.bin hat folgende Struktur: Page komplett mit Spare: 4 Bytes - Marker NC 512 Bytes - Daten 1-es Block 13 Bytes - ЕСС 1-es Block (angenommen BCH ECC, ausgelesen aus einem NAND Flash MX MX30LF4G18AC, was für eine CPU ist unbekannt. Deswegen kann nur raten) 512 Bytes - Daten 2-es Block 13 Bytes ЕСС 2-es Block 512 Bytes- Daten 3-es Block 13 Bytes ЕСС 3-es Block 469 Bytes - Daten 4-es Block, nur ein Teil Spare: 6 Bytes - FF NC 43 Bytes - Daten 4-es Block, der Rest 13 Bytes ЕСС 4-es Block 2 Bytes - FFNC Auf Laufwerk C, ein Ordner "ECC" anlegen und dahin Dump.bin und a.exe ablegen. Eingaben bitte wie folgt eingeben: 2048 (Bytes Main pro Page), 64 (Bytes Spare) und 64 (Pages pro 1 Block) Ablauf wie folgt, - es wird 1 Block in ein Buffer geladen (2048+64)*64 Bytes. - dann 1 Page (2048+64) von Buffer in ein anderen Buffer1 kopiert. - dann aus dem Buffer1 (Page 2112 Bytes) je 512 und 13 Bytes in ein dritten Buffer buf_bp 512 Bytes und code 13 Bytes kopiert. Es wäre nett, wenn sich jemand den Code anschauen könnte und ich würde mich über Feedback freuen. Vor ein paar Wochen wusste ich nicht, wie ich Daten von einem Puffer mit Offset an einen anderen Puffer übergeben kann. Als nächstes befasse ich mich mit Code BCH ECC.
Können Sie mir bitte noch etwas helfen mit C?) Was bedeutet diese Zeile (rand() & 65536) >> 16; oder rand() & 0xFF; Danke voraus! Sonst können Sie bitte mir eine Seite schreiben, wo ich ab und zu zu C fragen könnte?
Jük P. schrieb: > (rand() & 65536) >> 16; > oder > rand() & 0xFF; rand() ist eine Funktion, die einen Zufallswert zurückgibt. & ist der bitweise UND-Operator 65536 ist eine Dezimalzahl (2 ^ 16), die genau ein gesetztes Bit enthält. >> ist der Operator für bitweises Schieben. Was passiert hier? rand() liefert einen Wert, der mit der UND-Verknüpfung auf zwei mögliche Werte reduziert wird: 0 oder 65536. Dieser Wert wird jetzt um 16 Bits nach rechts geschoben, was gleichbedeutend ist, daß er durch 2 ^ 16 geteilt wird -- das ist 65536. Also ist das Ergebnis der Zeile entweder 0 oder 1. In der zweiten Zeile taucht die bereits bekannte Funktion rand() auf, und auch der bereits bekannte bitweise UND-Operator. Jetzt wird aber mit 0xFF verknüpft, das ist eine Zahl in hexadezimaler Darstellung, identisch mit 255. Und das ist 2 ^ 8 -1, eine Zahl, in der genau acht Bit gesetzt sind. Ergebnis dieser Verknüpfung ist ein Zufallswert zwischen 0 und 255. Hast Du schon mal überlegt, Dir vielleicht ein Buch über die Programmiersprache C anzusehen? Der Klassiker, Brian Kernighan & Dennis Ritchie, "Programmieren in C", zweite Ausgabe, ist zwar einige Jahrzehnte alt, erklärt aber alle diese Konzepte.
Angehängte Dateien:
-

Unbenannt.JPG
81 KB
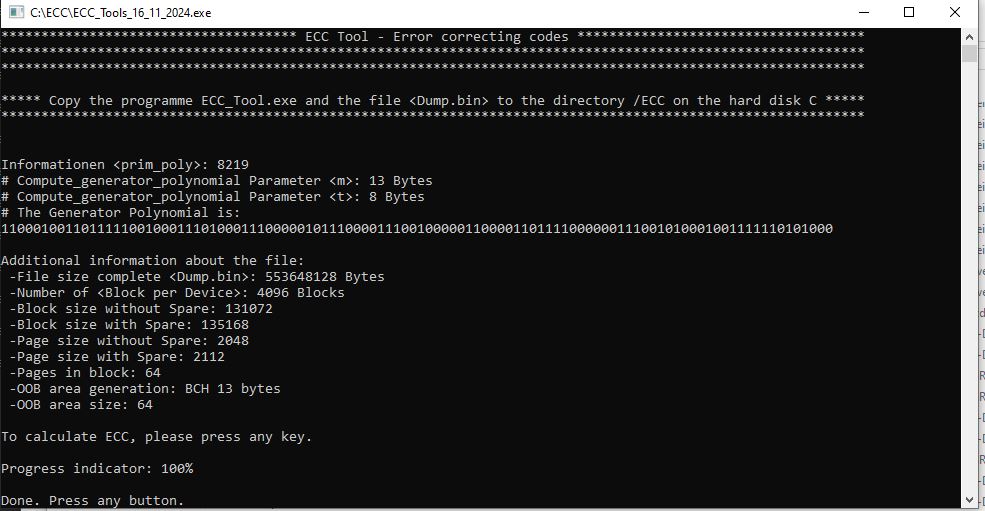
Hallo, nun habe etwas funktionierendes erstellt. Es berechnet ECC nach Standard BCH-8 mit Standard Polynom Degree 13 - 8219 oder Gf(2^13)= 8192 oder: x^13 + x^4 + x^3 + x^1 + 1. Ich habe noch sehr viel bei C zu lernen) Wenn ich fragen zu C habe, kann ich hier stellen? Nächste Aufgabe wäre, ein Programm zu schreiben welches nach ECC Code ein Polynom findet). Weil viele Hersteller lassen ECC Code nicht nach Standard Polynom erstellen.... Danke im voraus für die Hilfe!
Jük P. schrieb: > Fabian H. schrieb: >> Könnte aus dem Linkerscript kommen. > > Der Script sollte doch auch eigentlich irgendwo in Kernel auftauchen > oder? > Wie findet man den?) grep
Angehängte Dateien:
-

Capture.JPG
100 KB
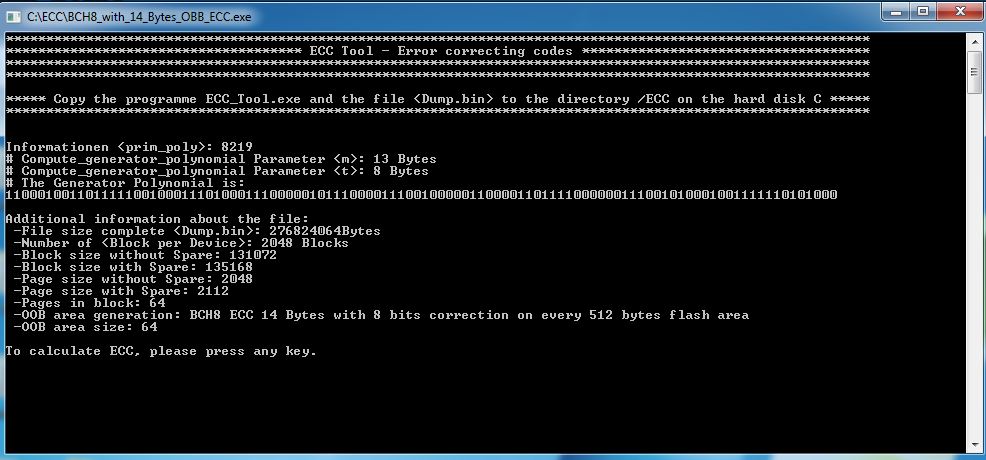
So nun habe ich ein funktionierendes Programm für die Berechnung ECC Code nach BCH-8 gezaubert und auch viel dabei gelernt. Codierung algorithmus ist z.B. in einem AM335x processor implementiert. Das programm berechnet erstmal nur ECC Code, als nächstes werde ich dann das Programm mit prüfen/korrigieren eines bestehendes Code komplett 2048+64 erweitern. z.B. für NAND flash: - Type: MT29F1G08ABCH - Bus width: 8 bit - Size: 128 MiB - Page size: 2048 Byte - Subpage size: 512 Byte - Erase block size: 128 KiB - OOB size per page: 64 Byte OOB layout: (64 bytes) - Bad block markers: 2 bytes [0xFF 0xFF] - 14th byte ECC for first subpage: 14 bytes - 14th byte ECC for second subpage: 14 bytes - 14th byte ECC for third subpage: 14 bytes - 14th byte ECC for fourth subpage: 14 bytes - Reserved: 6 bytes [0xFF 0xFF 0xFF 0xFF 0xFF 0xFF] Tool selbst hier zum Probieren. https://fex.net/ru/s/9yzvcxy
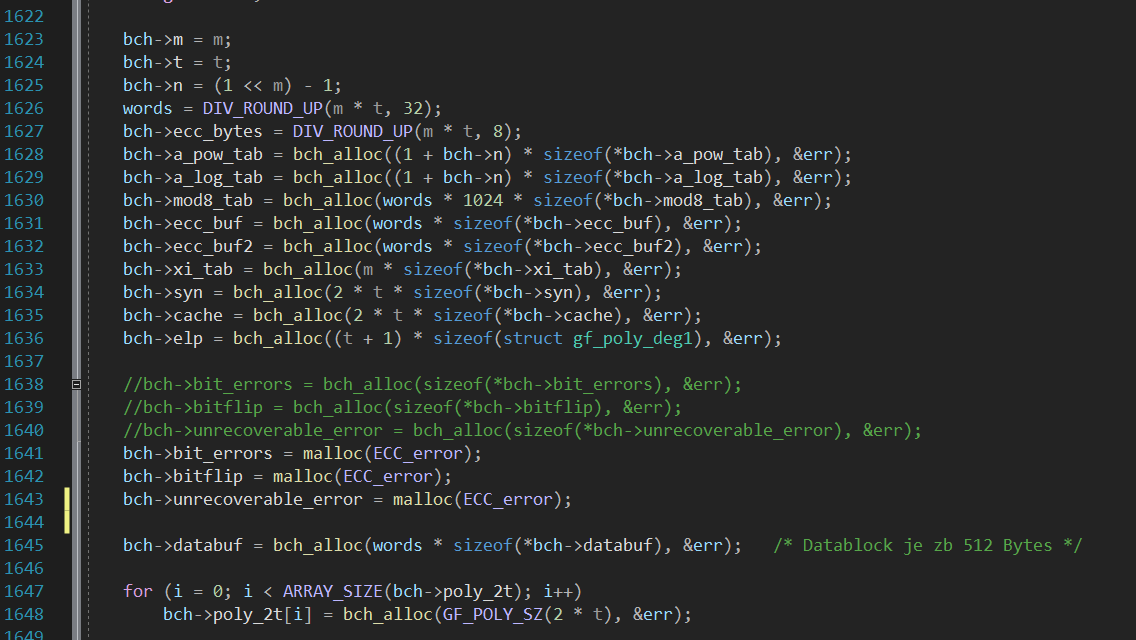
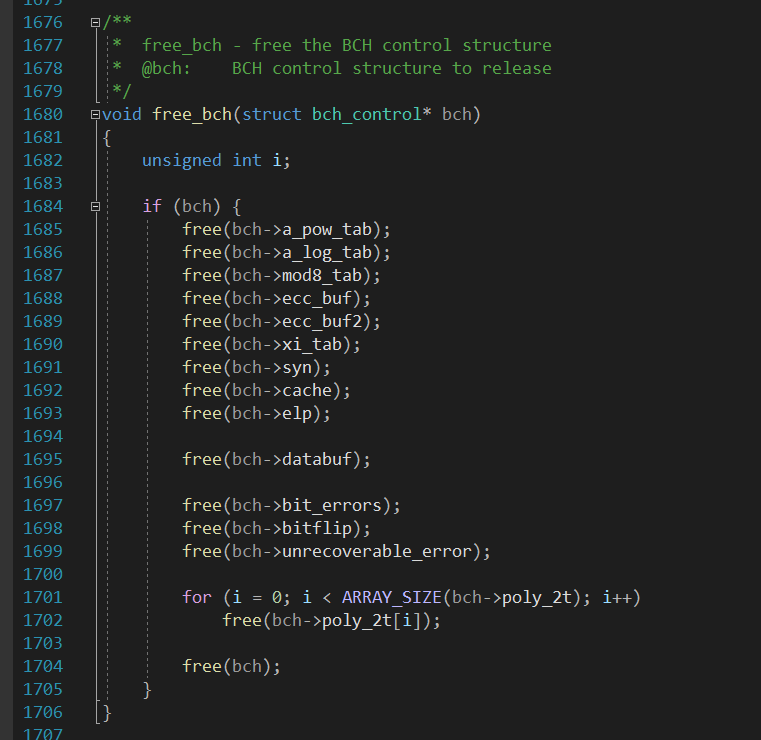
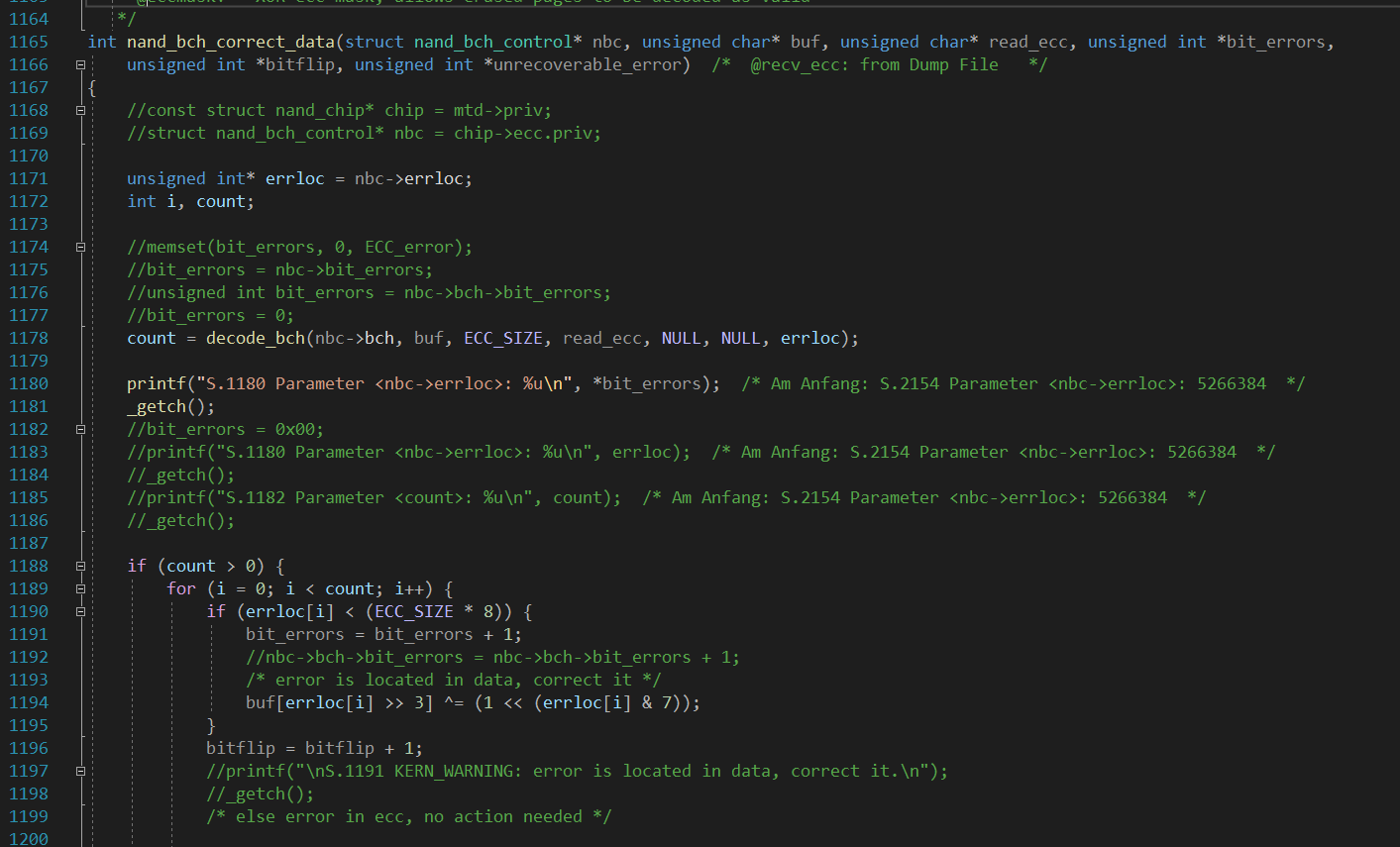
Hallo zusammen, nun habe ich ein sehr großes Problem mit C. Seit 3 Tagen bekomme ich es nicht hin, dass der Fehlerzähler (von mir neu erstellt) in der Funktion "int nand_bch_calculate_ecc" seine Werte nach <main> liefert. Ich habe schon viel ausprobiert. Die Werte von <main> werden nach "int nand_bch_calculate_ecc" geleitet, dort wird es geändert: z.B. bit_errors = bit_errors + 1; oder so nbc->bch->bit_errors = nbc->bch->bit_errors + 1;. Zurück zu <main> geänderter Wert kommt nicht an. Von "main" gebe ich die Werte an Funktion so: nand_bch_correct_data(nbch2, buf_data, buf_ecc, &bit_errors, &bitflip, &unrecoverable_error); Ich habe auch an der Funktion mit int nand_bch_correct_data(struct nand_bch_control* nbc,......... und auch void nand_bch_correct_data(struct nand_bch_control* nbc, probiert, geht nicht. Jetzt habe ich eine Frage zu den Zeilen im Code: 1. struct nand_bch_control *nbc = NULL; - Warum wird es auf Null gesetzt? 2. Wie ist die Rückgabe geänderter Werte im Code realisiert, standardmäßig weg oder gibt es Besonderheiten? Die Code die ich in Bearbeitung habe stammt von hier: https://github.com/merbanan/ltq-nand Es wäre schön, wenn sich das jemand ansehen und mir die Richtung zeigen könnte) Vielen Dank im Voraus.
Hänge Deinen Code als Code an, NICHT ALS SCREENSHOTS!
Gerade noch mal probiert und Wunder geschehen) Mit Sternchen funktioniert es nun auch) *bit_errors = *bit_errors + 1; Nur mir bleib ein Rätsel immer noch, wie die Änderungweitergabe realisiert, weil da geht es ohne Sternchen) Danke nochmal!
Wenn Du tatsächlich willst, daß man Dir hilft und Deine Fragen beantwortet: HÄNGE DEINEN QUELLTEXT ALS CODE AN, NICHT ALS SCREENSHOT! Ist das so irrsinnig schwer zu kapieren?
Jük P. schrieb: > Nur mir bleib ein Rätsel immer noch, wie die Änderungweitergabe > realisiert, weil da geht es ohne Sternchen) Vor dem Laufen kommt das Gehen. Du übst allerdings noch Sitzen... Jük P. schrieb: > Es wäre schön, wenn sich das jemand ansehen und mir die Richtung zeigen > könnte) Ein Buch, das dir die grundlegensten Dinge der Programmiersprache C nahebringt. Es nutzt nichts, per trial and error wird das nichts. Oliver
Moin, Jük P. schrieb: > Nur mir bleib ein Rätsel immer noch, wie die Änderungweitergabe > realisiert, weil da geht es ohne Sternchen) Sowas kann nur durch schwarze Magie passieren. Weiche von mir, Daemon! scnr, WK
Angehängte Dateien:
-

20241210_111358.png
2,6 MB
{kind=link}
Ich habe zur Zeit 3 Bücher für c. Die 2 auf dem Bild und das dritte zu Hause. Gibt es noch bessere? Was gestern passiert ist, ist eigentlich das Gegenteil von dem, was in den Büchern steht, deswegen hat es so lange gedauert. Und erst als ich den Code ganz tief angeschaut habe, habe ich gesehen, auf welche Weise die Änderung stattfindet). Wie gesagt, ich bringe mir selbst c)). Hatte bis vor ca. 6 Monaten nichts damit zu tun. Vieles ist im Internet zu finden, dauert etwas länger und nur in neuen Bereichen wo keine Erfahrung dann schwierig. Weil keiner fragen kann..... Ich denke aber es wird langsam) Ich brauche nur einen speziellen Bereich. Danke!
Jük P. schrieb: > 20241210_111358.png 2,6 MB Das ist ein banales Foto. Statt des tollen weißen Handtuchs und den um 90° gedrehten Büchern hätte das hier völlig genügt: "K&R, Pogrammieren in C, zweite Ausgabe" und "Erlenkötter, C Programmieren von Anfang an". Seufz.
Vielen Dank! Es wird ein sehr schönes Weihnachtsgeschenk)
Hier riecht es streng. Nach Troll.
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.