Ich logge verschiedene Daten von verschiedenen "Rechnern" auf eine Volkszähler-Instanz bei einem Webhoster seit ca. 3 Tagen gibt es Probleme, aber nur bei manchen Rechnern: Raspi 1: curl meinedomain.de --> funktioniert Raspi 2: curl meinedomain.de --> funktioniert Debian in einem Proxmox-Container: curl meinedomain.de --> Failed to connect to meinedomain.de port 80: Verbindungsaufbau abgelehnt Andere Linux-Installation auf der selben Proxmox-Maschine: funktioniert einwandfrei Ein ESP32 mit ESPEasy hat auch plötzlich Probleme - bei anderen ESPEasy-Installationen läuft es problemlos Ca. jede Stunde funktioniert es kurz - siehe Screenshot Das ganze hat bis vor 3 Tagen über Jahre problemlos funktioniert, ich habe nichts geändert Die Fritzbox zeigt auch nichts auffälliges im Log Hat evtl. jemand eine Idee wie ich den Fehler am Besten eingrenze?
Heinz R. schrieb: > seit ca. 3 Tagen gibt es Probleme, aber nur bei manchen Rechnern: > > Raspi 1: curl meinedomain.de --> funktioniert > Raspi 2: curl meinedomain.de --> funktioniert > > Debian in einem Proxmox-Container: curl meinedomain.de --> Failed to > connect to meinedomain.de port 80: Verbindungsaufbau abgelehnt Ist Dein "Proxmox-Container" eine virtuelle Maschine oder ein richtiger Container (Docker, LXC, Podman, ...)? Läuft etwas in diesem Container, das auf Port 80 lauscht, also ein Apache, Nginx, Caddy oder anderer Webserver / Proxy? > Andere Linux-Installation auf der selben Proxmox-Maschine: funktioniert > einwandfrei Hm, okay. > Ca. jede Stunde funktioniert es kurz - siehe Screenshot > Das ganze hat bis vor 3 Tagen über Jahre problemlos funktioniert, ich > habe nichts geändert Laufen da vielleicht cron-apt oder unattended-upgrades oder etwas in der Art? > Hat evtl. jemand eine Idee wie ich den Fehler am Besten eingrenze? Was sagen die Logs? Was siehst Du, wenn Du in die VM oder den Container gehst und dort mit ps(1) schaust, welche Prozesse laufen?
> siehe Screenshot
kann ich leider nicht sehen
Vermutung: DNS Auflösung schlägt fehl
Fehlersuche: curl-Aufruf mit strace kapseln.
Peter schrieb: > Vermutung: DNS Auflösung schlägt fehl Da gibt curl einen anderen Fehler aus. Erst mal mit ping die Verbindung prüfen, in der Reihenfolge Interface, Gateway, Server.
Peter schrieb: > Vermutung: DNS Auflösung schlägt fehl Bei der Fehlerbeschreibung? Unwahrscheinlich. > Fehlersuche: curl-Aufruf mit strace kapseln. Dann sieht er die Systembefehle, die curl(1) aufruft. Das hilft vermutlich nicht sonderlich viel weiter.
Angehängte Dateien:
-

Zwischenablage_10-16-2024_01.jpg
110 KB -

Zwischenablage_10-16-2024_02.jpg
150 KB -

Screenshot3.jpg
120 KB
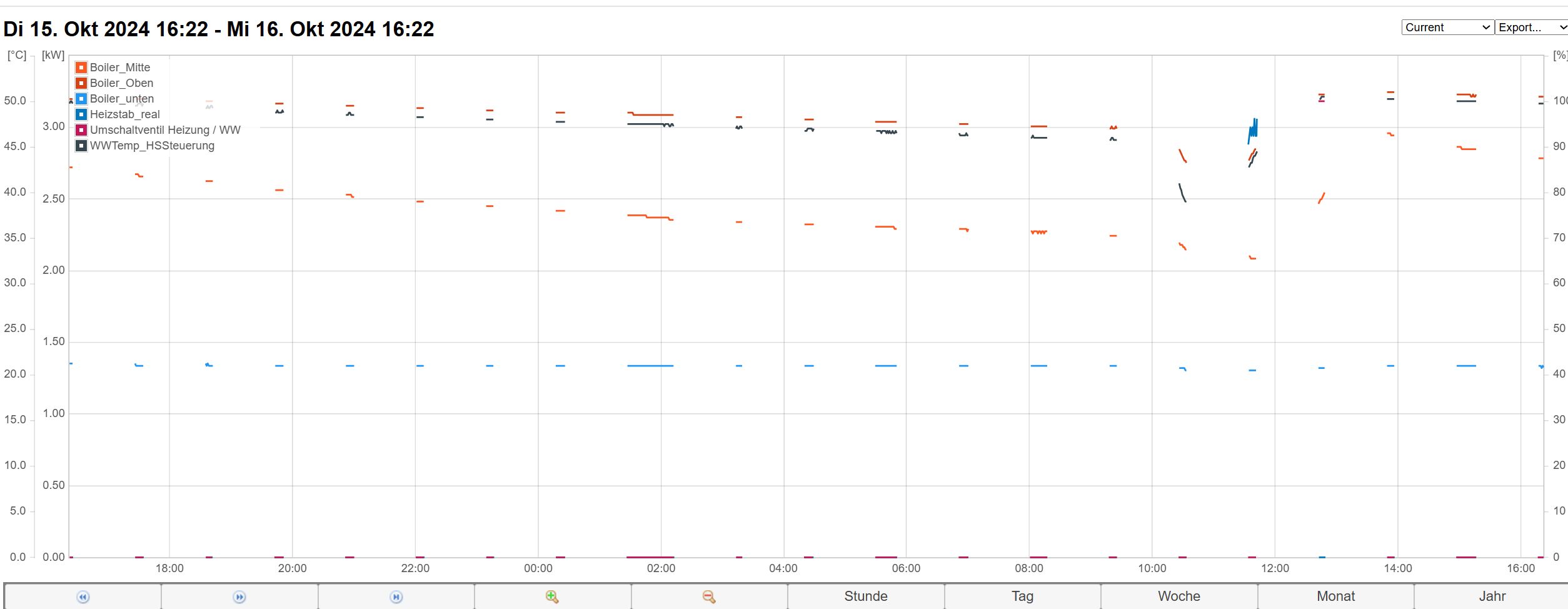
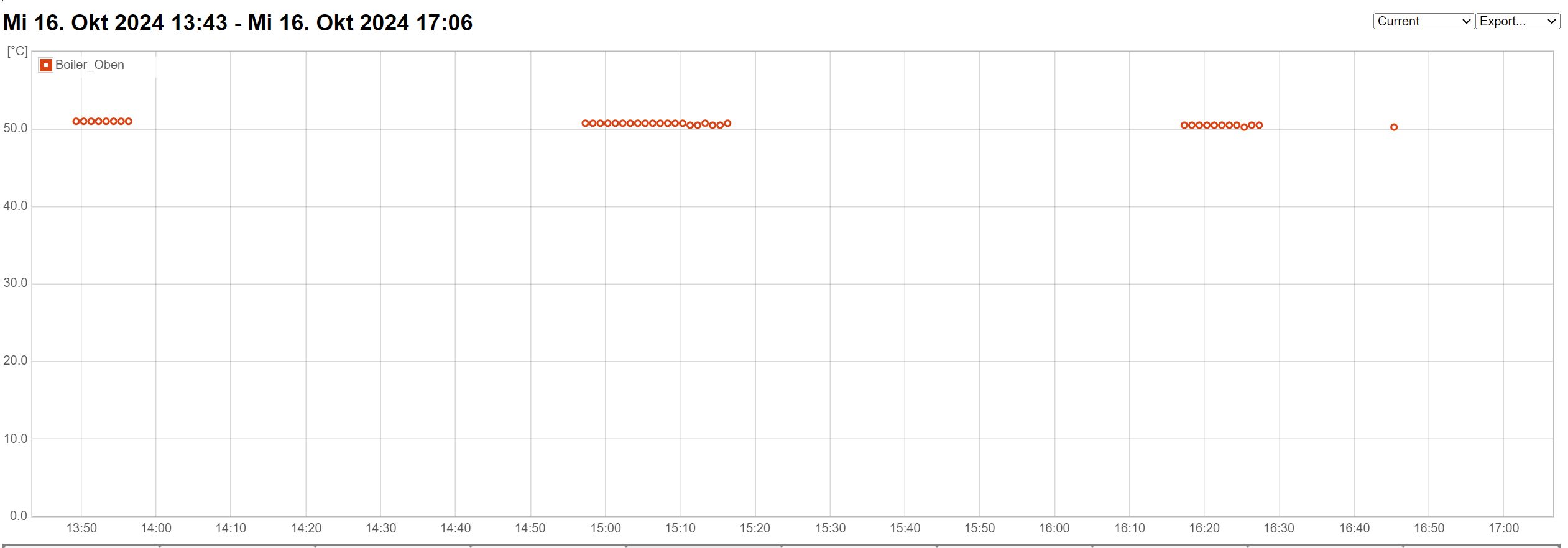
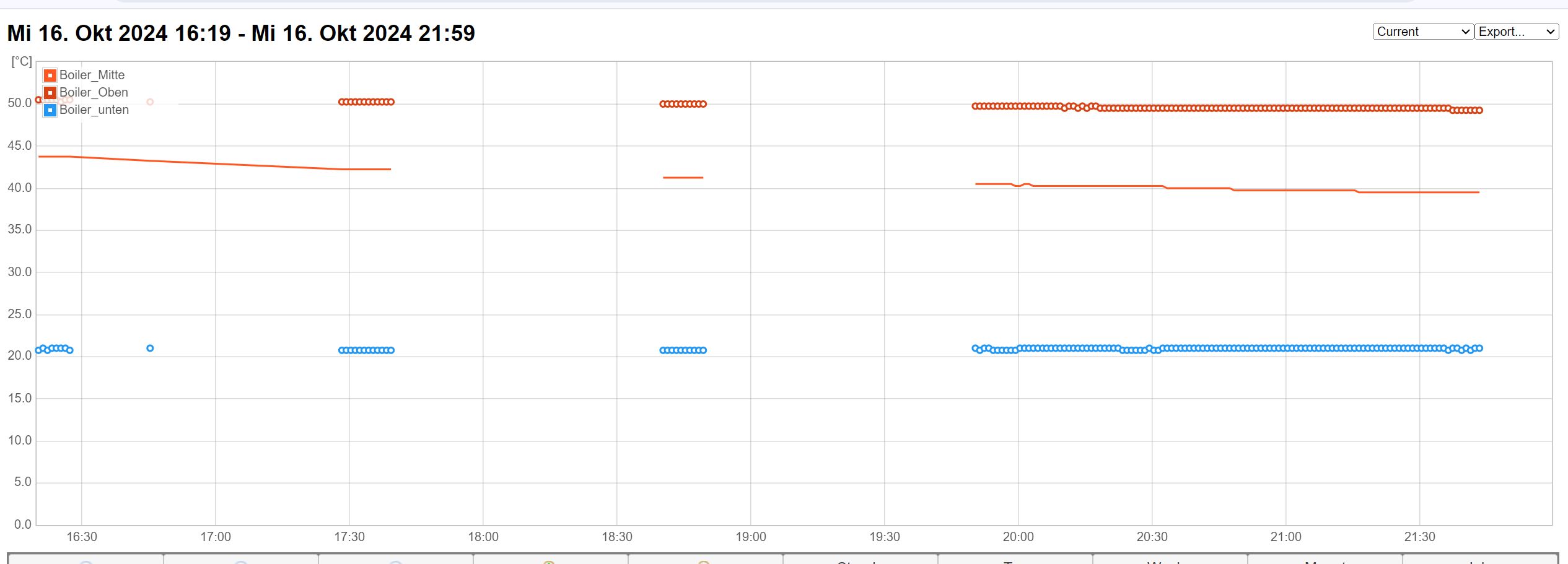
Peter schrieb: >> siehe Screenshot > kann ich leider nicht sehen sorry, vergessen - jetzt anbei Man sieht im 2. Screenshot wie es am 11.10. um ca. 16:20 Uhr anfing Ein T. schrieb: > Ist Dein "Proxmox-Container" eine virtuelle Maschine oder ein richtiger > Container Es läuft eine virtuelle Maschine ich werde heute Abend den diversen Tipps hier mal nachgehen Was ich aber bereits sagen kann: Ein ping zur gewünschten Adresse funktioniert auf der betroffenen virtuellen Maschine problemlos interessant finde ich screenshot03: die rote Linie mit Aussetzern kommt vom Debian auf der virtuellen Maschine die blaue Linie mit Aussetzern vom ESP32 der direkt zum Webhoster loggt Die grüne Linie von einem weiteren Raspberry Auffällig, kommt bei rot / blau was an dann immer zur gleichen Zeit Die Zeitspanne in der es funktioniert ist ungleichmäßig Aber die Zeit vom Aussetzen bis zum wieder funktionieren immer ca. 60 Minuten
Firewall/IDS/DenialOfService-Protection beim Hoster? Zuviele Requests von derselben IP?
Gibt es einen Unterschied, wie der grün loggende Raspi in Deinem Netzwerk eingebunden ist? Beschreibe doch die lokale Netzkonfiguration. Sind alle Instanzen per WLAN im Netz, wenn ja, über denselben Access-Point? Die Stunde Sperre sieht tatsächlich ein wenig so wie ein IDS/Fail2ban etc. aus. Warum ist dann aber der "grüne" nicht betroffen? Wie oft connected curl pro Stunde? Ist der Rhytmus bei allen gleich? Sinnvoll dürfte ein capture auf der Fritzbox sein: http://fritz.box/#cap Dort auf dem WAN Interface per Filter den Traffik vom/zum Webhoster mitschneiden. Dann sollte man dann mittels wireshark sehen, ob die curl-Aufrufe - rejected werden (icmp bzw. rst) - gedroppt werden (keinerlei Antwort Paket) - oder der 3-way handshake gelingt, und die Verbindung dann abbricht. Welche Möglichkeiten/Rechte hast Du bei Deinem Hoster? Interessant könnten hier ja auch die Logs des Webservers sein: - Gibt es ggf. DOS-Zugriffe auf den Webserver, der beim Hoster ein IDS triggern könnte? - Wieviele Aufrufe/Zeiteinheit kommen in der einstündigen Pause durch, wieviele danach?
Angehängte Dateien:
-

Zwischenablage02.jpg
460 KB -

Zwischenablage03.jpg
90 KB
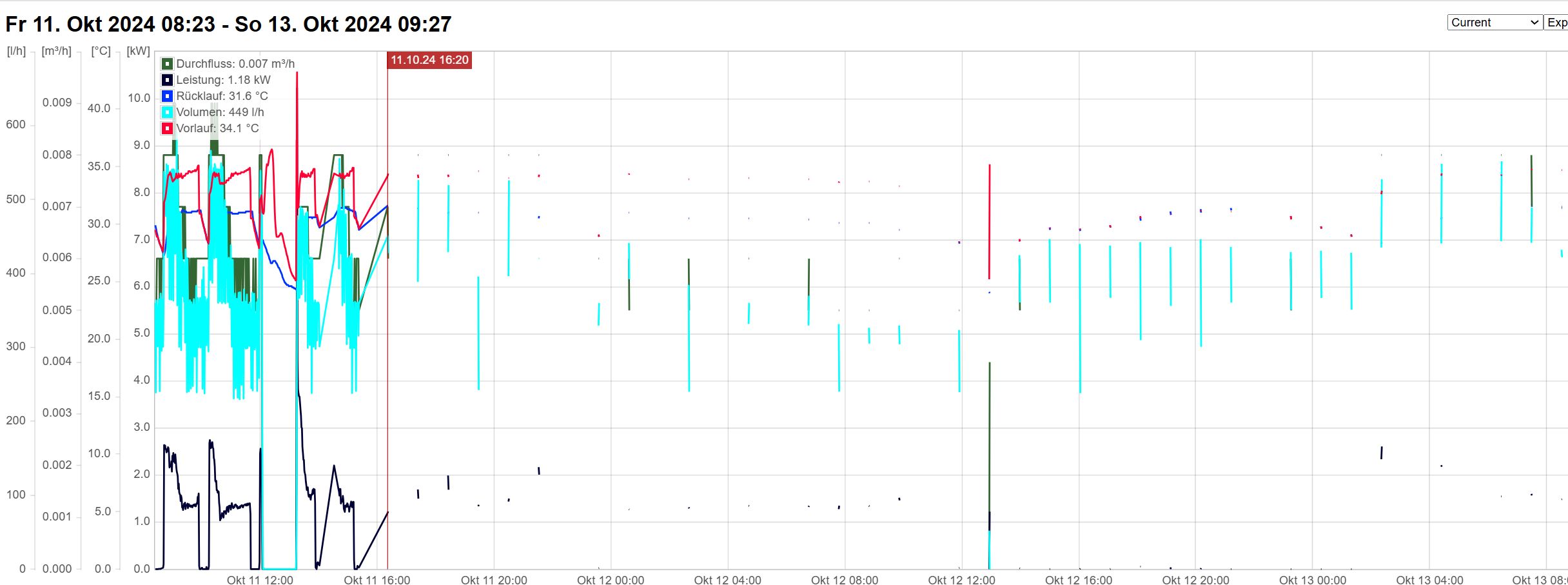
Peter schrieb: > Gibt es einen Unterschied, wie der grün loggende Raspi in Deinem > Netzwerk eingebunden ist? > Beschreibe doch die lokale Netzkonfiguration. Sind alle Instanzen per > WLAN im Netz, wenn ja, über denselben Access-Point? der grün loggende Raspi geht über einen GBit-Switch an die Fritzbox, der Proxmox-Server (rot) direkt per LAN an die Fritzbox, der ESP32 (blau) über eine Ubiquity-Wifi-Installation die an der Fritzbox hängt Peter schrieb: > Die Stunde Sperre sieht tatsächlich ein wenig so wie ein IDS/Fail2ban > etc. aus. Warum ist dann aber der "grüne" nicht betroffen? > > Wie oft connected curl pro Stunde? Ist der Rhytmus bei allen gleich? die Werte werden im Abstand von 1 bis 5 Minuten geloggt Es gibt noch viel mehr Werte, über 100 Stück - siehe Screenshot :-) Es ist nur die eine Debian-Installation die ca. 20 Werte loggt und ein ESP32 mit ca. 5 Wertenbetroffen Der andere Raspi macht weiterhin problemlos ca. 60 Werte, weitere ESP8266 / ESP32 ca. 20 Werte Peter schrieb: > Sinnvoll dürfte ein capture auf der Fritzbox sein: das werde ich später mal versuchen - ich suche erst mal ob es weitere Unterschiede gibt Peter schrieb: > Welche Möglichkeiten/Rechte hast Du bei Deinem Hoster? fast keine , ich finde kein Log Peter schrieb: > - Wieviele Aufrufe/Zeiteinheit kommen in der einstündigen Pause durch, > wieviele danach? sehr viele, Zwischenablage3 ist einer der betroffenen Kanäle, auf Einzelpunkte umgestellt - jeder Punkt ein Messwert
Heinz R. schrieb: > Es gibt noch viel mehr Werte, über 100 Stück - siehe Screenshot :-) > Es ist nur die eine Debian-Installation die ca. 20 Werte loggt und ein > ESP32 mit ca. 5 Wertenbetroffen Wenn diverse Clients zeitgleich den Server mit hunderten von Requests bombardieren, kann es passieren, dass die SYN-Queue überläuft und der Server mit RSTs antwortet. Würde man im Kernel-Log des Servers sehen, aber wenn Du da nicht rankommst, sieht's natürlich schlecht aus. Peter schrieb: > Dann sollte man dann mittels wireshark sehen, ob die curl-Aufrufe > - rejected werden (icmp bzw. rst) > - gedroppt werden (keinerlei Antwort Paket) > - oder der 3-way handshake gelingt, und die Verbindung dann abbricht. "Verbindungsaufbau abgelehnt" dürfte die deutsche Verunglimpfung von "Connection refused" sein, also RST. Entweder wegen voller Queue (s.o.) oder weil nichts auf dem Port lauscht (hier unwahrscheinlich).
Hmmm schrieb: > Wenn diverse Clients zeitgleich den Server mit hunderten von Requests > bombardieren, kann es passieren, dass die SYN-Queue überläuft und der > Server mit RSTs antwortet. nein, es muss ein anderes Problem sein Ich habe gerade festgestellt das auch weitere ESPEasy Sensoren betroffen sind Ich gebe hier mal eine meiner Domains preis, ist ja nichts so geheimes: Auf Rasperi 1 - curl kr123.de - Antwort: <!DOCTYPE html> <html lang="de"> <head> <meta charset="utf-8"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <title>Hier entsteht eine neue Webseite.</title> <style>.... scheint zu funktionieren jetzt das ganze auf Raspi2, oder auch einer virtuellen Maschine: curl kr123.de Antwort: curl: (7) Failed to connect to kr123.de port 80: Verbindungsaufbau abgelehnt Aber jede Stunde geht es wieder für paar Minuten - so wie jetzt gerade
Heinz R. schrieb: > jetzt das ganze auf Raspi2, oder auch einer virtuellen Maschine: > curl kr123.de > Antwort: > curl: (7) Failed to connect to kr123.de port 80: Verbindungsaufbau > abgelehnt Lass mal nebenbei auf dem RPi tcpdump mitlaufen: tcpdump -n port 80
Hmmm schrieb: > > "Verbindungsaufbau abgelehnt" dürfte die deutsche Verunglimpfung von > "Connection refused" sein, also RST. Entweder wegen voller Queue (s.o.) > oder weil nichts auf dem Port lauscht (hier unwahrscheinlich). Das passt nicht so recht zu der jeweils einstündigen Pause nach Verbindungsabbruch. Wenn das nur ein Queue-Problem ist, dann nicht so synchron und mit jeweils einer Stunde Reset. Da spielt noch jemand mit. Heinz R. schrieb: > Ich gebe hier mal eine meiner Domains preis, ist ja nichts so geheimes: Der Aussage nach entnehme ich, dass Du gegen mehrer Domains loggst. Ist von dem Fehler nur Eine betroffen? Hast Du den CURL-Aufruf z.B. über eine mobile Verbindung versucht, wenn es wieder mal klemmt?
Auch noch ein beliebter Fehler: Mehrere DHCP-Server im Netz die unterschiedliche Gateways verkünden.
Peter schrieb: > Der Aussage nach entnehme ich, dass Du gegen mehrer Domains loggst. Ist > von dem Fehler nur Eine betroffen? viel schlimmer - ja, ich logge auf mehrere Subdomains Problem ist hier eine die nicht so recht will , der Rest funktioniert Und diese eine halt auch nur von manchen Clients nicht - bzw. seit Samstag nicht mehr Peter schrieb: > Hast Du den CURL-Aufruf z.B. über eine mobile Verbindung versucht, wenn > es wieder mal klemmt? Das ist schwer zu realisieren - ich müsste dann meinen Raspi ins mobile Netz bringen Denke auch nicht das es daran liegt, es geht ja von einem anderen Raspi im gleichen Heimnetz problemlos Ich denke entweder hat der Provider (Netcup) irgendwas umgestellt - oder irgend ein Update der Fritzbox
1N 4. schrieb: > Auch noch ein beliebter Fehler: Mehrere DHCP-Server im Netz die > unterschiedliche Gateways verkünden. Die Diode ist wieder da :-) Nein, daran liegt es sicher nicht Auf dem Raspi wo ein "curl kr123.de" abgelehnt wird funktioniert ein "ping kr123.de" einwandfrei aktuell läuft es übrigens seit 19:50 Uhr wieder problemlos - ohne das ich was geändert habe Mal schauen wie lange...
> Auf dem Raspi wo ein "curl kr123.de" abgelehnt wird funktioniert ein > "ping kr123.de" einwandfrei Ok, dann scheidet ein Fehler auf IP-Ebene aus. Kindersicherung auf der Fritzbox aktiv? Irgendwelche Infos aus dem Logfile des Webservers? Laufen darauf noch weitere Dienste, die zu dem Zeitpunkt ebenfalls nicht erreichbar sind?
Heinz R. schrieb: > ja, ich logge auf mehrere Subdomains > Problem ist hier eine die nicht so recht will , der Rest funktioniert Landen die alle auf derselben Server-IP? Wenn ja, ist es noch seltsamer, denn die Verbindungen sehen für alle Hosts gleich aus, die Unterscheidung passiert erst im HTTP-Header. Stimmen die DNS-Einträge? Wenn Du z.B. mehrere A-Records hast, würde das erklären, warum es mal geht (richtige IP-Adresse erwischt) und mal nicht (falsche IP-Adresse, die auf einen Server zeigt, der nicht auf Port 80 lauscht).
Angehängte Dateien:
-

Zwischenablage04.jpg
120 KB
merkwürdig, es hat jetzt 2 Stunden funktioniert - jetzt wieder nicht mehr Ich habe mal im Netcup-Forum geschrieben, mal schauen ob ich eine ANtwort erhalte sonst schreibe ich morgen mal an den Support Eigentlich kann es nur an denen liegen? Gab es irgendein Update von Curl?
Sind die DNS Server für die zone synchron?
netcup ist eigentlich recht zuverlässig. Was sagt der Support von denen? Der Umstieg vom Hosting auf einen virtuellen Server kostet kaum mehr, bringt aber alle Möglichkeiten, solche Dinge auch von der Serverseite zu debuggen. Eine Sache, die ich nun ausprobieren würde: Den curl-Aufruf von der Maschine, die Fehler bekommt, per ssh über eine funktionierende Maschine aufrufen. Ich gehe davon aus, dass Deine Messdaten alle in der URL stecken. Dann sollte statt: curl kr123.de/data... so aussehen: ssh raspi1 "curl kr123.de/data..." Wenn das dann funktionieren sollte, die curl-Versionen vergleichen. Eventuell werden unterschiedliche Header gesetzt, die das Fingerprinting eine IDS/IPS triggern oder auch nicht. Hier würde natürlich auch das capture-file von der Fritzbox helfen, wenn man die Requests vergleichen kann. Die Stunde Sperre riecht eben verdammt nach IDS/IPS.
Peter schrieb: > netcup ist eigentlich recht zuverlässig. Was sagt der Support von denen? > Der Umstieg vom Hosting auf einen virtuellen Server kostet kaum mehr, > bringt aber alle Möglichkeiten, solche Dinge auch von der Serverseite zu > debuggen. ja, ich wollte schon lange umsteigen, vielleicht finde ich über Weihnachten die Zeit ich komme merkwürdigerweise auch per SSH nicht von der funktionierenden Maschine auf die nicht funktionierende - andersrum geht es Mich würde interessieren: funktioniert bei Euch da draußen ein curl kr123.de ? Bitte gebt falls ihr es versucht auch die Uhrzeit mit an
> Mich würde interessieren: funktioniert bei Euch da draußen ein curl > kr123.de ? Ja, gerade eben. Du kommst mit ssh nicht innerhalb deines Netzes von einer auf die andere Maschine? Aber mit ping geht es?
1N 4. schrieb: > Du kommst mit ssh nicht innerhalb deines Netzes von einer auf die andere > Maschine? Aber mit ping geht es? ich komme als User X mit Passwort Y per Putty auf beide Maschinen Von Maschine A komme ich mit User X Passwort Y auf Maschine B Aber ich komme per SSH nicht von Maschine B auf Maschine A - merkwürdig, aber wohl ein anderes Problem
> Aber ich komme per SSH nicht von Maschine B auf Maschine A - merkwürdig, > aber wohl ein anderes Problem Nur seltsam, dass es dabei diejenige ist, die auch mit curl Probleme hat? BTW: Wed Oct 16 10:57:15 PM CEST 2024: http://kr123.de is working Wed Oct 16 10:58:15 PM CEST 2024: http://kr123.de is working Wed Oct 16 10:59:16 PM CEST 2024: http://kr123.de is working Wed Oct 16 11:00:16 PM CEST 2024: http://kr123.de is working Wed Oct 16 11:01:16 PM CEST 2024: http://kr123.de is working Wed Oct 16 11:02:16 PM CEST 2024: http://kr123.de is working Wed Oct 16 11:03:16 PM CEST 2024: http://kr123.de is working Wed Oct 16 11:04:16 PM CEST 2024: http://kr123.de is working Wed Oct 16 11:05:16 PM CEST 2024: http://kr123.de is working Wed Oct 16 11:06:16 PM CEST 2024: http://kr123.de is working Wed Oct 16 11:07:16 PM CEST 2024: http://kr123.de is working Wed Oct 16 11:08:16 PM CEST 2024: http://kr123.de is working Wed Oct 16 11:09:16 PM CEST 2024: http://kr123.de is working Wed Oct 16 11:10:16 PM CEST 2024: http://kr123.de is working Wed Oct 16 11:11:16 PM CEST 2024: http://kr123.de is working
1N 4. schrieb: > Nur seltsam, dass es dabei diejenige ist, die auch mit curl Probleme > hat? ja, sehr seltsam Aber um so seltsamer das auch die ESPxx exakt seit dem gleichen Zeitpunkt Probleme haben - und exakt zum gleichen Zeitpunkt für paar Minuten funktionieren
Heinz R. schrieb: > Ich logge verschiedene Daten von verschiedenen "Rechnern" auf eine > Volkszähler-Instanz bei einem Webhoster sudo traceroute -T -p 80 meinedomain.de
> Aber um so seltsamer das auch die ESPxx exakt seit dem gleichen > Zeitpunkt Probleme haben - und exakt zum gleichen Zeitpunkt für paar > Minuten funktionieren Dann mach doch mal nach dem curl auf deine Webhoster-URL ein curl auf die Fritte und evtl. noch ein curl auf eine andere URL (google.com oder so)
G. K. schrieb: > sudo traceroute -T -p 80 meinedomain.de bringt auf dem nicht funktionierenden Raspi: root@Dell-Server:/var/kr/waermezaehler# sudo traceroute -T -p 80 kr123.de traceroute to kr123.de (188.68.47.69), 30 hops max, 60 byte packets 1 fritz.box (192.168.178.1) 0.218 ms 0.299 ms 0.325 ms 2 * 3 ip-081-210-144-002.um21.pools.vodafone-ip.de (81.210.144.2) 38.180 ms 37.202 ms 38.175 ms 4 de-str01c-rc1-ae-46-0.aorta.net (84.116.197.133) 35.650 ms 37.016 ms 36.989 ms 5 de-fra04d-rc1-ae-10-0.aorta.net (84.116.140.205) 37.106 ms 37.107 ms 37.103 ms 6 84.116.190.94 (84.116.190.94) 36.990 ms 33.252 ms 33.206 ms 7 80.81.192.68 (80.81.192.68) 33.217 ms 17.029 ms ae3-1337.bbr02.anx25.fra.de.anexia-it.net (80.81.195.166) 23.078 ms 8 ae1-0.bbr01.anx84.nue.de.anexia-it.net (144.208.208.140) 27.703 ms ae1-0.bbr02.anx25.fra.de.anexia-it.net (144.208.208.149) 27.577 ms ae1-0.bbr01.anx84.nue.de.anexia-it.net (144.208.208.140) 27.667 ms 9 ae1-0.bbr01.anx84.nue.de.anexia-it.net (144.208.208.140) 28.647 ms 28.658 ms 28.648 ms 10 a2f45.netcup.net (188.68.47.69) 27.578 ms 27.530 ms 94.16.25.155 (94.16.25.155) 25.972 ms
1N 4. schrieb: > Dann mach doch mal nach dem curl auf deine Webhoster-URL ein curl auf > die Fritte und evtl. noch ein curl auf eine andere URL (google.com oder > so) das funktioniert alles, auch zu diversen Webseiten, selbst zu netcup.de, aber halt nicht zu meinem Webspace bei Netcup
> das funktioniert alles, auch zu diversen Webseiten, selbst zu netcup.de, > aber halt nicht zu meinem Webspace bei Netcup Zu den gleichen Zeiten? Dann würde ich mal bei Netcup vorsprechen.
1N 4. schrieb: >> das funktioniert alles, auch zu diversen Webseiten, selbst zu > netcup.de, >> aber halt nicht zu meinem Webspace bei Netcup > > Zu den gleichen Zeiten? Dann würde ich mal bei Netcup vorsprechen. ja, gerade eben versucht - ich komme per curl überall hin - nur halt nicht zu keiner meiner 4 Domains Aber halt auch nur von 2 meiner 3 Raspis, am 3. funktioniert es problemlos Auch an 2 PCs funktioniert es einwandfrei Und wie gesagt, es geht seit Samstag nicht mehr, ohne das ich was geändert habe
Angehängte Dateien:
-

Netzzwerg_1.png
11 KB
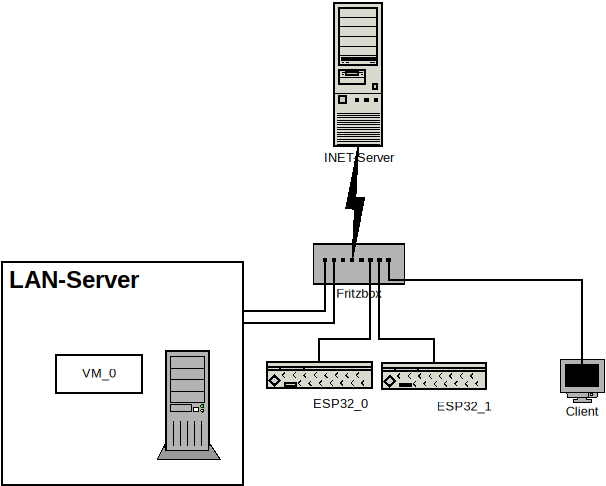
Heinz R. schrieb: > ich komme merkwürdigerweise auch per SSH nicht von der funktionierenden > Maschine auf die nicht funktionierende - andersrum geht es Ich würde zunächst erst einmal die Default-Routen der betreffenden Maschinen sowie deren DNS-Auflösungen checken. Und mal ins Blaue gefragt: wie lang ist eigentlich die Leasetime Deines DHCP-Servers? Möchtest Du vielleicht einmal ein anschauliches Bildchen Deines Netzwerks malen? Mit Dia geht das recht einfach, und die Software läuft unter Linux, Windows und MacOS, bei Ubuntu gibt es dafür sogar ein Distributionspaket. Im Anhang habe ich mal skizziert, wie ich Dein Netzwerk verstanden habe, und Bezeichner für die beteiligten Komponenten vergeben. Kommt das so etwa hin? [1] http://dia-installer.de/ > Mich würde interessieren: funktioniert bei Euch da draußen ein curl > kr123.de ? Do 17. Okt 11:30:23 CEST 2024: funktioniert. Edit: Anhänge hinzugefügt.
Ein T. schrieb: > Im Anhang habe ich mal skizziert, wie ich Dein Netzwerk verstanden habe, > und Bezeichner für die beteiligten Komponenten vergeben. Kommt das so > etwa hin? ja, genau so sieht es aus - einzig, es gibt noch Raspis die genau wie die ESPxx angebunden sind Ich hatte im Netcup-Forum auch mal angefragt es wurde ein Traceroute empfohlen: (am nicht funktionierenden Rechner ausgeführt) tcptraceroute kr123.de 80 Running: traceroute -T -O info -p 80 kr123.de traceroute to kr123.de (188.68.47.69), 30 hops max, 60 byte packets 1 fritz.box (192.168.178.1) 0.269 ms 0.261 ms 2.605 ms 2 * 3 ip-081-210-144-002.um21.pools.vodafone-ip.de (81.210.144.2) 16.306 ms 17.465 ms 17.455 ms 4 de-str01c-rc1-ae-46-0.aorta.net (84.116.197.133) 22.685 ms 22.671 ms 22.658 ms 5 de-fra04d-rc1-ae-10-0.aorta.net (84.116.140.205) 23.629 ms 23.634 ms 22.619 ms 6 84.116.190.94 (84.116.190.94) 22.561 ms 20.223 ms 20.187 ms 7 80.81.192.68 (80.81.192.68) 21.195 ms ae3-1337.bbr02.anx25.fra.de.anexia-it.net (80.81.195.166) 18.972 ms 17.809 ms 8 ae1-0.bbr02.anx25.fra.de.anexia-it.net (144.208.208.149) 21.884 ms 21.496 ms 22.567 ms 9 ae1-0.bbr01.anx84.nue.de.anexia-it.net (144.208.208.140) 22.591 ms 22.580 ms 22.564 ms 10 94.16.25.155 (94.16.25.155) 26.783 ms a2f45.netcup.net (188.68.47.69) 26.770 ms 94.16.25.155 (94.16.25.155) 25.904 ms Es sieht für mich danach aus das die Anfrage mein Haus verlässt, auch bei Netcup ankommt?
Heinz R. schrieb: > Von Maschine A komme ich mit User X Passwort Y auf Maschine B > > Aber ich komme per SSH nicht von Maschine B auf Maschine A - merkwürdig, > aber wohl ein anderes Problem Ist bei Dir in der Fritzbox WLAN/Sicherheit "Aktive WLAN-Geräte dürfen untereinander kommunizieren" aktiv?
Peter schrieb: > Ist bei Dir in der Fritzbox WLAN/Sicherheit > "Aktive WLAN-Geräte dürfen untereinander kommunizieren" aktiv? Dann würde es in beiden Richtungen nicht funktionieren. Außerdem ist nur der ESP im WLAN. Heinz R. schrieb: > der grün loggende Raspi geht über einen GBit-Switch an die Fritzbox, der > Proxmox-Server (rot) direkt per LAN an die Fritzbox, der ESP32 (blau) > über eine Ubiquity-Wifi-Installation die an der Fritzbox hängt
Heinz R. schrieb: > 9 ae1-0.bbr01.anx84.nue.de.anexia-it.net (144.208.208.140) 22.591 ms > 22.580 ms 22.564 ms > 10 94.16.25.155 (94.16.25.155) 26.783 ms a2f45.netcup.net > (188.68.47.69) 26.770 ms 94.16.25.155 (94.16.25.155) 25.904 ms > > Es sieht für mich danach aus das die Anfrage mein Haus verlässt, auch > bei Netcup ankommt? Ja, allerdings sieht der letzte Hop merkwürdig aus. Von den 3 gesendeten Paketen wurde nur das zweite von Deinem Server (188.68.47.69) beantwortet, das erste und dritte wiederum von einer Adresse, die zu Anexia gehört (94.16.25.155). Das kann harmlos sein (z.B. irgendein Balancing, durch das die Route mal einen Hop länger, mal einen Hop kürzer ist), aber auch auf ein Routingproblem bei Deinem Hoster hindeuten. Am besten sprichst Du mal mit dem Netcup-Support.
Hmmm schrieb: > Am besten sprichst Du mal mit dem Netcup-Support. ja, das mache ich gerade zuerst haben sie angemerkt das sie für meine Probleme nicht zuständig sind - nur für eigene Dienste helfen können, nichts mit meinem Screenshot mit den Temperaturen anfangen können Ich habe es noch mal erklärt - direkt gefragt ob es letzten Freitag eine Änderung gab Antwort: Ja, es gab Änderungen unserer Sicherheits-Infrastruktur. Es ist allerdings noch nicht ganz klar, ob dies der Auslöser für diese Ausfälle ist. sie forschen jetzt Hat zufällig einer von Euch ESPEasy am laufen? Ich habe hier nachgeforscht - kein einziger meiner direkt an Volkszähler loggenden ESPEasy-Sensoren kommt noch durch
> Ich habe hier nachgeforscht - kein einziger meiner direkt an Volkszähler > loggenden ESPEasy-Sensoren kommt noch durch Na, das ist doch schonmal ein Indiz, dass da evtl. der http-GET/POST von ESPEasy nicht so ganz standardkonform sein könnte.
1N 4. schrieb: > Na, das ist doch schonmal ein Indiz, dass da evtl. der http-GET/POST von > ESPEasy nicht so ganz standardkonform sein könnte auf einem Debian-System unter Proxmox geht es auch nicht mehr Aber wer definiert den Standard? Klar, Netcup "verdient" 6€ pro Monat an mir, Peanuts Aber falls sie damit ankommen das meine Installation nicht Standartkonform ist - was wird passieren? Vertrag wird gekündigt, gut ist
> Aber wer definiert den Standard? Vermutlich der: https://de.wikipedia.org/wiki/RFC-Editor Es scheint ja eine gewisse Client-Abhängigkeit gegeben zu sein. Die interne IP-Adresse kann der Hoster dank NAT ja nicht zuordnen, also bleiben nur die höheren Schichten.
1N 4. schrieb: > Vermutlich der: > https://de.wikipedia.org/wiki/RFC-Editor naja, es lief jetzt seit über 5 Jahren problemlos wollen wir jetzt diverse Dinge wie ESPEasy so umbiegen das es wieder läuft? Oder Netcup dazu bringen das es wieder läuft? Wäre ja eine tolle Werbung für Netcup wenn man sagt mit diesen und jenen Produkten funktioniert es nicht
> Wäre ja eine tolle Werbung für Netcup wenn man sagt mit diesen und jenen > Produkten funktioniert es nicht Ist das für Netcup ein großes oder ein homöpathisches Problem?
Da mir dies auch mal passiert ist: Container "geclont" mit einem Backup? Schau mal ob die beiden LCX Container nicht die gleiche Mac Adresse haben ;-) So als kleiner Tipp.... - kein SSH - falsches Routing deutet alles so ein wenig darauf hin. Ich bin auf das gleiche Reingefallen und habe Stundenlang danach gesucht.
1N 4. schrieb: > Ist das für Netcup ein großes oder ein homöpathisches Problem? darfst Du aussuchen :-) Rene K. schrieb: > Da mir dies auch mal passiert ist: Container "geclont" mit einem Backup? als das Problem auftrat war ich 700km weg von daheim, hatte besseres zu tun als am Rechner rum zu spielen :-)
UM hier eine Aussage zu treffen, wäre es wirklich sinnvoll ein capture von der Fritzbox mitzuschneiden. Gerade beim Thema ESP erinnere ich mich an ein Problem, dass ich mit ESPurna hatte: Nach einem Update, kam ich aus einem anderen lokalen Subnetz (OpnSense) mit Firefox nicht mehr auf die Lichtschalter, mit Chrome-basierten Browsern ging es. Nach einem ESPurna-Update ging es dann wieder, so dass ich damals nicht weiter nachgeforscht habe. Wenn der ESP hier tatsächlich TCP-Pakete oder Header erzeugt, die nicht 100% sauber sind, könnten die natürlich das aktualisierte NetCup-IDS triggern. Hier hilft dann der Vergleich von funktionierenden und blockierten Verbindungen per Wireshark aus dem Capture-File.
Angehängte Dateien:
-

screenshot.jpg
340 KB
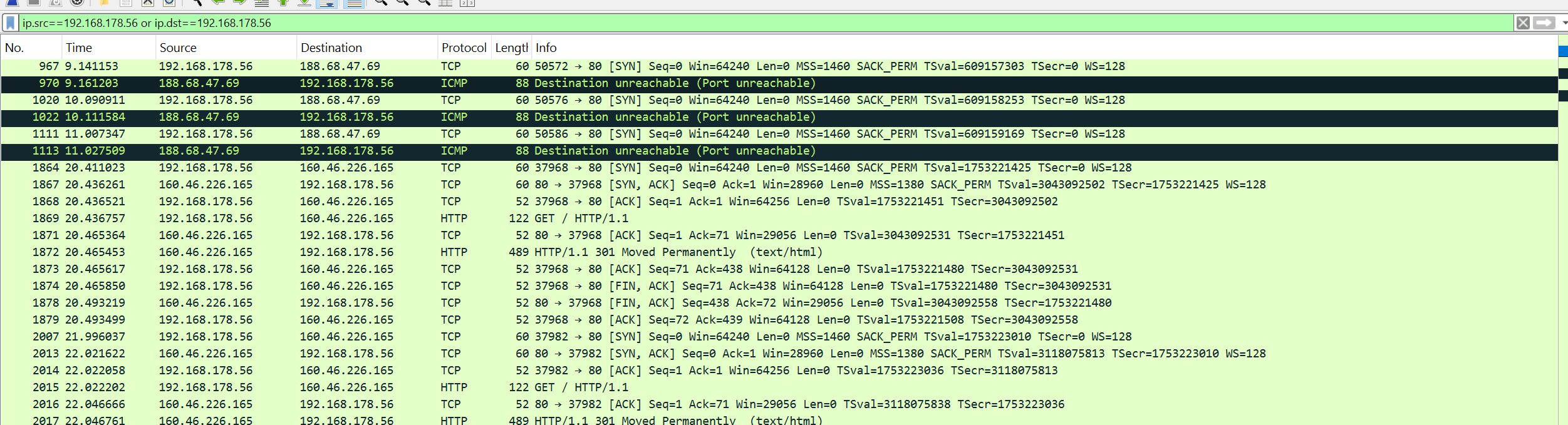
Ich habe jetzt mal ein Capture erstellt - anbei ein Screenshot 192.168.178.56 ist einer der Rechner die nicht durchkommen 188.68.46.69 ist die Webhosting-IP Ich habe 3 x curl kr123.de ausgeführt Im beiliegenden PDF ist die 2. Zeile ausgewählt Hilft das evtl. weiter, hier eine Lösung zu finden?
Merkwürdig, der Server bzw. die Firewall meldet, dass der Port nicht offen sei. Zeig doch mal den Inhalt des SYN-Pakets aus Zeile 967. P.S.: Es muss die Firewall sein, ein geschlossener Port wird mit RST-ACK signalisiert.
anbei Zeile 967 Du meinst eine Firewall in der Fritzbox? Merkwürdig das es von mehreren Clients nicht funktioniert - dann immer mal wieder für ein paar Minuten, dann exakt eine Stunde lang nicht Das Problem tritt Zeitsynchron bei allen betroffenen Clients auf
Heinz R. schrieb: > Ich habe jetzt mal ein Capture erstellt - anbei ein Screenshot Firewall-Kram, und zwar direkt auf dem Server (ICMP-Source-IP = Server-IP), schick das an den Netcup-Support.
Das ist eindeutig das Netcup IDS/IPS System. Das ICMP kommt von der Serveradresse. Es wird nun entweder direkt auf dem Server generiert oder aber auf einem dazwischenliegenden Firewall/IPS Account. Ursachen können vielfältig sein, z.B. auch zuviele parallele Verbindungen zu einer IP/Port-Kombination, die das OS nicht handeln kann. Dies scheidet aber wegen der zeitlichen Komponente aus. Die Stunde Sperre in Kombination mit der ICMP-Antwort deutet sehr stark auf ein IPS. Nun wären wirklich drei Captures zum selben Ziel hilfreich: - Ein Capture, das eine Verbindung zeigt, die nie unterbrochen wird - Ein Capture, das eine kurzzeitig funktionierende Verbindung zeigt - Ein Capture, das eine abgebrochene Verbindung zeigt. Die drei Captures aus Wireshark exportieren und hochladen. Dann kann man u.U. feststellen, ob und wenn, welche Verbindungsanomalien das IPS triggern könnten. Parallel sollte natürlich der Netcup-Support auch dazu befragt werden. Denen könnten diese Captures natürlich auch helfen.
Komisch ist halt, dass nur einzelne Clients betroffen sind. Könnte das auch eine Nachwirkung dieser behobenen Störung bei netcups sein? https://www.netcup-status.de/2024/10/stoerung-in-unserer-webhosting-umgebung/
Mario M. schrieb: > Komisch ist halt, dass nur einzelne Clients betroffen sind. Könnte das > auch eine Nachwirkung dieser behobenen Störung bei netcups sein? > > https://www.netcup-status.de/2024/10/stoerung-in-unserer-webhosting-umgebung/ Das ist aus meiner Sicht nicht komisch, denn man kann davon ausgehen, dass die sparsamen ESP-IP-Stacks durchaus Paketanomalien bewirken können, die von einem IPS erkannt u.u.U. als Bots/DOS eingeordnet werden. Die von Dir verlinkte Störung wurde laut netcup bereits am 9. behoben, der TO berichtet, den Fehler erst ab dem 13. zu beobachten.
Deswegen schrieb ich Nachwirkung. Aber es sind nicht nur ESPs betroffen.
Peter schrieb: > man kann davon ausgehen, dass die sparsamen ESP-IP-Stacks durchaus > Paketanomalien bewirken können Sehr unwahrscheinlich. Ich denke eher, der Hoster analysiert den HTTP-Traffic: Viele Connections mit HTTP/1.0 ohne "Connection: Keep-Alive", fehlender oder negativ aufgefallener User-Agent (curl sehe ich z.B. öfter bei Spam-Harvestern) etc.
Hmmm schrieb: > Peter schrieb: >> man kann davon ausgehen, dass die sparsamen ESP-IP-Stacks durchaus >> Paketanomalien bewirken können > > Sehr unwahrscheinlich. > > Ich denke eher, der Hoster analysiert den HTTP-Traffic: Viele > Connections mit HTTP/1.0 ohne "Connection: Keep-Alive", fehlender oder > negativ aufgefallener User-Agent (curl sehe ich z.B. öfter bei > Spam-Harvestern) etc. Ich sehe, wir sind uns einig. Für mich wären das jetzt in der Analyse auch Anomalien, die in den jeweiligen Capture-Files zu sehen wären. Die Grenze ist dabei sehr fliesend. Habe z.B. auch schon unterschiedliche Zeilenenden im Header (CR/CRLF) gesehen etc. Keep-Alive erwarte ich bei einem Datenlogger, insbesondere von ESPs ausgehend nicht. Ich kann mir jedoch bislang nicht erklären, nach welchem Kriterium geblockt wird, das es die absendende IP nicht ist, von der gehen laut TO ja weiterhin Verbindungen zu der fraglichen Subdomain (=IP) ein. Also kann es auch nicht das Tuple SenderIP-EmpfängerIP sein.
Peter schrieb: > Ich kann mir jedoch bislang nicht erklären, nach welchem Kriterium > geblockt wird, das es die absendende IP nicht ist, von der gehen laut TO > ja weiterhin Verbindungen zu der fraglichen Subdomain (=IP) ein. Evtl. TCP-Fingerprinting, hier fällt mir z.B. die wenig zufällige ISN (0) ins Auge. Aber wirklich sicher kann das nur der Hoster (hoffentlich) beantworten.
Heinz hat wohl schon im Netcups-Supportforum geschrieben. Ich hoffe, er hält uns auf dem Laufenden.
Mario M. schrieb: > Heinz hat wohl schon im Netcups-Supportforum geschrieben. Ansonsten hat er ja genug RasPis im Netz. Einem davon einen Proxy-Server verpassen, und schon bleiben alle ESP-TCP-Anomalien lokal, und er könnte sogar recht einfach die Verbindung in's Internet auf https umstellen.
Mario M. schrieb: > Heinz hat wohl schon im Netcups-Supportforum geschrieben. Ich hoffe, er > hält uns auf dem Laufenden. das Forum hat wenig geholfen - aber Mails an den Support Mittlerweile bin ich beim 4. Mitarbeiter angelangt - der hat jetzt meine IP auf eine Whitelist gesetzt - ich war wohl auf einer Blacklist Mir ist zum einen trotzdem nicht klar warum manche meiner Clients weiterhin problemlos funktioniert haben Außerdem ist das wohl auch keine dauerhafte Lösung, evtl. bekomme ich ja morgen eine andere IP, dann geht der Spaß von vorne los?
Heinz R. schrieb: > ich war wohl auf einer Blacklist Wenn sie Dir nicht beantworten können/wollen, wie es dazu kam, solltest Du den Hoster, mindestens jedoch das Produkt wechseln. Billiges Massen-Webhosting ist halt für normale Browser als Clients ausgelegt, nicht zur Zweckentfremdung des Webservers, um Messwerte einzusammeln. Heinz R. schrieb: > Mir ist zum einen trotzdem nicht klar warum manche meiner Clients > weiterhin problemlos funktioniert haben Was tun die denn genau? Übermitteln die zig Werte auf einmal und bauen dafür separate Verbindungen auf? Welcher User-Agent steht drin? Warten die brav auf die Antwort des Servers, oder schicken sie ihren Request ab und beenden einfach die Verbindung? Antwortet der Server mit 200, oder liefert der evtl. einen Fehler? Mir fällt spontan auf, dass der Server (wie heutzutage die meisten) bei HTTP-Requests automatisch einen Redirect auf die entsprechende HTTPS-URL liefert. Wenn ein Client das ignoriert und weiterhin HTTP-Requests schickt, ist das z.B. auffällig. Je seltsamer sich ein Client verhält, desto grösser die Wahrscheinlichkeit, dass er als verdächtig empfunden und irgendwann blockiert wird.
Hmmm schrieb: > Wenn sie Dir nicht beantworten können/wollen, wie es dazu kam, solltest > Du den Hoster, mindestens jedoch das Produkt wechseln. > > Billiges Massen-Webhosting ist halt für normale Browser als Clients > ausgelegt, nicht zur Zweckentfremdung des Webservers, um Messwerte > einzusammeln. ja, ich überlege schon lange auf einen gehosteten Server umzusteigen, da gehts auch nicht um 5€ hin oder her - mir fehlt einfach die Zeit und das hat sich so entwickelt, hat ja bislang auch funktioniert Ich will so was halt auf alle Fälle extern haben - sollen sich andere um die Sicherheit, Updates usw kümmern Hmmm schrieb: > Was tun die denn genau? Übermitteln die zig Werte auf einmal und bauen > dafür separate Verbindungen auf? Welcher User-Agent steht drin? Warten > die brav auf die Antwort des Servers, oder schicken sie ihren Request ab > und beenden einfach die Verbindung? Antwortet der Server mit 200, oder > liefert der evtl. einen Fehler? das kann ich Dir zugegeben gar nicht so genau sagen - es läuft halt Volkszähler drauf Jeder Wert z.B. wird per http://kr123.de/wasauchimmer/volkszaehler.org/htdocs/middleware.php/data/$uuid1.json?operation=add&value=$vorlauf3 übergeben Da kommen schon einige Anfragen jede Sunde zusammen - es sind hier über 100 Kanäle
Heinz R. schrieb: > Außerdem ist das wohl auch keine dauerhafte Lösung, evtl. bekomme ich ja > morgen eine andere IP, dann geht der Spaß von vorne los? Genau deswegen wäre es sinnvoll, die problematischen Verbindungen gegen die unproblematischen Verbindungen zu vergleichen. Dem Verhalten nach ist es wohl eine intelligentere Blocklist, wie die meisten IDS/IPS das handhaben. Im Prinzip läuft das so: Wenn zu einer IP eine Häufung bestimmter verdächtiger Aufrufe festgestellt wird, werden genau diese (und nur diese) geblockt. Damit sollen z.B. Bots etc. die sich bei regulären Usern im System eingenistet haben, unterbrochen werden, nicht jedoch der reguläre Aufruf einer Seite durch den Benutzer. Wenn der Nutzer komplett gesperrt wird, nimmt er das als einen Fehler einer Webseite wahr, was in der Folge zu schlechtem Ruf (Hoster ist instabil) führt, bzw. auch mehr Supportanfragen erzeugt. Einfach auf eine Seite umleiten, wo mitgeteilt wird, dass diese IP derzeit wegen verdächtigen Aufrufen gesperrt ist, will man auch nicht, weil es sich ja nur um einen "Verdacht" handelt. Je mehr bei sowas jetzt auch KI mitmischt, desto weniger können Dir sogar die Supportleute sagen, warum es klemmt. Da hilft nur, auf einen selbst gemanagten (virtuellen) Server umzusteigen. Wenn der nur für Deine Volkszählerlösung dienen soll, geht das auch sehr sicher: Der Webserver lauscht auf einem dummy-Interface, angesprochen wird er über ein VPN von der Fritzbox aus. Damit hast Du dann keinerlei Probleme, auch wenn mal eine Sicherheitslücke in einer der Komponenten aufkommt. SSH Zugang nur per Key, dann können auch all die brute-forcer Dir nichts anhaben.
Heinz R. schrieb: > Da kommen schon einige Anfragen jede Sunde zusammen - es sind hier über > 100 Kanäle Einfache Lösung: Alle Daten auf einem Pi sammeln und der schickt dann alles in einer einzigen POST-Anfrage an den Server.
Heinz R. schrieb: > Von Maschine A komme ich mit User X Passwort Y auf Maschine B > > Aber ich komme per SSH nicht von Maschine B auf Maschine A - > merkwürdig, aber wohl ein anderes Problem Wenn Du Dir nicht absolut sicher bist, daß dieses Problem wirklich erst zeitgleich (oft baut man ja im Zuge des Debugings erstmals (seit langem) eine ganz bestimmte Verbindung auf) mit dem anderen begonnen hat, dann ist das sehr wahrscheinlich. Hängt das nichtfunktionieren von B nach A auch an einem bestimmten Nutzer/Passwort? (Nur weils bei den funktionierenden Verbindungen extra erwähnt ist.) Eventuell ein fehlerhafter Eintrag in known_hosts auf Maschine B; sollte zwar normalerweise eine brauchbare Fehlermeldung geben, aber man kann da ja vieles wegkonfigurieren... Oder unterschiedliche SSH-Version, Authentifizierungs-Einstellungen oder Krypto-Einstellungen zwischen Putty und Maschine B, dann sollte sich zumindest im Log auf A zu den abgelehnten Logins näheres finden.
Michi S. schrieb: > Wenn Du Dir nicht absolut sicher bist, daß dieses Problem wirklich erst > zeitgleich (oft baut man ja im Zuge des Debugings erstmals (seit langem) > eine ganz bestimmte Verbindung auf) mit dem anderen begonnen hat, dann > ist das sehr wahrscheinlich. ja, das eine hatte wohl mit dem anderen nichts zu tun, ich hatte halt nie von Maschine A auf Maschine B zugegriffen Das Problem hat sich jetzt in soweit gelöst das Netcup auf eine Whitelist gesetzt hat Ich habe wohl auch beim Fehler suchen einen Fehler gemacht - ist mit erst später mit Netshark aufgefallen: Es war wohl doch so das alle betroffenen Geräte per IPV4 connected haben, die nicht betroffenen per IPV6 Ich hoffe auf eine ruhige Weihnachtszeit, werde dann wohl von Webhosting zu einem Server wechseln Aber trotzdem - vielen Dank allen für die Hilfen und Ideen
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.