Hat jemand Erfahrung mit der CUDA-Programmierung?
Folgendes einfaches Beispiel lässt sich bei mir problemlos compilieren
(Ubunut 20.04):
1 | // This is the REAL "hello world" for CUDA!
| 2 | // It takes the string "Hello ", prints it, then passes it to CUDA with an array
| 3 | // of offsets. Then the offsets are added in parallel to produce the string "World!"
| 4 | // By Ingemar Ragnemalm 2010
| 5 | // https://computer-graphics.se/hello-world-for-cuda.html
| 6 |
| 7 | #include <stdio.h>
| 8 |
| 9 | const int N = 16;
| 10 | const int blocksize = 16;
| 11 |
| 12 | __global__
| 13 | void hello(char *a, int *b)
| 14 | {
| 15 | a[threadIdx.x] += b[threadIdx.x];
| 16 | }
| 17 |
| 18 | int main()
| 19 | {
| 20 | char a[N] = "Hello \0\0\0\0\0\0";
| 21 | int b[N] = {15, 10, 6, 0, -11, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0};
| 22 |
| 23 | char *ad;
| 24 | int *bd;
| 25 | const int csize = N*sizeof(char);
| 26 | const int isize = N*sizeof(int);
| 27 |
| 28 | printf("%s", a);
| 29 |
| 30 | cudaMalloc( (void**)&ad, csize );
| 31 | cudaMalloc( (void**)&bd, isize );
| 32 | cudaMemcpy( ad, a, csize, cudaMemcpyHostToDevice );
| 33 | cudaMemcpy( bd, b, isize, cudaMemcpyHostToDevice );
| 34 |
| 35 | dim3 dimBlock( blocksize, 1 );
| 36 | dim3 dimGrid( 1, 1 );
| 37 | hello<<<dimGrid, dimBlock>>>(ad, bd);
| 38 | cudaMemcpy( a, ad, csize, cudaMemcpyDeviceToHost );
| 39 | cudaFree( ad );
| 40 | cudaFree( bd );
| 41 |
| 42 | printf("%s\n", a);
| 43 | return EXIT_SUCCESS;
| 44 | }
|
Laufen tut es auch, aber die Frage ist: Wie kann man feststellen, dass
es auf der GPU und nicht auf dem Prozessor läuft?
ChatGPT sagt:
1 | In CUDA, you can determine which GPU a thread is running on by using the cudaGetDevice() function, which retrieves the current device in use. Here’s a quick example in CUDA C++:
| 2 |
| 3 | cpp
| 4 |
| 5 | #include <cuda_runtime.h>
| 6 | #include <iostream>
| 7 |
| 8 | __global__ void checkDevice() {
| 9 | int device;
| 10 | cudaGetDevice(&device);
| 11 | printf("This code is running on GPU device: %d\n", device);
| 12 | }
| 13 |
| 14 | int main() {
| 15 | // Set a specific device (optional)
| 16 | int device = 0;
| 17 | cudaSetDevice(device);
| 18 |
| 19 | // Launch a kernel to check which device it’s running on
| 20 | checkDevice<<<1, 1>>>();
| 21 | cudaDeviceSynchronize(); // Wait for the kernel to complete
| 22 |
| 23 | return 0;
| 24 | }
| 25 |
| 26 | Explanation
| 27 |
| 28 | cudaGetDevice(): Returns the current GPU device on which the code is running.
| 29 | cudaSetDevice(int device): Sets a specific GPU device before launching the kernel, if needed.
| 30 | cudaDeviceSynchronize(): Ensures that the kernel finishes execution before continuing (useful for seeing printed output).
| 31 |
| 32 | This code launches a kernel checkDevice that runs on the currently selected GPU, printing the device ID.
|
Nicht ausprobiert, aber vielleicht hilft die Info...
Danke für den Hinweis. Wäre super, wenn es klappen würde. Aber:
1 | ~/tmp/cuda$ nvcc check.cu
| 2 |
| 3 | check.cu(9): error: calling a __host__ function("cudaGetDevice") from a __global__ function("checkDevice") is not allowed
| 4 |
| 5 | check.cu(9): error: identifier "cudaGetDevice" is undefined in device code
| 6 |
| 7 | 2 errors detected in the compilation of "/tmp/tmpxft_000017b4_00000000-8_check.cpp1.ii".
|
Das Programm selber läuft immer auf der CPU. Nur die Rechenoperationen
die mit
Christoph M. schrieb:
> hello<<<dimGrid, dimBlock>>>(ad, bd);
Ausgeführt werden laufen auf der GPU. Meines wissen kann cuda in der
Standard installating gar keine Emulation auf der CPU.
Such Mal nach einem Tool/Code das die verfügbaren devices auflistet.
Wenn da nur deine Hardware gelistet wird kann es nur auf der GPU laufen.
Timo W. (timo)
>Such Mal nach einem Tool/Code das die verfügbaren devices auflistet.
>Wenn da nur deine Hardware gelistet wird kann es nur auf der GPU laufen.
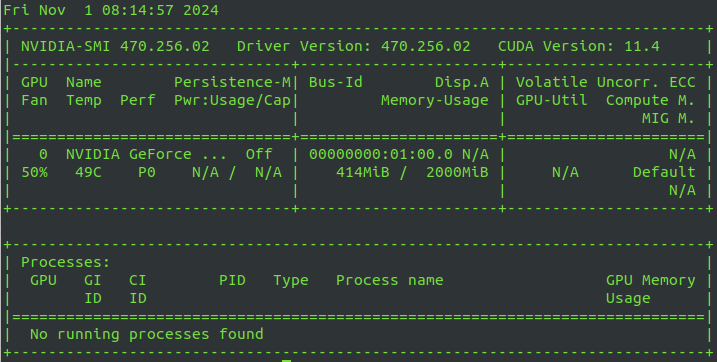
Meinst Du den Befehl "nvidia-smi"?
Das Ergebnis im angehängten Bild würde ich so interpretieren, dass die
CUDA -Installation irgendwie korrekt ist. Das Hello-World im
Eingangspost kann ich kompilieren und es erscheint der Output in der
Konsole.
Ich wollte die NVIDIA-Samples aus diesem Repository ausprobieren:
https://github.com/NVIDIA/cuda-samples
Ich kann das "Device Query Sample" kompilieren und laufen lassen. Die
Ausgabe ist dann aber:
1 | ./deviceQuery
| 2 | ./deviceQuery Starting...
| 3 |
| 4 | CUDA Device Query (Runtime API) version (CUDART static linking)
| 5 |
| 6 | cudaGetDeviceCount returned 35
| 7 | -> CUDA driver version is insufficient for CUDA runtime version
| 8 | Result = FAIL
|
Ich geb's zu, meine Graphikkarte ist uralt. Da das Hello-World aber
läuft, gehe ich davon aus, dass die Samples auch irgendwie laufen
sollen.
Mit CUDA direkt arbeiten ist aber auch grausam. Da würde ich mir einen
Layer of Abstraktion gönnen. tinygrad oder so. Der 470 Treiber ist halt
ein Indiz auf deine alte Hardware. Eventuell gibt das Probleme, wobei
die Kombi 11.4 + 470 die stabilste / kompatibelste ist.
Jonas B.
>Eventuell gibt das Probleme, wobei
>die Kombi 11.4 + 470 die stabilste / kompatibelste ist.
Tja, irgendwie scheint meine Installation da ein wenig durcheinander.
Aus dem ScreenShot ist ja die Cuda-Version 11.4 und der Treiber 470
ersichtlich.
Zum kompilieren des Hello-World nutze ich das Kommando
Das scheint ja zu kompilieren und die Ausgabe erscheint.
Die NVIDA-Samples compilieren auch, werfen aber den oben besagten Fehler
35 (Versionskonflikt)
Wenn ich mit synaptic auf die installierte Cuda-Version schaue, steht da
12.6
Das make-File der NVIDIA samples scheint also die neuere CUDA-Version
nutzen zu wollen, während das Kommando "nvcc" vermutlich mit der
passenden, alten kompiliert.
Christoph M. schrieb:
> aber die Frage ist: Wie kann man feststellen, dass
> es auf der GPU und nicht auf dem Prozessor läuft?
Tja, wirklich gute Frage! Ich hab zwar jetzt von CUDA echt NullPlan,
trotzdem würde ich in erster Näherung vermuten, daß folgende Zeile
> __global__
dem nvcc sagt, daß die darauffolgende Funktion auf der GK laufen soll.
Wenn das Manual meine Vermutung bestätigen sollte und Du Deinem nvcc
vertraust, bist Du fertig.
Falls Du aber Deinem Compiler misstraust, dann - ja dann - isses echt
blöd, denn dann solltest Du auch keinem anderen Tool trauen. Damit
bleibt Dir als letzter Ausweg nur, die Binary in mühevoller Handarbeit
in Assembler rückzuwandeln und dann zu kontrollieren, ob sie das
gewünschte macht und wo gerechnet wird. --- Viel Spaß! ;)
Gibt da ein nettes Essay über das grundlegende Problem einen ersten
Compiler auf einer Maschine vertrauenswürdig bootzustrappen, entweder
vom K. oder R. aus K&R, wenn ich mich recht erinnere.
Sag mal, hast du WSL und dort die cuda toolchain installiert?
Normalerweise sieht man im Taskmanager und Co die Last der GPU.
So Kleinkram mit wenigen hundert Elementen sieht man allerdings erst gar
nicht. Die Grafikkarte ist ja schließlich dafür gemacht, 4096x2048x3*120
Byte pro Sekunde allein "nebenbei" zu erzeugen.
Jonas B.
>Sag mal, hast du WSL und dort die cuda toolchain installiert?
Erster Post: Ubuntu 20.04
Soweit ich weiß, werden Cuda-Kernels immer auf der Grafikkarte
ausgeführt. Man kann aber das zu verwendende Gerät auch mit
cudaSetDevice explizit auswählen.
Wenn du ganz genau wissen willst, was passiert, kannst du NVIDIA Nsight
Verwenden. Das zeigt dir genau, was wann wo ausgeführt wurde, wann Daten
über den Bus gelaufen sind und wie lange das alles gebraucht hat.
Christoph M. schrieb:
> Jonas B.
>>Sag mal, hast du WSL und dort die cuda toolchain installiert?
>
> Erster Post: Ubuntu 20.04
Das heißt ja nicht zwingend, dass es das WSL-Ubuntu sein muss.
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
|