Moin Moin,
ich stehe gerade so ziemlich auf der Leitung..
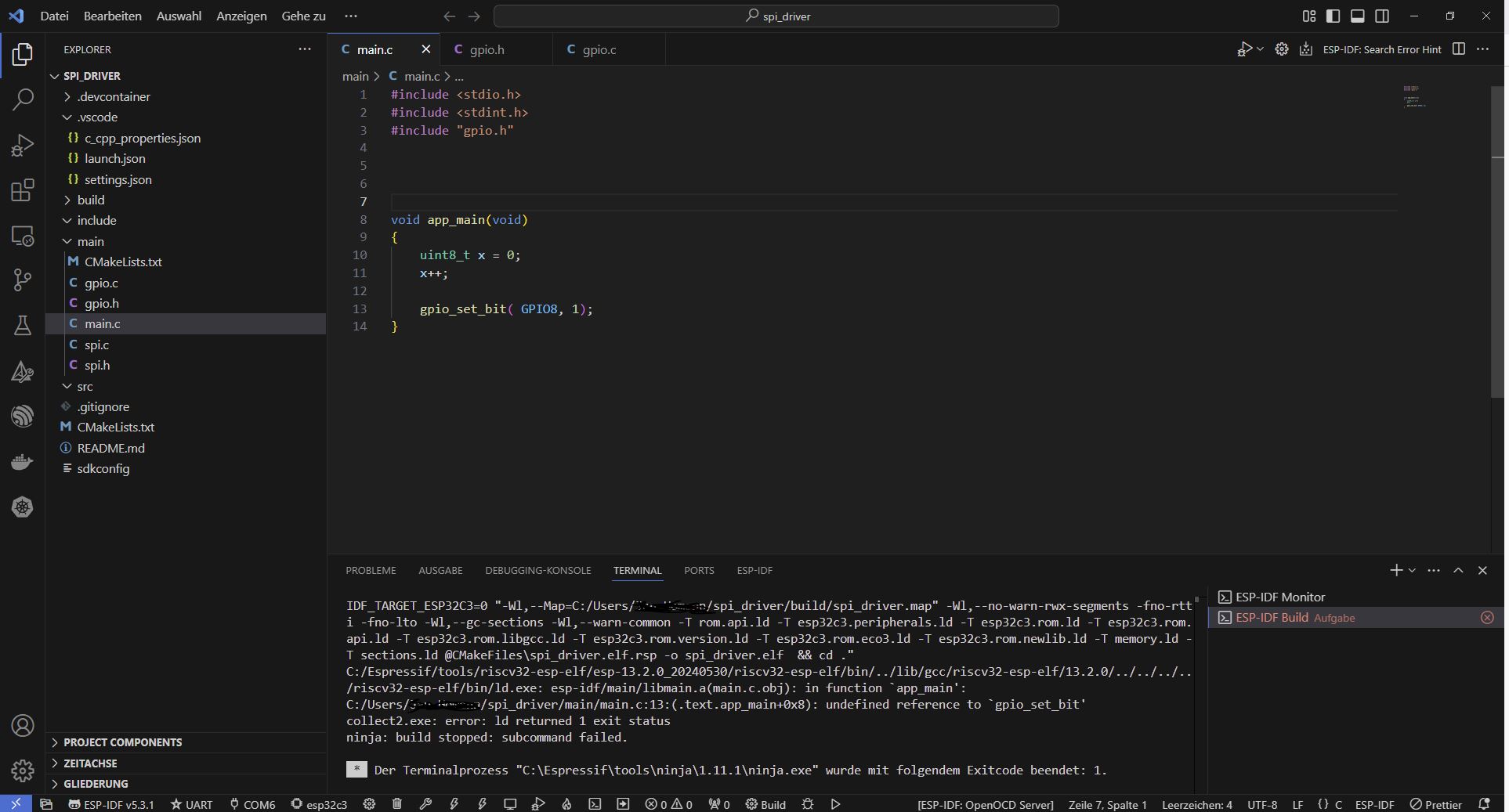
Die IDE wirft mir folgende Meldung:
1 | C:/Users/spuky/spi_driver/main/main.c:13:(.text.app_main+0x8): undefined reference to `gpio_set_bit'
|
Die entsprechende Headerdatei ist eingebunden, dort steht auch der
Prototyp drin >
"gpio.h" 1 | extern void gpio_set_bit( const gpio_t _pin, const uint8_t _level );
|
In der "gpio.c" ist der Prototyp auch vorhanden.
Auch ein #include "gpio.h" ist vorhanden.
Die #defines werden komischer weise erkannt aus der "gpio.h"
Was ist falsch?
Jan H. schrieb:
> Die IDE wirft mir folgende Meldung:
Nihct wirklich. Tatsächlich wirds der linker sein.
Jan H. schrieb:
> In der "gpio.c" ist der Prototyp auch vorhanden.
Prototyp? Irgendwo braucht es die Implementierung der Funktion. Der
linker findet halt keine.
Oliver
Oliver S. schrieb:
> Jan H. schrieb:
>> In der "gpio.c" ist der Prototyp auch vorhanden.
>
> Prototyp? Irgendwo braucht es die Implementierung der Funktion.
>
> Oliver
Die ist ja in der "gpio.c" vorhanden.
Jan H. schrieb:
> Oliver S. schrieb:
>
>> Jan H. schrieb:
>>> In der "gpio.c" ist der Prototyp auch vorhanden.
>>
>> Prototyp? Irgendwo braucht es die Implementierung der Funktion.
>>
>> Oliver
>
> Die ist ja in der "gpio.c" vorhanden.
Und die wird auch im Projekt kompiliert und gelinkt?
Oliver
Im Anhang sieht man die Fehlermeldung..
Wenn ich im Projekt explizit die Quelldatei mit angebe, sprich "gpio.c"
dann funktioniert es ohne Probleme, nehme ich sie wieder weg auch.
Das heißt der Linker findet die sonst nicht?
Jan H. schrieb:
> Wenn ich im Projekt explizit die Quelldatei mit angebe, sprich "gpio.c"
Wir gibst du sie an im Projekt?
Jan H. schrieb:
> nehme ich sie wieder weg auch.
Vermutlich wird beim ersten Mal wo es geht das Objekt-File generiert.
Wenn du es dann wieder falsch übersetzt findet der Linker das alte
Objekt File.
Mach Mal zwischendrin ein Clean. Dann wird es nicht mehr gehen.
Okay und was tut man dagegen?
Im Screenshot ist eine CMakeLists.txt zu sehen. Dort hast du sicherlich
deine main.c eingetragen und musst eben auch deine gpio.c eintragen,
sonst wird sie nicht mit kompiliert.
Niklas G. schrieb:
> Im Screenshot ist eine CMakeLists.txt zu sehen.
Sogar zwei.
Jan H. schrieb:
> Das heißt der Linker findet die sonst nicht?
Der Linker findet garnix.
Es gibt das Makefile, das üblicherweise von der IDE generiert wird.
In dem steht zunächst drin, welche Quelldateien vorhanden sind, das
können C-Dateien sein, oder Assemblerquellcodes oder prinzipiell, wenn
die Calling-Conventions der verwendeten Compiler kompatibel sind, auch
ganz andere Sprachen. (Auf PC wurde das früher(TM) z.B. mit (Turbo)
Pascal und C durchaus gemacht.)
Ein #include im C-File (oder H-File) macht nichts anderes, als genau an
dieser Stelle die referenzierte Datei 1:1 einzufügen. Einfach wie
Copy/Paste, weiter passiert da nichts. Da das mehrfach passieren kann
(z.B. wenn das Headerfile auch die stdio.h einbindet), haben headerfiles
üblicherweise das #ifndef BLAH_H #define BLAH_H .. Körper .. #endif
Konstrukt.
Aus den so vom Präprozessor vorbereiteten C Files werden dann
Objektfiles. Eines pro Datei. Das ist Maschinencode, wo aber alle
Speicheradressen noch leer sind. Zusätzlich Metadaten, mit was sie
gefüllt werden sollen.
Der Linker fasst dann alle Objektfiles (die ihm auch vom Makefile
genannt werden) zusammen und trägt die Adressen ein und baut so das
Executable.
(U.u. kommt da noch Relokationscode und Startupcode usw. dazu das will
ich aber erstmal beiseite lassen, verkompliziert es nur)
Wenn im Makefile nun keine gpio.c steht, aus der dann eine gpio.o wird
die dem Linker vorgesetzt wird, bindet er den aus gpio.c erzeugen
Maschinencode nicht mit ein und hat damit natürlich auch keine Adresse
für "gpio_set_bit".
Eine weitere Möglichkeit ist die Verwendung einer vorkompilierten
Library, das ist als z.B. libc sogar der Standard. Der Linker bekommt
dann gesagt, dass diese Library existiert und kopiert die nötigen
Funktionen aus dieser heraus.
Eine passend konfigurierte IDE versteckt viel davon, aber wenn es mal
nicht geht sollte man schon wissen wie das ganze abläuft.
Christian E. schrieb:
> Es gibt das Makefile
Wo siehst du hier ein Makefile?
Niklas G. schrieb:
> Wo siehst du hier ein Makefile?
Hier wird CMake verwendet, das erzeugt eins aus CMakeLists.txt, passend
zum vorhandenen Buildsystem.
Und das liegt dann üblicherweise unter ./CMakeFiles
Harald K. schrieb:
> das erzeugt eins aus CMakeLists.txt,
Benutzt das ESP-IDF nicht Ninja?
Keine Ahnung. Wie schon jemand anderes anmerkte, sind auf dem
Screenshot, der idiotischerweise anstelle des TEXTES der Fehlermeldung
angehängt wurde, gleich zwei CMakeLists.txt zu sehen (links in der
Baumansicht).
Das kann natürlich verschiedene Ursachen haben, z.B. daß hier jemand
einfach nur irgendwelche Verzeichnisse mit irgendwelchen Sourcedateien
irgendwie zusammen in ein anderes Verzeichnis geklatscht hat und
versucht, daraus eine Suppe zu bereiten.
Visual Studio Code jedenfalls ist beides egal, wie der Buildprozess
tatsächlich aussieht, ist konfigurierbar.
Bei einem unverbastelten VScode gibt es .vscode/tasks.json, in der man
das macht.
Aber das geht sicherlich auch anders.
Harald K. schrieb:
> gleich zwei CMakeLists.txt zu sehen
Ist normal beim ESP-IDF, das äußere CMakeLists.txt ist für das ganze
Projekt, das innere für das Main-Modul. Größere Projekte können mehr als
ein Modul enthalten.
Die Datei muss in die innere CMakeLists.txt hinein. Allerdings soll das
VS Code Plugin die CMakeLists.txt eigentlich automatisch erzeugen /
aktualisieren.
Christian E. schrieb:
> Jan H. schrieb:
>> Das heißt der Linker findet die sonst nicht?
>
> Der Linker findet garnix.
Na sicher tut er das. Er durchsucht alle Object-Files und Libraries, die
ihm per Kommandozeile genannt wurden, nach Symbolen, wie z.B.
Funktionen, die in einem Object-File aufgerufen, aber nicht definiert
werden. Wenn er die Funktion nirgends findet, kommt diese Meldung.
> Es gibt das Makefile, das üblicherweise von der IDE generiert wird.
Das wird hier von CMake generiert, nicht von der IDE.
> In dem steht zunächst drin, welche Quelldateien vorhanden sind, das
> können C-Dateien sein, oder Assemblerquellcodes oder prinzipiell, wenn
> die Calling-Conventions der verwendeten Compiler kompatibel sind, auch
> ganz andere Sprachen. (Auf PC wurde das früher(TM) z.B. mit (Turbo)
> Pascal und C durchaus gemacht.)
Dem Makefile ist völlig wurscht, was das ist. Das muss nicht mal was mit
Programmierung zu tun haben. Das enthält einfach nur Regeln zum
Generieren von Dateien aus anderen Dateien und die Abhängigkeiten
zwischen diesen Dateien.
Harald K. schrieb:
> Niklas G. schrieb:
>> Wo siehst du hier ein Makefile?
>
> Hier wird CMake verwendet, das erzeugt eins aus CMakeLists.txt, passend
> zum vorhandenen Buildsystem.
>
> Und das liegt dann üblicherweise unter ./CMakeFiles
Das Makefile wird im Build-Verzeichnis angelegt.
Rolf M. schrieb:
> Das Makefile wird im Build-Verzeichnis angelegt.
Nein. Es KEIN Makefile im Spiel. Es wird eine build.ninja erzeugt und
dann wird ninja damit gestartet. Make wird überhaupt nicht benutzt.
Das ist jetzt klugscheisserei weil das ninja build file die gleiche
Funktion hat und auch nahezu die gleiche Syntax. Wichtig ist nur das es
es hier generiert wird und man das nicht manuell modifiziert.
Das ESP IDF hat da sein eigenes Regelwerk für Cmake gebaut um die
Benutzung zu stanadardisieren und mit Kconfig die ganze Modularisierung
zu vereinfachen.
Niklas G. schrieb:
> Rolf M. schrieb:
>> Das Makefile wird im Build-Verzeichnis angelegt.
>
> Nein. Es KEIN Makefile im Spiel. Es wird eine build.ninja erzeugt und
> dann wird ninja damit gestartet. Make wird überhaupt nicht benutzt.
Das kommt drauf an, wie cmake aufgerufen wird. Aber so oder so liegt das
zu verwendende generierte File dann direkt im build-Verzeichnis und
nicht unter CMakeFiles.
Rolf M. schrieb:
> Aber so oder so liegt das
> zu verwendende generierte File dann direkt im build-Verzeichnis und
> nicht unter CMakeFiles.
Wenn das so konfiguriert wird. Ein "nacktes" CMake erzeugt ./CMakeFiles
und wirft da alles mögliche rein.
es gibt kein nacktes Cmake, das ist ein Kommandozeilenprogramm und wird
mit Argumenten aufgerufen, u.a. wo das build Verzeichnis liegt. Man kann
auch mehrere derer haben, das benutze ich für mehrere targets z.B. genau
so.
https://cmake.org/cmake/help/latest/manual/cmake.1.html
Harald K. schrieb:
> Rolf M. schrieb:
>> Aber so oder so liegt das
>> zu verwendende generierte File dann direkt im build-Verzeichnis und
>> nicht unter CMakeFiles.
>
> Wenn das so konfiguriert wird.
Immer.
> Ein "nacktes" CMake erzeugt ./CMakeFiles und wirft da alles mögliche
> rein.
Aber nicht das Makefile bzw. das File für ninja. Da können irgendwelche
Hilfsfiles dafür liegen, aber das, was man an make bzw. ninja übergeben
muss zum bauen, das liegt nicht da drin.
Und was meinst du hier überhaupt mit ./? Das Verzeichnis CMakeFiles wird
ebenfalls im build-Verzeichnis angelegt.
Rolf M. schrieb:
> Aber nicht das Makefile bzw. das File für ninja.
OK, gut. Da mag ich mich geirrt haben.
Welchen Vorzug hat "ninja" gegenüber einem normalen make?
Harald K. schrieb:
> Rolf M. schrieb:
>> Aber nicht das Makefile bzw. das File für ninja.
>
> OK, gut. Da mag ich mich geirrt haben.
>
> Welchen Vorzug hat "ninja" gegenüber einem normalen make?
Weiß ich nicht. Es soll wohl schneller sein als make. Mir waren aber die
Ausgaben zu sparsam, wobei ich nicht weiß, ob das von ninja selbst oder
von CMake so gemacht wird. Ich hab es einmal verwendet für eine
Software, in deren Build-Anleitung stand, man müsse ninja nehmen. Da hat
es nicht funktioniert. Ist einfach stehen geblieben für immer und hat
nichts mehr getan, auch keine CPU-Last. Einen Grund dafür konnte ich
auch nicht finden, auch in einem gesprächigeren Modus nicht.
Ninja soll Abhängigkeiten besser auflösen können. Die generierten
makefiles können sehr groß sein, da wird jeder Compileraufruf komplett
aufgelöst damit beim Build stur die fertige Liste abgearbeitet werden
kann.
In das Dreigestirn gehört noch CCache, das hält kompiliertes im RAM und
beschleunigt das nochmals. Wenn aus mehreren hundert Quellen gebaut wird
macht das echt Freude zuzusehen wie der Compiler da durchrennt als würde
man einfach scrollen.
J. S. schrieb:
> Die generierten makefiles können sehr groß sein, da wird jeder
> Compileraufruf komplett aufgelöst damit beim Build stur die
> fertige Liste abgearbeitet werden kann.
Was bedeutet für Dich "komplett aufgelöst"?
J. S. schrieb:
> Wenn aus mehreren hundert Quellen gebaut wird
> macht das echt Freude zuzusehen wie der Compiler da durchrennt als würde
> man einfach scrollen.
Wie soll das funktionieren? Der Compiler wird für jede "translation
unit" aufgerufen und weiß nichts von den anderen. Oder ist das eine
verklausulierte Art von "precompiled headers"?
Harald K. schrieb:
> Was bedeutet für Dich "komplett aufgelöst"?
im build.ninja sind für alle libraries für alle Übersetzungseinheiten
solche Einträge:
1 | #############################################
| 2 | # Order-only phony target for mbed-os
| 3 |
| 4 | build cmake_object_order_depends_target_mbed-os: phony || mbed-os/mbed-linker-script
| 5 |
| 6 | build mbed-os/CMakeFiles/mbed-os.dir/__/custom_targets/TARGET_STM32H7/TARGET_FK743M5_XIH6/PeripheralPins.c.obj: C_COMPILER__mbed-os_unscanned_debug /home/jojo/projects/mbed/mbed-ce-H7/custom_targets/TARGET_STM32H7/TARGET_FK743M5_XIH6/PeripheralPins.c || cmake_object_order_depends_target_mbed-os
| 7 | DEFINES = -DARM_MATH_CM7 -DCY_RTOS_AWARE -DMBED_CONF_EVENTS_PRESENT=1 -DMBED_CONF_NANOSTACK_LIBSERVICE_PRESENT=1 -DMBED_CONF_RTOS_API_PRESENT=1 -DMBED_CONF_RTOS_PRESENT=1 -DMBED_DEBUG -DMBED_MINIMAL_PRINTF -DMBED_TRAP_ERRORS_ENABLED=1 -DTARGET_NAME=FK743M5_XIH6 -DTOOLCHAIN_GCC -DTOOLCHAIN_GCC_ARM -D__CMSIS_RTOS -D__CORTEX_M7 -D__FPU_PRESENT=1
| 8 | DEP_FILE = mbed-os/CMakeFiles/mbed-os.dir/__/custom_targets/TARGET_STM32H7/TARGET_FK743M5_XIH6/PeripheralPins.c.obj.d
| 9 | FLAGS = -Wall -Wextra -Wno-unused-parameter -Wno-missing-field-initializers -Wno-psabi -fmessage-length=0 -fno-exceptions -ffunction-sections -fdata-sections -funsigned-char -fomit-frame-pointer -g3 -mthumb -mfpu=fpv5-d16 -mfloat-abi=softfp -mcpu=cortex-m7 -std=gnu11 -O2 -Og -include /home/jojo/projects/mbed/mbed-ce-H7/build/FK743M5_XIH6_STM32CUBE-Debug/mbed-os/generated-headers/mbed-target-config.h
| 10 | INCLUDES = -I/home/jojo/projects/mbed/mbed-ce-H7/custom_targets/TARGET_STM32H7/TARGET_FK743M5_XIH6/. -I/home/jojo/projects/mbed/mbed-ce-H7/mbed-os/targets/TARGET_STM/TARGET_STM32H7/TARGET_STM32H743xI/. -I/home/jojo/projects/mbed/mbed-ce-H7/mbed-os/targets/TARGET_STM/TARGET_STM32H7/. -I/home/jojo/projects/mbed/mbed-ce-H7/mbed-os/targets/TARGET_STM/.
| 11 | // .... ganz viele weitere Includes
| 12 | OBJECT_DIR = mbed-os/CMakeFiles/mbed-os.dir
| 13 | OBJECT_FILE_DIR = mbed-os/CMakeFiles/mbed-os.dir/__/custom_targets/TARGET_STM32H7/TARGET_FK743M5_XIH6
| 14 | TARGET_COMPILE_PDB = mbed-os/CMakeFiles/mbed-os.dir/
| 15 | TARGET_PDB = ""
|
ist über 10 MB groß, enthält aber auch viele build targets die in
CMakeLists definiert sind, aber nicht alle immer benutzt werden.
Das Kompilieren mit Ninja dauert für ca. 300 files 17 Sekunden. Ich habe
mal ein Unix Makefile generieren lassen, mit make dauert das gleiche 31
Sekunden, und dabei war jetzt noch einiges im Dateicache, beim ersten
Aufruf war es noch langsamer.
Also egal was und wie Ninja es macht, es ist gut und schnell. Gut weil
die Erkennung von Abhängigkeiten zuverlässig funktioniert. D.h. auch
eine Änderung in einem tief verschachtelten Include führt dazu das nur
die nötigen C/Cpp Quellen übersetzt werden. Ich kenne das von anderen
Buildsystemen das es hier oft sicherer war ein make all zu machen wenn
man nicht Phantom Fehler suchen wollte...
edit:
bzw. der Ccache wird auch bei make benutzt, bei den 31 s hat auch make
davon profitiert.
Mit kompiliertem im Ccache braucht Ninja nur noch 7 s.
https://ccache.dev/
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
|