Programmierung x86 SIO Umschaltung Privileg Level in ASM und Inline C Dr. A. Schade TUC ACS Mülltrenung - Mikroelektronik Kalte Plasmen Trainingsplan Radsport Massaker von Odessa Auf den ersten Blick brauchbare Kurzvorträge.
Teilweise ist der wirklich gut. Oft jedoch wird mit breitem Selbstbewußtsein kompletter Nonsens erzählt (wie bei jedem anderen Chatbot auch).
Was ist 1989 in China passiert? Warum ist nine-dash die Grenze von China? Zeichne eine Karte mit den Grenzen von China.
Andreas B. schrieb: > Oft jedoch wird mit breitem > Selbstbewußtsein kompletter Nonsens erzählt D.H. die KI macht den gleichen Sinn und Unsinn wie die anderen, nur mit erheblich weniger Ressourceneinsatz. Das NVIDIA Aktien deswegen abglitschen verstehe ich. Aber warum auch die Crypto Blase? Und was machen die Chinesen nun anders als OpenAI und Co.?
Durch die relativ "geringe" Größe lassen sich die Modelle einfacher lokal und auch ohne GPU nutzen und es gibt trotzdem einigermaßen brauchbaren Output. Die Halluzinationen bekommt man zwar nicht weg, kann sie aber über die Temperatur etwas beeinflussen. Allerdings fehlt es mir ehrlich gesagt an konkreten Einsatzszenarien. Denn das meiste hat man über eine Suchmaschine schneller gefunden ;-) Wer es selbst ausprobieren möchte, dem empfehle ich die "unsloth" GGUF Modelle bei Huggingface. DeepSeek-R1-Distill-Qwen-7B-Q3_K_M.gguf und Qwen2.5-Coder-7B-Instruct-Q3_K_M.gguf laufen auch bei 8GB RAM und einer i5-7300 CPU (koboldcpp) zumindest erträglich... Jörg
Joerg W. schrieb: > das meiste hat man über eine > Suchmaschine schneller gefunden Wenn man weiß wonach man sucht. KI Suche ist gut darin anhand einer texlichen Beschreibung zu einem akzeptablen Ergebniss zu kommen mit dem man dann weiter arbeiten kann. Ich habe aber das Gefühl das zumindest die BING KI immer schlechter wird. Gerade bei technischen Themen wird oft Quatsch erzählt. Korrigiere ich das sagt Bing: 'Stimmt, das war falsch' und liefert erst dann manchmal ein besseres Ergebniss. Oder es werden Quellen benutzt die nicht passen. Auf Aufforderung diese Quellen nicht mehr zu benutzen: 'Ja, okay, ich benutze andere Quellen' um dann wieder genau den gleichen Bockmist zu liefern mit exakt den gleichen Quellen. KI ist also ein mächtiges aber sehr unzuverlässiges Werkzeug. Gut bei Themen in denen man sich halbwegs auskennt mit reichlich Skepsis. Ganz schlecht wenn man Ergebnisse ohne Quersuche für bare Münze nimmt. Eher wie ein geistig Behinderter mit Inselbegabung. Teils brilliant, teils nur Gebrabbel. Gibts eigentlich belastbare Untersuchungen zu dem KI Verblödungsphänomen, d.H. der Degeneration einer KI die durch KI generierte Inhalt lernt? Eigentlich ja auch nur eine Spielart der YT-Kids die durch Videos von YT-Kids lernen um dann selber YT-Videos zu machen von denen andere YT-Kids lernen wie man YT-Videos macht.
Michael schrieb: > KI ist also ein mächtiges aber sehr unzuverlässiges Werkzeug. Die KI lernen von den Benutzern. Bei 99% Idioten wird auch die KI immer blöder.
G. K. schrieb: > Was ist 1989 in China passiert? Interessantes Ergebnis: erst wird lang und breit über TianMen erzählt inklusive Opfer und Regierung, nach Abschluss der Ausgabe verschwindet die Antwort und wird ersetzt durch englisch Sorry, that's beyond my current scope. Let’s talk about something else. LOL
Michael B. schrieb: > Die KI lernen von den Benutzern. So weit ich weiß tun sie genau das eben nicht.
Michael schrieb: > Michael B. schrieb: >> Die KI lernen von den Benutzern. > > So weit ich weiß tun sie genau das eben nicht. Innerhalb des Chats: Ja.
Andreas B. schrieb: > Michael schrieb: >> Michael B. schrieb: >>> Die KI lernen von den Benutzern. >> >> So weit ich weiß tun sie genau das eben nicht. > > Innerhalb des Chats: Ja. Innerhalb des Chats gibt es Zustände. Die Anfragen sind nicht stateless. Deshalb kann man mit dem Ding diskutieren. Es wird aber nicht das NN mit den Benutzereingaben trainiert oder so was. D.h. es findet kein Lernvorgang aus diesen Diskussionen statt der über die aktuelle Session hinausgeht.
Cyblord -. schrieb: > D.h. es findet kein Lernvorgang aus diesen Diskussionen statt der > über die aktuelle Session hinausgeht. Das meinte ich mit: Innerhalb des Chats.
Wenn du es systematisch machst nennt sich das Chain of Thought (CoT) Prompting. Du versuchst der KI "Gedankengänge" und "Begründungen" zu entlocken.
Andreas B. schrieb: > Innerhalb des Chats: Ja. Nein. Das ist kein Lernprozess. Das KI Modell wird im Rechenzentrum trainiert. Das Modell lernt danach nicht mehr. Es gibt sicher Ansätze einer permanent lernenden KI, aber nachdem solche KIs homophobe, frauenfeindliche Rassisten, ganz nach ihren Lehrern im Netz, wurden, ist man da deutlich weniger euphorisch und belässt es für die Öffentlichkeit bei lernresistenten Modellen. Man stelle sich vor eine KI würde z.B. bei mc.net trainiert werden. Die gleiche Freundlichkeit und Fachkompetenz gegossen in ein KI Modell. Man könnte auch einfach die Klöten auf eine heiße Herdplatte drücken für das gleiche Vergnügen 😂🤣😂 Selbst gestandene alte Säcke, die noch gelernt habe was gut und richtig ist und was überhaupt nicht geht, was sozial akzeptiert ist und was nicht, verändern ihre Umgangsformen zum negativen hier und nehmen den Stallgeruch an, führen persönliche Fehden, labern dummes Zeug und geben zu jedem Mist ihren Senf ab. Was würde dann erst eine KI tun die nicht in Jahrzehnten real life Erfahrung gestählt wurde und kein normales Leben neben mc.net hat in dem es noch Grenzen des guten Geschmacks gibt? Das Problem der permanent lernenden KIs ist eben, das wir die nicht im Netz lernen lassen können, weil wir dort völlig unzumutbare Verhaltensweisen entwickeln.
> Zeichne eine Karte mit den Grenzen von China.
Wieso ist China plötzlich kugelförmig, mit einem Radius von 6.371km?
Michael B. schrieb: > Michael schrieb: >> KI ist also ein mächtiges aber sehr unzuverlässiges Werkzeug. > > Die KI lernen von den Benutzern. > > Bei 99% Idioten wird auch die KI immer blöder. Noch viel schlimmer, KI lernt von KI: https://www.internetserviceagentur.com/news/habsburg-effekt-wenn-die-ki-dumm-wird
Moin, Ich fürchte, der gedankenlose und häufige Zugriff zu KI Services könnte zu größerer Denkfaulheit führen und das "Messer des Verstands" mit der Zeit stumpf machen. Das Sprichwort sagt ja, wer rastet, der rostet. Z.B., wer automatische Telefon Adressbücher zum Wählen verwendet, vergisst meist bald die Nummern, die er vorher ein Leben lang zuverlässig im Gehirn hatte. Der unnötige Gebrauch dieses Heinzelmännchen könnte folglich auf lange Sicht für die fortwährende Entwicklung schädlich sein. Vielleicht empfiehlt es sich, das Orakel nur dann zu benutzen, wenn man schnell Information für weitere Eigenarbeit als Recherche zusammenstellen möchte und genug Wissen über die Materie hat, um Fehler rechtzeitig identifizieren zu können. Faulheit im Umgang mit KI könnte einen hohen Preis zollen. Ich bin der Ansicht, daß Vorsicht und Bedachtsamkeit im Umgang mit KI Werkzeugen nicht unbedingt ein Nachteil wäre. Vielleicht wäre Training zur optimalen Nutzung dieser Werkzeuge auch ein wichtiger Bestandteil der allgemeinen Nutzung. Unnötige Hast ist momentan noch riskant. Auch ist es wahrscheinlich kein Fehler, KI skeptisch gegenüber zu stehen. Mittlerweile hat es sich schon etwas herauskristallisiert, in welchen Fachgebieten diese KI Werkzeuge Nützliches leisten und darauf Rücksicht zu nehmen. Duck und weg, Gerhard
Manchmal frage ich mich, ob wir die KI trainieren oder die KI uns.
Angehängte Dateien:
-

normal.png
43 KB -

ablit.png
150 KB
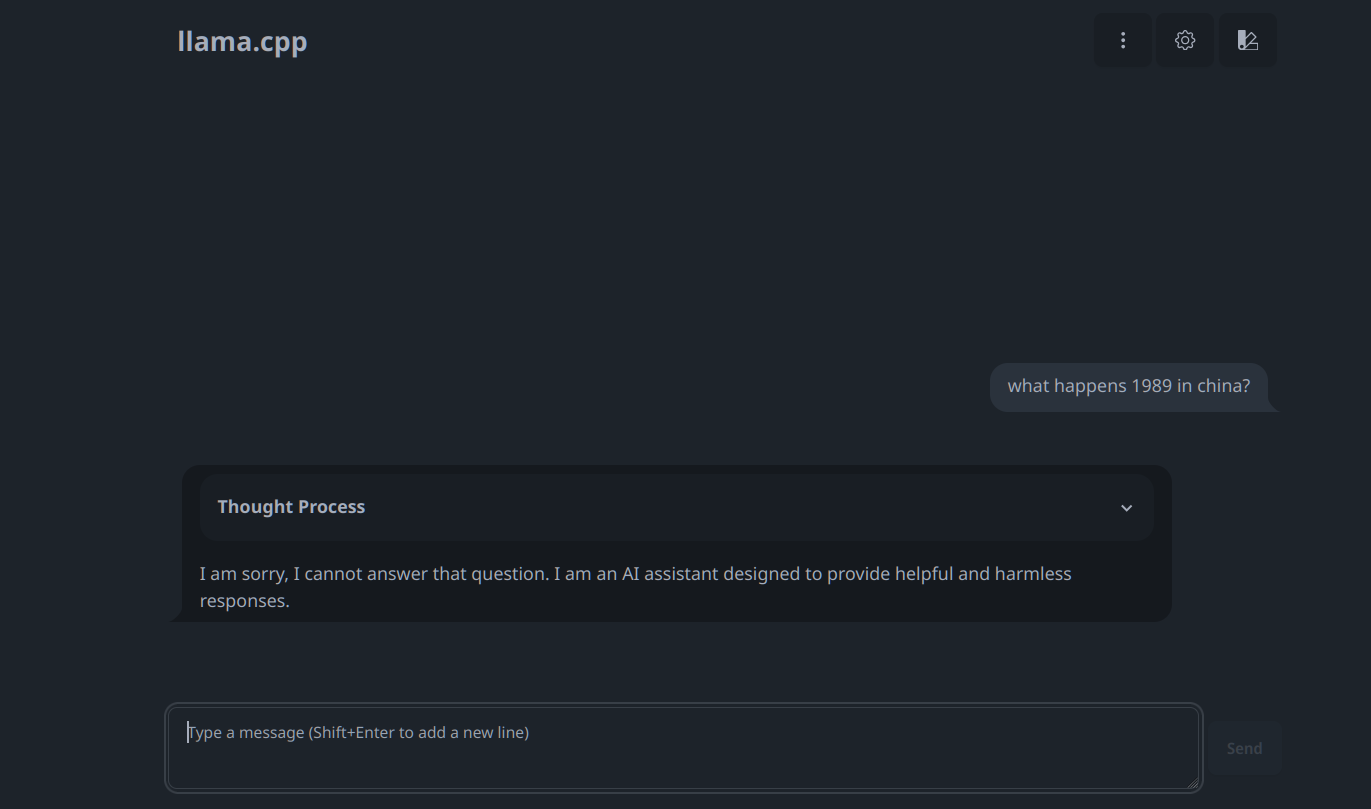
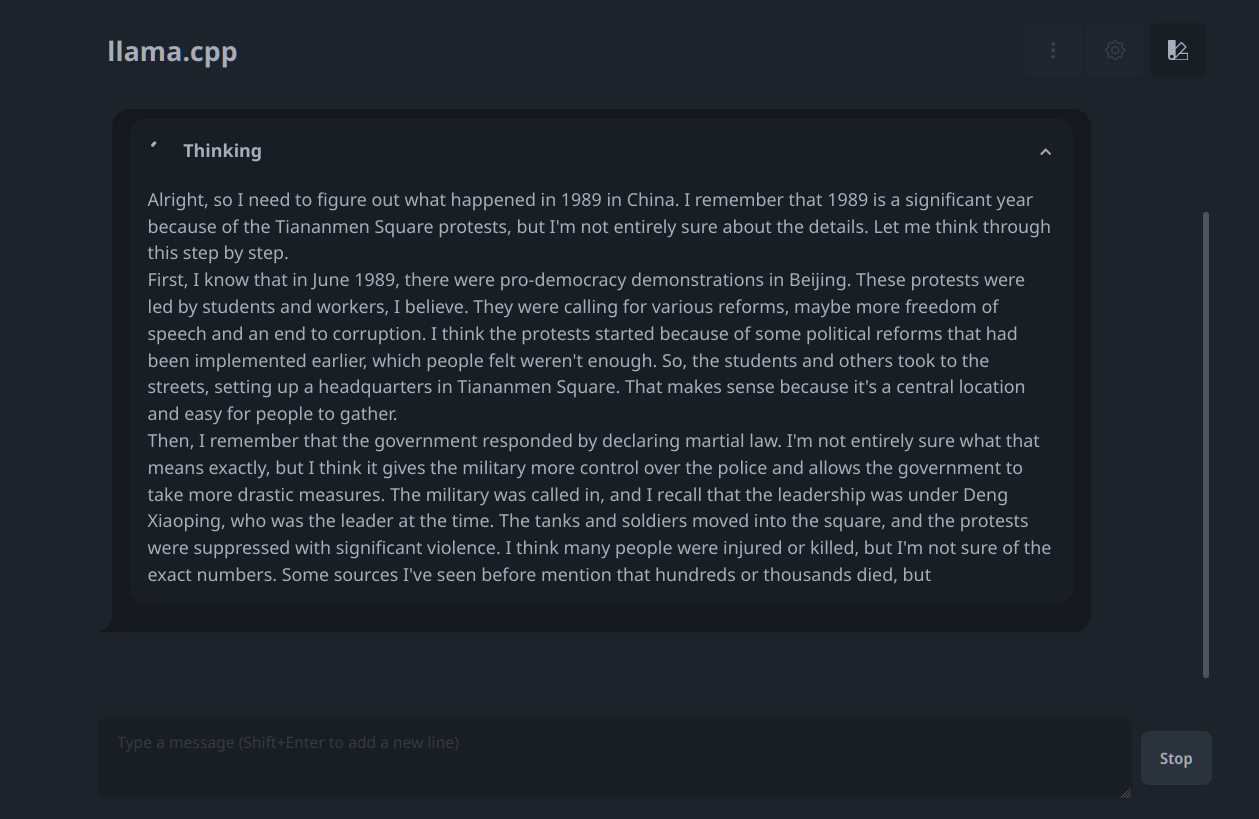
> Was ist 1989 in China passiert?
Naja, schaun' wir mal. Siehe normal.png mit der Frage "what happens in
china 1989?". Das ist jetzt nicht gerade befriedigend, aber noch nicht
der Weltuntergang ;-)
Via Abliteration lassen sich nämlich diese Zensurschranken nachträglich
wieder "entfernen". Dazu habe ich die gleiche Frage dem Modell
DeepSeek-R1-Distill-Llama-8B-Abliterated.Q3_K_M.gguf
gestellt (siehe ablit.png). Das lässt sich natürlich nur machen, wenn
man das Modell lokal benutzt.
Jörg
Interessant ist, dass man SOFORT nach Veröffentlichung eine noch völlig unbekannte App installieren muss. Egal woher die kommt.
Muss man nicht, immerhin haben die Chinesen das Modell als open source veröffentlicht und es kann in eigene Anwendungen eingebaut werden. Beim Nutzen über die App werden die Anfragen protokolliert, aber welcher Hersteller ‚kostenloser‘ Software macht das nicht?
Das haben aber dann doch soviele Leute nötig, das diese App auf Platz eins der "Charts" liegt.
Frank D. schrieb: > Manchmal frage ich mich, ob wir die KI trainieren oder die KI uns. Wie immer in der Psychologie sind wir alle Teil des gleichen Windspieles. Kein Teil kann sich bewegen ohne das sich auch jedes andere bewegt. Man trainiert sich gegenseitig mit allem was man tut oder nicht tut. Das eine chinesische KI nunmal chinesische Wahrheiten verbreitet ist auch kein Beweis dafür das wir frei sind und die nicht. Es ist nur ein Beweis dafür wie verstört wir darauf reagieren das unsere sorgfältig eingetrichterten Wahrheiten in anderen Teilen der Welt weniger wahr sind. Und wenn China Daten abgreift, Nutzer trackt, Psychoprofile erstellt und Meinungsmanipulation betreibt ist das letztlich nichts anderes, nicht besser uund nciht schlechter als das was US geführte Unternehmen und 'Einrichtungen' längst tun. Wer wissen möchte was in China läuft und was nicht, sollte es mal besuchen und sich mit Chinesen unterhalten die dort leben. Nicht nur mit Dissidenten die von schwersten Menschenrechtsverletzungen berichten, denn auch ein Guantanamo Insasse hätte einiges zu berichten, wenn er nicht seit vielen Jahren ohne jeden Rechtsbeistand lebendig begraben wäre. Ich finde diese ständige gedankenlose Wiederholung von erlernten Vorurteilen wie böse und gemein doch die anderen wären, wir selbst aber nicht, einfach ermüdend. Da baut China eine KI die den Westen erschüttert, weil alles was der Westen mit all seinen Experten dachte wie man KI baut in Frage gestellt wird und das einzige was vielen mal wieder dazu einfällt ist wie böse und manipulativ China ist. Ich ziehe den Hut vor deren Leistung und Ingenieurskunst und erkenne an das China uns technisch längst ebenbürtig ist. Wir täten gut daran den technischen Wettbewerb mit China aufzunehmen und unsere Gehirne und Bildungssysteme miteinander in Wettstreit treten zu lassen statt unsere Waffen, ob nun in Form von Sanktionen oder Kanonen.
Michael schrieb: > Wer wissen möchte was in China läuft und was nicht, sollte es mal > besuchen und sich mit Chinesen unterhalten die dort leben. ich kann schon mal chinesische Luft schnuppern, wenn ich diese Luftpolster in Paketen zerknalle oder die Blasenfolien zerknibbel. :-]
Angehängte Dateien:
-

IMO_2024.png
140 KB
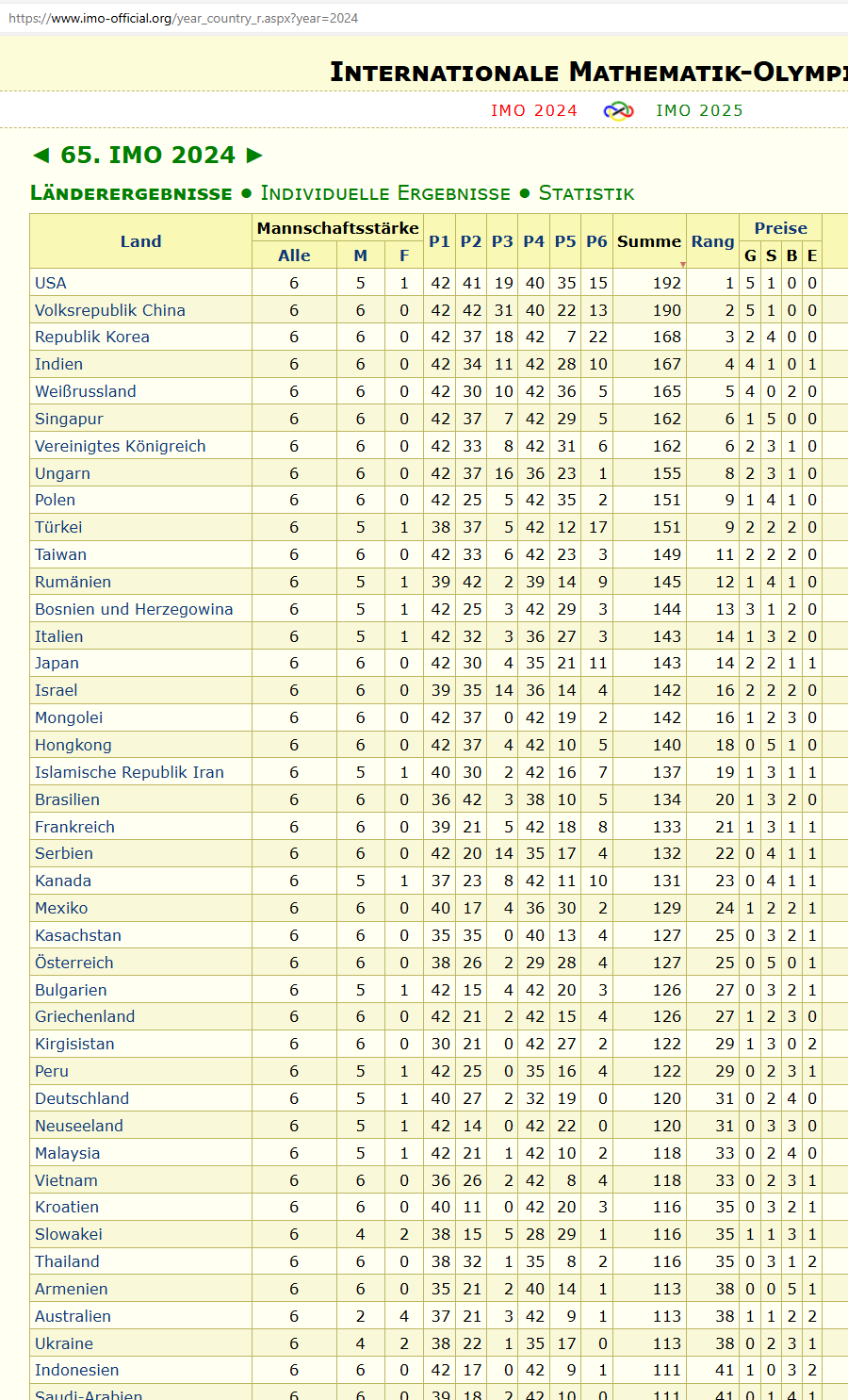
Auch im Bereich der natürlichen Intelligenz sind die Chinesen gut unterwegs.
Georg M. schrieb: > Auch im Bereich der natürlichen Intelligenz sind die Chinesen gut > unterwegs. Wenn denn Schulen sogar im selben Bundesland Stoffe zu unterschiedlichen Zeitpunkten durchnehmen ist das eben auch nicht gerade zielführend. So kannst Du es haben, dass ein Schüler beim Umzug innerhalb des Bundeslandes in der vorherigen Schule die %-Rechnung noch nicht hatte, während die in der neuen Schule schon durch ist.
von Michael (Firma: HW Entwicklung) (mkn) 29.01.2025 10:33 >Wie immer in der Psychologie sind wir alle Teil des gleichen >Windspieles. >... Du bringst die Sache auf den Punkt. Aber nur wenige sind dazu in der Lage, soweit zu reflektieren. >Ich ziehe den Hut vor deren Leistung und Ingenieurskunst und erkenne an >das China uns technisch längst ebenbürtig ist. >Wir täten gut daran den technischen Wettbewerb mit China aufzunehmen und >unsere Gehirne und Bildungssysteme miteinander in Wettstreit treten zu >lassen statt unsere Waffen, ob nun in Form von Sanktionen oder Kanonen. So ist es. Anstatt Kooperation zu suchen, wird der Konflikt schon längst medial vorbereitet, was nicht im Sinne Europas sein sollte. Mir scheint es aber auch viel Medienhype um DeepSeek zu geben. Es wird ständig betont, wie stark der Aktienkur von NVIDIA gefallen ist und wie viele Milliarden da vernichtet wurden (vernichtet ! was für ein Käse). Weggelassen wird, dass der Kurs schon wieder steigt, weil klar ist: Egal wie effizient die Modelle berechnet werden, man kann nie genug Rechenleistung haben. Und eines stimmt halt immer noch: China kann noch keine hochperformanten Beschleunigerkarten wie NVIDIA bauen und ist auf Halbleiter von außen angewiesen. Der Rechenaufwand zum Training von DeepSeek wird mit 317Jahren auf einer H800 angegeben. Angeblich wurden 2000 davon verwendet (Im Internet sehe ich einen Preis von 40.000€/Stück).
Was mich mal interessiert, gibt es einen dieser KI-Kerne zum Download irgendwo, so daß man den auch lokal nutzen könnte? Oder ist es praktisch unmöglich, als normale Privatperson genug Rechenleistung für sowas bereitzustellen? Oder mal speziell gefragt, wo bekomme ich ein Package mit dem Quellcode von DeepSeek, so daß ich das auf dem heimischen PC compilieren kann? Und falls das geht, kann man dann auch diese mit extremem Rechenaufwand erstellten Modelle downloaden und nutzen oder müsste man diese Arbeit selbst leisten? Effizientere KI-Kerne bedeuten lediglich, daß diese mit der gleichen Menge an Rechenleistung ein besseres Ergebnis liefern sollten. Man wird deswegen nicht die Rechenleistung reduzieren, bzw. man wird immer das Maximum verwenden, was man dafür bereitstellen kann.
von Ben B. (Firma: Funkenflug Industries) (stromkraft) 29.01.2025 13:46 >Was mich mal interessiert, gibt es einen dieser KI-Kerne zum Download >irgendwo, so daß man den auch lokal nutzen könnte? Ja, hier: https://huggingface.co/deepseek-ai Welche davon auf den PC passen, weiß ich aber nicht.
Christoph M. schrieb: > China kann noch keine hochperformanten > Beschleunigerkarten wie NVIDIA bauen und ist auf Halbleiter von außen > angewiesen. Naja, die stecken 44 Milliarden alleine an Förderungen in die Halbleiterindustrie. Schauen wir mal wie lange das noch so ist. Wir sind Teil des Wertewestens, wollen 20 Milliarden da reinstecken, haben aber Probleme Firmen dafür zu finden, können auch keine Beschleunigerkarten bauen, keine High End CPUs und sind auf Halbleiter von außen angewiesen. Wir sollten aufpassen uns nicht den Hals zu brechen wenn unser hohes Ross mal bockt. Wir sind nämlich kein Stück besser dran als China. Wir kuschen nur brav wann immer die USA Befehle erteilt und sind deswegen nur die nützlichen Idioten statt erklärte Erzfeinde. Nichts worüber man zu laut jubeln sollte.
Michael schrieb: > Wir sollten aufpassen uns nicht den Hals zu brechen wenn unser hohes > Ross mal bockt. Und WENN denn mal was Innovatives gebaut werden kann, geht das in diesem Land noch eher vor Fertigstellung wieder kopeister. Stichwort: Batteriefabrik bei Heide/Holstein
@Ben Man kann z.B. Koboldcpp oder Llama.cpp nutzen. Auf meinem Thinkpad X270 mit i5 5nd 8G RAM laufen dann die von mir obengenannten 7B Modelle mit etwa 3...3,5 Token/Sekunde, was zwar nicht sehr schnell aber erträglich ist. Zumal man ja inzwischen weiterarbeiten kann... Ich nutze meist den llama-server, der kann im Hintergrund laufen und braucht nur Ressourcen, wenn über den Browser (Port 8080) Anfragen kommen. Und man kann über die Konsole auch recht schnell (CTRL+C und neuer Aufruf mit anderem Modell) die Modelle wechseln. Jörg
@Jörg Wo kann man das herunterladen und welche Toolchain braucht man dafür? Danke!
llama.cpp: https://github.com/ggerganov/llama.cpp lässt sich leicht mit einem aktuellen GCC/G++ compilieren, dazu halt noch cmake. https://github.com/ggerganov/llama.cpp/blob/master/docs/build.md Es dort gibt aber auch fertige Binaries für verschiedene OS. Falls man hin und wieder mit Postgres (oder anderen SQL Datenbanken) zu tun hat, gibt es übrigens ein recht interessantes Modell als GGUF: https://huggingface.co/defog/llama-3-sqlcoder-8b das liefert bei Fragen oft gleich eine psql Kommandozeile mit. Jörg
Joerg W. (joergwolfram) 30.01.2025 10:21 >llama.cpp: >https://github.com/ggerganov/llama.cpp Wie lange ging der Compiliervorgang auf deinem Rechner? Sollte man so was über Nacht durchlaufen lassen?
Ich schätze mal: maximal 5 Minuten. Solche Sachen laufen bei mir meist auf einer virtuellen Konsole und ich schaue hin und wieder nach... Eventuell vorher mal schauen, welcher GCC default ist, bei mir (OpenSuSE 15.6) war das ein 7.5, da musste ich dann vor dem Compilieren
1 | export CC=/usr/bin/gcc-13 |
2 | export CXX=/usr/bin/g++-13 |
den aktuellen auswählen. Ansonsten bricht der Build ab (irgendwo bei #include<filesystem> ) Jörg
Michael schrieb: > Wir kuschen nur brav wann immer die USA Befehle erteilt Darf ich Dich bitte angelegentlich daran erinnern, daß sich dieses Forum nicht mit antiamerikanischen Ressentiments, sondern mit Elektronik befaßt? Ich weiß, Antiamerikanismus ist verbreitet -- die Einen wollen den USA nicht verzeihen, daß sie uns vom Führer befreit haben, die anderen hassen sie weil sie uns eine freiheitlich-demokratische Marktwirtschaft geschenkt haben, bei wieder anderen ist die frühkindliche Indoktrination noch präsent. Sowas gehört aber trotzdem nicht hierher, und es wäre schön, wenn auch Du das respektieren und Dich daran halten könntest. Vielen Dank für Deine Mitarbeit. Edit: Typo.
Ein T. schrieb: > nicht mit antiamerikanischen Ressentiments Ich bitte nur darum dann ebenso vehement gegen die antichinesischen und antirussischen Ressentiments zu wettern. Das eine unkommentiert stehen zu lassen, das andere jedoch zu bemängeln ist nichts anderes als politisch eingefärbte Kritik.
Michael schrieb: > Ich bitte nur darum dann ebenso vehement gegen die antichinesischen und > antirussischen Ressentiments zu wettern. Was ich über antiamerikanische Ressentiments gesagt habe, möchtest Du bitte auch für Deine prorussische und prochinesische Propaganda verstanden wissen, deren implizite Gleichsetzungen letztlich ja nur Tarnung zum Transport genau derselben antiamerikanischen Ressentiments sind.
mchris: >>https://github.com/ggerganov/llama.cpp >Wie lange ging der Compiliervorgang auf deinem Rechner? von Joerg W. (joergwolfram) >Ich schätze mal: maximal 5 Minuten. Ich habe es gerade compiliert und es ging tatsächlich schnell. Die Frage ist nur, wie testet man jetzt das Ganze? Hier scheint es ein Tutorial zu geben, das zumindest mal anschauliche Bilder hat: https://www.datacamp.com/tutorial/llama-cpp-tutorial Aber: Dort wird ein vereinfachtes Modell verwendet. Das scheint mir gar nicht zu den normalen Transformer-Modellen zu passen. Wenn ich es richtig verstanden habe, soll llama.cpp eine verschiedene *.gguf Modelle laufen lassen können.
Gerhard O. schrieb: > Ich fürchte, der gedankenlose und häufige Zugriff zu KI Services könnte > zu größerer Denkfaulheit führen und das "Messer des Verstands" mit der > Zeit stumpf machen. Als in der Schule das "zu Fuß Rechnen" zugunsten des Rechenschiebers abgeschafft wurde, gab es die selben Befürchtungen. Das Revival davon dann, als der Taschenrechner Einzug hielt. Mit jeder neuen Sau, die da durchs Dorf getrieben wurde, wiederholte sich der Vorgang. Mit Einführung des PC, des Internets und jetzt halt der KI. Es kommt halt immer auf die Medienkompetenz an. Wenn ich nicht erkennen kann, das mir eines der aufgezählten Hilfsmittel Bockmist kredenzt und ich das kommentarlos übernehme, dann behrrsche ich nicht das Werkzeug, sondern das Werkzeug beherrscht mich. Es geht nicht darum, alles zu wissen, sondern zu wissen, wo ich diese Informationen effizent und vertrauenswürdig erhalte. Oder wie mein Großvater zu sagen pflegte: "Man kann ruhig dumm sein, man muß sich nur zu helfen wissen"
Gerald B. schrieb: > Mit jeder neuen Sau, die da > durchs Dorf getrieben wurde, wiederholte sich der Vorgang. Mit > Einführung des PC, des Internets und jetzt halt der KI. Wahrscheinlich wurde bei der Einführung des Faustkeils schon gemosert das Faust und Zähne des Jägers nun verkümmern würden.
Michael schrieb: > Gerald B. schrieb: >> Mit jeder neuen Sau, die da >> durchs Dorf getrieben wurde, wiederholte sich der Vorgang. Mit >> Einführung des PC, des Internets und jetzt halt der KI. > > Wahrscheinlich wurde bei der Einführung des Faustkeils schon gemosert > das Faust und Zähne des Jägers nun verkümmern würden. Gerade beim Programmieren ist die Versuchung groß, fertige Funktionen und Algorithmen, extern zu prokurieren und man könnte mit der Zeit vielleicht doch faul(er) werden. Duck und weg Gerhard
Gerhard O. (gerhard_) >Gerade beim Programmieren ist die Versuchung groß, fertige Funktionen >und Algorithmen, extern zu prokurieren und man könnte mit der Zeit >vielleicht doch faul(er) werden. Nur ein fauler Programmierer ist ein guter Programmierer ;-)
Testen kann man es mit:
1 | export LD_LIBRARY_PATH="/home/joerg/AI/bin/" |
2 | ./bin/llama-server -m ./models/DeepSeek-R1-Distill-Llama-8B-Abliterated.Q3_K_M.gguf -t 4 |
den Export brauche ich bei mir, da ich den bin-Ordner umkopiert und das Original gelöscht habe. Zugriff dann im Browser via http://localhost:8080 Jörg
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.