Guten Morgen, das papierarme Büro kommt bei mir immer wieder an die gleiche Grenze: Echte Ordner lassen ich einfach besser durchsuchen als Dateiordner mit gescannten PDF-Dateien. Letzteres ginge zwar super, wenn alles perfekt verschlagwortet wäre, aber leider ist das nicht der Fall. Die Dokumente mehrerer Jahrzehnte entsprechend systematisch aufzuarbeiten ist ja auch keine echte Option. Sehr viele Suchoptionen sind ja: "Ich suche das Schreiben, an das das rosafarbene Formular in der charakteristischen Form angehängt war" oder "Ich suche den Prospekt mit dem gelben Bagger auf der dritten Seite". Beim echten Ordner blättert man bis zum nächsten Blatt mit dem entsprechenden Farbeindruck und hat sehr schnell das entsprechende Dokument gefunden. Außerdem das Dokument davor und danach. Bei einem Verzeichnis voller PDF-Dokumente ist visuell nur die erste Seite sichtbar, da funktioniert die Methode nicht. Gibt es ein Art PDF-Datei-Browser, in der sich Verzeichnisse/Verzeichnisstrukturen auf diese herkömmliche Art gut durchsuchen lassen? *TLDR*: Ich suche einen PDF-Viewer, mit dem sich ganze Verzeichnisse/Verzeichnisbäume visuell durchsuchen lassen.
Ich denke, Dokument-Management und OCR sind die Schlüsselwörter, nach denen du suchen solltest. Da wird sehr viel als Cloud-Dienst angeboten, ich würde allerdings nur lokale Lösungen akzeptieren.
Walter T. schrieb: … > Die Dokumente > mehrerer Jahrzehnte entsprechend systematisch aufzuarbeiten ist ja auch > keine echte Option. Und warum nicht? Lass da sinnvolle OCR-Batches drüber laufen und schon kannst du deine ganzen Teile nach Wörtern und Wortkombinationen durchsuchen. Das geht deutlich besser als sich manuell optisch durch tausende Dateien durchwühlen zu müssen. Sonnigen Tag!
Ove M. schrieb: > Lass da sinnvolle OCR-Batches drüber laufen und schon > kannst du deine ganzen Teile nach Wörtern und Wortkombinationen > durchsuchen. Been there - done that. Die Fehlerquote ist hoch und es funktioniert nur, wenn man ein selektives Suchwort findet, das in nicht zu vielen Dokumenten vorhanden ist und gerade in dem gesuchten Dokument richtig erkannt wurde. Drittes Anwendungsbeispiel: Application Notes, bei denen die erste Seite nur noch "Fairchild Is Now Part of ON Semiconductor" lautet, das visuelle Unterscheidungsmerkmal auf Seite 2 ist und aus deren PDF-Dateien sich nur mit viel Aufwand Seiten löschen lassen.
Bei irfanview kann man Miniaturansichten (Thumbnail, Kontaktabzug?) drucken, das ist ganz praktisch, weil dann z.b. statt 60 Bildern nur 1 Bild (eine Datei) geöffnet werden muss. Sowas automatisiert? Weiß nicht, ob irfan PDF so verarbeiten kann. PDF mit mehreren Seiten/Blatt neu in PDF drucken*? Screenshot von der Seitenanzeige? Klar, das sind nur Krücken, der Link zum Dokument ist dann weg & kostet zusätzlichen Speicherplatz. * Luxusversion: diesen Miniatur-Audruck als zusätzlich erste Seite vor das Original, geht mit sowas wie pdfsam split and merge Irgendwas ist hier "so schlau" und macht aus dem Sternchen * für eine Fußnote eine Aufzählung, hurra
Das klingt (theoretisch) nach einer Aufgabe, die wohl mit KI gut zu lösen wäre. Ich kenne da allerdings bisher nichts Fertiges, schon garnicht ohne Cloud ... Wäre sicher ein gutes Software-Projekt, falls jemand bereit ist, die Entwicklungskosten zu tragen. KIs mit beachtlicher Intelligenz kann man inzwischen auch lokal betreiben, man sehe sich z.B. mal die Projekte - GPT4All - Faraday.dev - Open WebUI - Ollama u.v.a. an. Bei denen handelt es sich quasi um Ausführungsumgebungen für LLM, von denen es inzwischen tausende bei huggingface.com zum download gibt, darunter auch welche, die mit Bildern (und damit OCR) umgehen können. Insebsondere GPT4All gestattet es, eigene Dokumente der KI zur Kenntnis zu geben. Auf deren Inhalte wird dann bei Antworten Bezug genommen. Falls die verwendeten PDFs nicht durch Scannen, sondern direkt aus einer Textverarbeitung stammen (z.B. Word), ist der ursprüngliche Text in Originalform lesbar enthalten, man spart sich also das OCR. Z.B. mit der "Apache PDFBox" kann man den Text mühelos extrahieren und einer Indizierung/Verschalgwortung zuführen. Ich würde bei einer solchen Software alle möglichen Methoden kombinieren wollen. Wäre doch gelacht, wenn man so den Wünschen des TO nicht ziemlich nahe kommen könnte ... theoretisch.
Frank E. schrieb: > KIs mit beachtlicher Intelligenz kann man > inzwischen auch lokal betreiben Das kostet dann eine halbe Millionen Euro plus einen Spezialisten, der das Ding am Laufen hält. -> darum gibt es die Cloud Dienste
Wie wäre es mit einem (sehr) großen Monitor auf dem sich vielleicht 50 PDF's gleichzeitig als Tumbernails betrachten lassen. dazu ein Dateimanager der das macht.
Nachtrag: Der Mensch kann visuell sehr viel schneller suchen, als durch das Lesen irgendwelcher Überschriften. Besorg dir doch mal einen PDF-Viewer, der beim Herunterstellen des Abbildungsmaßstabes mehrere Seiten auf einmal darstellt (sog. Miniaturen). So finde ich optisch oft Gesuchtes sehr viel schneller ... Ich mache das auch oft bei Google-Suchen so: Ich bemühe zunächst die Bildersuche, falls das Thema dafür geeignet ist. Hilft zwar nicht immer, aber oft genug, um es immer wieder zu versuchen. Bräuche man nur noch eine Software, die Miniaturen aus mehreren PDF-Dokumenten gleichzeitig darstellen kann ... gibts nicht? Selber machen. Ein möglicher Ansatz: Seit einiger Zeit gibt es das Projekt "pdf.js", das ist ein komplett in Javascript geschriebener (und damit in jedem Browser einsetzbarer) PDF-Renderer. Frei zu laden, zu konfigureren, zu verwenden ... wenn es auch etwas kosten darf: Die Lib "DynaPDF", gibts quasi für alle Plattformen und IDEs/Sprachen. Die kann noch sehr viel mehr als Rendern, aber eben auch das. Rendern: (Temporäres) Umwandeln einer PDF-Seite in eine darstelbare Pixelgrafik für die Anzeige.
Sherlock 🕵🏽♂️ schrieb: > Frank E. schrieb: >> KIs mit beachtlicher Intelligenz kann man >> inzwischen auch lokal betreiben > > Das kostet dann eine halbe Millionen Euro plus einen Spezialisten, der > das Ding am Laufen hält. > > -> darum gibt es die Cloud Dienste Das war gestern. Sorry, aber solange da nicht Teusende User gleichzeitig dranhängen ist das schlicht Unfug. Probier doch einfach mal - kost nix. Läuft sogar auf einem mittelmäßigen Notebook (mind. 8GB RAM). Wir haben im Büro extra für unsere Praktikanten ein System am Laufen, dass zumindest von der Geschwindigkeit her, (bei Text-Chats) dem ChatGPT absolut ebenbürtig ist: - Acer Ganmingboard mit Intel i7 3GHz, 32GB RAM, 2TB SSD - gebrauchte Grafikkarte RTX3060 (ca. 150,-) - Open WEBUI mit einem 16GB-LLM (die wechseln immer mal), zur Zeit nutzen wir den frischen Chinesen (DeepSeek R1) Geht ab wie Schmitts Katze. Durch Nutzen der API kann man dessen Fähigkeiten rel. problemlos in eigene Anwendungen integrieren.
Hallo Walter T. Walter T. schrieb: > das papierarme Büro kommt bei mir immer wieder an die gleiche Grenze: > Echte Ordner lassen ich einfach besser durchsuchen als Dateiordner mit > gescannten PDF-Dateien. Das ist eine Erschwernis aber kein "NoGo" in Bezug auf geringe Papierverwendung. > Letzteres ginge zwar super, wenn alles perfekt > verschlagwortet wäre, aber leider ist das nicht der Fall. Richtig. Ich behelfe mich damit, sprechende Dateinahmen zu verwenden. Man sollte sich aber vorher eine Methodik dazu überlegen. Grundsätzlich für Dokumente bei mir: ZweckOderKategorie_Spezialisierung1_Spezialisierung2_SpezialisierungX_Fa llsNoetigSeitenangabeMitGesamtanzahlDerSeiten_Datum.DateiTypischerSuffix z.B. Lohnabrechnung_UnternehmensName_MeinName_S1v4_07Jul2009.pdf Aus Kompatibilitaetsgruenden werden nur die Buchstaben (groß und klein) A-Z, die Ziffern 0-9 und Bindestrich, Tiefstrich und der Punkt verwendet. ä wird durch ae ersetzt, analog ö durch oe und ü durch ue. ß wird durch ss ersetzt. Das Leerzeichen wird nicht verwendet. Alle Dateisysteme mit denen ich umgehe unterstützen zwar wesentlich mehr an Möglichkeiten, aber man kann ja nie wissen, auf was man mal stösst, und wenn ein System z.B. ein Fragezeichen unterstützen würde und ein anderes nicht, kann man beim Kopieren in Probleme laufen Es wird bei mehreren Wörtern der CamelCase (BinnenMajuskel) verwendet. Grund: Austerität - Dateinahmen können nur eine begrenzte Länge haben. Sprechende Dateinahmen werden eh schon Lang, und auf Abkürzungen sollte man besser verzichten, weil schnell undurchsichtig. Seitenangabe mit Angabe der Gesamtseitenzahl, damit man erkennt ob etwas fehlt. Bei Buechern/Datenblaettern/ApplicationNotes oder vergleichbarem lasse ich die Seitenzahl weg. Datumsangabe in der Form TageszahlMonatsabkürzunJahreszahl. Es gibt zwar eine Norm dafür, aber die vergesse ich immer. Und in der angegebenen Form ist alles gut erratbar. Der Monat in Buchstabenabkürzung ist eindeutig von der Tageszahl in Ziffern zu unterscheiden (Unterscheidung 7. eines Monats vom Jul) , und die Tage vom Jahr, weil sie durch Buchstaben getrennt sind, und die Tage 2 stellig und das Jahr vierstellig. Buechern/Datenblaettern/ApplicationNotes haben die Dateinamenstruktur: Titel-OptionaleErgaenzung_Revisionsnummer_ZweckOderKategorie_AutorAutore nOder-Herausgeber_DokumentID_Datum.DateiTypischerSuffix Beispiel: FundamentalsOfGalliumNitridePowerTransistors-GaN_Applikation_Luedenschei dMueller-BaeckerzeitungFuerElektronik_snyp0814_Apr2011.pdf Beim Titel und dessen optionaler Ergaenzung muss ich gelegentlich Mut zur Luecke haben, weil z.B. Bachelor- Master- oder Diplomarbeiten und Dissertationen oefters irre lange Titel haben. Die Revisions- oder Auflagenbezeichnung ist optional. Oft ist das keine gute Unterscheidung, weil z.B. die erste Auflage nicht explizit genannt ist, weil zu diesem Zeitpunkt noch nicht klar war, das weitere Auflagen folgen. Darum ist eigentlich eine Unterscheidung nach dem Datum besser. Bei Autoren nur den Nachnamen (oft schwer zu erkennen). Wissenschaftliche Abhandlungen haben oft dutzende von Autoren. Wenn es zu viele werden, den HerausgeberEtAl. Viele Dokumente (z.B. die Datenblaetter und Applikationen von Motorola, TexasInstruments bzw. deren Nachfolgeorganisationen) haben eine explizite Dokumenten Identitaetsnummer. Bei Buechern kann das auch die ISBN Nr. sein. Beim Datum im allgemeinen das Erscheinungsdatum. Wird leider nicht immer explizit angegeben. Bei Artikeln oder Dissertationen kann es ganz kompliziert werden, weil mehrere Daten existieren. z.B. Datum der Einreichung, der Aktzeptierung oder der Verteidigung existieren. Da diese im allgemeinen einige Monate auseinanderliegen bietet ein Datum davon aber schon einen Ansatz, das vorhergehende und das folgende Jahr zu untersuchen. > Die Dokumente > mehrerer Jahrzehnte entsprechend systematisch aufzuarbeiten ist ja auch > keine echte Option. Richtig. Bei mir ist auch viel aufgelaufen. Ein erster Schritt ist beim Aufarbeiten das Ablegen in Dateiordnern die eine Vorsortierung geben, wie z.B. Datenblaetter, DatenblaetterTransistoren, DatenblaetterDioden, DatenblaetterMOSFET, ApplikationNotesTransistoren ec. Mühsam ernaert sich dass Eichhoernchen. > Sehr viele Suchoptionen sind ja: "Ich suche das Schreiben, an das das > rosafarbene Formular in der charakteristischen Form angehängt war" oder > "Ich suche den Prospekt mit dem gelben Bagger auf der dritten Seite". Da musst Du noch auf eine gut trainierte KI warten. ;O) > > Beim echten Ordner blättert man bis zum nächsten Blatt mit dem > entsprechenden Farbeindruck und hat sehr schnell das entsprechende > Dokument gefunden. Außerdem das Dokument davor und danach. > > Bei einem Verzeichnis voller PDF-Dokumente ist visuell nur die erste > Seite sichtbar, da funktioniert die Methode nicht. Du bist Visuell-Bildorientiert, ich dagegen Visuell-Textorientiert. Wenn PDF neu angelegt wurden, funktioniert auch eine Suche nach Text gut. Bei eingescannten Dokumenten geht das nicht oder nur eingeschränkt wenn OCR verwendet wurde. Letzteres kann aber auch Fallen bilden, wenn Buchstaben nicht richtig erkannt werden. Ich hatte einmal den Fall, das in einem Artikel zu etwas bestimmten das Wort nirgendwo gefunden wurde, weil das Wort jedesmal falsch erkannt worden ist. Unabhängig davon ist eine Suche nach Textvariationen beliebter Rechtschreibfehler sinnvoll.... > Gibt es ein Art PDF-Datei-Browser, in der sich > Verzeichnisse/Verzeichnisstrukturen auf diese Herkömmliche Art gut > durchsuchen lassen? > > > *TLDR*: Ich suche einen PDF-Viewer, mit dem sich ganze > Verzeichnisse/Verzeichnisbäume visuell durchsuchen lassen. Meines Wissens gibt es so etwas noch nicht. "Visuelle Suche" halte ich sowieso für eine nicht so tolle Idee. Bei der Darstellung von Dateien waehle ich bei Dateibrowsern immer "Listendarstellung" und nie "Symboldarstellung" oder gar "Thumpnaildarstellung". Das pflastert mir den Bildschirm nur unübersichtlich zu. Meine "Workarounds": Alternativ durchsuche ich meine Ordner mit der Suchfunktion des Krusaders. Find und grep sind auch recht vielseitig und können z.B. auch regulaere Ausdruecke verwenden, was sehr komfortabel sein kann. find und grep sind Kommandozeilenprogramme, die sehr gut mit z.B. einem Pythonscript beschikt werden können, das eine gute grafische Hilfestellung gibt. Das Programm "Catfish" bietet ebenfalls eine graphische Benutzeroberflaeche und ist sehr komfortabel. Ich denke, das es unter Windows vergleichbares gibt Mit freundlichem Gruß: Bernd Wiebus alias dl1eic http://www.l02.de
Bernd W. schrieb: > Es gibt zwar eine Norm dafür Mach Dir einfach Deine eigene Norm, mit der Du zurechtkommst. Funktioniert bei mir seit Jahren. ;)
Walter T. schrieb: > > *TLDR*: Ich suche einen PDF-Viewer, mit dem sich ganze > Verzeichnisse/Verzeichnisbäume visuell durchsuchen lassen. Windows/Linux: XNViewMp mit den passenden Einstellungen um auch pdfs in der Übersicht darzustellen. Windows only PDFExcange Editor (auch die kostenlose Version) durchsucht pdfs nach Text, wenn nötig auch über ein ganzes Verzeichnis (= Laufwerk) hinweg. Ah ja - und PDFEdxchange kann auch halbwegs brauchbar OCR in pdfs erstellen... und es telefoniert IIRC nicht nach Hause.
Hallo Frank und Rene. Frank E. schrieb: > Der Mensch kann visuell sehr viel schneller suchen, als durch das Lesen > irgendwelcher Überschriften. Nicht "der Mensch" sondern Du und viele andere. Es gibt aber auch viele Leute, die sind nicht wie Du Visuell-Bildorientiert sondern Visuell-Textorientiert. Und ab einigen zehntausend Dateien hilft Dir eine Visuelle Sichtung nur im Abschluss einer vorherigen maschinellen Durchsuchung nach Text im Dateinahmen (oder Dokumententext) weiter. > Ich mache das auch oft bei Google-Suchen so: Ich bemühe zunächst die > Bildersuche, falls das Thema dafür geeignet ist. Hilft zwar nicht immer, > aber oft genug, um es immer wieder zu versuchen. Die Bildersuche verwende ich nur extrem selten. Voreingestellt im Browser als Tabulator ist aber die spezielle Suche https://www.google.de/advanced_search Google verwende ich aber nur wenn ich sonst nichts finde, weil Google sollte möglichst wenig über mich wissen.... Google ist leider nur wirklich gut im Suchen, wenn es viel aus meinen früheren Suchen kennt. Wenn ich also eine Historie anlege und alle Cookies zulasse, verwende ich dazu wenn möglich einem anderen Rechner mit anderer IP aus einer anderen Gegend. Ansonsten Startpage ( https://www.startpage.com/de/ ) oder direkt Bibliotheken durchsuchen. Gute Adressen: http://www.osti.gov/bridge/index.jsp http://www.everyspec.com/ https://armypubs.army.mil/default.aspx http://www.d-nb.de/ http://gdz.sub.uni-goettingen.de/gdz/ http://www.open-access.net/ http://www.scientific.net/ http://e-collection.library.ethz.ch/ https://www.deutsche-digitale-bibliothek.de/ http://thesis.library.caltech.edu/view/option/ https://www.1000dokumente.de/ https://www.gesetze-im-internet.de/ https://wikipedialibrary.wmflabs.org/ https://archive.org/ https://archive.org/details/nasa_techdocs https://archive.org/details/manuals https://archive.org/details/NASA_NTRS_Archive?&sort=-week&page=2 https://archive.org/details/europeanlibraries?&sort=-week&page=2 https://archive.org/details/europeanlibraries https://archive.org/details/bellsystem und https://www.dco.uscg.mil/Our-Organization/Assistant-Commandant-for-Prevention-Policy-CG-5P/Inspections-Compliance-CG-5PC-/Office-of-Investigations-Casualty-Analysis/Marine-Casualty-Reports/ https://www.sust.admin.ch/de/sust-startseite/ https://www.interfire.org/ https://www.kas-bmu.de/publikationen.html https://www.csb.gov/ http://www.eisenbahn-unfalluntersuchung.de/cln_032/sid_A8C3F590F4C5DE5CF0C2A88B57DEAEF1/EUB/DE/Home/homepage__node.html?__nnn=true https://www.bsu-bund.de/DE/Publikationen/Unfallberichte/Unfallberichte_node.html https://www.gov.uk/government/organisations/rail-accident-investigation-branch https://www.eisenbahn-unfalluntersuchung.de/SiteGlobals/Forms/Suche/Untersuchungsberichtesuche/Untersuchungsberichtesuche_Formular.html?gts=dateOfIssue_dt+desc&documentType_=Publication&sortOrder=dateOfIssue_dt+desc&cl2Categories_Suchpfad=1558656 Bei MetaGer / Suma-eV habe ich jetzt vor, Mitglied zu werden. Zur Wikimedialibrary gibt es nur Zugang wenn man fleissig ist: https://wikipedialibrary.wmflabs.org/ Es lohnt sich aber! :O) René H. schrieb: >> Es gibt zwar eine Norm dafür > Mach Dir einfach Deine eigene Norm, mit der Du zurechtkommst. > Funktioniert bei mir seit Jahren. ;) Ja, kein Problem. Andere werden sich das schon zurechtraten können, wenn sie eine Datumsangabe in meiner Form lesen. Dafür habe ich mir die ja selber so ausgedacht. ;O) Mit freundlichem Gruß: Bernd Wiebus alias dl1eic http://www.l02.de
Bernd B. schrieb: > Wie wäre es mit einem (sehr) großen Monitor auf dem sich vielleicht 50 > PDF's gleichzeitig als Tumbernails betrachten lassen. dazu ein > Dateimanager der das macht. Schon vorhanden. Doch der Dateimanager zeigt nur die erste Seite. Für alle drei Szenarien bringt mir das nichts. (Nichts = Nicht mehr, als eh schon da.) Harry R. schrieb: > Bei irfanview kann man Miniaturansichten (Thumbnail, Kontaktabzug?) > drucken, Das probiere ich mal aus, ob es mir weiterhilft. Nachtrag: Batch-Aufträge in IrfanView funktionieren anscheinend nur für "eingebaute" Dateiformate. PDF gehört nicht dazu. Es wird zwar über das Plugin angezeigt, aber für Batch-Jobs wird es noch nicht einmal aufgelistet. Frank E. schrieb: > Bräuche man nur noch eine Software, die Miniaturen aus mehreren > PDF-Dokumenten gleichzeitig darstellen kann ... Das ist genau das, was ich suche (siehe Eröffnungsbeitrag). Bevor ich das selbst versuche zu implementieren, wollte ich suchen, ob es das nicht schon gibt. Bernd W. schrieb: > Man sollte sich aber vorher eine Methodik dazu überlegen. Vorher war vor 20...30 Jahren. Jetzt ist jetzt. Alte Dokumente, von denen >90% nie wieder gebraucht werden, systematisch aufzuarbeiten will ich vermeiden. Selbst wenn heute damals wäre und ich damit anfangen würde: Ich hätte das Domänenwissen noch nicht, die Systematik entsprechend umzusetzen. Meistens betreibt man ja Datenarchäologie gleichzeitig mit der Aneignung des Domänenwissens. Wenn man dann weniger Monate/Jahre später fertig ist, wüßte man, wie man perfekt angefangen hätte. Bernd W. schrieb: > Das Programm "Catfish" bietet ebenfalls eine graphische > Benutzeroberflaeche und ist sehr komfortabel. Catfish ist auch eine Textsuche. Wenn ich die Beschreibung richtig lese, könnte ich nicht nach dem Dokument mit dem gelben Bagger auf Seite 3 (Szenario 2) suchen. Linux/Windows ist ja heute weniger das Problem. Mi. W. schrieb: > XNViewMp mit den passenden Einstellungen um auch pdfs in der Übersicht > darzustellen Stellt doch meines Wissens auch nur die erste Seite dar. Mi. W. schrieb: > PDFExcange Editor Habe ich hier, nutze ich auch, aber mehrere Seiten mehrerer PDFs übersichtlich darstellen kann es nicht. Bernd W. schrieb: > Es gibt aber auch viele > Leute, die sind nicht wie Du Visuell-Bildorientiert sondern > Visuell-Textorientiert. Das war und ist aber die Fragestellung. Zur Textsuche gibt es ja genug Material. "Einfach" alle PDFs seitenweise aufteilen, damit es zu jeder Seite ein Thumbnail gibt, ist auch keine Lösung. Spätestens bei geschützten PDFs.
Walter T. schrieb: > Alte Dokumente, von denen >90% nie wieder gebraucht werden, > systematisch aufzuarbeiten will ich vermeiden. Verständlich. Dann lege dir doch neue Order mit einer guten Struktur und aussagekräftigen Dateinamen für das an, was gerade gebraucht wird. Alle anderen Dateien kommen in einen "Archiv" Ordner.
Also ich hab dafür eine Docker Instanz von Paperless NGX auf meinem NAS dafür. Diesbezüglich muss ich dir auch wiedersprechen: da wird jedes einzelne Wort erkannt, verschlagwortet und auch gefunden. Wie die originale abgelegt werden kann man auch festlegen. Bei mir ist es sowas wie Jahr/Monat/Korrespondenz. Also suchen im Explorer geht theoretisch auch. Nach Farben kann man glaube ich nicht suchen. Aber mir kommt nichts mehr anderes ins Haus.
Angehängte Dateien:
-

Screenshot_Paperport.png
250 KB
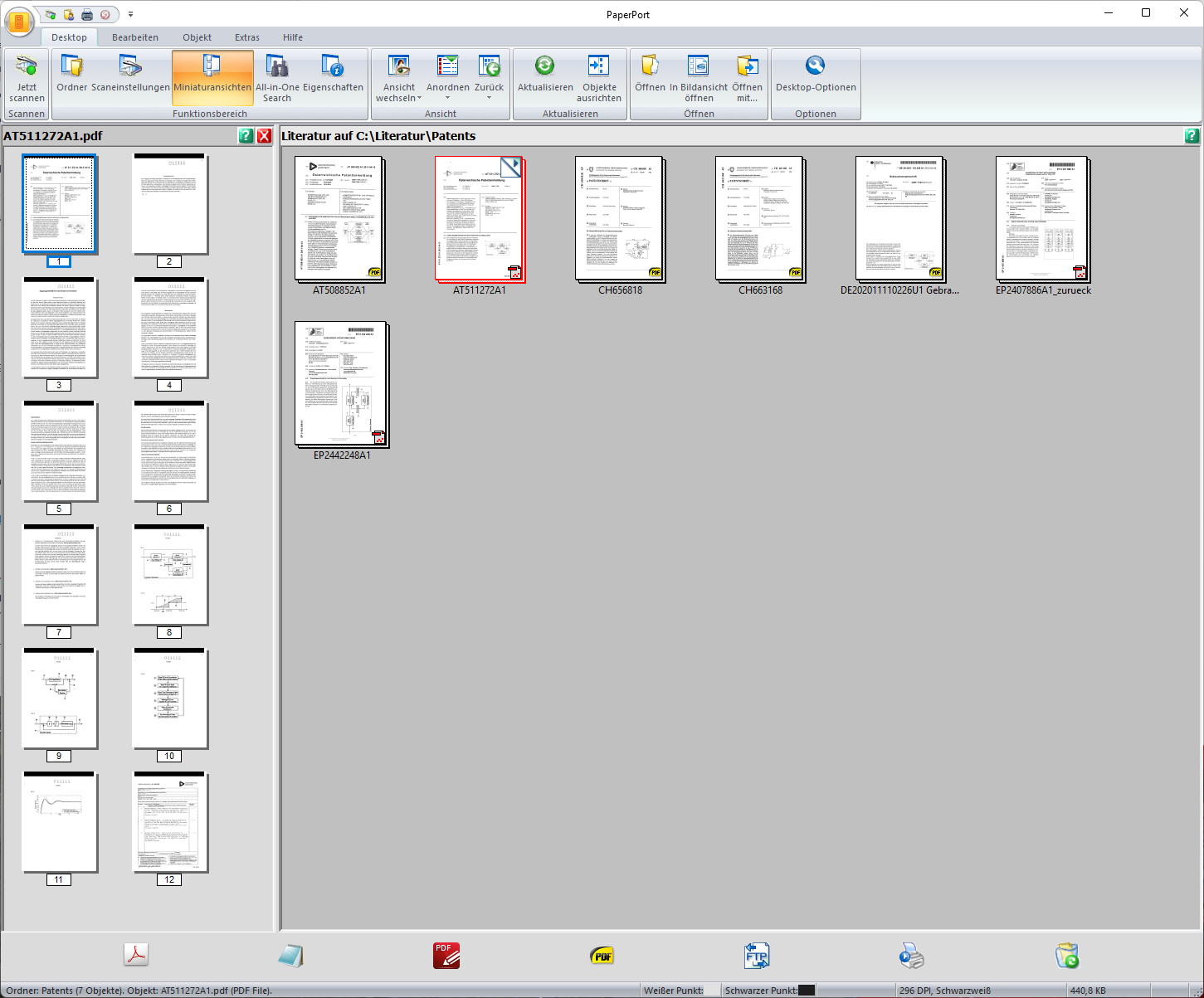
Paperport scheint rudimentär das zu bieten, was ich suche. Man kann sich mit der Tastatur durch ein Verzeichnis navigieren, und die Miniaturansicht-Vorschau zeigt alle Seiten. Schöner wäre es natürlich, die Vorschauen von mehreren Dateien auf einmal zu sehen, (z.B. Reihenweise die Dokumente und dann Spaltenweise die Seiten), aber das hier ist besser als nichts.
Nachtrag: Ich habe jetzt ein bischen herumprobiert. Ich denke, mein Problem lässt sich mit einem wenigzeiligen Python-Script lösen, das mir Thumbnail-Streifen als Bilddateien erzeugt. Das pdf2image-Paket ist erstaunlich schnell. Tausend Seiten gehen in grob 2 Sekunden. Damit brauche ich die Index-Bildstreifen nicht einmal mehr dauerhaft zu speichern.
Walter T. schrieb: > Nachtrag: Ich habe jetzt ein bischen herumprobiert. Ich denke, > mein > Problem lässt sich mit einem wenigzeiligen Python-Script lösen, das mir > Thumbnail-Streifen als Bilddateien erzeugt. > > Das pdf2image-Paket ist erstaunlich schnell. Tausend Seiten gehen in > grob 2 Sekunden. Damit brauche ich die Index-Bildstreifen nicht einmal > mehr dauerhaft zu speichern. Mit pdfunite aus den poppler-utils könnte man alle pdfs eines Verzeichnisses zu einem pdf zusammenpacken, dann hat man beim Anzeigen alles innerhalb einer pdf-Viewer-Session drin (wenn auch nicht mehr pro Einzel-pdf) ...
Beitrag #7827512 wurde von einem Moderator gelöscht.
Angehängte Dateien:
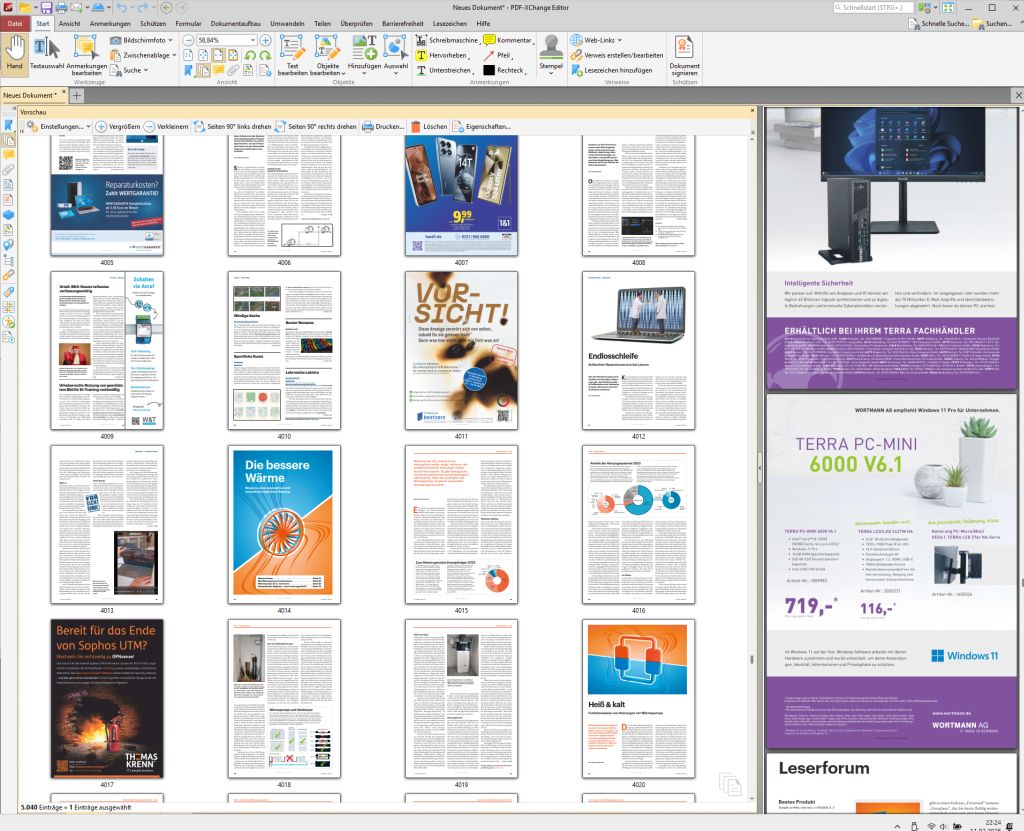
Jens G. schrieb: > [...] alle pdfs eines > Verzeichnisses zu einem pdf zusammenpacken Mit den Einzeldokumenten als Lesezeichen. Das könnte sogar sehr gut funktionieren. Das probiere ich direkt ähnlich aus: Im guten alten Acrobat 9 funktioniert es auf Anhieb ganz gut, dauert aber eine Ewigkeit. Der PDF-XChange Editor ist da schneller. Ich habe mal eben alle C'Ts vom letzten Jahr in eine Datei gepackt, und es hat fünf Minuten gedauert. (Zwei Minuten, wenn keine Lesezeichen erstellt werden.) Damit weiß ich, dass das auch mit schreibgeschützten Dateien funktioniert, und der C'T-Order ist definitiv untypisch groß. Damit lässt sich gut arbeiten. Die 5040 Seiten lassen sich schnell visuell sichten und markante Seiten schnell finden. Damit betrachte ich mein Problem als gelöst. Danke für die Anregung!
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.