Bei meiner Beschäftigung mit dem Raspberry Pi ist eine umfangreiche
C-Werkstatt entstanden.
Ich würde gerne im Sinne des Open Source Gedankens etwas zurückgeben und
suche einen
Autor für ein Buch oder einen Blog rund um das Thema 'Praktischer
Einsatz von C'.
Das Ergebnis können Sie unter http://www.schmuckhexen.at [Projekt /c]
einsehen.
Vorwort http://www.schmuckhexen.at/programs/c/clar_vorwort.pdf.
Kapitel: 'Projekt c/' und 'Autoren gesucht'
Vielleicht können Sie mir weiterhelfen. Danke
Günther Schardinger, Austria, Trofaiach
Webseite : http://www.schmuckhexen.at/
Websuche : schardinger linux c
eMail : v.schardinger@gmx.net
Günther S. schrieb:> Ich würde gerne im Sinne des Open Source Gedankens etwas zurückgeben und> suche einen> Autor für ein Buch
Verstehe ich nicht. Wenn du etwas zurück geben willst, dann bist DU der
Autor.
Günther S. schrieb:> Bei meiner Beschäftigung mit dem Raspberry Pi ist eine umfangreiche> C-Werkstatt entstanden.
Hmm. Was ist eine C-Werkstatt? Und Linux gibt es seit über 30 Jahren, C
noch länger. Da gibt es schon gefühlt 1000 Tutorials. Der RasPi ist halt
nur eine (weitere) Plattform auf der Linux läuft.
Versteh mich nicht falsch. Ich will das nicht madig machen. Es sieht
nach viel Arbeit aus. Und einige der o.a. Tutorials sind schlechter als
deins. Trotzdem stellt sich halt die Frage nach dem Sinn. Hoffentlich
hattest du wenigstens Spaß dabei.
> Ich würde gerne im Sinne des Open Source Gedankens etwas zurückgeben und> suche einen> Autor für ein Buch oder einen Blog rund um das Thema 'Praktischer> Einsatz von C'.>> Das Ergebnis können Sie unter http://www.schmuckhexen.at [Projekt /c]> einsehen.
Sieht doch gut aus. Wozu brauchst du da noch einen (weiteren) Autor?
Wird es dir zuviel? Dann hör auf.
Die ganze Seite gibt mir nostalgische Gefühle.
Was soll der Unsinn?
Günther S. schrieb:> Neues Beispiel: Programm 'wwwtool' zum Bearbeiten/Warten von Webseiten.
So erstellt und wartet niemand seit 1995 mehr Webseiten.
Ehrliche Frage: Was denkst du in welchem Jahr wir uns aktuell befinden?
Wann bist du hängengeblieben?
Ein T. schrieb:> Es wäre vermutlich sinnvoll, Deinen früheren Thread zu verlinken.
Ich habe beide Threads (den alten und den neuen) zusammengeführt.
An Günther S. (projekt_c): Bitte nicht jedesmal einen neuen Thread
öffnen, sondern den bereits vorhandenen Thread nutzen, solange es kein
neues Thema ist.
Frank M. schrieb:> An Günther S. (projekt_c): Bitte nicht jedesmal einen neuen Thread> öffnen, sondern den bereits vorhandenen Thread nutzen, solange es kein> neues Thema ist.
Der Günther macht eh immer nur Fire and Forget und geht auf nichts ein.
Im Grunde spamt er nur Werbung für seine Seite.
Günther S. schrieb:> Ich habe die Erklärungen zu Projekt /c durch> Grundlegende Konzepte und weiter Beispiele erweitert.>> Webseite : https://www.projektc.at
Du schreibst:
"Die geprüften Bibliotheken beheben Defizite der Linuxbibliothek 'Libc'.
Beispiel: Libc Funktion strcmp(NULL,NULL) stürzt ab, die Funktionkopie
StrCmp(NULL,NULL) nicht."
1
#include<stdio.h>
2
#include<stdlib.h>
3
#include<string.h>
4
5
int
6
main(void)
7
{
8
9
printf("res = %d\n",strcmp(NULL,NULL));
10
11
returnEXIT_SUCCESS;
12
}
[bash]
~/C/test$ gcc -Wall -pedantic -std=c99 -o tstrcmp tstrcmp.c
tstrcmp.c: In function ‘main’:
tstrcmp.c:9:26: warning: argument 1 null where non-null expected
[-Wnonnull]
9 | printf("res = %d\n", strcmp(NULL, NULL));
| ^~~~~~
In file included from tstrcmp.c:3:
/usr/include/string.h:156:12: note: in a call to function ‘strcmp’
declared ‘nonnull’
156 | extern int strcmp (const char *__s1, const char *__s2)
| ^~~~~~
tstrcmp.c:9:26: warning: argument 2 null where non-null expected
[-Wnonnull]
9 | printf("res = %d\n", strcmp(NULL, NULL));
| ^~~~~~
/usr/include/string.h:156:12: note: in a call to function ‘strcmp’
declared ‘nonnull’
156 | extern int strcmp (const char *__s1, const char *__s2)
| ^~~~~~
~/C/test$ ./tstrcmp
res = 0
~/C/test$ echo $?
0
[/bash]
Bei mir unter Debian/GNU-Linux mit gcc stürzt es nicht ab. gcc warnt vor
der Verwendung der NULL-Pointer und strcmp liefert 0 zurück, da beide
pointer gleich sind.
Alexander S. schrieb:> "Die geprüften Bibliotheken beheben Defizite der Linuxbibliothek 'Libc'.> Beispiel: Libc Funktion strcmp(NULL,NULL) stürzt ab, die Funktionkopie> StrCmp(NULL,NULL) nicht."
Dem C-Standard zufolge ist das Übergeben von NULL-Pointern an strcmp
"undefined behaviour", es darf also irgendwas passieren (Rückgabe 42,
Programmabsturz, Festplatte formatiert). Es handelt sich also nicht um
einen Fehler. Dass die gnu libc bei solch elementaren Funktionen
fehlerhaft wäre, wäre auch sehr schwer vorstellbar...
Lieber Alexander!
Danke für Deine Antwort!
Ich habe nicht vor an C-Standard zu rütteln. Im Gegenteil: Dieser
Standard hat es mir erst ermöglicht, Projekt /c zu implementieren.
Basis ist nur Linux, gcc und Libc.
Für mich geht es um die Möglichkeit umfangreiche Projekte zu realisieren
und nicht um eine Programmiersprache.
Beispiel: Schon das Hifsprogramm 'chelp' hat derzeit bereits 4791 Zeilen
Programmcode. Da möchte ich nicht ständig auf NULL prüfen müssen.
Meine Lösung: Zu strcmp(...) gibt es die geduldige Funktion StrCmp(..)
Die Bibliotheksfunktionen von Projet /c bieten sichere und komplexe
Systemaufrufe. Sie können aber müssen nicht verwendet werden!
Vielleicht magst Du https://www.projektc.at einmal ausprobieren.
Es lässt sich rückstandsfrei entfernen.
Servus, Günther
Günther S. schrieb:> Da möchte ich nicht ständig auf NULL prüfen müssen
So ist das aber halt wenn man in C programmiert - man macht alles von
Hand, auch Fehlerbehandlung. In anderen Sprachen wie C++, Rust, Java,
Python, Kotlin ... geht das viel einfacher.
Günther S. schrieb:> Beispiel: Schon das Hifsprogramm 'chelp' hat derzeit bereits 4791 Zeilen> Programmcode. Da möchte ich nicht ständig auf NULL prüfen müssen.> Meine Lösung: Zu strcmp(...) gibt es die geduldige Funktion StrCmp(..)
Hallo Günther,
1
#include<stdio.h>
2
#include<stdlib.h>
3
#include<string.h>
4
5
/* Aus ProjektC/c/lib/include/utils.h */
6
intStrCmp(constchar*a,constchar*b);// wie strcmp(), case-sensitiv
D.h. StrCmp lässt sich mit NULL Pointern aufrufen ohne beim Compilieren
eine Warnung zu erzeugen. Soll das der Vorteil ggü. strcmp der stdlib
sein?
Kannst Du genau beschreiben was der Vorteil von StrCmp ggü. strcmp der
stdlib sein soll? Kannst Du genau beschreiben welche Defizite in "Die
geprüften Bibliotheken beheben Defizite der Linuxbibliothek 'Libc'"
gemeint sind. Was genau meinst Du mit "Zu strcmp(...) gibt es die
geduldige Funktion StrCmp(..)". Meinst Du mit "geduldig" "unterdrückt
Warnungen beim Compilieren und erlaubt die Verwendung von NULL
Pointern"?
Erstmal vielen Dank für diese konstruktive Diskusion!
1
voidTest()
2
{clrScr();
3
printf("Laufzeit Test\n");
4
char*s=NULL;
5
char*t=NULL;
6
printf("s=%s t=%s\n",StrN(s),StrN(t));
7
printf("strcmp(s,s) ->%i\n",strcmp(s,t));
8
9
WeiterMitTaste();
10
}
1
LaufzeitTest
2
s=NULLt=NULL
3
Speicherzugriffsfehler(Speicherabzuggeschrieben)
Test mit gnuc 13.3.0 und Libc 2.39. Den Startwert für uninitialisierte
Pointer und Objektpointer setze ich immer erstmals auf NULL.
Ich wollte mir keine unnötige Arbeit aufhalsen. Als Einzellkämpfer macht
Programmieren aber nur Spaß, wenn die eigenen Programme wirklich
funktionieren.
Trotz sorgfältiger Codierung wird es Fehler geben. Fehlermeldungen
wie "Speicherzugriffsfehler (Speicherabzug geschrieben)" sehr sind
mühsam.
Meine Fehlermeldungen ermöglichen es sofort mit 'Text suchen' die Stelle
im Sourcecode zu finden. Dazu kann man auch das einfache aber
reichaltige Fehlerobjekt Err benutzen.
Nochmals: Projekt /c zwingt zu nichts. Wer möchte kann gerne strcmp(...)
benutzen.
Weitere Fragen beantworte ich gerne!
Moin,
Also mich erinnern solche Projekte wie hier eher an sowas: Beim
Einschlagen von Naegeln, einfach die Hand, die die Naegel haelt, lokal
betaeuben. Dann tut's auch nicht weh, wenn man mal daneben kloppt...
Ich bevorzuge einfach mal die Warnings des gcc zu aktivieren und nicht
zu ignorieren und ihrer Ursache auf den Grund gehen. Und die auch auf
Englisch belassen, dann findet man deutlich mehr dazu im Netz.
Dann nochmal ein Lauf mit valgrind und dort eigenartigen Meldungen
nachspueren und der Drops ist deutlich nachhaltiger gelutscht, als mit
irgendwelchen windigen glibc-Funktionsverschlimmbesserungen.
Gruss
WK
Günther S. schrieb:> Trotz sorgfältiger Codierung wird es Fehler geben. Fehlermeldungen> wie "Speicherzugriffsfehler (Spe
Findest du? Wenn du das Programm im Debugger (gdb) startest findest du
solche Fehler (NULL-Pointer-Zugriff) sofort.
Der Debugger hilft erst, wenn der Fehler aufgetreten ist!
Ich habe im Projekt /c 317 Stellen mit Str-Tests gefunden.
Es geht um das Laufzeitverhalten. Ich sehe als Mathematiker keine
Möglichkeit mit Test herauszufinden, unter welchen Bedingungen diese
Test schief laufen könnten.
Die einfachste Lösung: Alle Tests funktionieren immer. Str NULL ist ja
kein Fehler!
Jeder Programmierer kann da seine eigene Lösung finden!
Wenn es um funktionierende Programme geht bringen solche
Diskusionen nicht weiter.
Günther S. schrieb:> Der Debugger hilft erst, wenn der Fehler aufgetreten ist!
Wenn Debugging der Vorgang ist, Fehler aus dem Code auszubauen, ist
Programmierung der Vorgang die Fehler einzubauen.
Günther S. schrieb:> Ich sehe als Mathematiker keine> Möglichkeit mit Test herauszufinden, unter welchen Bedingungen diese> Test schief laufen könnten.
Richtig, das geht grundsätzlich nicht (verwandt mit Halteproblem, Satz
von Rice).
Günther S. schrieb:> Die einfachste Lösung: Alle Tests funktionieren immer. Str NULL ist ja> kein Fehler!
Heißt aber auch, dass du zuvor auftretende Fehler verschleierst - wenn
irgendein String eigentlich nie NULL sein sollte, aber doch mal NULL
wird, wird dein StrCmp das einfach ignorieren und du wunderst dich
warum. Wenn das strcmp aber abstürzt, findest du schnell den Fehler.
Wichtiges Konzept: Fehler möglichst früh finden (auch durch Absturz),
statt später zu ignorieren. Abstürze können etwas Gutes sein, um Fehler
zu finden. Die kann man daher auch gezielt per assert() herbeiführen.
Ich würde grundsätzlich versuchen, String-Pointer nie NULL werden zu
lassen. Wenn eine Funktion (z.B. strdup()) doch mal NULL zurückgibt,
sollte man lieber direkt abbrechen/Programm beenden (z.B. per abort()).
Wenn man den NULL-Pointer hier aber "erlaubt" und dann später in einem
eigenen StrCmp() ignoriert, hat man erfolgreich den ursprünglichen
Fehler verschleiert und findet ihn nicht mehr so leicht, hat aber
wahrscheinlich nichts gewonnen, weil der gewünschte String nicht
existiert und das Programm nichts sinnvolles mehr machen kann. Ein
Programm, das kein sinnvolles Ergebnis mehr abliefern kann, kann man
auch abstürzen lassen.
Natürlich gibt es auch Situationen wo ein String (oder sonst irgendein
Pointer) durchaus mal NULL sein darf. Dann muss man aber überall dort,
wo man den Pointer nutzt, eine Überprüfung auf NULL einbauen. Und das
gehört eigentlich nicht in Low-Level-Funktionen wie strcmp, sondern in
das Modul/Funktion, die den Pointer deklariert. Modernere Sprachen haben
Optional- oder Nullable-Typen, mit denen sich explizit Werte/Referenzen
deklarieren lassen, die leer sein können - hier muss man immer
explizit auf Null prüfen, sonst gibt's Compiler-Fehler. Stringvergleiche
akzeptieren dort keine Optional-Typen, d.h. die Prüfung auf "leer"
obliegt dem Aufrufer.
Moin,
Günther S. schrieb:> Ich habe im Projekt /c 317 Stellen mit Str-Tests gefunden.
Und wer hat diese 317 Stellen programmiert?
(Und ich bin auf 10 Planeten zum Tode verurteilt. :-))
Komischerweise hab' ich mir mit C schon ein paarmal in den Fuss
geschossen und mir sind Daemonen aus der Nase gekommen. Aber noch nie
mit strcmp() mit NULL-ptr Aufrufen.
Günther S. schrieb:> Str NULL ist ja> kein Fehler!
Es ist halt ein Fehler, irgendwelche Funktionen mit NULL ptr aufzurufen,
die dafuer nicht gemacht sind. Ich traue den libc Schreibern und
Standardisierern mehr als dir. Bei free() ist ja was eingebaut, dass man
das mit NULL aufrufen kann und alles ist prima. Die werden schon Gruende
haben, sowas nicht ueberall einzubauen.
Gruss
WK
Dergute W. schrieb:> Es ist halt ein Fehler, irgendwelche Funktionen mit NULL ptr aufzurufen,> die dafuer nicht gemacht sind.
So ist es.
Günther S. schrieb:> Ich sehe als Mathematiker
Als Mathematiker&Informatiker kann ich sagen:
Die ideale Lösung ist es eine Sprache zu nutzen die
Nullable/Optional-Typen kennt und strikt prüft wie Rust oder Kotlin; C++
unterstützt das nur so halb mit std::optional, aber Pointer sind
weiterhin ungeprüft. Durch diese statische Prüfung umgeht man das
Unentscheidbarkeitsproblem, indem man sich vom Compiler dazu zwingen
lässt, einfach den Problemraum zu reduzieren.
Wenn es C sein muss gibt es keine strikte Compiler-Prüfung, aber man
kann das Verhalten manuell nachmachen, indem man wie erwähnt zwischen
Pointern unterscheidet die NULL sein dürfen und solche bei denen es
"verboten" ist, und für zweitere eben vor dem Zuweisen auf NULL prüft
und ggf. terminiert.
So verhindert man das unerwartete NULL-Werte zu späteren Fehlern führen
und implementiert eine sinnvolle Fehlerbehandlung; vergisst man die
Prüfung irgendwo, verhindert das Weglassen der NULL-Prüfung vor
strcmp() etc. das Verschleiern von Fehlern und erleichtert die Suche
nach dem zuvor gemachten Fehler.
Günther S. schrieb:> Die einfachste Lösung: Alle Tests funktionieren immer. Str NULL ist ja> kein Fehler!
Mir wäre dabei unwohl, meine Programmierfehler durch eine "tolerante"
Funktion zu kaschieren. Wenn sie nicht mehr zu Tage treten, wie soll ich
sie dann beheben?
Deine Lösung erschwert für mich die Fehlersuche. Natürlich kann ein gcc
mich nicht davor warnen, wenn ich einen NULL-Pointer übergebe, der erst
zur Laufzeit gesetzt wird. Dann bin ich aber froh, wenn das Programm zur
Laufzeit crasht. Mit einem core dump bzw. durch einen Debugger findet
man dann schnell die entsprechende Stelle und den Verursacher.
Dann gibt es zwei Möglichkeiten:
1. Der Null-Pointer ist harmlos. Dann rufe ich meine Funktion, die einen
gesetzten Pointer != NULL erwartet, nur bedingt auf. Durch diese
Codierung teile ich dem geneigten Leser mit: "Achtung, NULL Pointer kann
durchaus vorkommen und ist getrennt zu betrachten!". Das kann zum
Beispiel ein simples
1
if(ptr!=NULL)
2
{
3
inti=strcmp(ptr,"foo");
4
...
5
}
sein.
2. Der Null-Pointer ist fatal und tritt wegen einer Ausnahmesituation
auf, z.B. durch einen vorherigen Bug im Programm. Dann ist es nicht
sinnvoll, das Programm weiterlaufen zu lassen, weil die Gefahr eines
Amoklaufes besteht, der weitere unvorhersehbare Konsequenzen haben kann.
Mit Deiner Funktion StrCmp() verwässerst Du die beschriebene Situation
Nr. 2 und gefährdest unter Umständen die Sicherheit Deines Systems zur
Laufzeit.
Mein Fazit:
Laufzeitfehler zu ignorieren kann fatale Auswirkungen haben. Es gibt
gute Gründe, warum die libc so ist wie sie ist.
P.S.
Natürlich: die Anwendung der libc ist nicht immer komfortabel und
zeitweise wirkt sie recht angestaubt, was der Enwicklung seit 1970
geschuldet ist. Aber deshalb macht diese Tatsache Deine StrCmp-Funktion
nicht zu einer besseren Funktion - ganz im Gegenteil.
Günther S. schrieb:> Erstmal vielen Dank für diese konstruktive Diskusion!>>
1
voidTest()
2
>{clrScr();
3
>printf("Laufzeit Test\n");
4
>char*s=NULL;
5
>char*t=NULL;
6
>printf("s=%s t=%s\n",StrN(s),StrN(t));
7
>printf("strcmp(s,s) ->%i\n",strcmp(s,t));
8
>
9
>WeiterMitTaste();
10
>}
>
1
LaufzeitTest
2
>s=NULLt=NULL
3
>Speicherzugriffsfehler(Speicherabzuggeschrieben)
4
>
>> Test mit gnuc 13.3.0 und Libc 2.39. Den Startwert für uninitialisierte> Pointer und Objektpointer setze ich immer erstmals auf NULL.>> Ich wollte mir keine unnötige Arbeit aufhalsen. Als Einzellkämpfer macht> Programmieren aber nur Spaß, wenn die eigenen Programme wirklich> funktionieren.>> Trotz sorgfältiger Codierung wird es Fehler geben. Fehlermeldungen> wie "Speicherzugriffsfehler (Speicherabzug geschrieben)" sehr sind> mühsam.>> Meine Fehlermeldungen ermöglichen es sofort mit 'Text suchen' die Stelle> im Sourcecode zu finden. Dazu kann man auch das einfache aber> reichaltige Fehlerobjekt Err benutzen.>> Nochmals: Projekt /c zwingt zu nichts. Wer möchte kann gerne strcmp(...)> benutzen.>> Weitere Fragen beantworte ich gerne!
Hallo Günther,
d.h. Du willst in deinen Programmen zwei Strings, von denen einer noch
nicht initialisiert wurde oder beide noch nicht initialisiert wurden,
miteinander vergleichen? Wozu soll das gut sein?
Günther S. schrieb:> Str NULL ist ja> kein Fehler!
Kannst Du das präzisieren? Unter welchen Bedingungen ist ein NULL
Pointer kein Fehler? Eigentlich doch nur, so lange er noch nicht
verwendet wird. Beim Aufruf einer Funktion, die etwas sinnvolles mit dem
Pointer machen soll, sollte er doch nicht mehr NULL sein.
Danke für die vielen Hinweise. Ich möchte versuchen diesen Thread noch
zu retten.
Ich habe keine finanziellen Interessen, brauche keine Follower. Es macht
mir einfach Freude komplexe Probleme zu lösen(!). Im Sinne von 'Open
Source' helfe ich gerne.
Projekt /c stellt Werkzeuge zu Verfügung um zügig auch sehr umfangreiche
Aufgabenstellungen zu
lösen. Alles nur auf der Basis von Linux, C und make. Keine sonstigen
Zutaten. Mit delete /c kann alles rückstandsfrei entfernt werde.
Probieren: https://www.projektc.at
Alle Hilfsprogramme wie z.B. 'chelp' dienen nur der Bequemlichkeit.
Die Zusammenstellung ist brauchbar für Umsteiger und Einsteiger. Wer sie
brauchbar findet, kann sie benutzen. Da gibt keine Vorschriften. Das
Ergebnis spricht für sich. Für so eine Menge fehlerarmer Programme
braucht es aber gute Konzepte im Hintergrund.
Ich persönlich brauche nach 50 Jahren Programmentwicklung auch keine
keine Erklärungen zur Vorgangsweise. Siehe:
https://www.projektc.at/programs/c/clar_vorwort.pdf
Diskussionen zu Programmiersprachen habe ich vor 35 Jahren geführt. Kein
Bedarf mehr!
An guten Lösungen bin ich aber immer sehr interessiert.
Als Mathematiker eine letzte Bemerkung zu Null: NULL, "" ,0
Sie ist unverzichtbar. Am Zerfall des römischen Reichs hatte auch die
fehlende Null einen Anteil. Die damalige Mathematik war damit an eine
unüberwindbare Grenze gestoßen.
Ich brauche die Null. Kann aber jeder so machen wie er möchte!!
Für weitere Fragen zu Projekt /c stehe ich gerne zu Verfügung.
Für mich gibt es keine schwachen oder inkompetenten Fragen.
Bei Erklärungen sollte man da vorsichtiger sein. Kompetenzmangel
schimmert da schnell durch.
An der Struktur erkennt etwas von der Funktionalität des Err-Objekts.
Der Compiler setzt beim Start des Programms Den Pointer Err auf NULL;
Wird zum Beispiel die Funktion ErrAdd(Err,"Beschreibung des Fehlers")
aufgerufen, so wird bei Err==0 das Err-Objekt tatsächlich angelegt.
Das Err-Objekt ist recht einfach aber sehr reihaltig. Der Header ist im
Anhang.
Servus, Günther
ErrPrint(Err," ergänzende Beschreibung ",tue);// Beispiel 1
3
ErrPrint(Err,__func__,true);// Beispiel 2
4
ErrPrint(Err,NULL,true);// Beispiel 3
ErrPrint() gib alle bisher aufgelaufenen Fehler aus.
Beispiel 1: Zu den Fehlern wird noch der String " ergänzende
Beschreibung " angezeigt.
Beispiel 2: Zu den Fehlern fügt der Compiler den Namen der Funktion ein.
Sehr praktisch.
Beispiel 3: Zu den Fehlern wird nichts hinzugefügt. Auch nicht ""!
Günther S. schrieb:> Für so eine Menge fehlerarmer Programme braucht es aber gute Konzepte im> Hintergrund.
Wenn man Code zum lernen als Beispiel veröffentlicht, macht es eben
Sinn, etablierte Konzepte zu demonstrieren. Dazu gehört es, Fehler früh
zu erkennen statt später zu verschleiern.
Günther S. schrieb:> Ich brauche die Null.
Aber nicht überall. Die Definitionsmenge von Funktionen enthält halt
nicht immer die Null, z.B. die Divisionsfunktion. Die Definition der
Division so anzupassen dass man doch durch Null teilen darf aber dann
einen Dummy-Wert ("unendlich"?) erhält ist sinnlos und macht die
Grundrechenarten auf Körpern inkonsistent. Die rationalen Zahlen wie wir
sie kennen zu verlieren nur weil man immer überall die Null zulassen
möchte ist kaum zielführend...
Günther S. schrieb:> Ich habe dir ein Beispiel vom Err-Objekt herauskopiert.
Ja DAS ist ein Beispiel bei dem Null-Zeiger sinnvoll sind, denn sie
repräsentieren eine sinnvolle, erwartete Datenstruktur (leere Liste).
Angenommen du möchtest dass alle gespeicherten Fehlermeldungen einen
Meldungstext haben, weil die Ausgabe leerer Fehlermeldungen nichts
bringt. Heißt also, der Parameter an ErrAdd darf nie NULL werden.
Angenommen ErrAdd speichert den Pointer ins Array, aber nutzt StrCmp()
um sicherzustellen dass eine Meldung nicht doppelt hinzugefügt wird.
Wenn jetzt jemand beim Aufruf von ErrAdd versehentlich NULL übergibt,
kann der C-Compiler das nicht so ohne weiteres als Fehler erkennen. Per
StrCmp wird zwar sichergestellt dass die NULL nur einmal hinzugefügt
wird, aber das hilft hier nichts.
Du wirst am Ende per ErrPrint() eine leere Fehlermeldung bekommen, weil
ErrPrint nur den Null-Pointer im Array sieht aber sonst nichts damit
machen kann. Mit einer leeren Meldung kannst du nichts anfangen und hast
keine Ahnung, wo der NULL-Wert herkommt. So hast du erfolgreich den
ursprünglichen Fehler verschleiert.
Wenn du jedoch in ErrAdd nicht StrCmp() sondern strcmp() aufrufen
würdest, wäre bei der Übergabe des NULL-Pointers sofort eine
Segmentation Fault aufgetreten und du würdest blitzschnell (ggf. per
Debugger) sehen, wo versehentlich die NULL übergeben wurde. Du könntest
sogar noch ein assert() zu ErrAdd() hinzufügen um NULL-Werte direkt
abzufangen. Dann bräuchtest du in ErrPrint() auch keine Prüfung auf NULL
mehr, sondern könntest davon ausgehen, dass im Array niemals NULL-Werte
stehen können.
Es hat sicher jeder so seine Präferenzen wenn es um eigene Projekte
geht. Wie er die Anlegt, wie er damit arbeitet, was für Skripte &
Hilfsfunktionen er sich erstellt, usw.
Ich denke aber, dass die wenigsten Interesse daran haben, wie Ich oder
Du da so vorgehen, gerade auch, weil jeder sein eigenes Vorgehen hat.
Nochmals. Mein Ziel ist es, schnell sicher komplexe(!) Aufgabestellungen
zu lösen.
Für mich hat es sich bewährt 'Top down' und 'Bottom up' vorzugehen.
'Bottom up', also auf der Ebene Compiler, Debugger usw. ist für mich
nicht wirklich was zu holen. C ist auf 100 Buchseiten vollständig
beschrieben, also eher simpel. Ich geh also davon aus, dass man ohne
weitere Werkzeuge syntaktisch fehlerfreien Code schreiben kann. Ich
möchte auf dieser Ebene auch keine Fehler produzieren, noch Fehler
suchen müssen! Die besten Fehler sind jene, die gar nicht auftreten.
Daher arbeite ich einfach geprüften Funktionen die alle mögliche
Parameter verarbeiten.
Kann aber jeder so machen wie er will!
'Top down', also bei der Benutzung des Programms kommen die eigentlichen
interessanten Probleme.
Mein Fehlerobjekt Err erfasst alle Fehler - also auch alle
Systemmeldungen mit Klartext.
- Der Programmbenutzer muss nicht über alle Fehler informiert werden.
- Angezeigte Meldungen müssen wirklich informativ sein.
- 'file not found' reicht nicht.
- Das Auftreten eines Fehlers, die Behandlung und die Meldung sind
verschiedene Dinge.
- Als Einzelkämpfer hänge ich noch automatisch ich den Funktionsnamen an
die Meldung.
- 'Bottom up' Fehler sollten da nicht mehr vorkommen
Bei Steuerungen ist die Sache noch komplizierter. Nicht fatale Fehler
dürfen den Ablauf nicht unterbrechen.
Ein Beispiel: Meine Steuerungen arbeiten mit dem Konzept Device,Events
und Loop. Derzeit werden die definierten Events zeitgesteuert der Reihe
nach behandelt. Dadurch kommt es bei ca. 30 Abfragen eines 1-Wire
Temperatursensors zu einem Timing-Problem. Dieser Fehler ist aber z.B.
bei einer Wetterstation völlig irrelevant. Mein Err-Objekt leitet alle
Fehler automatisch in die Logdatei um. Die notwendige Programmänderung
ist ja einfach.
PS: Das Auftreten einer zusätzlichen Leerzeile in einer Fehlermeldung
wäre für mich kein Problem.
Bei den bisher 1966 Aufrufen des Err-Objekts in Projekt /c ist auch noch
nie passiert. Das Err-Objekt ist sehr simpel. Ich sehe keine Möglichkeit
es zum Absturz zu bringen.
Günther S. schrieb:> Nochmals. Mein Ziel ist es, schnell sicher komplexe(!) Aufgabestellungen> zu lösen.
Gerade für komplexe Aufgaben ist dein Ansatz ungeeignet. Genau deswegen
arbeitet die ganze Informatik-Welt seit Jahrzehnten (!) daran, Methoden
und Werkzeuge zu entwickeln, genau diese Art von Problem zu lösen.
Günther S. schrieb:> Ich geh also davon aus, dass man ohne weitere Werkzeuge syntaktisch> fehlerfreien Code schreiben kann.
Syntaktisch fehlerfrei ist eben nichtmal die halbe Miete.
Günther S. schrieb:> . Ich möchte auf dieser Ebene auch keine Fehler produzieren,
Viele Programmierer glauben, fehlerfreien Code schreiben zu können. Gute
Programmierer wissen, dass dies utopisch ist, und lassen sich dabei
helfen - durch entsprechende Methoden und Werkzeuge, die Fehler früh
finden.
Günther S. schrieb:> Die besten Fehler sind jene, die gar nicht auftreten. Daher arbeite ich> einfach geprüften Funktionen die alle mögliche Parameter verarbeiten.
Es ist aber auch ein Fehler, wenn das Programm etwas sinnloses macht
(z.B. leere Fehlermeldung ausgeben), ohne abzustürzen. Das ist sogar der
schlimmere Fehler: Unbemerkte/Verschleierte Fehler, oder "heimlich"
falsche Ausgabe, sind viel schlimmer als ein Programmabsturz.
Günther S. schrieb:> Das Auftreten einer zusätzlichen Leerzeile in einer Fehlermeldung wäre> für mich kein Problem
Für mich schon. Da könnte irgendwo im Programm was fatal schief laufen,
und ich würde es nicht merken, weil statt einer Fehlermeldung eine
Leerzeile kommt.
Es sind schon Menschen ums Leben gekommen, weil Steuerungen Fehler
verschleiert haben und diese nicht bemerkt wurden (Therac-25, Boeing 737
Max Absturz). Besser wäre es, wenn die Steuerung abstürzt und der Nutzer
merkt, das was schief läuft.
Günther S. schrieb:> Das Err-Objekt ist sehr simpel. Ich sehe keine Möglichkeit es zum> Absturz zu bringen.
Wie gesagt - Absturz ist nicht so schlimm.
Es ist lustig, wie mir jede Menge nicht getätigter Aussagen
zugeschrieben werden.
Ich denke es entspricht dem Zeigeist Ausführungen einfach nicht lesen
sonder sofort zu posten.
Ich schrieb eindeutig: 'Mein Fehlerobjekt Err erfasst alle Fehler - also
auch alle Systemmeldungen mit Klartext.'
Ich kann aber nicht erkennen ,worin der Vorteil eines Programmabsturzes
- also ein völlig undefinierter Zustand des Rechners - liegen sollte.
Bei mit fällt nichts unter den Tisch, nein bei mir bleibt das System
einfach nur handlungsfähig. Damit ist diese Frage für mich erledigt.
Das ist übrigens das Konzept in der Luftfahrt.
Moin,
Günther S. schrieb:> Ich schrieb eindeutig: 'Mein Fehlerobjekt Err erfasst alle Fehler - also> auch alle Systemmeldungen mit Klartext.'
Naja, also mir persoenlich reicht eigentlich alles, was schiefgehen
kann, aus errno.h und ihren Begleitfiles. Da brauche ich kein
Fehlerobjekt.
Ist aber voellig OK, wenn du dir da einen Wolf programmierst. Nur musst
du damit leben, dass da halt viele deine Programmieranstrengungen nicht
entsprechend wuerdigen, und noch viel weniger dir beim Buchschreiben
helfen wollen.
Ich fuer meinen Teil mache z.B. ganz gerne digitale Signalverarbeitung
auf AVR/attiny. Ich weiss aber, dass das eigentlich ziemlich bekloppt
ist. Daher mach' ich das rein zum eigenen Spass, suche keine Mitstreiter
und versuche auch nicht, andere von meiner Genialitaet zu ueberzeugen.
Dann und wann schreib' ich hier halt mal was bei Projekte und Code dazu,
aber das wars denn schon. Alles fein.
Gruss
WK
Günther S. schrieb:> Das ist übrigens das Konzept in der Luftfahrt.
Ich glaube deine Art zu programmieren und die Sicherheitskonzepte in der
Luftfahrt könnten nicht weiter voneinander entfernt sein.
Dergute W. schrieb:> Ich weiss aber, dass das eigentlich ziemlich bekloppt> ist. Daher mach' ich das rein zum eigenen Spass, suche keine Mitstreiter> und versuche auch nicht, andere von meiner Genialitaet zu ueberzeugen.
Jeder Geniale muß auch irgendwie bekloppt sein und nur der Geniale
versucht nicht andere von seiner Genialität zu überzeugen.
SCNR
Günther S. schrieb:> Ich schrieb eindeutig: 'Mein Fehlerobjekt Err erfasst alle Fehler - also> auch alle Systemmeldungen mit Klartext.'
Wie funktioniert das?
Als nachlässiger Programmierer könnte man mal versehentlich einen derart
fehlerhaften Code produzieren:
1
// Korrigierte Version von memcpy
2
void*MemCpy(void*dest,constvoid*src,size_tcount){
3
if(dest==NULL||src==NULL)returnNULL;
4
returnmemcpy(dest,src,count);
5
}
6
7
char*readBlock(FILE*myFile){
8
void*buffer=malloc(2048);
9
fread(buffer,1,2048,myFile);
10
returnbuffer;
11
}
12
13
intmain(){
14
char*data=readBlock();
15
16
// ... viel weiterer Code ...
17
18
intmoney;
19
MemCpy(&money,data+42,
20
printf("Überweise %d €\n",money);
21
}
Wenn eine der diversen Fehlermöglichkeiten in der readBlock -Funktion
auftritt, wie bemerkt dein Fehlerobjekt "Err" das?
Wenn jetzt beispielsweise das malloc() fehlschlägt, wie bemerkt das
Fehlerobjekt Err das, und am Wichtigsten: Wie viel € werden dann am Ende
überwiesen? Wenn plötzlich 192374237 € überwiesen werden, wie findest du
die Fehlerursache?
Günther S. schrieb:> Ich kann aber nicht erkennen ,worin der Vorteil eines Programmabsturzes> - also ein völlig undefinierter Zustand des Rechners - liegen sollte.
Wenn ein Programm abstürzt, ist der Rechner danach in einem wunderbar
wohldefinierten Zustand, denn das Betriebssystem räumt alle belegten
Ressourcen auf. Der Vorteil liegt darin, dass du bemerkst, dass ein
Problem vorliegt, und dass du die genaue Ursache des Problems sehr
schnell finden kannst. Ich verstehe nicht, warum du solche Probleme mit
Abstürzen hast - ein Absturz ist meist ein leicht auffindbarar Fehler.
Günther S. schrieb:> Das ist übrigens das Konzept in der Luftfahrt.
In der Luftfahrt wird so etwas wie StrCmp benutzt, was Fehler unter den
Teppich kehrt, sodass dann irgendwelche zufälligen Daten weiter
verarbeitet werden?
Niklas G. schrieb:>> Das ist übrigens das Konzept in der Luftfahrt.>> In der Luftfahrt wird so etwas wie StrCmp benutzt, was Fehler unter den> Teppich kehrt, sodass dann irgendwelche zufälligen Daten weiter> verarbeitet werden?
Er meint dass dort fehlertolerante Systeme eingesetzt werden. Es macht
dort natürlich keinen Sinn dass das ganze Ding abstürzt (Wortspiel) weil
ein SW Fehler auftritt.
Das ist aber IMO etwas ganz anderes. Denn hier geht es um das
Systemverhalten zur produktiven Laufzeit. In der Entwicklungsphase
möchte man alle Fehler, bis auf den kleinsten, sofort sehen und nicht
kaschieren.
Cyblord -. schrieb:> Es macht> dort natürlich keinen Sinn dass das ganze Ding abstürzt (Wortspiel) weil> ein SW Fehler auftritt.
Ja, aber auch hier gehört die Fehlererkennung nicht in
Low-Level-Funktionen wie StrCmp sondern das muss "nach oben"
durchgeschleift werden. Sollte durch Speicherkorrumption (kosmische
Strahlung etc) ein zuvor gültiger Pointer zu NULL werden, könnte StrCmp
das zwar prüfen, aber muss dann auch einen kontrollierten Neustart o.ä.
einleiten.
Niklas G. schrieb:> Ja, aber auch hier gehört die Fehlererkennung nicht in> Low-Level-Funktionen wie StrCmp sondern das muss "nach oben"> durchgeschleift werden. Sollte durch Speicherkorrumption (kosmische> Strahlung etc) ein zuvor gültiger Pointer zu NULL werden, könnte StrCmp> das zwar prüfen, aber muss dann auch einen kontrollierten Neustart o.ä.> einleiten.
Das ist korrekt.
Günther S. schrieb:> Die besten Fehler sind jene, die gar nicht auftreten.> Daher arbeite ich einfach geprüften Funktionen die alle mögliche> Parameter verarbeiten.
Hallo Günther,
ist das nicht ein wenig Selbstbetrug? Auch du wirst Fehler machen,
versuchst aber, diese zu "verstecken". Die gemachten Fehler tauchen dann
halt an anderer Stelle auf.
Ist in etwa so, als würde ich meine Waage manipulieren, so dass Sie
immer 10 Kilo zu wenig anzeigt. Dann stehe ich drauf und denke: "puuuh,
Glück gehabt, alles in Ordnung!" ;-)
Noch etwas zum Projekt selbst habe ich auch noch beizutragen: Das
Projekt /c und auch dein Ordner "c", den deine Tools erwarten, lösen bei
mir irgend wie Unbehagen aus. Ich würde wenn möglich solche Ordner nicht
"c" nennen. Okay, "/" ist Unix und "C" Win, da kann erstmal nix
passieren. Trotzdem bleibt ein ungutes Gefühl beim Ordner "c" :-)
ciao
Marci
Der Unterhaltungswert dieses Threads steigt und steigt.
Ich bin da aber raus. Ich geniere mich ja schon fast, dass die Tools
meine Werkstatt trotz der vielen offensichtlichen Mängel so gut
funktionieren. Es kann aber jeder kann eine bessere Werkstatt codieren
oder auch nicht.
Zu den interessanten Mutmaßungen und Unterstellungen möchte ich doch
noch die reinen Fakten festhalten.
1. Ja: NULL ist ein gültiger Variablenwert.
2. Nein: Ich habe Libc nicht umgeschrieben. Wäre ziemlich doof auf
Updates zu verzichten.
3. Ja: Alle meine Hilfsfunktionen kommen mit allen Eingabeparametern
zurecht. Das gilt auch für Libc Aufrufe. Ja, dieses Konzept stammt aus
der Luftfahrt!
4. Nein: Mein Err-Objekt unterdrückt keinen einzigen Fehler - im
Gegenteil. In autonom laufenden Systemen kann alles automatisch in die
Logdatei umgeleitet werden.
5. Nein: Laufzeitfehler verbessern nichts. Der Fehler würde nicht einmal
in der Logdatei landen.
6. Ja: Ohne ausführliches Risikomanagement wäre ich als Kletter,
Skitourengeher und ehemaliger Segelflieger nicht mehr am Leben. Im
Fliegerclub Timmerdorf durfte ich bei der Wartung von Motor- und
Segelfliegern mitarbeiten. Da habe ich wirklich viel gelernt. Ich habe
also absolut kein Interesse an Halbwahrheiten über die Fliegerei.
Das wars für mich.
Für ernsthafte Fragen bin ich gerne unter
https://www.projektc.at/gnu.html erreichbar.
Danke und weiterhin noch viel Spaß.
Mein letzter Beitrag zeigt nochmals das vielgeschmähte Err-Objekt.
Das letzte Beispiel zeigt mögliche Fehler beim Einlesen der
Konfigurationsdatei von 'chelp'
Anhang chelp0.conf: Einige Zeilen der Konfigurationsdatei.
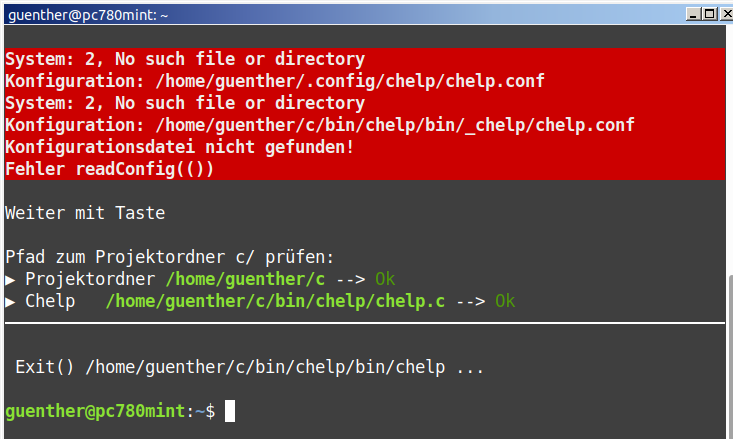
Anhang chelp1.png: Zum Test 1 habe einen falschen Dateinamen verwendet.
'chelp' sucht die Konfiguration 'chelp.conf' an zwei Stellen. Das
Fehlerobjekt hat zuerst den Systemfehler 2 gefunden und danach die
Informationen ergänzt. Das Programm wurde daraufhin mit ErrExit(...)
beendet. Dabei wird automatisch vor exit() noch Exit() von 'chelp'
gerufen. Dort könnten noch wichtige Aufräumarbeiten von 'chelp'
erfolgen.
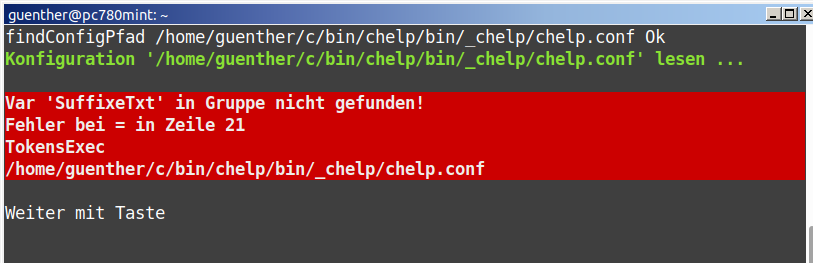
Anhang chelp2.png: Zum Test 2 habe ich einen Fehler in die
Konfigurationsdatei eingebaut. Man könnte aber auch ohne Fehlermeldung
auskommen,
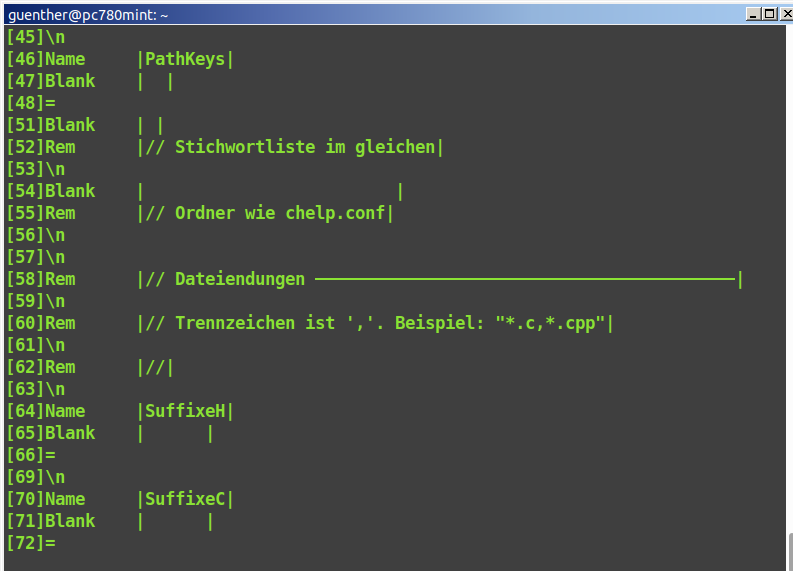
Anhang chelp3.png: Alle meine Module werden immer im Debugmodus
entwickelt. Startet man mit
'chelp -d' so werden fortlaufend Debuginfos angezeigt. Die
Konfigurationsdatei wir beim Einlesen vom Parser in relevante C-Items
zerlegt. Siehe chelp3.png. Man sieht, dass die Konfigurationsdatei
eigentlich in Ordnung ist. Man könnte sie ohne Fehler verwenden und dann
beim Schreiben den fehlenden Strichpunkt ergänzen.
Alle Debuggerfans können sich diesen Startvorgang ja einmal im Debugger
ansehen. Da geht die Post ab.
Günther S. schrieb:> Ich bin da aber raus.
Oh nein, was tun wir nun ohne einen Geronten der die C-Programmierung
völlig neu erfinden will und alle andere für doof hält? Was nur?
Schau mal, dein ERR Objekt mag für dich und deine immer gleichen
wiederkehrenden Programmierprojekte gut funktionieren. Geschenkt. Aber
das sagt so gar nichts über die Verwendbarkeit für alle anderen aus. Du
programmierst in deiner eigenen kleinen Blase. Belass es dabei und
behalte dein ERR Objekt.
Günther S. schrieb:> Das gilt auch für Libc Aufrufe. Ja, dieses Konzept stammt aus> der Luftfahrt!
Hast du eine Quelle dafür? Insbesondere, dass Libc-Aufrufe Fehler wie
NULL-Pointer ignorieren sollen?
Günther S. schrieb:> Mein Err-Objekt unterdrückt keinen einzigen Fehler - im> Gegenteil.
Aber nur wenn man das "Err-Objekt" überhaupt erstmal aufruft. Aber es
gibt so viele Fehlermöglichkeiten, da kann es schnell passieren, dass
man für irgendeinen Fall keine Fehlerbehandlung eingebaut hat.
Ich glaube eher dass du Softwarefehler und Laufzeit-Fehler in einen Topf
wirfst. Laufzeit-Fehler muss man abfangen und sinnvoll behandeln ("Datei
nicht gefunden" etc.), erstere kann man nie vollumfänglich vorhersehen,
man kann sich nicht darauf verlassen sie alle abgefangen zu haben.
Günther S. schrieb:> Alle Debuggerfans können sich diesen Startvorgang ja einmal im Debugger> ansehen. Da geht die Post ab.
Die Debuggerfans arbeiten mit komplexeren Projekten und staunen nicht
über die Behandlung von erwarteten (!) Fehlern.
Man sollte nicht vergessen, dass z.B. memcmp nicht garantiert crasht,
wenn man einem der 2 Pointer 0 übergibt. Es ist UB. Es kann crashen,
muss aber nicht. Und tatsächlich hab ich beides schon gesehen.
Ganz egal, ob man jetzt 0 erlaubt/definiert, oder eine Funktion macht
die garantiert crasht, das ist beides besser als das UB zu lassen.
Gerade bei memcmp finde ich das auch komplett bescheuert, dass 0 da
explizit undefiniert ist. Da denkt man sich, man hat bei count ja auch 0
drin, also werden 0 bytes verglichen, ist doch egal, ob der Pointer 0
ist, wird ja nicht drauf zugegriffen... Schön wärs.
Und Ich frag mich, was da passieren würde, wenn man das Resultat von
malloc(0) nehmen würde...
Günther S. schrieb:> ErrPrint() gib alle bisher aufgelaufenen Fehler aus.
Fehler_meldungen_, bitte, so viel Zeit muß sein.
Das, was Du hier beschreibst, wird gemeinhin als "Logging" bezeichnet.
Dafür haben sich etablierte Techniken entwickelt. Gemeinhin wird ein
Logger-Objekt erstellt und konfiguriert, indem Handler hinzugefügt
werden, welche dann die Formatierer, Ausgabekanäle, Min- und selten
auch Max-Loglevel festlegen. Auf diese Weise ist es möglich,
gleichzeitig mit verschiedenen Formatierungen in unterschiedliche Kanäle
mit den gewünschten Logleveln zu loggen. So kann die Applikation die
Warnings, Errors und Fatals im Text auf STDERR, gleichzeitig alle
Meldungen, von Trace bis Fatal, als JSON in Syslog, journald oder sogar
eine Volltext-Suchmaschine wie Elastic- oder OpenSearch zur Analyse.
Solche verbreiteten Vorgehensweisen haben im Allgemeinen einen Sinn, der
sich im Laufe der Zeit herausgebildet hat. In der Regel ist es keine
gute Idee, von solchen etablierten Vorgehensweisen abzuweichen.
Ein T. schrieb:> Wenn man fehlerhaften Code erfinden muß, um ein Argument zu> konstruieren, belegt das nur die eigene argumentative Schwäche.
Fehlerhafter Code ist allgegenwärtig. Jede neu geschriebene Funktion
enthält grundsätzlich mindestens 3 Bugs. Das gilt ganz besonders für C.
Das ist die Realität. Was anderes zu behaupten ist illusorisch. Gerade
hier im Forum wird sich doch sehr gern über schlechte Software
echauffiert. Ein guter Anteil fehlerhafter Software kommt von Leuten die
behaupten sie würden keine Fehler machen.
C ist und war nie als kugelsichere Programmiersprache gedacht. Ich sehe
keinen Sinn darin, mit eigenen Bibliotheken dieses Ziel in C zu
verfolgen. Dazu gibt es schon lange andere etablierte
Programmiersprachen, mit denen das besser geht.
Der Versuch ist so seltsam, wie das Motorrad mit Dach (BMW C1).
Niklas G. schrieb:> Ein T. schrieb:>> Wenn man fehlerhaften Code erfinden muß, um ein Argument zu>> konstruieren, belegt das nur die eigene argumentative Schwäche.>> Fehlerhafter Code ist allgegenwärtig.
Das ist unstrittig, aber nicht der Punkt. Der Punkt ist, daß Du
fehlerhaften Code erfindest, um dem TO Deinen eigenen fehlerhaften Code
vorzuwerfen. Das ist keine seriöse Argumentation und auch kein guter
Stil -- zumal der Code des TO ja nun wirklich mehr als genug seriöse
Kritikpunkte bietet, ohne daß jemand noch welche hinzu erfinden müßte.
Nemopuk schrieb:> Ich sehe keinen Sinn darin, mit eigenen Bibliotheken dieses Ziel in C zu> verfolgen
Bibliotheken bringen da nicht viel, da braucht es Methodik. Architektur,
assert(), statische Code-Analyse, Coding-Rules, Dokumentation, Debugger
und Instrumentation, und am wichtigsten, Tests. Am besten nutzt man
direkt C++ und nutzt die strengere Typprüfung um viele Fehler direkt vom
Compiler finden zu lassen.
Ein T. schrieb:> Der Punkt ist, daß Du fehlerhaften Code erfindest, um dem TO Deinen> eigenen fehlerhaften Code vorzuwerfen. Das ist keine seriöse> Argumentation und auch kein guter Stil
Du hast es nicht verstanden - ich habe nicht diesen fehlerhaften Code
kritisiert. Ich habe kritisiert, den Fehler nachträglich zu
verschleiern. Offensichtlich schreibt der TO selbst gelegentlich derart
fehlerhaften Code, denn sonst würde er das StrCmp nicht brauchen. Nur
dass so ein StrCmp der falsche Ansatz ist, weil man so den
ursprünglichen Fehler nicht findet.
Hier mal ein Beispiel für einen schwierig zu findenden Fehler:
1
#include<sys/uio.h>
2
#include<string.h>
3
#include<stdlib.h>
4
#include<errno.h>
5
6
void*flatten_iovec(
7
size_t*restrictconstp_total_size,
8
size_tcount,
9
conststructiovecv[restrictconstcount]
10
){
11
size_ttotal_size=0;
12
for(size_ti=0;i<count;i++){
13
size_tsum=total_size+v[i].iov_len;
14
if(total_size<sum){
15
errno=EINVAL;
16
return0;
17
}
18
total_size=sum;
19
}
20
char*mem=malloc(total_size);
21
if(!mem)
22
return0;
23
{
24
char*restrictit=mem;
25
for(size_ti=0;i<count;i++){
26
size_tlen=v[i].iov_len;
27
memcpy(it,v[i].iov_base,len);
28
it+=len;
29
}
30
}
31
*p_total_size=total_size;
32
returnmem;
33
}
Wer sieht ihn?
## Auflösung
memcpy mit src=0 ist ub, selbst wenn len=0. struct iovec hingegen hat
keine solche Limitation, egal ob man sich man 3 iovec oder man 2
readv/writev ansieht.
Mit anderen Worten, wenn in dem iovec array ein (struct iovec){0,0}
enthalten ist, ist das völlig OK und wohldefiniert. Es werden 0 bytes
kopiert.
Aber die flatten_iovec Funktion oben kann damit nicht umgehen, und läuft
beim memcpy ins UB.
Der Springende Punkt hier ist, es würde Sinn machen, bei memcpy für
src/dst null zu erlauben, wenn length null ist. Wäre das nicht explizit
im C Standard als UB genannt, wäre der Spezialfall wohldefiniert
gewesen, und würde genau das machen, was man erwartet, nämlich nichts (0
bytes kopieren).
Aber so wie es jetzt ist, kann einem der obere Fehler schnell mal
passieren. Vielleicht schreibt man sich ein dynamisches Array oder so,
denkt nicht mehr an den Edgecase von length=0, und schon hat man das
Problem.
UB bei length != 0 wäre mir ja egal, aber der spezifische Fall, der
bringt mich jedes mal auf die Palme.
Daniel A. schrieb:> if(!mem)> return 0;
Den hätte man auch schöner schreiben können. 😎
Und den etwas darüber auch.
Auch wenn's wohl funktioniert, aber die Augen essen halt mit.
Daniel A. schrieb:> Aber so wie es jetzt ist, kann einem der obere Fehler schnell mal> passieren. Vielleicht schreibt man sich ein dynamisches Array oder so,> denkt nicht mehr an den Edgecase von length=0, und schon hat man das> Problem.
In der Programmiererei ist das das eigentliche Hauptproblem: LOGISCHE
Fehler bei syntaktischer Fehlerfreiheit.
Und gegen dieses Problem helfen auch die höheren Programmiersprachen
nicht, weil dort ebenfalls solche logischen Fehler (= Gedankenfehler)
auftreten können. Umgehen oder einschränken lässt sich das nur, wenn man
zuerst alle Laufzeitfälle durchdenkt und separiert sowie anschließend -
gegebenenfalls vom komischen Verhalten überrascht - die hier schon
vielfältig beschriebenen Fehlerbehandlungen bzw. Fallunterscheidungen
einbaut.
Ein gutes Beispiel sind while-Schleifen, die gerne einmal ungewollt
unendlich laufen ...
Hans D.
Hans D. schrieb:> Umgehen oder einschränken lässt sich das nur, wenn man> zuerst alle Laufzeitfälle durchdenkt
Wenn man das so macht, dürfte dies
Hans D. schrieb:> Ein gutes Beispiel sind while-Schleifen, die gerne einmal ungewollt> unendlich laufen ...
eigentlich nicht mehr auftreten
C hält da noch ganz andere Fallstricke bereit, die einen immer wieder
ins straucheln bringen, insbesondere dann wenn man auch noch mit anderen
Programmiersprachen hantiert.
Hans schrieb:> Wenn man das so macht, dürfte dies> ...> eigentlich nicht mehr auftreten
Das ist der Idealfall. Aber die eigene Unzulänglichkeit und nicht selten
eine anfängliche Nichtwahrnahme besonderer Umstände führen dennoch immer
wieder in solche Überraschungsmomente.
Aber mit der zunehmenden Erfahrung ist man hinsichtlich der möglichen
Fallstricke besser sensibilisiert und entwickelt auch Strategien, unter
anderem Endlosschleifen nicht zuzulassen.
Hans D.
Günther S. schrieb:> Ich habe die Erklärungen zu Projekt /c durch> Grundlegende Konzepte und weiter Beispiele erweitert.>> Webseite : https://www.projektc.at
Hallo Günther,
ich habe mir das Beispiel infosys unter
https://www.projektc.at/programs/c_bsp/infosys/index.html angeschaut.
Die Informationen kann sich ein erfahrener Linux Nutzer oder
Administrator doch einfacher und flexibler direkt mit Standard
Linuxprogrammen wie lsusb, lspci, lsblk, nmap, htop, nmon, lsof, etc.
ansehen und ggf. durch Verwendung von pipes aufbereiten.
Daniel A. schrieb:> size_t sum = total_size + v[i].iov_len;>> if(total_size < sum){
Das ist doch immer der Fall, außer iov_len ist 0 - oder es tritt ein
Overflow auf, was aber nicht passieren kann, weil man zuvor schon
zurückgekehrt ist.
Daniel A. schrieb:> Der Springende Punkt hier ist, es würde Sinn machen, bei memcpy für> src/dst null zu erlauben, wenn length null ist.
Wäre aber schlechter für die Performance; der Sinn davon, UB zu
erlauben besteht ja darin, nicht unbedingt erforderliche Prüfungen
weglassen zu können.
Hans D. schrieb:> Und gegen dieses Problem helfen auch die höheren Programmiersprachen> nicht
Doch, aber natürlich nur in einem gewissen Rahmen. Höhere
Programmiersprache mit strikterer Typprüfung können diverse Logikfehler
direkt im Compiler finden. Und gerade das Problem mit den Null-Pointern
lässt sich mithilfe von Optional/Nullable -Typen stark eindämmen. z.B.
ein Kotlin -Programm, das nirgends den "!!" Operator enthält, kann
"eigentlich" nie mit NullPointerException abstürzen (außer ein paar
Randfälle bedingt durch die historisch gewachsene JVM).
Niklas G. schrieb:> Daniel A. schrieb:>> size_t sum = total_size + v[i].iov_len;>>>> if(total_size < sum){>> Das ist doch immer der Fall, außer iov_len ist 0 - oder es tritt ein> Overflow auf, was aber nicht passieren kann, weil man zuvor schon> zurückgekehrt ist.
Ups, das hab ich vertauscht. Ja, das sollte sum < total_size sein.
Niklas G. schrieb:> Hans D. schrieb:>> Und gegen dieses Problem helfen auch die höheren Programmiersprachen>> nicht> Doch, aber natürlich nur in einem gewissen Rahmen. Höhere> Programmiersprache ...
Das war gar nicht Gegenstand meiner Aussage, wenngleich es natürlich
richtig ist, dass in höheren Programmiersprachen mit strengeren
Anforderungen mögliche Fehlerfälle und Irritationen von vornherein
ausgeschlossen werden können. Deshalb ist es beispielsweise bei VBA in
jedem Fall empfehlenswert, in einem Modul ganz oben (als erstes) die
Anweisung "Option Exlplicit" zu verwenden. Einen Zwang dazu gibt es
freilich nicht.
Mein Hinweis adressiert die Gedankenfehler (= logische Fehler) in der
Programmlogik, und zwar auch dann, wenn alle Maßnahmen wie die
vorstehend als Beispiel benannte Option bereits genutzt sind. Und genau
diese Gedankenfehler können und werden je nach ihrer Art zu
Laufzeitfehlern wie zum Beispiel eine Nullexception führen.
Am Ende bleibt nur, wie hier bereits erwähnt wurde, das Programm zu
testen und/oder Laufzeitfehler sukzessive auszumerzen.
Hans D.
Hans D. schrieb:> Mein Hinweis adressiert die Gedankenfehler (= logische Fehler) in der> Programmlogik, und zwar auch dann, wenn alle Maßnahmen wie die> vorstehend als Beispiel benannte Option bereits genutzt sind. Und genau> diese Gedankenfehler können und werden je nach ihrer Art zu> Laufzeitfehlern wie zum Beispiel eine Nullexception führen.
Grundsätzlich und theoretisch stimmt das, z.B. in einem komplexen
Graphen-Algorithmus der viel mit Zeigern herumhantiert lässt sich das
prinzipbedingt nicht vermeiden. Aber 95% der Verwendung von Referenzen
folgen einem simplen Schema, welches sich in den entsprechenden
Programmiersprachen in Nullable-Typen abbilden lässt. Und dann zwingt
der Compiler den Programmierer dazu, diese Gedankenfehler zu beheben,
sonst wird das Programm nicht übersetzt, und dann können
Null-Exceptions nicht mehr auftreten.
Aber solche Null-Exceptions sind natürlich sowieso nur ein möglicher
Fehlerfall, und Mengen von sonstigen Logik-Fehlern kann man nicht so
einfach statisch finden - die sind dafür aber oft besser reproduzierbar
& testbar.
Niklas G. schrieb:> Gibt's eigentlich einen Grund warum so viele Funktionen auf die> historische Art deklariert sind? Also z.B.:> bool isRoot()
Ds ist entweder K&R-Code aus der vorderen Altsteinzeit (dann ist das von
Dir geschriebene möglich) oder aber C++, und dann geht das nicht, denn
in C++ ist x() äquivalent zu x(void).
Harald K. schrieb:> oder aber C++, und dann geht das nicht, denn in C++ ist x() äquivalent> zu x(void).
Ja, aber es ist ja C, und explizit als C-Werkstatt tituliert...
Harald K. schrieb:> Ds ist entweder K&R-Code aus der vorderen Altsteinzeit (dann ist das von> Dir geschriebene möglich) oder aber C++, und dann geht das nicht, denn> in C++ ist x() äquivalent zu x(void).
Meines Wissens gibt es die Prototypen bis und mit C17, ab C23 ist
`void()` equivalent zu `void(void)`.
Finde ich persönlich schade, damit konnte man fast einen generischen
Funktionspointer mit erlaubter impliziter Konvertierung erstellen,
ähnlich wie void* für Objekte. Nur der Rückgabetyp musste passen:
https://godbolt.org/z/j5daqxYdn
Daniel A. schrieb:> Finde ich persönlich schade
Was hindert Dich daran, Deinen Code mit einem entsprechendem
Compilerswitch zu übersetzen?
> clang supports the -std option, which changes what language mode> clang uses. The supported modes for C are c89, gnu89, c94, c99,> gnu99, c11, gnu11, c17, gnu17, c23, gnu23, c2y, gnu2y, and various> aliases for those modes.
Für den original-Eidotter-und Brotkrümel-im-Bart-Stil von 1977 brauchst
Du möglicherweise einen anderen Compiler, aber ganz so weit muss man ja
vielleicht nicht zurückgehen.
Daniel A. schrieb:> Finde ich persönlich schade, damit konnte man fast einen generischen> Funktionspointer mit erlaubter impliziter Konvertierung erstellen,> ähnlich wie void* für Objekte. Nur der Rückgabetyp musste passen:> https://godbolt.org/z/j5daqxYdn
Wobei sich mir der Nutzen nicht so ganz erschließt, warum nicht z.B. so?
https://godbolt.org/z/eKsqbqW6r
Es ist nur marginal mehr Tipparbeit, und die Casts sind zulässig,
solange man den Funktionszeiger ausschließlich über den ursprünglichen
Typ aufruft. So ist IMO auch deutlich klarer was dort passiert.
Alternativ auch so:
https://godbolt.org/z/nKh8563ze
Noch etwas länger, aber so ist immerhin zentral sichtbar welche
Zeigertypen erlaubt sind.
Daniel A. schrieb:> Ich finde es einfach Eleganter.
Weil dich der explizite Cast stört? Du konvertierst ja auch, nur dass
der Compiler das ohne den Cast-Operator durchgehen lässt. In C++
könntest du dir eine Wrapper-Klasse bauen der die implizite
Konvertierung ermöglicht...
Also wenn ich diesen Thread verfolge, stellt sich mir ein paar Fragen.
Eine davon wäre, warum man immer weiter auf C herumreiten will? Da gibt
es unendlich viele Tutorials. Es wird gefühlt kein Aspekt ausgelassen.
Viel interessanter finde ich C++. Auch dafür gibt es bereits reichlich
Literatur. Aber, sobald man den PC als Zielplattform verlässt, wird es
sehr dünn. Ich finde, dass Arduino mit seiner Machart etwas zu weit
geht. Soviel Mist muss übersetzt werden, der am Ende gar nicht verwendet
wird.
Und wer glaubt, dass sich dies bei den 32-Bit Mikrocontrollern wie die
ARM Cortex-M geändert hätte, liegt falsch. Den Grundstein hat ST mit
seiner unsäglich schrottigen Libraries gelegt. Arduino macht es nicht
wirklich besser.
Da wäre es doch interessant, mal in diese Richtung aktiv zu werden. SO
richtig viel ordentlich recherchierte und verfasste Literatur gibt es
eigentlich nicht in einem Buch.
Thema Wrapper in C++ - Ja, die muss man nutzen, wenn C Code eingebettet
wird. Auch keine wirklich schöne Sache - vor allem dann nicht, wenn mal
ein halbwegs vernünftiger Debugger ins Spiel kommen muss.
Gerhard W. schrieb:> Also wenn ich diesen Thread verfolge, stellt sich mir ein paar Fragen.
Und die hättest Du nicht zu Lebzeiten dieses Threads stellen können?
> Eine davon wäre, warum man immer weiter auf C herumreiten will?
C ist nun einmal der kleinste gemeinsame Nenner.
Gerhard W. schrieb:> Viel interessanter finde ich C++.
C++ wird immer mit Fackeln und Mistgabeln begegnet. Nicht sehr
motivierend. Da behält man sein Wissen lieber für sich und freut sich,
produktiver als die Konkurrenz zu sein.
Gerhard W. schrieb:> Thema Wrapper in C++ - Ja, die muss man nutzen, wenn C Code eingebettet> wird.
Was wo? Nur das 'extern "C"' Ding aber das ist kein Wrapper.
Gerhard W. schrieb:> Viel interessanter finde ich C++. Auch dafür gibt es bereits reichlich> Literatur. Aber, sobald man den PC als Zielplattform verlässt, wird es> sehr dünn.
C++ ist ja nun, wie alle anderen Programmiersprachen auch, völlig
plattformunabhängig. Und die Zeit der Bücher zu solchen Themen neigt
sich doch auch arg dem Ende zu.
Oliver
Oliver S. schrieb:> C++ ist ja nun, wie alle anderen Programmiersprachen auch, völlig> plattformunabhängig
Es gibt aber gewisse Patterns und Methoden die für Mikrocontroller
besonders geeignet sind, die aber in der gängigen Literatur nicht
auftauchen.
Und so manche Programmiersprache ist überhaupt nicht
plattformunabhängig.
Rick schrieb:> Sogar Beethoven hat seine erste Sinfonie> in C geschrieben!
Wobei sich dann sofort die Frage stellt: könnte man die Sinfonie heute
in C++ schreiben?
Nemopuk schrieb:> Eher in C#
Musik mit dem .Net-Geraffel als Unterbau ... mit nicht definiertem
Zeitverhalten, weil während der Aufführung immer mal wieder jemand über
die Bühne latscht, um Müll einzusammeln.
Harald K. schrieb:> Man muss nicht alles erklären. Ich gehe stark davon aus, daß mich> auch jemand verstanden haben dürfte.
Es ging nicht um Dich. C# = C Dur in der Musik.
Frank M. schrieb:> C# = C Dur in der Musik.
Nee. C# heißt Cis. Das ist nur ein Ton, keine Tonart. Cis ist einen
Halbton höher als C. Ein Halbton ist ein Zwölftel der Oktave.
Christoph M. schrieb:> könnte man die Sinfonie heute in C++ schreiben?
Ich denke schon.
Im Zweifelsfall packt man ein 'extern "C" {}' drumrum. Ich kenne mich
mit Notenschrift aber nur recht rudimentär aus....
Günther S. schrieb:> Bei meiner Beschäftigung mit dem Raspberry Pi ist eine> umfangreiche> C-Werkstatt entstanden.
Danke, für mich eine gute Hilfe.
Gruss Jan
Frank M. schrieb:> Es ging nicht um Dich. C# = C Dur in der Musik.
Cis
(abgekürzt als C♯) ist in der Musik eine erhöhte Note, die einen
Halbtonschritt über dem Stammton C liegt, erkennbar am Kreuz-Symbol (#)
in der Notation und den schwarzen Tasten auf dem Klavier.
https://youtu.be/Wj002s8DtK8