Hallo,
dies ist eine Anfängerfrage. Ich will in einem C-Programm, das auf einem
AVR läuft, einen String programmatisch zusammen setzen und stehe etwas
auf dem Schlauch (in anderen Sprachen wie z.B. JAVA, VB oder C# für
PC-Programmierung ist das einfach).
Der String testString soll aus Zeichenfolgen wie z.B. "A = " und aus
beliebigen Zahlen, die in uint8_t Variablen vorliegen, zusammen gesetzt
werden. Die Zahlen sollen einfach nur als Byte-Wert in den String
eingefügt werden. Sie sollen nicht dezimal oder formattiert erscheinen,
sondern nur als einzelner character, auch wenn es dafür kein
menschen-lesbares ASCII-Zeichen gibt.
Danke schon Mal für eure Hilfe.
Beispiel:
String testString = "";
uint8_t byte1 = 0x4B; //entspricht ASCII-Zeichen für K
uint8_t byte2 = 0xC8; //keine lesbare ASCII-Zeichen Entsprechung bzw.
Sonderzeichen
testString = "A = " + byte1 + ", B = " + byte2 + "." + "\n"; //Abschluss
mit Zeilenvorschub
So soll der zusammengesetzte String (als Text) aussehen:
A = K, B = irgendein Zeichen für byte2.
neue Zeile
Es ist nicht wirklich sinnvoll, nicht druckbare Zeichen in einem String
zu speichern, der für druckbare Zeichen vorgesehen ist.
Natürlich geht das trotzdem.
> Gunnar F.
sprintf(,,) ist tatsächlich dafür geeignet ...
aber da es eine Art eierlegende Wollmilchsau ist, braucht es mächtig
viel Platz im Speicher.
Danke schon Mal für die ersten Antworten. Die Zahlen, die in byte1 und
byte2 enthalten sind müssen nicht in für Menschen lesbaren Zeichen im
testString erscheinen. Der testString soll seriell übertragen werden.Es
reicht, wenn er maschinenlesbar ist.
sprintf verbraucht zu viel Flash. Ich will nicht mehr als ein paar
Code-Bytes spendieren, bzw. soviel wie minimal nötig.
StefanK schrieb:> Die Zahlen, die in byte1 und> byte2 enthalten sind müssen nicht in für Menschen lesbaren Zeichen im> testString erscheinen.
Du musst nur aufpassen, dass die rohen Bytes am Ende dein Protokoll
nicht brechen. Schwierig sind da mindestens '\x00', '\n', '\r', und ','.
Benedikt M. schrieb:> Du musst nur aufpassen, dass die rohen Bytes am Ende dein Protokoll> nicht brechen
Eben deshalb benutzt man für binäre Daten keine Strings.
Es reicht ein Magic-Word als StartWort, dann die beiden Bytes und zum
Abschluss noch eine einfache Prüfsumme, z.B. die Addition der beiden
Bytes.
5 Bytes in der Übertragung für 2 Nutzbytes sind schon mehr als genug
Overhead.
Benedikt M. schrieb:> Du musst nur aufpassen, dass die rohen Bytes am Ende dein Protokoll> nicht brechen. Schwierig sind da mindestens '\x00', '\n', '\r', und ','.
Interessanter Hinweis, danke. Ich implementiere das in einem Soft-UART.
Wenn der String übertragen ist, soll ein Zeilenumbruch erfolgen.
Wie erreiche ich den Zeilenumbruch? Bzw womit muss ich den String
abschliessen?
Ein String in C ist ja nun nichts anderes als ein Array. Dafür gibts
memcpy.
Falls dir das für Strings und den abschliessenden /0 noch zu kompliziert
ist, gibts dafür passende String-Funktionen. Ich werfe mal strcat und
strcpy in den Ring.
Oliver
Benedikt M. schrieb:> Du musst nur aufpassen, dass die rohen Bytes am Ende dein Protokoll> nicht brechen. Schwierig sind da mindestens '\x00', '\n', '\r', und ','.
NUL ist ein Problem, wenn man die für strings vorgesehenen Funktionen à
la strlen verwendet. Aber was soll an den anderen Zeichen "schwierig"
sein?
Oliver S. schrieb:> Ist das denn alles zur Compilezeit bekannt, oder sind die Bytes> variabel?
Die Bytes bzw. die Zahlenwerte werden im Hauptprogramm berechnet und
sind variabel. Der Textanteil wie z.B. "A = " ist konstant und steht zur
Compile-Zeit schon fest.
Harald K. schrieb:> NUL ist ein Problem, wenn man die für strings vorgesehenen Funktionen à> la strlen verwendet. Aber was soll an den anderen Zeichen "schwierig"> sein?
Je nach Implementierung der entgegennehmenden Software wird zeilenweise
eingelesen und verarbeitet. Ein \n (und meistens auch ein \r) würden
dann zu zwei ungültigen, partiellen Nachrichten führen. Das Komma stört
beim Trennen der Werte in einer Zeile.
StefanK schrieb:> sprintf verbraucht zu viel Flash. Ich will nicht mehr als ein paar> Code-Bytes spendieren, bzw. soviel wie minimal nötig.
Mit ein wenig Pointerakrobatik, geschickt genutzten Unions auf
Arrays usw., ist das ja auch kein Problem.
Nur muss man den Wald und seine Bäume kennen, sonst herrscht da nur
Dunkelheit.
Nemopuk schrieb:> Wie gefällt dir das?
Gut, schließlich habe ich es ja schon vor 3 Stunden gepostet.
Nemopuk schrieb:> mit strchr() suchen
Von hinten durch die Brust ins Auge?
Dann kann man ja gleich sprintf nutzen.
StefanK schrieb:> sprintf verbraucht zu viel Flash.
Dann nimmste eben nicht den ATtiny13, sondern den ATtiny85.
Die Lib kostet doch nur beim ersten Aufruf mehr Flash.
StefanK schrieb:> Ich würde gern ohne das Einbinden von Funktionen auskommen. Wie gesagt,> wenn String ungeeignet ist, nehme ich lieber ein Array.> Soft-UartStefanK schrieb:> Wie erreiche ich den Zeilenumbruch? Bzw womit muss ich den String> abschliessen?StefanK schrieb:> ohne das Einbinden von Funktionen
In Summe ist m.E. Marios Ansatz der einzig sinnvolle, möglicherweise
sogar noch eine Nummer "rudimentärer" für den Anfang. Statt
Mario M. schrieb:> Dann kann man die Teile auch nacheinander ausgeben.> puts("A =");> putc(byte1);> puts(", B =");> putc(byte2);> puts(".\n");
eher
Wie oft soll Benedikt das noch sagen?
Benedikt M. schrieb:> Je nach Implementierung der entgegennehmenden Software wird zeilenweise> eingelesen und verarbeitet. Ein \n (und meistens auch ein \r) würden> dann zu zwei ungültigen, partiellen Nachrichten führen. Das Komma stört> beim Trennen der Werte in einer Zeile.
Ja, es gibt Fälle, wo byte1 und byte2 nie kleiner als 32 werden können.
Aber selbst dann geht's dank ',' immer noch schief. Solange man den
möglichen Wertebereich nicht kennt, kann man Strings vergessen.
Ich würde je 2 Zeichen spendieren und Hex senden. Das kostet nur ein
paar Byte Flash.
StefanK schrieb:> Die Zahlen sollen einfach nur als Byte-Wert in den String> eingefügt werden. Sie sollen nicht dezimal oder formattiert erscheinen,> sondern nur als einzelner character, auch wenn es dafür kein> menschen-lesbares ASCII-Zeichen gibt.
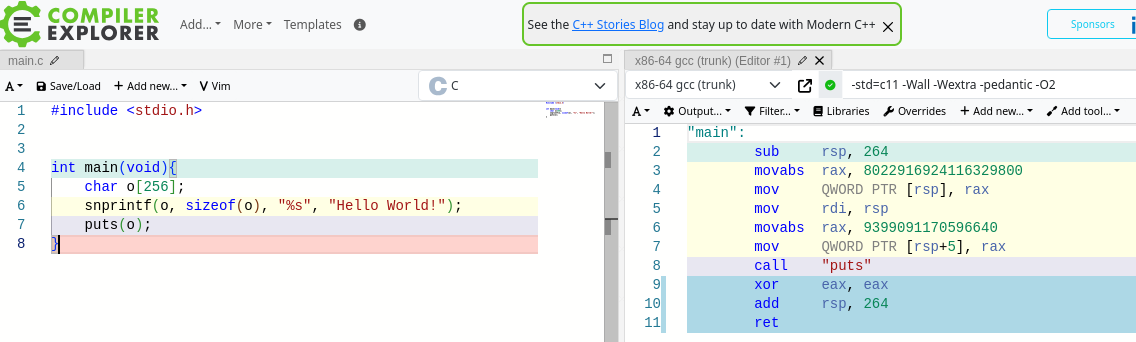
Also wenn du das wirklich so möchtest, dann hab ich dir da eben mal kurz
was zusammengebastelt. Vielleicht kannst es noch auf deine Bedrüfnisse
anpassen, aber im großen und ganzen funktioniert es.
Getest in der Konsole (Visual Studio).
1
#include<stdio.h>
2
#include<stdint.h>
3
#include<string.h>
4
5
/**
6
* str Input String with placeholder '%' for values
StefanK schrieb:> Die Zahlen sollen einfach nur als Byte-Wert in den String> eingefügt werden.
...
> So soll der zusammengesetzte String (als Text) aussehen:> A = K, B = irgendein Zeichen für byte2.> neue Zeile
Und wenn du nun 10 / 0xA als Wert von dem Byte hast, dann hast du dort
ein newline. Also das erscheint mir nicht sinnvoll. Entweder du machst
alles ein Binärprotokoll, oder alles ein Text Protokoll, aber doch nicht
gemischt!
In diesem Fall, wie wärs mit 2 Bytes Hexadezimal stattdessen?
1
#include<stdio.h>
2
#include<stdint.h>
3
4
staticinlinecharhex(uint8_tx){
5
returnx<10?x+'0':x<16?x-10+'A':'#';
6
}
7
#define HEX(X) hex((X) / 16), hex((X) % 16)
8
9
intmain(void){
10
intbyte1=0x4B;
11
intbyte2=0xC8;
12
chartestString[]={
13
'A',' ','=',' ',HEX(byte1),',',' ',
14
'B',' ','=',' ',HEX(byte2),'.','\n',
15
0
16
};
17
puts(testString);
18
}
In solchen Fällen wäre es echt praktisch, wenn man sowas wie "char
x[]={"A = ", 'A', 0};" schreiben könnte, aber leider kann das C noch
nicht...
Oder man nimmt halt snprintf:
1
chartestString[17];
2
snprintf(testString,sizeof(testString),"A = %02X, B = %02X.\n",byte1,byte2);
Irgendwie ist das echt so eine Macke von C, oder? Irgendwie scheint C
Probleme mit Strings zu haben. Merke das gerade bei Arduino-Sprech, was
ich für meinen MPP-Tracker mit ESP32-Webserver "lernen" musste. Die
Ausgaben mittels getrennten Funktionsaufrufen aneinander zu basteln ist
wirklich die einfachste Methode, ein Char an einen String anhängen geht
auch noch, aber den Versuch, mehrere Strings zusammenfügen und in einer
Funktion ausgeben, habe ich auch erstmal nach hinten geschoben.
Moin,
Ben B. schrieb:> Irgendwie ist das echt so eine Macke von C, oder? Irgendwie scheint C> Probleme mit Strings zu haben.
Ja, es ist wie verhext. Um in C mit Strings arbeiten zu koennen, muss
man C koennen. Ein Teufelskreis.
scnr,
WK
Dergute W. schrieb:> Um in C mit Strings arbeiten zu koennen, muss man C koennen.
"Arduino" macht einem das Leben mit Strings ja etwas einfacher. Und aber
in "Arduino" mit Strings zu arbeiten, muss man "Arduino" können.
Ist schon blöd mit der Programmiererei...
Oliver
Ben B. schrieb:> aber den Versuch, mehrere Strings zusammenfügen ...> habe ich auch erstmal nach hinten geschoben.
Kennst du etwa strncat() und snprintf() nicht? Vielleicht sollte man die
Anleitung lesen, bevor man ein Werkzeug benutzt und dabei scheitert.
C ist eigentlich sehr durchdacht. Nur die '\0' ist reserviert für
Stringfunktionen als Endezeichen. Damit ist es theoretisch möglich,
selbst 1TB lange Strings anzulegen.
Beim Arduino kannst du mit "Serial.print" alles wild
aneinanderklatschen. Der macht das dann schon irgendwie. Ist dort ja
auch egal, wenn man da einen "dicken" oder einen noch dickeren Prozessor
auf dem Steckbrett hat.
Axel R. schrieb:> eim Arduino kannst du mit "Serial.print" alles wild> aneinanderklatschen. Der macht das dann schon irgendwie.
Es geht hier aber um C, nicht um Arduino und auch nicht um C++. Dass es
in anderne Sprachen einfach ist, hat der TO schon in den
Eröffnungsbeitrag geschrieben.
Ich kenne die printf-Varianten, aber sie nerven. Man merkt da halt
irgendwie eine Schwäche der Programmiersprache, und zwar eine, die ich
von einer Hochsprache so nicht erwarte. In Hochsprachen sollten einem
solche Probleme eigentlich abgenommen werden bzw. da darf sich der
Compiler drum kümmern und in anderen Programmiersprachen funktionierts
ja schließlich auch. Nur manche kriegens irgendwie nicht hin, egal wie
alt sie sind und wie lange daran schon weiterentwickelt wird.
Und übrigens muss ich euch enttäuschen, ich bin nicht gescheitert. In
diesem Forum scheinen es ein paar Kranke besonders gerne zu sehen, wenn
irgend jemand an irgendwas scheitert - solange sie es nicht selber sind
versteht sich. Es tut mir furchtbar leid, aber der MPP-Tracker und der
darauf laufende Webserver funktioniert bislang einwandfrei.
Wenn man mit Strings anfängt, bleibt nur strcat oder eigene
Pointer-Arithmetik.
Letztendlich baut man sich dann auch nur die Funktion von strcat
Benutzerdefiniert zusammen. (man spart sich aber printf etc. die
Overhead erzeugen.)
Ben B. schrieb:> In Hochsprachen sollten einem solche Probleme eigentlich abgenommen> werden bzw. da darf sich der Compiler drum kümmern und in anderen> Programmiersprachen funktionierts ja schließlich auch.
Das sind aber alles Programmiersprachen für weit größere Computer als
ATiny13. Bedenke, daß C von allen "Hochsprachen" mit Absicht eine der
niedrigsten ist. Sie stammt aus den frühen 70er Jahren, da hatten die
Computer nur wenige kB RAM. Deswegen ist C ja für kleine Mikrocontroller
fast alternativlos.
Arduinos Stream und String Klassen gehen in die Richtung, die dir
vorschwebt, brauchen aber auch etwas größere Mikrocontroller. Der
ATtiny85 wurde schon genannt.
Wenn ich mal unterstelle, dass DU keine eierlegende Wollmilchsau
brauchst, solltest DU es mal ins Auge fassen, selber eine Funktion zu
schreiben.
Ist gar nicht so schwer. Vor allem wenn DU genau weist, wie groß der
Wertebereich ist und nicht noch 1000 Sonderfälle abgedeckt werden
müssen.
Normale Sensoren liefern nicht plötzlich: "keine Ahnung" sondern immer
irgendwelche Werte in einem genau vorhersagbaren Bereich.
Ben B. schrieb:> Man merkt da halt> irgendwie eine Schwäche der Programmiersprache, und zwar eine, die ich> von einer Hochsprache so nicht erwarte. In Hochsprachen sollten einem> solche Probleme eigentlich abgenommen werden bzw. da darf sich der> Compiler drum kümmern und in anderen Programmiersprachen funktionierts> ja schließlich auch.
Eigentlich nicht. Der Compiler kann nur sehr begrenzt ahnen, was
dargestellt wird. Meist wird ein Vielfaches an RAM und Rechenleistung
vorausgesetzt und der String mit dynamischem Speicher zur Laufzeit
gebastelt.
Für den TO ist selbst die C-Standardlösung noch zu ressourcenhungrig.
Nemopuk schrieb:> Deswegen ist C ja für kleine Mikrocontroller> fast alternativlos.
Überhaupt nicht.. es ist ja egal worauf portiert oder gewrapped wird..
Letztendlich ist egal welche Sprache man nimmt, es bleibt nur ein
"Wrapper" auf optimiertes ASM in einem kompiliertem Binary..
Es kommt halt nur darauf an wie nah es umgesetzt wurde.
z.B. SprintF .. Wäre es Perfekt im Compiler umgesetzt, sollte es nicht
mehr aufblähen als vergleichbare Strcat Aufrufe. Das macht beim Attiny
Sinn, beim Mega nicht mehr.. deswegen ist es wohl eher "nice to Have"
Philipp K. schrieb:> z.B. SprintF .. Wäre es Perfekt im Compiler umgesetzt, sollte es nicht> mehr aufblähen als vergleichbare Strcat Aufrufe.
Also überhaupt keine Ahnung...
Johann L. schrieb:> Also überhaupt keine Ahnung...
und du keinen Horizont ..
bei AVR haben die nunmal das avr-libc Framework für die Teile, es ist
nur alternativlos weil womöglich alles andere darauf basiert und niemand
etwas anderes braucht.
Philipp K. schrieb:> Johann L. schrieb:>> Also überhaupt keine Ahnung...>> und du keinen Horizont ..>> bei AVR haben die nunmal das avr-libc Framework für die Teile, es ist> nur alternativlos weil womöglich alles andere darauf basiert und niemand> etwas anderes braucht.
Kannst du irgendeine Toolchain nennen, gleich ob für AVR oder nicht, ob
GCC oder nicht, die sprintf zu strcat transformiert?
Johann L. schrieb:> Kannst du irgendeine Toolchain nennen, gleich ob für AVR oder nicht, ob> GCC oder nicht, die sprintf zu strcat transformiert?
Er wird eine sprintf-Implementierung finden, die auch die 3 Zeilen von
strcat enthält.
(Für alle nicht C-ler: strcat hat z.B. den Code unten, ohne jeden
Funktionsaufruf. sprintf braucht je nach Implementierungsumfang ~ 100
oder 1000 Mal mehr Zeilen Quelltext)
Bruno V. schrieb:> Johann L. schrieb:>> Kannst du irgendeine Toolchain nennen, gleich ob für AVR oder nicht, ob>> GCC oder nicht, die sprintf zu strcat transformiert?>> Er wird eine sprintf-Implementierung finden, die auch die 3 Zeilen von> strcat enthält.
Selbst wenn, hat das absolut nix mit meiner Frage zu tun.
Dergute W. schrieb:> Moin,>> StefanK schrieb:>> Wie erreiche ich den Zeilenumbruch?> "Vielleicht mal einen Blick in ein C-Buch werfen?\n">> Gruss> WK
ASCII-Tabelle wäre besser geeignet.
Johann L. schrieb:> Philipp K. schrieb:>> z.B. SprintF .. Wäre es Perfekt im Compiler umgesetzt, sollte es nicht>> mehr aufblähen als vergleichbare Strcat Aufrufe.>> Also überhaupt keine Ahnung...
Naja, moderne Compiler verstehen den Formatstring und vergleichen ihn
mit den angegebenen Parametern und bringen ggf. eine Fehlermeldung. Es
wäre also nicht so schwer, so eine Optimierung einzubauen. Geht
natürlich nur für statische Formatstrings.
Man hat damit aber die sprintf-Funktion in den Compiler verlagert. Sowas
möchte ich nicht warten müssen.
Markus K. schrieb:> Es wäre also nicht so schwer, so eine Optimierung einzubauen. Geht> natürlich nur für statische Formatstrings.
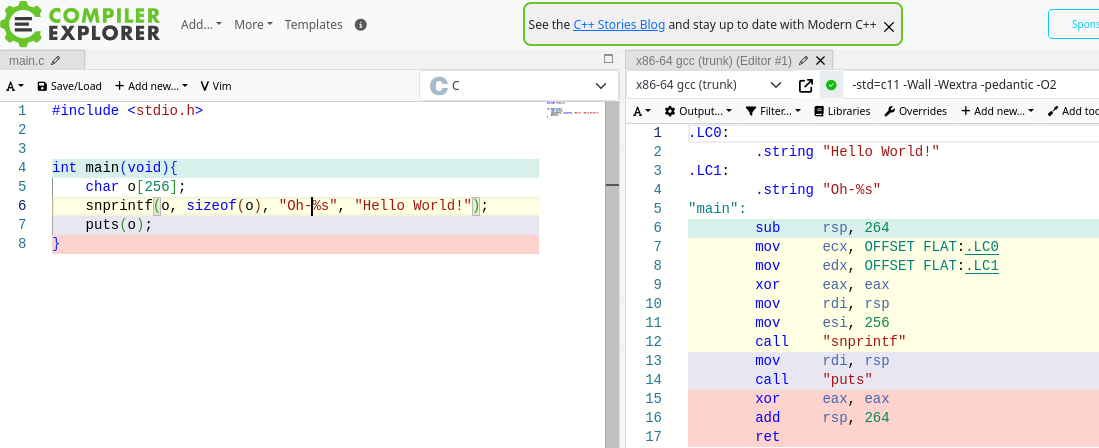
Wird manchmal sogar gemacht. z.B. hier https://godbolt.org/z/snE5Tj3WP
ist die Funktion komplett weg.
Daniel A. schrieb:> Markus K. schrieb:>> Es wäre also nicht so schwer, so eine Optimierung einzubauen. Geht>> natürlich nur für statische Formatstrings.>> Wird manchmal sogar gemacht. z.B. hier https://godbolt.org/z/snE5Tj3WP> ist die Funktion komplett weg.
Leider nur für den trivialen Formatstring "%s" als Ausnahmefall,
vermutlich weil da einfach gar nichts für snprintf() zu tun ist und
deshalb der ganze Aufruf ersatzlos (!) wegoptimiert werden kann.
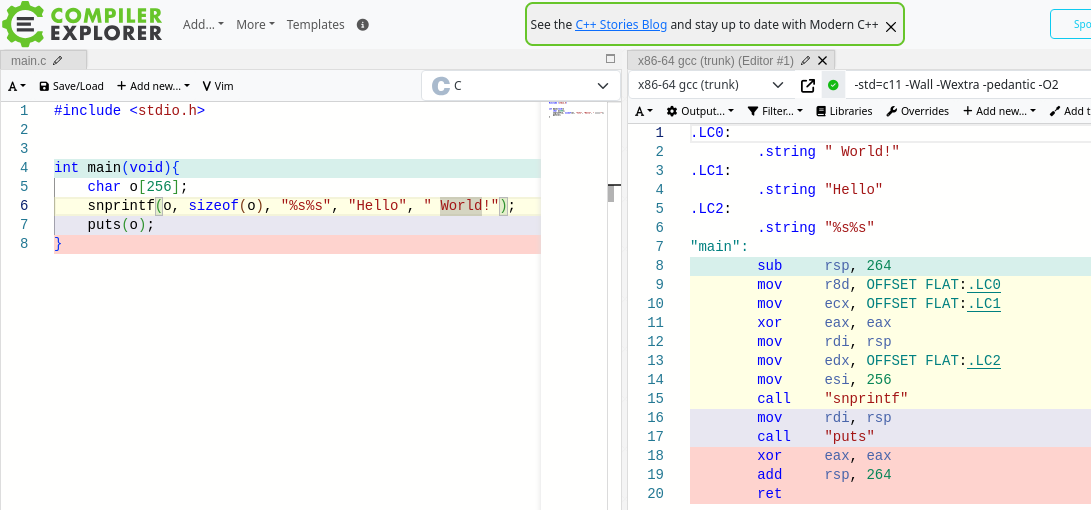
Aber schon bei Anreicherung des Formatstrings um konstante Zeichen oder
um ein zweites Stringargument "%s%s" wird auch hier (wie Johann ja
weiter oben schon nahelegte) nicht etwa zu strcat() transformiert,
sondern wieder ganz stumpf snprintf() aufgerufen.
Markus K. schrieb:> Man hat damit aber die sprintf-Funktion in den Compiler verlagert. Sowas> möchte ich nicht warten müssen.
Zumal strcat() und snprintf() afaik ja auch noch aus verschiedenen
Bibliotheken kommen. Trotzdem schade, eigentlich...
(re)
Nemopuk schrieb:> Das sind aber alles Programmiersprachen für weit größere Computer als> ATiny13. Bedenke, daß C von allen "Hochsprachen" mit Absicht eine der> niedrigsten ist. Sie stammt aus den frühen 70er Jahren, da hatten die> Computer nur wenige kB RAM. Deswegen ist C ja für kleine Mikrocontroller> fast alternativlos.
Das ist wohl etwas kurz gesprungen.
Zur damaligen Zeit gab es auch schon andere Hochsprachen, z.B. Pascal
(1971 und damit 1 Jahr früher als C 1972), die auf den damaligen
Systemen problemlos liefen. Mikropozessoren und embedded Systeme standen
zum damaligen Zeitpunkt noch nicht zur Verfügung bzw. waren gerade am
Start (TMS1000 von TI 1971). Der legendäre Z80 kamm rund 5 Jahre später.
Diese kleine Systeme wurden seinerzeit auch nicht mit Hochsprachen
programmiert da war Assemblercode das höchste der Gefühle und nicht
selten wurde die SW als Opcode in diese kleinen Systeme eingehackt.
Natürlich gab es auch schon Hochsprachen wie Algol, Fortran, Cobol oder
Basic, um nur mal eine kleine Auswahl zu nennen, allerdings waren diese
den damaligen "Großrechnern" vorbehalten - Personalcomputer gab es 1971
auch noch nicht. Computer waren damals eben vom Volumen her noch
ordentlich groß.
Welche Hochsprache nun zur Programmierung von Mirocontrollern/embedded
Systemen benutzt wird ist keine Frage der Sprache selbst, sondern ob es
einen Compiler/Linker für diese Sprache gibt, der den für den Controller
passenden Binärcode in möglichst compakter Form erzeugen kann - es gibt
ja mittlerweile auch Pascalcompiler die embedded Code erzeugen.
Dennoch hat sich da offenbar C als recht vorteilhaft erwiesen. Ich
zitiere mal aus Wikipedia
(https://de.wikipedia.org/wiki/C_(Programmiersprache):
"Der Grund liegt in der Kombination von erwünschten Charakteristiken wie
Portabilität und Effizienz mit der Möglichkeit, Hardware direkt
anzusprechen und dabei niedrige Anforderungen an eine Laufzeitumgebung
zu haben." (Zitatende).
C in seiner Grundversion hat eigentlich nur 4 Datentypen (char, int,
float, double) und nur 32 Schlüsselworte, was die Sprache sehr schlank
und damit prädisteniert für embedded Systeme macht. Einen Stringtyp, um
den es in diesem Thread geht, kennt C gar nicht. Das ist halt ein
char-Array. Genau das macht das Stringhandling für den Programmierer
(Anfänger) eben schwieriger und ungewohnter, zumindest für Leute die von
anderen Sprachen kommen.
Neben den vielen Vorteilen, muß man eben auch einige Nachteile in Kauf
nehmen - Stichwort: undefined behavior.
Philipp K. schrieb:> z.B. SprintF .. Wäre es Perfekt im Compiler umgesetzt, sollte es nicht> mehr aufblähen als vergleichbare Strcat Aufrufe. Das macht beim Attiny> Sinn, beim Mega nicht mehr.. deswegen ist es wohl eher "nice to Have"
Eben.
Es gibt noch vieles, was der Compiler idealerweise optimieren können
sollte. Bspw. könnte ich mir vorstellen, dass er jegliche Arithmetik im
Programmcode mittels eines integrierten CAS erst einmal mathematisch
vereinfacht, bevor er Assembler-/Maschinencode daraus generiert.
Wahrscheinlich fällt jedem irgendetwas ein, was der Compiler noch
zusätzlich können sollte. Integriert man das alles in den Compiler,
passt dieser halt irgendwann nicht mehr in 64 GB Hauptspeicher ;-)
Eigentlich finde es ja auch ganz gut, dass man beim Programmieren noch
etwas mitdenken darf. Für das Problem des TE sind mehrere effiziente
Lösungen vorgeschlagen worden, auf die mit etwas Nachdenken jeder hätte
kommen können. Auch arithmetische Vereinfachungen können IMHO durchaus
dem Programmierer zugemutet werden.
Und wenn der Schalter für die Aktivierung des Gehirns dann doch einmal
klemmt, gibt es ja immer noch die KI :)
Die Optimierung ist ja auch das, was Compiler generell am besten können
sollten. Da kann man mit massivem Rechenleistungsbedarf bzw. Ressourcen
draufhauen, um das beste Ergebnis zu bekommen. Macht man nur ein
einziges Mal, danach ist es fertig und spart hinterher Ressourcen im
Betrieb ein.
Wenn man sowas warten muss, dann wartet man ja normalerweise den
ursprünglichen Quelltext und nicht das Compilat. Das ist doch der Kern,
den ich von einer Hochsprache erwarte - möglichst gute Ergebnisse in (im
Vergleich zu Assembler) deutlich kürzeren Programmierzeit,
Portierbarkeit über mehrere Prozessor-Architekturen und daß ich mich
eben genau nicht um das kümmern muss, was da an Maschinencode aus dem
Compiler rauskommt, bzw. noch nicht mal das System (oder spezielle
Prozessor-Eigenschaften) kennen muss, auf dem das Programm irgendwann
mal laufen soll.
Ben B. schrieb:> Die Optimierung ist ja auch das, was Compiler generell am besten können> sollten. Da kann man mit massivem Rechenleistungsbedarf bzw. Ressourcen> draufhauen, um das beste Ergebnis zu bekommen. Macht man nur ein> einziges Mal, danach ist es fertig und spart hinterher Ressourcen im> Betrieb ein.
Im Prinzip schon, aber es gibt viele Leute, die Interpreter bevorzugen,
weil man da nicht ständig auf den Compiler warten muss.
> Wenn man sowas warten muss, dann wartet man ja normalerweise den> ursprünglichen Quelltext und nicht das Compilat.
Mit "warten" meinte ich den Compiler. Wenn normalerweise ein Bug in
sprintf ist, dann wird er in der stdlib gefixt und es gibt eine neue
Version der stdlib. Wenn aber der Compiler diese Optimierung macht, dann
muss man den Bug im Compiler fixen und je nach Implementation vielleicht
auch noch die Stdlib. Dann ist es plötzlich wichtig, dass die Entwickler
immer die neueste Version vom Compiler installiert haben.
Auch vom Verständnis her: Eine einzelne Funktion in der stdlib zu
verstehen (Sourcecode lesen) ist nicht so schwierig, denn die sind ja
relativ unabhängig voneinander, aber in den Compiler schaut man nicht
mal so kurz rein.
Achso.
Naja, daß man Bugs in seiner Software (also auch in Compilern) fixen
sollte, habe ich mal vorausgesetzt. Und natürlich ist ein Compiler ein
eher komplexes Stück Software, wer sowas mit hoher Qualität schreiben
kann, der kann es hinterher auch warten. Das werden ja Teams sein, sowas
schreibt man heutzutage wohl nicht mehr alleine im stillen Kämmerlein.
Das generelle Problem bei sowas ist eher, sich in fremden Quellcodes
zurechtzufinden. Vor allem wenn sie (mit dem Alter zunehmend) schlecht
dokumentiert und kommentiert sind.
Wenn man aus der Assemblerecke kommt, dann sieht printf erstmal riesig
aus. Aber nennenswert Flash kostet immer nur der erste Aufruf. Danach
kostet es nur noch weitere Formatstrings und den Call.
Float printf paßt sogar spielend in den kleinen ATTiny85.
Daß der Formatstring eine Variable sein kann, ist durchaus ein
nützliches Feature. Ich habe das schon mehrmals benutzt.
In Assembler zu programmieren war vorwiegend ein notwendiges Übel. Vor
den µCs hatte ich schon auf dem PC in Turbo-C programmiert.
Den Keil C51 hatte ich erst 1995 verfügbar und das war immer ein Hassle,
ständig den Dongle umzustecken.
Der AVR-GCC habe ich nicht zum Laufen bringen können. Den konnten die
nicht Linuxer erst mit WINAVR auch benutzen.
Es soll immer noch Leute geben, die den WINAVR2010 benutzen.
Assemblerkenntnisse helfen aber durchaus zu analysieren, wenn der
Compiler mal etwas besonders umständlich macht oder ob er überhaupt das
macht, was man dachte.
Markus K. schrieb:> Mit "warten" meinte ich den Compiler. Wenn normalerweise ein Bug in> sprintf ist, dann wird er in der stdlib gefixt und es gibt eine neue> Version der stdlib. Wenn aber der Compiler diese Optimierung macht, dann> muss man den Bug im Compiler fixen und je nach Implementation vielleicht> auch noch die Stdlib.
...und die newlib und die dietlibc und... eine Dose voller Würmer. Und
wer mit "-ffreestanding" kompiliert, hat vielleicht eine eigene libc.
Ich habe selten so gestaunt, wie damals, als der gcc mein printf() durch
puts() ersetzt hat.
Zu der ursprünglichen Frage: will man überhaupt Strings zusammen bauen?
Ich finde printf() viel übersichtlicher. Oft muss man sowieso warten,
bis die Ausgabe fertig ist. Dann kann printf() direkt ausgeben und
braucht nur ein paar Byte Stack. Wer fprintf() nicht mag, kann auch
stdout umschalten.
Damit sich die Ausgabe per DMA oder Interrupt wirklich lohnt, braucht
printf() beliebig viel RAM. Oder man muss doch wieder warten, aber nur
manchmal, und man weiß trotzdem nicht, wann die Ausgabe fertig ist.
Ben B. schrieb:> Naja, daß man Bugs in seiner Software (also auch in Compilern) fixen> sollte, habe ich mal vorausgesetzt.
Aber das ist genau der Punkt. Wenn Du Maintainer der glibc bist, dann
ist der Compiler eben nicht Deine Software. Das ist ein ganz anderes
Projekt, mit anderen Leuten. Da kommt dann ein Bugreport rein und dann
ist das 10 Jahre her, dass das implementiert wurde und der Compiler
sieht intern mittlerweile ganz anders aus.
Natürlich wird man dann einen Bugreport beim Compiler-Projekt einkippen
usw. usf. aber insgesamt ist das alles sehr viel komplexer geworden.
Ben B. schrieb:> Die Optimierung ist ja auch das, was Compiler generell am besten können> sollten.
An erster Stelle sehe ich da die Korrektheit des erzeugten Codes.
> Da kann man mit massivem Rechenleistungsbedarf bzw. Ressourcen> draufhauen, um das beste Ergebnis zu bekommen.
Nicht wirklich. In GCC zum Beispiel müssen alle Algorithmen
linearistisch in der Eingabe sein, d.h. Komplexität ist O(x^{1+eps}) für
beliebig kleines eps (zum Beispiel ist Komplexität x*log(x) ok, x^2 ist
es nicht). Viele Algorithmen haben jedoch sogar exponentielle Laufzeit,
etwa beste Registerallokation, bestes Scheduling, etc. Die
nichttriviale Kunst besteht dann darin, eine abgeschwächte
linearistische Version des Algorithmus zu finden, die keine allzu großen
Abstricht bei der Codegüte macht. Das beste Ergebnis (also an der
Pareto-Grenze) ist jedoch ein nicht erreichbares Ziel.
Yalu X. schrieb:> Es gibt noch vieles, was der Compiler idealerweise optimieren können> sollte. Bspw. könnte ich mir vorstellen, dass er jegliche Arithmetik im> Programmcode mittels eines integrierten CAS erst einmal mathematisch> vereinfacht, bevor er Assembler-/Maschinencode daraus generiert.
Im GCC kein voll ausgewachsenes CAS (wäre zu langsam), aber immerhin
eine Beschreibungssprache die Vereinfachungen beschreibt:
https://gcc.gnu.org/git/?p=gcc.git;a=blob;f=gcc/match.pdhttps://gcc.gnu.org/onlinedocs/gccint/The-Language.html
Leider liegt es im Auge des Betrachters, was unter "optimal" zu
verstehen ist, und match.pd beschreibt sowohl Optimierungen als auch
Kanonisierungen. Das kann auch gerne mal in die Hose gehen, wie zum
Beispiel hier:
Wie jeder AVR Programmierer weiß, geht das alles in 6 Instruktionen.
Mit avr-gcc v8 und v15 besser, aber auch da reibt man sich die Augen:
1
func:
2
push r14
3
push r15
4
push r16
5
push r17
6
/* prologue: function */
7
sbrs r14,0
8
rjmp .L2
9
or r22,r18
10
or r23,r19
11
or r24,r20
12
or r25,r21
13
.L2:
14
/* epilogue start */
15
pop r17
16
pop r16
17
pop r15
18
pop r14
19
ret
Hier ist das Problem, dass c als long R14 übergeben wird, also in
callee-saved Registern und es in GCC keine Möglichkeit gibt zu
unterscheiden, ob R14 nur lesend zugegriffen wird oder verändert
(PR109910).
Alles Problem(chen), die man in Compilern des 21 Jahrhunderts nicht mehr
erwartet...
Johann L. schrieb:> Die nichttriviale Kunst besteht dann darin, eine abgeschwächte> linearistische Version des Algorithmus zu finden, die keine allzu großen> Abstricht bei der Codegüte macht.https://xkcd.com/3026/
> An erster Stelle sehe ich da die Korrektheit des erzeugten Codes.
Na sowas ist bei mir allein schon aus der Logik impliziert, das sehe ich
nicht als herausstechende elementare Funktion. Einen Compiler, der aus
einem beliebigen Quellcode nur Scheiße produziert, kann ich auch
alleine. Aber mit sowas kann niemand was anfangen.
Und dann ist noch die Frage, worauf man gerne hin optimieren möchte.
Geringste Code-Größe, geringsten RAM-Bedarf? Höchste Geschwindigkeit
bzw. höchste Geschwindigkeit auf einer bestimmten Plattform? Da müsste
man dem Compiler entsprechende Vorgaben machen können, was man gerne als
Ergebnis hätte.
Ben B. schrieb:>> An erster Stelle sehe ich da die Korrektheit des erzeugten Codes.> Na sowas ist bei mir allein schon aus der Logik impliziert,
Welche Logik soll das denn sein, die Fehler ausschließt oder unmöglich
macht?
> Welche Logik soll das denn sein, die Fehler> ausschließt oder unmöglich macht?
Möchtest Du einen Compiler haben, der Dir fehlerhaften Code produziert?
Klaus schrieb:> Ben B. schrieb:>> Da müsste man dem Compiler entsprechende Vorgaben machen können,>> was man gerne als Ergebnis hätte.>> Die Option -O existiert.
GCC kennt mehr als 500 Optionen und Parameter (--param) alleine zum
Tunen der Optimizer:
https://gcc.gnu.org/onlinedocs/gcc/Optimize-Options.html
Hinzu kommen die genannten Sammeloptionen wie -O0, -O1, -O2, -O3, -Og,
-Os, -Oz, -Ofast die 99% aller praktischen Belange abdecken.
Zusätzlich gibt es Optimierungsoptionen für einzelne Architekturen (für
AVR ca 1 Duzend).
Und schließlich wird auch gerne das ABI gepimpt um die Performance zu
beeinflussen (-f[no-][un]signed-bitfields, -f[no-]short-enums,
-f[no-][un]signed-char, -f[no-]wrapv, -f[no-]strict-overflow,
-f[no-]strict-aliasing, -f[no-]common, -f[no-]jump-tables, ...)
Ben B. schrieb:>> Welche Logik soll das denn sein, die Fehler>> ausschließt oder unmöglich macht?> Möchtest Du einen Compiler haben, der Dir fehlerhaften Code produziert?
Das ist keine Antwort auf meine Frage.
>>> Welche Logik soll das denn sein, die Fehler>>> ausschließt oder unmöglich macht?>> Möchtest Du einen Compiler haben,>> der Dir fehlerhaften Code produziert?> Das ist keine Antwort auf meine Frage.
Kannst Du Dir die Antwort darauf nicht selbst geben?
Falls doch, ist das glasklare Logik.
Genauso wie es eine Tatsache ist, daß sich Programmfehler niemals völlig
ausschließen oder unmöglich machen lassen, erst recht nicht wenn man das
komplette System betrachtet (Stichwort Bitfehler). Man kann sie durch
Qualitätskontrolle und Tests minimieren, aber niemals ganz und für alle
Situationen ausschließen.
C-Strings sind absolut ungeeignet fuer Controller, da man den String
durchgehen muss, um zur Laenge zu kommen. Besser Pascal Strings
verwenden, bei welchem die Laenge binaer im 0-ten byte steht.
Die C-String-Routinen sollte ma eh gleich sein lassen, da viel zu
klotzig.
Pandur S. schrieb:> C-Strings sind absolut ungeeignet fuer Controller
So ungeeignet, wie Bleistifte zum schreiben. WTF?
> Die C-String-Routinen sollte ma eh> gleich sein lassen, da viel zu klotzig.
Werfe mal einen Blick in den Quelltext der avr-libc. Danach hast du
wenigstens einen Funken Ahnung von dem Thema.
Pandur S. schrieb:> Ein printf mit einem Float verschleudert 16k auf einem AVR
Wo siehst du bei der eingangs gestellten Frage denn float oder printf?
Da geht es darum, jeweils einzelne Bytes in einem String zu setzen, und
die Antwort wurde bereits hier gegeben:
Beitrag "Re: Wie baut man in C Strings zusammen?"
Da braucht es nich nicht mal String-Funktionen aus string.h, geschweide
denn stdio.h.
Außerdem braucht es für float -> ASCII kein printf, sondern es gibt
dafür auch spezielle Funktionen. Dafür muss der Horizont aber weiter
als printf reichen...
> Ein printf mit einem Float verschleudert 16k auf einem AVR
Und zudem sind wir hier in PC-Programmierung?
Pandur S. schrieb:> Ein printf mit einem Float verschleudert 16k auf einem AVR
Ich komme auf ganz andere Zahlen. Im angehängten Projekt habe ich drei
Varianten implementiert, um einen Millisekunden-Zähler seriell
aufzugeben.
Ohne Ausgabe: 303 Bytes
Mit utoa() und puts(): 997 Bytes
Mit printf() dezimal: 2279 Bytes
Mit printf() float (erfordert eine Änderung im Makefile): 3931 Bytes
Compiliert mit avr-gcc 5.4.0
Nemopuk schrieb:> Pandur S. schrieb:>> Ein printf mit einem Float verschleudert 16k auf einem AVR>> Ich komme auf ganz andere Zahlen. [...]> Mit printf() float (erfordert eine Änderung im Makefile): 3931 Bytes
Die Benchmarks der AVR-LibC listen ca. 3 KiB für sprintf für float
(sprintf_flt). Dies enthält alle Abhängigkeiten von sprintf, allerdings
kein Startup-Code und keine Vektortabelle.
https://avrdudes.github.io/avr-libc/avr-libc-user-manual/benchmarks.html
Die 16k von Pandur sind also aus dem Finger genuckelt.
Aktuellere Benchmarks mit AVR-LibC v2.3 + avr-gcc v15 bleiben bei ca 3
KiB für sprintf + float.
Rbx schrieb:> Beim PC kann man auch die SSE für Stringbearbeitung nutzen.
Das witzige ist, z.B. bei Linux bekommt man C-Sourcen über den
Paketinstaller, bei denen SSE in den direkten Stringfunktionen zu finden
ist.
Bei Windows ist an den Stellen verschachtelte Pointer Arithmetik.
Philipp K. schrieb:> Rbx schrieb:>> Beim PC kann man auch die SSE für Stringbearbeitung nutzen.>> Das witzige ist, z.B. bei Linux bekommt man C-Sourcen über den> Paketinstaller, bei denen SSE in den direkten Stringfunktionen zu finden> ist.>> Bei Windows ist an den Stellen verschachtelte Pointer Arithmetik.
Das ist doch weniger eine Windows / Linux Sache als vielmehr, welche
Toolchain bzw. Libc man verwendet?
Johann L. schrieb:> Das ist doch weniger eine Windows / Linux Sache als vielmehr, welche> Toolchain bzw. Libc man verwendet?
Mag sein, ich hatte in Linux nur die Standard Version damals.. bei
Windows habe ich da keine Ahnung. "Einfach installiert und go".
Dergute W. schrieb:> Keinesfalls will ich am Nutzen von asprintf() zweifeln.> Nur - ob das aufm AVR (siehe 1. Post) so wirklich der Bringer ist...?
Die Entscheidung nimmt einem die AVR-LibC ab. Die unterstützt
nämlich kein asprintf et al.
Davon ab wurde die gestellte Frage bereits hier beantwortet:
Beitrag "Re: Wie baut man in C Strings zusammen?"