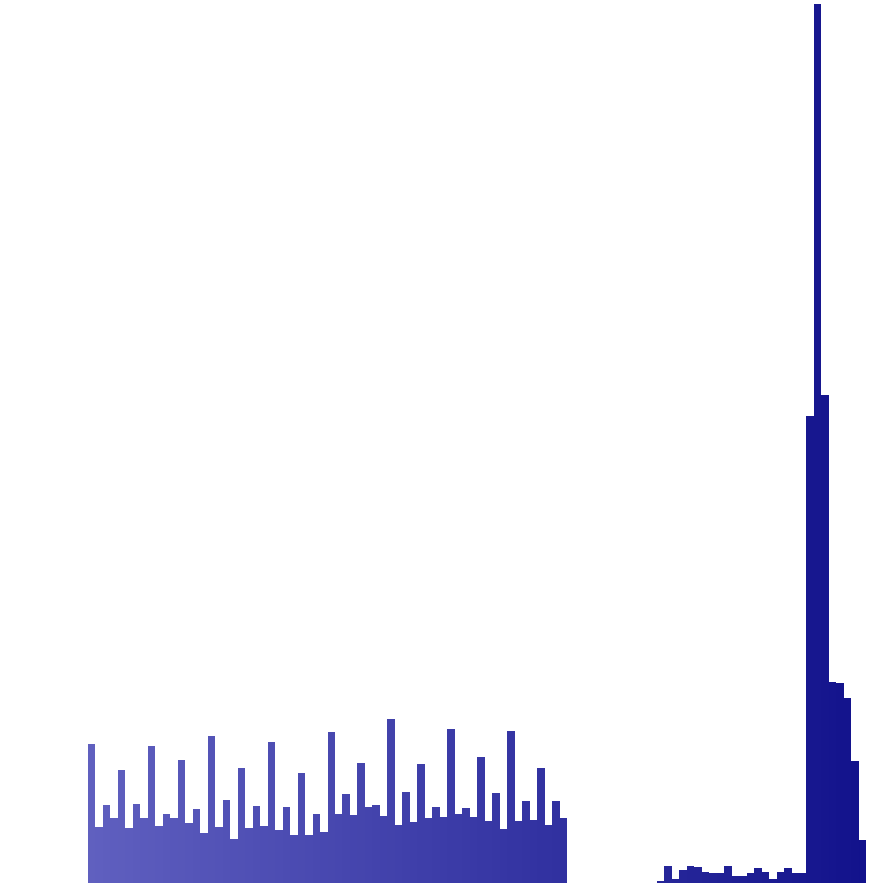
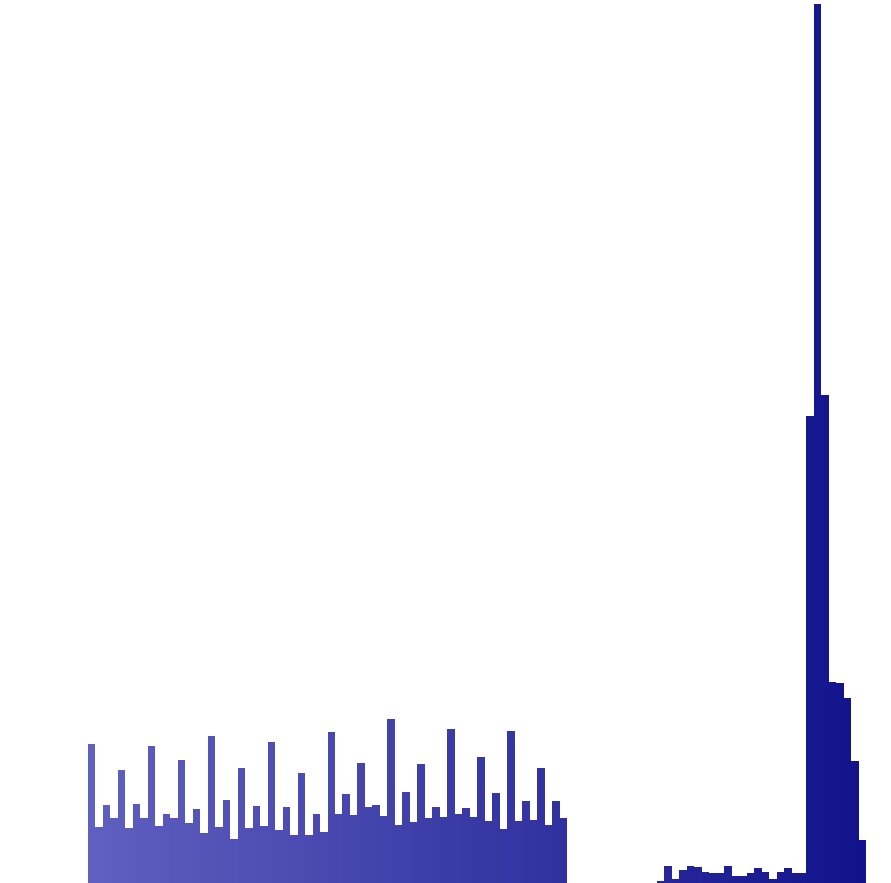
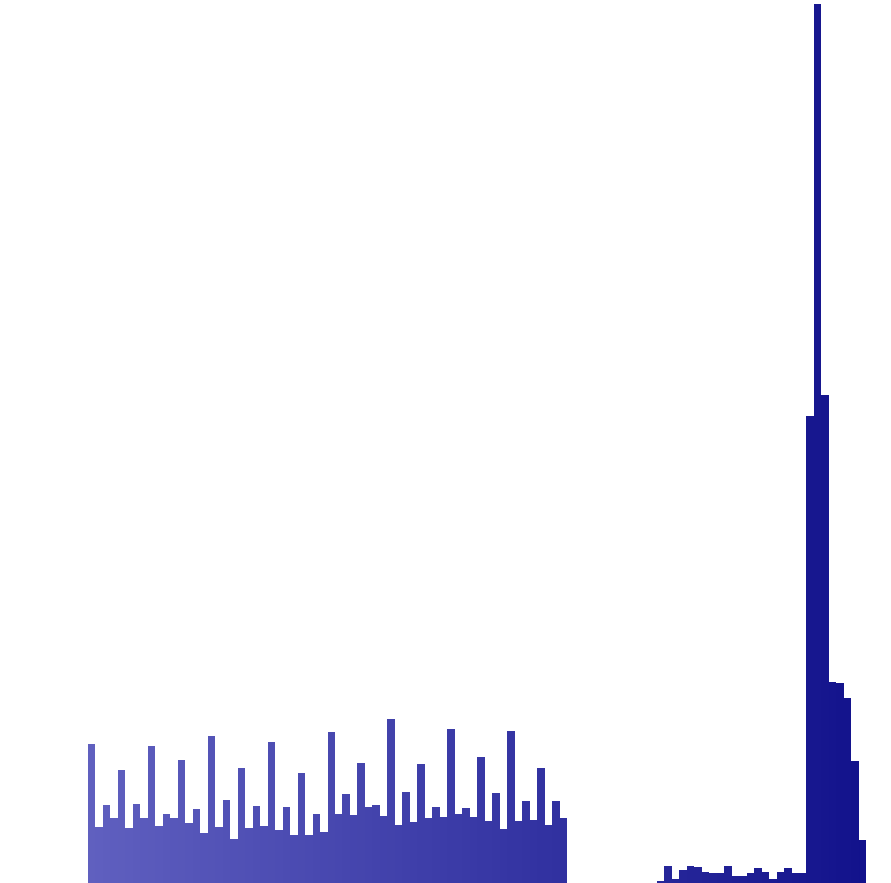
Hallo allerseits :-) Ich versuche gerade hinter die Logik eines interessanten Formates zu kommen, mache aber nur bedingte Fortschritte, vielleicht hat sich aber schon mal jemand damit befasst und kann mir ein paar Tips in die richtige Richtng geben. Es geht um die Protokolldaten eines Programmes, diese können als Textdatei im CSV-Format exportiert werden, was ich auch bisher nutze um sie in eine Datenbank einzupflegen. Diese Protokolldaten werden aber auch fein säuberlich in einer lokalen Datei abgelegt. Jetzt reizt es mich diese Datei auszulesen und damit den Datenimport zu automatisieren. Leider ist es kein Klartext, sondern jedes Ascii-Zeichen des Protokolls ist in einem Word(16Bit) gespeichert. Somit verdoppelt sich die Dateigröße exakt, unter dieser Maßgabe kann man auch die Datensätze gut erkennen. Da zu jedem Protokoll eine Protokollnummer gehört und diese im Programm frei editierbar ist, kann man leere Protokolle mit dieser Nummer als einzige Ascii-Ziffernfolge erzeugen und folgendes beobachten: Ascii-Ziffernfolge | abgelegte Daten 00000 | CD81 CDB2 CEA3 CF94 D085 00001 | CD81 CDB2 CEA3 CF94 D09A 00002 | CD81 CDB2 CEA3 CF94 D0AF Die ersten vier Ziffern sind alle "0" und erzeugen auch immer in diesem Zusammenhang die gleichen vier Doppelbytes --> CD81 CDB2 CEA3 CF94 Nur die Letze Ziffer ist aufsteigend 0,1,2 --> D085,D09A,D0AF... Wenn ich jetzt neue Protokolle erzeuge mit einstelligen Protokollnummern, dann sieht das ganze so aus: Ascii-Ziffernfolge | abgelegte Daten 0 | CD81 1 | CD92 2 | CDA3 3 | CDB4 5 | CE85 6 | CE96 Wie komme ich nun auf Base64? Ganz einfach, das niederwertige Byte vom Word bewegt sich exakt zwischen 0x80 und 0xBF, das sind genau 64 Zeichen, nur halt mit einem Offset zum regulären Index von Base64. Der höherwertige Teil vom Word beinhaltet offenbar Überträge aus einem Fehlerkorrekturverfahren oder anders verknüpfte Werte, welche nach der Base64-Codierung aufgerechnet wurden und eine Abhängigkeit zum "Vorgänger" haben. Genau hier liegt der Hase im Pfeffer, ich tüftle schon paar Abende dran, aber der Aha-Effekt blieb bisher aus. Im Anhang hab ich mal die Zeichenanalyse angehangen, auffalend ist eben der erste Block wlecher die Zeichen 0x80 bis 0xBF darstellt und der zweite Block quasi als Steuerzeichen (höherwertige Teil des Word) gerade mal von 0xCC bis 0xE7... Fragen: -Warum nimmt man eine Datenverdopplung in Kauf, meines erachtens nur für ein sicheres Fehlerkorrekturverfahren? -Könnte es evtl. auch ein Speicherformat mit irgendwelchen eingearbeiteten Index sein? Vielen Dank fürs lesen :)
Angehängte Dateien:
-

Analyse_Zeichenvorkommen.png
3,1 KB -

Analyse_Zeichenvorkommen.png
3,1 KB -

Analyse_Zeichenvorkommen.png
3,1 KB
Frank K. schrieb: > Fragen: > -Warum nimmt man eine Datenverdopplung in Kauf, meines erachtens nur für > ein sicheres Fehlerkorrekturverfahren? > -Könnte es evtl. auch ein Speicherformat mit irgendwelchen > eingearbeiteten Index sein? Glaube ich beides nicht. Das dürfe ein ganz normales 16Bit "Wide-Char" sein. Das ist heutzutage eigentlich ganz normal um die ganzen Sonderzeichen in den verschiedenen Sprachen abzubilden. - https://en.cppreference.com/w/cpp/keyword/wchar_t.html
hey, erstmal vielen Dank für deine Antwort :) Wenn es ein normales Wide-Char wäre, dann dürfte sich aber eine Änderung eines Zeichens nicht auf den Rest der Bitfolge auswirken? Sobald ich ein Zeichen ändere, werden auch die darauf folgenden Bytes "neu berechnet"...
Lade halt mal eine Beispieldatei hier hoch und verrate vielleicht auch welches Programm diese erzeugt.
Frank K. schrieb: > Frank D. schrieb: >> 춁춲캣쾔킅 .... > > Schick, was will er mir damit sagen? :) "Tusch, Tusch, Katze, Tusch" : dass er kein Koreanisch kann...
Bleiben die denn immer gleich? Also wenn man jetzt neue Listen 0-6 macht, bleibt es dann wie oben geschrieben, oder ändert sich das wieder?
Oft machen sich Programmierer das Leben leicht, indem sie sich nicht ein komplexes, neues Schema überlegen, sondern die vorhandenen Algorithmen und Bibliotheken wiederverwenden, auch wenn die Umsetzung dann nicht optimal zum Problem passt. Ich würde also mal schauen was für Bibliotheken in dem Programm verwendet wurden. Wofür sind die so gut? Gibt es da öffentliche Dokumentation zu? Haben die irgendwelche nativen Datenformate die in die Richtung Deiner Daten gehen? Gibt es evtl. ein Vorgängerprodukt oder anderes Produkt vom selben Hersteller was etwas ähnliches macht? Sind dort die Datenformate dokumentiert oder durch dritte Reverse-Engineered? Gibt es irgendwelche Schnittstellenprogramme die diese Daten decodieren können?
Flunder schrieb: > "Tusch, Tusch, Katze, Tusch" : dass er kein Koreanisch kann... Das ist halt das was bei der Interpretierung als rauskommt.
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.