Erhoffe mir Tipps wie man Fehler bei der Speicherallokation auf die Spur
kommt.
Bin dabei, einen relativ komplexen C-Code (26 Dateien) aus dem Bereich
digitaler Signalverarbeitung für den PC auf einen 32Bit uC (RP2350) zu
portieren.
Im ersten Schritt erst mal alles PC-spezifische wie GUI,
Dateioperationen und RTC-Anhängigkeiten entfernt bzw ersetzt. Der
abgespeckte Code funktioniert als Consolenanwendung noch immer und
bleibt nach Analyse mit Valgrind/ massif mit ca 200 kByte RAM auch im
Rahmen des Controllers.
Auf dem uC, wo auch noch eine andere Anwendung läuft, stürzt der ab.
Leider bekomme ich den Debugger dort nicht zum Laufen. Ausgaben auf
dessen Display sind möglich. Compiler / Linker zeigen keine Fehler an.
Ich vermute das Speicher überschrieben wird. Der Code strotzt vor Makros
und Stukturen, die wiederum zahlreiche Arrays enthalten. Zunächst wird
in einer Initialisierungprozedur dynamisch Speicher allokiert.
Der Teil läuft fehlerfrei durch.
Im nächsten Schritt mit Signaldaten gefüllt und gerechnet. Das geht
schief.
Könnte mir vorstellen, dass z.B. sizeof(von irgendwas) bei der
Allokation auf dem uC fälschlicher weise zu klein ausfällt und auf dem
PC dagegen passt.
Ein kleiner Codeschnipsel, wie das in etwa aussieht. KISS_FFT_MALLOC ist
ein Makro, da steckt am Ende malloc hinter.
Wulf D. schrieb:> Leider bekomme ich den Debugger dort nicht zum Laufen.
Hast Du einen freien UART? Logging kann sehr hilfreich sein.
Wulf D. schrieb:> Zunächst wird in einer Initialisierungprozedur dynamisch Speicher> allokiert.
Wird zwischendurch auch welcher freigegeben? Dann kann es zu
Fragmentierung kommen, so dass es knallt, sobald Du wieder einen
grösseren zusammenhängenden Speicherblock brauchst.
Fehlende Freigaben könnte natürlich ein Grund sein, der auf dem PC wegen
GByte an RAM nicht auffällt.
Ob der Code schon beim ersten Durchlauf abschmiert oder erst später weiß
ich gar nicht. Vermutung ist, dass nur einmalig bei der Initialisierung
allokiert wird.
Werde mal nach einem Durchlauf verriegeln und schauen ob das geht.
Mit der UART muss ich mal schauen. Ansonsten sind auch (asynchrone)
Display-Ausgaben drin.
Wulf D. schrieb:> sizeof(kiss_fft_cpx) * ( nfft * 3 / 2)
Das muss m.E. nicht immer passen. Vergleiche dort einfach den Zugriff
"hinters" letzte Element mit dem Byte-Ptr und Zugriff + memneeded
Bruno V. schrieb:>> sizeof(kiss_fft_cpx) * ( nfft * 3 / 2)>> Das muss m.E. nicht immer passen. Vergleiche dort einfach den Zugriff> "hinters" letzte Element mit dem Byte-Ptr und Zugriff + memneeded
Verstehe nicht richtig was du meinst. Könnte natürlich den mit diesem
Konstrukt berechneten Speicherbedarf auf das Display des uC ausgeben und
mit dem Wert vom PC vergleichen.
Allerdings ist der ganze Code mit solchen Konstrukten übersät. Was auf
dem PC auch funktioniert, die Testdaten werden richtig berechnet.
Wulf D. schrieb:> Fehlende Freigaben könnte natürlich ein Grund sein, der auf dem PC wegen> GByte an RAM nicht auffällt.
Ich meinte nicht mal Speicherlecks, die natürlich auch ein Problem sein
können, sondern Speicherfragmentierung.
Wenn Du z.B. 256kB zur Verfügung hast und 4x 64kB anforderst, sind nach
dem Freigeben des zweiten und vierten Blocks zwar wieder 128kB frei,
aber mehr als 64kB am Stück wirst Du dann nicht mehr bekommen.
Hi
Gibts in deiner Bibliothek Anzeichen für
https://en.wikipedia.org/wiki/Type_punning? Dann könnte irgendwo ein
unaligned 32 Bit Zugriff versteckt sein. Cortex-M0 mag das nicht. Zur
Diagnose mal einen HardFault Handler einhängen.
Matthias
Moin,
Wulf D. schrieb:> Auf dem PC kann ich debuggen, aber da gibt es auch keinen Fehler> und der> Code läuft beliebig oft durch.
Das schrubst du ja schon. Ich meinte eher, das binary fuer deinen
Zielprozessor via qemu aufm PC laufen zu lassen. Oder hast das schon
probiert?
Gruss
WK
Hmmm schrieb:> Wenn Du z.B. 256kB zur Verfügung hast und 4x 64kB anforderst, sind nach> dem Freigeben des zweiten und vierten Blocks zwar wieder 128kB frei,> aber mehr als 64kB am Stück wirst Du dann nicht mehr bekommen.
Grundsätzlich stimme ich dir zu. Da aber von einer 200K Speichernutzung
gesprochen wurde, der 2350 aber über ein halbes MB hat, müsste die
Software schon so extrem schlecht geschrieben sein, dass es wirklich
gleich beim zweiten Blick auffallen sollte.
Wenn wirklich gar nix Gescheites zum Debuggen da ist, einfach nach jedem
malloc/calloc den Zeiger prüfen und bei Nichtgefallen ne Lampe
anschalten.
Falsche Größe allozieren könnte ich mir aber auch vorstellen.
Dergute W. schrieb:> Das schrubst du ja schon. Ich meinte eher, das binary fuer deinen> Zielprozessor via qemu aufm PC laufen zu lassen. Oder hast das schon> probiert?
Ok, jetzt verstanden: hab nachgeschaut, für qemu ist die RP2350
Unterstützung zwar in Arbeit, aber da gibt es noch nichts.
Μαtthias W. schrieb:> Gibts in deiner Bibliothek Anzeichen für> https://en.wikipedia.org/wiki/Type_punning? Dann könnte irgendwo ein> unaligned 32 Bit Zugriff versteckt sein. Cortex-M0 mag das nicht. Zur> Diagnose mal einen HardFault Handler einhängen.
An einem Ringbuffer habe ich das gesehen, da funktioniert es
nachweislich.
Ansonsten muss ich den Code genau danach absuchen. Wegen der zahlreichen
Makros ziemlich unübersichtlich.
HardFault Handler kenne ich nicht, muss mich einlesen.
Μαtthias W. schrieb:> unaligned 32 Bit Zugriff versteckt sein. Cortex-M0 mag das nicht.
Das ist ein Cortex-M33.
»The Cortex-M33 processor supports unaligned accesses.«
Wenn du es mit address sanitizer
(https://github.com/google/sanitizers/wiki/addresssanitizer) kompilierst
und laufen lässt, ist auch alles schick? Das wäre Werkzeug erster Wahl
um Speicherfehler auf einem High Level OS aufzudecken.
Mach’s nicht ohne Debugger auf dem Zielsystem. Das ist gut investiertes
Geld bzw Zeit, gerade wenn es ein kommerzielles Projekt ist. Für einen
verplemperten Entwicklertag kann man sich bereits einen JLink kaufen und
muss nicht mit Basteldebuggern anfangen. Printf ist mittelfristig die
teuerste Art, zu debuggen.
Danke, den address sanitizer kenne ich auch nicht, probiere den aus.
Ist kein kommerzielles Projekt, rein Hobby. Nutze eigentlich die
Pico-Probe und die funktioniert bei kleinen Sachen auch bestens.
Dass es hier nicht geht, liegt vermutlich am Pi-Pico-SDK. Ist die
aktuelle Version, aber schlecht gepflegt, d.h. mit Bugs. Damit USB im
Release-Build überhaupt funktioniert, musste ich im TinyUSB Submodul ein
commit reinpatchen.
Sobald die Initialisierung vom SDK im Debug-Mode durchläuft, hängt die
CPU in einem trap fest.
Habe erstmal einige Tipps abzuarbeiten, reicht bis zum WE - Danke!
Wulf D. schrieb:> Verstehe nicht richtig was du meinst.> memneeded = sizeof(struct kiss_fftr_state) + subsize + sizeof(kiss_fft_cpx) * (
nfft * 3 / 2);
> st = (kiss_fftr_cfg) KISS_FFT_MALLOC (memneeded);
Es gibt also eine Struktur vom Type kiss_fftr_cfg. Die Enthält ein Array
(nennen wir es 'a', den Namen kann ich nicht raten) mit n elementen
(vermutlich n=nfft oder so).
1
/* byte-ptr basteln */
2
char*p=st;
3
intn=...nfft??;
4
5
/* check if groß genug */
6
if(p+memneeded<&st->a[n])ZuendeDieRoteLaterne();
Mit ZuendeDieRoteLaterne = LED, Display, Uart, Portpin oder irgendwas
...
Anmerkung: Es ist immer blöd, wenn der Speicherbedarf der Struktur a von
sizeof(Struktur b) + komische Rechnungen ("sizeof(Struktur c) n 3 /
2") abhängig ist.
Norbert schrieb:> Μαtthias W. schrieb:>> unaligned 32 Bit Zugriff versteckt sein. Cortex-M0 mag das nicht.>> Das ist ein Cortex-M33.> »The Cortex-M33 processor supports unaligned accesses.«
Muss man das wie bei M3 oder M4 ggfs. aktivieren?
Zwei Dinge ausprobiert:
- erstmal den Code so verriegelt, dass der nur einmal durchlaufen kann.
Schafft der nicht, stürzt vorher ab. Damit entfallen Dinge wie
unterschlagene Freigaben oder Speicherfragmentierung.
- AddressSanitizer: PC-Code mit "-fsanitize=address" übersetzt und
environment variable LSAN_OPTIONS=verbosity=1:log_threads=1 gesetzt.
Einen vollständigen Datensatz verarbeitet, der Code wird dabei einmal
Initialisiert und Speicher allokiert, aber anschließend mehrmals
durchlaufen.
Am Ende Speicher wieder freigegeben.
Die Sanitizer-Ausgabe ist angehängt. Meldet Fehler, aber weiß noch nicht
ob die aus der Rechnerumgebung (Ubuntu mit VS Code) oder aus dem zu
untersuchenden Programm stammen.
Wulf D. schrieb:> Ansonsten muss ich den Code genau danach absuchen. Wegen der zahlreichen> Makros ziemlich unübersichtlich.
Jeder halbwegs brauchbare C-Compiler lässt sich davon überzeugen den
Code nach der Makro-Expansion durch den Preprozessor zu zeigen. Z.B. -E
beim GCC.
Das wird kein schöner Code sein, aber es ist der Code den der
eigentliche Compiler sieht. Eventuell noch durch einen C Beautifier
laufen lassen um ihn etwas lesbarer zu gestalten.
Wulf D. schrieb:> Auf dem PC kann ich debuggen, aber da gibt es auch keinen Fehler und der> Code läuft beliebig oft durch.
Hast Du valgrind(1) einmal mit dem Parameter "--leak-check=full"
aufgerufen? Das könnte Dir womöglich einen Hinweis geben, wo es klemmt.
Siehe dazu auch [1] sowie möglicherweise [2]. HTH, viel Erfolg!
[1] https://valgrind.org/docs/manual/mc-manual.html
[2] https://valgrind.org/docs/memcheck2005.pdf
Wulf D. schrieb:> Die Sanitizer-Ausgabe ist angehängt. Meldet Fehler, aber weiß noch nicht> ob die aus der Rechnerumgebung (Ubuntu mit VS Code) oder aus dem zu> untersuchenden Programm stammen.
Sieht unauffällig aus. Der Fehler am Ende deutet auf eine Ausführung in
GDB hin, ist aber für das Speicherthema irrelevant.
> - erstmal den Code so verriegelt, dass der nur einmal durchlaufen kann.> Schafft der nicht, stürzt vorher ab.
Du könntest dich jetzt per bisect an den Fehler rantasten, also Programm
irgendwo mutwillig abbrechen und eine Ausgabe machen. Oder du erzeugst
dir einen Trace auf einem GPIO Pin und verfolgst das mit dem Logic
Analyzer.
> Ist kein kommerzielles Projekt, rein Hobby.
Dann zeig doch den minimalisierten Code im lauffähigen Zustand. Am Ende
bequemt sich noch jemand und findet den Fehler für dich.
> Sobald die Initialisierung vom SDK im Debug-Mode durchläuft, hängt die
CPU in einem trap fest.
Nur mit deinem Code oder auch mit einem Mickey-Maus Example?
Pete K. schrieb:> Was sagt denn der Compiler? Keine Warnungen/Fehler? Überprüfe mal den> Warn-Level und schau Dir dann die Warnings an.
Da sind nur Warnungen zu unused variable, wegen der zusätzlichen
Instrumentierung um den Fehler zu ermitteln. Warnlevel ist recht
kleinlich eingestellt.
Rbx schrieb:> Könnte man das Programm auch in Fortran übersetzen?
gcc kann auch Fortran. Die Referenzimplementierung ist sogar Fortran90
Code. Aber die würde niemals in den Controller passen.
Johann L. schrieb:> Sanitizer? Im GCC -fsanitize=
siehe oben, ein Sanitizer log
Ein T. schrieb:> Hast Du valgrind(1) einmal mit dem Parameter "--leak-check=full"> aufgerufen?
1
valgrind --leak-check=full ./ft8re 1msg_fs15.raw
2
==5433== Memcheck, a memory error detector
3
==5433== Copyright (C) 2002-2017, and GNU GPL'd, by Julian Seward et al.
4
==5433== Using Valgrind-3.18.1 and LibVEX; rerun with -h for copyright info
==5433== All heap blocks were freed -- no leaks are possible
17
==5433==
18
==5433== For lists of detected and suppressed errors, rerun with: -s
19
==5433== ERROR SUMMARY: 0 errors from 0 contexts (suppressed: 0 from 0)
Richard W. schrieb:> Wulf D. schrieb:>> Die Sanitizer-Ausgabe ist angehängt.> Sieht unauffällig aus. Der Fehler am Ende deutet auf eine Ausführung in> GDB hin, ist aber für das Speicherthema irrelevant.
Danke.
> Du könntest dich jetzt per bisect an den Fehler rantasten, also Programm> irgendwo mutwillig abbrechen und eine Ausgabe machen. Oder du erzeugst> dir einen Trace auf einem GPIO Pin und verfolgst das mit dem Logic> Analyzer.
bisect müsste ich mir anschauen. Das mit dem abbrechen hatte ich
gemacht, im nächsten Post mehr. Ein Tipp mit GPIO-Ausgabe mit
hinterliegender Pointerkontrolle kam schon von Bruno, werde ich noch
versuchen.
> Dann zeig doch den minimalisierten Code im lauffähigen Zustand. Am Ende> bequemt sich noch jemand und findet den Fehler für dich.
Da fehlt mir leider die Phantasie das zu minimieren. Einen echten Fehler
erwarte ich auch nicht, eher eine Fehlinterpretation beim Übergang auf
das embedded-System. Läuft ja auf dem PC.
>> Sobald die Initialisierung vom SDK im Debug-Mode durchläuft, hängt die> CPU in einem trap fest.>> Nur mit deinem Code oder auch mit einem Mickey-Maus Example?
Wie gesagt, der Initialisierungscode des SDK crashed, wenn mit
Debug-Option "-g" übersetzt wurde. Hier die ersten Zeilen, aus
stdio_init_all(); kommt der nicht raus. Ohne Initialisierung ginge es
weiter, aber da läuft das Programm natürlich irgendwann in den Wald.
Denke es hängt am TinyUSB. Dem issue-Tracker des SDK im github nach, ist
der Maintainer gerade nicht in der Lage Bugfixes einzubauen. Geschenktem
Gaul ...
Was man zu Testzwecken machen könnte:
malloc & co. durch eigene Varianten ersetzen, und in denen auf einer
seriellen Schnittstelle ausgeben, wieviel sie anfordern und welche
Adresse sie zurückgeben.
Das beeinflusst zwar das Laufzeitverhalten, aber da der Fehler
anscheinend recht schnell in der Startphase auftritt, sollte man aus dem
aufgezeichneten Mitschrieb herausfinden können, was das ist.
Sofern die Codegröße kein Problem ist, könnte man den Funktionen auch
noch einen zusätzlichen String-Parameter mitgeben, den man mit _LINE_
befüllt, dann hat man eine Chance, zu erkennen, welcher Aufruf von
malloc & Co. Probleme macht. Gegebenenfalls noch _FILE_ dazupacken.
Wulf D. schrieb:> bisect müsste ich mir anschauen. Das mit dem abbrechen hatte ich> gemacht, im nächsten Post mehr. Ein Tipp mit GPIO-Ausgabe mit> hinterliegender Pointerkontrolle kam schon von Bruno, werde ich noch> versuchen.
Ich meinte lediglich, die Stelle zu suchen wo der Fehler auftritt in dem
man das Programm kontrolliert abbricht, bzw. eine synchrone Traceausgabe
auf einem GPIO machst. Zuerst brichst du nach der Hälfte des Codes ab.
Crasht er, wird der Fehler in dieser Hälfte gewesen sein, wenn nicht,
war er in der anderen Hälfte. Dann nimmst du die Hälfte mit dem Crash
und brichst dort wieder nach der Hälfte ab usw. So tastest du dich
Schritt für Schritt an den Fehler ran.
Wenn es überhaupt ein Crash ist, weil:
> watchdog_enable(2000, true);
scheint ja alle 2ms einen Kick zu erwarten. Erfolgt der denn bei dir?
Brauchst du den Watchdog unbedingt für deine Versuche? Raus damit. Alles
weg was am Anfang irgendwie Komplikationen verursachen könnte.
Vielleicht sogar erst mal mit dem einfachsten Blink-Example anfangen.
> Wie gesagt, der Initialisierungscode des SDK crashed, wenn mit> Debug-Option "-g" übersetzt wurde. Hier die ersten Zeilen, aus> stdio_init_all(); kommt der nicht raus.
-g sollte null am generierten Code verändern sondern lediglich Debug
Informationen in den ELF Dateien hinzufügen. Es wird eher daran liegen
dass du einen Debugger angeschlossen hast.
Lu schrieb:> Sorry wennn ich jetzt eine dumme Frage stelle. Könnt Ihr keine> Prüfpunkte einbauen, um herauszubekommen, wo es hängt?
Gar nicht dumm, hat so ähnlich auch Richard gestellt. Antwort ist nicht
so ganz eindeutig.
Im Bild ein Screenshot um die Stelle herum wo der Code aussteigt, durch
schrittweises Einfügen von return; herangetastet.
Original ist das Programm an Stelle 1 beim Aufruf von kiss_fftr(...)
versackt. Dachte erst es läge an der Routine, konnte da aber nichts
finden. Die dann probehalber eine for-Schleife höher an Stelle 2
eingehängt, und da lief die Routine (mit mehreren Subroutinen dahinter)
durch, überlebte aber nicht die nächste for-Schleife zwischen 2 und 1.
monitor_t *me ist eine sehr verschachtelte Struktur, für die bei der
Initialisierung dynamisch Speicher reserviert wird.
const float* frame ist ein 2400 Wörter langes Array mit den
Eingangs-Samples (Stack).
An der Stelle werden nun jede Menge Daten verschoben. Da liegt die
Vermutung nahe, dass es irgendwo nicht passt.
Harald K. schrieb:> Was man zu Testzwecken machen könnte:>> malloc & co. durch eigene Varianten ersetzen, und in denen auf einer> seriellen Schnittstelle ausgeben, wieviel sie anfordern und welche> Adresse sie zurückgeben.>
Muss man schauen wie sich das einbauen lässt, geht auch in die Richtung
Pointer-Kontrolle. Man könnte die Ergebnisse dann gut mit denen auf dem
PC vergleichen und ggf plausibilisieren.
Richard W. schrieb:> Wenn es überhaupt ein Crash ist, weil:>>> watchdog_enable(2000, true);>> scheint ja alle 2ms einen Kick zu erwarten. Erfolgt der denn bei dir?> Brauchst du den Watchdog unbedingt für deine Versuche? Raus damit.
Es sind 2s. Klar, der Watchdog kommt im Fehlerfall. Kann den rausnehmen
oder probehalber verlängern.
> Vielleicht sogar erst mal mit dem einfachsten Blink-Example anfangen.
Das geht natürlich, auch mit Debugger.
>> Wie gesagt, der Initialisierungscode des SDK crashed, wenn mit>> Debug-Option "-g" übersetzt wurde. Hier die ersten Zeilen, aus>> stdio_init_all(); kommt der nicht raus.>> -g sollte null am generierten Code verändern sondern lediglich Debug> Informationen in den ELF Dateien hinzufügen. Es wird eher daran liegen> dass du einen Debugger angeschlossen hast.
Mag sein. Habe aber schon eine Woche nach Feierabend vergeblich eine
Lösung versucht. Liegt sicher auch daran, dass ich das CMake Build auf
dem embedded system nicht richtig blicke, die CMakeLists.txt hat mehrere
hundert Zeilen.
Wulf D. schrieb:> überlebte aber nicht die nächste for-Schleife zwischen 2 und 1.
Könnte man den Schleifenteil in Assembler einbauen?
Auch wenn die Bedingung eigentlich noch nicht problematisch aussieht,
könnte sie doch..
> Könnte mir vorstellen, dass z.B. sizeof(von irgendwas) bei der> Allokation auf dem uC fälschlicher weise zu klein ausfällt und auf dem> PC dagegen passt.
Ich wuerde mich mit "vorstellen" nicht zufrieden geben. Der Grund wieso
ich dynamischen Speicher bei Controllern nicht mag, man kann so schlecht
ein Fenster mit "Out of Memory" aufmachen. Also lass dir da eine
Strategie einfallen. Selbst wenn es nicht dein aktuelles Problem ist,
langfristig braucht man sowas.
Vanye
Wulf D. schrieb:> Original ist das Programm an Stelle 1 beim Aufruf von kiss_fftr(...)> versackt. Dachte erst es läge an der Routine, konnte da aber nichts> finden. Die dann probehalber eine for-Schleife höher an Stelle 2> eingehängt, und da lief die Routine (mit mehreren Subroutinen dahinter)> durch, überlebte aber nicht die nächste for-Schleife zwischen 2 und 1.
Klingt nicht so, als läge die Ursache im kss_fft Code. Tritt der Fehler
auch auf wenn du deinen Code durch eine Endlosschleife ersetzt bzw.
läuft es wenn du für die Ausführung die Interrupts auf der CPU sperrst?
>> Vielleicht sogar erst mal mit dem einfachsten Blink-Example anfangen.> Das geht natürlich, auch mit Debugger.
Dann solltest du das vielleicht als Grundlage für dein Projekt nehmen
und ausbauen.
Vanye R. schrieb:> Der Grund wieso> ich dynamischen Speicher bei Controllern nicht mag, man kann so schlecht> ein Fenster mit "Out of Memory" aufmachen.
Bin auch kein Freund dynamischer Allokation auf dem uC.
Der Code ist aber kein Pappenstiel, mal neu schreiben wäre sicher ein
Jahr Arbeit.
Wenn Du einen Tipp hast, wie man beim RP2xy0 den noch verfügbaren RAM
herausbekommt, nur her damit!
Bei den kleinen AVR war das ganz simpel, hat einem die IDE direkt nach
dem Compilieren angezeigt.
Richard W. schrieb:> Klingt nicht so, als läge die Ursache im kss_fft Code. Tritt der Fehler> auch auf wenn du deinen Code durch eine Endlosschleife ersetzt bzw.> läuft es wenn du für die Ausführung die Interrupts auf der CPU sperrst?
Interrupt habe ich nicht angefasst, aber wenn ich meinen Code abkürze
und das Füllen des allokierten Speichers (und rechnen damit) verhindere,
läuft alles stabil auf beliebige Zeit.
>>> Vielleicht sogar erst mal mit dem einfachsten Blink-Example anfangen.>> Das geht natürlich, auch mit Debugger.>> Dann solltest du das vielleicht als Grundlage für dein Projekt nehmen> und ausbauen.
Muss mich irgendwann mit dem Build-System näher beschäftigen. Das ist
für den RP2040 ausgelegt. Hab den RP2350 vermutlich unvollständig da
untergebracht.
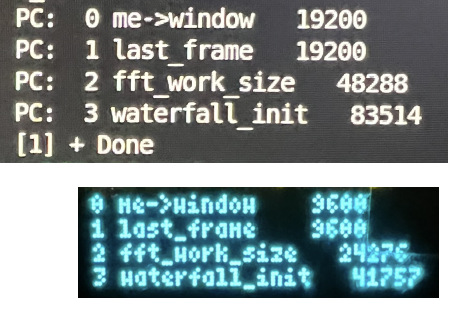
Habe die Allokationen mit malloc und calloc aufs Display geschrieben
(Bild).
Bis auf den zweiten Wert sind die reservierten Speicher auf dem PC
doppelt so groß wie auf dem uC. Könnte der Unterschied 64Bit vs 32Bit
sein, muss aber im Detail schauen was das bedeutet.
Etwas seltsam, dass valgrind 8 allocs meldet, hier aber nur 4 stehen.
Vielleicht hab ich was übersehen.
Moin,
Wulf D. schrieb:> Bis auf den zweiten Wert sind die reservierten Speicher auf dem PC> doppelt so groß wie auf dem uC.
Holla, the wood fairy...
Gruss
WK
Vanye R. schrieb:> Der Grund wieso> ich dynamischen Speicher bei Controllern nicht mag, man kann so schlecht> ein Fenster mit "Out of Memory" aufmachen.
Man kann eine LED anmachen.
Wulf D. schrieb:> Bei den kleinen AVR war das ganz simpel, hat einem die IDE direkt nach> dem Compilieren angezeigt.
Nee, die hat Dir nur angezeigt, wieviel statischer Speicher noch frei
ist. Über dynamischen, d.h. zur Laufzeit angeforderten Speicher hat die
gar nix gesagt; wie sollte sie das auch können?
> Wenn Du einen Tipp hast, wie man beim RP2xy0 den noch verfügbaren> RAM herausbekommt, nur her damit!
Es gibt im wesentlichen zwei Pointer, deren Differenz hier interessant
ist.
Einerseits der Stackpointer, andererseits der Heappointer. Der Heap wird
für malloc & co. verwendet. Diese beiden Pointer wandern i.d.R. aus
unterschiedlichen Richtungen aufeinander zu. Kommen sie sich zu nahe,
knallt es.
Und das sollte die allocator-Funktion prüfen, oft heißt die sbrk.
> Wenn Du einen Tipp hast, wie man beim RP2xy0 den noch verfügbaren RAM> herausbekommt, nur her damit!
Ich bei sowas den Speicher schon mal mit 0xDEAD gefuellt und einmal
laufen lassen geschaut wo das noch drin stand.
Vanye
Norbert schrieb:> Das ist ein Cortex-M33.> »The Cortex-M33 processor supports unaligned accesses.«
Nicht mit allen Instruktionen und nicht überall. Der Compiler könnte
versuchen mit Load/Store Dual oder Multiple etwas zu optimieren.
"The Cortex-M33 processor supports unaligned access only for the
following instructions:
• LDR, LDRT.
• LDRH, LDRHT.
• LDRSH, LDRSHT.
• STR, STRT.
• STRH, STRHT.
All other load and store instructions generate a UsageFault exception if
they perform an unaligned
access, and therefore their accesses must be address aligned."
und
"In addition, some memory regions might
not support unaligned accesses."
Martin schrieb:> Der Compiler könnte> versuchen mit Load/Store Dual oder Multiple etwas zu optimieren.
Möglich … Vermuten … Compiler Lauf mit Assembler Ausgabe … egrep
anwenden … Wissen.
Norbert schrieb:> Martin schrieb:>> Der Compiler könnte>> versuchen mit Load/Store Dual oder Multiple etwas zu optimieren.>> Möglich … Vermuten … Compiler Lauf mit Assembler Ausgabe … egrep> anwenden … Wissen.
Das wäre dann aber ein Compilerfehler. Das halte ich bei solchen
grundlegenden Dingen für sehr unwahrscheinlich.
Habe probehalber einfach mal den allokierten Speicher verdoppelt.
Damit das funktioniert, die Überabtastung im Zeit- und Frequenzbereich
mittels Parameter halbiert. Da würde zwar unbrauchbare Rechenergebnisse
liefern, aber zum Speichertest ok.
Leider hat das überhaupt keinen Effekt, stürzt genau im selben Bereich
ab. Damit wird falsch allokierter Speicher auch unwahrscheinlich.
Richard hat Recht, komme wohl um den Debugger-Einsatz nicht rum.
Versuche diesen Code außerhalb des "restlichen" Umfangs separat auf dem
uC "stand-alone" aufzusetzen, ähnlich wie auf dem PC.
Müsste dann die Testdaten z.B. in einem generierten, riesigen Headerfile
zuspielen.
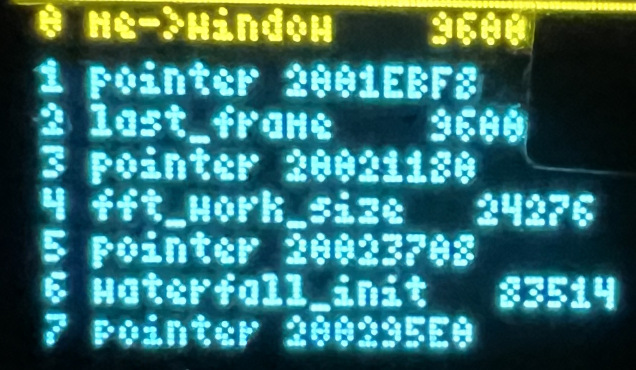
Anbei nochmal eine Display-Ausgabe des dynamisch allokierten Speichers
(dezimal), mit der RAM-Adresse (HEX) in der Zeile darunter.
Wulf D. schrieb:> alloc2.jpg> Richard hat Recht, komme wohl um den Debugger-Einsatz nicht rum.Wulf D. schrieb:> Sobald die Initialisierung vom SDK im Debug-Mode durchläuft, hängt die> CPU in einem trap fest.
Der M33 hat eine Hand voll Register, die nach einem Trap die genaue
Ursache, die Adresse im Code und, je nach Ursache, die Adresse im RAM
enthalten. Diese Info kann man im Hard Fault Handler mit printf
ausgeben, ähnlich wie im alloc2.jpg. Zusammen mit einem objdump vom
*.elf bekommt man so exakt den Maschinenbefehl und damit die
Quellcode-Zeile, wo es passiert ist. Bei z.B. einem unaligned usage
fault bekommt man auch die genaue Datenadresse.
Das funktioniert komplett ohne Debugger und ohne -g. Mit -Os ist der
objdump auch noch gut lesbar, evt. besser als ganz ohne Optimierung. Ja,
die Cortex-M kennen auch Fehler, bei denen die Adressen nicht genau
stimmen, aber das wird sogar mit einem Flag angezeigt. Trotzdem lohnt
sich so ein Hard Fault Handler, meine ich.
Μαtthias W. schrieb:> Das wäre dann aber ein Compilerfehler. Das halte ich bei solchen> grundlegenden Dingen für sehr unwahrscheinlich.
Wenn der Compiler einen Pointer auf eine 32-Bit-Variable sieht, geht er
davon aus, dass dieser korrekt aligned ist. Er legt ja die Variablen
aligned in den Speicher.
Wenn der Pointer aber erst zur Laufzeit berechnet wird, dann kann der
Compiler zu Compilezeit noch nicht wissen, ob immer ein aligned Pointer
rauskommt. Hier muss der Compiler darauf vertrauen, dass der Pointer
aligned.
Da moderne Prozessoren unaligned Zugriff erlauben wird bei
PC-spezifischen Code unaligned Zugriff vorausgesetzt.
Ich sollte Capt'n Proto Serialisierung embedded implementieren. Der
Frame besteht aus einem 13 Byte Header gefolgt von dem Payload als
uint32-Array. Der C-Code für PC rechnet sich den Pointer des
Payload-Arrays aus und macht einfach 32-Bit-Zugriffe aus das unaligned
Array. Ich musste einen Wrapper für den Zugriff aus das Payload
schreiben.
Es ist nicht auszuschließen, das der PC-spezifische Code sich nicht
einen unaligned Pointer ausrechnet und der Compiler, in der Annahme es
würde sich um einen aligned Pointer handeln, versucht mit eine Dual-
oder Multiple-Zugriff zu optimieren.
Es wäre sinnvoll im HardFault Handler auf unaligned fault zu prüfen.
Bauform B. schrieb:> Der M33 hat eine Hand voll Register, die nach einem Trap die genaue> Ursache, die Adresse im Code und, je nach Ursache, die Adresse im RAM> enthalten. Diese Info kann man im Hard Fault Handler mit printf> ausgeben
Das ist das, was ich auch als erstes versuchen würde. Die Chance die
Codestelle damit zu finden ist sehr hoch.
Und man braucht keinen Debugger. :)
Der HardFaulthandler ist kein Hexenwerk.
Wulf D. schrieb:> Wäre denn jede nicht durch vier teilbare Pointeradresse automatisch> „unaligned“?
Ja, für die Adresse des Pointers; nein für Pointer auf uint16_t oder
char.
Der Stackpointer muss sogar 8-Byte aligned sein. Jedenfalls bei
neueren/größeren Cortex-M wie M33, beim M4 war das noch halbwegs
optional.
Rbx schrieb:> 900ss schrieb:>> Und man braucht keinen Debugger. :)>> Du hast also noch nie einen benutzt?
Naja, wir haben hier den Spezialfall: es gibt keinen Debugger, aber ein
Display und das passende printf(). Damit funktioniert so ein Hard Fault
Handler auch im originalen fertigen Gerät beim Kunden. So eine einmalige
Gelegenheit nimmt man natürlich mit. Außerdem: je mehr davon man
einbaut, umso unwahrscheinlich wird es, dass der gebraucht wird ;)
Bauform B. schrieb:> Außerdem: je mehr davon man> einbaut, umso unwahrscheinlich wird es, dass der gebraucht wird ;)
OK.
Wir bräuchten auch eine genauere Beschreibung darüber, in welcher Weise
die PC-Version läuft, ob sie auf 32 Bit beschränkt ist, oder ähnliche
Datenformateinschränkungen hat wie der Mc.
Hätte man einen 64Bit Raspi, könnte man auch da nachsehen, was da
abgeht.
Wulf D. schrieb:> Versuche diesen Code außerhalb des "restlichen" Umfangs separat auf dem> uC "stand-alone" aufzusetzen, ähnlich wie auf dem PC.> Müsste dann die Testdaten z.B. in einem generierten, riesigen Headerfile> zuspielen.
Kleines update:
Das oben stehende lies sich mit geringem Aufwand umsetzen. Da
funktioniert auch der Debugger, die Build-Umgebung halt selbst
aufgesetzt.
Der Code stürzt dabei auf dem uC nicht ab. Bringt mich auf den ersten
Blick zwar bei meinem eingangs geschildertem Problem nicht weiter, bin
aber trotzdem froh dass der Code auch auf dem uC voll lauffähig ist. Und
vor allem liefert er Ergebnisse in gleicher Qualität wie auf dem PC. Die
geringere Wortbreite hat keinen negativen Einfluss auf die Ergebnisse.
Habe Testdaten in einem gut 400kByte großen const Array im Flash
vorbereitet. Die arbeitet der uC in ca 1s ab, was auch völlig ok ist.
Vielleicht schaffe ich es heute Abend mir den HardFault Handler
anzuschauen.
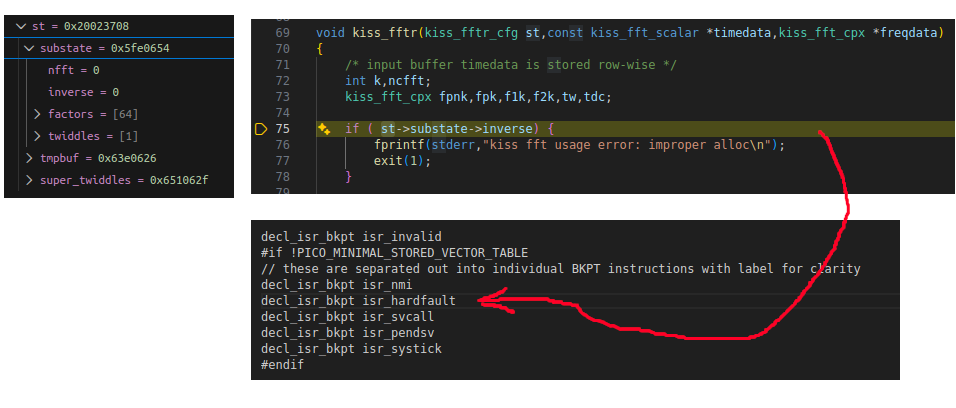
Bin einen kleinen Schritt weiter, habe den Debugger im Zielsystem
(instabil) zum Laufen gebracht.
Das Programm wird tatsächlich durch einen Hardfault gestoppt. Dank
Debugger lies sich die genaue Codezeile reproduzierbar ermitteln. Die
if-Abfrage führt unmittelbar zum Hardfault. Im Bild eine
Zusammenstellung aus der IDE.
Was man doch plötzlich mit einem Debugger so alles sieht ;-)
Wo zeigt denn die Adresse 0x5fe0654 im Screenshot (Pointer zu substate)
hin? Laut dem RP2350 Datenblatt 3.8.2.2 ist das keine gültige Adresse.
Und dann bekommst du einen Fault beim Zugriff.
Schau doch mal mit dem Debugger nach was dort im Moment der Zuweisung an
st steht und ob der "substate" Member nicht vielleicht irgendwo mit dem
Wert 0x5fe0654 überschrieben wird.
Sag mal, das dein Stack gross genug ist, das hast du schon geprueft? Ich
frag ja nur...
Kuck dich auch mal an wo dein Stack endet und wo deine Daten im Speicher
liegen. Nicht das Stack und Speicher fuer malloc zusammenknallen.
Vanye
>> schreibst?
Sorry, verstehe nicht wozu?
st->substate->inverse wird doch auch hier zum crash führen.
Vanye R. schrieb:> Sag mal, das dein Stack gross genug ist, das hast du schon geprueft? Ich> frag ja nur...
Auf jeden Fall gute Frage, bin mir nicht sicher. Nur die Hinweise, dass
die Zeiger der dynamischen Allokierungen noch alle satt im RAM lagen.
Hab mir zum Test sowas zurechtgelegt, crashed aber auch:
1
volatileuint32_tsta,hea,*psta,*phea;
2
sta=12345678;
3
psta=&sta;
4
hea=12345678;
5
phea=malloc(4);
6
*phea=12345678;
mit
1
psta=0x20081f68
2
*psta=12345678
3
phea=malloc(4)=>decl_isr_bkptisr_svcall
0x20081f68 ist nur minimal unterhalb RAM-Ende, kann das nicht einordnen.
Gehe davon aus, dass der Stack bei dem uC zu niedrigeren Adressen
wächst, oder?!
Richard W. schrieb:> Wo zeigt denn die Adresse 0x5fe0654 im Screenshot (Pointer zu substate)> hin?>> Schau doch mal mit dem Debugger nach was dort im Moment der Zuweisung an> st steht und ob der "substate" Member nicht vielleicht irgendwo mit dem> Wert 0x5fe0654 überschrieben wird.
Der "substate" Member meandert wild auf illegalen Adressen im Speicher,
warum weiß ich noch nicht.
Beim Anlegen der übergeordneten Struktur:
1
&mon.fft_work=0x20023708
2
&mon.fft_cfg.substate=0xf0000000
3
&mon.fft_cfg.substate.inverse=0
etwas später wieder andere Adresse
1
this.mon.fft_work=0x20023708
2
this.mon.fft_cfg.substate=0x67406ba
3
this.mon.fft_cfg.substate.inverse=0
Dem sollte ich als nächstes nachgehen. Vielen Dank für den Hinweis.
Informier dich mal darüber wie man „Memory Watchpoints“ setzt. Das
sollte vom RP2350 unterstützt werden. Damit kannst du herausfinden wer
wann an die Stelle schreibt.
Ich glaube ich muss mich näher mit dem Memory-Layout des RP2350
befassen.
Hier steht etwas über den RP2040, wird nicht so weit entfernt sein:
https://petewarden.com/2024/01/16/understanding-the-raspberry-pi-picos-memory-layout/
Sinngemäß steht da, dass die beiden M-cores jeweils ihren eigenen Stack
haben, default 2kByte und direkt untereinander. Mit irgend einer
Linker-Option kann man die Grenzen steuern.
Habe natürlich ordentlich Arrays mit mehreren kByte auf den Stack von
Kern 0 gepackt. Auf Kern 1 läuft auch einiges.
Im erfolgreichen Stand-alone-Test nur Kern 0 benutzt und so konnte sich
nichts in die Quere kommen.
> Ich glaube ich muss mich näher mit dem Memory-Layout des RP2350> befassen.
Eigentlich gehoert doch mit zu den ersten Dingen wenn man ein Projekt
startet das man mal einen Blick in sein Linkerscript wirft und eventuell
anpasst. Das hat nichts mit dem Prozessor zutun.
Vanye
War bisher nie notwendig, hatte auch noch nie mit einem multicore uC zu
tun. Mit denen ich arbeitete, konnte man den Stackpointer bei der
Initialisierung zur Laufzeit setzen.
Aber wenn dir das so geläufig ist, vielleicht hast du einen Tipp wo man
das findet? In der CMake CMakeLists.txt steht auf den ersten Blick
nichts, vielleicht irgendwo in den zahlreichen verlinkten Scripten.
> Aber wenn dir das so geläufig ist, vielleicht hast du einen Tipp wo man> das findet?
Leider nicht, ich hab meine eigene Umgebung aufgesetzt weil ich cmake
indiskutable finde. .-)
Such einfach mal in deinem Dateibaum nach *.ld
Vanye
Dennoch glaube ich dass das eine heiße Spur ist, suche weiter.
An CMake kommt man heute kaum vorbei. Kleine Sachen sind kein Problem,
das hier ist aber nicht mehr klein.
Und die Autotools vergangener Tage will auch keiner mehr haben.
> Dennoch glaube ich dass das eine heiße Spur ist, suche weiter.
Suchen kannst du ja auch erstmal im mapfile. Das sollten die Werte auch
drin stehen. Nur anpassen wirst du es im ld-file muessen.
Und erinnere dich meines Tips mit 0xdead. Wenn du in deinem startupfile
den Speicher damit fuellst dann kannst spaeter im Hardfaulhaendler
suchen bis wo sich was veraendert hat. Ich bin da manchmal echt
ueberrascht wie wenig Stack eine Anwendung so braucht, manchmal aber
auch wieviel.
Vanye
Wulf D. schrieb:> Habe natürlich ordentlich Arrays mit mehreren kByte auf den Stack von> Kern 0 gepackt. Auf Kern 1 läuft auch einiges.
Mach das doch mal statisch.
Geht evtl. am schnellsten? Dann kannst du ggfs. mit den vorgesehenen
Defaultwerten weiterarbeiten.
900ss schrieb:> Mach das doch mal statisch.> Geht evtl. am schnellsten? Dann kannst du ggfs. mit den vorgesehenen> Defaultwerten weiterarbeiten.
Statisch heißt die Daten müssen auf den Stack. Da habe ich doch
vermutlich das Problem, dass dort per default nur 4k Platz ist. Weiter
Objekte vom Heap auf den Stack packen hilft nicht.
Die Stack-Pointer müssen runter gesetzt werden.
_stack_low_core0 = _estack_core0 - 0x2000; /* untere Grenze */
7
_stack_low_core1 = _estack_core1 - 0x2000;
und per so etwa in die CMakeLists.txt gebaut: die dritte Zeile gab es
vorher nicht.
1
add_executable(pico2 ${PICORX_SRCS})
2
target_compile_features(pico2 PUBLIC c_std_11)
3
target_link_options(pico2 PUBLIC "-Wl,--script=../linker.ld")
Hat leider Null Effekt, wenn ich dem MAP-File trauen kann. Gibt aber
auch keine Fehlermeldungen. Den Syntax irgendwo im Netz gefunden,
vielleicht fehlerhaft. Oder falsche Stelle im Script, oder ...
Wulf D. schrieb:> Statisch heißt die Daten müssen auf den Stack.
Äh nö. Gerade dann sind sie nicht auf dem Stack sondern im Datensegment
außerhalb des Stacks Entweder in .data oder .bss. Mit 0 initialisierte
Variablen landen in .bss sonst .data. Kannst du ja im Mapfile sehen.
Wulf D. schrieb:> Den Syntax irgendwo im Netz gefunden
Das ist so eine Sache, irgendwo gefunden. Aber nicht verstanden. Dann
weiß man nicht was da passiert.
Aber zugegeben, Linker Scripts sind ggfs. auch nicht ohne.
Wulf D. schrieb:> Sorry, verstehe nicht wozu?> st->substate->inverse wird doch auch hier zum crash führen.
Nö, das tut es nicht. C nutzt etwas, was sich "short-circuit-evaluation"
nennt.
Ein zusammengesetzter Ausdruck wie
1
if(st&&st->substate&&st->substate->inverse)
wird Schritt für Schritt von links nach rechts ausgewertet. Sobald einer
der Schritte ein ungültiges Ergebnis (logisch false) liefert, wird die
Auswertung abgebrochen.
Und damit wird, wenn z.B. der Pointer "st" NULL ist, der Rest nie
ausgewertet, und gleichermaßen, wenn zwar "st" nicht NULL ist, aber
"st->substate", dann wird dieser Pointer nicht dereferenziert.
"short-circuit-evaluation" gibt es auch bei logischem Oder, da wird
abgebrochen, sobald der erste Schritt ein gültiges Ergebnis (logisch
true) liefert.
Der Sachverhalt ist mir bekannt. Dachte nur, da die Adresse der Struktur
substate außerhalb der definierten Adressbereiche steht, wäre das
sinnlos.
Werde es trotzdem mal testen.
@900ss: hast Recht mit den Segmenten. Habe mal im MAP-File ein wenig
geschaut und ein paar RAM-Adressen notiert.
1
2
bis: 0x2000de5c - vorhandener, lauffähiger Code. Nutzt keine dynamische Alloc.
3
bis: 0x2001169c - 14400kB, mehrere neu hinzugefügte Buffer
4
0x2001169c - .bss.heap_end.0
5
bis: 0x2001EBF8 - 9608kB me->window neue dynamische Allokation
6
bis: 0x20021180 - 9608kB me->last_frame neue dynamische Allokation
7
bis: 0x200295e0 - 24276kB fft_work_size neue dynamische Allokation
8
bis: 0x2003DC60 - 83584kB waterfall_ini neue dynamische Allokation
9
10
271264₁₀kByte freier Speicher?
11
12
0x20080000 __StackLimit
Der msp (main stack pointer) steht nach der Speicherinitialisierung bei
0x20081f78 und unmittelbar vorm Crash bei 0x2007d450.
Ich denke das ist der Fehler.
Glaube der Versuch Elemente vom Stack wo anders hin zu verschieben ist
sinnlos. Die Grenzen müssen verschoben werden. Wenn ich nur wüsste wie.
Wulf D. schrieb:> Glaube der Versuch Elemente vom Stack wo anders hin zu verschieben ist> sinnlos.
Glauben heißt nicht wissen!
Und weshalb sollte es sinnlos sein, den Stackverbrauch zu reduzieren
wenn er sonst überläuft? Was spricht dagegen, die großen Arrays statisch
zu machen?
Hast du Angst dass es dann funktionieren könnte? ;)
Quatsch, die großen Arrays liegen doch gar nicht auf dem Stack. Habe ich
mit der Liste oben versucht zu zeigen.
Auf dem Stack liegt nur Kleinkram, macht halt auch „Mist“.
Aber darunter liegen noch über 250kByte freier Speicher!
Warum den liegen lassen und statt dessen - vielleicht vergeblich - den
Code Byte für Byte optimieren?
Konkret: ein Linkerscript, mit dem man den 0x20081000 __StackOneTop von
Core 1 auf vielleicht 0x20078000 setzen, und __StackOneBottom sowie
__StackLimit noch ein Stückchen darunter platzieren kann: das wäre es
doch?!
Wulf D. schrieb:> Quatsch, die großen Arrays liegen doch gar nicht auf dem Stack.Wulf D. schrieb:> Habe natürlich ordentlich Arrays mit mehreren kByte auf den Stack von> Kern 0 gepackt. Auf Kern 1 läuft auch einiges.
Was du als "Quatsch" bezeichnest, schrieb ich genau deshalb.
Ich rate dir noch einmal dazu, dein eingedampftes Projekt offen zu legen
und zwar so dass es andere nachvollziehen können. Das garantiert zwar
nicht dass du eine Lösung präsentiert bekommst, aber es würde die
Chancen deutlich erhöhen und Zeit sparen.
900ss schrieb:> Was du als "Quatsch" bezeichnest, schrieb ich genau deshalb.
Ja sorry, da hattest du mich ja bereits mit dem Verweis auf das Map
-File korrigiert. Da habe ich auch die Arrays wiedergefunden, eben nicht
im Stack, sondern unten im RAM, unterhalb des Heap.
Richard W. schrieb:> Ich rate dir noch einmal dazu, dein eingedampftes Projekt offen zu legen> und zwar so dass es andere nachvollziehen können. Das garantiert zwar> nicht dass du eine Lösung präsentiert bekommst, aber es würde die> Chancen deutlich erhöhen und Zeit sparen.
Das eingedampfte funktioniert ja. Was soll das bringen?
Meinst du nicht auch, dass der Fehler gefunden ist?
Bin mir ziemlich sicher, dass sich die beiden Cores den Stack
gegenseitig überschreiben, weil der genutzte Speicherbereich überlappt.
Der Core 0 braucht mehr Stack. Genug RAM ist da.
Das Problem ist gelöst, es lag tatsächlich an den gegenseitig
überschriebenen Stacks.
Zwei Lösungen finden sich in diesem Thread:
https://forums.raspberrypi.com/viewtopic.php?p=2342300&hilit=linker+script#p2342300
Da ist einmal der Einsatz eines Linker-Scripts, wie schon von Vanye
vorgeschlagen.
Muss an geeigneter Stelle im CMakeLists.txt verlinkt werden, Syntax wie
folgt:
Erste Zeile ist optional. Als Basis nimmt man eines der Templates aus
dem SDK, die aber aktiv nicht verwendet werden. Jedenfalls hat es keinen
Effekt wenn man direkt darin editiert. Also z.B. memmap_default.ld aus
den Tiefen des SDK
.../pico/pico-sdk/src/rp2_common/pico_crt0/rp2350 in den Projektordner
kopieren, anpassen und im CMake verlinken.
Die zweite Methode, gerade erfolgreich ausprobiert, ist den Stack des
Core 1 beim Starten des Threads tiefer im RAM zu positionieren. Es gibt
dafür eine Methode im SDK. Beispiel, untere Adresse 0x2007B000 mit
4kByte Stack darüber.
Das ergibt für den darüber liegenden Core 0 Stack
20082000−2007B000−1000=6000, also rund 24kByte Stack. Etwas übertrieben,
noch zu optimieren.