Hallo! Ich finde immer interessante Bauanleitungen im Netz mit englischem Text welchen ich nur per Screenshot und speichert als JPG sicher kann. Das ganze lässt sich so nicht in einen Translator einfügen. Hat jemand einen Tip wie ich trotzdem zu einer Übersetzung komme ? Ich probiere schon rum, einiges muss ich noch testen. Gibt es ein Tool? MfG
Die Schrifterkennung gimagereader ist kostenlos, damit kann man auch pdf direkt erkennen lassen. https://sourceforge.net/projects/gimagereader/ https://github.com/manisandro/gImageReader/releases
Wie wäre es mit Kopieren und Einfügen statt Bildschirmkopie als Grafik? Für Text in Grafikdatei gibts OCR. Es gibt auch Übersetzer die beides machen.
Hier die URL der zu übersetzenden Seite eingeben: https://translate.google.com/?sl=auto&tl=de&op=websites
Mario M. schrieb: > Wie wäre es mit Kopieren und Einfügen statt Bildschirmkopie als Grafik? > Für Text in Grafikdatei gibts OCR. Es gibt auch Übersetzer die beides > machen. Gibt echt Seiten die Informationen liefern würden aber nur wenn man sich anmeldet. Wenn man sich nicht anmelden will, bleibt nur der Screenshot. Vorteil, man kann alles als Bild erstellt das ganze vom Müll drumherum befreien. Gerade sehe ich bei meinem PDF- Reader ,dass der Text erkennen kann... Da fällt mir was ein, weil Libre Office Writer in PDF konvertieren kann. Das werde ich gleich testen...
Herbert Z. schrieb: > Gibt echt Seiten die Informationen liefern würden aber nur wenn man sich > anmeldet Google Chrome kann doch jede beliebige Seite live übersetzen, egal ob angemeldet oder nicht.
Bingo! Also ich habe das Foto mit dem Text in ein Libre Office Textdokunment eingefügt und das ganze in ein PDF konvertiert. Im PDF Reader konnte ich dann die Bildschrift in Text umwandeln. Jetzt kann ich übersetzen und die Übersetzung mir als Textdokument speichern. Sind mehrere Schritte aber es geht. Ich freue mich! Niklas G. schrieb: > Google Chrome kann doch jede beliebige Seite live übersetzen, egal ob > angemeldet oder nicht. Google kann nicht alles übersetzen und wenn doch , dann lässt sich das auf manchen Seiten nicht kopieren, bleibt nur der Screenshot.
> Ich finde immer interessante Bauanleitungen im Netz mit englischem Text > welchen ich nur per Screenshot und speichert als JPG sicher kann. D Man macht es den OCR tools einfacher sobald man das Ganze als *.png mit wenigen Farben ohne dithering abspeichert. *.Jpg fügt dem Ganzen weitere Fehler zu. Und die Übersetzung sollte man unbedingt händisch überarbeiten, es soll technische Katastrophen gegeben haben, weil man fremde Baupläne nachbaute ohne sie zu verstehen. https://de.wikipedia.org/wiki/Not-invented-here-Syndrom
Herbert Z. schrieb: > Gibt es ein Tool? Tesseract OCR [1,2]. [1] https://github.com/tesseract-ocr/tesseract [2] https://tesseract-ocr.github.io/tessdoc/#tesseract-user-manual
Bradward B. schrieb: > *.Jpg fügt dem Ganzen weitere > Fehler zu. Im Textfoto gibt es nur schwarz und weiß..., mehrere Teile lassen sich sinnvoll zusammenfügen und unwichtiges ausschneiden...
Herbert Z. schrieb: > Also ich habe das Foto mit dem Text in ein Libre Office Textdokunment > eingefügt und das ganze in ein PDF konvertiert. Im PDF Reader konnte ich > dann die Bildschrift in Text umwandeln. Jetzt kann ich übersetzen und > die Übersetzung mir als Textdokument speichern. Sind mehrere Schritte > aber es geht. Ich freue mich! Ein schönes Beispiel für: Von hinten durch die Brust ins Auge geschossen.
Norbert schrieb: > Ein schönes Beispiel für: > Von hinten durch die Brust ins Auge geschossen. Mag sein, aber dafür mit Software die er schon kennt und hat.
Norbert schrieb: > Ein schönes Beispiel für: > Von hinten durch die Brust ins Auge geschossen. Ein gutes Beispiel für nur lästern...
Herbert Z. schrieb: > Ein gutes Beispiel für nur lästern... Ach, da interpretierst du zu viel hinein. Wenn ich lästere, dann merkt man das.
Herbert Z. schrieb: > Google kann nicht alles übersetzen und wenn doch , dann lässt sich das > auf manchen Seiten nicht kopieren, bleibt nur der Screenshot. Warum noch kopieren wenn du es dann einfach in der übersetzten Form lesen kannst? Kannst ja auch immer noch als (übersetztes) PDF speichern.
Herbert Z. schrieb: > Gibt echt Seiten die Informationen liefern würden aber nur wenn man sich > anmeldet. Wenn man sich nicht anmelden will, bleibt nur der Screenshot Da fehlt mir gerade die Phantasie. Magst Du uns ein Beispiel nennen?
Herbert Z. schrieb: > Bradward B. schrieb: >> *.Jpg fügt dem Ganzen weitere >> Fehler zu. > > Im Textfoto gibt es nur schwarz und weiß..., mehrere Teile lassen sich > sinnvoll zusammenfügen und unwichtiges ausschneiden... Hier hat Beumel recht - Jpg ist wegen der Kompressionsartefakte ungeeignet. Nimm PNG. Das kann man genauso zusammenstückeln, aber es entfallen die Kompressionsartefakte. Keine Matschkanten an Schwarz/Weiß-Kontrasten.
Ein T. schrieb: > Herbert Z. schrieb: >> Gibt es ein Tool? > > Tesseract OCR [1,2]. > > [1] https://github.com/tesseract-ocr/tesseract > [2] https://tesseract-ocr.github.io/tessdoc/#tesseract-user-manual Mal eine Frage, leicht off-topic: Wird Tesseract eigentlich noch "inhaltlich" weiter entwickelt? Ich meine bezüglich der benutzten Algorithmen? Soweit ich weiss, stammt die OCR-Engine ursprünglich aus einem kommerziellen Projekt von HP, was aber aufgegeben wurde. Um "etwas Gutes" zu tun, wurde der Code der OpenSource-Gemeinde überlassen. Das war aber schom in den 1990er Jahren ...
:
Bearbeitet durch User
Angehängte Dateien:
-

a.png
110 KB
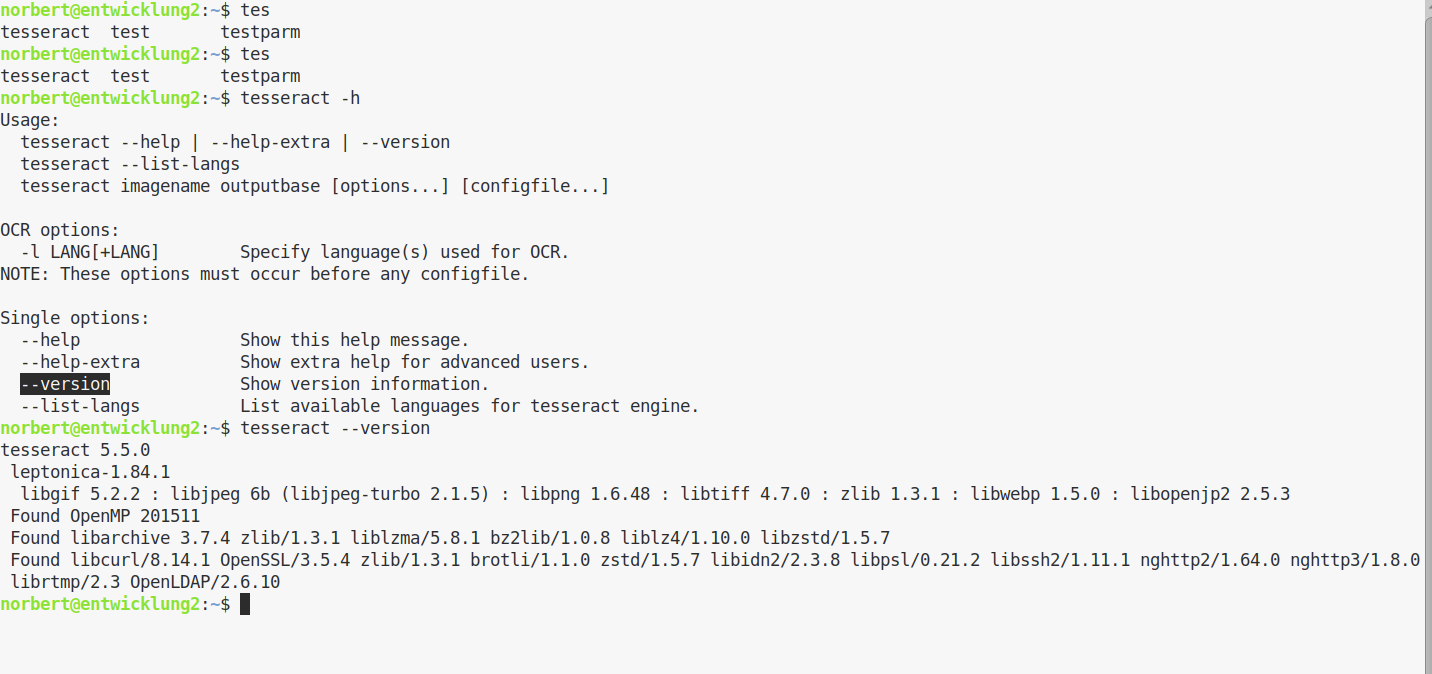
Frank E. schrieb: > Mal eine Frage, leicht off-topic: Wird Tesseract eigentlich noch > "inhaltlich" weiter entwickelt? Ich meine bezüglich der beutzten > Algorithmen? »tesseract a.png a.txt«
:
Bearbeitet durch User
Frank E. schrieb: > Wird Tesseract eigentlich noch > "inhaltlich" weiter entwickelt? Sieh Dir die Commits etc. auf https://github.com/tesseract-ocr/tesseract an. Ja, es ist davon auszugehen, daß das weiterentwickelt wird; es wird im wissenschaftlichen Bereich (Bibliothekswesen) verwenden, um auch ältere Schriftsysteme wie Fraktur zu digitalisieren.
Nemopuk schrieb: > Mag sein, aber dafür mit Software die er schon kennt und hat. Genauso ist es. Geht schneller als wenn man sich irgendwo einarbeiten muss. Harald K. schrieb: > Hier hat Beumel recht - Jpg ist wegen der Kompressionsartefakte > ungeeignet. Nimm PNG. Das kann man genauso zusammenstückeln, aber es > entfallen die Kompressionsartefakte. Keine Matschkanten an > Schwarz/Weiß-Kontrasten. Nach dem Übersetzen ist das ganz normaler Text in guter Qualität fertig um ihn zu kopieren und in Libre Office Writer einzufügen und abzuspeichern. Mario M. schrieb: > Da fehlt mir gerade die Phantasie. Magst Du uns ein Beispiel nennen? https://de.scribd.com/document/578569099/Simple-Rx-Magnetic-Loop ...um nur ein Beispiel zu nennen. Solche Sachen gibt es öfter als es mir lieb ist. Ich will mich aber nicht immer überall anmelden und meine Daten verbreiten.
Harald K. schrieb: > Ja, es ist davon auszugehen, daß das weiterentwickelt wird; es wird im > wissenschaftlichen Bereich (Bibliothekswesen) verwenden, um auch ältere > Schriftsysteme wie Fraktur zu digitalisieren. Da hängt wohl auch damit zusammen, dass es ein Tool gibt, um Tesseract für bisher unbekannte Schriften zu trainieren. Aller dings war das nur extrem kryptisch zu bedienen ...
:
Bearbeitet durch User
Herbert Z. schrieb: > Nach dem Übersetzen ist das ganz normaler Text in guter Qualität Ich hab' irgendwie den Verdacht, daß Du nicht verstanden hast, worum es geht. Es geht um das QUELLMATERIAL, das Du zurechschnibbelst, um es Deiner OCR vorzuwerfen. Und wenn das QUELLMATERIAL die üblichen JPEG-Artefakte enthält (egal, ob das jetzt s/w oder bunt ist), dann erhöht das völlig unnötig die Fehlerrate Deiner OCR. PNG kannst Du exakt genauso zurechtschnibbeln wie JPG, aber es enthält keine Kompressionsartefakte und liefert daher bessere OCR-Ergebnisse. (Wenn Du Deine Dokumente übrigens auf solchen Seiten wie "scribd" betrachtest, dürfte dieser Link Dir einiges an lästiger Arbeit ersparen: https://scribd.vdownloaders.com/)
Harald K. schrieb: > (Wenn Du Deine Dokumente übrigens auf solchen Seiten wie "scribd" > betrachtest, dürfte dieser Link Dir einiges an lästiger Arbeit ersparen: Habe ich gerade getestet...geht, aber das Prozedere bis man durch ist dauert länger als ganze so zu machen wie ich das beschrieben habe. Danke trotzdem für den Link.
Angehängte Dateien:
-

HistoOfText.PNG
100 KB
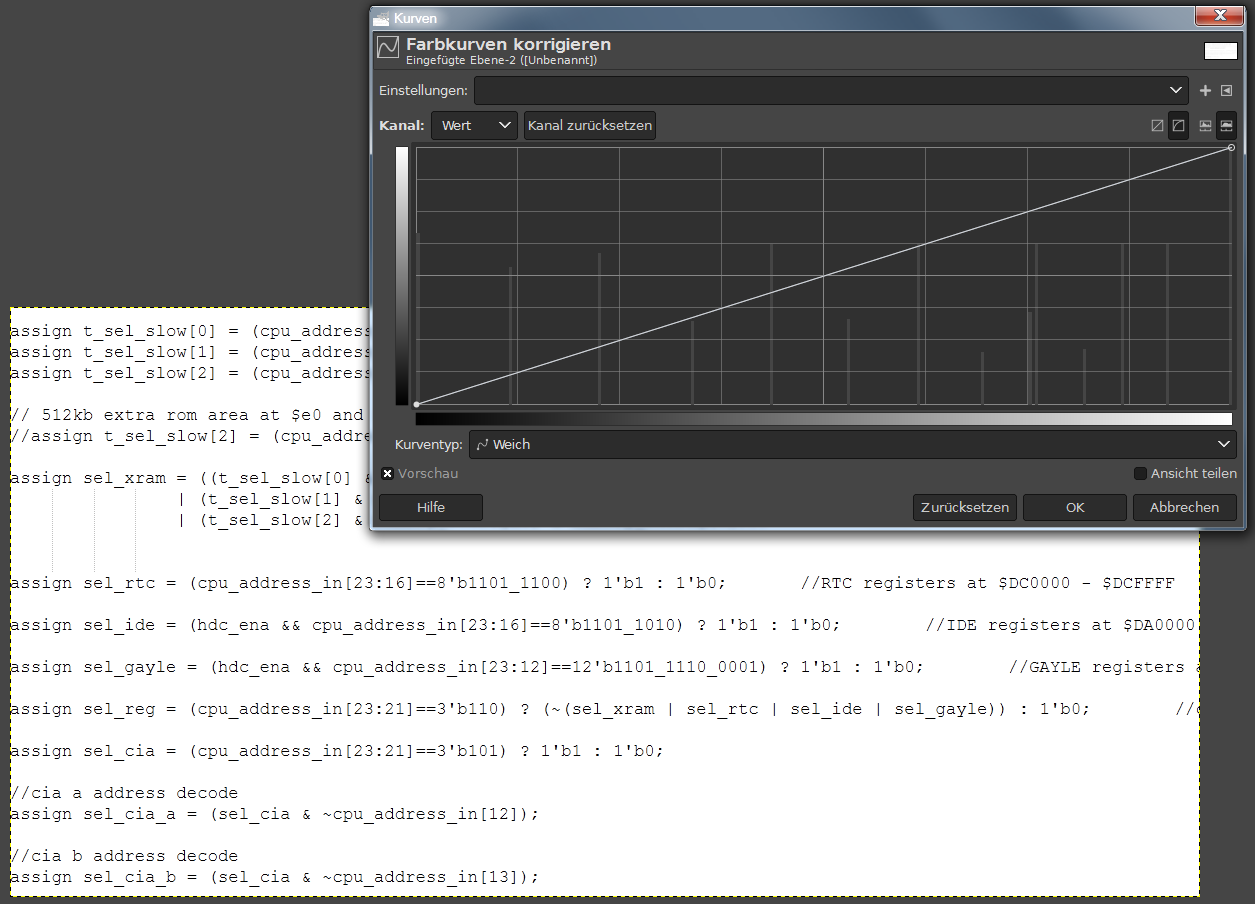
> > Im Textfoto gibt es nur schwarz und weiß..., mehrere Teile lassen sich > sinnvoll zusammenfügen und unwichtiges ausschneiden... Wenn das Textfoto nur schwarz und weiß hat, dann ist das gut, das sollte man aber denoch überprüfen. Hier habe ich mal ein Teil einer Textanzeige als screenshot ausgeschniden, in eine Bildverarbeitung geladen, das Histogramm anzeigen lassen und wiederum ausgeschnitten und unverändert als png abgepeichert. (sieha Anhang) Und lt. Histogramm ist das Textfenster nicht zweiwertig aschwarz und weiß sondern besteht aus ca 13 Farbtönen. Ich tippe das solchesolche "Windows-Ausgabe-Verbesserungen" wie Subpixelschärfung (Cleartype) und reduzierung Blautöne gegen Kopfschmerzen (Blaulichtfilter) dazu führen, das ein "Textfoto" unerwarteterweise mehr als nur schwarz und weiss enthält. Das macht es der OCR nicht einfacher, denke ich. * https://de.wikipedia.org/wiki/Subpixel-Rendering * https://www.giga.de/tipp/windows-10-blaulichtfilter-nachtmodus-aktivieren/
Herbert Z. schrieb: > aber das Prozedere bis man durch ist > dauert länger als ganze so zu machen wie ich das beschrieben habe. Äh ... keine Ahnung, was Du da anstellst. Wenn Du nur einseitige Dokumente betrachtest, mag das sein, aber wenn es um mehrseitige Dokumente (Datenblätter, Bücher etc.) geht, dann definitiv nicht. Da fällt 'ne PDF-Datei raus und fertig. Wenn man keinen Adblocker verwendet, wird man vermutlich mit Reklame zugeschissen, aber genau deswegen verwendet man ja Adblocker.
Harald K. schrieb: > Äh ... keine Ahnung, was Du da anstellst. Ich habe das auf dieser SCRIPD Seite mit deinem Link als PDF herunterladen können. Allerdings in englisch. Dann habe ich das PDF im Google Übersetzer ins deutsche übersetzt. Soweit so gut! Vorteil Ich habe das samt Fotos in einer PDF Datei. Aber mein Problem ist so oder so gelöst. Danke allen welche sich konstruktiv geäußert haben. MfG
Herbert Z. schrieb: > Also ich habe das Foto mit dem Text in ein Libre Office Textdokunment > eingefügt und das ganze in ein PDF konvertiert. Im PDF Reader konnte ich > dann die Bildschrift in Text umwandeln. Bis jetzt hast Du ja noch nicht geschrieben, dass die englische Bauanleitung mit Text, die Du verwursten willst, direkt in eine Grafik eingebettet ist (Du redest nur von Screenshot als Quelle). Also nutze doch einfach die Druckfunktion des Browser, und wähle als Ziel PDF aus. Dann hast Du Dein PDF mit echtem Text ...
Angehängte Dateien:
> https://de.scribd.com/document/578569099/Simple-Rx-Magnetic-Loop > > > ...um nur ein Beispiel zu nennen. Solche Sachen gibt es öfter als es mir > lieb ist. Ich will mich aber nicht immer überall anmelden und meine > Daten verbreiten. Soll die Übersetzung so etwa aussehen?
Deepl übersetzt besser als Google. Mit einem Deeple Pro Account habe ich schon ganze Bücher (300-400 Seiten) übersetzt. Limit ist übrigens nicht die Anzahl der Zeichen oder Worte, sondern die rein physische Dateigröße.
Angehängte Dateien:

Harald K. schrieb: > um auch ältere > Schriftsysteme wie Fraktur zu digitalisieren. In gimagereader gibt es eine wählbare Erkennung von Frakturschrift- Hab gerade mal ein Bild erkennen lassen, irgendwo gefunden https://www.fraktur.com/storage/images/... (elend lange URL) Das Ergebnis ist nicht sehr ermutigend: Zur freien Entwiclung nad allen Seiten bedarf jede Pflanze etwas Luft und Licht, das ihr gerade fo meit gewährt werden muß, als zur Befundheit, Dichtigfeit und Fülle aller nötig ift. Es ift dies die Freiheit der Bäume, nach der wir ung ebenfalls fo fehr fehnen. die Schrifterkennung lispelt, das "s" ist ein Problem.
:
Bearbeitet durch User
Herbert Z. schrieb: > welchen ich nur per Screenshot und speichert als JPG sicher kann Bei schlechten Bildern ist oft die OCR-Erkennung weniger fehlerfrei. Der Google-Übersetzer hat jedoch einige Heim-Vorteile, da er viele Wörterbücher als Vergleichsmaterial kennt.
Tesseract (Standard)
1 | Zur freien Entwiclung nach allen |
2 | Seiten bedarf jede Pflanze etwas |
3 | Luft und Licht, das ihr gerade fo |
4 | weit gewahrt werden mug, als zur |
5 | Sefundheit, Dichtigteit und Fille |
6 | aller notig ift. |
7 | |
8 | G8 ift dies die Fretheit ber Gaume, |
9 | nach det wit uns ebenfalls |
10 | |
11 | fo feht fehnen. |
12 | |
13 | First Hermann von Piickler-Muskau |

Karlsson V. schrieb: > ChatGPT 5.2 kann das fehlerfrei. Das muss gar nichts bedeuten. Das kommt auch dann zustanden, wenn der KI-Slop-Generator in seinem Trainingsmaterial irgendwo eine Abbildung des Textes und eine Transkription gesehen hat. Dem KI-Slop-Generator würde ich deswegen nocht lange keine Fähigkeiten andichten.
Karlsson V. schrieb: > ChatGPT 5.2 kann das fehlerfrei. KI kann nur das fehlerfrei, wo vorher ein Muster gelernt wurde. Wenn es eine alte Stückliste in Frakturschrift gewesen wäre, wo kein Muster davon im Web zu finden ist, wären die Ergebnisse schlechter.
Angehängte Dateien:
-

rapunzel.png
22 KB

Aus: „Rabrunsel las dein Baart herunter.“, rief der Prins zum Torm herauf. wird durch ShitGPT: „Rabunsel lass dein Bart herunter“, rief der Prinz zum Tor hinauf. Die Frage ist nun, möchte ich eine Texterkennung oder eine geratene Interpretation unter magischem Pilzbrühen-Einfluß.
Norbert schrieb: > Die Frage ist nun, möchte ich eine Texterkennung oder eine geratene > Interpretation unter magischem Pilzbrühen-Einfluß. Viel Spass mit einer wörtlichen Übersetzung eines aktuellen Textes aus traditionellem chinesisch.
Angehängte Dateien:

{kind=link}
> Das muss gar nichts bedeuten. Das kommt auch dann zustanden, wenn der > KI-Slop-Generator in seinem Trainingsmaterial irgendwo eine Abbildung > des Textes und eine Transkription gesehen hat. Oder der Namen des Autors verlinkt mit der Zitatesammlung seiner. Bspw.: https://www.garten-literatur.de/Leselaube/pueckl.htm Grad bei alten Texten deren Schutzrechte abgelaufen sind, gibt es nicht nur Dank des Projektes Gutenberg irgendwie eine aSCII-Version und die auch noch in heutiger Rechtschreibung. https://de.wikipedia.org/wiki/Projekt_Gutenberg-DE Anbei ein Test-Faksimilie (Rezensionen zu einem Buch) die es IMHO noch nicht fertig gescannt gibt. Da wäre interessant, wie Chat-GTP das wiedergibt.
Bradward B. schrieb: > Anbei ein Test-Faksimilie (Rezensionen zu einem Buch) die es IMHO noch > nicht fertig gescannt gibt. Da wäre interessant, wie Chat-GTP das > wiedergibt. Google-KI zeigt in Druckbuchstaben folgenden Text: "EIN PRACHTVOLLES PENDANT ZUM „KATER MURR“ IST: REINEKE FUCHS DICHTUNG VON WOLFGANG VON GOETHE REICH ILLUSTRIRT VON HERMANN SCHÜSSLER 3. AUFLAGE (6.–8. TAUSEND) PREIS IN LIEBHABEREINBAND GEBUNDEN M. 2.50 „EIN PRÄCHTIGES BILDERBUCH – DIE HUMORVOLLE GESCHICHTE DER ABENTEUER REINEKES ZU LESEN IST AN UND FÜR SICH IMMER WIEDER EIN KÖSTLICHER GENUSS. DERSELBE WIRD ABER NOCH ERHEBLICH GESTEIGERT, WENN MAN SIE AN DER HAND DER VORTREFFLICHEN BILDER HERMANN SCHÜSSLERS DURCHWANDERT. DER ZEICHNER HAT WIRKLICH DEN SCHLAUEN ROTPELZ SO LEBENDIG UND CHARAKTERISTISCH IM BILDE FESTGEHALTEN, DASS ES EINE HERZERQUICKENDE FREUDE IST. NICHT WENIGER LEBENSWAHRHEIT WEISEN DIE BILDER DER ANDEREN TIERE, DER FEINDE, FREUNDE, RICHTER DES FUCHSES AUS. FREUDE UND SCHMERZ, GRIMM UND ENTTÄUSCHUNG – DIE GANZE SKALA DER EMPFINDUNGEN KOMMT IN IHREN MIENEN UND BEWEGUNGEN ZUM AUSDRUCK. JEDEM LIEBHABER DER GOETHESCHEN DICHTUNG, JEDEM TIERFREUNDE WIRD DIESES BUCH EIN WILLKOMMENES GESCHENK SEIN.“ FRÄNKISCHE VOLKSZEITUNG. „EINE PRÄCHTIGE AUSGABE. BRESLAUER ZEITUNG. ... SCHÖNER DRUCK UND AUSGEZEICHNETE HOLZSCHNITTE, ALS DA SIND KOPF- UND SCHLUSSSTÜCKE, ABBILDUNGEN IM TEXT UND GANZSEITIGE EINSCHALTBILDER ...“ BOZNER ZEITUNG. „DIE 44 SCHÖNEN BILDER LASSEN UNS MIT DOPPELTEM VERGNÜGEN DIE GAUNEREIEN DES REINEKE VERFOLGEN. FÜR JEDEN TIERFREUND MUSS DAS BUCH GERADEZU EIN GENUSS SEIN.“ MAGDEBURG. ZEITUNG. „EINE ZIERDE FÜR DEN WEIHNACHTSTISCH UND JEDEN SALON ...“ PFÄLZISCHER MERKUR. „DA SCHLIESSLICH DIE AUSSTATTUNG DIESER AUSGABE DER EWIG JUNGEN DICHTUNG GOETHES DURCHAUS GEDIEGEN UND PRÄCHTIG IST, EIGNET SIE SICH GANZ BESONDERS ZU EINEM LIEBEN UND WILLKOMMENEN GESCHENK FÜR ALLE.“ BRAUNSCHWEIGER NACHRICHTEN."
Hier der Text von gimagereader "erkannt", auch wieder mit vielen Fehlern.
> Google-KI zeigt in Druckbuchstaben folgenden Text: > ... > „EIN PRÄCHTIGES BILDERBUCH – DIE HUMORVOLLE GESCHICHTE DER ABENTEUER ... > „DA SCHLIESSLICH DIE AUSSTATTUNG DIESER AUSGABE DER EWIG JUNGEN DICHTUNG > GOETHES DURCHAUS GEDIEGEN UND PRÄCHTIG IST, EIGNET SIE SICH GANZ > BESONDERS ZU EINEM LIEBEN UND WILLKOMMENEN GESCHENK FÜR ALLE.“ > BRAUNSCHWEIGER NACHRICHTEN." Interessant, auf den ersten Blick spricht das IMHO für die Qualität von ChatGPT. Nebenbemerkung: aus dem 'ß' in "schließlich" hat die Software ein "SS" gemacht, wohl wegen der Grosschreibung. Und aus dem .. in der ersten Rez.-Zeile zwischen "Bilderbuch .. die" wurde ein '-' > Hier der Text von gimagereader "erkannt", auch wieder mit vielen > Fehlern. Auch interessant, vielen Dank.
:
Bearbeitet durch User
Ralf X. schrieb: > Viel Spass mit einer wörtlichen Übersetzung eines aktuellen Textes aus > traditionellem chinesisch. Geht aber nicht um eine Übersetzung. Schon gar nicht um die stark symbolische Darstellung chinesischen Textes. Es geht um die Erkennung und korrekte Wiedergabe von Buchstaben im ASCII- Bereich. Nicht deren Interpretation. Weshalb wird bei ›Rabrunsel‹ das ›r‹ unterschlagen und zu ›Rabunsel‹ gewandelt? An anderer Stelle wird ein ›r‹ ja offensichtlich korrekt erkannt. Weshalb wird aus einem korrekten ›herauf‹ ein ›hinauf‹? Wieso glaub das System bei der Interpretation, dass man etwas zum ›Tor‹ und nicht zum ›Turm‹ hinauf ruft?
Norbert schrieb: > Wieso glaub das System bei der Interpretation, dass man etwas zum ›Tor‹ > und nicht zum ›Turm‹ hinauf ruft? Da steht "Torm". Mit "o". Und das ist so ungebräuchlich, daß die Fehlerkorrektur daraus ein "Tor" macht. Die Fehlerkorrektur weiß nichts von der Mundart, die der Text wiedergibt, und fällt deswegen auf die Fresse.
Harald K. schrieb: > Da steht "Torm". Da es sich um eine Interpretation handelt, sollte doch – wenn man etwas hinauf ruft – ganz klar dem Turm und nicht dem Tor Vorrang gegeben werden. Harald K. schrieb: > Die Fehlerkorrektur weiß nichts von der Mundart, die der Text > wiedergibt, und fällt deswegen auf die Fresse. Deshalb soll sie es sein lassen. So etwas kann man selbst viel besser.
Norbert schrieb: > Weshalb wird aus einem korrekten ›herauf‹ ein ›hinauf‹? > > Wieso glaub das System bei der Interpretation, dass man etwas zum ›Tor‹ > und nicht zum ›Turm‹ hinauf ruft? Dichterische Freiheit ...
Christoph db1uq K. schrieb: > Es ift dies die Freiheit der Bäume, > nach der wir ung ebenfalls > fo fehr fehnen. > > die Schrifterkennung lispelt, das "s" ist ein Problem. Fo hätte ich daf aber auch gelefen. :-)
Lu schrieb: > Karlsson V. schrieb: >> ChatGPT 5.2 kann das fehlerfrei. > > KI kann nur das fehlerfrei, wo vorher ein Muster gelernt wurde. Ja, aber anders als Du und der Kornpichler glauben. KI ist ziemlich gut darin, Zeichen -- zumal gedruckte -- zu erkennen. Darum war der MNIST-Datensatz einer der frühesten standardisierten Benchmarks für KI-Modelle. Leider ist der Link auf der Webseite von Yann LeCun defekt und aktuell finde ich nur diese Quelle [1], bei der allerdings leider das TLS-Zertifikat abgelaufen ist. Fakt ist jedenfalls, daß moderne KI-Modelle diese Aufgabe nicht nur wesentlich schneller, sondern auch deutlich besser bewältigen können als Menschen. [1] https://yann.lecun.org/exdb/mnist/
Wie wurde denn aus Rapunzels Bart ihr Haar? Bekanntlich hatten damals Frauen noch keinen Bart, hm 😆 Ich bin verwirrt.
> KI ist ziemlich gut > darin, Zeichen -- zumal gedruckte -- zu erkennen. Darum war der > MNIST-Datensatz einer der frühesten standardisierten Benchmarks für > KI-Modelle. MNIST hat aber Handschrift, nicht Typographie mit optisch teilweise widersprechenden Schriftsätzen wie Fraktur und Antiqua * https://de.wikipedia.org/wiki/MNIST-Datenbank * https://de.wikipedia.org/wiki/Fraktur_(Schrift) * https://de.wikipedia.org/wiki/Antiqua OCR bediente sich schon lange vor Einführung von ChatGPT der Künstlichen Neuronalen Netze, neudeutsch Machine learning. Wenn hier ChatGPT besser ausschaut als bspw. gimagereader dann liegt das wohl eher an einem fehlerhaften Schritt im Workflow - der Vorgabe oder auch Erkennung des als Referenz zu verwendeten Mustersatzes. gimagereader versucht sich an der Ähnlichkeit des Zeichens für 's' und scheitert bei Frakturschrift, da dort das 's' wie ein 'f' ausschaut. Und das große 'A' schaut in Fraktur wie das große 'U' aus. Und noch ein paar Stolpersteine. Trainiert man den Imagereader mit dem tatsächlich benutzten Fraktur-Schriftsatz sollte das "lispeln" passé sein. * https://www.lwl.org/waa-download/pdf/Installation%20OCR%20Software.pdf * https://forum.ubuntuusers.de/topic/gimagereader-fraktur/ PS: Ich seh grad, das mit dem 's' in Fraktur ist noch etwas verzwickter, am Wortende wird ein Zeichen/Type verwendet, das wie 's' ausschaut, am Wortanfang oder mittendrin, das das dem 'f' ähnlich ausschaut. Das ist fast so verzwickt wie farsi, auch als arabische Schrift bezeichnet, da schauen die Zeichen je nach Position im Wort anders aus. Der Teufel steckt halt im Detail ;-) (-; شیطان در جزئیات است
:
Bearbeitet durch User
Bradward B. schrieb: > und scheitert bei Frakturschrift, da dort das 's' wie ein 'f' ausschaut. Nicht "das" 's', sondern eines von beiden. Es gibt in der Fraktur nämlich auch ein 's', das dem heute gebräuchlichen entspricht. Das findet man am Silbenende, das andere hingegen am Beginn oder innerhalb einer Silbe. Siehe: https://de.wikipedia.org/wiki/Langes_s
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.